随着信息技术与制造业的不断融合,工业互联网[1-4]成为最受关注的发展热点之一。工业互联网将感知设备、计算机网络和云平台等现有的物联网技术融入进工业生产的各个环节,用以解决工业生产流程参数获取问题,从而实现对工业生产的数字化、精细化与智能化管理[5-8]。
与传统的工业信息化系统相比,工业互联网进一步强调解决非确定性问题的能力(例如:对象状态评估、风险预测、价值判断等)。工业互联网应用场景具有以下特点:
1) 云端服务化。互联网的成熟改变了工业软件的传统架构。云端服务成为工业软件的主要架构模式。在这一模式中,工业软件脱离原有的局域环境部署的方式,将终端的功能弱化,形成较为单一数据采集与结果呈现工具。在云端,实现终端数据的处理、存储、查询与分析等功能。通过网络实现云端-终端之间的数据交换。由于业务承载量的膨胀,云端需要具有高效的数据读写机制。一方面保证平台并发性能。另一方面,避免云端的数据处理负担,简化数据的各种格式清洗与预处理等操作。
2) 数据泛化。结合大数据,工业互联网的发展改变了生产活动的商业与服务模式。这一趋势导致传统的数据生产-消费关系发生颠覆性的变化。云平台结合大数据手段,在对象全寿命周期的基础上,从多个维度开展知识挖掘围绕对象行为导向、价值判断、决策支撑等开展分析与支撑。这就需数据管理系统能够支撑上层复杂挖掘分析的多值查询、布尔查询等复杂操作。
从数据的角度出发,工业互联网中数据具有一定的实时性。同时,与传统的信息系统中数据相比,其具有以下特点:
1) 数据价值具有时效性。在云平台日常数据增量过程中,为了支撑对象分析、知识提取以及事件回溯等需要实现全寿命周期的数据存储管理。另一方面,在大多数应用场景中,数据自身的信息承载价值随着时间变化。整体而言,在数据产生的初期,其信息承载价值较高,随着时间的变化,这一价值逐渐降低。从数据存储管理的角度出发,应围绕时间-价值的关系建立数据组织机制,保证数据整体有效存储管理,避免大量价值不均数据无差别管理导致的效率降低。
2) 数据不是强事务性。在云平台形成生态圈中,所产生的大量数据用于记录对象的操作行为、客观事物的监测记录、对象状态变更等。这一类数据以时间序列的方式增量,在数据生产-消费过程中,不存在复杂、频繁的变更。同时,也不具备回滚等强事务性处理的需求。因此,在数据存储管理过程中,数据库系统的内部存储管理模型较为简单,无需复杂的锁等控制机制。
在工业互联网环境中,信息系统的架构、组织与应用模式发生巨大变化。这一变化导致云平台在非结构化数据统一存储管理、高性能检索查询等方面提出较高要求。同时,与传统的应用系统相比,数据在价值分布、一致性、事务性等方面管理需求不同。这些因素叠加导致传统的数据库系统面临一定的局限性。工业互联网需要解决以下几个核心问题:
1) 在工业互联网环境中,对于各种不同的工业传感器采集的数据,如何实现异构数据的统一存储管理?
2) 在问题1)的场景中,如何围绕非结构化数据建立有效的基本读写控制机制,保证存储空间的利用效率?
3) 在问题1)和2)的场景中,如何围绕数据建立有效的索引机制,满足海量数据中多值查询、布尔查询等复杂查询操作的效率?
