长期以来,大量关于空战文献的研究仅仅局限于“空战怎么打”。文献[2-3]将人工免疫系统运用到空战建模、机动决策问题中,建立战术免疫机动系统 (Tactical Immunized Maneuvering System, TIMS),模仿生物免疫系统和进化算法,基于不同的空战态势,自动生成合适的机动动作以回应目标威胁;文献[4]采用模糊推理的方法,根据空战态势在标准动作库里选择合适的机动动作;文献[5]提出基于智能微分对策的自主机动决策方法;文献[6]提出使用模糊支持向量机的方法分析空战过程;文献[7]采用滚动的多级影响图进行优化控制;文献[8]基于基本动作识别和组合动作识别库,可以识别近距空战的战术动作,根据敌机动作采用模糊推理的方法进行应对;文献[9]提出基于混合算法的空战机动决策方法,利于飞行员分析当前空战态势;文献[10]基于群集智能理论,构建以作战单元为智能体的协同多目标攻击决策模型,并通过定义智能体的贡献度扩展群集智能构架,用于解决空战多目标攻击问题。
然而上述文献更多的是关注飞行员“怎么打”,很少从飞行员的角度分析近距空战过程,回答到底是什么因素才是导致近距空战胜利的关键。文献[11]虽然通过模糊理论对空战数据进行分析并得到战斗机的战术机动决策序列,使用决策序列来评估空战训练双方的优劣。但是这个分类结果的依据仅仅是战斗机飞行过程中航向、俯仰、侧滚、速度、高度和能量等战斗机数据,并没有从这些数据中挖掘出飞行员决策过程变化的信息。事实上,空战时机稍瞬即逝,从飞行员下定决心到操控战斗机进行战斗,这个时间非常短。绝大部分的空战击落过程所用的时间仅仅只有十几秒,其余绝大部分的时间都用在互相追尾,抢占优势位置当中。所以,分析近距空战过程中飞行员作战决策的变化情况对于空战分析至关重要。毕竟,是人操控武器作战,而不是相反。在同等条件下,飞行员操控飞机的品质才是空战过程中的绝对制胜因素。
本文首先分析了2种典型的近距空战理论,并且给出近距空战中典型的飞行员作战流程,随后构建隐马尔可夫模型推断飞行决策点,最后给出一种飞行员决策包络分析方法,从而评判飞行员飞行品质。
1 近距空战理论与作战流程 空战历史经验表明,如果一种理论不能解释该领域内的某些现象,那么说明这种理论还不成熟,有继续完善的空间。早期飞机缺乏远距离攻击手段,主要以航炮对射、尾追打击为主要进攻手段。受限于技术水平,这一时期的空战理论主要是几何空战理论,通过分析作战飞行几何关系来分析空战过程。当包以德根据自身实践经验提出战机剩余功率之后,能量机动理论得到极大的发展,不仅用于作战实际,甚至对战机设计也产生了很大的影响[12]。但是,伴随过失速技术的实用化,过失速作为角度理论的典型战术,显然对能量机动理论产生了极大的冲击。本文在分析2种理论的思路上,提出了一种新的决策点理论,以为空战研究提供新的思路。
1.1 能量机动理论 包以德提出的能量机动理论强调对敌建立能量优势,然后通过一系列机动动作,将能量优势转化为位置优势[12]。以“滚转剪刀”机动为例,进攻方高速或从高向低冲过防守方,而防守方被迫拉起,降低自己的速度,诱使进攻方冲过头,接着防守方滚转使得机头对准敌机,拉头,双方形成类似双螺旋形状。双方通过高度的转化完成优势的转化。这是一种典型的能量机动战术。在能量机动理论中,主要强调能量的转化所形成的优势,这种转化往往是长时间的 (相对攻击而言)。战斗机进行近距空战时,需要及时加速爬升保持能量优势,然后将其转化为速射位置。例如滚转剪式机动中能量优势可以带来各种各样的射击和脱离战斗的机会,与此同时可以使战斗机始终保持进攻性。能量优势主要包括高度优势和速度优势,能量优势可以表示为
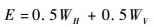 | (1) |
式中:WH=mgΔH为相对势能优势,其中m为作战飞机的质量,g为重力加速度,ΔH为高度差;
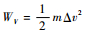
1.2 角度机动理论 角度战术简单地讲,就是通过最快的速度,先敌占据对敌机的绝对位置优势 (通常指机头指向敌机尾部)。而在角度机动过程中,通常会损失能量。并且在大多数情况下,越快失去能量,越可能更快地获得优势角度。故这种战术也被称为“负能量战术”,强调通过尽快失去能量完成对敌的角度优势。以“蛇形机动”这种典型的角度机动战术为例,进攻方尾追防守方,防守方利用快速左右滚转产生的巨大的诱导阻力,急速消耗自身能量,降低速度,使得本处于优势位置的攻击方被迫冲前,从而迅速完成攻守双方位置互换。这种角度机动战术显然是利用失去能量来获得优势角度,明显与持续累计能量的能量机动战术思路相悖。
为分析角度优势,首先给出双机近距空战角度位置关系示意图, 如图 1所示。
 |
| 图 1 角度位置关系示意图 Fig. 1 Schematic diagram of relation of angle and position |
| 图选项 |
图 1中,红方飞机为R,蓝方飞机为B,vB和vR分别表示蓝方飞机和红方飞机的速度。在空战中,战斗机可能会以更小的半径转弯获得角度优势,在这个过程中会失去能量,但是可以维持优势位置 (角度),然后努力维持或增强这种优势,直到取得期望的发射参数为止。通常角度战术的转弯方式有尾追转弯和对头转弯2种。使用Simpson函数可以定量地描述空战对抗双方的角度优势关系:
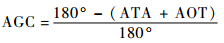 | (2) |
式中:AOT为进入角,即目标机中轴线尾部延长线与瞄准线的夹角;ATA为视线角,即攻击机中轴线前端延长线与瞄准线的夹角。表 1为近距空战对抗双方占位角度关系。
表 1 近距空战双方占位角度关系 Table 1 Relative angular position of two sides in close-range air combat
