关键词:大麦; 遗传多样性; 单倍型; 连锁不平衡; 关联分析 Association of Genetic Diversity forAmy6-4 Gene with α-Amylase Activity in Germplasm of Barley JIANG Xiao-Dong1,2, GUO Gang-Gang1, ZHANG Jing1,* 1 Institute of Crop Science, Chinese Academy of Agricultural Sciences, Beijing 100081, China
2College of Agronomy, Shanxi Agricultural University, Taigu 030801, China
AbstractAmy6-4 is one of the genes codingα-amylase with high isoelectric point, which plays an important role in germination and malting process in barley (Hordeum vulgare L.). To detect the intervarietal polymorphism onAmy6-4 locus, we resequenced theAmy6-4alleles in 58 barley varieties that are deposited in the germplasm bank of China, and analyzed the association of single nucleotide polymorphisms (SNPs) and haplotypes with α-amylase activity based on the population structure. A total of seven SNPs in five haplotypes were detected among the 58 barley entries. Haplotype H_3 was most popular with frequence of 51.7% (30/58) in the entries tested, and haplotype H_1 ranked the second with frequnce about 39.7% (23/58). However, the remaining three haplotypes only shared about 10% of the frequency. No SNP or haplotype was associated with α-amylase activity.
Keyword:Barley; Genetic diversity; Haplotype; Linkage disequilibrium; Association analysis Show Figures Show Figures
(续表1) 58份供试大麦种质的编号、原产地及特性 Table 1 Continued Accession number, origin, and characteristics of 58 barley entries
品种编号Accession No.
原产地Origin
棱型Row number
皮裸性1)Covered/ naked1)
冬春性2)Growth habit2)
种质类型3)Germplasm type3)
单倍型类型 Type of haplotype
α-淀粉酶活性Activity of α-amylase
ZDM3447
中国湖北 Hubei, China
6
C
W
L
1
0.917
ZDM5240
中国黑龙江 Heilongjiang, China
6
C
S
L
3
0.824
ZDM1175
中国黑龙江 Heilongjiang, China
6
C
S
L
1
1.255
ZDM860
中国河南 Henan, China
6
N
S
L
3
1.079
ZDM586
中国河南 Henan, China
6
C
S
L
1
1.209
ZDM14
中国河北 Hebei, China
6
C
S
L
1
1.265
ZDM8986
中国贵州 Guizhou, China
6
C
F
L
3
1.053
ZDM8981
中国贵州 Guizhou, China
6
C
W
L
1
0.781
ZDM3883
中国贵州 Guizhou, China
2
C
S
L
1
1.371
ZDM3901
中国贵州 Guizhou, China
6
C
W
L
1
1.330
ZDM3629
中国广东 Guangdong, China
6
C
W
L
1
1.245
ZDM8055
中国甘肃 Gansu, China
6
N
S
L
3
0.868
ZDM7825
中国甘肃 Gansu, China
2
C
S
L
3
1.516
ZDM8018
中国甘肃 Ganshu, China
6
N
S
L
3
1.115
ZDM3606
中国福建 Fujian, China
6
N
S
L
3
1.145
ZDM5258
中国安徽 Anhui, China
6
C
F
L
1
0.505
ZDM5260
中国安徽 Anhui, China
6
C
F
L
1
0.655
ZDM5261
中国安徽 Anhui, China
6
C
F
L
1
0.754
WDM4911
伊朗 Iran
6
N
S
L
3
0.587
WDM3692
叙利亚 Syria
6
C
S
L
3
0.784
1) C和N分别代表皮大麦和裸大麦;2) S、W和F分别代表春性、冬性和半冬性;3) C、L和W分别代表栽培品种、地方品种和野生种。 1) C and N stand for covered and naked barely, respectively;2) S, W, and F stand for spring, winter, and facultative barely, respectively;3) C, L, and W stand for cultivar, landrace, and wild species, respectively.
