摘要: 利用指数加权在线核序列极限学习机(exponential weighted online sequential extreme learning machine with kernel, EW-KOSELM)辨识算法, 开展了针对混沌动力学系统的动态重构研究. EW-KOSELM算法将核递归最小二乘(kernel recursive least squares, KRLS)算法直接延伸至在线ELM (extreme learning machine)框架中, 通过引入遗忘因子削弱了旧数据的影响, 并基于“固定预算(fixed-budget, FB)”内存技术, 应对在线核学习算法所固有的规模不断增长的计算困难. 将所提辨识算法应用于Duffing-Ueda振子的混沌动力学系统数值仿真实例中, 对基于FB-EW-KOSELM的辨识模型与原系统的动态性能进行了定性与定量的分析校验, 定性校验准则是基于对比辨识模型与原系统吸引子(轨迹嵌入)、庞加莱映射、分岔图、极限环完成的, 定量校验准则包括对比辨识模型与原系统的李雅普诺夫指数与关联维. 进一步将其分别应用于来自测量蔡氏电路产生双涡卷吸引子与螺旋吸引子的实测数据实验及某一实际混沌电路所产生的时间序列中, 对于具有低信噪比的实测电压或电流数据还需进行了小波降噪预处理. 通过分析辨识模型重构吸引子, 实验结果表明, FB-EW-KOSELM算法具有良好的动态重构性能, 能精确地再生出展示混沌动态行为的过程非线性模型, 且具有与原混沌系统非常接近的动态不变性指标.
关键词: 动态重构 /
混沌系统 /
核方法 /
指数加权在线序列极限学习机 English Abstract Dynamic reconstruction of chaotic system based on exponential weighted online sequential extreme learning machine with kernel Li Jun Hou Xin-Yan School of Automation and Electrical Engineering, Lanzhou Jiaotong University, Lanzhou 730070, China. Fund Project: Project supported by the National Natural Science Foundation of China (Grant No. 51467008) and Key Laboratory of Opto-Technology and Intelligent Control, Ministry of Education (Lanzhou Jiaotong University) (Grant No. KFKT2016-3).Received Date: 27 January 2019Accepted Date: 18 March 2019Available Online: 01 May 2019Published Online: 20 May 2019Abstract: For the dynamic reconstruction of the chaotic dynamical system, a method of identifying an exponential weighted online sequential extreme learning machine with kernel(EW-KOSELM) is proposed. The kernel recursive least square (KRLS) algorithm is directly extended to an online sequential ELM framework, and weakens the effect of old data by introducing a forgetting factor. Meanwhile, the proposed algorithm can deal with the ever-increasing computational difficulties inherent in online kernel learning algorithms based on the ‘fixed-budget’ memory technique. The employed EW-KOSELM identification method is firstly applied to the numerical example of Duffing-Ueda oscillator for chaotic dynamical system based on simulated data, the qualitative and quantitative analysis for various validation tests of the dynamical properties of the original system as well as the identification model are carried out. A set of qualitative validation criteria is implemented by comparing chaotic attractors i.e. embedding trajectories, computing the corresponding Poincare mapping, plotting the bifurcation diagram, and plotting the steady-state trajectory i.e. the limit cycle between the original system and the identification model. Simultaneously, the quantitative validation criterion which includes computing the largest positive Lyapunov exponent and the correlation dimension of the chaotic attractors is also calculated to measure the closeness i.e. the approximation error between the original system and the identification model. The employed method is further applied to a practical implementation example of Chua's circuit based on the experimental data which are generated by sampling and recording the measured voltage across a capacitor, the inductor current from the double-scroll attractor, the measured voltage across a capacitor from the Chua's spiral attractor and an experimental time series from a chaotic circuit. The digital filtering technique is then used as a preprocessing approach, on the basis of wavelet denoising the measured data with lower signal-noise ratio (SNR) which can produce the double-scroll attractor or the spiral attractor, the reconstruction attractor of the identification model is compared with the reconstruction attractor from the experimental data for original system. The above experimental results confirm that the EW-FB-KOSELM identification method has a better performance of dynamic reconstruction, which can produce an accurate nonlinear model of process exhibiting chaotic dynamics. The identification model is dynamically equivalent or system approximation to the original system.Keywords: dynamic reconstruction /chaotic system /kernel method /exponential weighted online sequential extreme learning machine 全文HTML --> --> --> 1.引 言 对于许多非线性系统, 尤其是混沌动力系统而言, 通常在一定程度上需要建立精确、完美的数学模型, 但模型的求解却十分困难, 需要对混沌系统的复杂结构和隐含特征参数进行分析和研究[1 ] . 因此, 在控制混沌等复杂非线性动力系统之前, 进行系统辨识也是重要甚至必要的步骤之一, 这可以体现在对混沌系统的动态重构[2 -6 ] 研究上, 即混沌动力系统的吸引子可以通过其状态空间中的状态变量演化而得到. 当未知混沌动力系统中的每个状态变量的演化过程均可获得, 就可以利用全局状态变量的观测值逼近该混沌系统, 这种混沌系统的全局建模和逼近方法构成一个多维输入、多维输出的复杂非线性系统辨识问题. 然而, 描述混沌动力系统状态演化的所有状态变量往往未知, 对实际观测而言, 有时仅可获得系统状态变量之一的输出, 即往往得到一组含有噪声的时间序列, 表示系统的某个状态变量随时间演化的过程. 