全文HTML
--> --> -->自从20世纪80年代机器学习成为一个独立的研究方向以来, 各种机器学习算法被大量提出, 但是如何直接利用硬件设备实现更高效的机器学习仍是一个值得探索的命题. 尽管电子器件的发展使机器学习在集成电路上能达到令人满意的效果, 这种方式需要比较高的能耗和带宽. 同时, 通过传统的电子设备实现机器学习通常需要大量时间和较大尺寸的硬件设备. 这使得我们在处理复杂问题和边缘计算时将会十分困难[6]. 波动系统实现监督学习(如实现人工神经网络), 具有天然的优势. 它保证了大规模的并行性[7,8]和片上集成后较小的设备尺寸. 信息将以非常快的速度传输, 例如光速, 并且这种传输方式极大地减少了能耗, 甚至能够达到零能耗[9]. 另一方面, 物理学和机器学习都试图分析数据的规律来建立模型, 从而预测系统的行为, 两者之间存在着一些本质联系. 可以用物理学的机制来理解和构建机器学习方法, 例如基于扩散系统实现分类、信息过滤、优化等无监督算法.
物理学和机器学习的交叉互融具有悠远的历史和广泛的应用, 涉及范围十分宽广. 更多有关机器学习与物理学的讨论可以参考《Review of Modern Physics》以及《Physics Reports》的两篇综述文章[5,10], 它们更一般地回顾了机器学习技术在物理学的各大领域的典型应用. 由于能力和篇幅限制, 本文主要基于课题组自身的研究积累, 尝试从波动与扩散动力学的物理视角, 来统一地阐述和理解机器学习相关研究. 特别地, 本文重点关注波动、扩散物理系统对物理实现的推进作用, 以及机器学习算法启发, 主要讨论波动物理作为人工神经网络的硬件平台以及两者之间的内在联系, 以及受扩散物理启发的分类、优化等机器学习算法. 扩散与波动过程是物理学中的基本动力学过程, 我们希望通过这一独特的切入点, 为后续物理启发的机器学习研究带来新的思路.
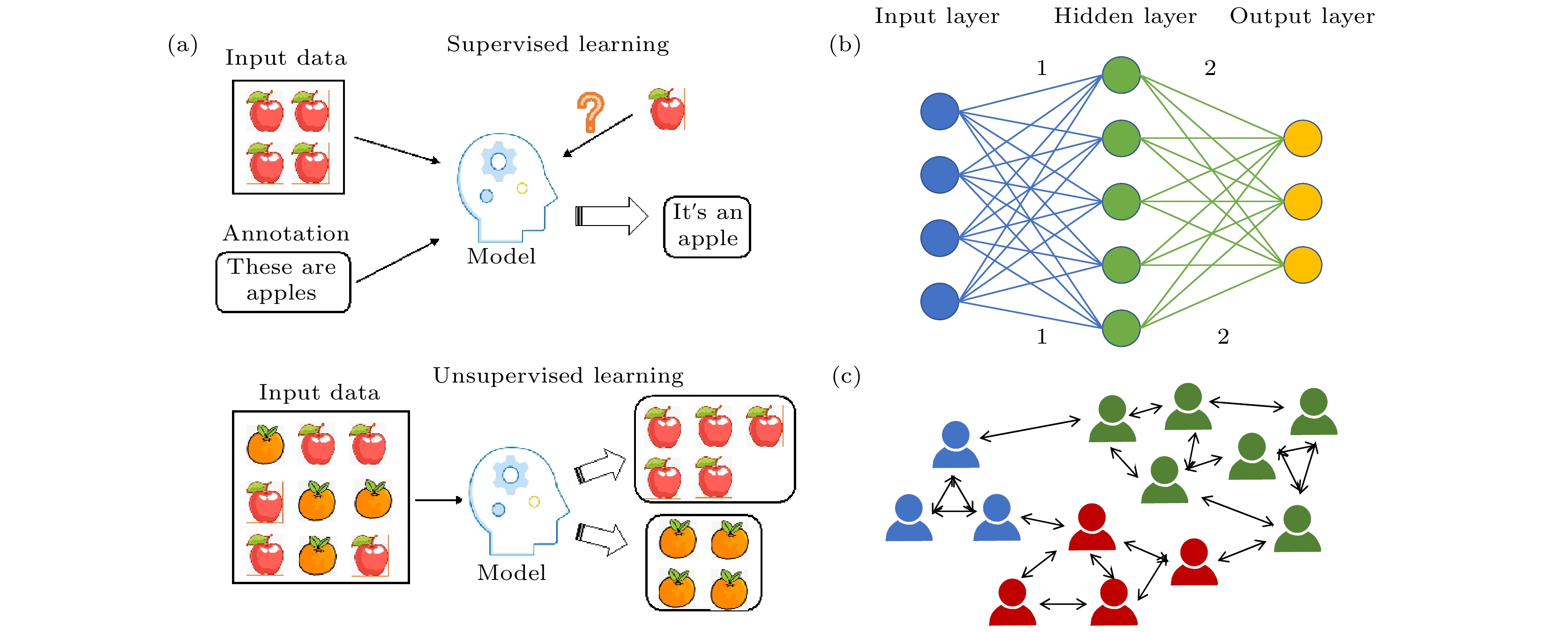 图 1 (a) 监督学习与无监督学习; (b) 一个单隐藏层神经网络的基本结构, 各层神经元根据权重系数相互连接; (c)利用无监督学习进行社交网络分析
图 1 (a) 监督学习与无监督学习; (b) 一个单隐藏层神经网络的基本结构, 各层神经元根据权重系数相互连接; (c)利用无监督学习进行社交网络分析Figure1. (a) Supervised learning and unsupervised learning; (b) the structure of a single hidden-layer neural network, where neurons are connected by weight coefficients; (c) unsupervised learning can be applied in social network analysis.