针对上述问题,本文提出了一种面向工业互联网的云存储方法——StoreCDB。StoreCDB采用并行架构,在多点协同的基础上实现多源、异构的JSON(JavaScript Object Notation)数据统一存储管理。在这一架构中,首先根据业务建立统一表达模型,来自不同数据源的异构JSON数据与该模型进行结构映射,形成统一表达映射索引,利用索引实现异构数据的统一检索。该索引具有查询执行效率受数据集规模影响较小的特点,且支持多维与布尔查询。原始数据记录以SN(Share-Nothing)的原则分布存储在底层节点的分页中,避免大量格式清洗以及后处理的负载,满足工业互联网的要求。
本文首先对数据管理方面的相关工作进行了调研;其次阐述了StoreCDB的系统架构,并分别介绍了StoreCDB的数据存储模型和数据写入操作方法及如何利用这一架构实现海量、异构数据的多值查询与布尔查询;最后讨论了系统的实现与实验结果。
1 相关工作 在海量异构数据存储与查询处理方面,目前主要有2种方法:典型的数据集中式管理方法和采用云数据管理及其相关技术的大数据管理。
1.1 数据集中式管理方法 在集中式数据管理系统中,由数据中心对数据进行统一的存储管理。感知层接收采样数据,首先将其按照一定的规则转换成为标准格式并上传至数据中心,然后再利用数据中心强大的存储与计算能力直接完成查询处理。
典型的数据集中式管理方法有关系数据库、并行数据库和数据库集群。并行数据库通过将多个关系数据库组织成数据库集群来支持海量结构化数据的处理,但这种方法在处理关键字查询时的性能要远低于“键-值”(K-V)数据库,无法快速地检索到所需要的数据。而且由于采用了严格的分布式事务处理机制[9],在采样数据频繁上传和更新的情况下,数据处理的效率十分低下[10]。所以传统的并行数据库技术主要针对通用的数据类型,尚不能有效地支持海量异构数据的并行存储与查询处理。
另一方面,由于关系数据库系统的出发点是追求高度的数据一致性和容错性,根据CAP(Consistency, Availability, tolerance to network Partitions)理论[11-13],在分布式系统中,一致性、可用性和分区容错性三者不可兼得,因而并行关系数据库无法获得较强的扩展性和良好的系统可用性。
1.2 云数据管理及其相关技术 云计算是最近几年新兴的一个技术领域,其核心特点是通过一种协同机制,动态管理几万台、几十万台甚至上百万台计算机资源所具有的总处理能力,并按需分配给全球用户,使它们可以在此之上构建稳定而快速的存储以及其他IT服务[14],因此云计算为海量数据处理提供了一种可能。大数据存储的形式包括分布式的文件系统、分布式的K-V对存储以及分布式数据库存储。当前的研究也集中在这3个方面,并依据应用的需求进行相关的优化。
在分布式文件系统研究方面,传统的分布式文件系统——NFS应用最为广泛[15]。为了应对搜索引擎数据,谷歌公布了其能够用于存储网页数据的分布式文件系统技术——GFS[16]。开源社区据此开发了适合部署在廉价机器上的Hadoop分布式文件系统——HDFS[17]。微软开发的Cosmos[18]支撑着其搜索、广告等业务。Facebook推出了专门针对海量小文件的文件系统Haystack[19],以降低对磁盘寻道速度的要求。K-V对存储也是一大类重要的存储系统。亚马逊提出的Dynamo以K-V为模式,是一个真正意义上的去中心化的完全分布式存储系统,具有高可靠性、高可用性且具有良好的容错机制[20]。由于模型的简单性,K-V对存储在应用模型不是很复杂的情况下能够获得更好的性能。Bigtable是谷歌开发的基于GFS和Chubby的非关系数据库,是一个稀疏的、分布式的、持久化存储的多维度排序映射表[21]。为克服其缺乏一致性支持的缺点,谷歌将其改进为Megastore系统[22],但是改进后的系统性能不是很高。随后谷歌进一步开发了Spanner系统,能够进一步加强一致性,将数据分布到了全球的规模,性能有了一定提高[23]。Spanner是第1个可以实现全球规模扩展并且支持外部一致事务的数据库。
然而,目前的绝大多数云数据存储系统及Map/Reduce主要面向关键词处理及静态的海量数据,在面向数据的多维逻辑、数值逻辑时,受到诸多的局限与制约,并不适用于复杂的大规模异构数据的存储与分析处理。例如MongoDB虽然广泛应用于云计算数据存储管理中,但是其索引采用B+树机制,面对多维度数据查询时,索引规模快速扩张,进而影响海量数据查询效率。
通过上述分析可以看出,工业互联网数据的存储技术目前还相当的不成熟。为了解决上述问题,本文针对工业互联网数据存储管理的核心问题进行研究,提出了面向工业互联网数据管理的存储管理方法及系统框架。
2 StoreCDB系统架构 本节将描述StoreCDB的系统架构与工作机理,StoreCDB的系统结构如图 1所示。
 |
| 图 1 StoreCDB的系统结构 Fig. 1 System structure of StoreCDB |
| 图选项 |
如图 1所示,StoreCDB是以并行架构为基础组成的数据存储管理系统,由一个Master节点和一组Worker节点构成。Master节点主要负责统一表达建模与异构数据映射、数据分发以及全局分页存储映射管理等;Worker节点实现原始数据记录在本地存储、索引维护以及查询执行等。整个架构由资源协同层、网络连接层和节点存储层构成的。
资源协同层利用抽象表达模型对采样数据进行统一的表达。通过模型实现数据的结构语义映射与互操作,并对多源异构大数据存储与管理过程进行统一表达,其中数据模型和映射关系的定义将在数据模型中详细介绍。在这一基础上,根据统一表达模型定义的主键取值实现定向分发,同时维护全局的分页存储映射信息。
网络连接层在Master与Worker节点之间建立网络连接。同时,在这一网络连接内部建立通道资源,为不同任务分配通信资源并维护会话状态。
节点存储层由Worker节点构成。Worker节点在分页的基础上,实现原始数据的本地存储。同时,在统一表达模型的基础上对原始JSON数据记录的结构进行映射并提取属性取值,维护本地索引。通过本地的SQL(Structured Query Language)引擎提供检索支持。