此时, 从可获得的一组含有噪声的时间序列值中, 利用Takens 的延迟-嵌入定理, 则可构造出一个非线性映射, 即时间序列预测模型, 去逼近未知的多维非线性混沌系统.[7 -10 ] 、模糊逻辑[11 ] 、支持向量机[6 ,12 ] 以及小波分析[13 ,14 ] 、非线性滤波器[15 ,16 ] 等算法, 常常被用于混沌动力学系统的动态重构研究中, 作为混沌序列预测或混沌动态重构的辨识模型表示, 已取得了成功应用.14 ]给出了一种多分辨率的离散小波算法, 应用于混沌动力学系统辨识中, 从描述系统动态不变性的定性与定量指标方面的比较, 验证了该算法的有效性. 文献[17 ]给出了一种小波核偏最小二乘回归算法, 成功应用于混沌系统建模中, 但仅体现出辨识模型与原系统之间的“函数逼近”关系, 未能从混沌系统内在的动态不变性指标方面表明辨识模型与原系统之间的“系统逼近”关系.[18 ] 是一种基于单隐层前馈神经网络(single-hidden layer feedforward neural networks, SLFNs)的快速学习算法, 由于其网络结构由隐含层节点数随机确定, 网络输入权值及隐含层节点参数也是随机给定. 训练时采用正则化最小二乘算法仅需考虑调节网络的输出权值, 从而极快地提高网络训练速度. 在ELM基础上, 文献[19 ]提出了在线序列极限学习机(online sequential extreme learning machine, OS-ELM)算法, 该算法的在线顺序学习能力使得它能够及时地适应环境的动态变化, 增强了模型的适应能力. 由于ELM类的精度与其隐含节点的关系较为敏感, 为避免该问题, 核极限学习机(kernel extreme learning machine, KELM)算法仅以核函数表示未知的隐含层非线性特征映射, 无需选择隐含层的节点数目, 通过正则化最小二乘算法计算网络的输出权值. 文献[20 ]将核递归最小二乘(kernel recursive least squares, KRLS)算法延伸至OS-ELM框架中, 给出了一种KOS-ELM算法, 并已成功应用于基准分类与回归数据集中, 包括混沌时间序列预测. 随着数据集的增大, 核矩阵的计算也会变得较为困难, 为解决该问题, 一些稀疏化准则如近似线性依赖(approximate linear dependence, ALD)准则等被提出并应用于核在线学习算法中, 基于固定预算技术, 文献[21 ]还提出了一种FB-KRLS算法, 在保持一定建模精度的基础上, 通过限制矩阵大小, 有效地解决了矩阵计算困难的问题.14 ]使用多分辨率小波分析算法在混沌动力学系统辨识中的成功应用, 考虑到KOS-ELM, FB-KRLS等算法在回归与在线建模中的优势, 进一步考虑到通过引入遗忘因子, 削弱旧数据对算法性能的影响, 以提高模型的精度[22 ] , 本文提出一种FB-EW-KOSELM算法, 将其应用于混沌系统的动态重构中, 预测混沌动力学系统动态行为的定性变化, 并从结构稳定性方面分析辨识模型与混沌系统的“动态等价”. 具体包括将FB-EW-KOSELM算法用于周期驱动力作用下的Duffing-Ueda振子混沌系统动态重构中, 定性与定量地分析重构吸引子与原模型的内在特性, 从庞加莱映射、李雅普诺夫指数、关联维数、分岔图等多方面衡量二者之间的“动态等价”特性; 将该算法应用于产生蔡氏电路双涡卷及螺旋涡卷吸引子的实测数据实例中, 通过对辨识模型重构吸引子与原系统吸引子的比较分析, 以验证本文算法的有效性; 此外还将该算法应用于混沌电路的实测数据实例中, 通过对比辨识模型重构吸引子与原系统的吸引子, 以及混沌电路所产生的电压值时间序列与辨识模型重构的电压值时间序列, 进一步验证该算法的有效性.2.FB-EW-KOSELM算法 22.1.核极限学习机与在线极限学习机的算法构造 2.1.核极限学习机与在线极限学习机的算法构造 给定$N$ 组训练样本数据集${{S}} = \left\{ { \left( {{{{u}}_j},{y_j}} \right)} \right\} _{j = 1}^N$ , 其中${{{u}}_j}$ 是输入向量, ${y_j}$ 是相应的标量输出. 对于节点激活函数为$h\left( {{u}} \right)$ , 隐含层节点数为L , 具有单输出的标准单层前馈神经网络(SLFN), 其网络节点的输出为${{{\varpi}} _i}$ 是连接输入层与第$i$ 个隐含层节点之间的权值向量; ${{\theta}} $ 为连接输出层与第$i$ 个隐含层节点之间的权值向量, 即${{\theta}} = {\left[ {{\theta _1}, \ldots,{\theta _L}} \right]^{\rm T}}$ ; ${b_i}$ 是第$i$ 个隐含层节点的阈值. 记$h\left( {{{u}};{{{\varpi}} _i},{b_i}} \right)$ 为${h_i}\left( {{u}} \right)$ , 则${{h}}\left( {{u}} \right) = {\left[ {{h_1}\left( {{u}} \right), \ldots,{h_L}\left( {{u}} \right)} \right]^{\rm{T}}} \in {{{R}}^{L \times N}}$ 为ELM的特征向量.${{\theta}} $ 的估计问题. 考虑到${l_2}$ 范数的正则化问题求解, 即有${{H}} = \left[ {{{h}}\left( {{{{u}}_1}} \right), \ldots,{{h}}\left( {{{{u}}_N}} \right)} \right]$ , $\eta $ 是正则化参数, 输出向量${{y}} = {\left[ {{y_1}, \ldots,{y_N}} \right]^{{\rm{T}}}} \in {{{R}}^{N \times 1}}$ , 单位阵${{{I}}_N}$ 大小为$N \times N$ .${{h}}\left( {{u}} \right)$ 未知时, 定义核矩阵:${{{\varOmega}} _{ij}} = k\left( {{{{u}}_i},{{{u}}_j}} \right)$ .1 )式和(2 )式, 并考虑到${{h}}\left( {{{{u}}_j}} \right){{{H}}^{\rm T}} = \left[ {\begin{array}{*{20}{c}} {k\left( {{{{u}}_j},{{{u}}_1}} \right)} \\ \vdots \\ {k\left( {{{{u}}_j},{{{u}}_N}} \right)} \end{array}} \right]$ , KELM的输出函数为${{{k}}_N}\!\left( {{u}} \right)\! =\! {\left[ {k\left( {{{u}},{{{u}}_1}} \right), \ldots,k\left( {{{u}},{{{u}}_N}} \right)} \right]^{{\rm{T}}}}$ , ${{\alpha}} \!=\!(\eta {{{I}}_N} +$ ${{\varOmega})^{ - 1}}{{y}}$ .2 )式中逆矩阵的在线计算, 文献[19 ]提出了一种OS-ELM算法. 假定数据集${{S}}$ 由$n$ 个最小批次连续的${{{S}}_i}$ 组成的, 即${{S}} = \bigcup\nolimits_{i = 1}^n {{{{S}}_i}} $ , 并用${{{H}}_i}$ , ${{{y}}_i}$ 分别表示第$i$ 批最小批次数据所对应的隐含层节点矩阵及输出向量, 则权值向量${{\theta}} $ 的初始化设置应为$i + 1$ 批数据到来时, 权值的更新为6 )式看出该算法等价于将递归最小二乘(recursive least squares, RLS)算法直接应用于ELM的特征向量${{h}}\left( {{u}} \right)$ , 因此与RLS算法具有同样的收敛性.2.2.EW-KOSELM在线学习算法的设计与实现 -->2.2.EW-KOSELM在线学习算法的设计与实现 RLS算法是线性自适应滤波算法中最常见的算法之一, 这种算法以最小二乘准则为依据, 其主要优点是收敛速度快, 将其扩展至非线性特征空间, 可形成KRLS算法, 其优点是算法的收敛速度比核最小均方算法(kernel least mean square, KLMS)通常快一个数量级. 将KRLS算法直接用于(4 )式所示的KELM算法的在线学习中, 则可形成在线核序列极限学习机(online sequential extreme learning machine with kernel, KOSELM)算法. 为削弱旧数据对模型性能的影响, 还可通过引入遗忘因子提高模型的预测能力, 从而形成指数加权在线核序列极限学习机(exponential weighted online sequential extreme learning machine with kernel, EW-KOSELM)算法. 由指数加权递归最小二乘(exponentially weighted recursive least squares, EW-RLS)算法可知, 在每次迭代过程中, 权值向量${{{\theta}} _t}$ 应满足目标函数${{J}}\left( {{{{\theta}} _t}} \right)$ 的极小值:$\beta $ 为遗忘因子,${{ B}_t} = \left[ {\begin{array}{*{20}{c}} {{\beta ^{t - 1}}}&0& \cdots &0 \\ 0&{{\beta ^{t - 2}}}& \cdots &0 \\ \vdots & \vdots & \ddots &0 \\ 0&0& \cdots &1 \end{array}} \right]$ , ${{{y}}_t} \!=\! {\left[ {{y_1},{y_2}, \ldots,{y_t}} \right]^{{\rm{T}}}}$ , ${{{\varPhi}} _t}\! =\! \left[ {\phi \left( {{{{u}}_1}} \right)\;\phi \left( {{{{u}}_2}} \right)\; \ldots \;\phi \left( {{{{u}}_t}} \right)} \right]$ . 