 ,1, 张认连1, 龙怀玉1, 王转1, 朱国龙1, 石乾雄2, 喻科凡1, 徐爱国,1
,1, 张认连1, 龙怀玉1, 王转1, 朱国龙1, 石乾雄2, 喻科凡1, 徐爱国,1Research on Spatial Distribution of Soil Particle Size Distribution in Loess Region Based on Three Spatial Prediction Methods—Taking Haiyuan County in Ningxia as an Example
SHEN Zhe,1, ZHANG RenLian1, LONG HuaiYu1, WANG Zhuan1, ZHU GuoLong1, SHI QianXiong2, YU KeFan1, XU AiGuo,1通讯作者:
责任编辑: 李云霞
收稿日期:2019-12-10接受日期:2020-03-17网络出版日期:2020-09-16
| 基金资助: |
Received:2019-12-10Accepted:2020-03-17Online:2020-09-16
作者简介 About authors
申哲,Tel:16619922154;E-mail:

摘要
关键词:
Abstract
Keywords:
PDF (2145KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
申哲, 张认连, 龙怀玉, 王转, 朱国龙, 石乾雄, 喻科凡, 徐爱国. 基于3种空间预测方法的黄土区土壤颗粒组成空间分布研究—以宁夏海原县为例[J]. 中国农业科学, 2020, 53(18): 3716-3728 doi:10.3864/j.issn.0578-1752.2020.18.008
SHEN Zhe, ZHANG RenLian, LONG HuaiYu, WANG Zhuan, ZHU GuoLong, SHI QianXiong, YU KeFan, XU AiGuo.
0 引言
【研究意义】土壤质地是十分稳定的土壤自然属性,也是最基础的土壤物理性质之一,它影响土壤的通气透水性、保水保肥性[1],决定着诸多其他土壤物理化学行为。黄土高原地区是我国主要的农业生产区,也是水土流失严重、生态脆弱区[2],因此,利用空间预测方法实现对黄土区土壤颗粒组成空间分布的精准预测,了解其空间分布规律,有助于研究黄土区域土壤侵蚀和土壤化学元素行为特征,为区域农田施肥、灌水的精准化管理和土壤质量评价提供科学依据。【前人研究进展】地统计学方法是预测土壤属性空间分布最常见、最成熟的方法,以克里格插值最具代表性。传统的普通克里格(ordinary Kriging,OK)适用于较均一、土壤属性变化不强烈的环境[3,4],在小尺度和均质景观区域应用较多[5,6,7]。黄土高原地形复杂,土壤属性空间变异程度大,其空间分布受地形等因素影响显著[8,9],结合辅助变量的混合插值模型和常规统计模型在黄土区取得了较好的空间预测效果。文雯等[10]利用基于土地利用类型修正的OK对黄土丘陵区土壤有机碳进行了空间插值。连纲等[11]以地形因子和土地利用方式为辅助变量,采用多元线性回归(multiple linear regression,MLR)和回归克里格(regression Kriging,RK)对黄土高原县域土壤养分进行空间预测,结果表明RK有效地减小了预测残差,精度高于MLR。LIU等[12]利用空间状态方程和MLR结合地形、气候等要素对整个黄土高原的土壤有机碳进行空间模拟,结果表明空间状态方程取得了更好的预测效果。除加入辅助变量提高预测精度以外,经验贝叶斯克里格(empirical Bayesian Kriging,EBK)也被证明是一种可对非均质景观区域进行空间预测的插值方法[13],但目前该方法在黄土区应用较少。地统计和传统统计模型均难以拟合土壤属性和环境变量之间的非线性关系,且面临着处理类别型变量的困难。为克服这些局限,分类与回归树(classification and regression tree,CART)、神经网络(artificial neural network,ANN)等机器学习方法被引入到土壤属性空间预测中,研究表明这些模型能成功预测类别型变量、提高土壤属性预测的精度[14,15],但两者均易过度拟合[16,17],且神经网络过程繁琐。随机森林(random forest,RF)模型在分类与回归树模型基础上发展而来,具有计算简单、不易过度拟合、反映辅助变量重要程度等特点[18],目前在平原和山区、流域等母质多样化地区应用较多。LIU等[19]基于MODIS获取的地表温度资料,用RF法完成了江苏平原土壤颗粒组成、有机质和PH的空间制图。郭澎涛等[20]利用RF结合多源环境变量(成土母质、平均降雨量、平均气温和归一化植被指数)对橡胶园土壤全氮含量进行空间预测,并与MLR、CART比较,结果表明RF模型表现最优。MAREIKE等[21]在厄尔多瓜安第斯山脉对土壤颗粒组成空间分布的研究和GERALD等[22]在布基纳法索西南部小流域对土壤颗粒组成、有机碳空间预测的研究均表明,RF法优于其他机器学习方法。【本研究切入点】就研究对象而言,前人对黄土区土壤属性空间预测的研究集中在土壤养分指标,对土壤颗粒组成等物理属性研究相对较少。与土壤养分指标相比,土壤颗粒组成受人类活动等随机因素的影响较小,受母质、地形、气候等结构性因素影响较大,空间分布规律性更强。且土壤颗粒组成属于成分数据,预测结果要满足非负、定和为1的要求。就空间预测方法而言,目前黄土区已有的研究中对较新近的EBK使用较少,且缺乏地统计学方法与机器学习方法的对比研究。就辅助变量的选择而言,平原地区多选择高光谱数据[23,24]、地表温度[19]等作为辅助变量进行预测;山区、流域多为母质多样化地区,以地形因子结合成土母质[20,25]为辅助变量能取得理想的预测结果。但在地形复杂、母质较为单一的区域,成土母质无法作为辅助变量参与空间预测,仅使用地形因子预测可能精度并不高,需考虑加入其他环境变量提高预测精度。因此,对地形复杂、单一母质地区的土壤属性进行空间预测时,在方法的选择、辅助变量的选择方面仍需进一步研究。【拟解决的关键问题】本文选择黄土、黄土状母质的宁夏自治区海原县为研究区,选用3种方法(SLR-EBK、SLR-RK、SLR-RF)结合地形、土壤类型、归一化植被指数等辅助变量进行表层土壤颗粒组成的空间制图,并进行精度对比选出最优模型,以期为地形复杂的黄土母质区土壤颗粒组成的空间预测提供依据。1 材料与方法
1.1 研究区概况
海原县地处黄土高原西北部(36°6′—37°4′N、105°9′—106°10′E),面积689 900 hm2。该区属大陆季风气候,年均气温7℃,≥10℃年积温2 398℃,年平均降水量 363 mm,降水量由南向北递减。县内地势由西南向东北倾斜(图1),地貌以黄土丘陵为主,南部月亮山、中部南华山、西部西华山、北部油井山呈孤立零星分布,被黄土丘陵包围,东北角与同心县交界处为狭长的河谷冲积平原,面积较小,为提灌区。研究区内绝大部分成土母质为黄土、黄土状母质,仅在南华山、西华山零星分布有岩石风化物。土壤类型包括灰褐土、黑垆土、黄绵土、灰钙土、新积土、红黏土和粗骨土7种,各土壤类型面积占比见表1。其中黄绵土、黑垆土、灰钙土3个土类面积最大,共占全县面积的81.51%。以盐池乡-李旺一线为界,此线以北主要为灰钙土,以南黄绵土和黑垆土插花分布,南华山、西华山发育有灰褐土,丘陵间低地及冲积平原有新积土分布。海原县以雨养农业为主,土地利用类型主要为旱地、草地,种植作物主要为玉米、荞麦、马铃薯。图1
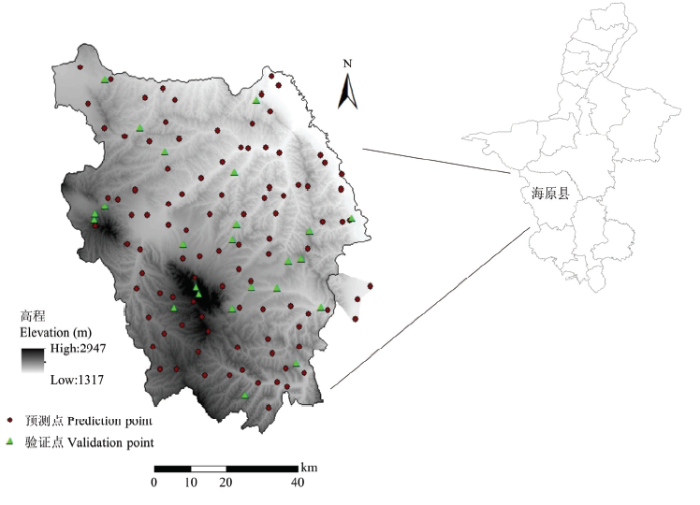 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1研究区位置及样点分布图