| 编号 | 攻击机位置 | 目标机位置 | ATA/(°) | AOT/(°) | AGC |
| 1 |  |  | 0 | 0 | 1.00 |
| 2 |  |  | 0 | 45 | 0.75 |
| 3 |  |  | 0 | 90 | 0.75 |
| 4 |  |  | 0 | 180 | 0.50 |
| 5 |  |  | 45 | 135 | 0 |
| 6 |  |  | 90 | 90 | 0 |
| 7 | 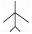 | 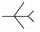 | 90 | 180 | -0.50 |
| 8 | 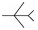 | 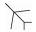 | 135 | 180 | -0.75 |
| 9 |  |  | 180 | 180 | -1.00 |
表选项
从表 1看出,Simpson函数值有正值、零和负值。当Simpson函数值为正值时,表示本机处于优势占位;为负值时,表示敌机处于优势占位;为零时,表示本机与敌机处于中立位置。
此外,2种空战机动理论都会强调武器发射所占有的优势。武器发射站位相当于延长了战机的攻击距离。在计算武器发射优势U时,需要建立机载武器攻击包线的索引表,包括最大攻击距离Rmax,最佳攻击距离 (不可逃逸区)Ropt和最小攻击距离Rmin。假设本机攻击敌机时,当本机与敌机之间的距离R < Rmin或R>Rmax时,敌机处于本机攻击距离之外,此时U=0;当本机与敌机之间的距离Rmin≤R≤Rmax时,使用式 (3) 计算本机武器发射优势U为
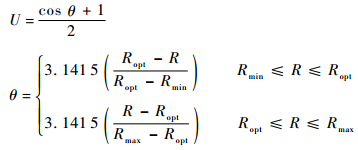 | (3) |
当本机被敌机攻击时,T=-1。武器发射优势T的范围在[—1, 1]之间,T=-1表示本机被敌机攻击,T=1表示敌机处于本机Ropt距离,其他数值表示敌机与Ropt的偏差值。
1.3 空战流程 包以德在长期一对一空战经验基础之上,提出近距空战OODA决策环的概念[12],用以描述飞行员在空战期间决策行为变化的过程。通过OODA决策环的概念,可以分析飞行员在空战期间决策行为的变化过程,从而得到飞行员飞行过程中的决策点。
以飞行员角度看待空战过程,飞行员分析周边态势,根据环境改变做出相应机动动作的整个过程可以分为4个阶段。如图 2所示,OODA分别指观察 (observe)、判断 (judge)、决策 (decide) 以及行动 (act)[13]。其中,由于观察过程以及行动过程主要依靠战斗机上的电子设备以及火控设备完成,所以OODA决策环中最为关键、并且直接影响空战结果的就是飞行员的判断过程以及决策过程。整个决策环描述这样一个过程:战斗机飞行员通过观察发现对手或者感知对手的行动,然后调整自身状态,做出交战的判断,最后进行决策,并进行作战行动。由于包以德提出OODA决策环的概念时,电子对抗手段尚未成熟[12],为简化分析,本文暂不考虑电子对抗等因素。整个OODA决策过程可以分为以下几个阶段 (见图 2)。
 |
| 图 2 OODA环图 Fig. 2 Diagram for OODA loop |
| 图选项 |
观察:使用电子设备或者飞行员对周边情况的感知进行战场观察,从战场环境中发现并搜集有用的信息以及数据。
判断:根据观察得到的信息评估当前的战场态势,并对相关的信息和数据进行处理。
决策:这是OODA决策环中最为关键的一步,决策过程需要根据战场环境信息以及战斗机当前自身状态指定合适的策略,并选择合适的行动方法。
行动:最后根据所选择的方案进行行动。
OODA决策环模型是从飞行员角度对近距空战的一种简洁的描述。由于该过程是在一种动态的、复杂的环境中进行,且易受到不确定性因素的影响,所以OODA决策环具有循环特性、时效性、嵌套性等特点。传统上一般认为,如果敌我双方有一方的OODA决策环比对手的操作周期短,就容易获得优势,并且这种优势是可以积累的。一般而言,经验丰富的飞行员OODA决策过程比新手的决策过程所用时间更短、更高效。在同等条件下,经验丰富的飞行员更具有优势。
2 基于隐马尔可夫模型的空战分析 隐马尔可夫模型 (Hidden Markov Model, HMM) 是一种关于时间序列的概率模型,描述一个由隐藏的马尔可夫链生成不可观测状态随机序列产生的观测随机序列的过程[14-15]。隐藏的马尔可夫链随机生成的状态序列称为状态序列 (state sequence);每个状态生成一个观测,由此产生的观测随机序列称为观测序列 (observation sequence)。其中,序列中的每一个元素就是某一个时刻的数据。本文使用隐马尔可夫模型去分析近距空战决策的过程。
2.1 近距空战的隐马尔可夫模型 由OODA决策环近距空战流程分析可知,飞行员近距空战期间会经历若干个由观察-判断-决策-行动状态组成的循环过程。当飞行员处于OODA决策环中某一个状态时,飞行员会做出不同的机动动作,使得战斗机的姿态发生改变。如果将飞行员操控战斗机进行近距空战这个过程看作一个隐马尔可夫模型的话,那么飞行员在飞行过程中的处于OODA决策环上状态序列就是隐藏的马尔可夫链的状态序列,而飞行员在不同状态期间操控战斗机,使得战斗机姿态发生改变的序列就是观测序列。飞行员在空战中的状态序列是不可观测的,但是战斗机表现出来的姿态变化序列却是可以观测的,通过分析观测序列,使用Baum-Welch算法可以推出飞行员所处的状态序列。