由(7 )式获得${{{\theta}} _t}$ 的最优解为${{{\theta}} _t}$ 可以表示为输入数据的线性组合, 即${{{\theta}} _t} = \sum\limits_{i = 1}^t {{\alpha _i}{{\varPhi}} } \left( {{{{u}}_i}} \right) = {{{\varPhi}} _t}{{{\alpha}} _t}$ . ${{{\alpha}} _t}$ 可以看作系数向量. 由(8 )式可知9 )式中${{{Q}}_t}$ 的递推计算同样可以基于“核技巧”. 参考KRLS算法的实现[23 ] , 对于序列数据$({{{u}}_t},{y_t}),$ $t = 1, \ldots,N$ , EW-KOSELM算法的实现步骤为:$\eta $ 、核参数$\sigma $ 、遗忘因子$\beta $ ;$t \!=\! 1$ , 计算${{{Q}}_1} \!=\! {\left[ {\eta \beta \!+\! k\left( {{{{u}}_1},{{{u}}_1}} \right)} \right]^{ - 1}}$ 以及系数向量${{{\alpha}} _1} = {{{Q}}_1}{y_1}$ ;$t = t + 1$ , 计算${{{k}}_{t - 1}}\left( {{{{u}}_t}} \right) = \left[k\left( {{{{u}}_1},{{{u}}_t}} \right),\right.$ $\left.k\left( {{{{u}}_2},{{{u}}_t}} \right), \ldots,k\left( {{{{u}}_{t - 1}},{{{u}}_t}} \right) \right]^{{\rm{T}}}$ ;${{{z}}_t} = {{Q}}_{t - 1}^{}{{{k}}_{t - 1}}\left( {{{{u}}_t}} \right)$ , ${r_t} = \lambda {\beta ^t} + $ $ k( {{{u}}_t},{{{u}}_t}) -{{z}}_i^{{\rm{T}}}{{{k}}_{t - 1}}\left( {{{{u}}_t}} \right)$ ;${{Q}}_t^{} = r_t^{ - 1}\left[ {\begin{array}{*{20}{c}} {{{Q}}_{t - 1}^{}{r_t} + {{{z}}_t}{{{z}}_t^{{\rm{T}}}}}&{ - {{{z}}_t}} \\- {{{z}}_t^{{\rm{T}}}}&1 \end{array}} \right]$ ;${e_t} = {y_t} - {{k}}_{t - 1}^{{\rm{T}}}\left( {{{{u}}_t}} \right){{{\alpha}} _{t - 1}}$ , 更新系数向量${{{\alpha}} _t} = \left[ {\begin{array}{*{20}{c}} {{{{\alpha}} _{t - 1}} - {{{z}}_t}r_t^{ - 1}{e_t}} \\{r_t^{ - 1}{e_t}} \end{array}} \right]$ ;9 )式中的${{{\alpha}} _t}$ , 但随着数据的不断增加, 矩阵也会无限增长. 可以通过限制数据“字典”的大小, 基于ALD准则, “滑动窗口”, “固定预算”等技术, 有效减少${{{\alpha}} _t}$ 的运算量. 假设在获取$t$ 时刻之前的训练数据后, 由训练数据的子集可构成字典${{{D}}_{t - 1}} = \{ {{\tilde {{u}}}_j}\} _{j = 1}^{{m_{t - 1}}}$ , 若$\phi \left( { \cdot } \right)$ 为特征映射, 将输入${{\tilde {{u}}}_j}$ 映射至高维特征空间F $\left\{ { \phi \left( {{{\tilde {{u}}}_j}} \right)} \right\} _{j = 1}^{{m_{t - 1}}}$ , 由ALD稀疏化准则保证其元素的近似线性独立[23 ] . “固定预算”技术则采用主动学习策略构建“字典”, 仅考虑“固定内存”中所存储的M 个数据, 算法在每次时间更新时, 并不“修剪”最旧的数据, 而是旨在“修剪”最无用的数据, 从而抑制核矩阵的不断增长, 使用固定预算技术的一种FB-KRLS算法实现可参见文献[21 ]. 将“固定预算”应用于EW-KOSELM算法中, 可形成FB-EW-KOSELM算法.$\left( {{{{u}}_t},{y_t}} \right),$ $t = 1, \ldots,N$ , 算法在第$t$ 次迭代时, 定义${{{\varPhi}} _t} = $ $ \left[ {\phi \left( {{{{u}}_1}} \right)\;\phi \left( {{{{u}}_2}} \right)\; \ldots \;\phi \left( {{{{u}}_t}} \right)} \right]$ , 令核矩阵${{{\varOmega}} _t} = {{{\varPhi}} _t}^{\rm{T}}{{{\varPhi}} _t}$ 及具有指数加权的正则化核矩阵${{K}_t} = \eta {\beta ^t}{ B}_t^{ - 1} + {{\varOmega} _t}$ . 若将新数据$\left( {{{{u}}_t},{y_t}} \right)$ 添加至内存中, 即对${{{K}}_{t - 1}}$ 增加一行及一列, 可得到扩充矩阵${{\mathop {{K}} \limits^ \smallsmile} _t}$ , 相应地可给出逆矩阵${{K}}_{t - 1}^{ - 1}$ 以及${\mathop {{K}} \limits^ \smallsmile} _t^{ - 1}$ :$g = {\left( {c - {{{b}}^{{\rm{T}}}}{{K}}_{t - 1}^{ - 1}{{b}}} \right)^{ - 1}}$ , $c = \eta {\beta ^t} + k\left( {{{{u}}_t},{{{u}}_t}} \right)$ , ${{b}} = {{{k}}_M}\left( {{{{u}}_t}} \right)$ ,${{{k}}_M}\left( {{{{u}}_t}} \right) = {\left[ {k\left( {{{\tilde {{u}}}_1},{{{u}}_t}} \right),k\left( {{{\tilde {{u}}}_2},{{{u}}_t}} \right), \ldots,k\left( {{{\tilde {{u}}}_M},{{{u}}_t}} \right)} \right]^{{\rm{T}}}}$ .$t$ 的取值大于$M$ 时, 需对存储在内存中的$M$ 个数据考虑误差丢弃准则, 也就是能够对矩阵${{\mathop {{K}} \limits^ \smallsmile} _t}$ 能够进行删除任意一行及一列的操作. 为完成此操作, 需要矩阵置换操作, 定义置换矩阵${{{P}}_i}$ , ${{{H}}_i}$ 分别为:${{{I}}_j}$ 为维数为j 的单位阵, ${{0}}$ 为相应维度的零矩阵, 且有${{{P}}_i}^{ - 1} = {{{P}}_i}$ , ${{{H}}_i}^{ - 1} = {{{H}}_i}^{\rm{T}}$ .${{\mathop {{K}} \limits^ \smallsmile} _t}$ 的第$i$ 行及$i$ 列被删除后, 记为${\mathop {{K}} \limits^ \smallsmile} _t^i$ , 则${\mathop {{K}} \limits^ \smallsmile} _t^i = {{{P}}_i}{{\mathop {{K}} \limits^ \smallsmile} _t}{{{P}}_i}$ , 且${\left( {{\mathop {{K}} \limits^ \smallsmile} _t^i} \right)^{ - 1}} = {{{P}}_i}{\mathop {{K}} \limits^ \smallsmile} _t^{ - 1}{{{P}}_i}$ , 若${\mathop {{K}} \limits^ \smallsmile} _t^i$ 删去其第1行及第1列的矩阵, 记为${{K}}_t^i$ . 为计算${\left( {{{K}}_t^i} \right)^{ - 1}}$ , 考虑由矩阵运算性质:11 )式可得${\left( {{{K}}_t^i} \right)^{ - 1}}$ , 应用置换矩阵${{{H}}_i}$ 的性质, 进一步得到M , 正则化参数$\eta $ , 遗忘因子$\beta $ , 核参数$\sigma $ ;$t = 1$ , 计算${{{K}}_1} = [ \eta \beta +$ $ k\left( {{{{u}}_1},{{{u}}_1}} \right)]$ , ${{K}}_1^{ - 1}$ , ${{{\alpha}} _1} = {{{K}}_1}^{ - 1}{{{y}}_1}$ ;$t = t + 1$ , 获取新数据$\left( {{{{u}}_t},{y_t}} \right)$ , 由(10 )式对${{{K}}_{t - 1}}$ 进行扩充操作, 以得到${{\mathop {{K}} \limits^ \smallsmile} _t}$ ;$t > M$ 时, 由误差丢弃准则[24 ] 舍弃最无意义的数据, 即${\alpha _i}$ 为向量${{{\alpha}} _t}$ 的第$i$ 个元素, ${\left[ {{\mathop {{K}} \limits^ \smallsmile} _t^{ - 1}} \right]_{i,i}}$ 表示矩阵${\mathop {{K}} \limits^ \smallsmile} _t^{ - 1}$ 对角线的第$i$ 个元素;13 )式, 计算$d\left( {{{{u}}_i},{y_i}} \right)$ , 并记录$d\left( {{{{u}}_i},{y_i}} \right)$ 最小的数据的索引号$J$ , 从内存中削减${{{u}}_J},{y_J}$ , 由式(12 )可获取${{K}}_t^{ - 1}$ .