1.School of Physics, Peking University, Beijing 100871, China 2.Center on Frontiers of Computing Studies, Peking University, Beijing 100871, China 3.School of Computer Science and Technology, Guangdong University of Technology, Guangzhou 510006, China
Fund Project:Project supported by the National Natural Science Foundation of China (Grant No. 91964101)
Received Date:02 August 2021
Accepted Date:04 October 2021
Available Online:23 October 2021
Published Online:05 November 2021
Abstract:Exploiting the coherence and entanglement of quantum many-qubit states, quantum computing can significantly surpass classical algorithms, making it possible to factor large numbers, solve linear equations, simulate many-body quantum systems, etc., in a reasonable time. With the rapid development of quantum computing hardware, many attention has been drawn to explore how quantum computers could go beyond the limit of classical computation. Owing to the need of a universal fault-tolerant quantum computer for many existing quantum algorithms, such as Shor’s factoring algorithm, and considering the limit of near-term quantum devices with small qubit numbers and short coherence times, many recent works focused on the exploration of demonstrating quantum advantages using noisy intermediate-scaled quantum devices and shallow circuits, and hence some sampling problems have been proposed as the candidates for quantum advantage demonstration. This review summarizes quantum advantage problems that are realizable on current quantum hardware. We focus on two notable problems—random circuit simulation and boson sampling—and consider recent theoretical and experimental progresses. After the respective demonstrations of these two types of quantum advantages on superconducting and optical quantum platforms, we expect current and near-term quantum devices could be employed for demonstrating quantum advantages in general problems. Keywords:quantum advantages/ random circuit sampling/ Boson sampling/ classical simulation
在量子计算机上, 采样就是对随机线路进行测量. 而经典计算机上则对应的是计算输出的希尔伯特空间上的概率分布上的一次采样. 随机线路的采样在经典计算机上进行模拟被认为是困难的(没有多项式时间的经典算法能够做到)[58]. 而对量子计算机本身, 要实现大规模高深度的计算也对硬件的容错率提出了很高的要求. 因此量子电路的结构设计需要考虑到超导硬件的设计, 以及支持的简单门操作类型. 下面介绍两个特定结构的随机线路的模型. Boixo等[6]提出的随机线路模型如下: ? 执行一层H门. ? 重复$ d $轮下面两步操作. ??1)交替地执行一次图1中的CNOT门, 这里一个黑点代表一个量子比特, 两个黑点之间的连线表示这两个量子比特有门作用. 图 1 随机线路的CNOT门的8种不同的摆放方式[6]. 其中第0层全部摆放H门, 电路中每8层循环一次(重复图中1—8层), 空白节点处随机放置$ {\boldsymbol I}, {\boldsymbol T}, {\boldsymbol X}^{1/2}, {\boldsymbol Y}^{1/2} $门, 两比特门为CZ门 Figure1. Eight different layouts of the CNOT gate in the random circuit, where all of qubits are performed H gate in the $ 0 $-th layer, and cycle once every 8 layers in the circuit (repeat 1–8 layers of this graph), the blank vertices are laid out $ {\boldsymbol I}, {\boldsymbol T}, {\boldsymbol X}^{1/2}, {\boldsymbol Y}^{1/2} $ randomly, and the two-qubit gates are all CZ gates[6].
2)在每个量子比特上, 随机地作用一个集合$ \left\{ {{{\boldsymbol{I}}}, {{\boldsymbol{X}}}^{1/2}, {{\boldsymbol{Y}}}^{1/2}, {{\boldsymbol{T}}}} \right\} $中的门. 这里$ {{\boldsymbol{X}}}, {{\boldsymbol{Y}}} $依次为Pauli-$ X $门和Pauli-$ Y $门. 令$ {{\boldsymbol{A}}}^{t}: = {\rm e}^{-{\rm i}t {{\boldsymbol{A}}}/2} $. 根据该定义可得图1中$ {{\boldsymbol{X}}}^{1/2} $和$ {{\boldsymbol{Y}}}^{1/2} $门的定义. 随机线路采样是从这样的一个随机线路中进行一次采样(在电路结束时对电路在计算基下进行测量). 如果想要体现量子的性质, 这里深度$ d $需要满足一定要求. 理想的量子随机线路采样的输出分布的概率值满足Potor-Thomas分布, Boixo等[6]通过模拟实验展示了在深度超过20层时, 量子电路输出的概率值跟Portor-Thomas分布逐渐开始靠近. Google团队在2019年提出了一个更大规模的网格结构, 门的摆放更复杂的量子随机线路模型—悬铃木量子计算机, 并且在量子设备上进行了测试, 可以在几秒内实现53个量子比特, 20层两比特门的随机线路保真度至少为0.2%的采样, 该随机线路结构如图2所示[7]. 图 2 悬铃木处理器随机线路架构[7]. 其中第0层全部摆放H门, 电路每层迭代重复模式ABCDCDBA, 两个模式中间由一层随机放置的单比特门$ {\boldsymbol X}^{1/2},\; {\boldsymbol Y}^{1/2},\;{\boldsymbol W}^{1/2} $构成, 两比特门为控制相位门和部分$ i $SWAP门的乘积(部分$ i $SWAP门后跟随一个控制相位门构成) Figure2. Random circuit architecture for Sycamore processor, where all of qubits are performed H gates in the $ 0 $-th layer, the layer of the circuit iterates and repeats the pattern ABCDCDBA, a layer of random single-qubit gates are performed between two modes, which constructed by $ {\boldsymbol X}^{1/2},\;{\boldsymbol Y}^{1/2},\; {\boldsymbol W}^{1/2} $, the two-qubit gate is the multiplication of the partial-iSWAP gate and control-phase gate (constructed by partial-iSWAP gate followed by a control-phase gate)[7].