对于战斗机姿态变化可以通过测量战斗机在不同时刻航向、俯仰、侧滚、速度、过载等物理量获得。但是在这些物理量中,哪个物理量与飞行员决策过程有直接关系?本文认为战斗机在飞行过程中过载的观测序列是可以反应飞行员的决策过程,理由如下:当飞行员处于OODA决策环当中观察、判断阶段时,战斗机的姿态不会产生大幅度改变,所以出现小过载的可能性较高,而大过载的可能性较小;而当飞行员经过观察、判断后,进行机动决策时,飞行员开始大幅度飞行,迅速改变飞行的状态,这个时候战斗机速度的变化会很大,出现大过载的可能性较高,而小过载的可能性较低。所以,飞行员在飞行过程中,飞机过载的变化与飞行员决策过程的相关性较高。
设Q={q1, q2, …, qN}为飞行员可能的状态的集合 (OODA决策环的状态),V={v1, v2, …, vM}为所有可能观测的集合 (过载的大小)。其中N为可能的状态数,M为可能的观测数。在本文中,飞行员状态数N=4,飞行员状态集合为{观察,判断,决策,行动};所有可能观测集合数M=3,观测集合为{小过载,中过载,大过载}。
I=(i1, i2, …, iT) 为长度为T的状态序列,O=(o1, o2, …, oT) 为对应的观测序列。A为状态转移概率矩阵:
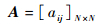 | (4) |
式中:aij=P(it+1=qj|it=qi)(i=1, 2, …, N; j=1, 2, …, N) 为在时刻t处于状态qi的条件下在时刻t+1转移到状态qj的概率。B为观测概率矩阵
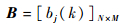 | (5) |
式中:bj(k)=P(ot=vkit=qj) 为在时刻t处于状态qj的条件下生成观测vk的概率。
π为初始状态概率向量
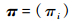 | (6) |
式中:πi=P(i1=qi) 为时刻t=1处于状态qi的概率。本文建立的近距空战隐马尔可夫模型由初始状态概率向量π、状态转移概率矩阵A、观测概率矩阵B决定。其中,π和A决定状态序列,而观测序列由B决定。则隐马尔可夫模型λ可以用三元符号表示,即
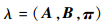 | (7) |
使用隐马尔可夫模型分析近距空战,必须证明对近距空战的观测过程满足:①观测序列满足观测独立性;②隐藏的马尔可夫链满足齐次马尔可夫性。
证明??假设隐藏的马尔可夫链为{Xn, n≥0},称{Xn, n≥0}在n时处于状态i的条件下经过k步转移,于n+k时刻到达状态j的条件概率pij(k)=P(Xn+k=jXn=i)(i, j∈S) 为{Xn, n≥0}在n时的k步转移概率,其中S表示状态空间。称以pij(k)(n) 为第i行第j列元素的矩阵P(k)(n)=(pij(k)(n)) 为{Xn, n≥0}在n时的k步转移矩阵。特别地,当k=1时,{Xn, n≥0}在n时的一步转移概率和一步转移概率矩阵分别记为Pij(n) 和P(n)。显然近距空战中一步转移概率Pij(n) 一定大于等于0,且满足
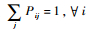
首先证明观测序列满足观测独立性。设状态空间S={0, 1, 2, …},观测序列为X1, X2, …, Xm, …, Xl, …,可知P(X=Xm)=Pm,P(X=Xl)=Pl。有
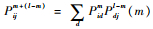
其次,证明隐藏的马尔可夫链满足齐次马尔可夫性。对于n=1, 2, …, m, …,有X1, X2, …, Xm相互独立,得
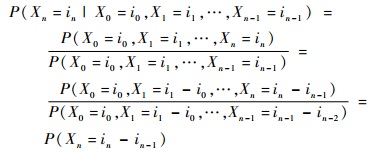 | (8) |
同理
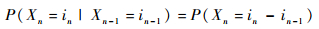 | (9) |
故
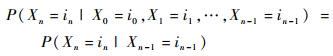 | (10) |
因此,{Xn, n≥0}是一马尔可夫链。????证毕
2.2 Baum-Welch算法 建立完近距空战的隐马尔可夫模型后,本文需要根据数据样本,即观测序列O=(o1, o2, …, oT),推测飞行员可能处于的状态,即状态序列I=(i1, i2, …, iT)。这是一个无监督的学习问题,通过数据估计模型λ=(A, B, π) 的参数,使得在该模型下观测序列概率P(O|λ) 最大,即用极大似然估计的方法估计模型参数;然后根据估计的模型参数λ=(A, B, π),在给定序列的前提下,求出最有可能的对应的状态序列。
假定已知包含S个长度为T的观测序列{O1, O2, …, OS}而没有对应的状态序列,现在需要通过这些观测序列样本学习隐马尔可夫模型λ=(A, B, π) 的参数。若观测序列记为O,状态序列为不可观测的隐数据I,则隐马尔可夫模型是一个含有隐变量的概率模型:
 | (11) |
对这个概率模型的学习可以使用Baum-Welch算法实现[16-17]。下面给出Baum-Welch算法的计算步骤。
输入:观测数据O=(o1, o2, …, oT)
输出:隐马尔可夫模型参数
步骤1??初始化:令n=0,选取aij(0), bj(k)(0), πi(0),得到模型λ(0)=(A(0), B(0), π(0))。
步骤2??递推:对n=1, 2, …
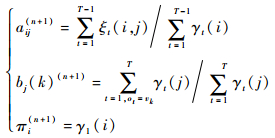 | (12) |
右端各值按照观测O=(o1, o2, …, oT) 和模型λ(n)=(A(n), B(n), π(n)) 计算。
步骤3??终止:得到模型参数λ(n+1)=(A(n+1), B(n+1), π(n+1))。其中,γi(t)=P(it
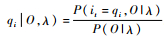
