Fund Project:Project supported by the National Natural Science Foundation of China (Grant No. 1217050658)
Received Date:14 April 2021
Accepted Date:27 June 2021
Available Online:09 September 2021
Published Online:05 December 2021
Abstract:Studying quantum phase transitions through order parameters is a traditional method, but studying phase transitions by machine learning is a brand new field. The ability of machine learning to classify, identify, or interpret massive data sets may provide physicists with similar analyses of the exponentially large data sets embodied in the Hilbert space of quantum many-body system. In this work, we propose a method of using unsupervised learning algorithm of the Gaussian mixture model to classify the state vectors of the J1-J2 antiferromagnetic Heisenberg spin chain system, then the supervised learning algorithm of the convolutional neural network is used to identify the classification point given by the unsupervised learning algorithm, and the cross-validation method is adopted to verify the learning effect. Using this method, we study the J1-J2 Heisenberg spin chain system with chain length N = 8, 10, 12, 16 and obtain the same conclusion. The first order phase transition point of J1-J2 antiferromagnetic Heisenberg spin chain system can be accurately found from the ground state vector, but the infinite order phase transition point cannot be found from the ground state vector. The first order and the infinite order phase transition point can be found from the first excited state vector, which indirectly shows that the first excited state may contain more information than the ground state of J1-J2 antiferromagnetic Heisenberg spin chain system. The visualization of the state vector shows the reliability of the machine learning algorithm, which can extract the feature information from the state vector. The result reveals that the machine learning techniques can directly find some possible phase transition points from a large set of state vectorwithout prior knowledge of the energy or locality conditions of the Hamiltonian, which may assists us in studying unknown systems. Supervised learning can verify the phase transition points given by unsupervised learning, thereby indicating that we can discover some useful information about unknown systems only through machine learning techniques. Machine learning techniques can be a basic research tool in strong quantum-correlated systems, and it can be adapted to more complex systems, which can help us dig up hidden information. Keywords:Heisenberg J1-J2 model/ machine learning/ neural network/ phase transition
使用J2/J1$\in $[0, 1)(链长N = 16的取J2/J1$\in $[0, 0.53), 因为取J2/J1$\in $[0, 1)会优先识别随系统尺寸变化而改变的相变点J2/J1 = 0.534)的海森伯J1-J2模型基态态矢量作为训练集, 生成n为2的GMM, 再用该模型对海森伯J1-J2模型基态态矢量分类, 得到如图2(a)所示的分类结果, 可以看出J2/J1 = 0.5是它的一个分类点, 其不随系统尺寸变化而改变. 图 2 (a) 训练数据为J2/J1$\in $[0, 1)的海森伯J1-J2模型基态矢量生成的GMM对基态矢量的分类结果; (b)采用标记为0的J2/J1$\in $[0.35, 0.45)和为1的J2/J1$\in $[0.55, 0.65); (c)标记为0的J2/J1$\in $[0.3, 0.4)和为1的J2/J1$\in $[0.55, 0.65); (d)标记为0的J2/J1$\in $[0.2, 0.3)和为1的J2/J1$\in $[0.55, 0.65)的基态态矢量作为训练数据, 训练所得的CNN模型对基态态矢量的预测结果 Figure2. (a) Ground state vector classification results of the GMM generated by the Heisenberg J1-J2 model ground state vector with the training data of J2/J1$\in $ [0, 1); (b) using the ground state vector of J2/J1$\in $[0.35, 0.45) marked as 0 and J2/J1$\in $[0.55, 0.65) marked as 1; (c) J2/J1$\in $[0.3, 0.4) marked as 0 and J2/J1$\in $[0.55, 0.65) marked as 1; (d) J2/J1$\in $[0.2, 0.3) marked as 0 and J2/J1$\in $[0.55, 0.65) marked as 1 as training data, the prediction results of the ground state vector by the trained convolutional neural network model.
