1.Department of Electronic Engineering, Fudan University, Shanghai 200433, China 2.Department of Radiology and Diagnostic Imaging, University of Alberta, Edmonton T6G2B7, Canada
Fund Project:Project supported by the National Natural Science Foundation of China (Grant Nos. 11525416, 11827808, 11804056), the Shanghai Committee of Science and Technology International Cooperation Project, China (Grant No. 17510710700), the Natural Science Foundation of Shanghai, China (Grant No. 19ZR1402700), and the State Key Laboratory for ASIC and System, China (Grant No. 2018MS004)
Received Date:19 May 2019
Accepted Date:02 July 2019
Available Online:01 September 2019
Published Online:20 September 2019
Abstract:With the advantages of non-ionizing and low cost, ultrasound imaging has been widely used in clinical diagnosis and treatment. However, due to the significant velocity changes between cortical bone and soft-tissue, the traditional ultrasound beamforming method under the assumption of constant velocity fails to reconstruct the cortical bone image. The velocity model based beamforming has been used in geophysics and non-destructive testing as an effective way to solve the challenges resulting from the velocity changes in multi-layer structure. Since the cortical bone can be modeled as a three-layer structure consisting of soft tissue, cortical bone and marrow, a multi-layer velocity model based synthetic aperture ultrasound method is introduced for cortical bone imaging. In this study, we first utilize synthetic transmit aperture ultrasound to obtain the full-matrix dataset to increase the signal-to-noise ratio. Second, a three-layer cortical bone velocity model is built with the compressed sensing estimated arriving time delay. The bases of compressed sensing consist of a series of excitation pulses with different delays. The received signals are regarded as a composition of the bases with different weights, thus can be projected into the bases by using compressed sensing. The time-delay of each received element is estimated by compressed sensing. According to the time-delay, the full-matrix dataset is reformed into a zero-offset format. By extracting the bases corresponded with the interface reflected signals, the time-delay between and the thickness values of the interfaces can be estimated. The velocity model can thus be built with the estimated cortical bone thickness. Based on the velocity model and zero-offset data, the phase shift migration method is used to reconstruct the cortical bone image. The finite-difference time-domain (FDTD) method is used to simulate the wave propagation in a 3.4-mm-thick cortical bone. The transmitting pulse is a Gaussian-function enveloped tone-burst signal with 6.25 MHz center frequency and 250 MHz iteration rate. The reconstructed image of simulation shows a clear top interface and bottom interface of cortical bone with correct thickness. Further FDTD simulations are carried out on a 3-mm-to-5-mm-thick cortical bone, and the average relative error of estimated thickness is 4.9% with a 13.5% variance. In vitro experiment is performed on a 3.4-mm-thick bovine bone plate to test the feasibility of the proposed method by using Verasonics platform (128-element linear array). The transmitting pulse is a Gaussian-function enveloped tone-burst signal with 6.25 MHz center frequency and 25 MHz sampling rate. The reconstructed image in experiment reveals a clear top interface and bottom interface of cortical bone with correct thickness. The experiment is repeated several times and the average relative error of estimated thickness is 3.6% with a 5.4% variance. The results of simulation and experiment both indicate that compressed sensing is effective in estimating the delay parameters of the velocity model. Finally, we evaluate the capability of compressed sensing in time-delay estimation, and the result shows that compressed sensing is more accurate than Hilbert transform even in a 20 dB-noise condition. In conclusion, the proposed method can be useful in the thickness estimation and the ultrasound imaging of cortical bone. In vivo experiment and clinical application should be further investigated. Keywords:synthetic aperture ultrasound/ cortical bone imaging/ velocity model/ compressed sensing
图5为皮质骨FDTD仿真结果, 其中${A_{\rm{N}}}$为归一化幅度. 图5(a)为仿真采用的发射脉冲经过不同延时组成的压缩感知基底. 图5(b)为FDTD仿真的单通道接收信号, 在4.6和7.0 μs附近可观察到两次明显的反射回波, 分别对应软组织和骨板上表面的分界面以及骨板下表面和软组织的分界面. 因超声存在衰减, 第二回波幅度明显小于第一回波. 图5(c)为第一个阵元发射时, 前30个通道的接收信号, 因回波信号到达各个阵元的路径不同, 通道间波形存在延时. 压缩感知计算各通道间接收延时参数, 并对信号进行延时调整, 结果如图5(d)所示. 与图5(c)对比可得, 调整后信号的第一回波延时已对齐, 可进行后续图像重建. 图 5 仿真结果 (a)压缩感知前30个基底; (b)单通道接收信号; (c)单次发射全部通道接收信号; (d)压缩感知调整的单次发射全部通道接收信号 Figure5. Simulated results: (a) The first 30 bases of compressed sensing; (b) received signal of single element; (c) received signals of all elements; (d) compressed sensing based temporally adjusted received signals of all elements.
