Fund Project:Project supported by the National Key Research and Development Program of China (Grant No. 2019YFA0308100), the National Natural Science Foundation of China (Grant Nos. 12075110, 11975117, 11905099, 11875159, U1801661), the Guangdong Basic and Applied Basic Research Foundation, China (Grant No. 2019A1515011383), the Guangdong International Collaboration Program, China (Grant No. 2020A0505100001), the Science, Technology, and Innovation Commission of Shenzhen Municipality, China (Grant Nos. ZDSYS20170303165926217, KQTD20190929173815000, JCYJ20200109140803865, JCYJ20170412152620376, JCYJ20180302174036418), the Pengcheng Scholars, the Guangdong Innovative and Entrepreneurial Research Team Program, China (Grant No. 2019ZT08C044), and the Guangdong Provincial Key Laboratory, China (Grant No. 2019B121203002)
Received Date:12 April 2021
Accepted Date:25 May 2021
Available Online:15 July 2021
Published Online:20 July 2021
Abstract:Machine learning is widely applied in various areas due to its advantages in pattern recognition, but it is severely restricted by the computing power of classic computers. In recent years, with the rapid development of quantum technology, quantum machine learning has been verified experimentally verified in many quantum systems, and exhibited great advantages over classical algorithms for certain specific problems. In the present review, we mainly introduce two typical spin systems, nuclear magnetic resonance and nitrogen-vacancy centers in diamond, and review some representative experiments in the field of quantum machine learning, which were carried out in recent years. Keywords:quantum machine learning/ spin systems/ nuclear magnetic resonance/ nitrogen-vacancy centers in diamond
求出解向量$ \left|{{x}}\right\rangle $. 和线性方程组问题类似, 经典计算机解线性微分方程要耗费大量计算资源. 当面临例如量子系统或者流体力学的问题时, 计算的维度大大增加, 这对于经典计算机来说难以解决. 随着量子计算的发展, 解线性方程组的量子算法已经被提出[19,33], 也相继在量子计算平台上进行验证. 而解线性微分方程组的量子算法虽然也被提出[35–37], 但是这些算法对于目前的量子计算机很难实现. 清华大学龙桂鲁团队[38] 提出了一种容易在量子线路中实现的基于逻辑门的解LDEs算法, 并且在4 bit的核磁共振体系上实现了解$ 4\times 4 $的线性微分方程组, 如图2所示. 线性微分方程组的解向量通式${{x}}\left(t\right)\!\approx\! \displaystyle\sum\nolimits_{m=0}^{k}\!\!\frac{{\left(Mt\right)}^{m}}{m!}{{x}}\left(0\right)+ $$ \displaystyle\sum\nolimits_{n-1}^{k}\frac{{M}^{n-1}{t}^{n}}{n!}{{b}}$所描述是非幺正演化, 而传统的量子计算是基于封闭系统和幺正演化. 该算法利用辅助系统使含有非幺正演化子系统的大系统进行幺正演化, 最终得以用便于实验实现的逻辑门线路完成解微分方程组. 解向量通式可以由计算基矢$ \left| {{j}} \right\rangle $展开, 图 2 解线性微分方程的量子线路图. 线路中第一个辅助寄存器是单比特, 第二个辅助寄存器为$ T=\mathrm{l}\mathrm{o}{\mathrm{g}}_{2}\left(k+1\right) $比特, 然后是一个工作系统. 所有的辅助寄存器被初始化为$ \left|0\right\rangle {\left|0\right\rangle }^{\mathrm{T}} $, 控制操作$ {U}_{x} $和$ {U}_{b} $分别被用来生成$ \left|{{x}}\left(0\right)\right\rangle $和$ \left|{{b}}\right\rangle $. 在编码和解码期间的演化算子为$\displaystyle \sum\nolimits_{\tau =0}^{k}\left|\tau \right\rangle \left\langle\tau \right|\otimes {U}_{\tau }$. 在线路的结尾, 在所有辅助比特为$ \left| 0 \right\rangle $的子空间中测量工作系统的态矢[38] Figure2. Quantum circuit for solving linear differential equations. The first auxiliary register in the circuit is a single bit, and the second auxiliary register is $ T=\mathrm{l}\mathrm{o}{\mathrm{g}}_{2}\left(k+1\right) $ bits, then is a working system $ \left|\phi \right\rangle $. All auxiliary registers are initialized to $ \left|0\right\rangle {\left|0\right\rangle }^{\mathrm{T}} $, and then the operation $ {U}_{x} $ and $ {U}_{b} $ are used to generate $ \left|{{x}}\left(0\right)\right\rangle $ and $ \left|{{b}}\right\rangle $. The evolution operator during encoding and decoding is $\displaystyle \sum\nolimits_{\tau =0}^{k}\left|\tau \right\rangle \left\langle\tau \right|\otimes {U}_{\tau }$. At the end of the circuit, the state vector of the working system is measured in the subspace where all auxiliary bits are $ \left| 0 \right\rangle $[38].