StoreCDB在上述存储管理的基础上,发挥并行架构优势,面向工业互联网中的上层应用提供高性能K-V、多值以及布尔查询操作支撑。
3 StoreCDB数据存储模型 本节将讨论数据存储模型,并重点从数据模型和存储结构2个方面对StoreCDB的存储模型进行描述。
3.1 StoreCDB数据模型 在StoreCDB中,异构采样数据需要进行统一的数据模型表示。下面将从原始采样数据以及属性映射关系对StoreCDB的数据模型进行描述。
定义1 ??数据记录sensorData是由数据标签和数据内容构成,可表示为
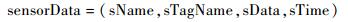 |
其中:sName表示传感器名称;sTagName表示传感器采样数据的类型标签;sData表示该标签的采样值;sTime表示采样时间。
表 1给出了在高速列车监控系统中各种传感器采样值的示例。
表 1 传感器采样值的示例 Table 1 Examples of sensor sample values
| 传感器名称 | 传感器类型标签 | 数据记录 |
| s08 | 运行速度 | (s08, 运行速度, 215, t1) |
| s10 | 行驶速度 | (s10, 行驶速度, 216, t2) |
| s401 | 转向架轴温 | (s401, 转向架轴温, 83, t1) |
| s401 | 转向架轴温 | (s401, 转向架轴温, 85, t2) |
表选项
定义2??采样数据序列srcData是由同一监控对象的所有传感器的采样值按照时间序列组织而成的,可表示为
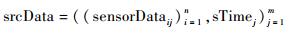 |
其中:sTimej表示第j个采样时间;sensorDataij表示第j个采样时间下第i个传感器采样值。
以表 1为例,与其对应的采样数据序列为srcData = (((s08, 运行速度, 215, t1), (s401, 转向架轴温, 83, t1)), t1), (((s10, 行驶速度, 216, t2), (s401, 转向架轴温, 85, t2)),t2)。
在原始采样数据中,由于数据的多源异构性,同一种传感器类型的表述可能千差万别。例如在表 1中,传感器类型同样是行驶速度,但s08的描述是运行速度,而s10的描述是行驶速度。为了统一管理,在StoreCDB中有一个属性映射表,即
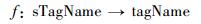 |
其中:sTagName表示原始采样数据中传感器类型标签;tagName是StoreCDB中与sTagName对应的统一表示的属性名称。一个tagName可以对应多个sTagName,通过属性映射表,StoreCDB可以为不同标准的采样数据类型提供统一的表示。
在StoreCDB中,为了对异构数据进行统一表示,在主节点接收采样数据之前,需要将采样数据序列转换为统一的数据格式。为了更好地描述数据转换格式,本文先给出了如下定义:
定义3 ??给定采样时刻sTime的采样数据srcDatasTime=((sensorDatai)i=1n, sTime),其对应的原始数据data由数据内容和采样时间构成,可表示为
 |
定义4??给定原始数据的数据内容content,其中的采样属性集合propertySet可表示为
 |
其中:tagNamei表示从content中提取的第i个传感器类型;posi表示该类型在content中对应的位置。
通过上述定义,在StoreCDB中可以将采样数据转换成为统一的数据格式,如定义5所示。
定义5??统一数据格式D由三元组构成,可表示为
 |
其中:timeStamp表示数据接收时间。
以表 1为例,假设ts1时刻接收到t1时刻的采样数据,统一数据格式D1 = ((((运行速度, 215), (转向架轴温, 83)), t1), ((速度, 1), (轴温, 2)), ts1),其中data项直接保存了原始采样数据内容,propertySet中的“速度”则是data中的“运行速度”在StoreCDB中的属性映射,同样“轴温”是“转向架轴温”的属性映射,ts1则是数据接收时间。
3.2 StoreCDB数据存储结构 在StoreCDB中,存储管理层采用主从结构进行分布式管理,由一个主节点(Master)和多个从节点(Worker)构成,其中主节点在统一表达模型的基础上负责增量数据分发、全局存储分页映射维护、高性能数据查询任务调度,从节点存储实际的采样数据、维护本地索引、执行查询任务。StoreCDB的存储管理结构如图 2所示。
 |
| 图 2 StoreCDB的存储管理结构 Fig. 2 Storage management structure of StoreCDB |
| 图选项 |
如3.1节所述,多源异构采样数据转换成统一的数据格式之后封装为数据D,主节点接收到数据D之后,首先根据D中的定义为主键的属性取值,映射到对应的分页存储空间,再根据数据划分方式找到对应的存储页,最后主节点将数据D发送给相应的从节点。
从节点接收到数据之后,首先将数据添加到对应的存储页,然后更新相应的页索引,再依据属性集propertySet中的属性值更新属性索引。
页索引记录了数据与存储位置之间的映射关系,实现了快速检索数据的一级索引,定义如下:
定义6 ??页索引mapIdx可表示为
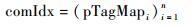 |
其中:rowIdi表示第i个数据的行号;idxi表示第i个数据对应的存储位置指针。
属性索引记录了属性集propertySet中各属性值与页索引mapIdx之间的映射关系,实现了快速检索数据的二级索引,定义见定义7。
定义7 ??属性索引comIdx可表示为
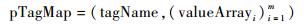 |
其中:pTagMapi为第i个属性的值域分布的映射向量集合,形式如下:
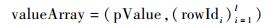 |
其中:tagName表示属性的标识;valueArrayi表示该属性第i个属性值的索引映射集合,可表示为