图6为采用PSM算法对FDTD仿真数据进行图像重建的结果. 未建立声速模型的重建结果如图6(a)所示, 虽可获得清晰的上下骨板界面, 但因声速未经矫正, 骨板厚度存在误差, 平均骨板厚度约为1.8 mm, 相对误差47.1%. 经压缩感知建立的多层声速模型调整后的重建结果如图6(b)所示, 平均骨板厚度约为3.4 mm, 相对误差为0%, 使用多层声速模型可实现骨板厚度的正确成像. 图 6 仿真重建结果 (a)未建立声速模型的仿真重建结果; (b)建立声速模型的仿真重建结果 Figure6. Simulated reconstructed results: (a) Simulated reconstructed result without velocity model; (b) simulated reconstructed result with velocity model.
表1皮质骨厚度估计及误差 Table1.Estimation and relative error of cortical bone thickness.
压缩感知估计皮质骨厚度的平均相对误差为4.9%, 方差为13.5%. 23.2.实验结果 -->
3.2.实验结果
图7为牛胫骨骨板的实验结果. 图7(a)为实验采用的发射脉冲经过不同延时组成的压缩感知基底. 图7(b)为实验的单通道接收信号, 在16.3和18.7 μs附近可观察到两次明显的反射回波, 分别对应软组织和骨板上表面的分界面以及骨板下表面和软组织的分界面. 因超声存在衰减, 第二回波的幅度明显小于第一回波. 图7(c)为第一个阵元发射时, 前30个通道的接收信号, 因回波信号到达各个阵元的路径不同, 通道间波形存在延时. 由压缩感知计算各通道间接收延时参数, 并对相应信号进行延时调整, 结果如图7(d)所示. 与图7(c)对比可得, 调整后信号的第一回波延时已对齐, 从而可进行后续图像重建. 图 7 实验结果 (a)压缩感知前30个基底; (b)单通道接收信号; (c)单次发射全部通道接收信号; (d)压缩感知调整的单次发射全部通道接收信号 Figure7. Experiment results: (a) The first 30 bases of compressed sensing; (b) received signal of single element; (c) received signals of all elements; (d) compressed sensing based temporally adjusted received signals of all elements.
图8为采用PSM算法对实验数据进行图像重建的结果, 图8(a)与图8(b)分别对应未建立声速模型的重建图像以及基于多层声速模型的重建图像. 如图8(a)所示, 虽可看到清晰的上下骨板界面, 但由于没有进行声速矫正, 骨板厚度存在误差, 平均骨板厚度约为1.8 mm, 相对误差47.1%, 形态重建不准确. 而多层声速模型的应用实现了准确的板厚成像. 对同一骨板进行重复实验, 估计得到平均骨板厚度约为3.5 mm, 平均相对误差为3.6%, 方差为5.4%. 可见声速模型可实现较为准确的骨板成像. 图 8 实验重建结果 (a)未建立声速模型的实验重建结果; (b)建立声速模型的实验重建结果 Figure8. Experiment reconstructed results: (a) Experiment reconstructed result without velocity model; (b) experiment reconstructed result with velocity model.