因此qPCA能够将时间复杂度降低到$ O\left(\log\left(N\right)\right) $. 然而上述方法需要的辅助比特数量随密度矩阵的大小指数增加, 大量的资源消耗以至于在实验平台上很难该算法进行验证, 所以文献 [45]中实验团队通过参数量子电路实现qPCA, 如图4所示, 该方法构建出一个厄密算符$ {\cal{U}} $, 能够将密度矩阵$ {{\rho }} $被对角化同时特征值按大小降序排列: 图 4 通过qPCA实现人脸识别的流程图. 通过混合经典量子控制方法对PQC $ {\cal{U}}\left({{\theta }}\right) $进行迭代优化, 其中在量子处理器上测量目标函数$ L\left({{\theta }}\right) $和梯度$ g\left({{\theta }}\right) $. 参数$ {{\theta }} $的存储和更新在经典计算机上实现. 用优化后的$ {U}_{g} $来计算特征脸矩阵D和协方差矩阵C的特征向量[45] Figure4. Workflow for human face recognition via qPCA. The PQC $ {\cal{U}}\left({{\theta }}\right) $ is iteratively optimized via the hybrid classicalquantum control approach, where the objective function $ L\left({{\theta }}\right) $ and the gradient $ g\left({{\theta }}\right) $ are measured on the quantum processor. The storage and update of the parameters $ {{\theta }} $ are implemented on a classical computer. The optimized PQC with the operator $ {U}_{g} $ is applied to compute the eigenvectors of the eigenface matrix $ {{D}} $ and the covariance matrix $ {{C}}={{A}}{{{A}}}^{\mathrm{T}} $[45].
3.NV色心体系金刚石中的NV色心由一个替代C原子的N原子以及相邻位置C原子的缺失产生的空位组成[46], 如图5(a)所示. NV色心是一种很重要的量子体系, 得益于其固态及室温下可操控等特点, 在量子计算、量子信息、量子精密测量等多个领域都有很好的应用前景[47-49]. 目前, 国内外都有科研团队在基于NV色心体系的量子技术上展开研究. 自然状态下, NV色心具有两种电荷态-电中性和带负电荷. 带负电的NV–由于其便于初始化、操控、读出, 对其本身及其应用的研究也最为广泛和深入, 本章节中我们将要回顾的相关研究也均是基于NV–. 图 5 (a)金刚石NV色心结构图; (b) NV色心电子能级跃迁过程示意图, $ {}_{ }{}^{3}{\mathrm{A}}_{2} $和$ {}^{3}\mathrm{E} $分别代表基态和激发态, $ {}^{1}{\mathrm{A}}_{1} $和$ {}^{1}\mathrm{E} $为中间亚稳态, 从激发态直接跃迁回基态会发出荧光, 而经中间态回基态不会发出荧光 Figure5. (a) NV color center structure; (b) schematic diagram of the transition process of NV color center electron energy level, $ {}^{3}{\mathrm{A}}_{2} $ and $ {}^{3}\mathrm{E} $ represent the ground state and excited state, respectively, $ {}^{1}{\mathrm{A}}_{1} $ and $ {}^{1}\mathrm{E} $ are the intermediate metastable states, which from the excited state directly transitions back to the ground state and emit fluorescence. But the path througt metastable state returns to the ground state without emitting fluorescence.