${{{\alpha}} _t} = {{{K}}_t}^{ - 1}{y_t}$ .3.混沌动力学系统的辨识实验及模型校验 本节实例中, 将FB-EW-KOSELM算法应用于Duffing-Ueda振子的混沌系统动态重构及实测蔡氏电路数据的吸引子重构实验中. 核函数采用如下的高斯核函数形式, 即$\sigma $ 为核参数.3.1.Duffing-Ueda振子的数值仿真及模型校验 3.1.Duffing-Ueda振子的数值仿真及模型校验 以Duffing-Ueda振子的非自治动力系统为例, 该系统由如下微分方程描述[25 ] :$\theta $ 为阻尼系数, $u\left( t \right)$ 为系统输入.${x_1} = y$ , ${x_2} = {\rm{d}}y/{\rm{d}}t$ , 则(15 )式的状态方程为$\theta = 0.1$ , 周期输入$u\left( t \right) = F\cos \left(\varOmega t\right)$ , 其中$F = 11$ , $\varOmega = 1$ . 此时为混沌动力学系统, 系统周期$T = 2{\text{π}} $ . 对(16 )式用龙格-库塔算法求解, 取积分间隔${\rm{d}}t = {\text{π}} /3000$ . 为使仿真获取的数据更接近实际, 利用信噪比$SNR\,=\,{\rm 10}\lg \left( {}^{\sigma _{y}^{2}}\!\!\diagup\!\!{}_{\sigma _{n}^{2}}\; \right)$ 公式, 其中${\sigma _y}$ 为信号$y\left( k \right)$ 的标准差, $\sigma _n^{}$ 为噪声$n\left( k \right)$ 的标准差, 在最终输出中加入标准差${\sigma _e} = 0.017$ , SNR 约为40 dB的高斯白噪声信号[26 ] . 按采样周期${T_{\rm{s}}} = {\text{π}} /50 \;{\rm{s}}$ 对输出数据采样, 产生1504个数据用于辨识实验.$f\left( \cdot \right)$ 为FB-EW-KOSELM模型, 辨识模型的输出为${\hat y}\left( k \right)$ , 输入向量为${\left[ {y\left( {k - 1} \right),y\left( {k - 2} \right),y\left( {k - 3} \right),u\left( {k - 1} \right)} \right]^{{\rm{T}}}}$ , 其中$k = 504$ 到$2003$ , 丢弃前500个数据, 目的是消除系统起始瞬态的影响, 即选取$1500$ 组数据作为训练数据集.$\sigma =32$ , 固定内存大小$M = 100$ , 遗忘因子$\beta = 0.995$ , 正则化参数$\eta = {10^{ - 3}}$ . 图1 给出了在训练过程中算法的均方误差收敛曲线, 可以看出, 随着训练数据的增加, 算法的收敛速度较快, 可以达到满意的精度.图 1 算法的均方误差收敛曲线Figure1. Convergence curve of MSE for FB-EW-KOSELM algorithm.17 )式的FB-EW-KOSELM辨识模型进行训练, 图2(a) 给出了原模型在未加噪声情形下的吸引子轨迹图, 图2(b) 给出了辨识模型所对应的重构吸引子轨迹图, 重构吸引子是辨识模型的输出所获取. 从图2 可看出, 显然, 在伪相平面上重构吸引子显现出的几何特征, 如整体形状、位置等与无噪声的原系统吸引子非常相像, 对比结果也初步表明了辨识模型的质量较好.图 2 Duffing吸引子(F = 11) (a)原模型; (b)辨识模型Figure2. Duffing attractor for F = 11 plotted using: (a)The original noise-free data; (b) the model predicted output.$\Phi \left( {{{x}}\left( t \right),{t_0}\;} \right)$ , 它依赖于初始条件${{x}}\left( {{t_0}} \right) = {{{x}}_0}$ , 系统的振荡周期为T , 周期性记录的轨迹位置可表示为:$P_N^k\left( {{x}} \right)$ 的收集, 即映射的轨迹$\left\{ {P_N^k\left( {{x}} \right)} \right\}_{k = 1}^\infty $ 称之为非自治系统的庞加莱映射或者庞加莱截面.18 )式可以看出${P_N}$ 上的一个固定点相应于系统流形上$T = 2{\text{π}} /\varOmega $ 的一个周期轨迹, 类似地, ${P_N}$ 上的k 个固定点体现了$k \times 2{\text{π}} /\varOmega $ 个谐波周期. 因此, 庞加莱映射揭示出的动态特性能被用于非线性模型的校验, 它能显示出关于系统局部动态变化和过渡到混沌状态的详细信息, 由庞加莱映射可以很容易地识别系统的准周期与混沌区域. 图3 给出了原混沌系统及辨识模型的庞加莱映射对比, 由图3 可知, 辨识模型与原系统的庞加莱映射非常相像, 显示出相同的分形结构, 这也进一步表明辨识模型已经抓住了原混沌系统的局部动态不变性.图 3 庞加莱映射(F = 11) (a)原模型; (b)辨识模型Figure3. The Poincare map(F = 11) for (a) the original system, (b) the identification model.15 )式所描述的实际系统对于控制参数的变化, 即驱动力幅值F 的变化所引起的结构稳定性变化. 因此, 实验中取F 在区间$\left[ {4.5,12} \right]$ 之间变化, 步长${\rm{\delta}} F = 0.01$ , 进一步给出原系统与辨识模型的分岔图, 通过比较判断系统的结构稳定. 分岔图能被看作是一系列压缩的庞加莱映射, 对于分岔图上的点$r$ 可定义为$I$ 为在区间范围变化的实数集, $0 \leqslant {t_0} \leqslant 2{\text{π}} /\varOmega $ , ${K_{\rm{ss}}}$ 为常数. 点$r$ 的选择以确保仿真时能消除系统的暂态影响. 实际中, 对于参数F 的每个取值, 在${t_i}$ 时刻将获取${n_{\rm{b}}}$ 个点用以绘制分岔图, 即${t_i}$ 的取值为图4 给出了原系统与辨识模型在${K_{\rm{ss}}} = 400$ , ${n_{\rm{b}}} = 15$ 时的分岔图比较, 由图4 看出, 系统显现出非常丰富的动力学行为变化, $F \in \left[ {4.5,4.9} \right]$ 及$F \in \left[ {11.6,12} \right]$ 时, Duffing-Ueda振子处于单周期运动状态, $F \in \left[ {4.9,5.5} \right]$ 时, Duffing-Ueda振子处于2倍周期运动状态, $F \in \left[ {5.5,5.8} \right]$ 及$F \in \left[ {9.9,11.6} \right]$ 时, Duffing-Ueda振子则处于混沌状态. 可以看出, 辨识模型与原系统的分岔图非常相像, 已经抓住了系统所有的主要全局不变量. 对于非自治系统而言, 分岔图与刻划系统局部不变量的庞加莱映射等相比, 对结构和参数的变化更敏感, 因此, 分岔图可更好地适用于模型校验, 这也进一步验证了FB-EW-KOSELM辨识模型的有效性.图 4 Duffing-Ueda振子的分岔图 (a)原模型; (b)辨识模型Figure4. Bifurcation diagram 4.5 ≤ F ≤ 12: (a) Original system; (b) identification model.图4 看出F = 8.5时, 辨识模型与原系统均处于稳定的极限环状态. 因此, 图5 进一步给出了二者的极限环比较, 可以看出辨识模型与原系统的极限环轨迹几乎匹配, 与分岔图所推断出的结果一致. 可见, 应用分岔图分析模型的优点在于对于不同的控制参数取值, 它对于研究系统的结构稳定性提供了唯一信息, 以更为便捷的方式抓住极限环的几何特征.图 5 F = 8.5时Duffing-Ueda振子的极限环 (a)原模型; (b)辨识模型Figure5. Limit cycle for F = 8.5: (a) Original system; (b) identification model.[25 ,27 ] , 在F = 11时, 取用于实验的1500个实际数据及辨识模型的输出数据1500个, 分别计算出原系统的最大正李雅普诺夫指数${\lambda _+ }=0.1757$ , 关联维数${D_{\rm{c}}} = 2.0339$ , 辨识模型的${\lambda _+ }=0.1754$ , ${D_{\rm{c}}} = 2.0330$ , 可见二者的动态不变性定量指标基本一致.3.2.蔡氏电路实测吸引子的动态重构实验及模型校验 -->3.2.蔡氏电路实测吸引子的动态重构实验及模型校验 考虑到蔡氏电路在混沌动态行为中的复杂性, 已有较多文献[28 ,29 ] 涉及该系统的非线性系统辨识研究, 并取得了较好的实验结果, 但数据的获取通常由系统的非线性解析模型数值仿真得到. 本节则通过产生双涡卷或螺旋涡卷吸引子的蔡氏电路实测数据[30 ] 对混沌动态行为进行辨识实验, 以进一步验证FB-EW-KOSELM算法的有效性. 蔡氏电路中非线性元件为双端分段线性的电阻所构成的“蔡氏二极管”, 它可由文献[31 ]所提出的双运算放大器配置方法进行构建. 蔡氏电路如图6(a) 和图6(b) 所示, 描述其动态特性的微分方程如下:图 6 (a)蔡氏电路; (b)蔡氏二极管(非线性电阻的配置)Figure6. (a)Chua’s circuit ; (b) Chua’s diode (nonlinear resistor implementation).${v_i}$ 为通过电容${C_i}$ 的电压, ${i_L}$ 为通过电感的电流, ${i_d}\left( {{v_1}} \right)$ 为通过“蔡氏二极管”的电流, 其大小为${B_{\rm{p}}}$ 为分段点; ${m_0},{m_1}$ 分别为各段的斜率, 对应的伏安特性曲线如图7 所示.