4.讨论部分由于皮质骨和软组织间显著的声速差异, 传统超声波束形成无法应用于骨成像, 建立正确声速模型是解决声速差异问题的关键. 目前仿真及实验中声速模型的建立需要事先测量真实骨板尺寸, 声速模型的实际应用受到限制. 因此本文提出了基于压缩感知建立声速模型的方法, 通过压缩感知计算延时参数从而在未测量骨板尺寸的情况下建立较为准确的声速模型. 图9比较了压缩感知和Hilbert变换提取延时的结果. 图9(a)中黑线表示原始信号, 原始信号由两个不同延时的发射脉冲叠加组成, 红线为信噪比20 dB的带噪信号. 图9(b)为压缩感知提取结果, 其中峰值对应发射脉冲起始点. 图9(c)为Hilbert变换提取结果, 其中峰值对应发射脉冲包络顶点. 比较图9(b)和图9(c)可知, 压缩感知的提取结果受噪声影响较小, 延时提取准确, 而Hilbert变换在有噪声条件下提取的信号峰值相比无噪声条件下发生了显著的偏移. 压缩感知是一个求解最优解的过程, 在计算中允许误差项存在, 因此压缩感知法比Hilbert变换更适用于有噪声条件下的延时估计. 且压缩感知提取结果对应脉冲起始点, 可直接用于波形到达时间的计算. 皮质骨仿真和实验结果均验证了压缩感知提取延时的准确性, 厚度估计的相对误差分别为4.9%和3.6%. 如图6(b)和图8(b)所示, 建立声速模型的仿真重建结果和实验重建结果均可以看到清晰的皮质骨上下界面, 且相比图6(a)和图8(a)未建立声速模型的结果, 皮质骨重建厚度准确. 与仿真重建结果比较, 实验重建结果存在明显伪影, 这是实验过程中存在噪声干扰导致的. 图 9 压缩感知与Hilbert变换比较 (a)原始信号及带噪信号; (b)针对原始信号和带噪信号的压缩感知结果; (c)针对原始信号和带噪信号的Hilbert变换结果 Figure9. Comparison of compressed sensing and