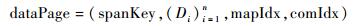 |
其中:pValue表示一个属性值。rowIdi为第i个包含该属性值的数据行号,与页索引中的行号对应。
依据不同的划分方式,采样数据存放在一系列存储页中,记为dataPage。每个存储页对应一个从节点,而一个从节点可以包含多个存储页,定义如下:
定义8??存储页dataPage表示为
 |
其中:spanKey表示数据划分方式,可以按照接收时间划分、某属性的取值范围划分、传感器类型划分等,在本文中默认采用按接收时间划分;(Di)i=1n为存储的数据;mapIdx表示页索引,记录数据与存储位置的映射关系;comIdx表示属性索引,记录属性集与页索引之间的关系。
为了支持多源异构数据,StoreCDB依据不同的应用场景分为若干个不同的源数据集,并为每一类源数据集定义了一个存储仓库,记为dataStore,如定义9所示。
定义9 ??分页存储空间dataStore可表示为
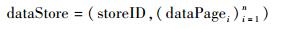 |
其中:storeID表示分页的编号;dataPagei表示划分的第i个存储页。
3.3 StoreCDB中的索引结构 StoreCDB的Worker节点采用两级索引结构:页索引和属性索引。其结构如图 3所示。
 |
| 图 3 StoreCDB的索引结构 Fig. 3 Index structure of StoreCDB |
| 图选项 |
页索引采用行号(rowId)和存储位置指针(idx)的方式记录了每一条原始数据在分页中的存储位置,即通过数据所在行号便可直接定位到物理存储位置。在页索引中,行号并不是基于顺序查找,而是通过散列完成,索引中的行号即为该散列的主键,而其指针指向数据存储的物理位置,即对应的从节点及其上的存储页。页索引具体结构如图 4所示。
 |
| 图 4 StoreCDB的页索引结构 Fig. 4 mapIdx structure of StoreCDB |
| 图选项 |
属性索引用于记录一条数据记录在不同属性上取值与该数据记录页索引的映射关系。属性索引将属性集propertySet中的各属性分别进行单维投影,按照属性分类,将属性值与对应的页索引关联起来,实现多值与布尔查询。属性索引具体结构如图 5所示。
 |
| 图 5 StoreCDB的属性索引结构 Fig. 5 comIdx structure of StoreCDB |
| 图选项 |
本文结合实例来讨论属性索引的结构,在图 5中,对应于StoreCDB中的属性映射表,属性集propertySet=(“velocity”, “temperature”, “operation”),属性索引对其中各属性进行单维投影,投影结果如表 2所示,其中数据行号对应于页索引中的行号,通过页索引mapIdx和行号rowId即可获得数据的存储位置,从而实现快速检索。
表 2 属性索引的单维投影范例 Table 2 Example of a one-dimensional projection of comIdx
| 属性tagName | 属性值pValue | 数据行号 | rowId |
| velocity | 135km/h | 289 | 390 |
| 136 km/h | 190 | 310 | |
| temperature | 83℃ | 367 | 390 |
| 85℃ | 390 | 463 | |
| operation | rw | 278 | 290 |
| c | 390 | 463 |
表选项
当要查找满足“运行速度135km/h,转向架温度83℃并且操作记录为c”的数据时,首先根据属性值(velocity=135km/h,temperature=83℃和operation=c)找出对应的行号,如表 3所示。由于行号390是所有属性值共同的取值,可以得出“运行速度135km/h,转向架温度83℃并且操作记录为c”的数据存放在390行,从页索引中找出390行的存储位置,便可以获得查询结果。
表 3 属性索引的查询实例 Table 3 Query instance of comIdx
| 属性tagName | 属性值pValue | 数据行号 | rowId |
| velocity | 135km/h | 289 | 390 |
| temperature | 83℃ | 367 | 390 |
| operation | c | 390 | 463 |
表选项
4 StoreCDB中数据写入操作 4.1 数据写入操作过程 在StoreCDB中,主节点在接收到数据写入请求后,需要根据写入数据D的主键(primeKey)确定分发的dataPage和对应的从节点。从节点接受到数据D之后,写入对应的分页中。然后根据返回的rowId和D的propertySet维护本地页索引和属性索引。算法1给出了数据写入操作过程。
算法1??数据写入算法。
输入:数据D、页索引mapIdx、属性索引comIdx。
输出:写入完成标记R。
1 ??/*主节点接到写入数据请求*/
2 ??primeKey←getPrimeKey(D);
3?? propertySet←getPropertySet(D);
4?? dataPage←hashPage(primeKey);
5?? Worker←hashNode(dataPage);
6?? /*数据D被分发到从节点*/
7??将数据D写入对应的dataPage;
8?? mapIdx←updataMapIdx(D, mapIdx);
9 ??comIdx←updataComIdx(D, dataPage, comIdx);
10 ??R←createR(dataPage, primeKey, propertySet);
11?? return(R)
