成分数据分析主要研究活动对象结构变化产生的规律及其对其他对象产生的影响。关于成分数据的理论研究,标志性的成果是1986年Aichison撰写的《成分数据统计分析》[10],该书详细阐述了成分数据统计分析方法建立的数学基础。在成分数据分析中,线性回归模型是一种常用的分析技术。现有的成分数据线性回归模型可以分为两大类:第1类因变量是普通数据[11-12],第2类因变量是成分数据[13-15]。Hron等[12]利用第1类成分数据线性回归模型研究了GDP组成与预期寿命的关系;而Wang等[14]利用第2类模型研究了地区总产值与就业和投资的关系。本文在因变量是普通数据的成分数据回归模型基础上进行研究。在成分数据回归模型中,通常以样本之间独立同分布作为前提。而在实际应用中,独立同分布的假设往往是不成立的。如何对现有的成分数据线性回归模型进行改进,使之适应实际应用的需求,是一个值得深入研究的问题。
在空间计量经济学[16]中,空间自回归模型通过引入空间依赖项,打破了因变量相互独立的假设,使得许多与空间地理位置或社交网络有关的现象得到解释。利用空间自回归模型,可以对区域经济发展的问题[17-18]、溢出性问题[19-20]等进行分析。现有的空间自回归模型在普通数据的基础上已经发展得相对完善,已有的对空间自回归模型进行估计的方法包括Ord[21]和Lee[22]提出的极大似然估计法、Kelejian、Prucha[23]和Lee[24]提出的广义矩估计法、Lesage和Pace[25]从贝叶斯的角度提出的马尔可夫链蒙特卡罗方法(Markov chain Monte Carlo method)。
因此,针对经典成分数据线性回归模型假设样本间相互独立的严格要求,研究因变量之间具有空间依赖的成分数据回归模型,通过在普通数据的空间自回归模型中,引入成分数据的协变量,提出了同时含有成分数据和普通数据的空间自回归模型。并依据成分数据的特点,给出了混合2种数据的空间自回归模型的估计方法。提出的新模型比已有的成分数据线性回归模型具有更强的灵活性,可以处理更加复杂的空间依赖问题。
1 基础理论 本节主要介绍成分数据的代数空间——单形空间(simplex)中的基本运算,以及与成分数据联系紧密的几种变换,利用这些变换可以将具有约束的成分数据转化成易于处理的普通数据。
1.1 单形空间 对于含有d个成分的成分数据,对应的单形空间Sd(上标d表示成分数据有d个成分,因此实际是d-1维的)定义为
 | (1) |
式中:x为一个d维的成分数据;xi>0表示成分数据的每一个成分都是非负的;
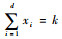
现有单形空间Sd中的任意2个成分数据x、y以及实数α,记x=(x1, x2, …, xd)T∈Sd,y=(y1, y2, …, yd)T∈Sd,α∈R,则x和y的加法⊕及α和x数乘运算⊙可分别定义为
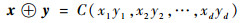 | (2) |
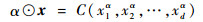 | (3) |
式中:C(·)表示闭合运算,定义为
 | (4) |
不难看出,闭合运算保证了运算结果仍在Sd中。基于运算⊕和⊙,可以导出x和y的减法运算,
 | (5) |
x和y的内积运算〈x, y〉a定义为
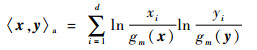 | (6) |
式中:

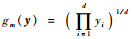
 | (7) |
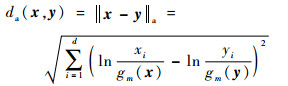 | (8) |
可以证明,含有内积运算的单形空间是一个希尔伯特空间。
1.2 等距对数比变换 需注意,因约束
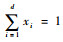
ilr变换是Egozcue等[26]提出的。该变换将d维的单形空间Sd映射到d-1维的欧几里得空间Rd-1上,得到的实数向量消除了原成分数据中不同成分之间的共线性,可以直接用于建模。该变换利用标准正交基的正交性和单位长度性质,将成分数据变换成易于处理的标准正交基的系数。设标准正交基为{ek}k=1d-1, ek=(ek1, ek2, …, ekd)T,则任意一个成分数据x都可以表示为x=〈x, e1〉a⊙e1⊕〈x, e2〉a⊙e2⊕…⊕〈x, ed-1〉a⊙ed-1,相应地,x的ilr变换坐标ilr(x)为
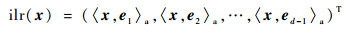 | (9) |
Egozcue等[26]证明,ilr变换是保内积的变换,即对于含有d个成分的成分数据x和y, 有
 | (10) |
下面给出具体的ilr变换过程。
已知观测到样本量n的d维成分数据{Ci}i=1n, 其中Ci=(xi1, xi2, …, xid)T,则Ci进行ilr变换后的坐标为
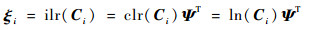 | (11) |
式中:
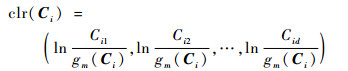 |
Ψ为(d-1)×d维的矩阵,具体表达式为
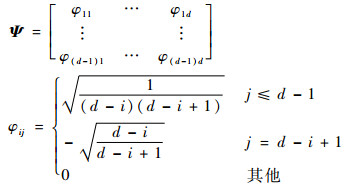 |
由于ilr变换是保内积的变换,因此在第3节的估计方法中,将使用变换后的坐标{ξi}i=1n代替原来的成分数据{Ci}i=1n进行参数估计。