Hilbert transform: (a) Origin signal and noisy signal; (b) result of compressed sensing; (c) result of Hilbert transform.
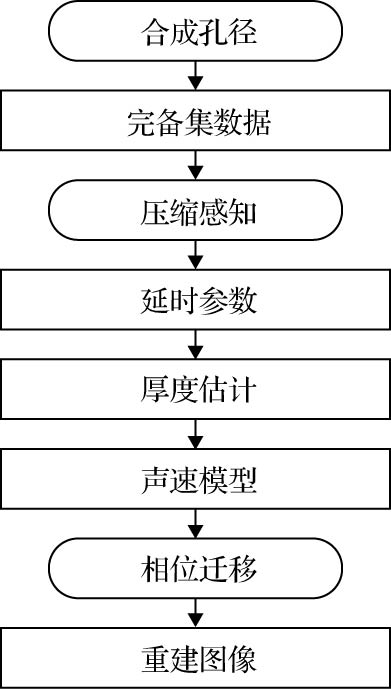 图 1 方法流程图
图 1 方法流程图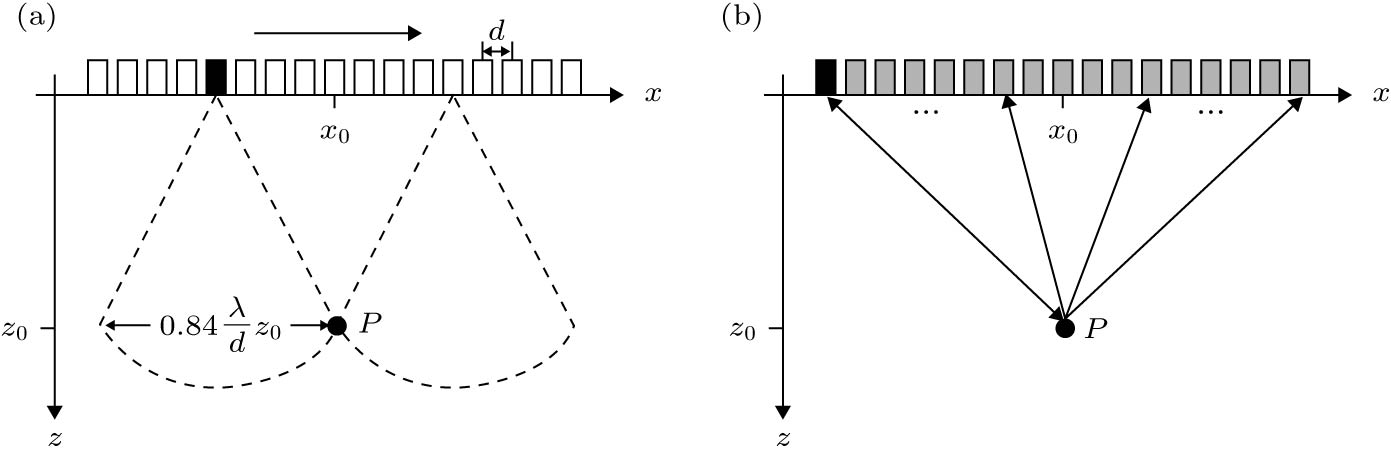 图 2 合成孔径超声原理 (a)合成孔径聚焦; (b)发射合成孔径
图 2 合成孔径超声原理 (a)合成孔径聚焦; (b)发射合成孔径














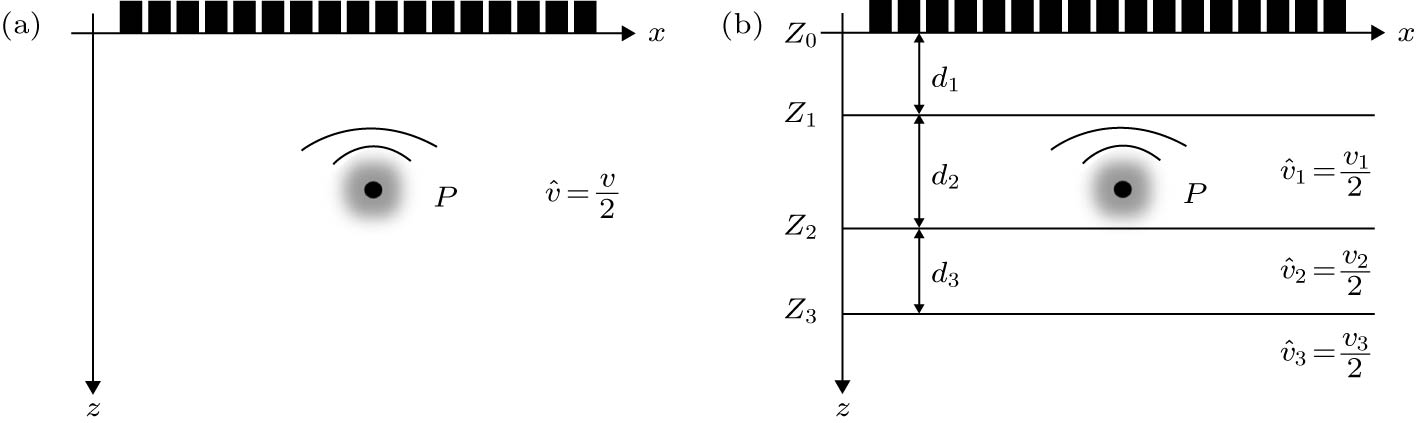 图 3 PSM模型 (a)单层介质模型; (b)多层介质模型
图 3 PSM模型 (a)单层介质模型; (b)多层介质模型

