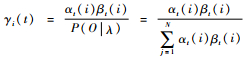
输入:隐马尔可夫模型λ和观测序列O=(o1, o2, …, oT)
输出:观测序列概率P(O|λ)
步骤1??初始化:α1(i)=πibi(oi), i=1, 2, …, N。
步骤2??递推:对于t=1, 2, …, T-1, αt+1(i)=
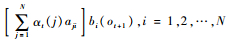
步骤3??终止:
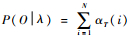
这里需要说明的是,在实际处理过程中,发现直接使用Baum-Welch算法分析观测序列,在采样点过多时,容易形成训练的模型参数趋向0的问题 (降低了分辨率)。针对此问题,本文建议:
1) 数据预处理。在使用算法处理数据之前,对数据进行清洗,并采用合适方法进行采样。本文建议对数据首先进行归一化处理,并且估计数据可能存在的最高频率fs,根据采样定理,按照最高频率的4~5倍进行间隔采样,减少数据点。并且最好使用足够多的样本来形成对比。对于训练模型参数趋于0的问题,本文建议对某些序列做出适当修正。
2) 这里给出一种序列分类方法。假设将需要处理的序列过程为{Xn, n=0, 1, 2, …}。通过分析序列的变化曲线,首先计算序列的平均值,然后根据平均值划定一条基准线,然后在此基准线基础上,确定所有的波峰值x1, x2, …, xk,以波峰值为样本,分析其众数,然后根据需要对序列划定不同的区间范围。本文给出一种划分3个区间范围 (即大过载、中等过载和小过载) 的经验方案:第1区间范围在0到平均值之间,第2区间范围在平均值到众数乘以1.5之间,第3区间范围在众数乘以1.5到最大值之间。
2.3 维特比算法求解隐马尔可夫模型 通过训练样本得到模型λ=(A, B, π) 参数的估计值之后,给定观测序列之后,可以使用维特比算法 (Viterbi algorithm) 求解隐马尔可夫模型的预测问题[18-20]。维特比算法的实质是通过动态规划 (dynamic programming) 求解概率最大路径。而每一条路径对应一个状态序列。导入2个变量δ、ψ,定义在时刻t状态为i的所有单个路径 (i1, i2, …, it) 中概率最大值为
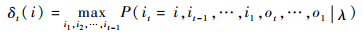 | (13) |
容易理解,式 (13) 的递推公式为
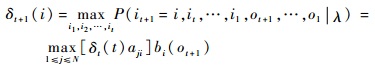 | (14) |
定义在时刻t状态为i的所有单个路径 (i1, i2, …, it-1, i) 中概率最大的路径的第t-1个结点为
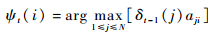 | (15) |
下面给出维特比算法计算步骤:
输入:模型的估计值λ=(A, B, π) 和观测序列O=(o1, o2, …, oT)
输出:最优状态序列I*=(i1*, i2*, …, iT*)
步骤1??初始化:δ1(i)=πibi(o1), ψ1(i)=0。
步骤2??递推:对t=2, 3, …, T
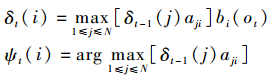 |
步骤3??终止:
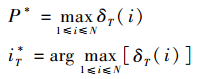 |
步骤4??最优路径回溯:对t=T-1, T-2, …, 1,it*=ψt+1(it+1*),求得最优状态序列I*=(i1*, i2*, …, iT*)。
3 决策点理论分析方法 通过第2节基于隐马尔可夫模型的空战流程分析,可以得到空战对抗过程中敌我双方的空战决策点 (下文用红方表示我方,用蓝方表示敌方,双方战机性能相同)。在得到决策点后,需要采用合适的处理方法对数据进行处理,将实验数据转化为可视的研究结论。本文提出几种分析理论。需要说明的是,国内外对空战决策点的研究几乎为空白,本文仅仅根据决策点数据,提出了以下几种分析方法,缺乏理论上的支撑。
3.1 决策点包络分析理论 本文认为,决策点是飞行员在空战过程中,通过机动动作,将自身劣势转化为优势或者增强优势迫使敌方迅速陷入困境的一系列点。所以决策点理论上应该是一些态势的转折点,具有高能量优势或者高角度优势。图 3给出2段空战过程的所有采样点的能量 (描述能量优势) 与AGC (描述角度优势) 的序列点图 (命名为能量-角度序列图),其中红圈表示红方能量-角度序列点,蓝圈表示蓝方能量-角度序列点。需要说明的是,2张图描述的空战过程中,红方均获得了胜利。图 3(a)描述红方利用“滚转剪刀”机动战术获得胜利 (典型的能量机动),而右图描述红方利用“蛇形机动”战术获得了胜利 (典型的角度机动)。从图 3可以看出,图 3(b)描述的空战过程比图 3(a)的空战过程要更为剧烈一些。
 |
| 图 3 空战中能量-AGC序列 Fig. 3 Energy-AGC sequence in air combat |
| 图选项 |
图 3(a)表示的能量机动中,可以看出红方的能量相对于蓝方要多一些,通过一系列机动动作,成功地占据优势站位,从而击落蓝方。从图 3(b)可以看出,整体上红方大多数情况下拥有占位的优势,但是能量稍逊于蓝方,虽然蓝方有很多时刻具有绝对优势,但是红方通过“蛇形机动”将敌我态势互换,从而获取了胜利。图 3是所有序列点的能量-角度序列图。图 4给出这2段空战过程中关键决策点 (红蓝双方对应时刻的所有决策点) 的能量-角度序列图。
 |
| 图 4 决策点的能量-AGC序列 Fig. 4 Energy-AGC sequence for decision-making point |
| 图选项 |