其中${q}_{1}({{k}})=t\mathrm{s}\mathrm{i}\mathrm{n}{k}_{x}$, ${q}_{2}({{k}})=t\mathrm{s}\mathrm{i}\mathrm{n}{k}_{y}$, ${q}_{3}({{k}})=t\mathrm{s}\mathrm{i}\mathrm{n}{k}_{z}$, $ {q}_{0}\left({{k}}\right)=t\left(\cos{k}_{x}+\cos{k}_{y}+\cos{k}_{z}+h\right.) $. t被设定为1, 而h是一个与维度无关的可调参量. 通过调控NV色心电子自旋基态的三个能级, 在实验上成功模拟出了所需的哈密顿量, 如图6(a)所示. 通过将NV色心基态的三个能级编码为$|1\rangle, |0\rangle, |–1\rangle$态, 观察$ {H}_{{{k}}} $可以发现其并没有对角项, 并且$ |1\rangle $与$ |–1\rangle $之间并没有直接的耦合. 因此实验中可以施加能级之间的共振微波, 通过绝热过程, 可以实现对应不同k值点的哈密顿量. 图 6 (a)利用共振微波操控NV色心基态能级; (b)可对拓扑相进行分类的3D卷积神经网络的体系结构, 输入是在10 × 10 × 10规则网格上的密度矩阵的实验数据. 每个密度矩阵由八个实数表示. 输出是每个可能相的分类概率[54] Figure6. (a) Using resonance microwave to control the ground state energy level of NV color center; (b) architecture of the 3D CNN to classify the topological phases. The input is experimental data of density matrices on a 10 × 10 × 10 regular grid. Each density matrix is represented by eight real numbers[54].
利用NV色心中的电子自旋模拟的三维手性拓扑绝缘体哈密顿量生成的原始数据, 训练卷积神经网络以识别拓扑相, 这样的监督学习类似于处理经典的图像识别. 如图6(b)所示,将在10 × 10 × 10规则网格的密度矩阵的实验数据作为输入, 通过一个用来预测拓扑不变量的预训练卷积神经网络迁移到分类不同拓扑相的问题中, 输出各个可能的拓扑相得经典概率. 实验发现即使只用输入10%实验数据, 模型也能够达到90%的识别率, 表明了即使使用最少数量的数据样本, 也可以训练CNN来成功识别拓扑阶段, 如图7所示. 图 7 迭代次数增加时的训练和验证准确性. 训练和验证准确性在训练过程开始时迅速增加, 然后达到了很高的饱和值(≈ 98%)[54] Figure7. The training and verification accuracy when the number of iterations increases. The training and validation accuracy increased rapidly at the beginning of the training process, and then reached a high saturation value (≈ 98%)[54].
由于主成分分析(PCA)在对数据降维的同时能够尽可能保留有效信息的特性, 其在机器学习领域有着十分广泛的应用前景. 量子主成分分析(qPCA)由于量子算法的量子加速特性, 可以比经典算法更加高效地解决问题. 对未知的低秩密度矩阵的量子主成分分析以量子形式快速揭示了与大特征值相对应的特征值, 并为机器学习和数据分析提供了潜在的量子加速器. 对于qPCA, 如何萃取出其主成分一直是一个问题. 前文提到, qPCA算法解决了时间复杂度的问题, 但实验上仍然需要大量的运算资源, 对量子比特数和操控的精确度都有着很高的要求, 所以完成实验一直都是一件很困难的事情. 杜江峰课题组[57]基于金刚石NV色心体系利用量子机器学习完成了主成分分析算法(PCA), 如图8所示. 在实验中使用了基于共振的量子主成分分析(RqPCA), 通过引入一个辅助比特, 实现了算法的量子指数加速. 图 8 共振量子主成分分析算法原理图 (a)探针-寄存器耦合系统的能级结构, $ \left|{\lambda }_{i}\right\rangle $是$ {{\rho }} $的第$ i $个本征态, 而$ {\lambda }_{i}\in [0, 1] $是对应的本征值, 如果扫描频率$ \omega \approx {\lambda }_{i} $, 就会引起探针量子位的拉比振荡; (b)使用Suzuki-Trotter分解的RqPCA的量子电路, 对探针量子位进行投影测量得到$ \left|1\right\rangle $表明该算法成功[57] Figure8. Algorithm schematic of RqPCA: (a) The energy structure of the coupled probe-register system. $ \left|{\lambda }_{i}\right\rangle $ is the i-th eigenstate of $ {{\rho }} $ and $ {\lambda }_{i}\in [0, 1] $ is the corresponding eigenvalue. Once the scanning frequency $ \omega \approx {\lambda }_{i} $, the Rabi oscillations of the probe qubit is induced; (b) the quantum circuit of RqPCA. The projective measurement of the probe qubit in the state $ \left|1\right\rangle $ indicates success of the algorithm, with principal component being distilled in the register[57].
