1.College of Physics and Information Engineering, Fuzhou University, Fuzhou 350116, China 2.Fujian Province Key Laboratory of Ship and Ocean Engineering, Marine Engineering College, Jimei University, Xiamen 361021, China 3.Research & Development Institute of Northwestern Polytechnical University in Shenzhen, Shenzhen 518057, China 4.School of Electronics and Information, Northwestern Polytechnical University, Xi’an 710072, China
Fund Project:Project supported by the National Natural Science Foundation of China (Grant No. 61704139), the Fund of Fujian Province Key Laboratory of Ship and Ocean Engineering, China, and the Fundamental Research Funds for the Science, Technology and Innovation Commission of Shenzhen Municipality, China (Grant No. JCYJ20180306171040865).
Received Date:18 January 2021
Accepted Date:18 February 2021
Available Online:20 August 2021
Published Online:05 September 2021
Abstract:Memristive networks are large-scale non-linear circuits based on memristor cells, playing a crucial role in developing the emerging researches such as next-generation artificial intelligence, bioelectronics, and high-performance memory. The performance of memristive networks is greatly affected by the memristor model describing physical and electrical characteristics of a memristor cell. However, existing models are mainly non-analytic and, accordingly, may have convergence issues in their applications in memristive networks’ analyses. Therefore, aiming at improving convergence of memristive networks, we propose an analytic modeling strategy for memristor based on homotopy analysis method (HAM). In this strategy, the HAM is used to obtain an analytic memristor model through solving the state equations of memristors in original physical model. Specifically, the HAM is used to solve the analytic approximate solution of the core parameter of memristor—state variable, from the state equations, in the form of analytic homotopy series. Then the analytic approximate model of memristor is obtained by using the solved state variables. The characteristics of the proposed strategy are as follows. 1) Its solution has a closed-form expression, i.e. an explicit function, 2) its approximation error is optimized, thereby realizing the convergence optimization. Moreover, according to the characteristics of memristive networks, we introduce an analysis criterion for memristor model applicable to memristive networks. Through the long-time evolution experiments of a memristor cell and a benchmark memristive matrix network with different inputs, and the comparisons with the traditional non-analytic (numeric) method, we verify the analyticity and convergence superiority of the modeling strategy. Besides, based on this strategy and the comparison experiments, we reveal that one of the underlying reasons for non-convergence in the large-scale memristive network simulation possesses the non-analyticity of the used memristor model. The strategy can be further used for analyzing the performances of a memristor cell and memristive networks in long-time. It also has potential applications in emerging technologies. Keywords:memristor/ memristive networks/ homotopy analysis method (HAM)/ analytic modeling strategy
4.验 证为验证所提HAM建模策略在大规模忆阻网络中的适用性, 以及与传统非解析建模方法相比具有的解析性和收敛性优势, 利用第3节所求的HAM模型, 分别进行忆阻器单元和忆阻矩阵网络的长时演化实验. 具体而言, 采用配置为Intel Xeon? E7-8870 CPU (2.4 GHz), 32 GB DRAM (DDR4-2666 MHz)的工作站、以及Hspice?[33] EDA工具, 分别进行了长时动态演化(图1、图2—图4)和演化时间统计(图5)的仿真, 并将实验结果与传统非解析数值模型进行了比较(图1和图5)和分析. 图 2$ M\times N $忆阻矩阵网络. 电流或电压信号可作用于网络的“in”输入端 Figure2. A $ M\times N $ memristive matrix network. The current or voltage is inputted into the “in” terminal of the network.
图 3 250 $ {\text{μ}}$A DC电流Iin输入下, 忆阻矩阵网络中“in”输入端电压Vin的瞬态长时演化 $ M=50 $, $ N=30 $. 除采用Biolek窗函数[30]($ P=2 $)、初始忆阻值${R}_{0}=16.6\;{\rm k}{ \Omega }$, $ \delta =1000 $之外, 其余仿真参数均与图1相同 Figure3. Transient long-time evolution of the “in” terminal voltage (Vin) of the matrix network under a 250 ${\text{μ}}$A DC current input (Iin). $ M=50 $, $ N=30 $, and the simulation parameters are the same as those in Fig. 1 except the Biolek window[30] ($ P=2 $), initial memristance $ {R}_{0}=1 $6.6 kΩ, and $ \delta =1000 $ are used.