物理学中的波动系统既能实现监督学习, 也能实现无监督学习[11,12]. 然而随着近年来计算机视觉等领域的发展, 波动系统执行推理任务的能力尤为重要, 于是波动系统被频繁地与一些监督学习算法联系在一起. 在监督学习中, 假设有n个数据样本, 用













物理学中的扩散现象描述了大量粒子集体运动的统计结果. 对物理学中的扩散机制的研究和深入了解启发了新的机器学习算法的诞生, 尤其是一些改进的无监督学习算法. 与监督学习不同, 无监督学习的训练样本是没有已知标记的. 因此, 无监督学习不再依赖于“经验”, 而是更注重数据样本的内在模式和统计规律, 这与物理学中的扩散机制存在本质联系. 传统的无监督学习方法包括聚类—k-means算法[16]和EM算法[17]等, 以及数据降维—主成分分析(PCA)[18]和流形学习[19,20]等方法. 基于对物理学中的热传导扩散和概率扩散等系统的研究, 逐渐开发出各种改进的机器学习算法. 例如, 基于扩散动力学实现数据降维, 并根据数据的内在规律进行分类[21]; 基于热传导扩散实现数据挖掘, 建立推荐模型并应用于社交网络分析[22](图1(c)); 以及基于全局扩散搜索算法建立优化模型, 实现材料搜索和结构预测, 等等.
下面将分别介绍波动系统中的监督学习, 包括神经网络的波动光学实现、波动系统的递归神经网络、神经形态的非线性波动计算, 以及基于扩散系统的无监督学习, 包括基于扩散动力学的分类模型、基于热传导扩散的推荐模型、基于全局和局部扩散搜索算法的优化模型.
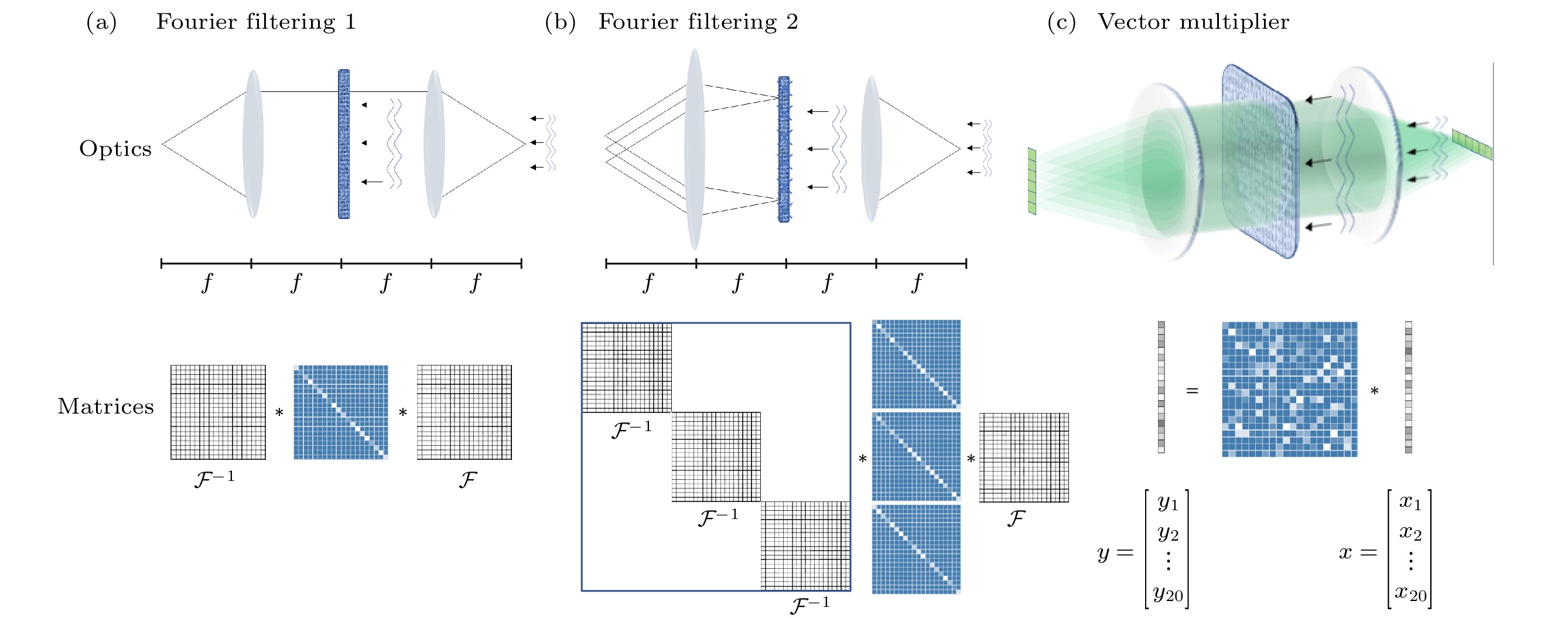 图 2 波在不同介质中的传播以及相应的线性矩阵运算 (a) 传统光学4f系统在傅里叶空间中实现乘法, 对应于在原空间中的卷积. 两个透镜分别实现傅里叶变换和傅里叶逆变换, 散射层对应于核矩阵, 场与薄散射层的相互作用相当于与对角矩阵的乘积; (b) 改进后的4f系统可以用光栅多次复制输入场, 并用不同的核矩阵进行卷积; (c) 通过类似4f的系统可以实现矢量-矩阵乘法, 实现一维行向量与稠密矩阵相乘, 得到一位列向量[6]
图 2 波在不同介质中的传播以及相应的线性矩阵运算 (a) 传统光学4f系统在傅里叶空间中实现乘法, 对应于在原空间中的卷积. 两个透镜分别实现傅里叶变换和傅里叶逆变换, 散射层对应于核矩阵, 场与薄散射层的相互作用相当于与对角矩阵的乘积; (b) 改进后的4f系统可以用光栅多次复制输入场, 并用不同的核矩阵进行卷积; (c) 通过类似4f的系统可以实现矢量-矩阵乘法, 实现一维行向量与稠密矩阵相乘, 得到一位列向量[6]Figure2. Wave propagation through different media and the corresponding linear matrix operations: (a) A traditional