 图 4 实验装置示意图
图 4 实验装置示意图
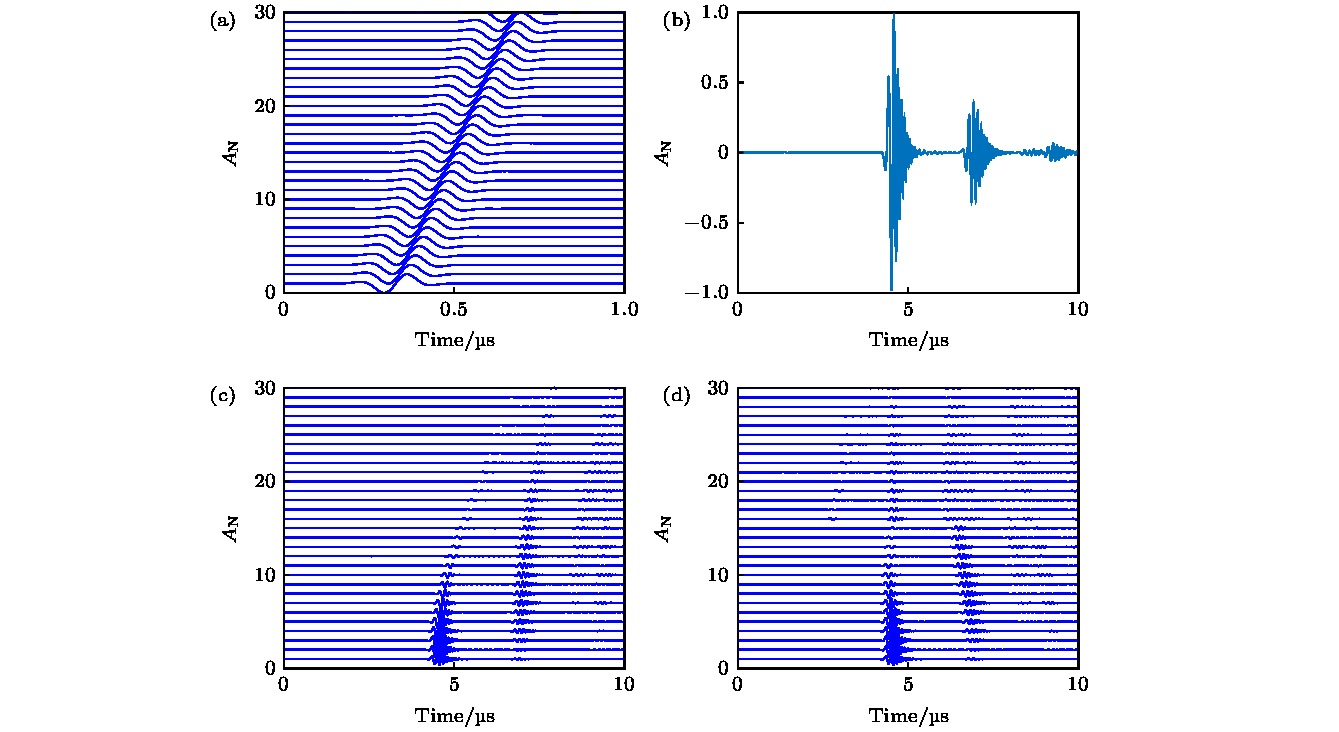 图 5 仿真结果 (a)压缩感知前30个基底; (b)单通道接收信号; (c)单次发射全部通道接收信号; (d)压缩感知调整的单次发射全部通道接收信号
图 5 仿真结果 (a)压缩感知前30个基底; (b)单通道接收信号; (c)单次发射全部通道接收信号; (d)压缩感知调整的单次发射全部通道接收信号 图 6 仿真重建结果 (a)未建立声速模型的仿真重建结果; (b)建立声速模型的仿真重建结果
图 6 仿真重建结果 (a)未建立声速模型的仿真重建结果; (b)建立声速模型的仿真重建结果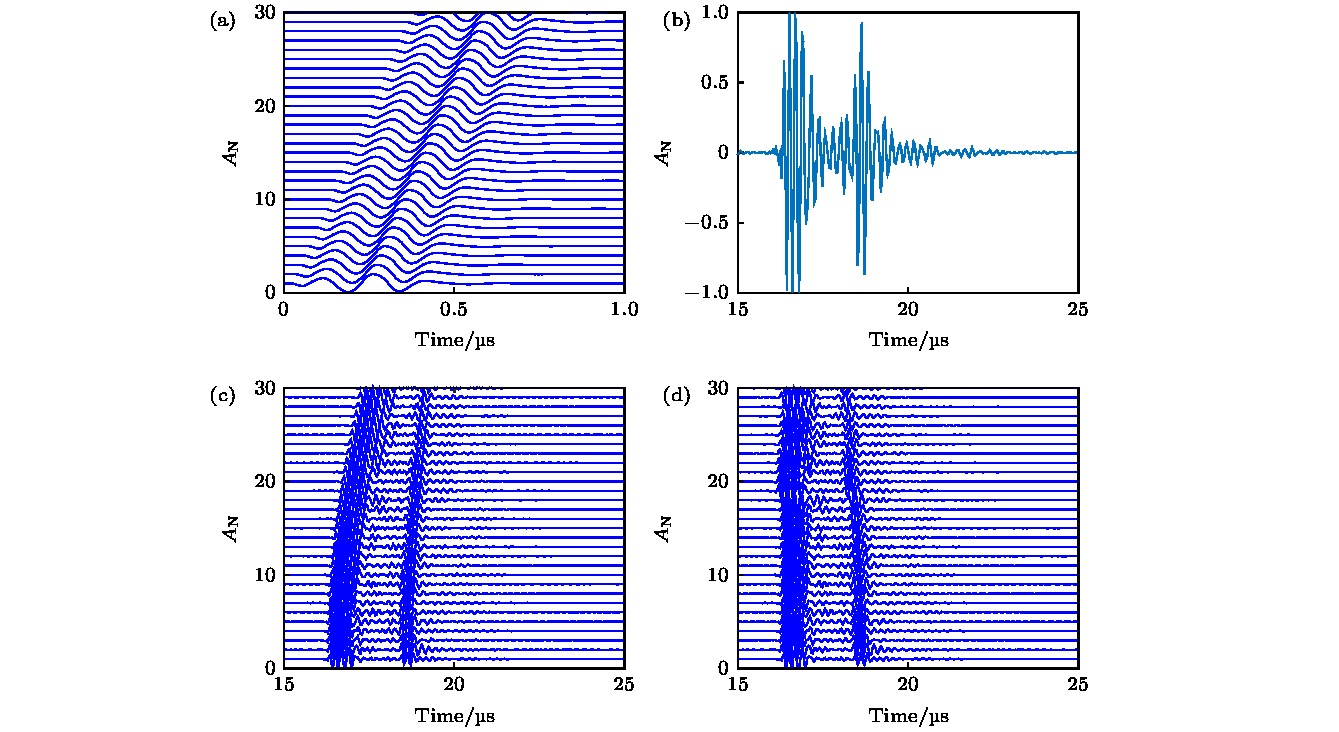 图 7 实验结果 (a)压缩感知前30个基底; (b)单通道接收信号; (c)单次发射全部通道接收信号; (d)压缩感知调整的单次发射全部通道接收信号