(续表1) 58份供试大麦种质的编号、原产地及特性 Table 1 Continued Accession number, origin, and characteristics of 58 barley entries
表2 Table 2 表2(Table 2)
表2 用于扩增 Amy6-4基因不同区段的引物 Table 2 Primers for Amplification of different parts of Amy6-4 gene in barley
引物 Primer
序列 Sequence (5′-3′)
产物期望大小 Expected product (bp)
退火温度 Annealing temp. (℃)
正向 Forward
反向 Reverse
Amy6-4_1
CGTTCAAAGCGTGTGTTATTTT
CATGATCGCGGTACATACAGA
1306
61
Amy6-4_2
CCATCTACATCACTTGGGCATT
ATGAACGAAACCAAGAAAAGAAA
1420
59
Amy6-4_3
TCTGTATGTACCGCGATCATGT
TGTATCATATAGGAACTTGTAGAGCTG
1400
62
Amy6-4_2
TTTCTTTTCTTGGTTTCGTTCA
AAGCTTTTGGTTATCTATATCCATTG
590
61
表2 用于扩增 Amy6-4基因不同区段的引物 Table 2 Primers for Amplification of different parts of Amy6-4 gene in barley
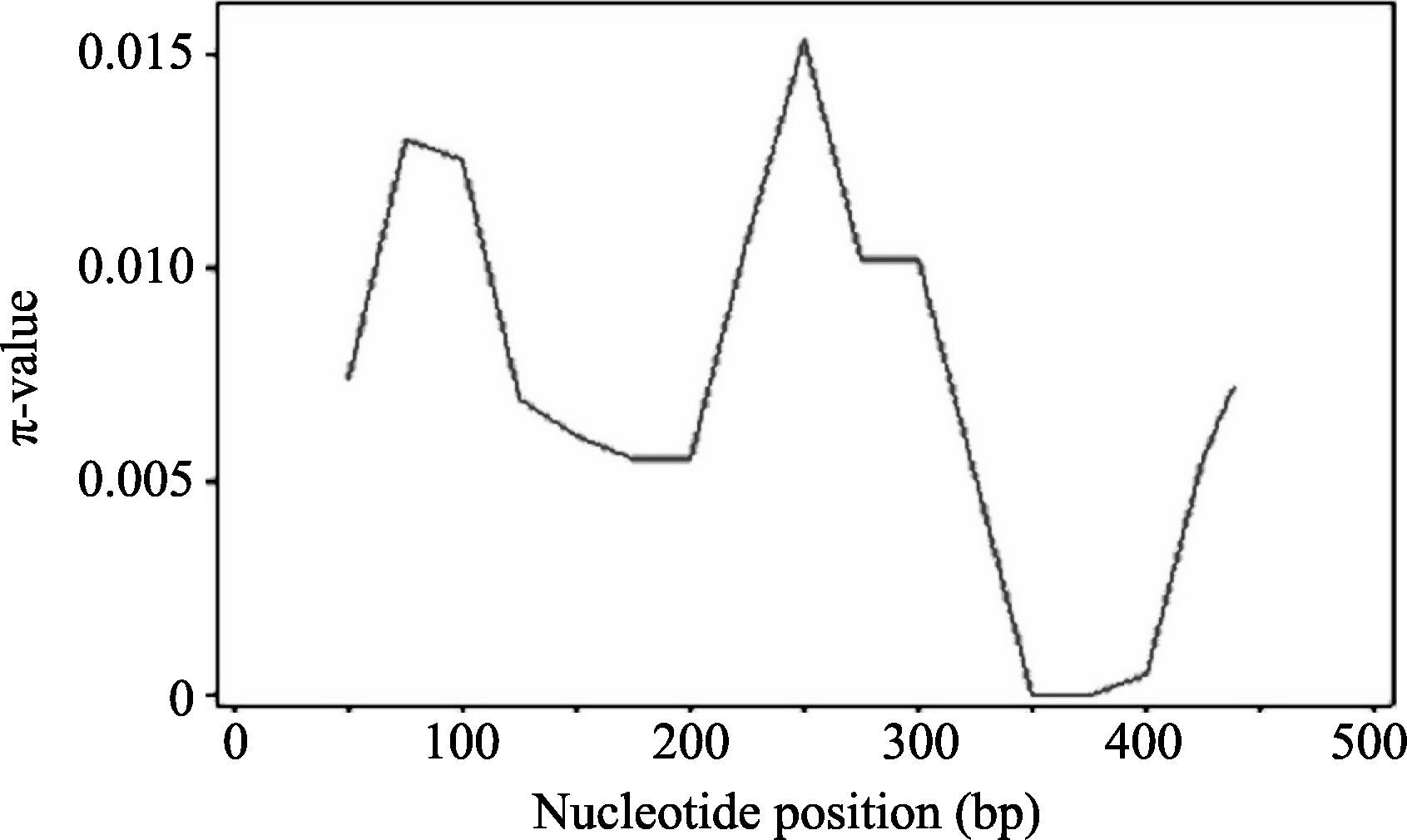
图2 Amy6-4结构示意图及在第3外显子和3′ UTR上的多态性位点(SNP)Fig. 2 Schematic structure of Amy6-4 with all detected SNPs, located in the third exon and the 3′ UTR