optical 4f system realizes multiplication in Fourier space, which corresponds to the convolution in the original space; (b) modified 4f systems can copy the input field with a grating and use different kernels for convolution; (c) a 4f-type system can implement the vector–matrix multiplication[6].
随着深度学习的兴起, 近年来人们更关注人工神经网络的波动物理实现. 人工神经网络需要在矩阵乘法运算的基础上引入非线性激活函数, 这在波动系统中是个挑战. 如何用波的传输模拟神经元中的信息传输, 如何控制权重也是亟待解决的问题. 接下来, 简要介绍近期与波动系统中的神经网络有关的部分工作.
2
3.1.神经网络的波动光学实现
对于最常见的全连接神经网络, 输出层中的每个元素都可以视作输入层中所有元素的加权和. 这种矢量-矩阵乘法的运算, 可以通过马赫-曾德干涉仪在光学领域实现[24]. 随着近年来光子集成电路的迅速发展, 科学家用一个可编程纳米光子处理器来实现基于相干光和全光学矩阵乘法的硅光子神经形态电路(图3(a))[25]. 光子神经形态计算的另一个重要方法是基于相变材料和器件的整合. 最近一项研究中, 科学家利用微米级环型谐振器将输入信息调制成不同波长, 并通过相变材料实现权重调节(图3(b)). 这种方式通过相变材料和环型谐振器的耦合来实现非线性激活, 最终在光子集成系统中构建出了脉冲神经网络[12,26], 有效地减小了光子芯片的体积.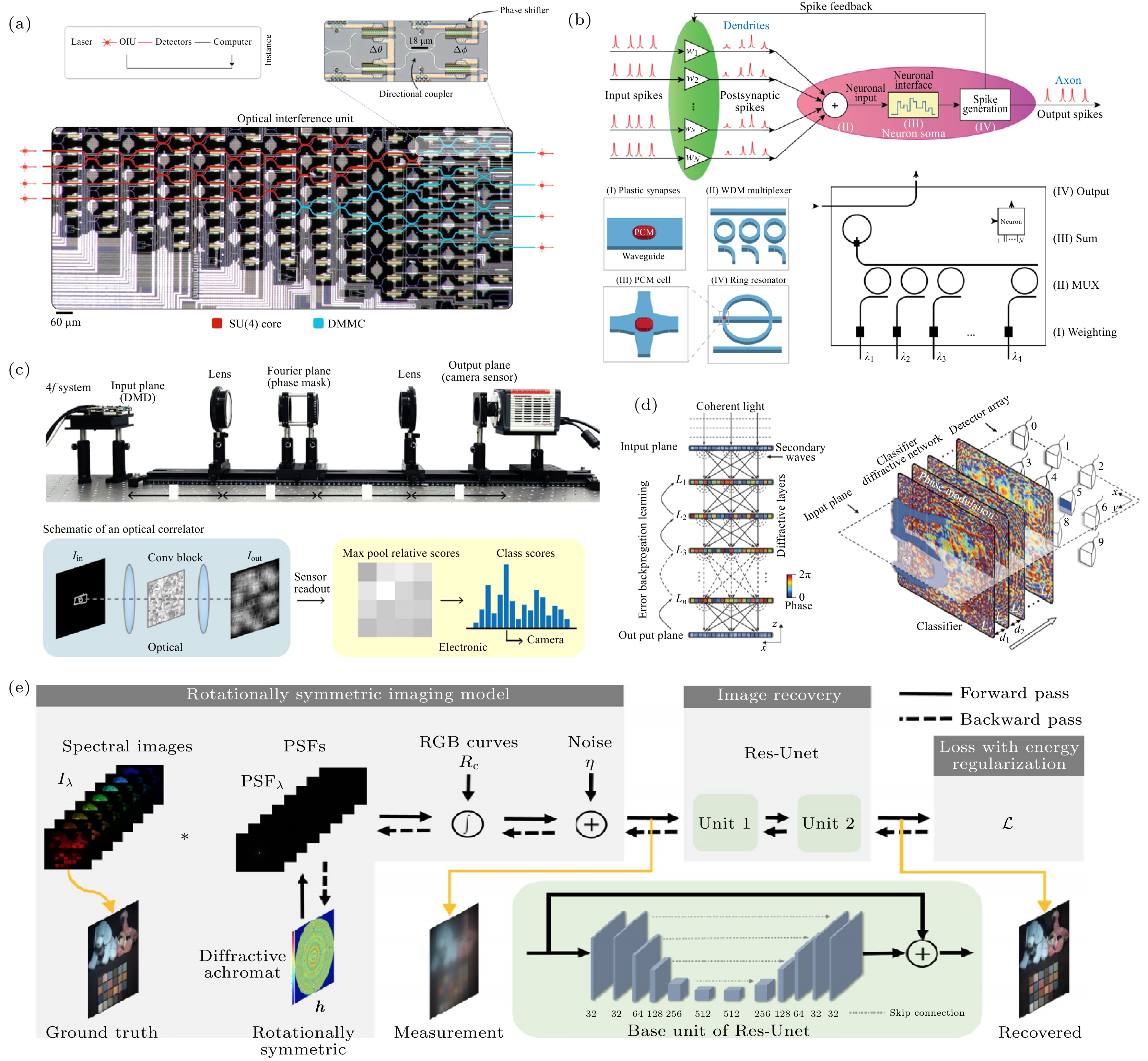 图 3 (a) 基于相干光和全光学矩阵乘法的硅光子神经形态电路可用于实现元音分类[25]; (b) 基于波分复用(WDM)的分层结构构成的全光脉冲神经网络, 能够实现图像和语言识别[12]; (c) 改进的光学4f系统实现卷积神经网络, 提高图像分类性能[27]; (d) 全光衍射深度神经网络实现数字分类[29]; (e) 光学衍射元件与图像处理算法端对端协同设计[32]
图 3 (a) 基于相干光和全光学矩阵乘法的硅光子神经形态电路可用于实现元音分类[25]; (b) 基于波分复用(WDM)的分层结构构成的全光脉冲神经网络, 能够实现图像和语言识别[12]; (c) 改进的光学4f系统实现卷积神经网络, 提高图像分类性能[27]; (d) 全光衍射深度神经网络实现数字分类[29]; (e) 光学衍射元件与图像处理算法端对端协同设计[32]Figure3. (a) Nanophotonic circuits based on coherent light