图 7 蔡氏二极管的伏安特性曲线Figure7. Volt-ampere characteristic curve of Chua’s diode.图6 中的电容、电感元件取值分别为${C_1} = \left( {10 \pm 0.5} \right) {\rm{nF}}$ , ${C_2} = \left( {90 \pm 5} \right) {\rm{nF}}$ , $L=21 \pm $ 2% mH, 滑动变阻器R 的最大阻值为$2\;{\rm{k }}\Omega$ , 其中, 蔡氏二极管的实测参数${m_0} = \left( { - 0.37 \pm 0.04} \right)\;{\rm{mS}}$ , ${m_1} = \left( { - 0.37 \pm 0.04} \right)\;{\rm{mS}}$ , ${B_{\rm{p}}} = \left( {1.1 \pm 0.2} \right)\;{\rm{V}}$ . 取$ R \approx 1800 \;\Omega \; $ 或$ R \approx 1900 \;\Omega \; $ 时, 电路会产生双涡卷状吸引子或螺旋状吸引子, 实测数据最终由数字示波器收集获取. 因此, 采样时间、分辨率及数据的总量个数受限于仪器设备的特性, 采样时间的选择还基于相关函数而确定, 本文实验与文献[30 ]一致, 辨识实验分别针对这两种情形进行.图8 给出了基于实测数据, 对原系统进行重构的双涡卷吸引子及螺旋吸引子图, 其纵坐标的重构延迟参数与文献[30 ]一致, 选择采样间隔为4个数据. 在双涡卷状吸引子情形下, 采样时间${T_{\rm{s}}}$ = 4 μs, 分辨率8 bits时, 记录了电感电流${i_L}$ 共计15000个数据点, 重构吸引子如图8(a) 所示. 在${T_{\rm{s}}}$ = 12 μs, 分辨率13 bits时, 记录了电容电压${v_1}$ 共计5000个数据点, 重构吸引子如图8(b) 所示. 在螺旋状吸引子的情形下, 采样时间${T_{\rm{s}}} $ = 4 μs 分辨率8 bits时, 记录了电容电压${v_1}$ 共计15000个数据点, 其重构吸引子如图8(c) 所示.图 8 基于实测数据的蔡氏电路吸引子Figure8. Measured data on the attractor of Chua’s circuit: (a) Projection of the double scroll attractor, measures of ${i_L}$ ; (b) measures of ${v_1}$ ; (c) projection of the spiral attractor, measures of ${v_1}$ .图8(a) —(c) 所示的原始信号, 其信噪比估计值分别为47.5, 72.3和49.3 dB[30 ] . 图8(a) 中测量数据的低信噪比是由于测量电流信号时的霍尔效应所引起的, 图8(c) 中测量数据的较低信噪比则是由于低的数据采样分辨率引起. 实验中, 首先需进行提高实测数据信噪比的预处理, 对图8(a) 及图8(c) 的信号采用Daubechies小波基函数进行4次分解, 进行降噪处理. 其次, 以250 kHz的频率预处理后的数据进行采样, 以获取辨识用数据, 三种情形下均选择了其中的1500—2000个数据点. 辨识模型结构为$f\left( \cdot \right)$ 为FB-EW-KOSELM模型, $y\left( k \right)$ 信号可以为${v_1}$ , ${v_2}$ 或${i_{\rm{L}}}$ ,${n_y}$ 为模型阶次.14 )式形式的高斯核函数, 辨识阶次${n_y} = 5$ , 给定固定内存$M=100$ , 遗忘因子$\beta =0.995$ , 核参数$\sigma =16$ . 对于图8(a) 中电感电流信号, 选取正则化参数$\eta ={10^{ - 6}}$ , 使用 (23) 式进行辨识, 输出为$y\left( k \right)$ 的估计值$\hat y\left( k \right)$ , 输入向量为${\left[ {y\left( {k - 1} \right),y\left( {k - 2} \right),...,y\left( {k - 5} \right)} \right]^{{\rm{T}}}}$ , 其中$k = 1000-$ 2500, 即选取1500组数据作为训练数据集. 对于图8(b) 中的电容电压信号, 选取$\eta ={10^{ - 3}}$ , 同样使用(23 )式进行辨识, 其中$k = 3000-5000$ , 即选取2000组数据作为训练数据集. 对于图8(c) 中的电容电压信号, 选取$\eta ={10^{ - 3}}$ , 使用(23 )式进行辨识, 其中$k = 1000-2500$ , 选取1500组数据作为训练数据集.图9(a) —(c) 所示. 比较图9 与图8 相对应的重构吸引子可明显看出, 若实测数据的信噪比低, 需进行降噪预处理, 由FB-EW-KOSELM辨识模型所得到的重构吸引子能较好体现出与基于实测数据重构的原系统吸引子相吻合的几何特征, 实现了混沌动态重构.图 9 基于模型预测输出的蔡氏电路重构吸引子 (a)双涡卷吸引子iL ; (b) 双涡卷吸引子v 1 ; (c)螺旋吸引子v 1 Figure9. Chua's attractor reconstructed from the model predicted output: (a) iL on the double scroll attractor; (b)v 1 on the double scroll attractor; (c) v 1 on the spiral attractor3.3.非线性硬件电路实测数据的动态重构实验及模型校验 -->3.3.非线性硬件电路实测数据的动态重构实验及模型校验 为了进一步验证FB-EW-KOSELM算法的有效性, 本节物理实例的数据取自混沌状态下的电路[32 ] 如图10 所示, 图10 包含一个将电压输入$v\left( t \right)$ 转换为输出$\alpha f\left( {v\left( t \right)} \right)$ 的非线性放大器, $L=145\;{\rm{mH}}$ , $ r = 347\;\Omega \; $ , $C = 343\;{\rm{nF}}\;$ , ${C_1} = 225\;{\rm{nF}}$ , R 的最大值为$3.38\;{\rm K}\Omega \; $ . 定义$\delta = r\sqrt {C/L} $ , $\gamma = \sqrt {LC} /\left( {R{C_1}} \right)$ , $\tau = C/{C_1}$ , 描述该电路动态特性的微分方程如下:图 10 混沌电路的构成Figure10. Block diagram of the chaotic circuit.$v\left( t \right)$ 为电容$C$ 两端的电压, ${i_L}\left( t \right) = $ $\sqrt {L/C} i\left( t \right)$ , $i\left( t \right)$ 为通过电感$L$ 的电流, ${v_1}\left( t \right)$ 为电容${C_1}$ 两端的电压. 非线性映射${f\left( v \right)}$ 为32 ]一致, 取(24 )式中的参数$\alpha $ = 15.6, $\gamma $ = 0.294, $\tau $ = 1.52, $\delta $ = 0.534, 采样周期${T_{\rm{s}}} $ = 40 μs, 实测时间序列数据为$v$ 的输出, 共计8192个数据点. 图11(a) 给出了基于实测时间序列数据所重构的双涡卷吸引子, 若选择辨识模型结构为图 11 重构吸引子 (a)原模型; (b)辨识模型Figure11. Reconstructed attractor: (a) The original noise-free data; (b) the model predicted output.$f\left( \cdot \right)$ 为FB-EW-KOSELM模型, $y{\left( k \right)}$ 为电容电压$v$ , 辨识模型的输出为$\hat y{\left( k \right)}$ , 输入向量为${\left[ {y\left( {k - 1} \right),y\left( {k - 2} \right),...,y\left( {k - 5} \right)} \right]^{{\rm{T}}}}$ , 其中$k = 1000-$ 4000, 即选取3000组数据作为训练数据集.14 )式形式的高斯核函数, 固定内存$M=100$ , 遗忘因子$\beta =0.995$ , 核参数$\sigma =32$ , 正则化参数$\eta ={10^{ - 6}}$ . 基于辨识模型的重构吸引子如图11(b) 所示, 比较图11(a) 与 图11(b) 可明显看出, 由辨识模型得到的重构吸引子能很好体现出与原系统吸引子相吻合的几何特征, 实现了混沌动态重构. 进一步, 图12(a) 给出了前500个数据点的辨识模型输出与实测时间序列值的对比, 图12(b) 给出了二者之间的误差, 可以看出模型的辨识结果优于文献[31 ]的结果.图 12 (a)辨识模型输出与实测时间序列值输出结果; (b)辨识误差Figure12. (a) Identify model outputs and measured time series values; (b) the error between the model output and the measured value.4.结 论 鉴于FB-EW-KOSELM算法的非线性建模优点, 本文开展了基于FB-EW-KOSELM算法的混沌动力学系统辨识与重构研究, 将其分别应用于Duffing-Ueda振子的混沌动力学系统数值仿真、产生双涡卷及螺旋涡卷吸引子的蔡氏电路实测数据及混沌电路实测数据的物理实例中, 得到如下结论.32 ]的参数与非参数建模相比, 结果进一步表明了FB-EW-KOSELM辨识模型的有效性. 


































































































































