原始的玻色采样问题[9]可以描述为: $ n $个无相互作用、不可分辨的玻色子, 在单粒子希尔伯特空间维数为$ m $的Fock空间中, 从某个给定的初始状态开始, 经过确定的演化, 在末状态进行投影到占据数表象基上的测量, 每次测量获得一个$ n $玻色子态, 即称为进行了一次玻色采样. 在初始条件、演化给定的情况下, 采样结果将服从一个确定的概率分布. 以实现玻色采样实验最常用的平台—线性光学平台为例, 如图3所示, 将$ n $个单光子由波导输入一个线性光学网络中, 该网络中可能存在不同波导模式间的互相叠加、干涉等, 所以也被称作干涉仪, 并可在输出的$ m $根波导中探测到光子. 在理想情况下, 每根波导仅能携带一种模式, 输入态到输出态演化可以在占据数表象下记为 图 3 玻色采样模型[56]. 输入是$ n $个单光子, 经过线性光学网络后, 可在输出的$ m $个模中探测光子 Figure3. Device of boson sampling[56]. The input are $ n $ photons, and one can detect photons on the $ m $ output modes through a linear optical network.
玻色采样提出后, 受制于确定性单光子源制备等难点, 其实验实现一直停留在小规模展示阶段, 难以达到实现量子优越性要求的$ n\approx 50 $界限. 与此同时, 一些基于玻色采样的理论工作被相继提出, 例如容许光子损耗的玻色采样(lossy boson sampling)[12], 输入$ n+k $个光子, 但后选择出$ n $个光子的输出态, 即容许$ k $个光子的损耗, 由于对该过程的理论分析依赖于对损耗过程的理解, 所以对其能够实现量子优越性的阈值分析仍然有待解决. 在另外一些工作中, 研究者关注于利用非确定性的、更高效、易于制备的光子源, 以扩展原始的玻色采样, 达到实现量子优越性的目标. 如 Lund等[10]提出了后来被称为SBS的方案, 如图4所示. 使用$ m $模的线性光学网络, 将$ m $个概率型光子源分别置于其输入端, 每个光子源将产生处于双模压缩态的光子(区别于单光子源的输入态具有确定的光子数, 由于其光子数的概率分布特性, 也被称作高斯态的一种), 利用双模压缩态的特性, 可以设计光路, 在输出端后选择出$ n $光子的测量事件, 但是, 这一方案的输入输出均有$\displaystyle {n^2\choose n}$种可能, 导致了采样空间的大幅增长. 图 4 SBS的装置简介[63]. 该模型中输入为$ 2 m $个单模压缩态, 在其进入分束器和相移子装置后产生双模压缩态, 并通过一个额外的测量装置来固定SBS的线性光学装置$ \boldsymbol{U}_m $输入的光子数 Figure4. Brief introduction of SBS device[63]. In this model, the input are $ 2 m $ single-mode compressed states, and the two-mode compressed states are generated after entering the beam splitter and the phase-shifting sub-device. An additional measuring device is used to fix the number of input photons for the linear optical device $ \boldsymbol{U}_m $ of SBS.
Kruse等[63]随后注意到了SBS方案的缺陷: 该方法利用了概率型的光子源, 但其后选择过程却抛弃了光子源的概率特性. 他们据此提出了GBS的方案(图5), 去掉了SBS方案中的后选择过程, 直接将单模压缩态注入干涉仪, 并在输出端进行光子数测量, 他们证明了, 输出态测量得到光子数${\boldsymbol{S}} = $$ (s_1, s_2, \cdots s_m)$的概率为 图 5 GBS的装置简介[63]. 输入端为K个单模压缩态注入线性光学网络, 在输出端的M个模中进行光子数探测 Figure5. Brief introduction to GBS device[63]. The input terminal is a K single-mode compressed state injected into the linear optical network, and the photon number is detected in M modes at the output terminal.