2 模型的提出 借鉴Qu和Lee[27]对空间自回归模型的背景假设,考虑空间关系发生在一个非均匀分布的格子L, L?Rp, p≥1上,格子上的点相互可分,即任意2点的距离大于0。从格子L上观测到了n个对象,每个对象的观测数据为{yi, xi1, …, xid, xid+1, …, xip}i=1n。其中xij(j=1, 2, …, d)共同组成d个成分的成分数据Ci=(xi1, xi2, …, xid)T,且每个Ci是随机成分数据C的独立同分布观测;xij(j=d+1, d+2, …, p)为普通数据,它们是随机变量Xj(j=d+1, d+2, …, p)的独立同分布观测,标记Xi=(xid+1, xid+2, …, xip)T。记Y=(y1, y2, …, yn)T,C=(C1, C2, …, Cn)T,X=(X1, X2, …, Xn)T,则因变量Y符合以下回归模型:
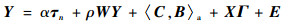 | (12) |
式中:ατn为截距项,τn为所有元素均为的1的维度为n的向量;ρ为未知的空间自相关参数,取值在区间(-1, 1)内;W={wij}n×n为外生的空间矩阵,wij为对象i与j之间的权重;B为待估的成分数据系数,具有p个成分;Γ为普通数据的待估系数;E为独立于X的误差项,服从均值为0,方差为σ2In多元正态分布,In为n×n的单位矩阵。
需强调的是,式(12)中C和回归系数B都为成分数据,〈C, B〉a为一个实数。在Aitchison内积空间中,〈C, B〉a代表X对Y解释性最强的投影方向。
当ρ=0时,式(12)退化为普通的成分数据线性模型。在这个意义上,式(12)比经典的成分数据线性模型具有更强的灵活性,可以处理更加复杂的数据关系。
3 估计方法 为估计模型式(12)中的参数α, ρ, B, Γ,首先需将相互不独立的成分数据转化为相互独立的普通数据,1.2节中已作详细介绍;其次,要解决因变量yi之间不相互独立的问题,此处采用极大似然估计法ilr变换后的模型进行估计。
同样利用1.2节中的ilr变换,可得到成分数据系数B的变换坐标b=ilr(B)。
由于B是需估计的参数,因此变换后的坐标b是未知的。记ξ=(ξ1, ξ2, …, ξn)T,则模型式(12)可写为
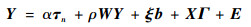 | (13) |
为描述简便,记:δ=(b, Γ)T,Z=(ξ, X),则式(13)可表示为
 | (14) |
由于模型式(12)中误差项服从多元正态分布,因变量Y的似然函数为
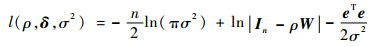 | (15) |
式中:e=Y-ατn-ρWY-Zδ。因式(15)有3个未知参数ρ、δ和σ2,直接对这3个变量求导存在一定的计算困难。现假若已得到ρ的估计值
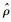
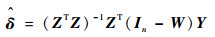 | (16) |
 | (17) |
考虑将似然函数式(15)中的变量δ和σ2分别用估计量

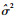
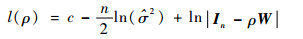 | (18) |
式中:c为一个常数。利用牛顿法等数值解法,可以得到的ρ的估计值
由于得到
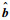
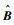
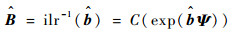 | (19) |
至此,所有参数都可以估计出来。
4 数值模拟 为评估所提出估计方法的统计性质,下面设计了几组数值模拟实验检验估计量的表现。所有的计算过程都是在R软件中实现,用到的包有“spdep”和“compositions”。
关于空间自回归模型的空间网络结构,采取最常见的“车”相邻(rook matrix)。假设n个样本点随机地散落在一个R行T列的格子棋盘上,每个样本点占据棋盘上的一个方格,那么在棋盘上共享一条边的2个样本点就是相邻的。在这样的情况下,处在棋盘中间的任意样本点都有4个邻居,处在棋盘边上的样本点有3个邻居,而处在棋盘角上的样本点只有1个邻居。分别设置R=10,20,30,T=30,25,30,相应地样本量n=R×T=300, 500, 900。为了查看空间依赖的强弱是否对估计量有影响,同样设计了3组不同的ρ值,ρ=0,0.5,0.8。
关于混合数据的空间自回归模型,由于截距项不是主要关注的参数,此处设α=0,其他参数设置如下:Y=ρWY+〈B, C〉a+ΓX+0.8E;C~Ns(μ,Σ); X~N(1,0.8);E~N(0, In); μ=(0.49,0.61)T; Σ=

在每一种情形下,重复实验次数k=100。对于参数ρ和Γ,用样本均值偏离真值的大小和样本标准差衡量估计量的表现。对于成分数据系数,用成分数据均值B与真值的偏差以及成分数据的总方差totvar(X)衡量估计结果的优劣。其中,样本均值的计算公式为
 | (20) |
样本的总方差的计算公式为
 | (21) |
其中:

估计结果如图 1~图 3所示。可以得到如下结论:
 |
图 1 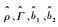  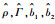 |
| 图选项 |
 |