表3 Table 3 表3(Table 3)
表3 在58份大麦种质中发现的 Amy6-4的单倍型 Table 3 Haplotypes in Amy6-4 gene among 58 barley entries
单倍型 Haplotype
种质数 No. of entries
频率 Frequency (%)
多态性位点 Polymorphic loci
2442C
2477C
2587C
2591C
2655U
2657U
2840U
H_1
23
39.7
G
A
G
C
A
C
A
H_2
3
5.2
C
G
A
G
G
G
G
H_3
30
51.7
C
G
G
G
G
G
G
H_4
1
1.7
C
A
G
G
A
C
G
H_5
1
1.7
G
G
G
G
G
C
G
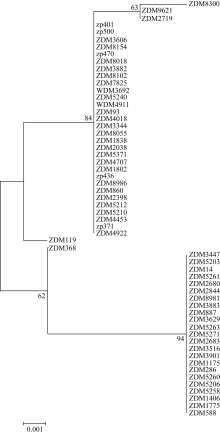
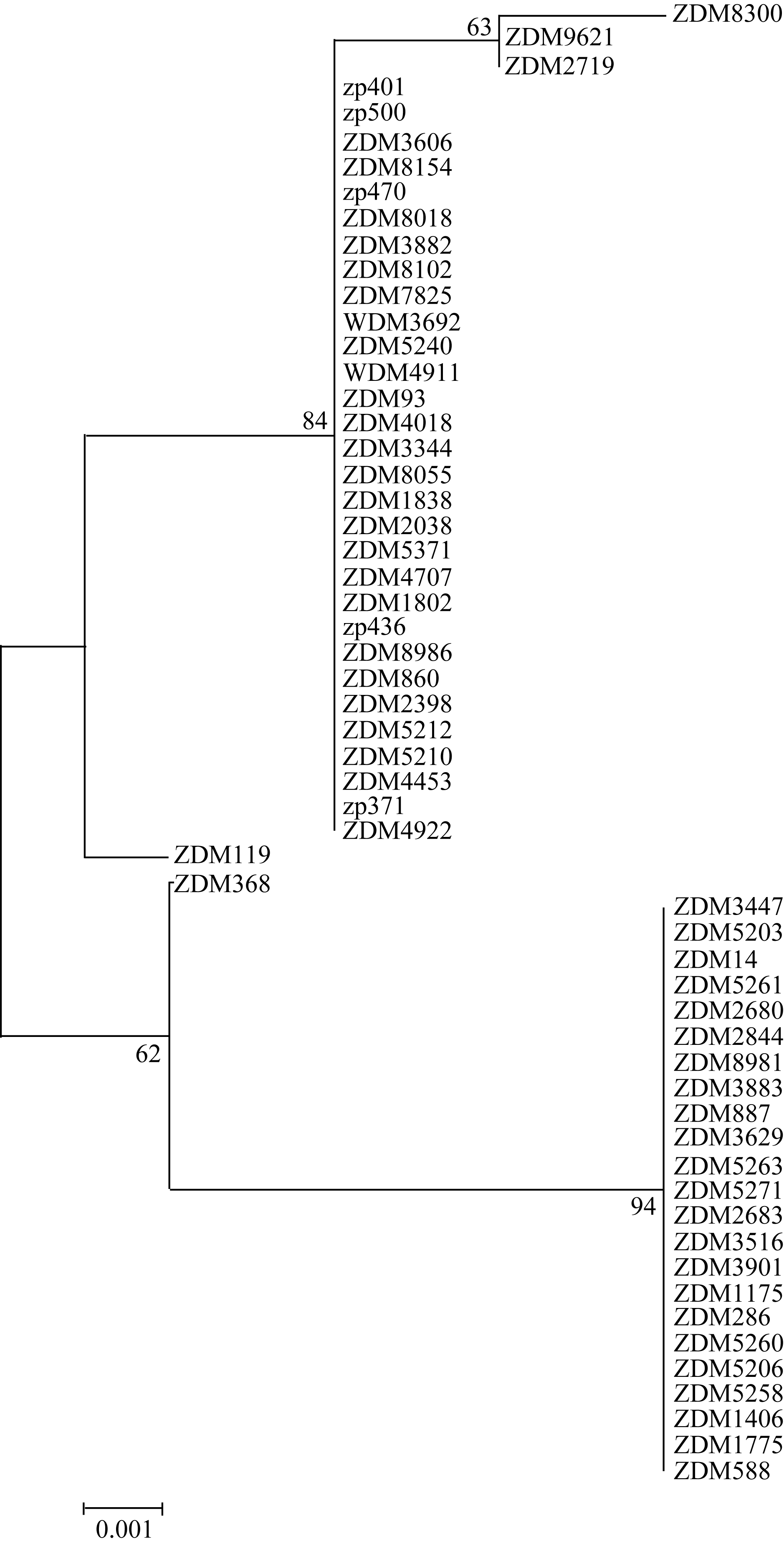
多态性位点表示为核苷酸序数+所在区域, 其中C表示编码区, U表示3′ UTR区。H_1单倍型包括种质ZDM14、ZDM286、ZDM887、ZDM1175、ZDM1406、ZDM1775、ZDM3447、ZDM3516、ZDM3629、ZDM5203、ZDM5206、ZDM5258、ZDM5260、ZDM5261、ZDM5263、ZDM5271、ZDM8981、ZDM2680、ZDM2683、ZDM586、ZDM2844、ZDM3883和ZDM3901; H_2单倍型包括种质ZDM2719、ZDM8300和ZDM9621; H_3单倍型包括种质ZDM860、ZDM3882、ZDM4922、ZDM8018、ZDM8102、ZP401、WDM3692、ZDM1838、ZDM5240、ZDM5371、ZDM1802、ZP436、ZDM4453、ZDM5210、ZDM8055、ZDM8986、ZP470、WDM4911、ZDM2398、ZDM3344、ZDM7825、ZDM4018、ZDM2038、ZP500、ZP371、ZDM8154、ZDM5212、ZDM4707、ZDM3606和ZDM93; H_4单倍型包括种质 ZDM368; H_5单倍型包括种质ZDM119。 The polymorphic locus is named as the series number of the nucleotide plus the letter “C” (coding region) or “U” (3′ UTR region). The H_1 haplotype included entries ZDM14, ZDM286, ZDM887, ZDM1175, ZDM1406, ZDM1775, ZDM3447, ZDM3516, ZDM3629, ZDM5203, ZDM5206, ZDM5258, ZDM5260, ZDM5261, ZDM5263, ZDM5271, ZDM8981, ZDM2680, ZDM2683, ZDM586, ZDM2844, ZDM3883, and ZDM3901; the H_2 haplotype included entries ZDM2719, ZDM8300, and ZDM9621; the H_3 haplotype included entries ZDM860, ZDM3882, ZDM4922, ZDM8018, ZDM8102, ZP401, WDM3692, ZDM1838, ZDM5240, ZDM5371, ZDM1802, ZP436, ZDM4453, ZDM5210, ZDM8055, ZDM8986, ZP470, WDM4911, ZDM2398, ZDM3344, ZDM7825, ZDM4018, ZDM2038, ZP500, ZP371, ZDM8154, ZDM5212, ZDM4707, ZDM3606, and ZDM93; and the H_4 and H_5 haplotypes included entries ZDM368 and ZDM119, respectively.