2019年, Google团队首次在Sycamore 超导量子平台上实现了量子优越性[7]. Sycamore量子芯片上有 53 个可用的量子比特, 86 个耦合器, 量子比特和耦合器都用transmon构成, 利用微波激发量子比特, 通过磁通调节耦合, 通过连接的谐振器读出量子态. Sycamore的平均单比特错误率达到了0.15%, 同时激发时也只略微高出一点, 控制在0.16%; 双比特平均错误率为0.36%, 同时激发时为0.62%; 单独读出错误率为3.1%, 同时读出错误率为3.8%. 通过简单地把门操作和读出操作的保真度相乘, 可以估计系统的保真度. 在该实验中, 最大的随机量子线路有53个量子比特, 1113个单比特门, 430个两比特门, 对每个量子比特进行一次测量, 通过相乘的简单模型估计系统的保真度可达到0.2%. 交叉熵$ \mathcal{F}_{\text{XEB}} $的不确定度为${1}/{\sqrt{N_{\rm s}}}$, 需要百万量级次抽样($N_{\rm s}$)来从实验上测定交叉熵. 交叉熵的测定需要对由超导随机量子线路抽样产生的百万量级的比特串中的每一个给出理想分布下对应的概率幅, 这个概率幅通过模拟随机量子线路得到, 但当随机量子线路的规模过大、纠缠程度太高时, 模拟随机量子线路在事实上是不可行的, 此时达到量子优越性区域. 