Fig. 1The map of the study position and sampling sites
Table 1
表1
表1各土壤类型面积占比及样点统计
Table 1
| 土壤类型 Soil type | 采样个数 Sampling point | 本县面积占比 Proportion of area (%) |
|---|---|---|
| 黄绵土 Cultivated loessial soil | 65 | 53.33 |
| 黑垆土 Dark loessial soil | 21 | 15.31 |
| 灰钙土 Sierozem | 19 | 14.87 |
| 灰褐土 Gray cinnamonic soil | 9 | 6.87 |
| 新积土 Alluvial soil | 5 | 4.71 |
| 粗骨土 Skeletal soil | 3 | 3.75 |
| 红黏土 Red clay | 2 | 1.16 |
新窗口打开|下载CSV
1.2 样品采集与分析
采用网格法布点,在此基础上综合考虑地形地貌、土壤类型等因素,在南华山、西华山等地形复杂地区加密样点,共选取具有代表性的样点124个(图1)。以盐池乡-南华山-九彩乡一线为界,南部面积占32%,采样点共53个,占全部采样点的43%,平均每4 300 hm2一个样点;北部面积占68%,采样点共71个,平均每6 600 hm2一个样点。研究区全部样点平均间隔7—8 km。东南部边缘因地势陡峭无路,取样较困难,故3个样点取在海原县外3—5 km范围内。各土壤类型的采样点个数见表1。土壤样品采集时间为2018年9月、2019年4月,采样深度为0—20 cm,记录样点经纬度、地形地貌、土壤类型、土地利用类型等信息。土壤颗粒组成采用湿筛-吸管法测定[26],粒级划分采用国际制(砂粒2—0.02 mm,粉粒0.02—0.002 mm,黏粒<0.002 mm)。1.3 辅助变量来源及处理
海原县内地形复杂,地势起伏较大,海拔落差大于1 600 m,地貌类型主要包括山地、黄土丘陵、平原。因地形地貌不同,各区域温度、降水量、植被差异较大,直接影响成土过程,进而影响土壤颗粒组成的空间分布。土壤类型是五大成土因素综合作用的产物,一定程度上包含土壤质地的信息;土壤类型也含有母质信息,而本研究区母质相对单一,因此,其他因素对质地的影响会更大;另外,许多研究表明,土壤类型与土壤有机质、容重有一定相关性[27,28]。温度、降水量对土壤颗粒组成有影响,由于缺乏研究区较精细的温度、降水数据,而植被覆盖情况直接受温度、降水影响,且研究区基本为雨养农业,故将反映植被覆盖程度的归一化植被指数作为辅助变量反映气候因素。同时地形、土壤类型在一定程度上也包含气象信息。与土壤养分相比,土壤颗粒组成稳定,受人为耕作影响较小,研究区土地利用类型主要为旱地和草地,受灌水耕作影响很小,因此本研究区黏土矿物分解更加缓慢。综上所述,本研究选取的辅助变量为地形因子、土壤类型、归一化植被指数。1.3.1 辅助变量来源
(1)宁夏自治区1﹕50 000等高线矢量图;(2)宁夏自治区1﹕200 000土壤图;(3)本文使用处于植物生长季(8—9 月)、且云量覆盖度少(小于5%)的卫星影像计算植被指数。2017年8月28日和9月6日的Landsat8 OLI_TIRS 四景卫星影像覆盖海原县全境,影像均来源于地理空间数据云网站(http://www. gscloud.cn)。由于缺乏研究区2018年5月以后的卫星影像,故采用前一年相应月份的影像代替。
1.3.2 辅助变量的提取及处理
(1)用1﹕50 000等高线矢量图在ArcGIS10.2中生成10 m分辨率的数字高程模型(digital elevation model,DEM)栅格影像,从中提取5个地形因子:高程(elevation,Ele)、坡度(slope,Slo)、平面曲率(horizontal curvature,HC)、剖面曲率(profile curvature,PC)、地形湿度指数(topographic wetness index,TWI)。使用SAGA GIS软件基于DEM提取风力作用指数(wind exposition index,WEI)[29],该指数是各个风向对区域的风影响(wind effect)[29]的平均值。WEI越大,表明该区域越容易受风力影响。(2)土壤类型(soil types,ST)为类别变量,本文采用“算术平均值变换”[30],以不同土壤类型下定量因变量的算术平均值代替该土壤类型,即将土壤类型变为一个具有7个数值的定量变量。由于有砂粒、粉粒、黏粒3个因变量,则土壤类型共转化为3组定量变量,分别用于构建砂粒、粉粒、黏粒的预测模型。算术平均值变换用动态思维(类别自变量与定量因变量的关系)建立起自变量各水平与定量结果变量之间数量关系,比传统的哑变量变换更具合理性[30];此外,哑变量变换将具有n个水平的类别变量变为(n-1)个二值变量,这些二值变量非相互独立[31],需全部进入回归模型中,造成模型中无关变量太多,拟合精度不高,而算术均值变换将类别变量变为具有n个数值的定量变量,提高了回归拟合精度[30]。(3)在ENVI5.1中对遥感影像进行镶嵌、计算,提取归一化植被指数(normalized difference vegetation index,NDVI)。(4)为消除变量之间的量纲影响,对变量进行归一化处理。
1.4 预测方法
1.4.1 数据转换方法 为了使数据满足正态分布,且使预测结果满足非负、定和为1的要求,本文首先对土壤颗粒组成进行对称对数比(symmetry log-ratio,SLR)转换[32],转换公式为:转回公式为:
式中,Zij代表第i个样点第j种粒级的相对含量(%);
$Z_{ij}^{\text{ }\!\!'\!\!\text{ }}$代表第i个样点第j种粒级含量的转换值;D表示成分数据的维度,本文中D=3;δj为常数,取研究区第j种颗粒除0外最小含量的一半。
1.4.2 经验贝叶斯克里格(EBK) EBK在OK的基础上发展而来,可以通过构造子集、建立局部模型对非平稳数据进行空间插值[33]。它克服了OK的两大局限:第一,EBK则通过构造子集,通过评估较小子集上的半方差函数,在研究区的不同区域中得到不同的半方差函数模型,克服了OK假设单一半方差函数可准确表示所有位置数据的空间结构的局限。第二,在半方差函数的参数评估方面,OK只依赖于单一半方差函数,忽略了模型的不确定性[34],因此在构建半方差函数的过程中,需对每个参数进行手动反复调试,以使该模型更接近于真实的半方差函数。而EBK在每个子集中,自动评估半方差函数,并以此半方差函数来模拟子集中的新数据值。然后使用这些模拟的数据值来评估子集的新半方差函数。此模拟和评估过程重复多次,并且在每个子集中生成多个模拟的半方差函数,最后将这些模拟混合在一起以生成最终的预测图。本研究中,训练集砂粒、粉粒、黏粒含量经SLR转换后的全局Moran’s I(莫兰指数)分别为0.293、0.260、0.192,且P值均小于0.05,表明经SLR转换的土壤颗粒组成在研究区域内有一定的空间自相关性。ArcGIS趋势分析发现,转换后的砂粒、粉粒含量均存在二阶趋势,不满足空间平稳假设。Voronoi图也显示两者的局部空间规律变化较大,因此使用EBK进行空间插值。具体步骤为:(1)将数据分为多个特定大小的重叠子集(通过逐次尝试,最终本文每个子集设置为70个点,子集重叠系数设置为3,即每个点可落入3个子集中);(2)对子集中的数据进行半方差函数拟合;(3)使用该半方差函数,在每个输入位置生成新值;(4)使用新的模拟数据生成新的半方差函数;(5)将步骤(3)和(4)重复100次。此过程将为每个子集生成100个半方差函数,每个都是子集真实半方差函数的估计。将其绘制在一起生成按密度着色的半方差函数分布;(6)对于空间内每个位置,都使用唯一的半方差函数分布生成预测,该分布是通过周围子集的半方差函数分布加权综合计算得出的;子集距离预测位置越近,给定的权重就越高。这就保证了每个预测值使用的是临近数据所定义的模型,而不是远处数据所定义的模型[13]。最后,将局部预测结果混合生成全局预测结果。