算法中,getPrimeKey(D)函数返回数据D中的主键primeKey;getPropertySet(D)函数返回数据D中的属性集合;hashPage(primeKey)函数返回与primeKey对应的dataPage;hashNode(dataPage)函数返回与dataPage对应的从节点;updataMapIdx(D, mapIdx)函数返回写入数据D之后更新的页索引mapIdx; updataComIdx(D, dataPage, comIdx)返回更新后的属性索引comIdx; create-R(dataPage, primeKey, propertySet)函数返回的是数据写入成功返回值R。
4.2 页索引更新操作 在Worker节点本地数据写入过程中,完成原始数据记录在分页存储后,需要更新页索引中行号顺序增加并记录映射地址。通过这一页索引可以行号从分页中提取原始数据记录。算法2给出了页索引的更新过程。
算法2??页索引的更新算法。
输入:数据D、页索引mapIdx。
输出:更新结果mapIdx。
1?? rowId←getRowId(D);
2?? idx←hash(rowId);
3 ??dataPage←getDataPage(idx);
4 ??锁定数据页dataPage的写操作;
5??将D写入dataPage的尾部;
6 ??mapIdx←updataIdx(rowId, idx);
7 ??解锁数据页dataPage的写操作;
8 ??return(mapIdx)
算法2中,getRowId(D)函数返回数据D中的数据行号;hash(rowId)函数返回rowId对应的哈希地址,即数据D应该存储的从节点及其上的存储页;getDataPage(idx)函数获取idx指向的从节点中的存储页dataPage;然后锁定dataPage的写操作;将D存入指定位置后,通过函数updataIdx(rowId, idx)更新mapIdx,然后解锁dataPage的写操作。
4.3 属性索引更新操作 从节点接收到数据后,首先获取数据D的属性集合、行号,并从dataPage中取出属性索引comIdx,若comIdx不存在则创建新的属性索引,否则对于每个属性的每个属性值,更新其对应的索引映射集合valueArray,并将其写入comIdx进行更新。算法3给出了属性索引的更新过程。
算法3 ??属性索引的更新算法。
输入:数据D、数据所需存储页dataPage、属性索引comIdx。
输出:更新结果R。
1 ??propertySet←getPropertySet(D);
2 ??rowId←getrowId(dataPage);
3?? comIdx←getComIdx(dataPage);
4?? if comIdx不存在then
5 ??创建属性索引comIdx;
6?? for each tagName∈propertySet do
7?? for each pValue∈tagName do
8 ??valueArray←addArray(pValue, rowId);
9 ??将valueArray存入tagName对应的pTagMap;
10?? comIdx←upcomIdx(pTagMap);
11?? return(comIdx)
算法3中,getPropertySet(D)函数返回数据D中的属性集合;getrowId(dataPage)函数获取存储页中的行号;getComIdx(dataPage)函数从dataPage中获取属性索引comIdx;addArray(pValue, rowId)函数更新索引映射集合valueArray;upcomIdx(pTagMap)函数更新comIdx。
5 StoreCDB中数据查询操作 在上述索引技术的基础上,StoreCDB系统通过查询引擎实现全局范围内的数据查询。这一过程由2个步骤完成:
1) 查询分解。主节点接收到查询后,将其分解为二叉任务树,其中叶节点为单值查询任务,中间节点为操作连接符,连接2个单值查询任务。
2) 查询处理。主节点将二叉任务树分发至相应的从节点进行查询,从节点对操作连接符两边的单值查询进行交叉过滤,形成局部查询结果,全部任务完成后形成最终的查询结果返回主节点。
定义10??查询query可以表示为
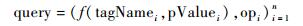 |
其中:tagNamei表示第i个属性;pValuei表示第i个属性值;f(tagNamei, pValuei)表示该属性与属性值之间的关系;opi表示操作连接符,取值为AND,OR,NOT,?,?表示没有操作连接符。
以表 3中的查询为例,“运行速度135km/h,转向架温度83℃并且操作记录为c”的查询可以表示为query=(velocity=135km/h)∧(temperature=83℃)∧(operation=c)。当主节点接收到查询任务query后,将其分解为多个单值查询任务,并通过操作连接符将其转换为一棵二叉任务树,二叉任务树结构如图 6所示。
 |
| 图 6 二叉任务树的实例 Fig. 6 Instance of task binary tree |
| 图选项 |
主节点将二叉任务树分发给相应的从节点后,等待所有从节点完成查询任务后,汇集全部查询结果。从节点接收到二叉任务树后,通过遍历二叉任务树对本地存储页进行匹配和筛选,首先从当前二叉任务树的最左叶节点开始,提取该左叶节点与右节点对应的属性取值映射索引pTagMap,经过筛选得到局部结果集合。将该结果作为当前子树的查询结果与上一级的右叶节点继续筛选,直到完成全部叶节点的属性取值映射索引的筛选。算法4给出了从节点的查询处理过程。
算法4 ??从节点查询处理算法。
输入:二叉任务树qtree、页索引mapIdx、属性索引comIdx。
输出:查询结构R。
1?? while true do
2?? lNode←getLNode(qtree);
3 ??if lNode = op then /*左节点是操作符*/
4 ??rNode ← getRNode(qtree);
5?? /*获取左右节点的属性及取值和操作符*/
6 ??fR ← getQuery(rNode);
7?? (fL, op) ← getFOp(rNode);
8?? query ←(fL, op, fR);
9 ??else then
10 ??op←getFOp(lNode);
11?? /*获取父节点的操作符*/