and all-optical matrix multiplication is capable for vowel recognition[25]; (b) image and language recognition are achieved by an all-optical spiking neural networking with wavelength division multiplexing (WDM)[12]; (c) a design for an optical convolutional layer using a modified optical 4f system[27]; (d) an all-optical diffractive deep neural network that implements the digit classification[29]; (e) end-to-end learning paradigms of diffractive optics and processing algorithms[32].
除了光子集成电路, 还可以利用波通过透镜的传播来构建神经网络. Chang 等[27]提出了一种光电混合的卷积神经网络, 即在电子计算之前加入一层光学卷积层, 减小电子计算成本和处理时间, 同时提高处理图像分类任务的性能(图3(c)). 这种方式是分离地在光计算层进行线性计算, 在电子计算层实现非线性激活函数, 但是光电转换过程的效率就成为主要瓶颈. 构建全光神经网络可以解决这一问题, 即神经网络中的线性和非线性操作都在波动系统中实现. 例如, 用空间光调制器和傅里叶透镜实现线性操作, 电磁诱导透明的激光冷却原子实现非线性光学激活函数[28].
衍射层可以用来代替透镜调节与波的相互作用, 在缩小系统外形的前提下构建更高效的全光神经网络. 衍射层上的每个点透射或反射入射波, 并通过波的衍射连接到下一衍射层. 根据惠更斯-菲涅耳原理, 输入波经过衍射层上各个点的透射或反射后成为次波源, 次波源的振幅和相位由输入波与该点的复数透射或反射系数的乘积决定. 因此, 衍射层上各点的透射或反射系数可被视作神经网络的权重, 通过设计固定结构的多层衍射层形成全光神经网络, 实现手写数字分类(图3(d))[29]. 类似的衍射神经网络还可以用来执行光学逻辑运算, 实现小型化的光学逻辑门[30]. 为了进一步提高核心计算模块的训练速度和能量效率, 科学家们提出了一种原位光学学习结构. 通过这种结构, 可以在光学系统中实现衍射神经网络的训练过程[31]. 衍射光学元件与计算成像结合, 有望实现轻薄的高性能成像系统. 同济大学程鑫彬课题组[32]提出基于同心圆环分解的成像模型计算降维理念, 成功地将衍射光学元件和图像处理算法端到端设计框架的内存需求降低了一个数量级, 有助于发展基于衍射光学元件的轻薄计算成像系统(图3(e)).