图 4为2段空战过程决策点形成的能量-角度序列图,可以看出,虽然所有序列点得到的能量-角度序列图红蓝双方点虽然聚集为若干类,但是彼此之间互为包含。但是决策点形成的能量-角度序列图却明显呈现出红方在右上方包围蓝方的情况,形成了决策点包络。而红方在右上方,说明在这些决策点上,红方的能量与角度均占优势。本文提出这样一种观点,对于空战决策过程而言,如果某一方的空战决策点在能量-角度序列图上更具有能量优势和角度优势 (即靠近图中右上角),则这一方更具备空战优势。并且,对于急速复杂的机动动作,其决策点的个数越多。
3.2 决策点包含能量理论 使用隐马尔可夫模型,不仅可以求出空战过程中的决策点,还可以求解出空战过程中的行动点。对于某一段空战过程而言,假设tA时刻表示空战过程某个决策点,而tB表示该决策点过程对应的行动点时刻 (对于某个决策点而言,不一定存在对应的行动点,如果出现此种情况,取之后时刻速度变化超过一定程度的时刻为行动点时刻)。使用
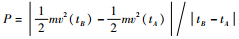
 |
| 图 5 包含能量变化过程 Fig. 5 Changing process of inherent energy |
| 图选项 |
为了方便显示,本文对纵坐标加以压缩。通过图 5可以发现,2段空战过程中红方的决策点包含能量要远远高于蓝方的包含能量。这说明红方决策点在单位时间内将更多的能量转化为位置或者角度的优势。这也是红方可以取胜的关键因素。
4 实验仿真及分析 在仿真中,主要需要进行2个实验:①验证使用过载作为观测序列,构建隐马尔可夫模型可以准确判断出飞行员决策点这个方法的可行性;②使用隐马尔可夫模型分析飞行数据,讨论飞行员决策点对于空战结果的影响。
仿真实验1??隐马尔可夫模型的可行性
这里给出一个近距空战中常见的前置追逐摆脱战术[21]。如图 6所示,攻击机采用前置追逐机动攻击目标机,若攻击机处于武器射程之外时,目标机对前置追逐机动可以采用2种防御措施。假如目标机具备速度优势,目标机则可以采用实线所示轨迹,目标机转弯脱离攻击机以尽可能降低AOT,然后利用速度优势,尽快增加与攻击机的距离。这时,目标机可以脱离战场,或者提供足够间距使之可以转向攻击机并与之迎头相遇,使攻击机的角度优势不复存在。若目标机速度较低,则可以采用虚线所示轨迹,速度较低能够通过减少转弯半径来防止弧形轨迹带来的负面影响。且在AOT很大的情况下与攻击机相遇。不管目标机采取何种摆脱战术,此时2种方案的起始点就是所谓的飞行员“决策点”。在决策点之后,目标机就开始行动了,决策点之后就是所谓的飞行员“行动点”。
 |
| 图 6 典型的逃逸战术 Fig. 6 Typical escape tactical maneuver |
| 图选项 |
现在主要观察前置追逐摆脱战术中目标机飞行轨迹的变化,文献[21]给出的2段数据作为样本数据。2段样本的攻击机与目标机均采用图 6中虚线所示的飞行轨迹,采样点有24个,采样频率为1 Hz。建立隐马尔可夫模型,随机选择一段样本当作训练样本,使用Baum-Welch算法进行参数学习;另一段样本数据作为测试样本,使用维特比算法进行状态序列的预测。首先对训练样本使用Baum-Welch算法进行参数学习。对于过载的观测序列,小过载记为“1”,中过载记为“2”,大过载记为“3”。对于训练样本,T=24,观测序列为O={o1, o2, …, oT}。得到模型参数的估计值
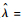
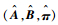
表 2 飞行员决策点 Table 2 Decision-making point of pilot
| 编号 | 目标机状态 |
| 1 | 观察点 |
| 2 | 观察点 |
| 3 | 观察点 |
| 4 | 观察点 |
| 5 | 观察点 |
| 6 | 观察点 |
| 7 | 判断点 |
| 8 | 判断点 |
| 9 | 判断点 |
| 10 | 决策点 |
| 11 | 行动点 |
| 12 | 观察点 |
| 13 | 观察点 |
| 14 | 观察点 |
| 15 | 观察点 |
| 16 | 观察点 |
| 17 | 观察点 |
| 18 | 观察点 |
| 19 | 观察点 |
| 20 | 观察点 |
| 21 | 观察点 |
| 22 | 观察点 |
| 23 | 观察点 |
| 24 | 观察点 |
表选项
并在图 7所示的目标机飞行轨迹图中标记出。
 |
| 图 7 目标机轨迹图 Fig. 7 Trochoid of target plane |
| 图选项 |
通过图 7所示的目标机飞行轨迹图可以看出,目标机轨迹中红色圆点是目标机的决策点,而行动点使用红色五角星标记出来。实验结果与图 6理论分析是一致的,说明了使用过载作为观测序列,构建隐马尔可夫模型可以准确判断出飞行员决策点方法的可行性。
这里给出一种典型的“预先转弯”典型机动动作。2架飞机以一定的横向间隔迎头相遇,在通过正前方之前,其中的一架飞机开始预先转弯以接近另外一架飞机,或者可以继续保持前进在进行转弯从而尾追敌方。这个圆形点就是“预先转弯”机动动作的决策点,而五角星表示此决策点对应的行动点, 如图 8所示。
 |
| 图 8 预先转弯轨迹图 Fig. 8 Trochoid of pre turn |
| 图选项 |
同样采集若干样本点,使用建立隐马尔可夫模型,通过算法训练样本数据,最后得到最后的仿真结果,如图 9所示。
 |
| 图 9 典型预先转弯仿真图 Fig. 9 Simulation diagram of typical "pre turn" |
| 图选项 |
从上面的仿真实验可以看出,使用本文建立的隐马尔可夫模型进行准确判断出飞行员决策点方法的可行性。
仿真实验2讨论决策点对空战结果的影响
