文献[9]中提出了一种基于ARM+FPGA的交通标志识别系统,通过设计图像预处理IP核,结合Zynq-7000全可编程片上系统(System on Chip,SoC)提出了一个新的硬件平台,与现有的基于FPGA的解决方案相比,该硬件平台可以实现高达8倍的速度。文献[10]中认为方向梯度直方图(Histogram of Oriented Gradient, HOG)算法是一个计算密集的任务,并在基于Zynq SoC的系统上提出了3种不同的实现方法来加速算法,第1种采用OpenCV在ARM上运行HOG的方法,第2种采用ARM和FPGA协同实现的方法,第3种仅使用FPGA实现HOG算法,实验结果表明采用ARM和FPGA的协同方法在处理速度和资源利用综合指标下达到最优。因此笔者采用了ARM+FPGA软硬件协同的方式来实现无人机跑道检测算法中图像预处理的硬件加速。
本文针对目前主流计算机处理算法成本高、运行效率低的情况,提出了一种低成本、运行效率高的适用于机载的SoC实现方法。针对算法处理中相对耗时的图像缩放处理进行实验,提出了一种适用于硬件模块实现的图像缩放算法,并设计缩放算法知识产权(Intellectual Property, IP)核。采用Xilinx公司的Zynq-7000系列, 该系统集成了2个ARM Cortex A9核,以及最多可达相当于500多万个逻辑门可编程逻辑单元,搭建软硬件协同的图像处理操作系统[11-15],搭载设计的缩放算法IP核,完成图像的采集、传输、缩放到显示的过程,达到图像实时处理的要求。
1 系统结构搭建 整个图像处理系统如图 1所示,系统的核心部分是Xilinx公司的Zynq-7000芯片,该芯片由处理系统(Processing System,PS)和可编程逻辑(Programmable Logic,PL)两大功能模块组成。PS和PL之间的接口都是基于总线协议(Advanced eXtensible Interface,AXI)设计的,包括高性能总线(High Performance AXI,AXI_HP)和通用总线(General Purpose AXI,AXI_GP)2种,在图像数据流传输中,部分使用AXI_HP设计的接口,提供快速传输的功能,而在控制部分使用AXI_GP总线设计的接口。图像采集部分使用的是OV7670图像传感器, 它具有体积小,工作电压低的特点,可以通过串行摄像机控制总线协议(Serial Camera Control Bus,SCCB)控制输入整帧、取窗口等方式的各种分辨率8位影像数据[9-12]。图像采集模块控制摄像头采集图像数据,并将数据传入到图像处理IP核中进行处理,处理后的数据送入数据搬运器(Datamover)中,通过Datamover可以实现数据从PL到双倍速率同步动态随机存储器(DoubleDataRate,DDR)的搬运,也可以实现数据从DDR到PL的传送,对一些硬件无法实现的复杂图像处理运算,可以将数据传送到PS端进行处理,通过Datamover传送数据可以减少中央处理器(Central Processing Unit,CPU)的利用率,加速平台处理的速度,通过显示器显示处理后的图像。系统的硬件结构框图如图 1所示。
 |
| 图 1 系统硬件结构示意图 Fig. 1 Schematic diagram of system hardware structure |
| 图选项 |
2 图像缩放算法设计 传统的图像缩放大多是采用插值算法来实现的,主要包括最邻近插值、双线性插值和双三次插值算法。由于需要用硬件实现图像缩放,考虑到FPGA内的逻辑资源有限,而算法越复杂设计时占用的逻辑资源就越多,完成一幅图像缩放所用的时间就越长,影响算法的实时性,因此,笔者在基于无人机自主着陆的跑道检测算法中,考虑在满足缩放精度并且简化算法的情况下,设计了一种适用于FPGA硬件实现的图像缩放算法。很多航空电子嵌入式图像处理系统是由固定的图像采集源和显示设备组成,系统中的缩放倍率是固定的,因此根据通用跑道检测算法中显著性区域提取时将输入图像缩小0.25倍来进行设计,大大减小了算法的复杂性和硬件开发的难度。
2.1 算法原理 由于考虑将图像以0.25进行缩小,该算法的核心思路是选择一个4×4的像素块求取区域内每个像素点对中心点的影响系数,将该16个点的影响集中在一个点上,实现图像的缩小,输入像素和输出像素的映射关系见图 2(a)。
 |
| 图 2 求取输出点示意图 Fig. 2 Schematic diagram of output point solving |
| 图选项 |
在计算过程中,先选取行像素点求取中心点,这里以图 2(a)中的第2行为例,根据A、B、C、D距离中心点的距离来确定影响系数并求取中心点E,如式(1)所示:
 | (1) |
同理可得E′、e、e′。再分别根据每行获取的中心点求取列中心点O,即4×4区域的中心点,见图 2(c)和式(2)。
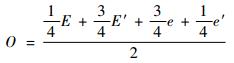 | (2) |
分别将求取每行中心点获得的等式代入式(2),即可求得每个点对输出点的影响系数,见式(3):
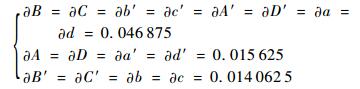 | (3) |
式中:?a为像素点a对输出像素点的影响系数,以此类推。用4×4的像素区域遍历输入图像,通过固定的系数处理该像素区域即可获得缩小后的图像,因此本文设计的缩放算法在结构上得到了简化,可以更方便地在FPGA中用硬件逻辑语言实现。