1.4.3 回归克里格(RK) RK是应用多元线性回归拟合土壤属性与辅助变量间的关系,然后对回归残差应用克里格法插值,最后将回归预测结果与残差插值结果结合起来的一种空间预测方法。首先用皮尔森相关分析对辅助变量进行初步筛选,表2相关分析的结果表明,高程、归一化植被指数和土壤类型与土壤颗粒组成显著相关。其中,高程和NDVI均与土壤砂粒含量呈负相关,与粉粒和黏粒含量呈正相关。为避免辅助变量间的共线性问题,基于筛选出的变量,采用逐步线性回归的方法对经SLR转换后的土壤颗粒组成进行预测(F值的概率Fp<0.05为变量进入方程的标准,Fp>0.10为剔除变量的标准),并对预测残差进行简单克里格插值,最后将回归预测值与残差相加并转回得到预测结果。
Table 2
表2
表2土壤各粒级含量与辅助变量的相关性分析
Table 2
| 辅助变量 Auxiliary variable | 粒级 Soil particle | ||
|---|---|---|---|
| 砂粒 Slr-sand | 粉粒 Slr-silt | 黏粒 Slr-clay | |
| 高程Ele | -0.387** | 0.341** | 0.239** |
| 坡度Slo | 0.044 | 0.061 | -0.111 |
| 平面曲率 HC | -0.129 | 0.043 | 0.107 |
| 剖面曲率 PC | -0.018 | 0.019 | -0.011 |
| 地形湿度指数 TWI | 0.130 | -0.132 | 0.065 |
| 风力作用指数 WEI | 0.129 | -0.045 | -0.111 |
| 归一化植被指数 NDVI | -0.296** | 0.235** | 0.204** |
| 土壤类型 ST1 | 0.576** | -- | -- |
| 土壤类型 ST2 | -- | 0.435** | -- |
| 土壤类型 ST3 | -- | -- | 0.466** |
新窗口打开|下载CSV
1.4.4 随机森林(RF) 与其他模型一样,随机森林(RF)可以反映若干自变量对因变量的作用[35]。其主要过程包括:从原始训练集中进行bootstrap重新抽样(有放回的随机抽取)构成新的训练集生成决策树;同时,随机地选择部分变量进行决策树节点的确定;随机地生成几百至几千个决策树构成随机森林。对于分类问题,所有决策树预测结果中得票最高的分类结果为最终结果;对于回归问题,所有决策树预测结果的平均值为最终的预测结果[18]。每次未被抽到的样本组成袋外样本,故RF可根据袋外误差估计模型误差,对于分类问题,袋外误差是分类错误率;对于回归问题,袋外误差通过回归残差计算,本文采用均方误差(mean square eroor,MSE)。
RF不要求原始数据符合正态分布,但为了更好地同其他两种方法做对比,且使预测结果满足定和为1的要求,本研究使用经SLR转换后的数据进行建模。由于RF不是简单的线性回归,皮尔森相关分析筛选变量的结果不一定适合RF模型,故用两步法对RF辅助变量进行筛选:对变量进行重要性排序,初步剔除不重要变量[36];对剩下的变量,基于随机森林逐步选择[37]。本文采用Breiman经典随机森林版本中的评价方法,通过变量值的置换计算变量重要性得分,剔除得分小于0的变量。结果表明平面曲率、剖面曲率两个辅助变量重要性得分均小于0,故剔除。剩下的变量按照重要性评分降序排列,以不同的变量子集所构建森林运行100次的MSE均值作为逐步筛选变量的标准,从最重要变量开始,遍历所有变量,MSE最小结束(变量筛选过程中,RF参数均为默认参数)。基于筛选的辅助变量对RF模型进行参数优化:首先以MSE最小化为目标,通过逐次计算确定决策树节点分裂时所用变量个数(mtry);通过观察决策树数量(ntree)与误差关系图,在保证误差稳定的前提下,选择较小的ntree[38]。
本研究中随机森林在R3.5.2中完成,相关性分析和逐步回归使用SPSS 22软件,经验贝叶斯克里格插值、回归残差的简单克里格插值和空间制图在ArcGIS 10.2中完成。
1.5 精度验证
从124个样点中随机选取80%的(100个)样点用于空间预测,20%的(24个)样点用于精度验证[39,40],训练样点和验证样点的分布如图1所示。本研究采用验证集的平均绝对误差(MAE)、均方根预测误差(RMSE)、平均Aitchison距离(MAD)[41]进行模型精度评价。MAE能更好地反映预测值误差的实际情况;RMSE对系统误差和随机误差都很敏感,常用来评估不同模型的预测精度;MAD可以反映成分数据预测值和观测值之间整体的相似性。MAE、 RMSE、MAD越小,模型精度越高。Zij代表第i个样点第j种粒级含量的观测值;$Z_{ij}^{\text{*}}$代表第i个样点第j种粒级含量的预测值;n表示验证点的数量;D表示成分数据的维度,本文中D=3。
2 结果
2.1 土壤颗粒组成的描述性统计特征
表3为研究区采样点土壤颗粒组成的描述性统计结果,可以看出研究区土壤砂粒含量最高(训练集和验证集砂粒平均含量分别为61.82%、63.96%),黏粒含量最低(训练集和验证集的平均黏粒含量分别为14.56%、13.36%),粉粒含量居中(训练集和验证集的平均粉粒含量分别为23.62%、22.68%)。训练集中3个粒级含量的范围和标准差都比验证集中的大,相对应地,训练集中砂粒、粉粒、黏粒含量的变异系数(14.02%、23.96%、27.41%)大于验证集(11.30%、21.91%、25.45%)。方差分析结果表明训练集与验证集土壤3个粒级含量差异均不显著,表明训练数据和验证数据都具有较好的代表性。训练集中3个粒级含量偏度均接近于0,但经Kolmogorov-Smirnov检验,只有砂粒含量P值大于0.05,满足正态分布,粉粒和黏粒含量均不符合正态分布。经SLR转换后,砂粒、粉粒、黏粒含量均符合正态分布,可用于空间插值和线性回归。Table 3
表3
表3研究区采样点土壤颗粒组成基本统计特征
Table 3
| 样本组 Sample group | 粒级 Soil particle | 样本数 Sample size | 最大值 Max (%) | 最小值 Min (%) | 均值 Mean (%) | 标准差 Std. deviation (%) | 变异系数 CV (%) | 偏度 Skewness |
|---|---|---|---|---|---|---|---|---|
| 训练集 Calibration sample | 砂粒Sand | 100 | 79.18 | 43.15 | 61.82 | 8.67 | 14.02 | -0.04 |
| 粉粒 Silt | 100 | 40.40 | 13.21 | 23.62 | 5.66 | 23.96 | 0.16 | |
| 黏粒Clay | 100 | 23.07 | 7.59 | 14.56 | 4.00 | 27.47 | 0.24 | |
| 验证集 Validation sample | 砂粒Sand | 24 | 77.49 | 48.68 | 63.96 | 7.23 | 11.30 | -0.34 |
| 粉粒 Silt | 24 | 34.06 | 13.76 | 22.68 | 4.97 | 21.91 | 0.48 | |