接下来采用稍微远离J2/J1 = 0.5的数据集作为训练集和验证集, 对该点是否是相变点进一步验证. 我们采用标记分别为0(采用one-hot编码)的J2/J1$\in $[0.35, 0.45)和为1的J2/J1$\in $[0.55, 0.65)的基态态矢量作为训练数据和验证数据(链长N = 16的取J2/J1$\in $[0.51, 0.61), 因为取J2/J1$\in $[0.55, 0.65)会识别随系统尺寸变化而改变的J2/J1 = 0.534相变点), 训练CNN模型. 之后使用该模型对海森伯J1-J2模型基态态矢量进行预测, 预测结果如图2(b)所示, 发现神经元输出在J2/J1 = 0.5 处发生跳变, 接下来采用标记分别为0的J2/J1$\in $[0.3, 0.4)和为1的J2/J1$\in $[0.55, 0.65)的基态态矢量和标记分别为0的J2/J1$\in $[0.2, 0.3)和为1的J2/J1$\in $[0.55, 0.65)的基态态矢量作为训练数据, 分别训练两个CNN模型, 再用模型对基态态矢量进行预测, 预测结果如图2(c)和图2(d)所示, 发现前后使用不同训练数据集训练的CNN对测试数据集的预测结果几乎没有发生变化, 因此, 基本就能确定J2/J1 = 0.5为该系统相变点. 这样就在没有任何先验知识, 不知道系统哈密顿量, 能量的条件下从基态态矢量中直接找到了J1-J2海森伯自旋链系统的一阶相变点. 同样使用J2/J1$\in $[0, 0.5)的海森伯J1-J2模型基态态矢量作为训练集(GMM模型给出的不同链长的分类点不尽相同, 但其结果基本一样, 所以仅以链长N = 10的态矢量的分类结果为例进行讨论), 生成n = 2的GMM, 再用该模型对海森伯J1-J2模型基态态矢量分类, 得到如图3(a)所示的分类结果, 其在J2/J1 = 0.305处出现分类点. 然后, 分别采用标记分别为0的J2/J1$\in $[0.25, 0.3)和为1的J2/J1$\in $[0.35, 0.4)的基态态矢量作为训练数据, 采用标记分别为0的J2/J1$\in $[0.2, 0.25)和为1的J2/J1$\in $[0.35, 0.4)的基态态矢量作为训练数据, 和采用标记分别为0的J2/J1$\in $[0.2, 0.25)和为1的J2/J1$\in $[0.35, 0.4)的基态态矢量作为训练数据(标记为1的数据是标记为0数据的5倍), 分别训练3个CNN模型, 之后使用模型对系统基态的态矢量进行预测, 预测结果如图3(b)—(d)所示. 可以看出, CNN给出的分类点随训练数据集数据的变化而发生改变, 不能给出确定的相变点, 因此不能通过该方法从基态态矢量中找到无穷阶相变点, 但能够有效排除无监督学习给出的假的相变点. 图 3 (a) 训练数据为J2/J1$\in $[0, 0.5)的海森伯J1-J2模型基态态矢量生成的GMM对基态态矢量的分类结果; (b) 分别为采用标记为0的J2/J1$\in $[0.25, 0.3)和为1的J2/J1$\in $[0.35, 0.4); (c)标记为0的J2/J1$\in $[0.2, 0.25)和为1的J2/J1$\in $[0.35, 0.4); (d)标记为0的J2/J1$\in $[0.2, 0.25)和为1的J2/J1$\in $[0.35, 0.4)(标记为1的数据是标记为0的5倍)的基态态矢量作为训练数据, 训练所得的CNN模型对基态态矢量的预测结果 Figure3. (a) Ground state vector classification results of the GMM generated by the Heisenberg J1-J2 model ground state vector with the training data of J2/J1$\in $ [0, 0.5); (b) respectively usingthe ground state vector of J2/J1$\in $[0.25, 0.3) marked as 0 and J2/J1$\in $[0.35, 0.4) marked as 1; (c) J2/J1$\in $[0.2, 0.25) marked as 0 and J2/J1$\in $[0.35, 0.4) marked as 1; (d) J2/J1$\in $[0.2, 0.25) marked as 0 and J2/J1$\in $[0.35, 0.4) marked as 1 (the data marked as 1 is 5 times as much as the data marked as 0)as training data, the prediction results of the ground state vector by the trained convolutional neural network model.