表3 在58份大麦种质中发现的 Amy6-4的单倍型 Table 3 Haplotypes in Amy6-4 gene among 58 barley entries
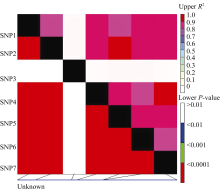
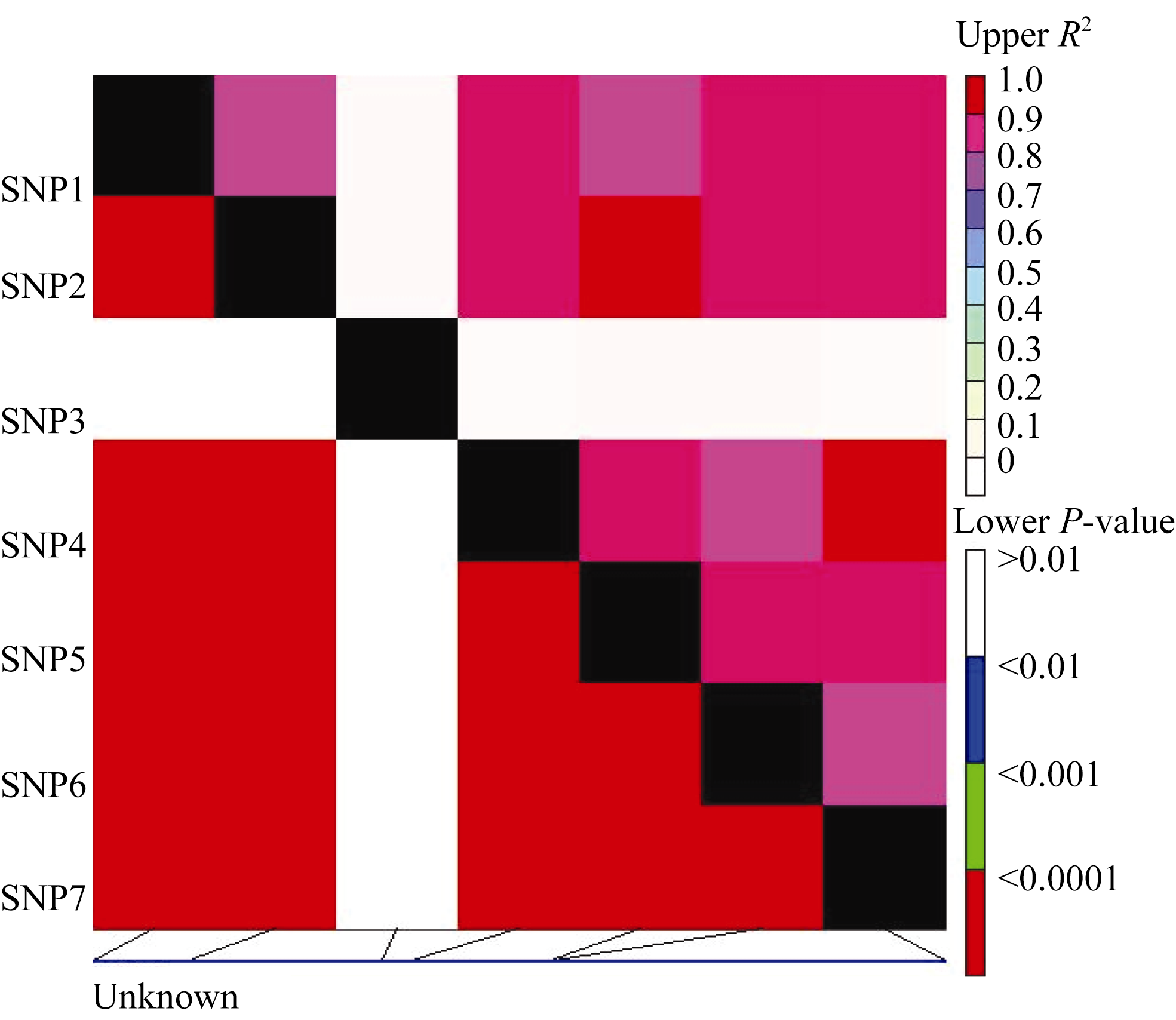
图5 Amy6-4基因内的多态性位点(SNP)的连锁不平衡关系对角线上为 R2值, 对角线下为 P值; 矩形表示SNP间的相关性。Fig. 5 Linkage disequilibrium of the Amy6-4gene revealed in different sets of barley varieties by SNP-analysis R2 values and P-values are shown in the upper and lower diagonal, respectively. The rectangles show correlation between SNP combinations.