| 黏粒Clay | 24 | 22.61 | 8.10 | 13.36 | 3.40 | 25.45 | 0.72 |
新窗口打开|下载CSV
2.2 多元线性回归和RF模型的构建
由表4可以看出,最终进入土壤颗粒组成线性回归预测模型的辅助变量包括高程Ele和土壤类型,NDVI由于与高程、土壤类型存在多重共线性,在逐步线性回归的过程中被剔除。从调整决定系数(Adjusted R2)来看,砂粒含量的线性回归模型方差解释率最高(0.339),拟合度较好;粉粒和黏粒含量的线性回归方程方差解释率较低(分别为0.208,0.205),拟合度较差。表5为RF模型的拟合结果,可以看出进入模型预测的辅助变量除了高程Ele、土壤类型外,还包括坡度Slo和风力作用指数WEI,这主要是因为RF可以拟合土壤颗粒组成和辅助变量之间的非线性关系。其中,高程对3个粒级含量的空间预测来说,均是最重要的辅助变量,其次是土壤类型,坡度、风力作用指数的重要性相对较低。虽然RF对辅助变量间的多重共线性不敏感,但考虑到NDVI对预测精度无显著影响,为了简化模型,提高计算速度,本研究未将NDVI作为RF的辅助变量。Table 4
表4
表4土壤颗粒组成逐步线性回归方程拟合结果
Table 4
| 粒级Soil particle | 方程Equator | 调整决定系数Adjusted R2 | 概率Probability |
|---|---|---|---|
| 砂粒 Slr-sand | slr-sand=0.160-0.140Ele+0.875ST1 | 0.339 | <0.001 |
| 粉粒 Slr-silt | slr-silt=-0.070+0.097Ele+0.811ST2 | 0.208 | <0.001 |
| 黏粒 Slr-clay | slr-clay=-0.054+0.042Ele+0.945ST3 | 0.205 | <0.001 |
新窗口打开|下载CSV
Table 5
表5
表5SLR-RF参数拟合结果
Table 5
| 粒级Soil particle | 辅助变量Auxiliary variable | Ntree | Mtry |
|---|---|---|---|
| 砂粒 Slr-sand | Ele、ST1、Slo、WEI | 300 | 2 |
| 粉粒 Slr-silt | Ele、ST2、Slo、WEI | 300 | 2 |
| 黏粒 Slr-clay | Ele、ST3、Slo、WEI | 300 | 2 |
新窗口打开|下载CSV
2.3 土壤颗粒组成的空间分布预测结果
利用拟合的SLR-EBK、SLR-RK和RF模型分别对研究区土壤砂粒、粉粒、黏粒含量的空间分布进行预测,得到其空间分布图(图2—4)。可以看出,3种方法预测的土壤各粒级含量空间分布的趋势大体一致。研究区砂粒含量基本呈现西南部低,东北部高的趋势,其中西华山-南华山-九彩乡海拔较高一带含量较低,集中在60%以下,北部和东部边缘含量较高,大多数为65%—70%,部分达到70%以上。粉粒和黏粒含量的空间分布趋势与砂粒相反,呈现西南部高,东北部低的趋势,西华山-南华山-九彩乡一带粉粒含量变化范围集中在25%—30%,黏粒含量变化范围集中在15%—20%,北部和东部边缘粉粒含量低至20%以下,黏粒含量大部分为10%—15%。土壤颗粒组成的空间分布趋势明显受到海拔的影响。图2
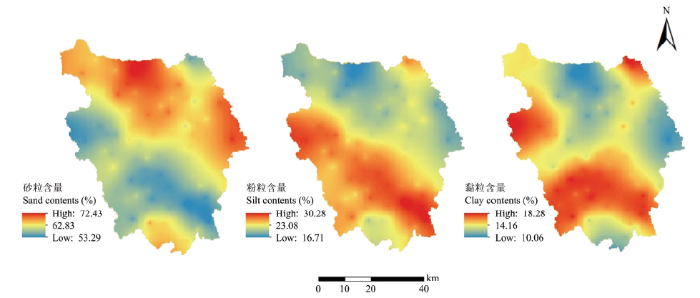 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2SLR-EBK预测土壤颗粒组成空间分布图
Fig. 2Spatial distribution of soil particle size distribution predicted by SLR-EBK
图3
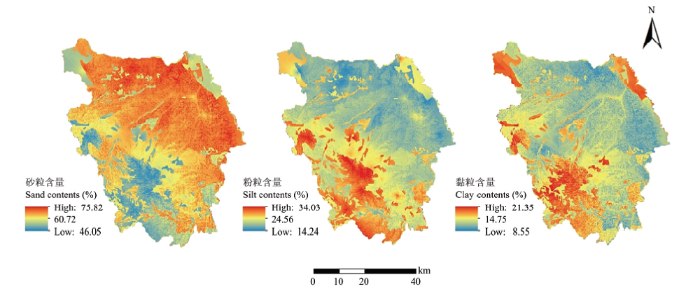 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3SLR-RK预测土壤颗粒组成空间分布图
Fig. 3Spatial distribution of soil particle size distribution predicted by SLR-RK
图4
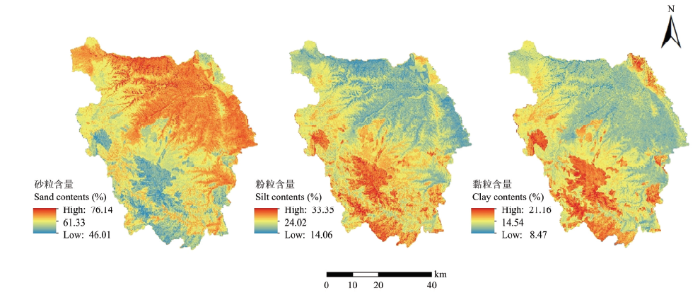 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图4SLR-RF预测土壤颗粒组成空间分布图
Fig. 4Spatial distribution of soil particle size distribution predicted by SLR-RF
虽然3种方法预测的土壤颗粒组成空间分布总体趋势比较相似,但在局部区域上不尽相同。首先,SLR-RK和SLR-RF的预测结果对细节刻画比较清晰,而SLR-EBK预测结果只能反映海原县土壤颗粒组成的宏观分布趋势,难以体现局部变异信息。其次,虽然3种方法预测的砂粒、粉粒、黏粒含量的平均值相近(SLR-EBK、SLR-RK、SLR-RF 3种方法预测砂粒含量的均值分别为62.32%、62.83%、62.53%,粉粒含量的均值分别为23.34%、23.25%、23.38%,黏粒含量的均值分别为14.34%、13.91%、14.09%),但由图2—4可以看出,SLR-EBK存在平滑效应,与土壤采样点原始数据相比,该方法预测的极大值和极小值均向均值方向靠拢,SLR-RK与SLR-RF的预测范围更接近实测值。
2.4 不同预测方法的精度对比
表6列出了3种方法在验证集的预测精度,可以看出SLR-RF法对3个粒级含量预测的MAE和RMSE均低于其他两种方法,且SLR-RF的MAD(0.208)最低,表明该方法的预测精度更高。因此,研究区土壤颗粒组成的最优预测模型为SLR-RF。Table 6
表6
表6不同空间预测方法精度对比
Table 6
| 方法 Method | 砂粒 Sand | 粉粒 Silt | 黏粒 Clay | MAD | |||
|---|---|---|---|---|---|---|---|
| MAE (%) | RMSE (%) | MAE (%) | RMSE (%) | MAE (%) | RMSE (%) | ||
| SLR-EBK | 5.706 | 6.741 | 3.515 | 4.308 | 3.113 | 4.069 | 0.274 |
| SLR-RK | 4.404 | 5.447 | 2.756 | 3.408 | 2.839 | 3.677 | 0.235 |
| SLR-RF | 3.809 | 4.868 | 2.623 | 3.317 | 2.189 | 2.914 | 0.208 |
新窗口打开|下载CSV
3 讨论
3.1 3种预测方法的精度