12?? rNode←getRNode(qtree);
13?? fL←getQuery(lNode);
14?? fR←getQuery(rNode);
15?? query←(fL, op, fR);
16 ??/*通过页索引和属性索引执行查询*/
17?? R←exeQuery(query, mapIdx, comIdx);
18 ??/*裁剪qtree的左右子节点,将结果存放当前op中*/
19?? qtree←remove(lNode, rNode, R);
20?? if qtree全部裁剪then
21?? return (R)
在算法4中,getLNode(qtree)(getRNode(qtr-ee))函数返回qtree的左节点(右节点);getQuery(node)函数获取节点的属性及取值;fL与fR分别表示当前查询中左侧节点和右侧节点的属性与取值;getFOp(rNode)函数获取父节点的操作符;exeQuery(query, mapIdx, comIdx)利用页索引mapIdx和属性索引comIdx执行查询query;remove(lNode, rNode, R)裁剪当前任务树的左右子节点,并将结果集存放在当前op节点中。
6 系统实现及性能分析 本节在模拟数据集的基础上,采用StoreCDB实验系统,旨在对StoreCDB的查询效率以及可扩展性进行了一系列实验验证。其中StoreCDB实验系统是在分布式集群上进行部署,形成一个协同工作的StoreCDB系统。
本实验中,主节点的处理器为Intel(R) Xeon(R) CPU E5-2620,主频2.0GHz,内存大小为2GB;从节点的处理器为Intel(R) Xeon(R) CPU E5-2620,主频2.0GHz,内存大小为3 GB。
实验所用的数据为基于实车采集数据的模拟数据集,其由数据格式为不同的CRH3和CRH5动车组轴温采样模拟数据(Src1)和CRH3和CRH5动车组运行状态数据(Src2)组成。表 4列出了实验中的主要参数。
表 4 实验参数 Table 4 Parameters of experiment
| 参数 | 数值 |
| 数据源的记录数目NSrc/行 | 2×1010 |
| 采样数据的平均时间间隔frequency/s | 5 |
| 主节点服务器的数目NmasterNodes | 1 |
| 从节点服务器的数目NworkerNodes | 1~32 |
表选项
在实验中,本文将StoreCDB与MySQL Cluster和HBase数据库进行对比测试。重点针对StoreCDB的查询响应时间及加速比进行了分析。
为了全面评估StoreCDB对K-V查询以及数据关系库(RDB)查询的支持,实验的测试用例采用了如下2种查询:
1) K-V查询
Select * From table Where date=“2017-05-01”。其中:table表示不同的数据源,分别为Src1或Src2;date表示关键字,查找所有与“2017-05-01”相关的数据。
2) RDB查询
Select * From table Where velocity=135 AND temperature=83 AND (operation=‘c’ OR operation=‘rw’)。
图 7给出了StoreCDB、MySQL Cluster和HBase处理K-V和RDB查询的响应时间。图 7(a)展示了K-V查询时间与数据集规模的关系,图 7(b)是RDB查询时间与数据集规模的关系。随着数据集的增加,K-V查询和RDB查询的时间都逐渐增加。StoreCDB在海量数据情况下,K-V查询效率高于MySQL Cluster,低于HBase。由于HBase不支持多条件查询,故图 7(b)中仅有MySQL Cluster和StoreCDB的实验结果。
 |
| 图 7 查询效率实验 Fig. 7 Query efficiency experiment |
| 图选项 |
随着数据集的增加,3种数据库的K-V查询时间都逐渐增加,HBase在进行列查询时,响应时间始终小于StoreCDB和MySQL Cluster。在数据集规模较小的情况下,StoreCDB与MySQL Cluster响应时间基本相同,随着数据集规模增大,StoreCDB响应时间增速逐渐小于MySQL Cluster。
在进行RDB查询时,MySQL Cluster和StoreCDB响应时间均高于K-V查询,这是因为K-V查询只涉及页索引,而RDB查询同时需要页索引和属性索引的检索。尽管如此,两种查询的效率相差并不大,且变化趋势也较一致。可以看出,在数据量快速增长的情况下,StoreCDB依然能快速响应查询,性能保持良好。
图 8给出了StoreCDB的可扩展性,为RDB的查询响应时间与从节点个数的关系。
 |
| 图 8 可扩展性实验 Fig. 8 Expandability experiment |
| 图选项 |
从图 8可以看出,随着从节点个数的增加,StoreCDB查询的性能明显提升,RDB查询与K-V查询性能提升效果变化趋势相似。StoreCDB具有良好的可伸缩性,并且保证在从节点增加的情况下有明显的性能提升。
为了进一步分析StoreCDB中从节点规模对查询的影响。本文在表 5中分别给出StoreCDB在处理2×1010行和7×106行数据源中RDB查询的加速比实验结果。加速比Speedup定义为
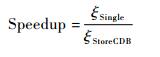 | (1) |
表 5 StoreCDB在RDB查询中的加速比 Table 5 The acceleration ratio of StoreCDB in RDB queries
| NworkerNodes | 加速比 | |
| Nsrc=2×1010行 | Nsrc=7×106行 | |
| 2 | 1.62 | 1.33 |
| 4 | 1.79 | 1.49 |
| 8 | 2.06 | 1.63 |
| 16 | 2.64 | 2.10 |
| 32 | 4.95 | 3.32 |
表选项
式中:ξSingle和ξStoreCDB分别为单数据库节点和StoreCDB的查询响应时间。