为了表征量子优越性区域的超导量子电路的保真度, Google团队在电路设计中采用了3种、两类线路. 线路按照连接的完整度分为3种: 全量子线路、删减量子线路、分割量子线路. 其中全量子线路是2.1节中描述的完整线路; 分割量子线路中量子电路被切分为两块, 两块之间没有相互作用的量子比特; 类似分割量子线路, 删减量子线路也对全量子线路里的双比特门进行了一些删减, 使得线路成为相对独立的两块, 但是仅仅删减了分割处的部分两比特量子门, 所以两块量子线路并不是完全独立的. 3种不同完整度的量子线路的示意图如图6(a)左下角插图所示. 按照两比特门的纠缠程度分为两类线路, 其中双比特门排列为EFGHEFGH的线路中双比特门之间纠缠程度较小, 更容易模拟, 称为简单量子线路; 而双比特门排列为ABCDCDBA的线路更难模拟, 称为复杂量子线路. 简单量子线路和复杂量子线路的示意图分别如图6(a)右上角和图6(b)左上角插图. 图 6 量子优越性证明的实验结果[7] (a)在经典可验证区, 简单全量子线路的保真度与简单删减量子线路、简单分割量子线路、简单乘积模型的保真度符合得很好, 每个数据点是多个随机量子线路采样的平均值; (b)在量子优越区, 通过更简单的线路和简单乘积模型来估计复杂全量子线路的保真度. 