本文利用3种方法在宁夏南部黄土丘陵区对土壤颗粒组成的空间分布进行预测,结果显示,SLR-EBK方法预测精度较低,原因在于空间插值方法仅利用了土壤颗粒组成的空间自相关性,忽略了环境变量的影响。虽然EBK在一定程度上考虑了土壤属性变化的不均匀性,但由于本研究区地形破碎,且南部高山区与北部黄土丘陵区气候条件差异大,故SLR-EBK法预测精度并不高。SLR-RK、SLR-RF法由于引入辅助变量参与预测,提高了土壤颗粒组成的空间预测精度,相比SLR-RK,SLR-RF的预测精度更高。可以看出,虽然RK通过对回归残差进行简单克里格插值进一步提高了多元线性回归的预测精度,但RF通过精确捕捉土壤属性同辅助变量之间的非线性关系,依然取得了比RK更好的预测效果。在黄土母质区,地形是影响土壤属性的主要因素,精确拟合地形因子与土壤属性之间的关系是进行土壤属性空间预测的关键所在。小尺度下,气候、植被等环境条件相对一致,地形因子与土壤属性之间的关系较为简单,可直接利用线性回归拟合[20]。王库[42]以高程、坡度等为辅助变量,使用RK对福建省旗山北麓一块面积为29 000 hm2的区域进行土壤全氮的空间预测,结果表明,RK取得了较高的预测精度,验证集的决定系数达到0.682。MOORE等[43]在科罗拉多州一块5.4 hm2的坡面上,利用多元线性回归结合地形因子(坡度、坡向、平面曲率、剖面曲率、地形湿度指数等)对土壤属性(有机质、pH、砂粒含量、粉粒含量等)进行空间预测,取得了理想的预测结果。但在大尺度区域,随着地形的变化,气候、植被等也出现明显变化,土壤属性与地形因子之间往往表现出非线性的特征,这时运用RF进行空间预测就有明显优势。姜赛平[28]等以整个海南岛(3.29×106 hm2)为研究区域,利用RK、RF结合辅助变量预测全岛的有机质空间分布,结果表明RF预测精度高于RK,更适合地形复杂的大尺度地区土壤属性的空间预测。本研究区面积达689 900 hm2,南北部地形、气候、植被差异较大,部分地形因子(坡度、风力作用指数)与土壤颗粒组成无显著的线性关系,并未进入回归方程,但却进入RF模型参与空间预测,表明RF模型可以拟合土壤属性同环境变量之间的非线性关系,进一步提高预测精度。除地形因子外,本研究中土壤类型也是预测土壤颗粒组成的重要变量。土壤类型属于类别变量,与多元线性回归模型相比,RF对类别变量具有更好的包容性[44],可以更多地捕捉土壤颗粒组成与土壤类型之间的关系。综上所述,RF更适合用于预测研究区土壤颗粒组成的空间分布。
3.2 土壤颗粒组成空间分布与辅助变量的关系
地形作为五大成土因素之一,通过影响物质与能量的再分配,引起土壤的理化性质变化[45]。本研究中,高程是预测土壤颗粒组成最重要的地形因子。皮尔森相关分析和空间预测结果均表明,海拔高度越高,砂粒含量越低,粉粒和黏粒含量越高。这与部分****[46,47,48]低海拔地区土壤黏粒含量更高的研究结果不符。但也有****与本文研究结果相似,BACIS等[49]在巴西杰尼罗州的研究表明高程与土壤质地的变异密切相关,海拔越高,黏粒含量越高。这是因为前者[46,47,48]的研究中,海拔主要影响土壤颗粒的运移速度和方向,粒径较小的颗粒在重力和地表径流的作用下运移的距离更远。BACIS等[49]的研究中,与海拔密切相关的是土壤母质,该地区高海拔区域土壤主要由前寒武纪片麻岩原位风化形成,质地较细;低海拔区域以砂质坡积物为主,砂粒含量较高。本研究中,海拔主要影响区域降水、植被等,研究区内区域降水量差异大,以盐池乡-李旺一线为界,南部高海拔地区降水在400 mm以上,植被覆盖度高,湿润的条件有利于黏土矿物的形成;北部低海拔地区降水为200—350 mm,植被覆盖度低,地表裸露多,蒸发强烈,土壤颗粒较粗。这也与NDVI和砂粒含量呈显著负相关,和粉粒和黏粒含量呈正相关的结果相一致。除高程外,坡度、风力作用指数两个地形因子也进入RF模型(表5),但重要性相对较低,表明这两个辅助变量虽然也会影响土壤颗粒组成的空间分布,但影响程度较小。坡度通过影响表层土壤颗粒运动、径流挟沙能力和侵蚀方式[50,51],从而影响土壤颗粒组成。邹心雨等[52]等研究表明,坡度对小尺度下土壤颗粒组成的空间变异影响较大,本文研究尺度较大,坡度的影响并不显著。除地形因子外,土壤类型也是预测土壤颗粒组成的重要变量。土壤类型在一定程度上可以反映母质、气候等信息,杨艳丽等[53]研究表明,土壤类型与黏粒含量的空间分布显著相关。海原县绝大部分区域为黄土、黄土状母质,在此母质上发育有黄绵土、灰钙土和黑垆土,与黄绵土和灰钙土相比,黑垆土形成的环境条件更为湿润,黏粒含量更高。海拔2 100 m以上的南华山、西华山中上部分布有页岩、泥岩和片岩的风化物,这些岩石风化物是形成山地灰褐土的主要母质,其中页岩、泥岩属于沉积岩中的泥质岩类,发育形成的土壤颗粒较细。新积土、粗骨土和红黏土的面积较小,其中新积土是在水力或重力迁移堆积的物质上形成,主要分布于东北角的冲积平原,颗粒较细;粗骨土仅分布于西华山等山地的陡坡,含较多的砂岩风化碎屑,植被覆盖度很低,土壤颗粒较粗。红黏土主要分布于研究区东南角,为裸露的第三纪红土层,质地较黏重。
本研究区地形复杂,地形因子是重要的辅助变量;区内土地利用类型多为天然草地和旱地,且单季种植,土壤物理性状受人为影响不强烈。因此要对平原地区、受人类活动影响强烈的地区进行颗粒组成的空间预测,仍需探索选取适当的辅助变量和预测方法。
4 结论
3种方法(SLR-EBK、SLR-RK和SLR-RF)预测的海原县土壤各粒级含量空间分布的趋势基本一致,表现为砂粒含量西南部低,东北部高,粉粒、黏粒则相反; SLR-RF、SLR-RK预测精度均高于SLR-EBK,其中以SLR-RF预测精度最高,为预测海原县土壤颗粒组成空间分布的最优方法;在黄土母质区,高程、土壤类型是与土壤颗粒组成的空间变异相关性较强的辅助变量。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
DOI:10.2136/sssaj2005.0126URL [本文引用: 1]
[本文引用: 1]
URL [本文引用: 1]
DOI:10.1016/j.catena.2013.09.008URL [本文引用: 1]

Nile Delta includes part of the most fertile and populated lands in the world. However, there is no accurate and reliable database about C and N pools of this region; in addition there are no published data in this regard. Spatial variation of soil C and N pools was studied based on Ordinary Kriging (OK) as a geostatistical method. This method was used for converting sampled soil C and N data to continuous maps of C and N pools in Northern part on Nile Delta, Egypt. The data revealed different levels of variability of C and N pools in the study area. The total C pool (TCP) ranged between 1.6 and 122.7 Mg/ha; while total N pool (TNP) ranged between 03 and 7.6 Mg/ha. Soil organic carbon pool (SOCP) ranged between 03 and 76.4 Mg/ha, whereas soil inorganic carbon pool (SOCP) ranged between 12 and 90.5 Mg/ha. Soil C and N pools are the lowest in the Northern part in the study area which is close to Mediterranean Sea coast because of low organic matter inputs in addition to salinity and alkalinity. (C) 2013 Elsevier BM.