2.2 性能测试 算法结构在简化后,其性能的好坏需要和传统缩放算法作对比,因此,笔者根据本文设计的图像缩放算法编写MATLAB测试程序,并且和传统的最邻近插值、双线性插值和双三次插值算法分别作对比,从缩放后的效果图、运算时间等2个方面作对比。输入图像是用飞行模拟器(FlightGear)模拟获得的无人机着陆时的跑道图片,图 3是3种传统算法和本文提出的算法处理效果对比图。
从图 3中可以看到,将输入图像按同等倍数缩小时,4幅图像都保持了原有图像的基本特征,但是最邻近插值处理后的图像比较粗糙,有较明显的锯齿,而后3种图像处理后的效果比较平滑。在图像清晰度上,本文算法的处理效果相对于双线性插值和双三次插值更清晰。
 |
| 图 3 不同算法处理效果图 Fig. 3 Processing effect diagram of different algorithms |
| 图选项 |
除此之外,引入定量分析的指标对实验结果进行评估,采用文献[16]中的将图像缩小后再放大到同一分辨率,再利用绝对误差均值(Mean Absolute Error,MAE)、均方误差(Mean Squared Error,MSE)、峰值信噪比(Peak Signal to Noise Ratio,PSNR)以及信噪比(Signal Noise Ratio,SNR)对缩放效果进行评估。MAE、MSE、PSNR、SNR的计算公式分别为
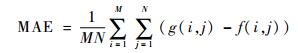 | (4) |
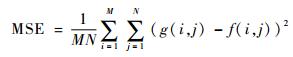 | (5) |
 | (6) |
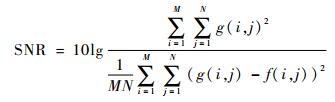 | (7) |
式中:M和N分别为输入二维图像的行数和列数;g(i, j)和f(i, j)分别为横坐标为i、纵坐标为j下的输入图像和输出图像像素值。当MAE、MSE的值越小,PSNR、SNR的值越大,图像的处理效果越好,质量越高。采用这4个指标的客观比较结果如表 1。
表 1 定量分析对比 Table 1 Comparison of quantitative analysis
| 客观评价指标 | 最邻近插值 | 双线性插值 | 双三次插值 | 本文算法 |
| left | 0.0274 | 0.0268 | 0.0257 | 0.0252 |
| MSE | 0.0026 | 0.0021 | 0.0020 | 0.0020 |
| PSNR | 25.9162 | 26.7568 | 27.0400 | 27.0521 |
| SNR | 18.0160 | 18.8565 | 19.1397 | 19.1518 |
表选项
从表 1中可以看到,评价指标中MAE是最小的,MSE和双三次插值法同时最小,PSNR和SNR都是最大的,所以定量分析的结果是本文提出的算法相较于其他3种算法处理效果更好。4种算法处理的时间见表 2。
表 2 4种算法的MATLAB运行时间对比 Table 2 Comparison of MATLAB running time among four algorithms
| 算法 | 运行时间/ms |
| 最邻近插值 | 3.02 |
| 双线性插值 | 13.73 |
| 双三次插值 | 25.66 |
| 本文算法 | 3.44 |
表选项
从表 2中可以看到,因为最邻近插值法的算法结构最简单,所以它的耗时最少,而双三次插值的耗时最多。在实际应用中,当基于无人机视觉算法的跑道跟踪过程中需要处理大量图片时,缩放环节节约的总时间是非常可观的。
因此,综合考虑算法的处理效果和运算时间,在该缩放应用处理中,本文提出的算法具有更大的优势,并且由于其结构简单,更利于使用FPGA的硬件逻辑编写实现进一步加速。
3 图像缩放IP核设计及仿真 缩放IP核的开发软件使用的是Xilinx公司的VIVADO设计套件,并用Verilog HDL(Hardware Description Language)进行硬件逻辑的编写。缩放图像中输入点对输出点的影响系数可以合并为以下3个:0.015625、0.046875、0.140625。在硬件实现的时候为了提高处理速度,尽量避免浮点数运算,又要同时保持数据的精度,通常采用去尾法来处理浮点数,这3个系数可以写成式(8)的形式:
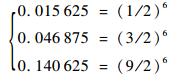 | (8) |
因此在硬件逻辑转化时将参数扩大26倍转换为整数运算,在二进制运算中即向左移6位,所以参数选用1、3、9,分别用二进制表示为4′b0001、4′b0011、4′b1001,最后获取处理后的数据时舍弃后6位数据即可。每个图像区域处理块中包含16个像素点,用4位计数器进行计数,根据计数器的数值对应像素块中点的相对位置,利用case语句选取对应参数,将输入数据依次乘上对应参数,并分别存入存储器中,进行累加。
图像缩放模块的仿真时序图如图 4所示,为了方便观察和计算,测试仿真时输入一个16列、8行的像素矩阵块,前4行全部输入测试像素2,后4行全部输入测试像素6,缩放后的结果应为一个4列、2行的像素块,像素值依次为2、2、2、2、6、6、6、6,见图 4仿真波形中的small_data。
 |
| 图 4 图像缩放模块仿真波形 Fig. 4 Simulation waveform of image scaling module |
| 图选项 |
将使用Verilog HDL编写的图像缩放IP核例化封装并加入到工程的IP核库中,在模块设计的时候添加该IP核即可完成调用。
4 系统平台测试及性能分析 图 5中只展示了系统部分关键模块图,包括设计的图像缩放IP核、ARM处理器模块、摄像头读取模块以及视频图形阵列(Video Graphics Array,VGA)显示模块。