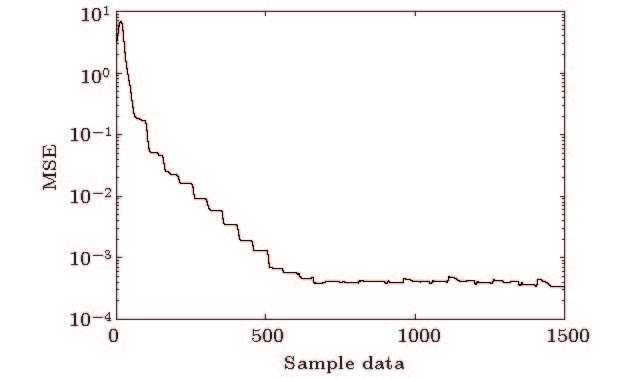 图 1 算法的均方误差收敛曲线
图 1 算法的均方误差收敛曲线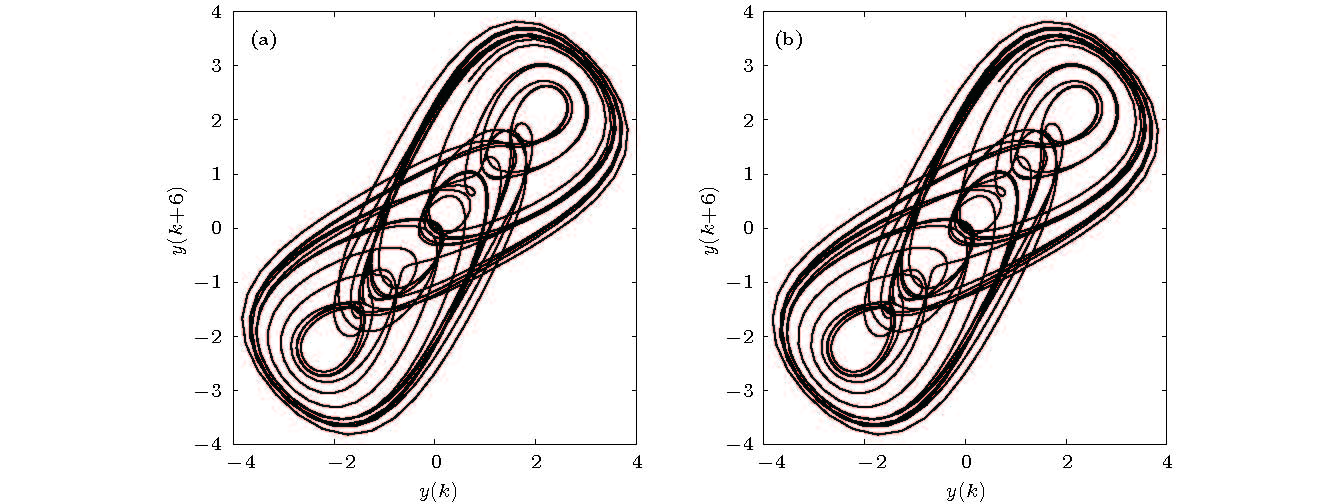 图 2 Duffing吸引子(F = 11) (a)原模型; (b)辨识模型
图 2 Duffing吸引子(F = 11) (a)原模型; (b)辨识模型







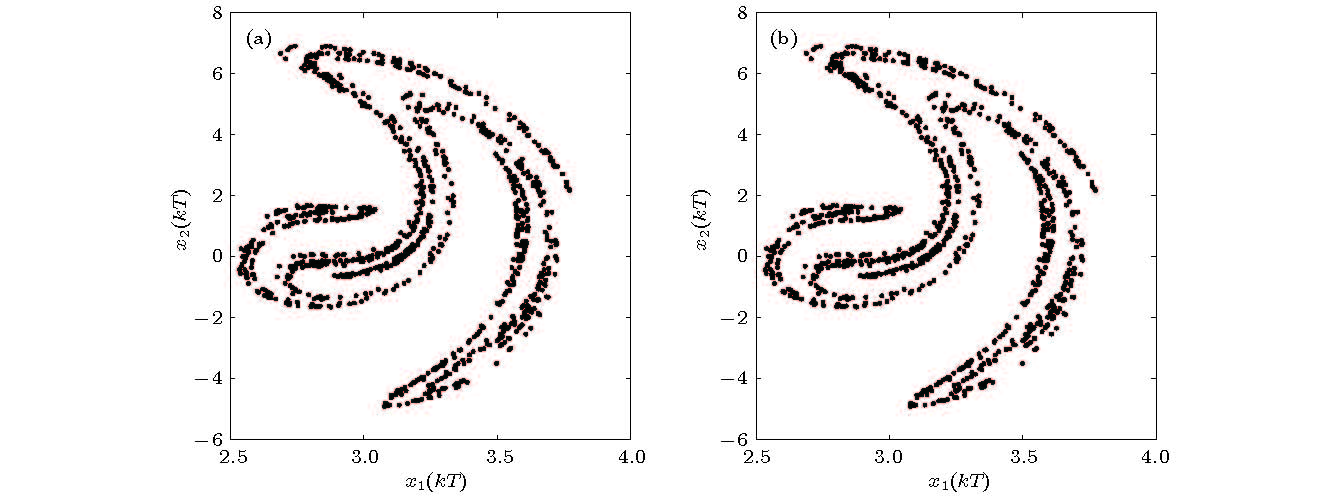 图 3 庞加莱映射(F = 11) (a)原模型; (b)辨识模型
图 3 庞加莱映射(F = 11) (a)原模型; (b)辨识模型
