图 7 实验结果 (a)压缩感知前30个基底; (b)单通道接收信号; (c)单次发射全部通道接收信号; (d)压缩感知调整的单次发射全部通道接收信号 图 8 实验重建结果 (a)未建立声速模型的实验重建结果; (b)建立声速模型的实验重建结果
图 8 实验重建结果 (a)未建立声速模型的实验重建结果; (b)建立声速模型的实验重建结果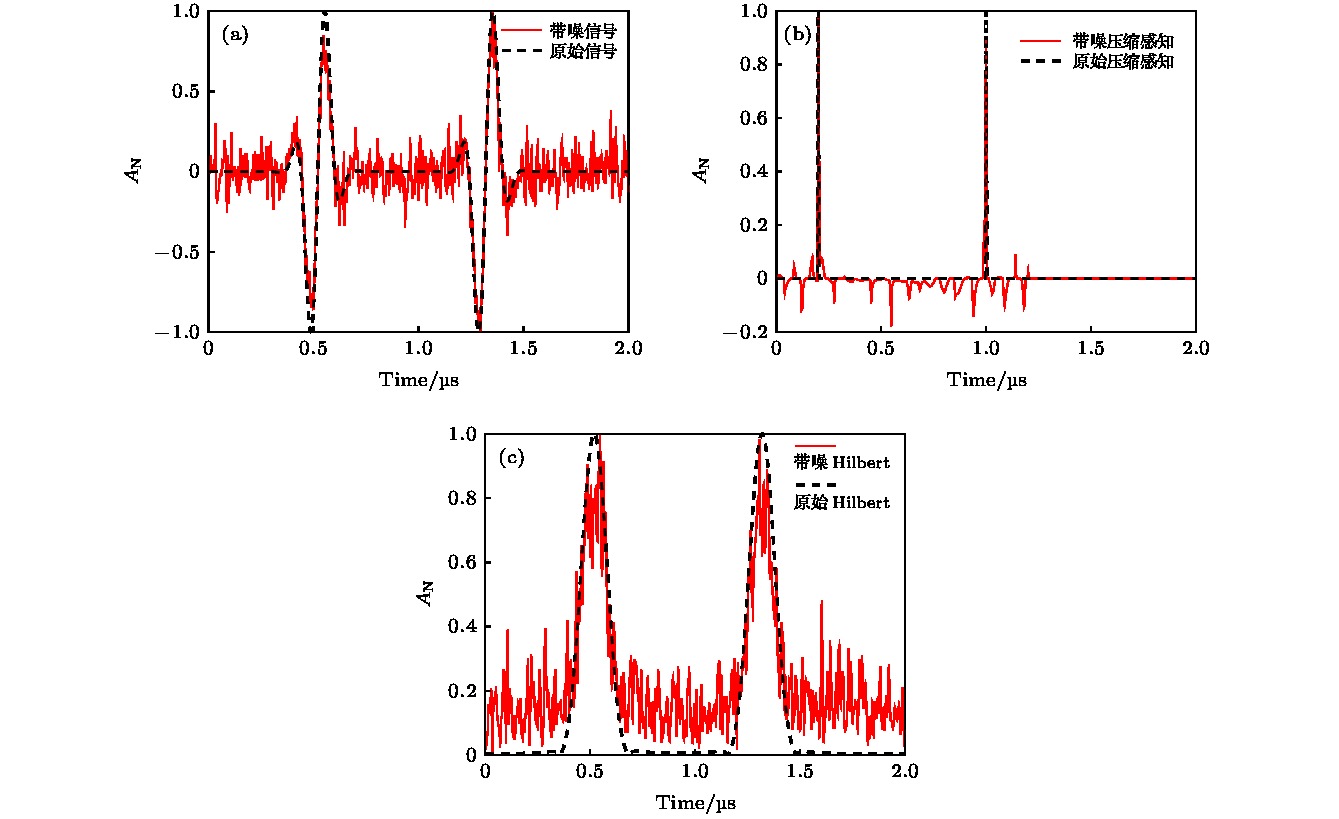 图 9 压缩感知与Hilbert变换比较 (a)原始信号及带噪信号; (b)针对原始信号和带噪信号的压缩感知结果; (c)针对原始信号和带噪信号的Hilbert变换结果
图 9 压缩感知与Hilbert变换比较 (a)原始信号及带噪信号; (b)针对原始信号和带噪信号的压缩感知结果; (c)针对原始信号和带噪信号的Hilbert变换结果