从表 5可以看出,StoreCDB在处理查询任务时,相比于单点数据库,加速比随着从节点数量的增加而上升,并且数据集规模越大,加速性能越明显。
为了评估存储空间的利用效率,本实验采用32节点的StoreCDB和HBase在不同数据集规模时的空间利用率进行对比测试。
HBase是通过文件合并(compaction)的方式对小文件和文件删改带来的空间碎片进行整理以提高存储空间利用效率。StoreCDB则采用虚拟行的方式,使得同一行数据可以存储在不连续的位置来减少空间浪费。
详细对比情况如图 9所示,图 9给出了空间利用率的对比实验结果。
 |
| 图 9 存储空间利用率实验 Fig. 9 Storage space utilization experiment |
| 图选项 |
从图 9可以看出,随着存储数据集规模的增加,StoreCDB的空间利用率逐渐降低,这是因为虚拟行中的索引规模随着数据集规模的增长造成的空间利用率下降。在数据集规模较小的情况下,HBase的空间利用率略高于StoreCDB。随着数据集规模的增长,StoreCDB空间利用率降低程度略优于HBase。这是由于HBase的合并策略在提高读写性能时会减少参与合并的文件数量,从而导致空间利用率下降。
综合上述分析,StoreCDB可以有效地支持K-V查询和RDB查询,提供了良好的工业互联网海量异构数据接入与查询处理能力,为工业互联网的海量异构数据管理提供了一种可行的解决方案。
7 结论 本文从工业互联网数据管理角度出发,对工业互联网在非结构化数据统一存储管理,高性能检索查询等方面所面临的挑战进行了分析,提出了面向工业互联网数据管理的云存储方法——StoreCDB。
1) 提出了一种能够应对海量多源异构数据统一管理的数据模型,实现了多源异构数据的统一表达,解决了不同服务系统的数据统一存储问题。
2) 提出了一种能够支持“键-值”查询和普通SQL查询的索引方法,通过页索引和属性索引的两级索引结构,突破了目前云数据管理技术主要针对“键-值”查询以及并行数据库技术主要针对SQL查询的局限。
3) 提出了基于两级索引结构的全局查询处理方法。
4) 采用StoreCDB实验系统,对该方法的查询效率及可扩展性进行了一系列实验验证。实验结果表明,StoreCDB具有良好的异构数据存储和检索性能。
参考文献
| [1] | LI D, WU H, LI S C. Internet of things in industries:A survey[J]. IEEE Transactions on Industrial Informatics, 2014, 10(4): 2233-2243. DOI:10.1109/TII.2014.2300753 |
| [2] | 李晓娟.物联网中海量数据管理技术研究[D].广州: 广东工业大学, 2015. LI X J.Huge amounts of data management technology for internet of things[D]. Guangzhou: Guangdong University of Technology, 2015(in Chinese). http://kns.cnki.net/kns/detail/detail.aspx?QueryID=1&CurRec=2&recid=&FileName=1015312027.nh&DbName=CMFD201502&DbCode=CMFD&yx=&pr=&URLID= |
| [3] | 孙鹏.动车组维修物联网及其关键技术研究[D].北京: 中国铁道科学研究院, 2013. SUN P.Study on EMU maintenance in the internet of things and its key technologies[D]. Beijing: China Academy of Railway Sciences, 2013(in Chinese). http://kns.cnki.net/kns/detail/detail.aspx?QueryID=4&CurRec=2&recid=&FileName=1014150015.nh&DbName=CDFD1214&DbCode=CDFD&yx=&pr=&URLID= |
| [4] | SANCHEZ L, MU?OZ L, GALACHE J A, et al. Smartsantander:IoT experimentation over a smart city testbed[J]. Computer Networks, 2014, 61: 217-238. DOI:10.1016/j.bjp.2013.12.020 |
| [5] | 宁焕生, 徐群玉. 全球物联网发展及中国物联网建设若干思考[J]. 电子学报, 2010, 38(11): 2590-2599. NING H S, XU Q Y. Research on global internet of things' developments and it's lonstruction in China[J]. Acta Electronica Sinica, 2010, 38(11): 2590-2599. (in Chinese) |
| [6] | ATZORI L, IERA A, MORABITD G. The internet of things:A survey[J]. Computer Networks, 2010, 54(15): 2787-2805. DOI:10.1016/j.comnet.2010.05.010 |
| [7] | 康世龙, 杜中一, 雷咏梅, 等. 工业物联网研究概述[J]. 物联网技术, 2013, 3(6): 88-90. KANG S L, DU Z Y, LEI Y M, et al. Over view of industrial internet of things[J]. Internet of Things Technologies, 2013, 3(6): 88-90. DOI:10.3969/j.issn.2095-1302.2013.06.035 (in Chinese) |