24.2.从第一激发态寻找相变点 -->
4.2.从第一激发态寻找相变点
同样, 使用J2/J1$\in $[0, 1)的海森伯J1-J2模型第一激发态态矢量作为训练集, 生成n为2的GMM, 再用该模型对海森伯J1-J2模型第一激发态态矢量分类, 得到如图4(a)所示的分类结果, 可以观察到J2/J1 = 0.24和J2/J1 = 0.5可能是它的相变点. 接下来, 采用稍微远离J2/J1 = 0.5数据集作为训练集和验证集, 对该点是否是相变点进一步验证. 采用标记分别为0的J2/J1$\in $[0.35, 0.45)和为1的J2/J1$\in $[0.55, 0.65)的第一激发态态矢量作为训练数据, 采用标记分别为0的J2/J1$\in $[0.3, 0.4)和为1的J2/J1$\in $[0.55, 0.65)的第一激发态态矢量作为训练数据, 和采用标记分别为0的J2/J1$\in $[0.35, 0.45)和为1的J2/J1$\in $[0.55, 0.65)的第一激发态态矢量作为训练数据(标记为0的数据是标记为1数据的5倍), 分别训练CNN模型, 训练得到的3个CNN模型预测结果如图4(b)—(d)所示, 发现训练好的CNN可以从测试数据中精确找到一阶相变点, 且其对测试数据集的预测结果几乎没有发生变化, 由此, 也可以通过第一激发态态矢量数据, 在没有任何先验知识, 不知道系统哈密顿量, 能量的条件下, 确定J2/J1 = 0.5为J1-J2海森伯自旋链系统相变点. 图 4 (a) 训练数据为J2/J1$\in $[0, 1)的海森伯J1-J2模型第一激发态态矢量生成的GMM对第一激发态态矢量的分类结果; (b)分别为采用标记为0的J2/J1$\in $[0.35, 0.45)和为1的J2/J1$\in $[0.55, 0.65); (c)标记为0的J2/J1$\in $[0.3, 0.4)和为1的J2/J1$\in $[0.55, 0.65); (d)标记为0的J2/J1$\in $[0.35, 0.45)和为1的J2/J1$\in $[0.55, 0.65) (标记为1的数据是标记为0的5倍)的第一激发态态矢量作为训练数据, 训练所得的CNN模型对第一激发态态矢量的预测结果 Figure4. (a) The first excited state vector classification results of the GMM generated by the Heisenberg J1-J2 model first excited state vector with the training data of J2/J1$\in $ [0, 1); (b) using the first excited state vector of J2/J1$\in $[0.35, 0.45) marked as 0 and J2/J1$\in $[0.55, 0.65) marked as 1; (c) J2/J1$\in $[0.3, 0.4) marked as 0 and J2/J1$\in $[0.55, 0.65) marked as 1; (d) J2/J1$\in $[0.35, 0.45) marked as 0 and J2/J1$\in $[0.55, 0.65) marked as 1 (the data marked as 1 is 5 times as much as the data marked as 0)as training data, the prediction results of the first excited state vector by the trained convolutional neural network model.
同样, 采用稍微远离J2/J1 = 0.24数据集作为训练集和验证集, 对该点是否是相变点进一步验证. 采用标记分别为0的J2/J1$\in $[0.1, 0.2)和为1的J2/J1$\in $[0.3, 0.4)的第一激发态态矢量作为训练数据, 训练CNN模型, 再用训练好的CNN模型对海森伯J1-J2模型第一激发态态矢量的类别进行预测, 预测结果如图5(a)所示, 我们发现训练好的CNN可以从测试数据中精确找到无穷阶相变点, 接着我们又采用标记分别为0(的J2/J1$\in $[0, 0.1)和为1的J2/J1$\in $[0.3, 0.4)的第一激发态态矢量作为训练数据, 训练CNN模型. 再用训练好的CNN模型对海森伯J1-J2模型第一激发态态矢量的类别进行预测, 预测结果如图5(b)所示, 发现训练好的CNN对测试数据集的预测结果几乎没有发生任何变化. 由此基本就能确定J2/J1 = 0.24为J1-J2海森伯自旋链系统相变点. 这样就在没有任何先验知识, 不知道系统哈密顿量, 能量的条件下从第一激发态态矢量中找到了该系统无穷阶相变点. 图 5 (a)采用标记为0的J2/J1$\in $[0.1, 0.2), 标记为1的J2/J1$\in $[0.3, 0.4); (b)标记为0的J2/J1$\in $[0, 0.1), 标记为1的J2/J1$\in $[0.3, 0.4)的第一激发态态矢量作为训练数据, 训练所得的CNN模型对第一激发态态矢量的预测结果 Figure5. (a) Using the first excited state vector of J2/J1$\in $[0.1, 0.2) marked as 0 and J2/J1$\in $[0.3, 0.4) marked as 1; (b)J2/J1$\in $[0, 0.1) marked as 0 and J2/J1$\in $[0.3, 0.4) marked as 1 as training data, the prediction results of the first excited state vector by the trained convolutional neural network model.