图 4 输入幅度为1 mA、频率为1 Hz的AC(正弦)电流时所对应的忆阻矩阵瞬态长时演化 (a) 忆阻矩阵网络中“in”输入端电压Vin; (b) 相应的I-V曲线(重叠压缩迟滞环). 各仿真参数均与图3相同 Figure4. Transient long-time evolutions of memristive matrix network under a 1 mA, 1 Hz AC (Sinusoidal) current input: (a) “in” voltage Vin; (b) corresponding I-V curves (compressed hysteresis loops). The simulation parameters are the same as those in Fig. 3.
图 5 分别采用HAM和传统非解析[37](数值积分)模型进行忆阻矩阵仿真, 随着忆阻器单元数目的增加, 仿真时间的对比 (a)和(b)分别表示DC和AC (正弦)电流输入下的仿真时间. 此对比分析基于图3(DC)和图4(AC)所示Vin的动态演化 Figure5. Comparisons of running time between simulations using the HAM and the traditional non-analytic (numeric integration)[35] and models with increasing memristor cells: (a) and (b) show the time under the DC and AC (Sinusoidal) current inputs, respectively. The comparisons are adopted to analyze the dynamic evolutions Vin as shown in Figs. 3 (DC) and 4 (AC).


























































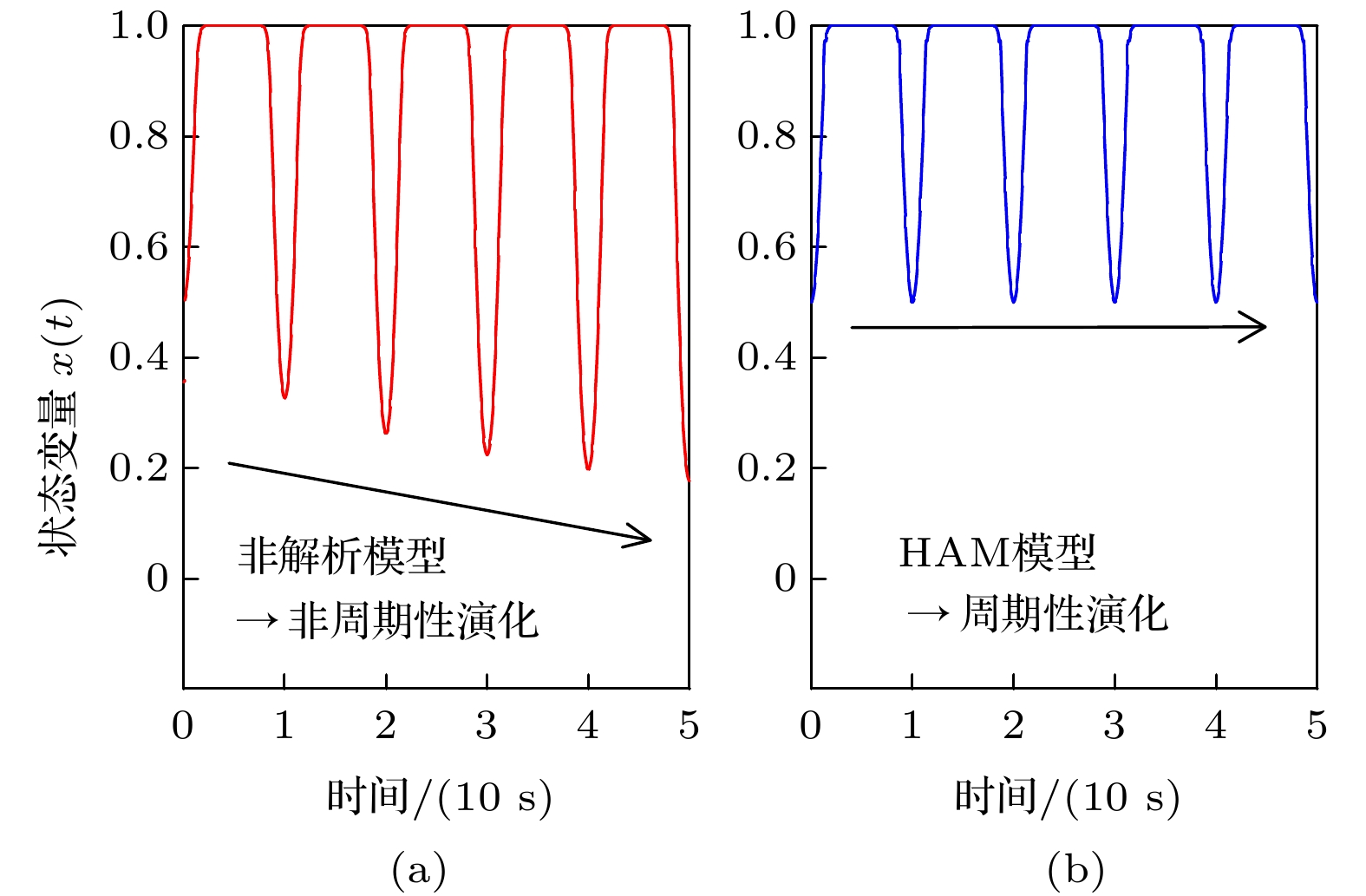 图 1 输入电流
图 1 输入电流


























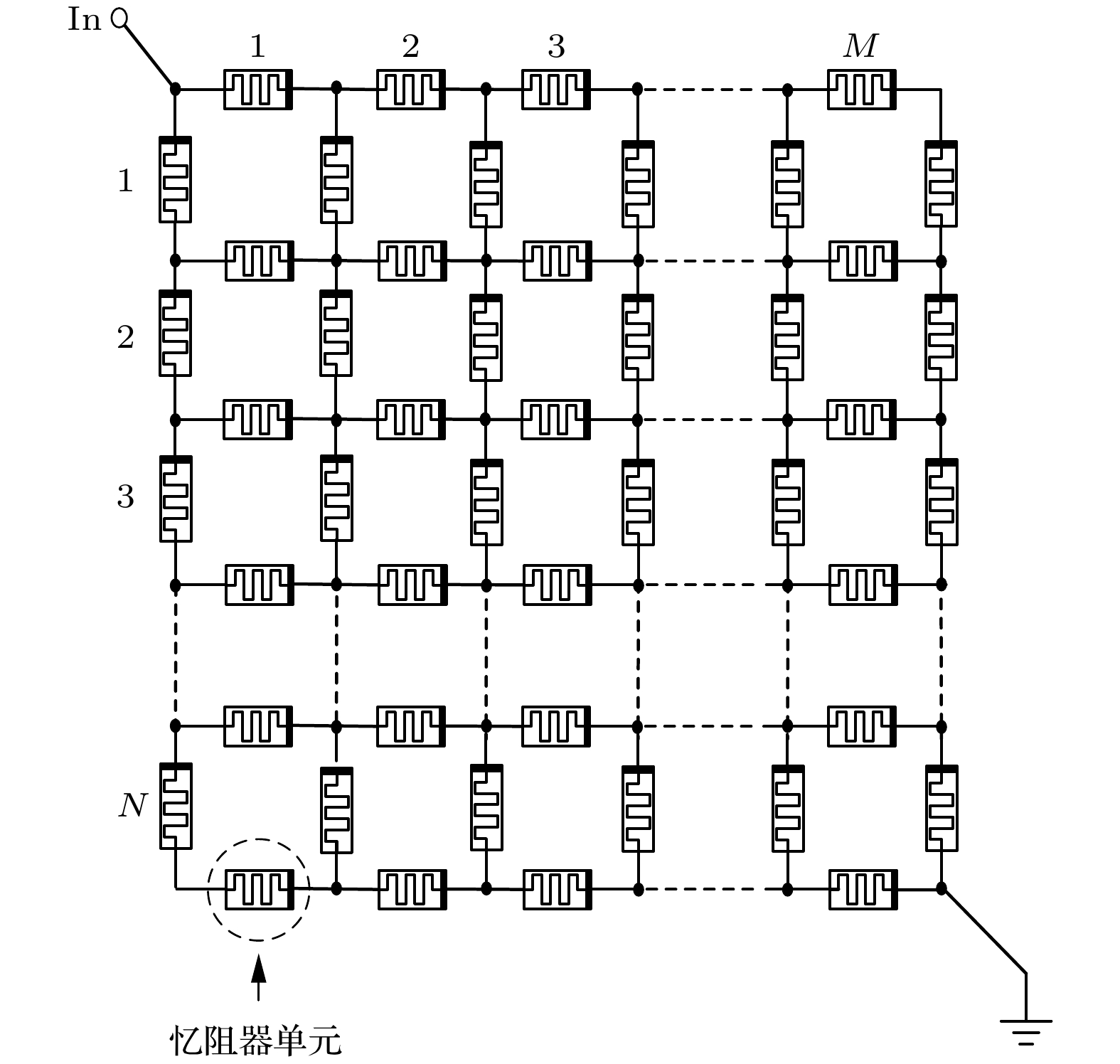 图 2