| [8] | GUBBI J, BUYYA R, MARUSIC S, et al. Internet of things (IoT):A vision, architectural elements, and future directions[J]. Future Generation Computer Systems, 2013, 29(7): 1645-1660. DOI:10.1016/j.future.2013.01.010 |
| [9] | ?ZSU M T, VALDURIEZ P. Principles of distributed database systems[M]. 3rd ed.New York: Springer Science & Business Media, 2011: 16. |
| [10] | STONEBRAKER M. SQL databases v.NoSQL databases[J]. Communications of the ACM, 2010, 53(4): 10-11. DOI:10.1145/1721654 |
| [11] | GILBERT S, LYNCH N. Brewer's conjecture and the feasibility of consistent, available, partition-tolerant web services[J]. ACM SIGACT News, 2002, 33(2): 51-59. DOI:10.1145/564585 |
| [12] | HUANG H, WU Q H, YU D. Robust distributed control of robot formations with parameter uncertainty[J]. Journal of Control Theory and Applications, 2011, 9(4): 51-58. |
| [13] | XU H G, HAN J H, PAN S P, et al.The research on data consistency of distributed storage system based on two-hop DHT[C]//Procceedings of IEEE ICITIS 2011.Piscataway, NJ: IEEE Press, 2011: 131-132. |
| [14] | PETER M, GRANCE T.The NIST definition of cloud computing: SP 800-145[R]. Gaithersbury: NIST, 2011. |
| [15] | SHEPLER S, CALLAGHAN B, ROBINSON D, et al.Network file system(NFS)version 4 protocol[R]. Reston: The Internet Society, 2003. |
| [16] | GHEMAWAT S, HOWARD G, LEUNG S T. The Google file system[J]. ACM SIGOPS Operating Systems Review, 2003, 37(5): 29-43. DOI:10.1145/1165389 |
| [17] | BORTHAKUR D.HDFS architecture guide[EB/OL]. (2013-10-10)[2018-03-20]. http://hadoop.apache.org/docs/r1.0.4/hdfs_design.html. |
| [18] | CHAIKEN R, JENKINS B, LARSON P A, et al. SCOPE:Easy and efficient parallel processing of massive data sets[J]. PVLDB, 2008, 1(2): 1265-1276. |
| [19] | BEAVER D, KUMAR S, LI H C, et al.Finding a needle in haystack: Facebook's photo storage[C]//Proceedings of OSDI 2010.Berkeley, CA: USENIX Association, 2010: 47-60. |
| [20] | DECANDIA G, HASTORUN D, JAMPANI M, et al.Dynamo: Amazon's highly available key-value store[C]//Proceedings of SOSP 2007.New York: ACM, 2007: 205-220. |
| [21] | CHANG F, DEAN J, GHEMAWAT S, et al. Bigtable:A distributed storage system for structured data[J]. ACM Transactions on Computer Systems, 2008, 26(2): 1-26. |
| [22] | BAKER J.Megastore: Providing scalable, highly available storage for interactive services[C]//Biennial Conference on Innovative Data Systems Research, 2011: 223-234. |
| [23] | CORBETT J C, DEAN J, EPSTEIN M, et al.Spanner: Google's globally-distributed database[C]//Usenix Conference on Operating Systems Design and Implementation, 2012: 251-264. |