除此之外, 衍射神经网络也可以在声学超构材料[33]或者傅里叶空间中[34]实现. 已有研究在声波系统中利用超材料控制声波的相位和透射率进行模拟计算[35], 可以实现空间上的微分、积分和卷积[36,37]以及常微分方程的求解[38,39]等. Weng等[33]从理论上提出并实验证明了一个纯粹的被动神经网络, 由于它的超材料单元产生深亚波长相移, 该声学神经网络能够通过分析声散射实时识别复杂物体(图4(a)). 特别地, 由于线性波动系统本身具有并行运算能力, 即两个或多个波包的传播不互相影响, 利用波动系统构建机器学习算法时还可以考虑结合量子算法进一步提升计算速度[40]. 例如, 以波元的振幅代表量子态的概率幅, 波元的相位代表量子态的相位, 可以实现有别于经典搜索的量子搜索算法. 对于一个包含有N个数据的数据库而言, 找到一个指定数据, 经典算法成功搜索一个数据需要根据搜索条件在数据库中逐一进行比对, 平均需要






 图 4 (a) 基于声学超构神经网络的被动目标识别[33]; (b) 利用声表面波系统实现量子搜索算法, 实现与量子逻辑门相似的操作[40]
图 4 (a) 基于声学超构神经网络的被动目标识别[33]; (b) 利用声表面波系统实现量子搜索算法, 实现与量子逻辑门相似的操作[40]Figure4. (a) Passive object recognition with acoustic meta-neural-network[33]; (b) realize quantum search algorithm with acoustic system, achieving operations similar to quantum logic gates[40].
2
3.2.波动系统的递归神经网络
波的动力学与递归神经网络(recurrent neural network, RNN)之间具有强烈的映射关系(图5)[41]. 包括声学和光学在内的波动物理可以自然地为时变信号构建模拟处理器. 如图5(a)所示, 递归神经网络中的更新过程可以描述为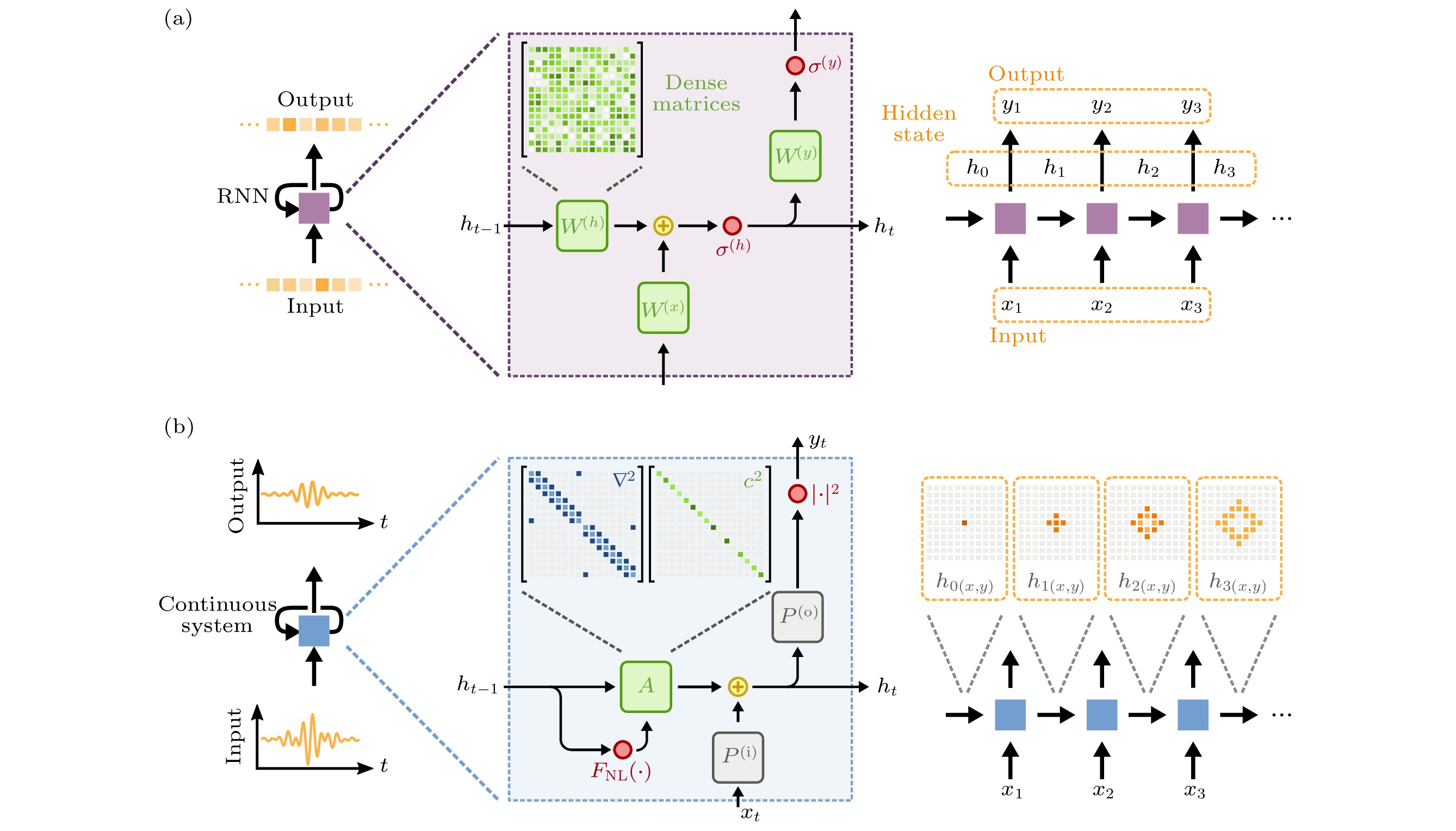 图 5 标准RNN和波物理的对比 (a)具有离散的输入、输出序列的RNN的更新过程; (b) 具有连续输入、输出序列的波动系统系统的更新过程[41]
图 5 标准RNN和波物理的对比 (a)具有离散的输入、输出序列的RNN的更新过程; (b) 具有连续输入、输出序列的波动系统系统的更新过程[41]Figure5. Comparison of a standard RNN and a wave system: (a) The update process of an standard RNN with discrete input and output sequence; (b) the update process of a wave-based physical system with continuous input and output sequence[41].