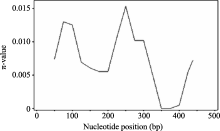
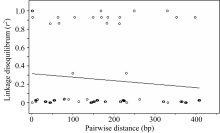
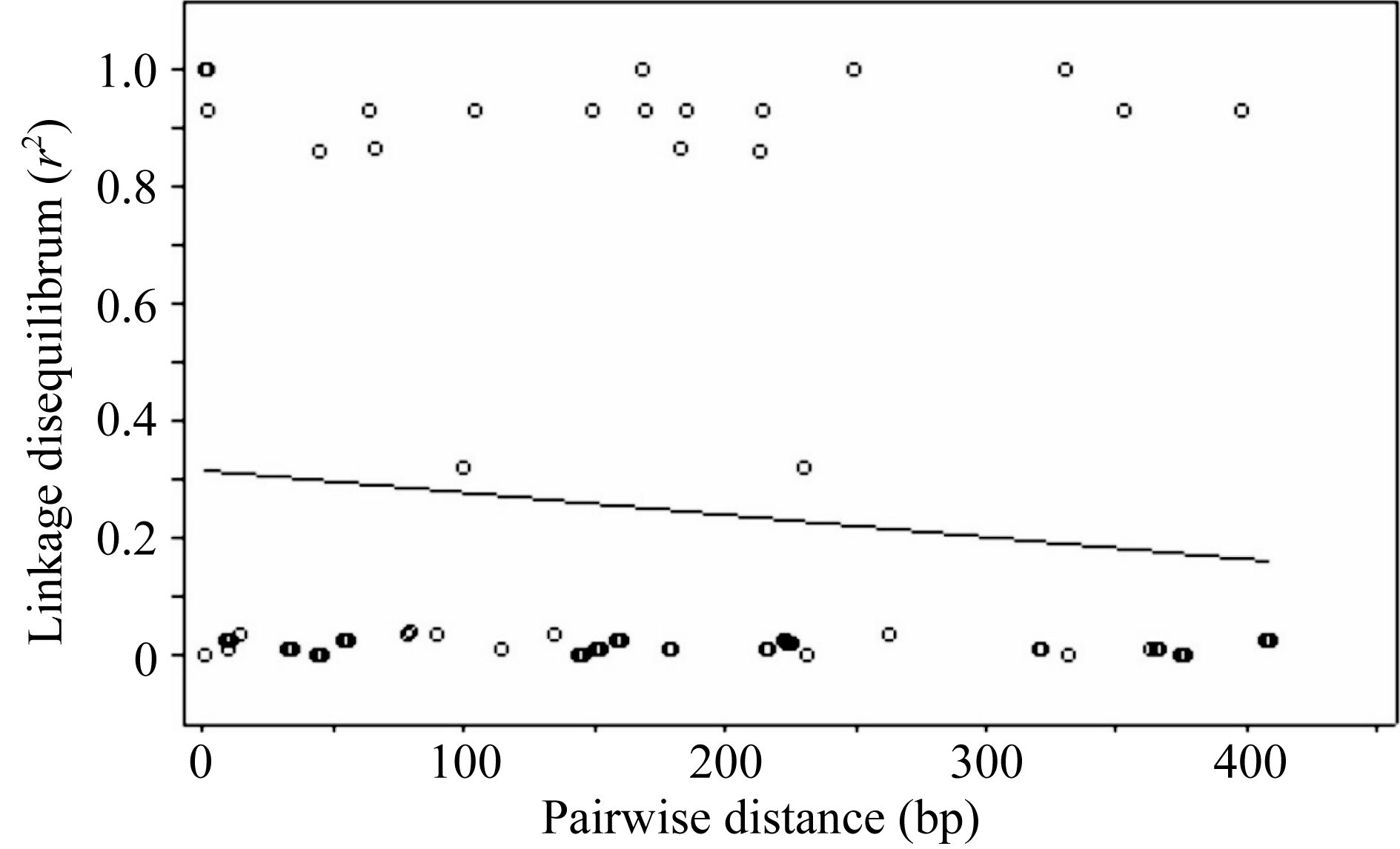
图6 Amy6-4基因SNP位点间 r2值随遗传距离衰减散点图Fig. 6 Attenuation of r2values between SNP pairs along with genetic distance on Amy6-4 locus
表4 Table 4 表4(Table 4)
表4 Amy6-4基因的单倍型及其相应的不同特性样品数统计 Table 4 Haplotype patterns of Amy6-4gene and their affiliation to samples based on different barley traits
单倍型 Haplotype
多态性SNP Polymorphisic SNP (5′-3′)
大麦类型 Type of barley
SNP1
SNP2a
SNP3
SNP4a
SNP5
SNP6
`SNP7
2r-s
6r-s
2r-W
6r-W
N
C
H_1
G (Arg)
A (Asn)
G (Gly)
C (Ala)
A
C
A
7
4
1
11
—
23
H_2
C (Arg)
G (Ser)
A (Gly)
G (Gly)
G
G
G
2
—
—
1
—
3
H_3
C (Arg)
G (Ser)
G (Gly)
G (Gly)
G
G
G
2
21
—
7
17
13
H_4
C (Arg)
A (Asn)
G (Gly)
G (Gly)
A
C
G
—
—
—
1
—
1
H_5
G (Arg)
G (Asn)
G (Gly)
G(Gly)
G
C
G
1
—
—
—
—
1
SNP位点后括号内字母表示编码的氨基酸;a表示该多态性位点编码的氨基酸发生替换。大麦类型中2r-S、6r-S、2r-W和6r-W分别代表二棱春大麦、六棱春大麦、二棱冬大麦和六棱冬大麦; N和C分别代表裸大麦和皮大麦。 Amino acids coded by the SNP are shown in the brackets follwing the SNP site; SNP marked witha indicates substititution of amino acid residue on this locus. Barley types 2r-S, 6r-S, 2r-W, and 6r-W represent two-rowed spring barley, six-rowed spring barley, two-rowed winter barley, and six-rowed winter barley, respectively; and types N and C represent naked and covered barley, respectively.