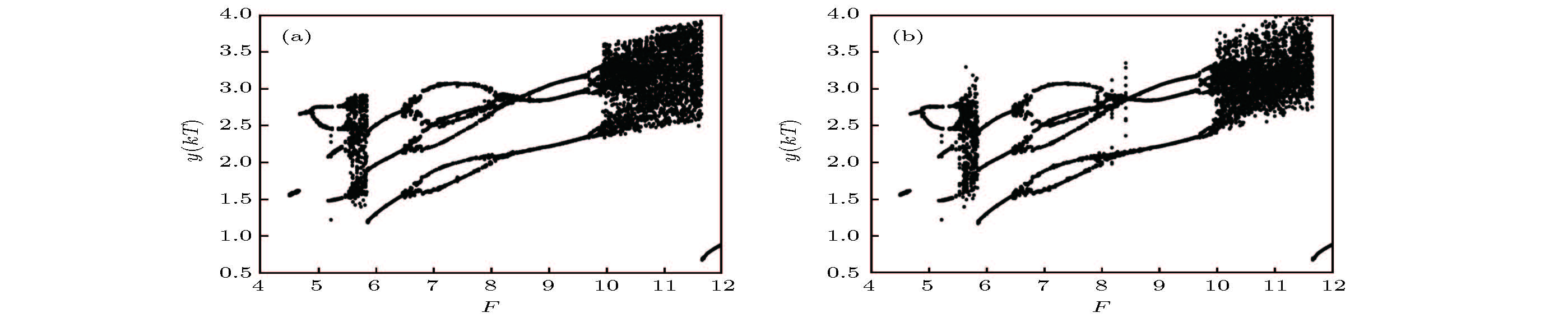 图 4 Duffing-Ueda振子的分岔图 (a)原模型; (b)辨识模型
图 4 Duffing-Ueda振子的分岔图 (a)原模型; (b)辨识模型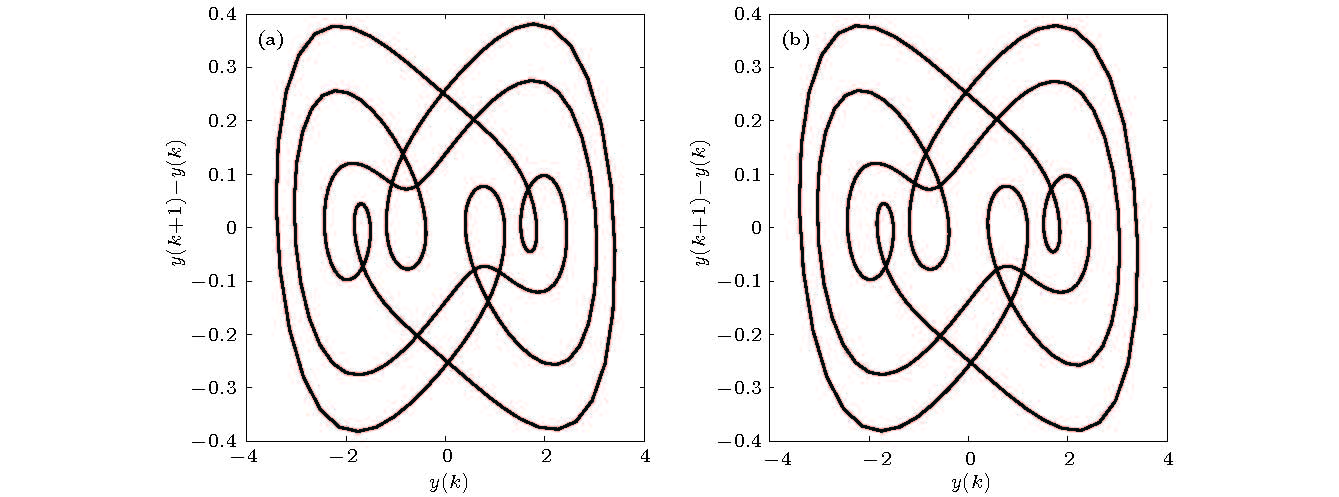 图 5 F = 8.5时Duffing-Ueda振子的极限环 (a)原模型; (b)辨识模型
图 5 F = 8.5时Duffing-Ueda振子的极限环 (a)原模型; (b)辨识模型



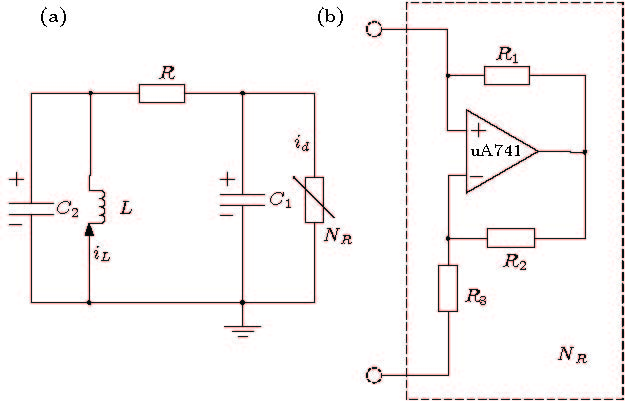 图 6 (a)蔡氏电路; (b)蔡氏二极管(非线性电阻的配置)
图 6 (a)蔡氏电路; (b)蔡氏二极管(非线性电阻的配置)





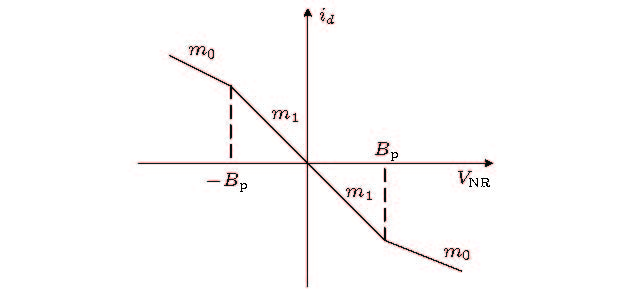 图 7 蔡氏二极管的伏安特性曲线
图 7 蔡氏二极管的伏安特性曲线














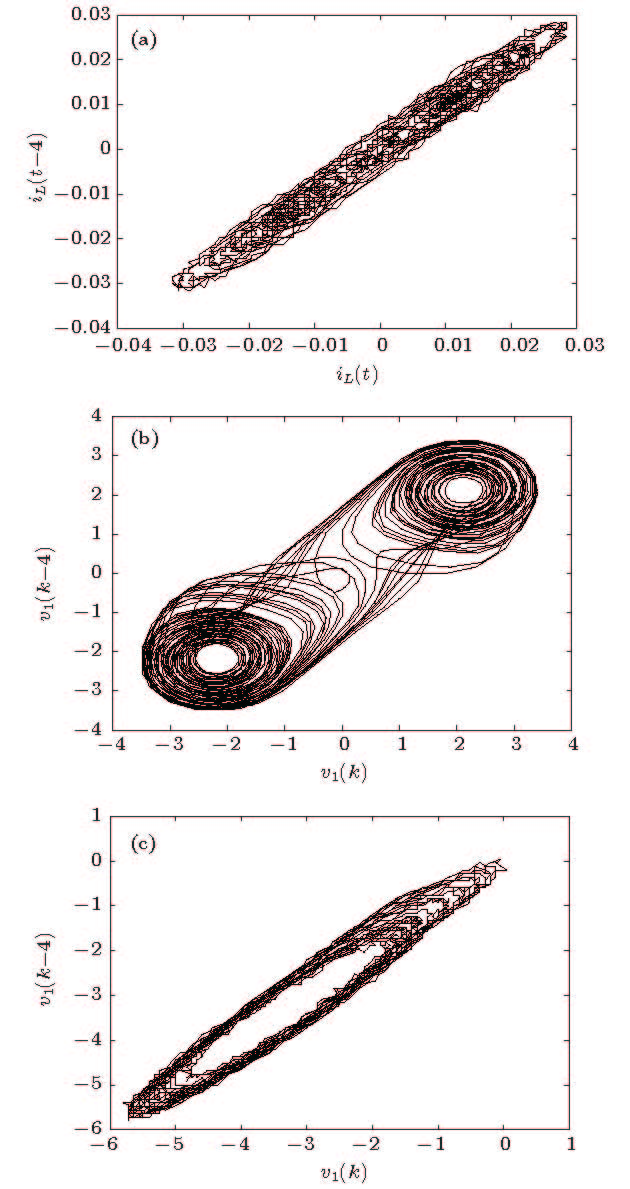 图 8 基于实测数据的蔡氏电路吸引子