波场分布




























通过这种递归神经网络与波动物理的映射表明, 神经网络学习时间数据中的复杂特征, 可以通过特定的波动物理系统来实现. 例如, 通过波在非均匀介质中的散射和传播实现对音频信号的元音分类, 实现了与递归神经网络的标准数字实现相当的性能[41]. 除此之外, 在小型硬件构成的神经网络上加入非线性动力学特征, 如振荡和同步, 可以实现特殊的分类任务, 例如训练一个由四个自旋转矩纳米振荡器组成的硬件网络, 通过自动实时学习规则调整语音元音的频率来识别语音元音[42]. 另外, 波在非均匀纳米光子介质中的散射也可以实现连续无分层的方式的人工神经网络计算. 非均匀介质通过变换波前来实现复杂的计算任务, 如图像识别. 这些计算介质可以小到几十个波长, 并提供超高的计算密度, 这种方式利用亚波长散射体来实现复杂的输入/输出映射, 超越了传统纳米光子器件的能力[43]. 除了经典的时间序列学习, 波动系统有望应用于更复杂的系统学习, 如厦门大学赵鸿[44]提出的利用时序数据的自演化学习机, 可以解决“黑箱”系统周期动力学, 甚至混沌动力学的推断问题, 并有望推广到复杂耦合体系的系统重构[45].
2
3.3.神经形态的非线性波动计算
神经网络计算同样可以通过非线性波实现. Marcucci等[46]最近研究了非线性波具有进行神经形态计算的潜力. 非线性波, 如孤子、冲击波和怪波的发散行为能够提供足够的复杂度来进行机器学习, 它们被有效地应用到储蓄池计算中. Marcucci等[46]提出了一个由非线性偏微分方程驱动的计算模型, 称为单波层前馈网络(single wave-layer feed-forward network, SWFN)(图6(a)). SWFN结构由三层组成: 编码层, 将输入向量编码成波的初始振幅或相位; 储蓄层, 波按照非线性波动方程演化; 读出层, 通过波动演化后, 从最终状态读出结果. 由于该网络是储蓄池计算网络, 只需对读出层的权值进行训练. 除了该系统中用到的非线性薛定谔方程, 其他任何非线性波动微分方程都可用于波的演化. 事实上, 任何具有非线性波动动力学特征的系统都可以用来建立神经形态的非线性波动网络. 研究人员用不同的编码方法实现了三种具体应用: 近似计算一维函数(图6(b)), 学习一个八维数据集(图6(c)), 实现布尔逻辑门(图6(d)). 三个例子中, SWFN都能与传统神经网络一样. 这说明了SWFN的通用性, 它能够用于近似计算任意函数和学习高维数据集. 这项基础工作阐明了非线性波与机器学习之间的联系, 为电子学、光子学、自旋电子学、流体力学、玻色-爱因斯坦凝聚等领域的各种非线性波现象用作神经形态计算打开了大门. 图 6 神经形态的非线性波动网络 (a) 单波层前馈网络(SWFN)包含编码层、储蓄层和读出层, 其中波按照非线性偏微分方程演化; (b) 偏差
图 6 神经形态的非线性波动网络 (a) 单波层前馈网络(SWFN)包含编码层、储蓄层和读出层, 其中波按照非线性偏微分方程演化; (b) 偏差

Figure6. Neuromorphic computing by nonlinear waves: (a) Single wave-layer feed forward neural network (SWFN) with input layer, reservoir and readout layer, where the wave evolves according to a nonlinear partial differential equation; (b) the bias and wave evolution and results of learning the function

储蓄池计算[47,48]是一类特殊的人工神经网络, 其作为中间层的储蓄层是随机生成的, 且生成后就保持不变, 只需要训练输出层. 科研工作者提出了一个多功能的基于孤子的计算系统[49], 使用离散孤子链作为储蓄池, 通过利用其可调的控制动力学, 证明了足够强的非线性动力学能够实现对非线性可分离数据集执行精确的回归和分类任务. 由于近年来科研工作者们才关注到非线性波中的机器学习, 相关的工作还很少. 但是基于非线性波实现储蓄池计算, 通过储蓄层中的波传输携带大量信息, 能够学习更大尺度的数据集, 并且这种方式往往不需要严格控制传播介质, 因此该方向值得深入的研究探索.