自动编码器的想法在神经网络领域已经流行了数十年, 通常是为了降低数据的维度. 它以一种无监督的方式学习有效的数据编码, 包括一个编码器, 用于学习一组数据的表示形式; 以及一个解码器, 用于从简化的编码中生成尽可能接近其原始输入的表示形式. 自编码器通过简单地学习将输入复制到输出来工作. 这一任务(就是输入训练数据, 再输出训练数据的任务)听起来似乎微不足道, 然而这过程有一个很大的难点, 那就是总要根据自己的需求去找到合适的方式来约束训练的过程. 我们最常用的降维其实就是一个很好的例子, 限制数据的维度并不是一个简单的过程. 我们所加的这些限制条件, 一方面要能够满足我们的要求(比如对噪声的处理或者还原), 另一方面还需要能够有效地防止程序机械的将数据复制输出, 使其具有高效表达的能力. 受到经典自编码器的启发, 其在量子领域也可以用来解决一些传统方法难以轻松解决的问题. 接下来我们介绍其中一种很有效的应用. 文献[58]基于NV体系构建了量子自编码器, 如图9所示, 并通过提高量子纠缠的寿命进行了验证. 量子纠缠作为极为重要的量子资源, 却又非常脆弱, 容易受到环境的干扰而发生退相干, 因此保护纠缠, 抑制退相干是量子领域里的核心话题. 有一种方法是将纠缠的有效信息通过机器学习的方式编码到相干时间长的子空间, 而在需要取出信息时再进行反向解码操作, 还原为原有信息, 这样就变相的提高了量子纠缠的寿命. 图 9 (a)量子自编码器线路图, 通过编码操作$ {{\cal{U}}}_{\cal{E}} $将$ \left|{\varPsi }_{i}\right\rangle $中的信息压缩到$ {\left|\phi \right\rangle }_{\mathrm{c}\mathrm{o}\mathrm{d}\mathrm{e}} $中, 在需要时通过解码操作$ {{\cal{U}}}_{\cal{D}} $将$ {\left|\phi \right\rangle }_{\mathrm{c}\mathrm{o}\mathrm{d}\mathrm{e}} $还原为$ \left|{\varPsi }_{f}\right\rangle $; (b)优化编码器的基于梯度算法的HQCA的训练过程, $ {\rho }_{\mathrm{i}\mathrm{n}} $是编码器的输入状态, $ {\rho }_{\mathrm{o}\mathrm{u}\mathrm{t}} $是辅助量子位的输出状态, $ f\left({{\cal{U}}}_{\cal{E}}^{\left(q\right)}\right) $是成本函数, q是迭代次数[58] Figure9. (a) Quantum autoencoder circuit. The target information of $ \left|{\varPsi }_{i}\right\rangle $ can be encoded to the code state $ {\left|\phi \right\rangle }_{\mathrm{c}\mathrm{o}\mathrm{d}\mathrm{e}} $ via the encoder $ {{\cal{U}}}_{\cal{E}} $. $ {\left|\phi \right\rangle }_{\mathrm{c}\mathrm{o}\mathrm{d}\mathrm{e}} $ can be reconstructed to $ \left|{\varPsi }_{f}\right\rangle $ when needed by the decoder $ {{\cal{U}}}_{\cal{D}} $. (b) Training process of the gradient-based HQCA to optimize encoder. Here, $ {\rho }_{\mathrm{i}\mathrm{n}} $ is the input state of the encoder, and $ {\rho }_{\mathrm{o}\mathrm{u}\mathrm{t}} $ is the output state on the ancilla qubits. $ f\left({{\cal{U}}}_{\cal{E}}^{\left(q\right)}\right) $ is the cost function, where q is the current iterative number[58].














