仿真实验2使用文献[11]给出的实例。在这个实例中,文献从训练数据航向角、俯仰角、侧滚角、速度、高度和空战能量等物理量入手,使用模糊聚类的方法得到单属性决策点。然后通过构建条件属性相对重要度矩阵,构建模糊粗糙决策系统,最后得到决策关键点。图 10为文献[11]使用模糊聚类方法得到的对抗双方的关键决策点集合, 其中K表示起始时刻。在这个实例中,红蓝双方使用同种型号战斗机,但是蓝方一直被红方压制,并且蓝方的决策过程比较犹豫,所以红方一共攻击蓝方2次,但是蓝方几乎没有还手之力。
 |
| 图 10 对抗双方的关键决策点集合[11] Fig. 10 Key decision-making set of two sides[11] |
| 图选项 |
事实上,如果将这个实例中对抗双方的能量优势、角度优势和武器发射优势当作输入变量,通过文献[11]提出的方法得到决策的关键点,与本文提出使用过载数据构建隐马尔可夫模型得到决策关键点进行比较,会对这个空战过程有更为深入的理解。
本文对文献[11]给出的实例进行复现,使用本文方法进行求解。表 3和表 4分别使用文献[11]给出方法和本文给出方法计算的红蓝双方关键决策点列表,计算出红方有决策关键点12个,蓝方有6个,这一点与文献得到的结果相同;并且2种方法得到的决策点出现的时间事实上相差不大,也间接验证了文献与本文给出方法求解决策点的合理性;但是原文献不能给出飞行员在飞行过程中OODA决策环中判断点的时间,使用本文方法可以求得这些判断点。本文求得这些判断点 (相应决策点对应的判断点时间是指决策点之前判断点当中最早的一个判断点的时间),并且计算出双方飞行员从判断到决策所用的时间,具体结果见表 3和表 4。
表 3 红方决策点集合 Table 3 Decision-making set of red sides
| 编号 | 文献[11]给出的决策点时刻 | 使用隐马尔可夫模型得到的决策点时刻 | 对应的判断点时刻 | 判断过程所用的时间 |
| 1 | K+18 | K+19 | K+18 | 1 |
| 2 | K+25 | K+25 | K+24 | 1 |
| 3 | K+30 | K+30 | K+29 | 1 |
| 4 | K+34 | K+36 | K+34 | 2 |
| 5 | K+49 | K+48 | K+47 | 1 |
| 6 | K+51 | K+52 | K+51 | 1 |
| 7 | K+57 | K+57 | K+57 | 0 |
| 8 | K+64 | K+65 | K+64 | 1 |
| 9 | K+71 | K+71 | K+70 | 1 |
| 10 | K+75 | K+73 | K+72 | 1 |
| 11 | K+92 | K+92 | K+91 | 1 |
| 12 | K+99 | K+98 | K+98 | 0 |
表选项
表 4 蓝方决策点集合 Table 4 Decision-making set of blue sides
| 编号 | 文献[11]给出的决策点时刻 | 使用隐马尔可夫模型得到的决策点时刻 | 对应的判断点时刻 | 判断过程所用的时间 |
| 1 | K+19 | K+19 | K+17 | 2 |
| 2 | K+45 | K+44 | K+40 | 4 |
| 3 | K+62 | K+61 | K+59 | 2 |
| 4 | K+79 | K+79 | K+77 | 2 |
| 5 | K+107 | K+108 | K+107 | 1 |
| 6 | K+112 | K+112 | K+111 | 1 |
表选项
从表 3和表 4可以得出如下结论:①从双方总体的决策过程来看,在双方武器装备处于同等条件下,决定空战结果的关键因素在于飞行员判断过程所用的时间。即当双方武器性能大体相同时,空战结果取决于OODA决策环的效率,如果某一方从判断到决策时间更短,哪一方就具有优势。红方从判断到决策平均所用时间约为1 s (考虑到样本采样频率,实际时间比1 s要更少),而蓝方决策比较优柔寡断,从判断到决策平均用时超过2 s),由于红方飞行员决策相当果断,所以红方飞行员期间一直阻止蓝方飞行员采取有效措施,使得蓝方飞行员在做无用功;②从蓝方飞行员决策过程来看,蓝方飞行员刚开始做出决策的时间与红方飞行员几乎是同时的 (K+19 s),甚至蓝方飞行员比红方飞行员更早的进行判断 (蓝方K+17 s,红方K+18 s),但是从飞行数据上显示,红方飞行员并没有收到蓝方飞行员决策过程的影响,相反地,蓝方飞行员却受到红方飞行员的影响。在后期,蓝方飞行员的判断过程所用时间明显缩短,但这不是由于蓝方飞行员判断能力提高的结果,而是由于后期,蓝方飞行员被迫进行决策的缘故。蓝方飞行员需要不断调整自身的状态,当蓝方正要做决策时,发现由于红方已经开始行动,空战态势又发生变化,蓝方又被迫进入观察判断阶段,这就导致蓝方陷入“OO”死循环,有意义的决策很少。这说明,作战双方如果有一方不跟对手的OODA环走,依旧我行我素,那么OODA环对对手是没有用的;③从整体来看,红方飞行员决策点数量明显多于蓝方飞行员,红方飞行员决策的效率也明显高于蓝方飞行员,红方飞行员一直积累这种优势,导致红方飞行员明显处于优势。这说明,提高飞行员决策能力是空战制胜的关键要素,如果飞行员决策能力偏弱,即使拥有足够的信息也不能快速做出决策,也就是说即便拥有信息优势,其OODA运行效率由于飞行员素质低下而仍然处于劣势,要赢取空战胜利就比较困难;反过来,如果飞行员决策能力强,即使信息不足,其OODA决策过程仍有可能处于优势,从而赢得胜利。
图 11给出了空战过程中决策点的能量-AGC序列图。
 |
| 图 11 空战实例决策点的能量-AGC序列 Fig. 11 Energy-AGC sequence for decision-making of two sides in air combat |