DOI:10.1016/j.jhydrol.2017.01.029URL [本文引用: 1]
URL [本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
DOI:10.5846/stxb201305030916URL [本文引用: 1]
利用普通克里格法(OK)、反距离加权法(IDW)、径向基函数法(RBF)、基于土地利用类型修正的普通克里格法(OK_LU)4种插值方法,对黄土丘陵羊圈沟小流域的土壤有机碳含量进行空间插值。预测结果的准确性通过Pearson相关系数(R),平均绝对误差(MAE),均方根误差(RMSE),准确度(AC)来评价。研究结果表明:(1)在前3种常规空间插值方法中,OK对刻画区域土壤有机碳的空间分布趋势效果最佳,其预测MAE值和RMSE值均为最小,Pearson相关系数(R)和准确度(AC)最大,说明其预测结果的准确性最好、预测的极端误差也最小;其次为RBF;IDW预测的效果最差。(2)OK_LU在空间特征表达方面能够更好地反映复杂地形区的局部变异,其插值结果的精度相比OK有一定程度的提高,其平均绝对误差(MAE)从0.900%降到了0.567%,均方根误差(RMSE)从1.101%降到了0.777%,Pearson相关系数(R)从0.4026提高到0.5589,准确度(AC)从0.9081提高到0.9505。综合比较,在黄土丘陵地区,OK_LU能使插值结果的精度有较大提高,是土壤有机碳空间制图的有效途径。
DOI:10.5846/stxb201305030916URL [本文引用: 1]
利用普通克里格法(OK)、反距离加权法(IDW)、径向基函数法(RBF)、基于土地利用类型修正的普通克里格法(OK_LU)4种插值方法,对黄土丘陵羊圈沟小流域的土壤有机碳含量进行空间插值。预测结果的准确性通过Pearson相关系数(R),平均绝对误差(MAE),均方根误差(RMSE),准确度(AC)来评价。研究结果表明:(1)在前3种常规空间插值方法中,OK对刻画区域土壤有机碳的空间分布趋势效果最佳,其预测MAE值和RMSE值均为最小,Pearson相关系数(R)和准确度(AC)最大,说明其预测结果的准确性最好、预测的极端误差也最小;其次为RBF;IDW预测的效果最差。(2)OK_LU在空间特征表达方面能够更好地反映复杂地形区的局部变异,其插值结果的精度相比OK有一定程度的提高,其平均绝对误差(MAE)从0.900%降到了0.567%,均方根误差(RMSE)从1.101%降到了0.777%,Pearson相关系数(R)从0.4026提高到0.5589,准确度(AC)从0.9081提高到0.9505。综合比较,在黄土丘陵地区,OK_LU能使插值结果的精度有较大提高,是土壤有机碳空间制图的有效途径。
[本文引用: 1]
[本文引用: 1]
DOI:10.1097/SS.0b013e318272f822URL [本文引用: 1]
DOI:10.1134/S1064229317030103URL [本文引用: 2]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
DOI:10.1016/j.ecolmodel.2008.08.011URL [本文引用: 1]
[本文引用: 1]
[本文引用: 1]
DOI:10.1023/A:1010933404324URL [本文引用: 2]
Random forests are a combination of tree predictors such that each tree depends on the values of a random vector sampled independently and with the same distribution for all trees in the forest. The generalization error for forests converges a.s. to a limit as the number of trees in the forest becomes large. The generalization error of a forest of tree classifiers depends on the strength of the individual trees in the forest and the correlation between them. Using a random selection of features to split each node yields error rates that compare favorably to Adaboost (Y. Freund & R. Schapire, Machine Learning: Proceedings of the Thirteenth International conference, ***, 148–156), but are more robust with respect to noise. Internal estimates monitor error, strength, and correlation and these are used to show the response to increasing the number of features used in the splitting. Internal estimates are also used to measure variable importance. These ideas are also applicable to regression.
DOI:10.1002/saj2.v84.1URL [本文引用: 2]
URL [本文引用: 3]
土壤全氮与土壤肥力和土壤氮循环紧密相关。掌握土壤全氮详细的空间分布信息对提高土壤肥力管理效率和更好地了解土壤氮循环至关重要。该文以儋州国营橡胶园为研究区域,采集2511个土壤样品,利用随机森林(random forest,RF)、逐步线性回归(stepwise linear regression,SLR)、广义加性混合模型(generalized additive mixed model,GAMM)以及分类回归树(classification and regression tree,CART)结合多源环境变量(成土母质、平均降雨量、平均气温和归一化植被指数)对研究区橡胶园土壤全氮含量进行空间预测,并通过754个独立验证点比较了4种模型的预测精度。结果表明RF对土壤全氮的预测值和实测值的相关系数(0.82)明显高于SLR(0.68)、GAMM(0.70)和CART(0.69),而RF的预测平均绝对误差(0.08836 g/kg)和均方根误差(0.13090 g/kg)均低于SLR、GAMM和CART。此外,RF模型预测结果能反映更为详细的局部土壤全氮含量空间变化信息,与实际情况更为接近。可见,RF模型可作为橡胶园土壤全氮含量空间分布预测的高效方法,为其他土壤属性的空间分布预测提供了一种新的方法。
URL [本文引用: 3]
土壤全氮与土壤肥力和土壤氮循环紧密相关。掌握土壤全氮详细的空间分布信息对提高土壤肥力管理效率和更好地了解土壤氮循环至关重要。该文以儋州国营橡胶园为研究区域,采集2511个土壤样品,利用随机森林(random forest,RF)、逐步线性回归(stepwise linear regression,SLR)、广义加性混合模型(generalized additive mixed model,GAMM)以及分类回归树(classification and regression tree,CART)结合多源环境变量(成土母质、平均降雨量、平均气温和归一化植被指数)对研究区橡胶园土壤全氮含量进行空间预测,并通过754个独立验证点比较了4种模型的预测精度。结果表明RF对土壤全氮的预测值和实测值的相关系数(0.82)明显高于SLR(0.68)、GAMM(0.70)和CART(0.69),而RF的预测平均绝对误差(0.08836 g/kg)和均方根误差(0.13090 g/kg)均低于SLR、GAMM和CART。此外,RF模型预测结果能反映更为详细的局部土壤全氮含量空间变化信息,与实际情况更为接近。可见,RF模型可作为橡胶园土壤全氮含量空间分布预测的高效方法,为其他土壤属性的空间分布预测提供了一种新的方法。
DOI:10.1016/j.geoderma.2011.10.010URL [本文引用: 1]
DOI:10.1371/journal.pone.0170478URLPMID:28114334 [本文引用: 1]
Accurate and detailed spatial soil information is essential for environmental modelling, risk assessment and decision making. The use of Remote Sensing data as secondary sources of information in digital soil mapping has been found to be cost effective and less time consuming compared to traditional soil mapping approaches. But the potentials of Remote Sensing data in improving knowledge of local scale soil information in West Africa have not been fully explored. This study investigated the use of high spatial resolution satellite data (RapidEye and Landsat), terrain/climatic data and laboratory analysed soil samples to map the spatial distribution of six soil properties-sand, silt, clay, cation exchange capacity (CEC), soil organic carbon (SOC) and nitrogen-in a 580 km2 agricultural watershed in south-western Burkina Faso. Four statistical prediction models-multiple linear regression (MLR), random forest regression (RFR), support vector machine (SVM), stochastic gradient boosting (SGB)-were tested and compared. Internal validation was conducted by cross validation while the predictions were validated against an independent set of soil samples considering the modelling area and an extrapolation area. Model performance statistics revealed that the machine learning techniques performed marginally better than the MLR, with the RFR providing in most cases the highest accuracy. The inability of MLR to handle non-linear relationships between dependent and independent variables was found to be a limitation in accurately predicting soil properties at unsampled locations. Satellite data acquired during ploughing or early crop development stages (e.g. May, June) were found to be the most important spectral predictors while elevation, temperature and precipitation came up as prominent terrain/climatic variables in predicting soil properties. The results further showed that shortwave infrared and near infrared channels of Landsat8 as well as soil specific indices of redness, coloration and saturation were prominent predictors in digital soil mapping. Considering the increased availability of freely available Remote Sensing data (e.g. Landsat, SRTM, Sentinels), soil information at local and regional scales in data poor regions such as West Africa can be improved with relatively little financial and human resources.