使用J2/J1$\in $[0, 0.24)的海森伯J1-J2模型第一激发态态矢量作为训练集(GMM模型给出的不同链长的分类点不尽相同, 但其结果基本一样, 所以仅讨论链长N = 10的态矢量的分类结果), 生成n为2的GMM, 再用该模型对海森伯J1-J2模型第一激发态态矢量分类, 得到如图6(a)所示的分类结果, 可以观察到J2/J1 = 0.125可能是该模型的相变点. 采用标记分别为0的J2/J1$\in $[0.05, 0.1)和1的J2/J1$\in $[0.15, 0.2)的第一激发态态矢量作为训练数据, 采用标记分别为0的J2/J1$\in $[0, 0.05)和1的J2/J1$\in $[0.15, 0.2)的第一激发态态矢量作为训练数据, 分别训练CNN模型, 训练得到的两个CNN模型对测试集的预测结果如图6(b), 图6(c)所示, 我们观察得到CNN模型的预测结果在J2/J1$\in $[0, 0.24)区域内未出现明显的间断点, 且预测结果随训练数据集的变化发生改变, 因此J2/J1 = 0.125不是该模型的相变点. 说明监督学习能够有效排除无监督学习模型提供的假相变点, 有效提高仅通过机器学习找系统相变点的准确率. 图 6 (a) 训练数据为J2/J1$\in $[0, 0.24)的海森伯J1-J2模型第一激发态态矢量生成的GMM对第一激发态态矢量的分类结果; (b), (c)分别为采用标记为0的J2/J1$\in $[0.05, 0.1)和为1的J2/J1$\in $[0.15, 0.2); 标记为0的J2/J1$\in $[0, 0.05)和为1的J2/J1$\in $[0.15, 0.2)的第一激发态态矢量作为训练数据, 训练所得的CNN模型对第一激发态态矢量的预测结果; (d) 训练数据为J2/J1$\in $[0.25, 0.5)的海森伯J1-J2模型第一激发态态矢量生成的GMM对第一激发态态矢量的分类结果 Figure6. (a) The first excited state vector classification results of the GMM generated by the Heisenberg J1-J2 model first excited state vector with the training data of J2/J1$\in $ [0, 0.24); (b) (c) respectively using the first excited state vector of J2/J1$\in $[0.05, 0.1) marked as 0 and J2/J1$\in $[0.15, 0.2) marked as 1; J2/J1$\in $[0, 0.05) marked as 0 and J2/J1$\in $[0.15, 0.2) marked as 1 as training data, the prediction results of the first excited state vector by the trained convolutional neural network model; (d) he first excited state vector classification results of the GMM generated by the Heisenberg J1-J2 model first excited state vector with the training data of J2/J1$\in $[0.25, 0.5).