| 图选项 |
从图 11可知,此次空战过程中,红方的决策点明显占据优势,增加了红方胜利的概率。图 12给出两方的包含能量的变化过程。
 |
| 图 12 双方包含能量变化过程 Fig. 12 Changing process of inherent energy of two sides |
| 图选项 |
通过分析红蓝双方的能量变化过程,可以看出前期红蓝双方的能量相差不大,但是后期红方的能量优势逐渐体现出来了,说明了红方使用能量机动战术的有效性。
5 结论 1) 本文从飞行员决策过程角度回答飞行员决策对于空战结果的影响,使用隐马尔可夫模型分析近距空战,使用维特比算法预测飞行员状态序列,得到飞行员在空战过程中的决策点。
2) 通过实验分析,发现在双方武器装备处于同等条件下,决定空战结果的关键因素在于飞行员判断过程所用的时间。飞行员从判断到决策所用时间越少,飞行员优势越大。经验丰富的飞行员相较于新手而言,决策更为果断,所用时间更少,几乎是下意识就做出决定,所以经验丰富的飞行员在空战中更具有优势。
3) 本文也发现,空战双方如果对手不跟我方的OODA环走,依旧我行我素,那么我方的OODA环对敌方的影响是有限的。
4) 空战决策点理论作为一个新的空战理论,仍有许多研究空白:对于观测序列状态区间范围的选择仍然依靠人为经验给定。对于决策点分析方法仍然缺少理论支撑。战机飞行时数据量巨大,如何利用算法高效处理这些数据,仍然是个问题。这些将在下一步的研究工作中加以考虑。
参考文献
| [1] | 傅莉, 王晓光. 无人战机近距空战微分对策建模研究[J].兵工学报, 2012, 10(10): 1210–1216.FU L, WANG X G. Research on close air combat modeling of differential games for unmanned combat air vehicles[J].Acta Armamentarii, 2012, 10(10): 1210–1216.(in Chinese) |
| [2] | KRISHNA K K, KANESHIGE J.Artificial immune system approach for air combat maneuvering[C]//Proceedings of SPIE-The International Society for Optical Engineering.Bellingham:SPIE, 2007:274-299. |
| [3] | ROGER W S, ALAN E B.Neural network models of air combat maneuvering[D].Las Cruces:New Mexico State University, 1992:125-131.. |
| [4] | 张立鹏, 魏瑞轩, 李霞. 无人作战战斗机空战自主战术决策方法研究[J].电光与控制, 2012, 19(2): 92–96.ZHANG L P, WEI R X, LI X. Autonomous tactical decision-making of UCAVs in air combat[J].Electronics Optics & Control, 2012, 19(2): 92–96.(in Chinese) |
| [5] | NUSYIRWAN I F, BIL C.Factorial analysis of a real time optimization for pursuit-evasion problem[C]//Proceedings of the 46th AIAA Aerospace Science Meeting and Exhibit.Reston:AIAA, 2008:195-198. |
| [6] | 杨俊, 谢寿生. 基于模糊支持向量机的飞机动作识别[J].航空学报, 2005, 26(6): 738–742.YANG J, XIE S S. Fuzzy support vector machines based recognition for aeroplane flight action[J].Acta Aeronautica et Astronautica Sinica, 2005, 26(6): 738–742.(in Chinese) |
| [7] | KAI V, JANNE K, TUOMAS R. Modeling air combat by a moving horizon influence diagram game[J].Journal of Guidance, Control, and Dynamics, 2006, 29(5): 1080–1091. |
| [8] | 钟友武, 柳嘉润, 申功璋. 自主近距空战中敌机的战术动作识别方法[J].北京航空航天大学学报, 2007, 33(9): 1056–1059.ZHONG Y W, LIU J R, SHEN G Z. Recognition method for tactical maneuver of target in autonomous close-in air combat[J].Journal of Beijing University of Aeronautics and Astronautics, 2007, 33(9): 1056–1059.(in Chinese) |
| [9] | 张涛, 于雷, 周中良, 等. 基于混合算法的空战机动决策[J].系统工程与电子技术, 2013, 35(7): 1445–1450.ZHANG T, YU L, ZHOU Z L, et al. Decision-making for air combat maneuvering based on hybrid algorithm[J].Systems Engineering and Electronics, 2013, 35(7): 1445–1450.(in Chinese) |