2
4.1.基于扩散动力学的分类模型
分类是机器学习的重要任务之一. 流形学习能够将真实世界中的高维数据映射到一个低维特征空间, 从而根据数据的内在规律进行分类. 但是对于非线性流形, 传统的线性映射方法并不可行, 因此科学家们提出了扩散映射[50,51]. 扩散映射的基本思想是在数据图上定义一个扩散行为, 通过一段时间的扩散, 逐渐滤除数据集中不重要的信息, 并得到数据之间的相似度关系.在具有N个数据点的数据集


































 图 7 利用扩散映射实现典型声子系统中的流形聚类 (a) 流形空间降维; (b) 流形空间的样本数据分布与势能绘景; (c) 流形空间的扩散与凝聚, 稳态显示出天然的聚类; (d)随机耦合的无序Su-Schrieffer-Heeger(SSH)声子链; (e) 无序非晶态声子的拓扑分类; (f) 一维非厄米声子链; (g) 高阶拓扑声子[21]
图 7 利用扩散映射实现典型声子系统中的流形聚类 (a) 流形空间降维; (b) 流形空间的样本数据分布与势能绘景; (c) 流形空间的扩散与凝聚, 稳态显示出天然的聚类; (d)随机耦合的无序Su-Schrieffer-Heeger(SSH)声子链; (e) 无序非晶态声子的拓扑分类; (f) 一维非厄米声子链; (g) 高阶拓扑声子[21]Figure7. Diffusion mapping in typical phononic systems to realize manifold clustering: (a) Dimension reduction in manifold space; (b) the probability distribution of samples and the effective landscape; (c) along with evolution, the samples diffuse and finally concentrate on positions with minimum local potentials, which indicates the clustering; (d)–(g) applications in disordered photonic SSH chain, amorphous topological phononics, 1D non-Hermitian phononic chain, high-order topological phononics[21].
最近, 同济大学声子学课题组通过扩散映射, 实现了基于实空间动力学性质相似性的拓扑声子无监督流形聚类(图7)[21]. 用一个








基于扩散动力学的分类算法有很强的可适应性, 通过定义式(8)式中的核矩阵

 图 8 基于扩散映射的无监督学习方法适用于解决不同物理系统中的拓扑分类问题 (a) 一维XY模型拓扑序的检测[52]; (b) 扩散映射能够不借助边缘态, 识别Haldane模型描述的拓扑相变点[54]; (c) 量子系统中的扩散映射算法, 能够无监督地识别
图 8 基于扩散映射的无监督学习方法适用于解决不同物理系统中的拓扑分类问题 (a) 一维XY模型拓扑序的检测[52]; (b) 扩散映射能够不借助边缘态, 识别Haldane模型描述的拓扑相变点[54]; (c) 量子系统中的扩散映射算法, 能够无监督地识别
Figure8. The unsupervised learning with diffusion map is applied to solve topology identification in different physical systems: (a) Identifying the topological order in 1-dimensional XY model[52]; (b) detection of the phase transition for the Haldane model without the edge states[54]; (c) diffusion maps in learning quantum phases with a

2
4.2.基于热传导扩散的推荐模型
除了基于概率扩散的机器学习算法, 热传导扩散也启发了新的机器学习算法. 热传导系统中, 由于介质与介质之间存在温度差而产生传热, 使能量从物体的高温部分传至低温部分, 经过一段时间后形成稳定的温度分布. 热传导机制能够有效地应用于建立社会网络中的信息挖掘和推荐模型. 这种方法通过用户已选择的偏好项目(高温部分)推测出用户可能选择的其他项目(低温部分). 例如淘宝网通过用户已购买的产品推荐其他类似的产品. 基于物理学中的热传导[57,58], 科研工作者们提出了可以处理个性化边界条件的推荐模型, 用于处理社会网络中庞大的数据信息.物理学中的热传导过程可以用偏微分方程:









 图 9 标号图表明6个点(项目)之间的连接关系, 右侧是对应的权重矩阵和邻接矩阵
图 9 标号图表明6个点(项目)之间的连接关系, 右侧是对应的权重矩阵和邻接矩阵Figure9. Labelled graphs show the connection of 6 points (items), and the corresponding degree matrix and adjacency matrix are on the right side.


格林函数可以用来处理图上的扩散型问题[22]. 在推荐模型中, 温度向量R即用户对项目的评级向量,











热传导扩散和概率扩散都能应用于机器学习. 值得注意的是, 热传导模型中, 定义行归一化的转移矩阵






2
4.3.基于全局和局部扩散搜索算法的优化模型
扩散搜索算法能够在庞大的数据集中, 通过随机且分布均匀的搜索方式实现信息的最优化处理, 被广泛的应用于结构搜索[59-61]. Pickard和Needs[62]将随机扩散与第一性原理相结合, 提出了从头算随机结构搜索算法(ab initio random structure searching, AIRSS). 该算法以最随机的方式生成初始结构, 为了提高效率可以考虑引入基于化学、实验或对称性的偏置条件, 然后在保持实验和对称约束的同时演化起始结构. AIRSS的计算量集中在演化大量不同的初始结构, 直到多次获得相同的最低能量结构, 以确保该结构的势能面位于全局最小值.粒子群优化算法(particle swarm optimization, PSO)[63]模拟自然界中鸟群的捕食行为, 它不同于普通的单一粒子扩散行为, 群体中每个粒子的扩散搜索不仅受到自身个体极值影响, 还受到整个粒子群的当前全局最优解影响, 最终实现全局或局部扩散搜索最优解(图10(a)). 利用PSO进行晶体结构搜索, 吉林大学马琰铭教授团队[64,65]开发了CALYPSO, 全称为基于粒子群优化算法的晶体结构分析(crystal structure analysis by particle swarm optimization). 该方法只需要给定材料的化学成分和外部条件, 如压力, 就能预测材料稳定或亚稳结构, 大大减少了第一性原理密度泛函计算的计算量 (图10(b)). CALYPSO算法的开发启发了很多原创性工作, 在设计各种材料方面具有广泛应用, 为功能驱动的材料设计打开了大门, 具体内容可以参考《Journal of Physics: Condensed Matter》, 《Computational Materials Science》以及《Chinese Physics B》上的相关综述文章[66-68].