表4 Amy6-4基因的单倍型及其相应的不同特性样品数统计 Table 4 Haplotype patterns of Amy6-4gene and their affiliation to samples based on different barley traits
Knox C A P, SonthayanonB, Chand raG R, MuthukrishnanS. Structure and organization of two divergent α-amylase genes from barley. Plant Mol Biol, 1987, 9: 3-17[本文引用:1][JCR: 3.518]
2
RogersJ C. Two barley alpha-amylase gene families are regulated differently in aleurone cells. J Biol Chem, 1985, 260: 3731-3738[本文引用:1][JCR: 4.651]
3
ThornsberryJ M, GoodmanM M, DoebleyJ, KresovichS, NielsenD, BucklerE S. Dwarf8 polymorphisms associate with variation in flowering time. Nat Genet, 2001, 28: 286-289[本文引用:1][JCR: 35.209]
4
谭贤杰, 宋燕春, 石云素, 程伟东, 吴子恺, 王天宇, 黎裕. 玉米Bubisco活化酶基因ZmRCA1的序列变异分析. 作物学报, 2011, 37: 58-66TanX J, SongY C, ShiY S, ChengW D, WuZ K, WangT Y, LiY. Analysis of sequence polymorphism of ZmRCA1 in maize. Acta Agron Sin, 2011, 37: 58-66 (in Chinese with English abstract)[本文引用:1][CJCR: 1.667]
5
张洪映, 毛新国, 景蕊莲, 谢惠民, 昌小平. 小麦TaPK7 基因单核苷酸多态性与抗旱性的关系. 作物学报, 2008, 34: 1537-1543ZhangH Y, MaoX G, JingR L, XieH M, ChangX P. Relationship between single nucleotide polymorphism of TaPK7 gene. Acta Agron Sin, 2008, 34: 1537-1543 (in Chinese with English abstract)[本文引用:1][CJCR: 1.667]
MillerG L. Use of dinitrosalicylic acid reagent for determination of reducing sugar. Anal Chem, 1959, 31: 426-428[本文引用:1][JCR: 5.695]
8
ThompsonJ D, HigginsD G, GibsonT J. CLUSTAL W: improving the sensitivity of progressive multiple sequence alignment through sequence weighting, position-specific gap penalties and weight matrix choice. Nucl Acids Res, 1994, 22: 4673-4680[本文引用:1]
9
RozasJ, Sánchez-DelBarrioJ C, MesseguerX, RozasR. DnaSP, DNA polymorphism analyses by the coalescent and other methods. Bioinformatics, 2003, 19: 2496-2497[本文引用:1][JCR: 5.323]
10
WattersonG A. On the number of segregating sites in genetical models without recombination. Theor Pop Biol, 1975, 7: 256-276[本文引用:1]
11
NeiM, LiW H. Mathematical model for studying genetic variation in terms of restriction endonucleases. Proc Natl Acad Sci USA, 1979, 76: 5269-5273[本文引用:1][JCR: 9.737]
12
TajimaF. Statistical method for testing the neutral mutation hypothesis by DNA polymorphism. Genetics, 1989, 123: 585-595[本文引用:1][JCR: 4.389]
PritchardJ K, StephensM, DonnellyP. Inference of population structure using multilocus genotype data. Genetics, 2000, 155: 945-959[本文引用:1][JCR: 4.389]
15
RobertX, HaserR, GottschalkT E, RatajczakF, DriguezH, SvenssonB, AghajariN. The structure of barley alpha-amylase isozyme 1 reveals a novel role of domain C in substrate recognition and binding: a pair of sugar tongs. Structure, 2003, 11: 973-984[本文引用:1][JCR: 5.994]
16
MatthiesI E, WeiseS, RöderM S. Association of haplotype diversity in the α-amylase gene amy1 with malting quality parameters in barley. Mol Breed, 2003, 23: 139-152[本文引用:1][JCR: 3.251]
17
BozonnetS, JensenM T, NielsenM M, AghajariN, JensenM H, KramhøftB, WillemoësM, TranierS, HaserR, SvenssonB. The ‘pair of sugar tongs’ site on the non-catalytic domain C of barley alpha-amylase participates in substrate binding and activity. FEBS J, 2007, 274: 5055-5067[本文引用:1][JCR: 4.25]