DOI:10.2355/isijinternational.37.188URL [本文引用: 1]
URL [本文引用: 1]
传统线性回归模型在借助光谱信息进行土壤属性预测时,通常忽略了土壤自身所具有的空间异质性和依赖性,并且未考虑模型残差的空间结构。针对以上不足,该文以江汉平原232个土壤样本为研究对象,以土壤反射光谱为辅助变量,采用偏最小二乘回归、普通克里格、协同克里格以及回归克里格分别构建土壤有机碳密度预测模型,选取决定系数(R2)、均方根误差、标准差与预测均方根误差比(ratio of performance to deviation,RPD)对模型预测精度进行对比评价。结果显示,结合高光谱信息,且同时考虑残差空间结构的回归克里格模型表现优于其他模型,预测决定系数R2为0.617,RPD为1.614。鉴于土壤光谱信息同时还具有测定简单、省时、无损等优点,因此土壤光谱是土壤有机碳密度空间插值的理想辅助因子。
URL [本文引用: 1]
传统线性回归模型在借助光谱信息进行土壤属性预测时,通常忽略了土壤自身所具有的空间异质性和依赖性,并且未考虑模型残差的空间结构。针对以上不足,该文以江汉平原232个土壤样本为研究对象,以土壤反射光谱为辅助变量,采用偏最小二乘回归、普通克里格、协同克里格以及回归克里格分别构建土壤有机碳密度预测模型,选取决定系数(R2)、均方根误差、标准差与预测均方根误差比(ratio of performance to deviation,RPD)对模型预测精度进行对比评价。结果显示,结合高光谱信息,且同时考虑残差空间结构的回归克里格模型表现优于其他模型,预测决定系数R2为0.617,RPD为1.614。鉴于土壤光谱信息同时还具有测定简单、省时、无损等优点,因此土壤光谱是土壤有机碳密度空间插值的理想辅助因子。
DOI:10.1016/S2095-3119(13)60395-0URL [本文引用: 1]
The spatial interpolation for soil texture does not necessarily satisfy the constant sum and nonnegativity constraints. Meanwhile, although numeric and categorical variables have been used as auxiliary variables to improve prediction accuracy of soil attributes such as soil organic matter, they (especially the categorical variables) are rarely used in spatial prediction of soil texture. The objective of our study was to comparing the performance of the methods for spatial prediction of soil texture with consideration of the characteristics of compositional data and auxiliary variables. These methods include the ordinary kriging with the symmetry logratio transform, regression kriging with the symmetry logratio transform, and compositional kriging (CK) approaches. The root mean squared error (RMSE), the relative improvement value of RMSE and Aitchison's distance (D-A) were all utilized to assess the accuracy of prediction and the mean squared deviation ratio was used to evaluate the goodness of fit of the theoretical estimate of error. The results showed that the prediction methods utilized in this paper could enable interpolation results of soil texture to satisfy the constant sum and nonnegativity constraints. Prediction accuracy and model fitting effect of the CK approach were better, suggesting that the CK method was more appropriate for predicting soil texture. The CK method is directly interpolated on soil texture, which ensures that it is optimal unbiased estimator. If the environment variables are appropriately selected as auxiliary variables, spatial variability of soil texture can be predicted reasonably and accordingly the predicted results will be satisfied.
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
[本文引用: 2]
[本文引用: 2]
[本文引用: 3]
[本文引用: 3]
DOI:10.3969/j.issn.1671-5144.2005.03.010URL [本文引用: 1]
回归分析中对自变量的要求比较宽松,可以是服从正态分布的随机变量,也可以是分类变量及有序变量,参与回归方程的估计时需首先对分类变量和有序变量赋值.实际应用中,分类变量的赋值存在较多的误用,势必导致错误的分析结果.本文给出了最普遍发生的定性变量被错误赋值的情形,剖析了错误的原因,指出对分析结果的严重歪曲.文中阐述了哑变量设置的具体方法和结果的解释,旨在指导读者采用正确的赋值方法,对分类变量采用多个派生的哑变量参与建模计算,从而得到合理的回归分析结果.
DOI:10.3969/j.issn.1671-5144.2005.03.010URL [本文引用: 1]
回归分析中对自变量的要求比较宽松,可以是服从正态分布的随机变量,也可以是分类变量及有序变量,参与回归方程的估计时需首先对分类变量和有序变量赋值.实际应用中,分类变量的赋值存在较多的误用,势必导致错误的分析结果.本文给出了最普遍发生的定性变量被错误赋值的情形,剖析了错误的原因,指出对分析结果的严重歪曲.文中阐述了哑变量设置的具体方法和结果的解释,旨在指导读者采用正确的赋值方法,对分类变量采用多个派生的哑变量参与建模计算,从而得到合理的回归分析结果.