| [10] | 刘波, 覃征, 邵利平, 等. 基于群集智能的协同多目标攻击空战决策[J].航空学报, 2009, 30(9): 1727–1739.LIU B, QIN Z, SHAO L P, et al. Air combat decision making for coordinated multiple target attack using collective intelligence[J].Acta Aeronautica et Astronautica Sinica, 2009, 30(9): 1727–1739.(in Chinese) |
| [11] | 左家亮, 杨任农, 张滢. 基于模糊聚类的近距空战决策过程重构与评估[J].航空学报, 2015, 36(5): 1650–1660.ZUO J L, YANG R N, ZHANG Y, et al. Reconstruction and evaluation of close air combat decision-making process based on fuzzy clustering[J].Acta Aeronautica et Astronautica Sinica, 2015, 36(5): 1650–1660.(in Chinese) |
| [12] | VEERASAMY N.A high-level mapping of cyberter-rorism to the OODA loop[C]//Proceedings of 5th European Conference on Information Management and Evaluation.Red Hook, NY:Curren Associates Inc., 2011:352-360. |
| [13] | 黄建明, 高大鹏. 基于OODA环的作战对抗系统动力学模型[J].系统仿真学报, 2012, 24(3): 561–574.HUANG J M, GAO D P. Combat systems dynamics model with OODA loop[J].Journal of System Simulation, 2012, 24(3): 561–574.(in Chinese) |
| [14] | RABINER L, JUANG B. An introduction to hidden Markov models[J].IEEE ASSP Magazine, 1986, 28(7): 6–10. |
| [15] | RABINER L. A tutorial on hidden Markov models and selected applications in speech recognition[J].Proceedings of the IEEE, 1989, 77(2): 257–286.DOI:10.1109/5.18626 |
| [16] | BAUM L, PETRIE T, SOULES G, et al. A maximization technique occurring in the statistical analysis of probabilistic functions of Markov chains[J].Annals of Mathematical Statistics, 1970, 41(3): 164–171. |
| [17] | BILIMES J A.A gentle tutorial of the EM algorithm and its application to parameter estimation for Gaussian mixture and hidden Markov models[EB/OL].(1997-06-15)[2016-03-21].http://ssli.ee.washington.edu/~bilmes/mypubs/bilmes1997-em.pdf. |
| [18] | LARI K, YOUNG S J. Applications of stochastic context-free grammars using the inside-outside algorithm[J].Computer Speech & Language, 1991, 5(3): 237–257. |
| [19] | GHAHRAMANI Z. Learning dynamic Bayesian networks[J].Lecture Notes in Computer Science, 1997, 45(2): 168–197. |
| [20] | RADFORO N, GEOFFREY H, JORDAN M.A view of the EM algorithm that justifies incremental, sparse, and other variants[M]//JORDAN M I.Learning in graphical models.Cambridge, MA:MIT Press, 1999:355-368. |
| [21] | ROBERT S. Fighter combat:Tactics and maneuvering[M].Annapolis, MD: Naval Institute Press, 1985: 84-86. |