18
YangX, WestcottS, GongX, EvansE, ZhangX Q, Lance R C M, LiC D. Amino acid substitutions of the limit dextrinase gene in barley are associated with enzyme thermostability. Mol Breed, 2009, 23: 61-74[本文引用:1][JCR: 3.251]
19
FoxG P, PanozzoJ F, LiC D, LanceC M, InkermanP A, HenryR J. Molecular basis of barley quality. Aust J Agric Res, 2003, 54: 1081-1101[本文引用:1][JCR: 1.328]
20
FleetC M, SunT P. A DELLAcate balance: the role of gibberellin in plant morphogenesis. Curr Opin Plant Biol, 2005, 8: 77-85[本文引用:1][JCR: 8.455]
21
GublerF, KallaR, RobertsJ K, JacobsenJ V. Gibberellin- regulated expression of a myb gene in barley aleurone cells: evidence for Myb transactivation of a high-pI alpha-amylase gene promoter. Plant Cell, 1995, 7: 1879-1891[本文引用:1][JCR: 9.251]
22
RogersJ C, LanahanM B, RogersS W. The cis-acting gibberellin response complex in high pI alpha-amylase gene promoters requirement of a coupling element for high-level transcription. Plant Physiol, 1994, 105: 151-158[本文引用:1][JCR: 6.555]
23
ÜlkerB, SomssichI E. WRKY transcription factors: from DNA binding towards biological function. Curr Opin Plant Biol, 2004, 7: 491-498[本文引用:1][JCR: 8.455]
24
UmemuraT, PerataP, FutsuharaY, YamaguchiJ. Sugar sensing and alpha-amylase gene repression in rice embryos. Planta, 1998, 204: 420-428[本文引用:1][JCR: 3.347]
25
PerataP, MatsukuraC, VernieriP, YamaguchiJ. Sugar repression of a gibberellin-dependent signaling pathway in barley embryos. Plant Cell, 1997, 9: 2197-2208[本文引用:1][JCR: 9.251]
26
BushD S. Calcium regulation in plant cells and its role in signaling. Plant Physiol Plant Mol Biol, 1995, 46: 95-122[本文引用:1][JCR: 25.962]
27
LovegroveA, HooleyR. Gibberellin and abscisic acid signalling in aleurone. Trends Plant Sci, 2000, 5: 102-110[本文引用:1][JCR: 11.808]
28
AyoubM, ArmstrongE, BridgerG, FortinM G, MatherD E. Marker-based selection in barley for a QTL region affecting alpha-amylase activity of malt. Crop Sci, 2003, 43: 556-561[本文引用:1][JCR: 1.513]
29
LiC D, TarrA, Lance R C M, HarasymowS, UhlmannJ, WestcotS, YoungK J, GrimeC R, CakirM, BroughtonS, AppelsR. A major QTL controlling seed dormancy and pre-harvest sprouting/grain α-amylase in two-rowed barley (Hordeum vulgare L. ). Aust J Agric Res, 2003, 54: 1303-1313[本文引用:1][JCR: 1.328]
30
ZhangX Q, LiC D, PanozzoJ, WestcottS, ZhangG P, TayA, AppelsR, JonesM, LanceR. Dissecting the telomere region of barley chromosome 5HL using rice genomic sequences as references: new markers for tracking a complex region in breeding. Mol Breed, 2011, 27: 1-9[本文引用:1][JCR: 3.251]
31
Marquez-CedilloL A, HayesP M, JonesB L, KleinhofsA, LeggeW G, RossnagelB G, SatoK, UllrichS E, WesenbergD M. QTL analysis of malting quality in barley based on the doubled-haploid progeny of two elite North American varieties representing different germplasm groups. Theor Appl Genet, 2000, 101: 173-184[本文引用:1][JCR: 3.658]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}