图 8 基于实测数据的蔡氏电路吸引子





















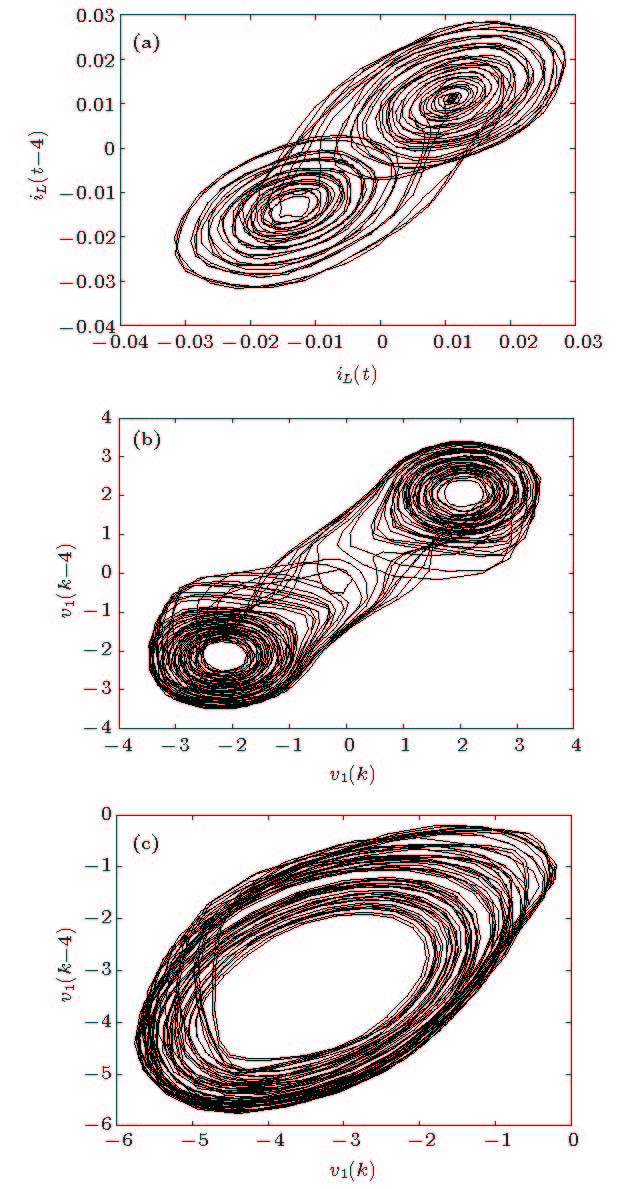 图 9 基于模型预测输出的蔡氏电路重构吸引子 (a)双涡卷吸引子iL; (b) 双涡卷吸引子v1; (c)螺旋吸引子v1
图 9 基于模型预测输出的蔡氏电路重构吸引子 (a)双涡卷吸引子iL; (b) 双涡卷吸引子v1; (c)螺旋吸引子v1









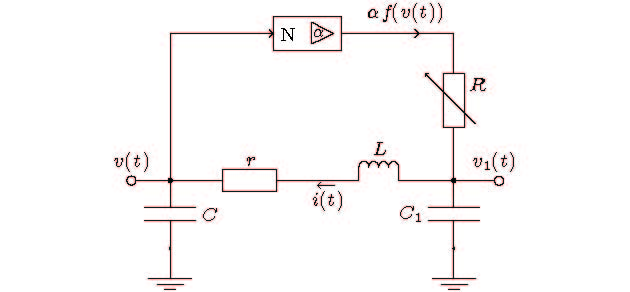 图 10 混沌电路的构成
图 10 混沌电路的构成














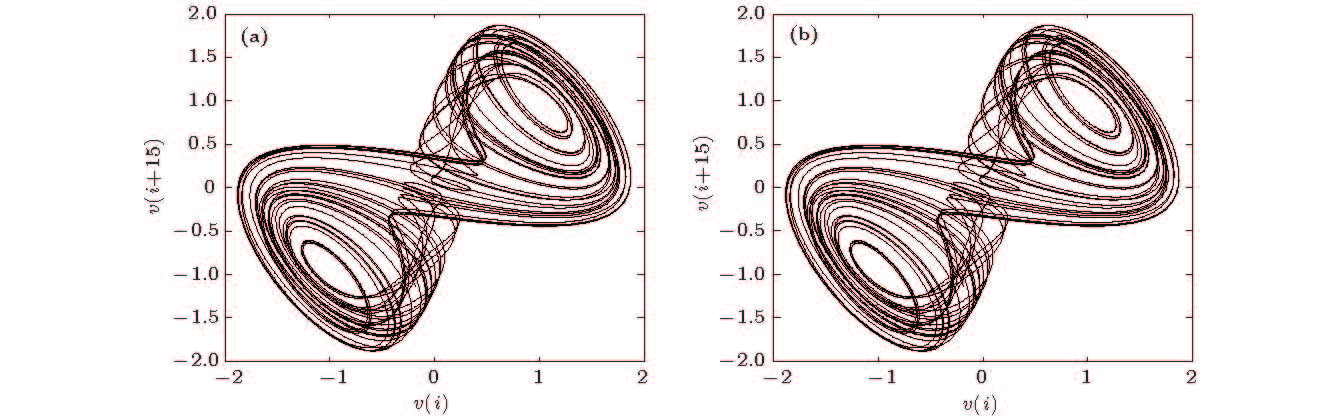 图 11 重构吸引子 (a)原模型; (b)辨识模型
图 11 重构吸引子 (a)原模型; (b)辨识模型









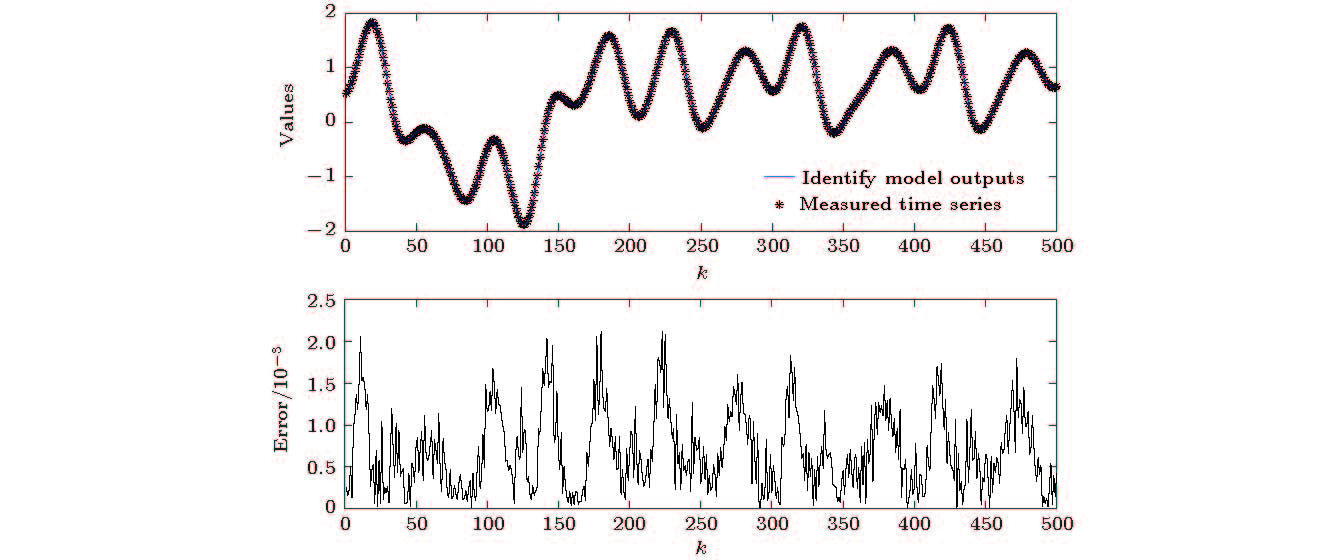 图 12 (a)辨识模型输出与实测时间序列值输出结果; (b)辨识误差
图 12 (a)辨识模型输出与实测时间序列值输出结果; (b)辨识误差