图 2 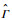 |
| 图选项 |
 |
| 图 3 n和ρ取不同值时, |
| 图选项 |
1)
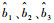
2)
3) 当样本量大小相同时,
5 结论 针对普通成分数据线性回归模型要求样本间相互独立的局限性,在空间自回归模型的基础上,提出了混合成分数据与普通数据的空间自回归模型,所提出的模型及估计方法具有如下优点:
1) 新提出的模型不仅能够同时处理成分数据和普通数据,还能表达数据中因变量之间相互依赖的问题。特别地,新模型可以处理地理空间中的依赖性。
2) 新模型所提出的估计量具有相合性。随着样本量的增大,可以发现估计值的标准差在逐渐减小。除此之外,新提出的估计方法操作简单,可以在R软件上直接实现。
在实际应用中,新模型可处理社交网络、地理空间等含有网络结构的依赖问题。而针对其他情况造成成分数据线性模型样本之间不相互独立的问题,则需要分情况进行深入分析。
参考文献
| [1] | RAMSAY J O, SILVERMAN B W. Functional data analysis[M]. Berlin: Springer, 1997. |
| [2] | RAMSAY J O, SILVERMAN B W. Applied functional data analysis:Methods and case studies[M]. Berlin: Springer, 2002. |
| [3] | VIEU P, FERRATY F. Nonparametric functional data analysis[M]. Berlin: Springer, 2006. |
| [4] | PAWLOWSKY-GLAHN V, BUCCIANTI A. Compositional data analysis:Theory and applications[M]. Chichester: Wiley-Blackwell, 2011. |
| [5] | BILLARD L, DIDAY E.Symbolic regression analysis[M]//JAJUGA K, SOKOLOWSKI A, BOCK H.Classification, clustering, and data analysis.Berlin: Springer, 2002: 281-288. |
| [6] | BILLARD L, DIDAY E. Regression analysis for interval-valued data[M]. Berlin: Springer, 2000: 369-374. |
| [7] | FRY J M, FRY T R L, MCLAREN K R. Compositional data analysis and zeros in micro data[J]. Applied Economics, 2000, 32(8): 953-959. DOI:10.1080/000368400322002 |
| [8] | PAWLOWSKY-GLAHN V, EGOZCUE J J. Exploring compositional data with the CoDa-dendrogram[J]. Austrian Journal of Statistics, 2011, 40(1 & 2): 103-113. |
| [9] | PAWLOWSKY-GLAHN V, EGOZCUE J J, TOLOSANA-DELGADO R. Modelling and analysis of compositional data[J]. Hoboken:John Wiley & Sons, Ltd., 2015, 152-154. |
| [10] | AITCHISON J. The statistical analysis of compositional data[M]. Berlin: Springer, 1986. |
| [11] | AITCHISON J. The statistical analysis of compositional data[J]. Journal of the Royal Statistical Society Series B, 1982, 44(2): 139-177. |
| [12] | HRON K, FILZMOSER P, THOMPSON K. Linear regression with compositional explanatory variables[J]. Journal of Applied Statistics, 2012, 39(5): 1115-1128. DOI:10.1080/02664763.2011.644268 |
| [13] | ATCHISON J, SHEN S M. Logistic-normal distributions:Some properties and uses[J]. Biometrika, 1980, 67(2): 261-272. |
| [14] | WANG H, SHANGGUAN L, WU J, et al. Multiple linear regression modeling for compositional data[J]. Neurocomputing, 2013, 122: 490-500. DOI:10.1016/j.neucom.2013.05.025 |