图 2 

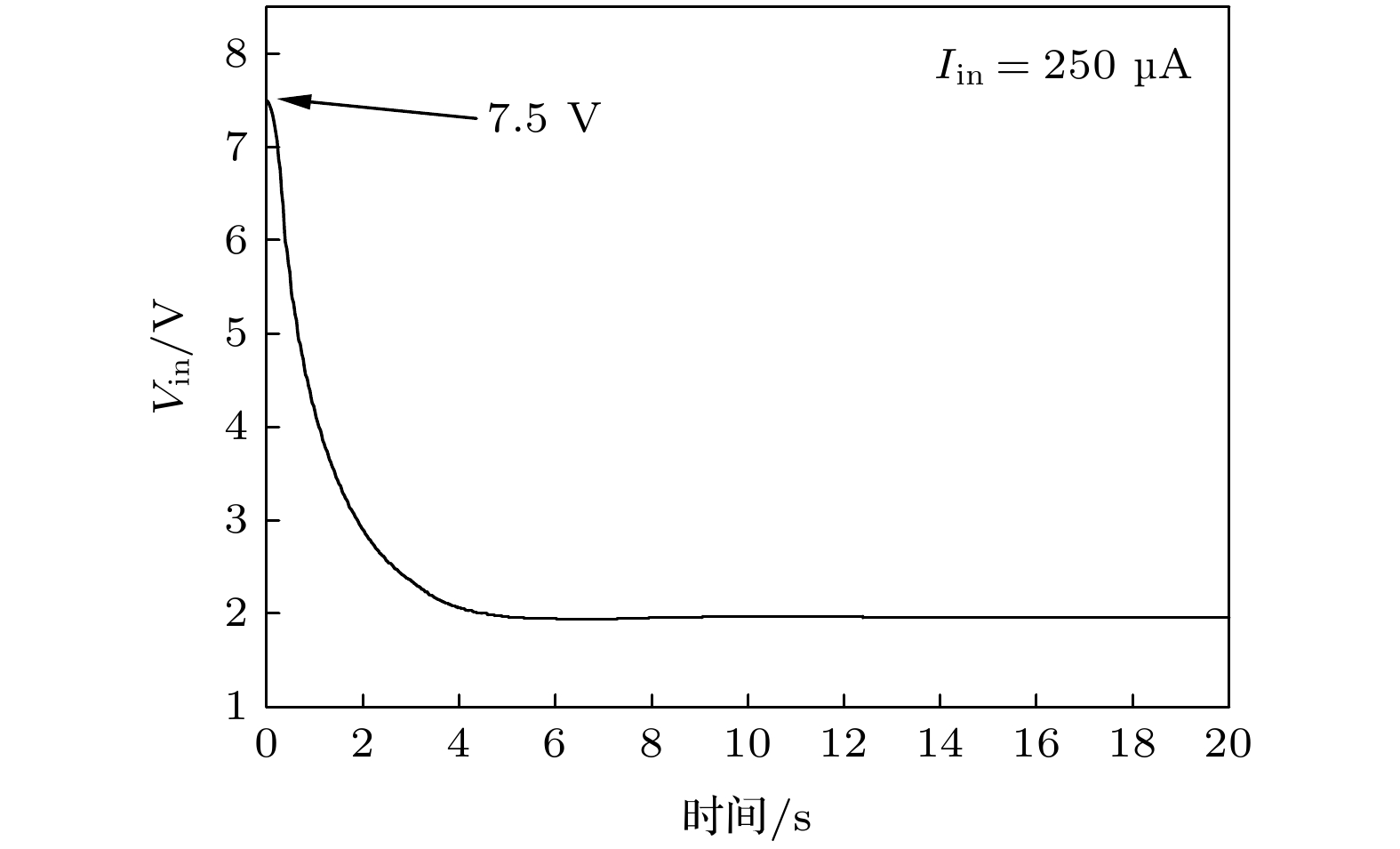 图 3 250
图 3 250 











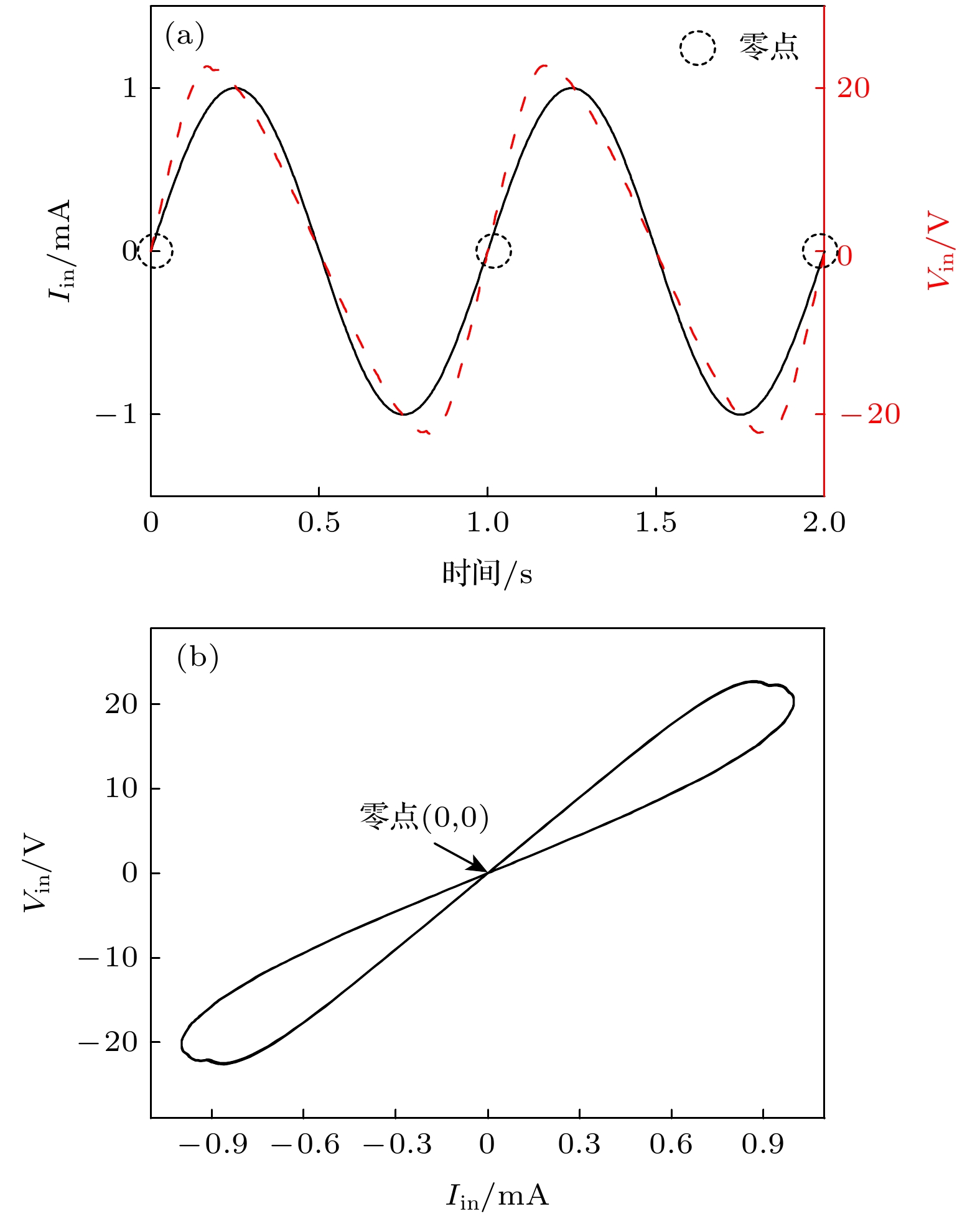 图 4 输入幅度为1 mA、频率为1 Hz的AC(正弦)电流时所对应的忆阻矩阵瞬态长时演化 (a) 忆阻矩阵网络中“in”输入端电压Vin; (b) 相应的I-V曲线(重叠压缩迟滞环). 各仿真参数均与图3相同
图 4 输入幅度为1 mA、频率为1 Hz的AC(正弦)电流时所对应的忆阻矩阵瞬态长时演化 (a) 忆阻矩阵网络中“in”输入端电压Vin; (b) 相应的I-V曲线(重叠压缩迟滞环). 