 |
| 图 5 系统部分模块图 Fig. 5 Part of module diagram of system |
| 图选项 |
系统测试的主要器材包括一个Zynq-7000开发板、OV7670摄像头和VGA显示器。利用FlightGear飞行模拟器获得无人机着陆过程的视频,用一台笔记本播放该视频,通过摄像头获取无人机着陆的图像信息,并在VGA中实时显示处理后的结果。实验设备和实验结果见图 6。
 |
| 图 6 系统测试图 Fig. 6 System test chart |
| 图选项 |
图 6(b)中VGA显示器中显示了两部分图片,一部分是输入的原图像,一部分是左上角显示的处理后的缩小图片。通过串口助手获取摄像头采集到的输入图像以及经过IP核处理后的图像数据。在MATLAB中将摄像头捕捉到的输入图像用本文提出的缩放算法处理,并和硬件IP核处理后的图片作对比,处理时间见表 3,SoC的处理速度比MATLAB快了171倍,基本实现了0延时。
表 3 本文算法的MATLAB和SoC处理时间对比 Table 3 Comparison of MATLAB and SoC processing time of proposed algorithm
| 处理方式 | 处理时间/ms |
| MATLAB | 3.44 |
| SoC | 0.02 |
表选项
MATLAB和SoC处理后的灰度直方图分别如图 7(a)、(b)所示,2幅图的像素点分布基本一致,处理后图像对应位置像素点的差值绝对值最大为0.0037,最小为0。由此可见,利用SoC进行图像缩放模块的设计,不仅运行速度大大提升,处理精度也非常高。
 |
| 图 7 MATLAB和SoC处理后直方图对比 Fig. 7 Histogram contrast after MATLAB and SoC processing |
| 图选项 |
5 结论 1) 本文采用了FPGA+ARM的SoC软硬件处理平台,综合了FPGA和ARM的优点,具有并行处理的能力和分系统控制能力,应用于图像处理中能够加速算法的处理速度。
2) 针对无人机自主着陆视觉算法中的图像缩放处理,提出了一种适用于硬件加速的图像缩放算法,在处理速度上仅次于结构简单的最邻近插值法,且处理效果最优。
3) 利用硬件描述语言实现本文的缩放算法,并封装成硬件IP核,在图像处理系统中的处理速度相较于软件实现提升了171倍,且处理后的像素误差最大值为0.0037。
4) 整个系统采用了ARM作为中央控制器协调各IP核工作,具有很强的通用性,可以通过增减IP核来改进系统,适用于进一步的研究,以及图像处理IP核的设计。
参考文献
| [1] | RETTKOWSKI J, BOUTROS A, GOHRINGER D. HW/SW co-design of the HOG algorithm on a Xilinx Zynq SoC[J]. Journal of Parallel and Distributed Computing, 2017, 109(1): 50-62. |
| [2] | KRYJAK T, KOMORKIEWICZ M, GORGON M. Real-time hardware-software embedded vision system for its smart camera implemented in Zynq SoC[J]. Journal of Real-Time Image Processing, 2016, 12(4): 1-37. |
| [3] | SENOUCI B, CHARFI I, HEYRMAN B, et al. Fast prototyping of a SoC-based smart-camera:A real-time fall detection case study[J]. Journal of Real-Time Image Processing, 2016, 12(4): 649-662. DOI:10.1007/s11554-014-0456-4 |
| [4] | SVETEK A, BLAKE M, HERMIDA M C, et al. The calorimeter trigger processor card:The next generation of high speed algorithmic data processing at CMS[J]. Journal of Instrumentation, 2016, 11(2): 201-210. |
| [5] | ZARANDY A, NEMETH M, NAGY Z, et al. A real-time multi-camera vision system for UAV collision warning and navigation[J]. Journal of Real-Time Image Processing, 2016, 12(4): 709-724. DOI:10.1007/s11554-014-0449-3 |
| [6] | 刘镇弢, 李涛, 黄虎才, 等. 一种用于实时图像处理的众核结构设计[J]. 西安电子科技大学学报, 2015, 42(2): 95-101. LIU Z T, LI T, HUANG H C, et al. A design of the core structure for real-time image processing[J]. Journal of Xidian University, 2015, 42(2): 95-101. DOI:10.3969/j.issn.1001-2400.2015.02.016 (in Chinese) |