红色时间标志表示经典模拟复杂全量子线路的验证任务需要的时间, 灰色时间标志表示经典模拟相应的采样任务需要的时间 Figure6. Experimental results of the proof of quantum advantage[7]: (a) In the classical verifiable region, the fidelity of simple full quantum circuit accords well with that of simple truncated quantum circuit, simple split quantum circuit and simple product model. Each data point is the average of multiple random quantum circuit samples. (b) In the quantum advantage region, the fidelity of complex full quantum circuits is estimated by using simpler circuits and simple product models. The red time label represents the time required for the verification task of the classical simulation complex full quantum circuit, and the grey time label represents the time required for the corresponding sampling task of the classical simulation.























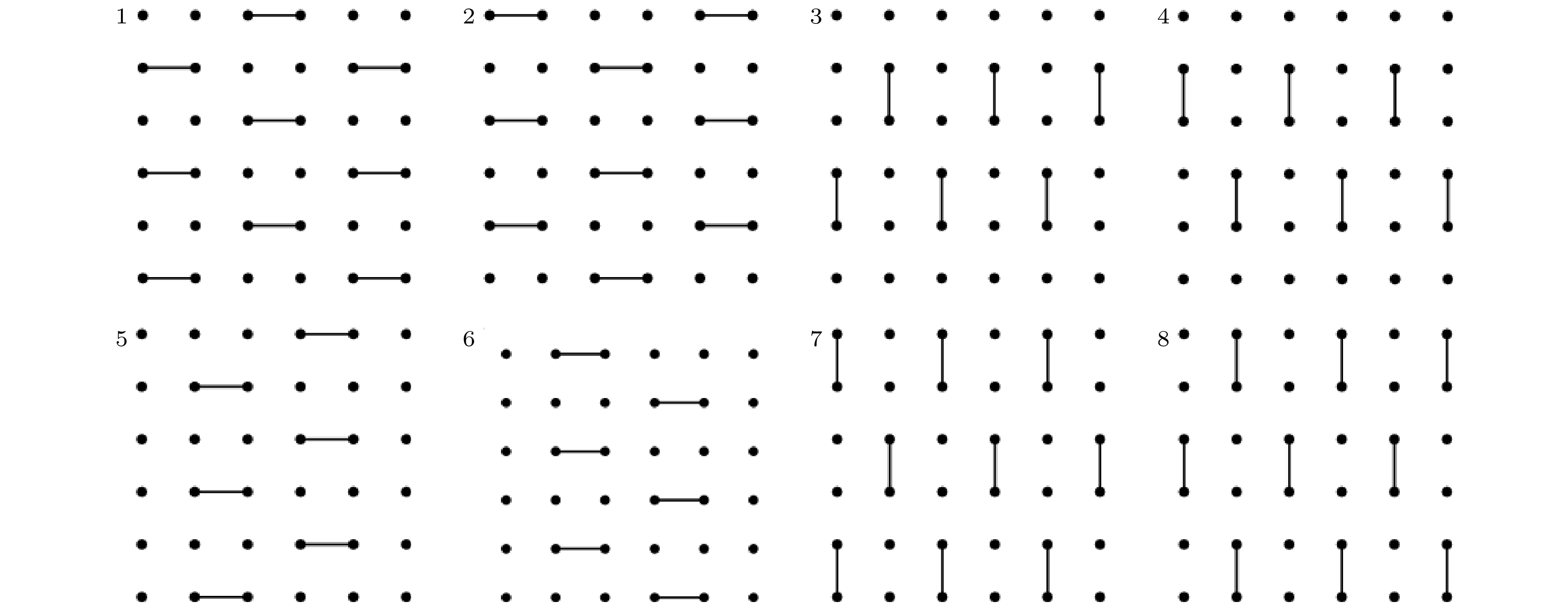 图 1 随机线路的CNOT门的8种不同的摆放方式[6]. 其中第0层全部摆放H门, 电路中每8层循环一次(重复图中1—8层), 空白节点处随机放置
图 1 随机线路的CNOT门的8种不同的摆放方式[6]. 其中第0层全部摆放H门, 电路中每8层循环一次(重复图中1—8层), 空白节点处随机放置










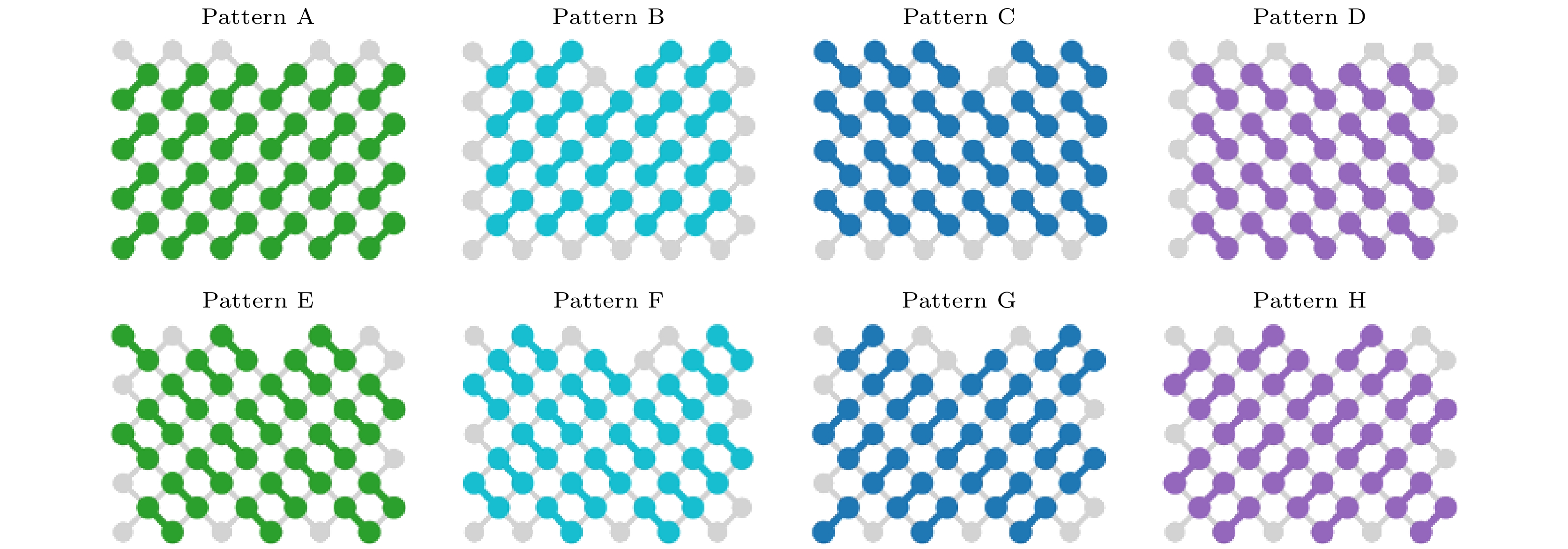 图 2 悬铃木处理器随机线路架构[7]. 其中第0层全部摆放H门, 电路每层迭代重复模式ABCDCDBA, 两个模式中间由一层随机放置的单比特门