 图 1 实现HHL算法的量子线路图. 其中
图 1 实现HHL算法的量子线路图. 其中









































 图 2 解线性微分方程的量子线路图. 线路中第一个辅助寄存器是单比特, 第二个辅助寄存器为
图 2 解线性微分方程的量子线路图. 线路中第一个辅助寄存器是单比特, 第二个辅助寄存器为



















































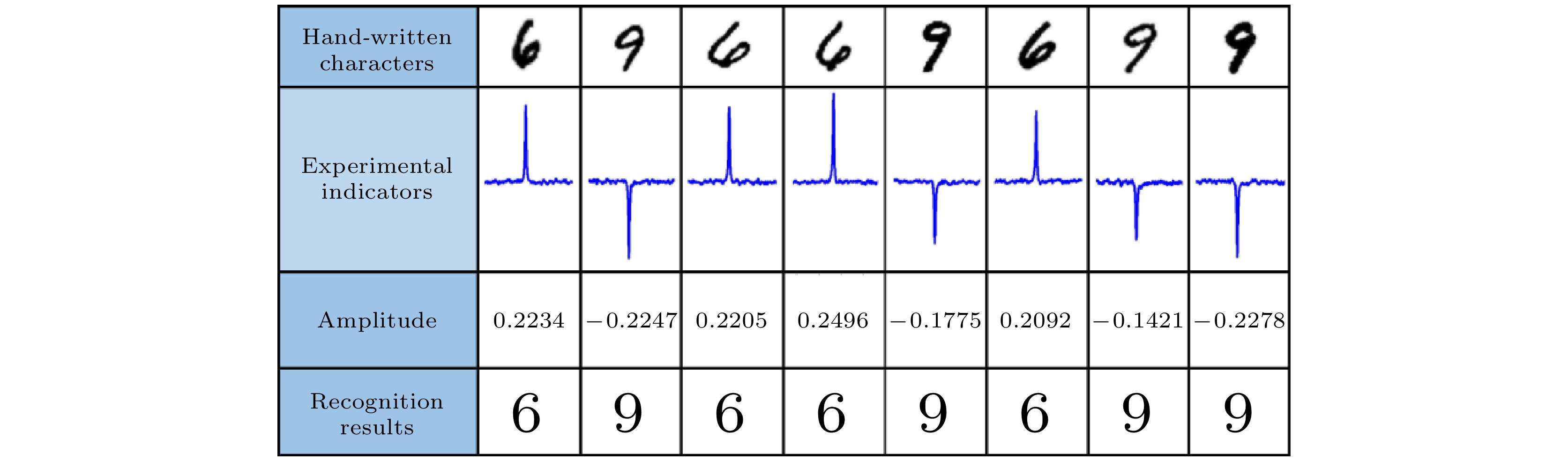 图 3 手写字符“6”和“9”的识别结果, 第1—4行分别代表手写字符, 实验指示符, 相干项的幅度和识别结果[42]