 图 1 不同链长的 J1-J2海森伯自旋链系统基态与第一激发态能量随J2/J1的变化 (a) N = 8; (b) N = 10; (c) N = 12; (d) N = 16
图 1 不同链长的 J1-J2海森伯自旋链系统基态与第一激发态能量随J2/J1的变化 (a) N = 8; (b) N = 10; (c) N = 12; (d) N = 16



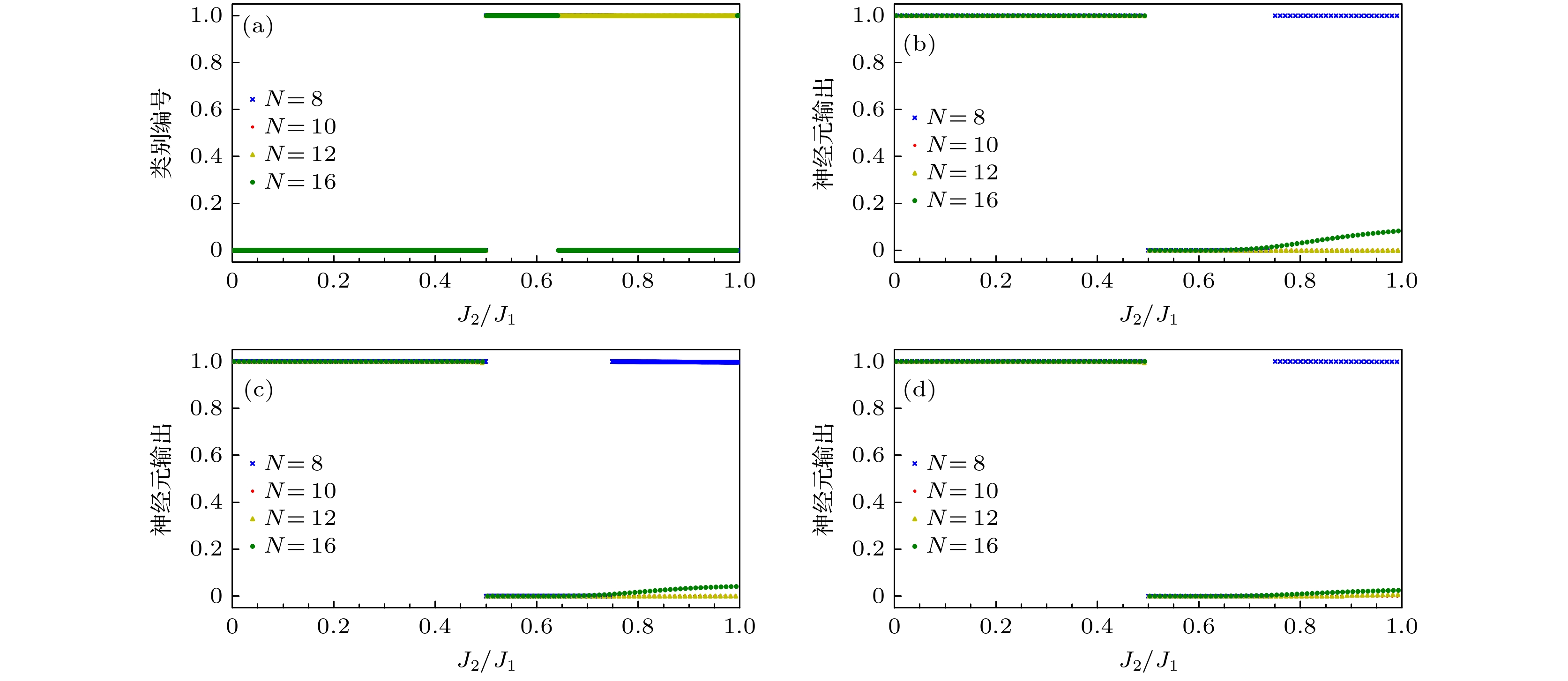 图 2 (a) 训练数据为J2/J1
图 2 (a) 训练数据为J2/J1




























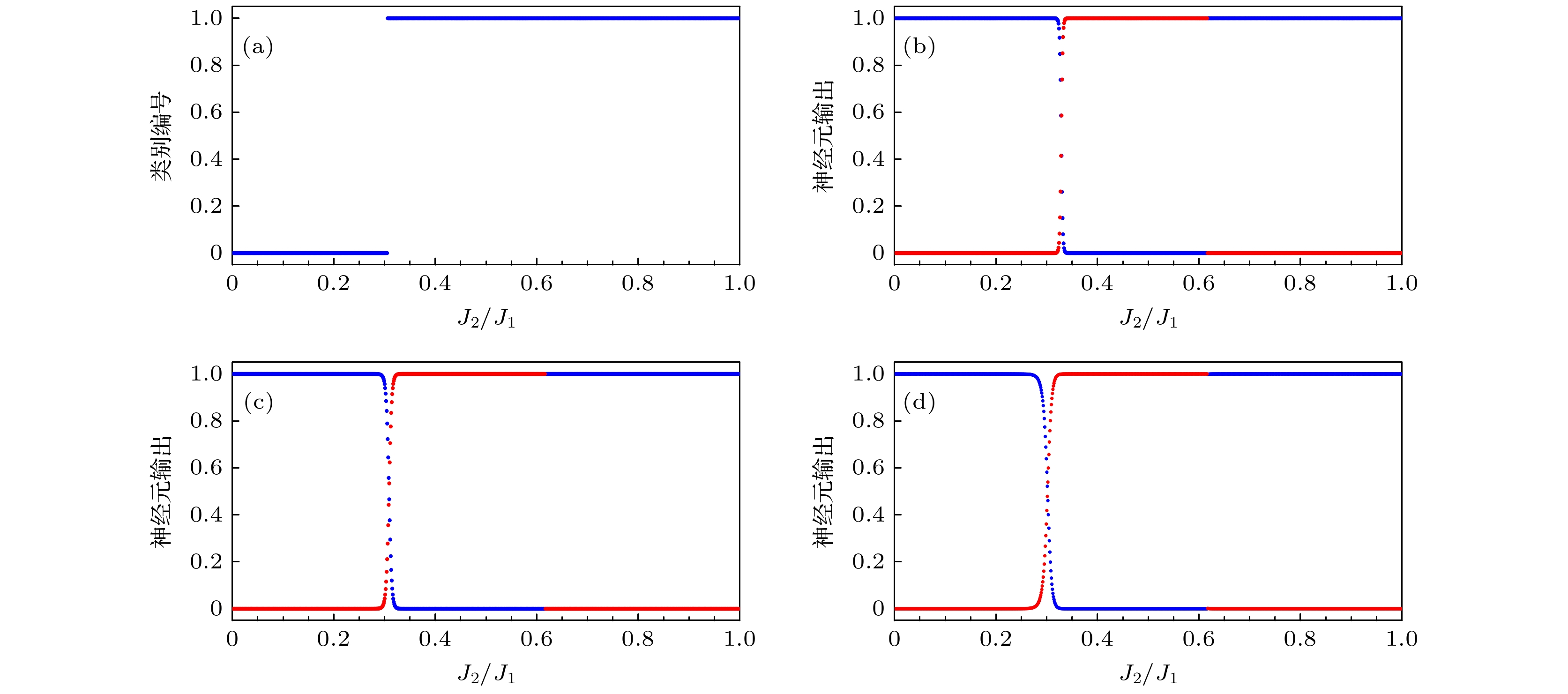 图 3 (a) 训练数据为J2/J1