 图 10 (a) 全局及局部粒子群优化算法示意图; (b) 粒子群优化算法中速度及位置更新示意图[68]; (c) 多目标优化的二维SnSe材料定向设计工作流程图; (d) 室温下(300 K), 二维SnSe材料单层结构的自由能; (e) 图(d) 中第一Pareto前沿(红线)上的四种新型单层结构的三视图, 深灰色和绿色的球分别表示Sn原子和Se原子[70]
图 10 (a) 全局及局部粒子群优化算法示意图; (b) 粒子群优化算法中速度及位置更新示意图[68]; (c) 多目标优化的二维SnSe材料定向设计工作流程图; (d) 室温下(300 K), 二维SnSe材料单层结构的自由能; (e) 图(d) 中第一Pareto前沿(红线)上的四种新型单层结构的三视图, 深灰色和绿色的球分别表示Sn原子和Se原子[70]Figure10. (a) The diagram of PSO; (b) The schematic diagram of the velocity and position updates in PSO[68]; (c) workflow of the multi-objective optimization for 2D SnSe materials design; (d) thermopower landscape at room temperature (300 K) versus the free energy of 2D SnSe materials; (e) four 2D SnSe structures on the first Pareto front, where the dark gray and green balls denote Sn and Se atoms, respectively[70].
Gao等[69] 通过晶体结构搜索, 找到了三种新型的具有平面内负泊松比的氧化硅结构, 并且确认了二维氧化硅结构的全局最小自由能, 这在纳米力学和纳米电子学中有巨大的潜在应用. 基于PSO的扩散搜索也可以是多目标的, 多目标约束下功能材料的定向设计是一个很大的挑战, 其中性能和稳定性是由不同物理因素的复杂关联决定的. 闫申申等[70]基于帕累托最优和粒子群优化方法的多目标优化方法, 对新型功能材料进行定向设计. 该工作利用第一性原理结合多目标优化算法同时预测了具有低自由能和高热电势的多种新型二维硒化锡(图10(c)—(e)), 并且揭示了这些新型二维材料高热电势来源于其费米面附近能带的多简并度. 基于粒子群扩散的多目标优化方法能为未来多目标、多功能材料的一体化设计提供一个新的思路.
除此之外, 物理学中的扩散机制可以延伸到更为宽泛的领域, 比如利用极小值跳跃[71]和微分演化[72]进行材料结构预测也可视作广义上的扩散过程. 扩散搜索算法有望应用于更多凝聚态物理学领域, 比如解决文章[73]中提到到的光子拓扑态逆设计问题, 以及文章[74]中提到的分子热流分束问题.
首先, 本文介绍了波动系统中的神经网络实现, 包括线性的光学、声学系统以及非线性波系统. 一系列相关工作说明了依赖于波的并行性和快速传输性, 波动系统中的神经网络具有高效、低能耗、高带宽的特点. 本文重点介绍了几个示例, 凸显出波动系统在推断视觉任务、时序任务或大数据集任务时的优越性. 波动系统作为人工神经网络硬件载体具有巨大潜力, 为下一代芯片的开发提供了启发性的思路. 再者, 本文介绍了由扩散系统启发的无监督机器学习算法. 扩散系统中物质根据一定规律扩散, 最终达到稳态分布, 这一机制开发了许多机器学习算法, 解决了许多具有类似特点的实际问题. 例如, 基于概率扩散的分类算法, 基于热传导的社会网络推荐模型, 以及基于群体扩散的结构搜索算法.
尽管这个方向的研究已经取得巨大的进展, 但是仍处于初步阶段, 一些重要的基本问题尚未解决. 首先, 如何在波动系统中实现非线性激励函数仍是个重要的问题. 考虑到波动系统实现非线性激励函数的复杂度和局限性, 在波动系统中实现神经网络是否优于传统方法(如线性回归)值得商榷[23]. 另外, 在光学系统中可以通过有效的电光转换机制进行信号恢复[75]避免散粒噪声, 但是在其他的波动系统中如何避免噪声还不明确. 除此之外, 现有的研究主要通过波动系统实现人工神经网络, 突破经典硬件平台的限制, 或是根据扩散机制分析数据的内在规律, 从而实现无监督学习. 二者之间的交叉结合却鲜有讨论, 扩散物理是否能与人工神经网络相结合, 从而进一步实现扩散系统中的深度学习, 以及如何实现硬件和软件的结合优化, 这些都是值得继续深入研究的问题. 最后, 在经典波动系统或者经典扩散系统中实现类量子或量子启发算法模拟也是一个重要的研究方向.