DOI:10.1007/BF00891269URL [本文引用: 1]
DOI:10.1007/s12665-017-6814-3URL [本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
DOI:10.1016/j.patrec.2010.03.014URL [本文引用: 1]
Abstract
This paper proposes, focusing on random forests, the increasingly used statistical method for classification and regression problems introduced by Leo Breiman in 2001, to investigate two classical issues of variable selection. The first one is to find important variables for interpretation and the second one is more restrictive and try to design a good parsimonious prediction model. The main contribution is twofold: to provide some experimental insights about the behavior of the variable importance index based on random forests and to propose a strategy involving a ranking of explanatory variables using the random forests score of importance and a stepwise ascending variable introduction strategy.[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
DOI:10.1080/00401706.1988.10488337URL [本文引用: 1]
[本文引用: 1]
[本文引用: 1]
DOI:10.2136/sssaj1993.03615995005700020026xURL [本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
URL [本文引用: 2]
【目的】以北京市平谷区为研究区域,采用传统统计和地统计学相结合的方法研究县域尺度下土壤质地空间变异的规律,探究土壤质地空间变异的机理。【方法】采用Levine’s方法进行方差奇次性检验,根据检验结果选取最小显著性差方法(least-significant difference,LSD)对土壤颗粒组成与高程、母质、土地利用和水域分布关系进行研究。空间预测采用普通克里格法,鉴于土壤质地属于成分数据,插值前对原始数据进行对称对数比转换。【结果】不同高程组、母质类型、土地利用类型及水域缓冲区组各颗粒平均含量存在一定的差异性,不同高程组和母质类型的土壤颗粒组成之间的差异性比不同土地利用类型和水域缓冲区明显。总体而言,研究区内随着海拔高度的降低,土壤颗粒呈现由粗变细的趋势;由石英含量较高的酸性岩母质发育的土壤土壤颗粒较粗;菜地土壤颗粒相对较细;随着离水域距离的增大,土壤砂粒含量呈增加趋势。地统计分析结果显示,土壤质地各颗粒表现出极强的空间自相关性,空间变异主要由结构性因素引起。各颗粒空间插值结果表明,土壤各颗粒组成空间分布总体趋势特征比较明显。【结论】传统统计分析和地统计学相结合的方法能够系统和全面地揭示土壤质地空间变异的确定性和随机性,研究区土壤质地空间格局主要受地形、母质等自然因素影响。经过对称对数比转换后,土壤质地各颗粒组成空间预测结果满足成分数据空间插值的要求。
URL [本文引用: 2]
【目的】以北京市平谷区为研究区域,采用传统统计和地统计学相结合的方法研究县域尺度下土壤质地空间变异的规律,探究土壤质地空间变异的机理。【方法】采用Levine’s方法进行方差奇次性检验,根据检验结果选取最小显著性差方法(least-significant difference,LSD)对土壤颗粒组成与高程、母质、土地利用和水域分布关系进行研究。空间预测采用普通克里格法,鉴于土壤质地属于成分数据,插值前对原始数据进行对称对数比转换。【结果】不同高程组、母质类型、土地利用类型及水域缓冲区组各颗粒平均含量存在一定的差异性,不同高程组和母质类型的土壤颗粒组成之间的差异性比不同土地利用类型和水域缓冲区明显。总体而言,研究区内随着海拔高度的降低,土壤颗粒呈现由粗变细的趋势;由石英含量较高的酸性岩母质发育的土壤土壤颗粒较粗;菜地土壤颗粒相对较细;随着离水域距离的增大,土壤砂粒含量呈增加趋势。地统计分析结果显示,土壤质地各颗粒表现出极强的空间自相关性,空间变异主要由结构性因素引起。各颗粒空间插值结果表明,土壤各颗粒组成空间分布总体趋势特征比较明显。【结论】传统统计分析和地统计学相结合的方法能够系统和全面地揭示土壤质地空间变异的确定性和随机性,研究区土壤质地空间格局主要受地形、母质等自然因素影响。经过对称对数比转换后,土壤质地各颗粒组成空间预测结果满足成分数据空间插值的要求。
[本文引用: 2]
[本文引用: 2]
DOI:10.1007/s10661-017-5997-0URLPMID:28534308 [本文引用: 2]
Knowledge of soil texture variations is critical for agricultural and engineering applications because texture influences many other soil properties. This study used random forest method to evaluate the effects of human activities and topographic parameters on the spatial variability of soil texture in hilly areas where soil parent material was uniform. The study site covers 252 km(2) and is located in the Upper Yangtze River Basin of south-west China. A total of 3636 samples were collected from the cultivated soils at a depth of 20 cm of dryland (sloping field and terraced land) landscape. The soil texture class for each sample was estimated by experienced soil scientists in the field. Two soil texture classes (loam and clay) were observed in the watershed. Eleven terrain parameters were derived from a digital elevation model with a resolution of 30 m. Compared with loamy soils, clayey soils were mostly observed in the areas with lower elevation and gentle slopes. The outcome of random forest indicated that human activities and elevation had strong effects on soil texture class variations across the study site. Further results showed that the relative importance of terrain parameters to soil texture class variations varied with dryland landscape. Topographic wetness index and elevation were the most important variables for sloping field and terraced land landscapes, respectively.
DOI:10.1590/S0103-90162009000300009URL [本文引用: 2]
[本文引用: 1]
[本文引用: 1]
URL [本文引用: 1]
为了揭示川中丘陵区紫色土地表微地形变化对土壤侵蚀的影响,该文通过室内人工模拟降雨试验,从地表糙度角度出发,结合多重分形理论与方法,分析了不同坡度条件下紫色土地表微地形变化特征,探讨了地表微地形变化与土壤侵蚀间的关系。结果表明:1)雨强为1.5 mm/min,历时为40 min降雨条件下,10°、15°和20°坡面地表相对高程的变化量分别为-11.66、-3.52 和-5.61 mm,仅20°坡面地表初始低洼部位被径流贯通形成细沟;各坡面地表糙度均有所减小,且表现为15°>10°>20°,其中10°和15°坡面不同坡位地表糙度均较雨前减小,20°坡面下坡地表糙度较雨前增大,不同坡度全坡面地表糙度均较雨前减小;2)地表微地形具有一定的多重分形特征,10°和15°坡面雨后多重分形参数广义分形维数跨度、奇异指数跨度和多重分形谱高差均较雨前增大,微地形空间分布差异增大,且地表变得圆润,20°坡面与之相反;3)随坡度增大,地表径流量呈先减小后增大的变化趋势,且地表糙度变幅越小的坡面,地表产流量越高,而侵蚀产沙量则随坡度的增大显著提高(P<0.05)。研究成果为揭示水蚀过程中地表微地形变化的本质和作用机理提供了参考。
URL [本文引用: 1]
为了揭示川中丘陵区紫色土地表微地形变化对土壤侵蚀的影响,该文通过室内人工模拟降雨试验,从地表糙度角度出发,结合多重分形理论与方法,分析了不同坡度条件下紫色土地表微地形变化特征,探讨了地表微地形变化与土壤侵蚀间的关系。结果表明:1)雨强为1.5 mm/min,历时为40 min降雨条件下,10°、15°和20°坡面地表相对高程的变化量分别为-11.66、-3.52 和-5.61 mm,仅20°坡面地表初始低洼部位被径流贯通形成细沟;各坡面地表糙度均有所减小,且表现为15°>10°>20°,其中10°和15°坡面不同坡位地表糙度均较雨前减小,20°坡面下坡地表糙度较雨前增大,不同坡度全坡面地表糙度均较雨前减小;2)地表微地形具有一定的多重分形特征,10°和15°坡面雨后多重分形参数广义分形维数跨度、奇异指数跨度和多重分形谱高差均较雨前增大,微地形空间分布差异增大,且地表变得圆润,20°坡面与之相反;3)随坡度增大,地表径流量呈先减小后增大的变化趋势,且地表糙度变幅越小的坡面,地表产流量越高,而侵蚀产沙量则随坡度的增大显著提高(P<0.05)。研究成果为揭示水蚀过程中地表微地形变化的本质和作用机理提供了参考。
[本文引用: 1]
[本文引用: 1]
URL [本文引用: 1]
江苏北部5市土壤表层(0~20cm)全氮含量连云港东北部、淮安南部和盐城西部显著高于其它地区;全磷含量呈现由北到南、自西向东升高的趋势;速效磷含量高值区位于北部的灌云县和南部的金湖县;速效钾含量东部沿海高于其它地区。土壤类型和成土母质对土壤养分产生显著影响:对于土类而言,沼泽土和水稻土养分较高;各成土母质中,湖相沉积物发育的土壤养分含量最高。在研究区1:5万尺度范围内,土壤类型对全氮和全磷的变异起主导作用,而速效磷受成土母质的影响较大,土壤类型和成土母质对速效钾的影响较小,土壤类型和成土母质对全量养分的影响要大于速效养分。
URL [本文引用: 1]
江苏北部5市土壤表层(0~20cm)全氮含量连云港东北部、淮安南部和盐城西部显著高于其它地区;全磷含量呈现由北到南、自西向东升高的趋势;速效磷含量高值区位于北部的灌云县和南部的金湖县;速效钾含量东部沿海高于其它地区。土壤类型和成土母质对土壤养分产生显著影响:对于土类而言,沼泽土和水稻土养分较高;各成土母质中,湖相沉积物发育的土壤养分含量最高。在研究区1:5万尺度范围内,土壤类型对全氮和全磷的变异起主导作用,而速效磷受成土母质的影响较大,土壤类型和成土母质对速效钾的影响较小,土壤类型和成土母质对全量养分的影响要大于速效养分。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}