| [7] | 杨帆, 张皓, 马新文, 等. 基于FPGA的图像处理系统[J]. 华中科技大学学报(自然科学版), 2015, 43(2): 119-123. YANG F, ZHANG H, MA X W, et al. Image processing system based on FPGA[J]. Journal of Huazhong University of Science and Technology(Natural Science Edition), 2015, 43(2): 119-123. (in Chinese) |
| [8] | ZHAI X, ALI A S, AMIRA A, et al. MLP neural network based gas classification system on Zynq SoC[J]. IEEE Access, 2016, 4(2): 8138-8146. |
| [9] | HAN Y, VIRUPAKSHAPPA K, VITORSILVAPINTO E, et al. Hardware/software co-design of a traffic sign recognition system using Zynq FPGAs[J]. Electronics, 2015, 4(4): 1062-1089. DOI:10.3390/electronics4041062 |
| [10] | KELLY C, SIDDIQUI F M, BARDAK B, et al.FPGA soft-core processors, compiler and hardware optimizations validated using HOG[C]//International Symposium on Applied Reconfigurable Computing.Berlin: Springer, 2016, 1: 78-90. |
| [11] | ALTUNCU M A, GUVEN T, BECERIKLI Y, et al. Real-time system implementation for image processing with hardware/software co-design on the Xilinx Zynq platform[J]. International Journal of Information and Electronics Engineering, 2015, 5(6): 473-477. DOI:10.7763/IJIEE.2015.V5.582 |
| [12] | KRAJNIK T, SVAB J, PEDRE S, et al. FPGA-based module for SURF extraction[J]. Machine Vision and Applications, 2014, 25(3): 787-800. DOI:10.1007/s00138-014-0599-0 |
| [13] | GAO F, HUANG Z, WANG S, et al. Optimized parallel implementation of face detection based on embedded heterogeneous many-core architecture[J]. International Journal of Pattern Recognition and Artificial Intelligence, 2017, 31(7): 175-180. |
| [14] | ISHIKAWA S, TAKAHASHI T, WATANABE S, et al. High-speed X-ray imaging spectroscopy system with Zynq SoC for solar observations[J]. Nuclear Instruments and Methods in Physics Research Section A:Accelerators, Spectrometers, Detectors and Associated Equipment, 2017, 22(1): 40-52. |
| [15] | CAI W, XU Z, LI Z. A high performance surf image feature detecting system based on Zynq[J]. DEStech Transactions on Computer Science and Engineering, 2017, 11(2): 101-110. |
| [16] | 王博.数字图像缩放及其质量评价方法研究[D].哈尔滨: 哈尔滨工程大学, 2015: 97-105. WANG B.Digital image zoom and its quality evaluation method[D]. Harbin: Harbin Engineering University, 2015: 97-105(in Chinese). http://cdmd.cnki.com.cn/Article/CDMD-10217-1017245829.htm |