各仿真参数均与图3相同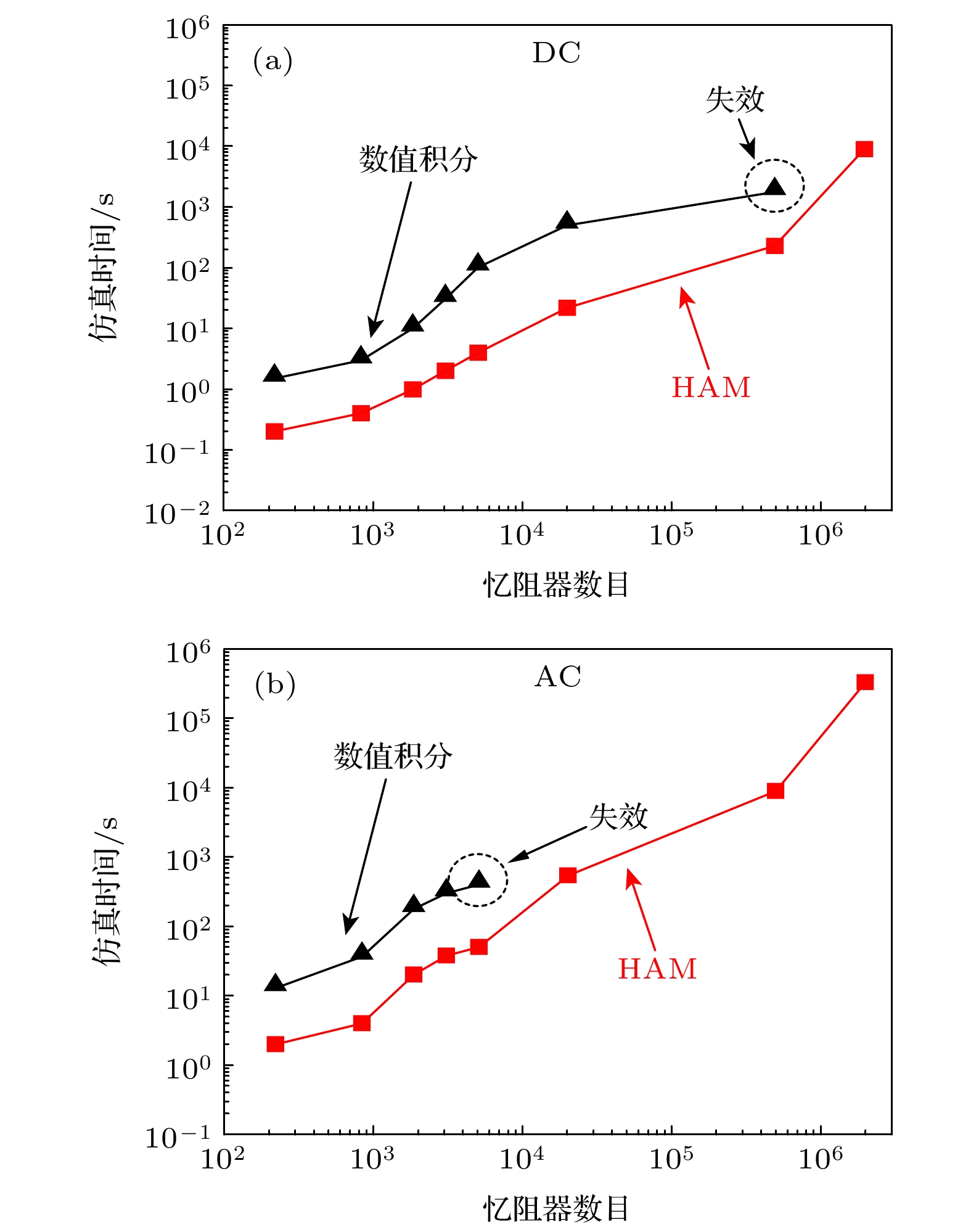 图 5 分别采用HAM和传统非解析[37](数值积分)模型进行忆阻矩阵仿真, 随着忆阻器单元数目的增加, 仿真时间的对比 (a)和(b)分别表示DC和AC (正弦)电流输入下的仿真时间. 此对比分析基于图3(DC)和图4(AC)所示Vin的动态演化
图 5 分别采用HAM和传统非解析[37](数值积分)模型进行忆阻矩阵仿真, 随着忆阻器单元数目的增加, 仿真时间的对比 (a)和(b)分别表示DC和AC (正弦)电流输入下的仿真时间. 此对比分析基于图3(DC)和图4(AC)所示Vin的动态演化

















