| [15] | TOLOSANA-DELGADO R, EYNATTEN H V. Simplifying compositional multiple regression:Application to grain size controls on sediment geochemistry[J]. Computers & Geosciences, 2010, 36(5): 577-589. |
| [16] | ANSELIN L. Spatial econometrics:Methods and models[M]. Berlin: Springer, 1988. |
| [17] | 林光平, 龙志和, 吴梅. 中国地区经济σ-收敛的空间计量实证分析[J]. 数量经济技术经济研究, 2006, 23(4): 14-21. LIN G P, LONG Z H, WU M. A spatial investigation of σ-convergence in China[J]. The Journal of Quantitative & Technical Economics, 2006, 23(4): 14-21. DOI:10.3969/j.issn.1000-3894.2006.04.002 (in Chinese) |
| [18] | 郭金龙, 王宏伟. 中国区域间资本流动与区域经济差距研究[J]. 管理世界, 2003(7): 45-58. GUO J L, WANG H W. Study on the regional capital flows and regional economic differences in China[J]. Management World, 2003(7): 45-58. (in Chinese) |
| [19] | TOPA G. Social interactions, local spillovers and unemployment[J]. Review of Economic Studies, 2010, 68(2): 261-295. |
| [20] | BAICKER K. The spillover effects of state spending[J]. Journal of Public Economics, 2005, 89(2-3): 529-544. DOI:10.1016/j.jpubeco.2003.11.003 |
| [21] | ORD H. Estimation methods for models of spatial interaction[J]. Publications of the American Statistical Association, 1975, 70(349): 120-126. DOI:10.1080/01621459.1975.10480272 |
| [22] | LEE L F. Asymptotic distributions of quasi-maximum likelihood estimators for spatial autoregressive models[J]. Econometrica, 2004, 72(6): 1899-1925. DOI:10.1111/ecta.2004.72.issue-6 |
| [23] | KELEJIAN H, PRUCHA I R. A generalized moments estimator for the autoregressive parameter in a spatial model[J]. International Economic Review, 1999, 40(2): 509-533. DOI:10.1111/iere.1999.40.issue-2 |
| [24] | LEE L F. GMM and 2SLS estimation of mixed regressive, spatial autoregressive models[J]. Journal of Econometrics, 2007, 137(2): 489-514. DOI:10.1016/j.jeconom.2005.10.004 |
| [25] | LESAGE J P, PACE R K. Introduction to spatial econometrics[M]. New York: CRC Press, 2009: 513-514. |
| [26] | EGOZCUE J J, PAWLOWSKYGLAHN V, MATEUFIGUERAS G, et al. Isometric logratio transformations for compositional data analysis[J]. Mathematical Geology, 2003, 35(3): 279-300. DOI:10.1023/A:1023818214614 |
| [27] | QU X, LEE L F. Estimating a spatial autoregressive model with an endogenous spatial weight matrix[J]. Journal of Econometrics, 2015, 184(2): 209-232. DOI:10.1016/j.jeconom.2014.08.008 |