图 3 (a) 训练数据为J2/J1




















 图 4 (a) 训练数据为J2/J1
图 4 (a) 训练数据为J2/J1

















 图 5 (a)采用标记为0的J2/J1
图 5 (a)采用标记为0的J2/J1













 图 6 (a) 训练数据为J2/J1
图 6 (a) 训练数据为J2/J1













 图 7 海森伯 J1-J2模型基态态矢量变换而来的灰度图 (a) J2/J1 = 0.44; (b) J2/J1 = 0.49; (c) J2/J1 = 0.51; (d) J2/J1 = 0.58
图 7 海森伯 J1-J2模型基态态矢量变换而来的灰度图 (a) J2/J1 = 0.44; (b) J2/J1 = 0.49; (c) J2/J1 = 0.51; (d) J2/J1 = 0.58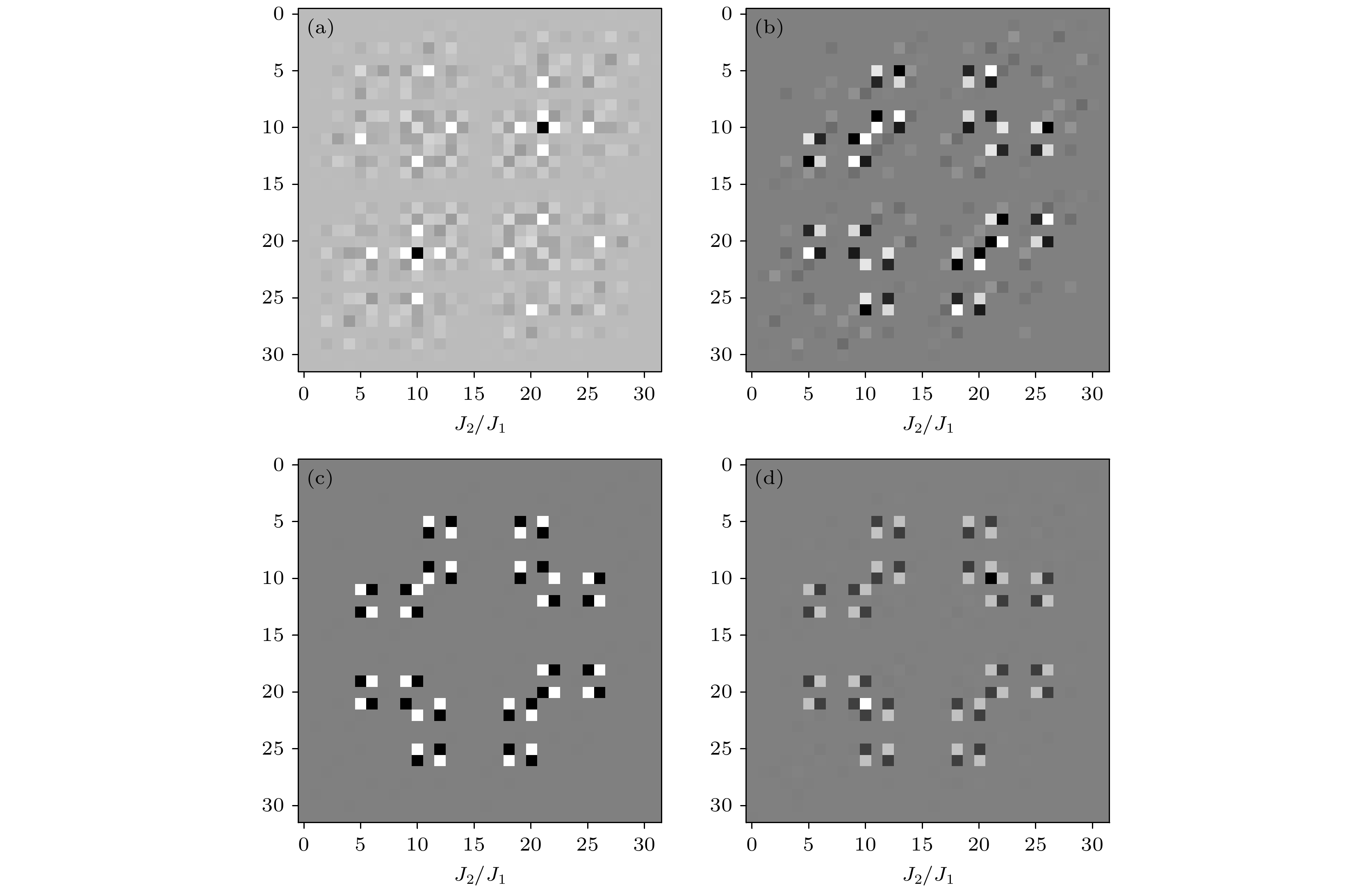 图 8 海森伯J1-J2模型第一激发态态矢量变换而来的灰度图 (a) J2/J1 = 0.24; (b) J2/J1 = 0.25; (c) J2/J1 = 0.49; (d) J2/J1 = 0.51
图 8 海森伯J1-J2模型第一激发态态矢量变换而来的灰度图 (a) J2/J1 = 0.24; (b) J2/J1 = 0.25; (c) J2/J1 = 0.49; (d) J2/J1 = 0.51