图 3 手写字符“6”和“9”的识别结果, 第1—4行分别代表手写字符, 实验指示符, 相干项的幅度和识别结果[42]
















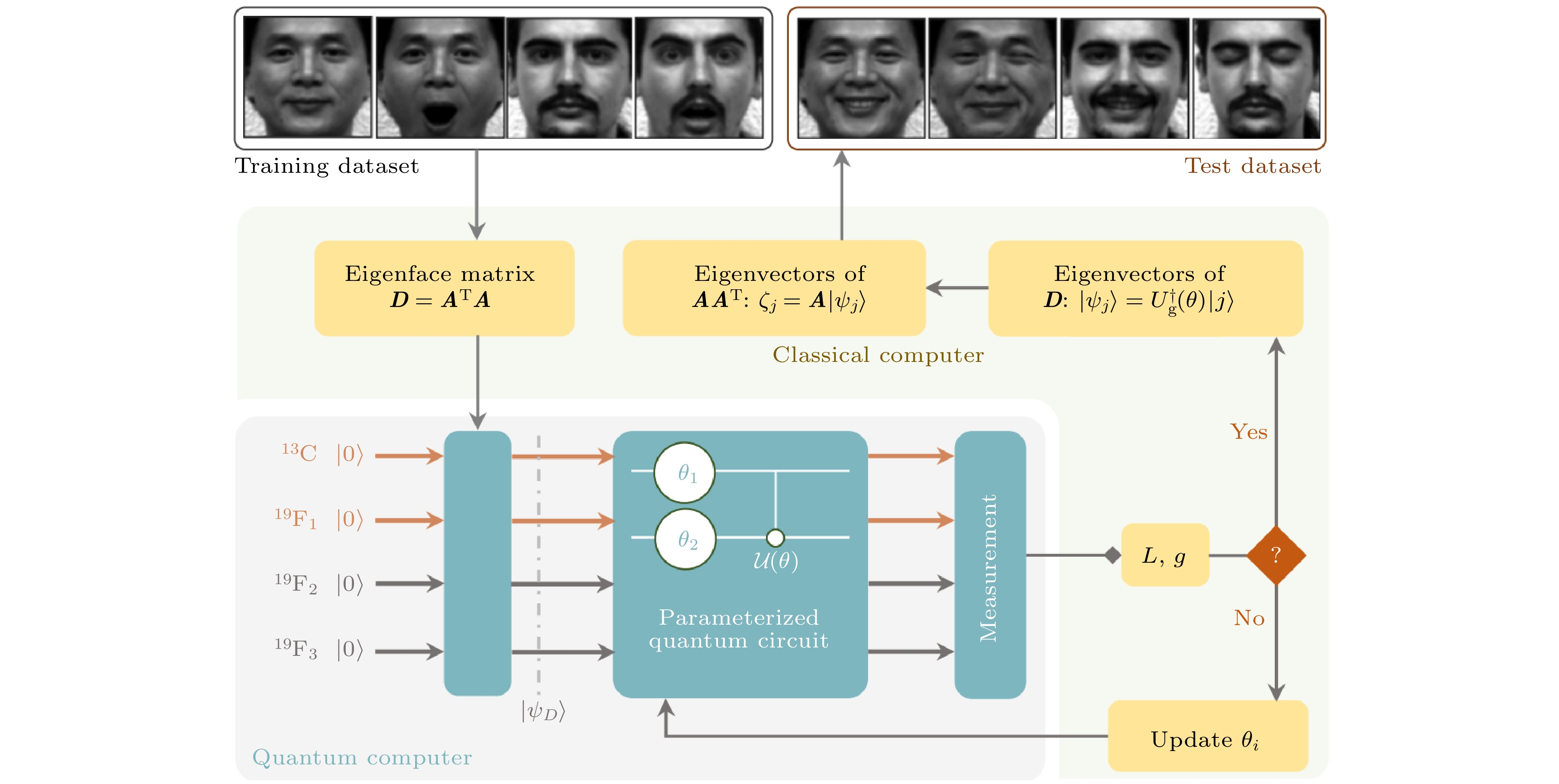 图 4 通过qPCA实现人脸识别的流程图. 通过混合经典量子控制方法对PQC
图 4 通过qPCA实现人脸识别的流程图. 通过混合经典量子控制方法对PQC 

















 图 5 (a)金刚石NV色心结构图; (b) NV色心电子能级跃迁过程示意图,
图 5 (a)金刚石NV色心结构图; (b) NV色心电子能级跃迁过程示意图, 











