图 2 悬铃木处理器随机线路架构[7]. 其中第0层全部摆放H门, 电路每层迭代重复模式ABCDCDBA, 两个模式中间由一层随机放置的单比特门




































































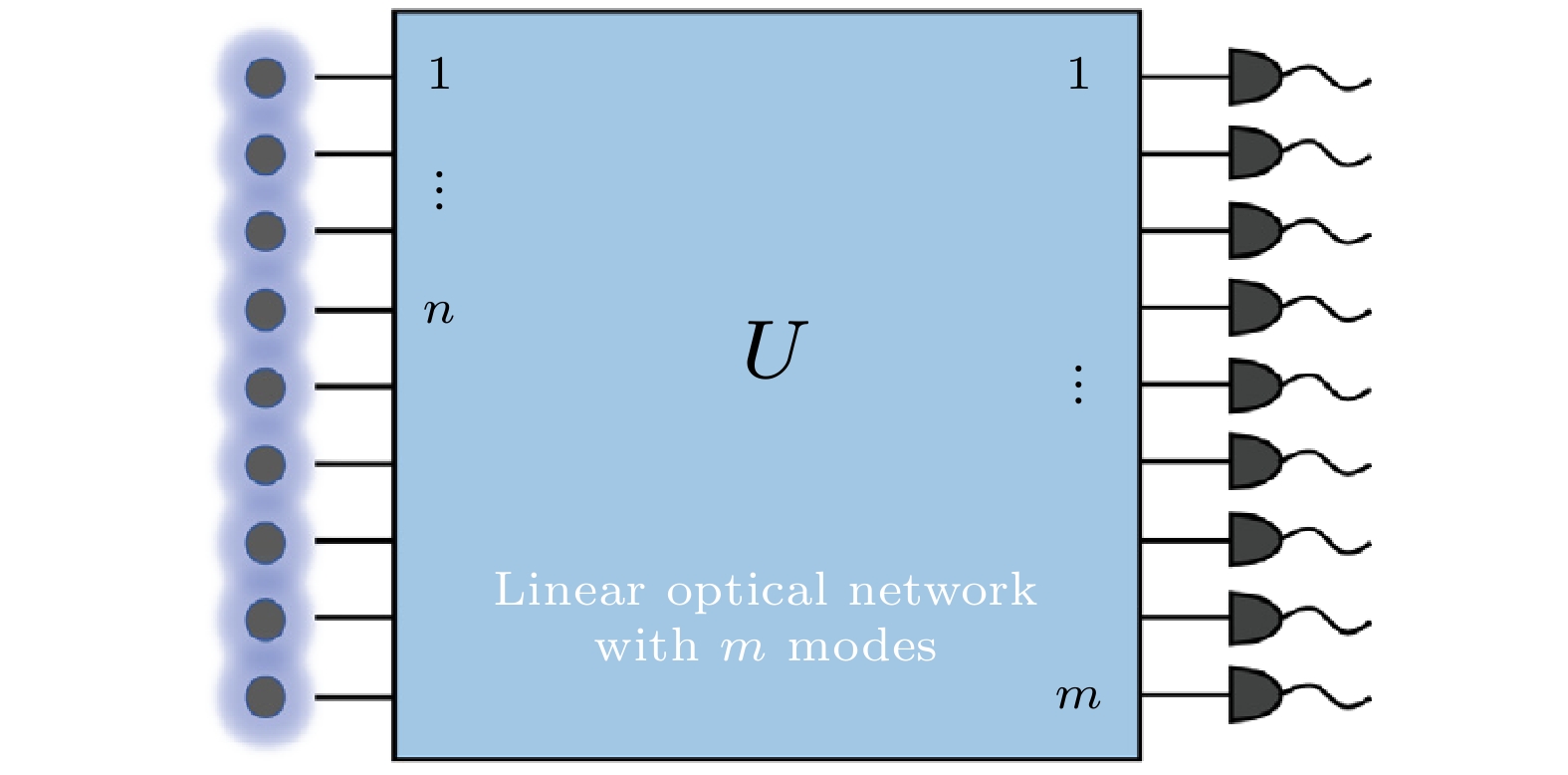 图 3 玻色采样模型[56]. 输入是
图 3 玻色采样模型[56]. 输入是













































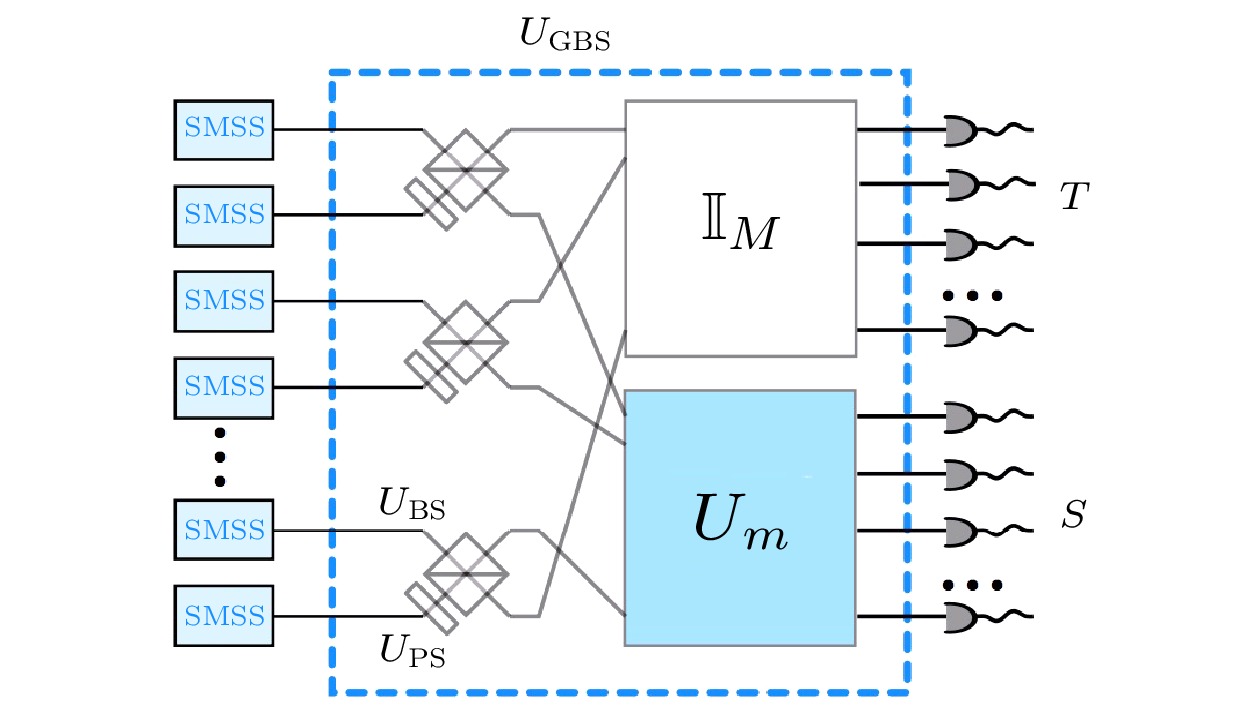 图 4 SBS的装置简介[63]. 该模型中输入为
图 4 SBS的装置简介[63]. 该模型中输入为





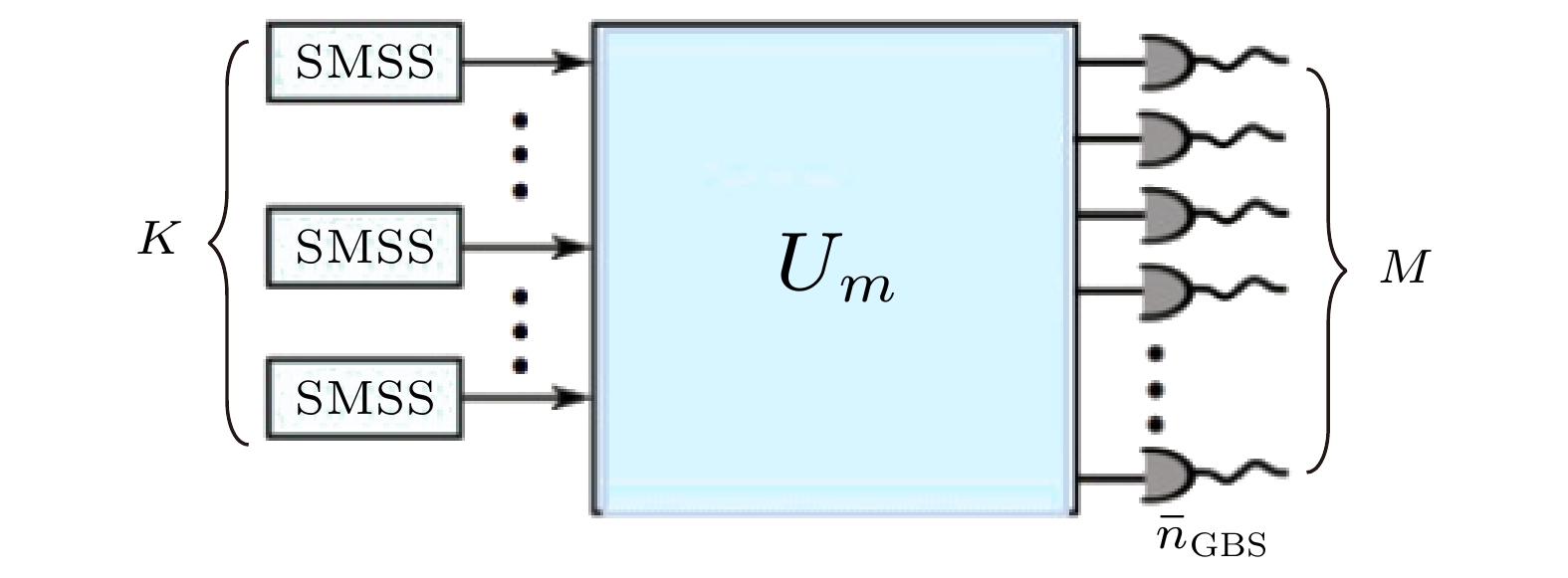 图 5 GBS的装置简介[63]. 输入端为K个单模压缩态注入线性光学网络, 在输出端的M个模中进行光子数探测
图 5 GBS的装置简介[63]. 输入端为K个单模压缩态注入线性光学网络, 在输出端的M个模中进行光子数探测
