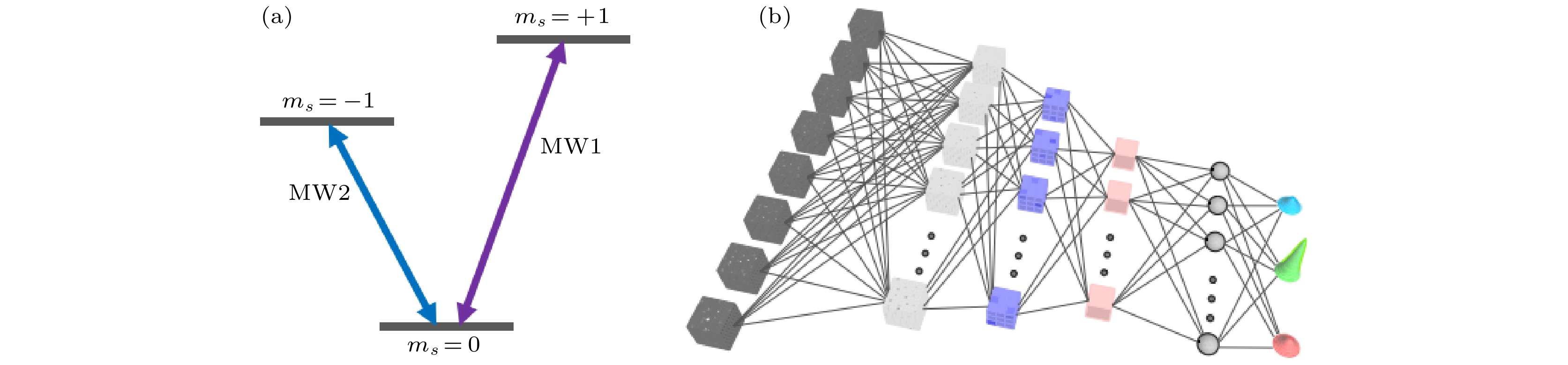 图 6 (a)利用共振微波操控NV色心基态能级; (b)可对拓扑相进行分类的3D卷积神经网络的体系结构, 输入是在10 × 10 × 10规则网格上的密度矩阵的实验数据. 每个密度矩阵由八个实数表示. 输出是每个可能相的分类概率[54]
图 6 (a)利用共振微波操控NV色心基态能级; (b)可对拓扑相进行分类的3D卷积神经网络的体系结构, 输入是在10 × 10 × 10规则网格上的密度矩阵的实验数据. 每个密度矩阵由八个实数表示. 输出是每个可能相的分类概率[54]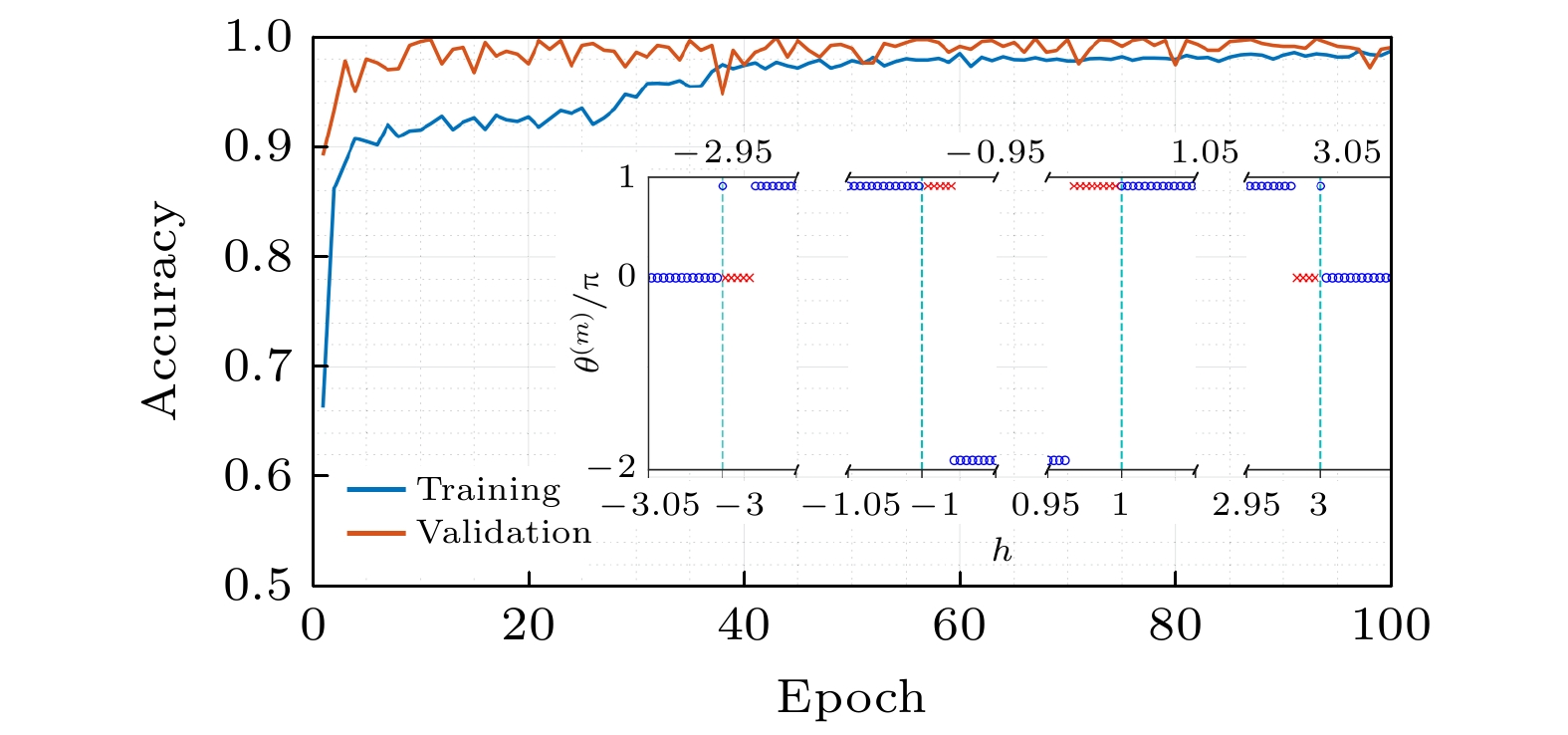 图 7 迭代次数增加时的训练和验证准确性. 