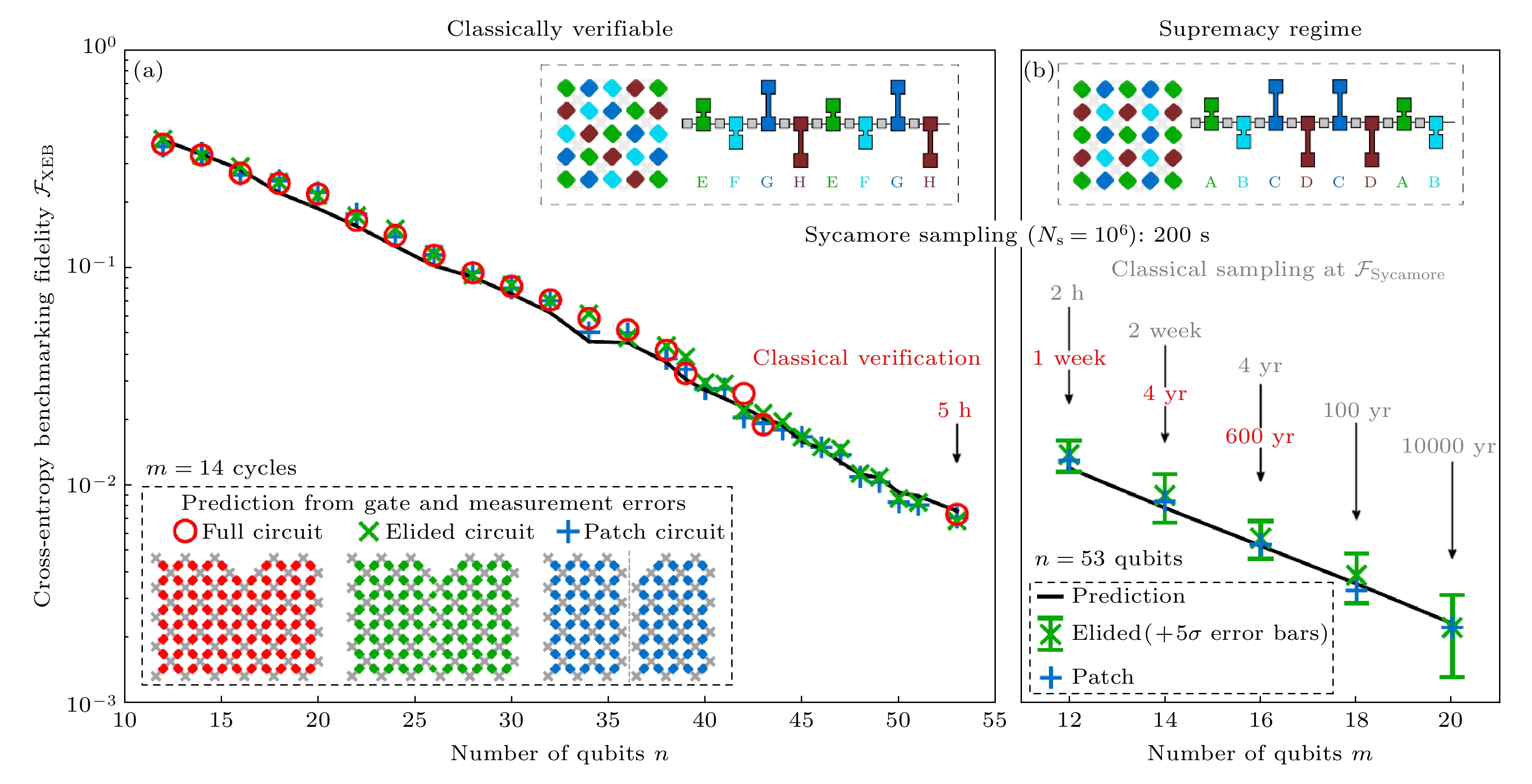 图 6 量子优越性证明的实验结果[7] (a)在经典可验证区, 简单全量子线路的保真度与简单删减量子线路、简单分割量子线路、简单乘积模型的保真度符合得很好, 每个数据点是多个随机量子线路采样的平均值; (b)在量子优越区, 通过更简单的线路和简单乘积模型来估计复杂全量子线路的保真度. 红色时间标志表示经典模拟复杂全量子线路的验证任务需要的时间, 灰色时间标志表示经典模拟相应的采样任务需要的时间
图 6 量子优越性证明的实验结果[7] (a)在经典可验证区, 简单全量子线路的保真度与简单删减量子线路、简单分割量子线路、简单乘积模型的保真度符合得很好, 每个数据点是多个随机量子线路采样的平均值; (b)在量子优越区, 通过更简单的线路和简单乘积模型来估计复杂全量子线路的保真度. 红色时间标志表示经典模拟复杂全量子线路的验证任务需要的时间, 灰色时间标志表示经典模拟相应的采样任务需要的时间










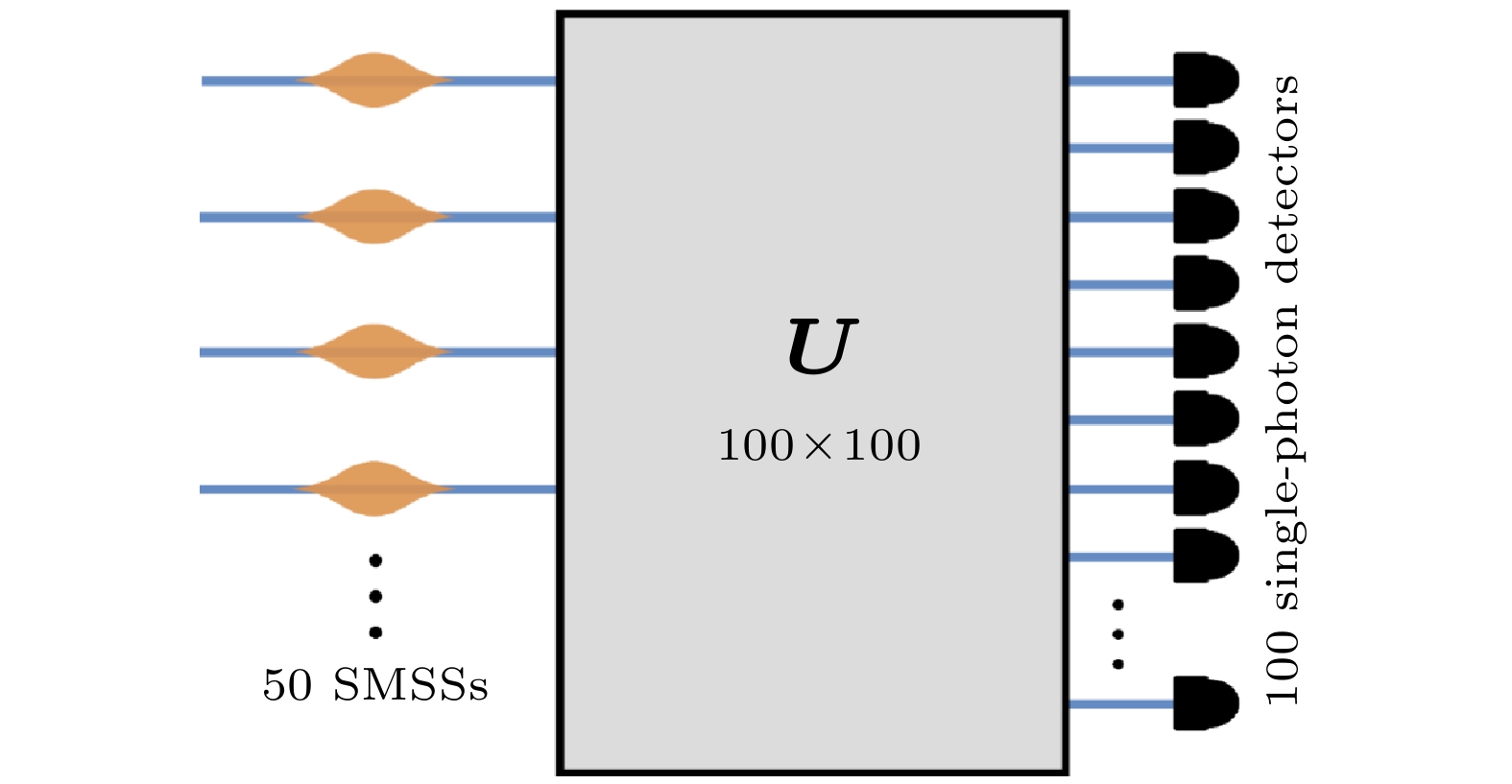 图 7 九章GBS 实验示意图[53]
图 7 九章GBS 实验示意图[53]