训练和验证准确性在训练过程开始时迅速增加, 然后达到了很高的饱和值(≈ 98%)[54]
图 7 迭代次数增加时的训练和验证准确性. 训练和验证准确性在训练过程开始时迅速增加, 然后达到了很高的饱和值(≈ 98%)[54]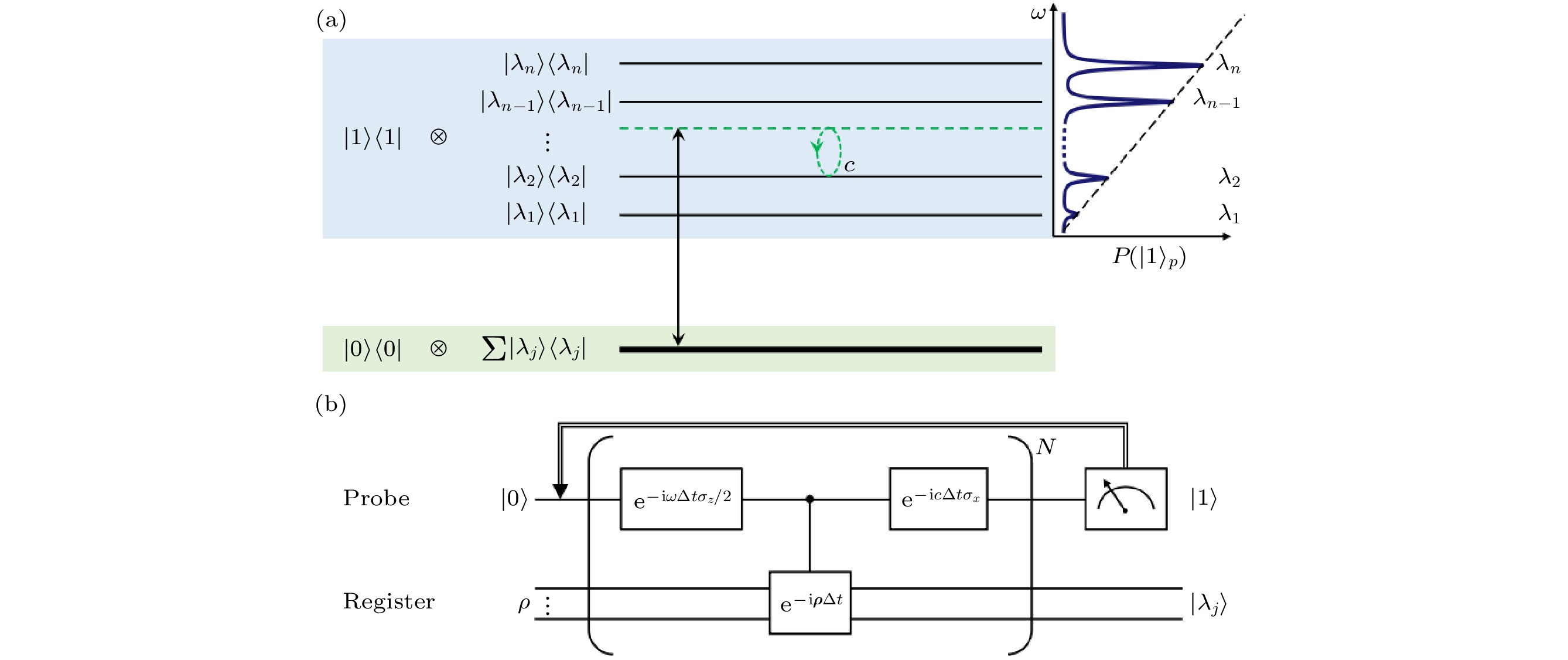 图 8 共振量子主成分分析算法原理图 (a)探针-寄存器耦合系统的能级结构,
图 8 共振量子主成分分析算法原理图 (a)探针-寄存器耦合系统的能级结构, 






















 图 9 (a)量子自编码器线路图, 通过编码操作
图 9 (a)量子自编码器线路图, 通过编码操作

















