全文HTML
--> --> -->目前已知的具有超越经典计算优势的量子算法主要可以归为三大类[16]. 第一类是利用量子傅里叶变换寻找周期的量子算法, 包括Shor算法[5]、Simon算法[18]、以及Hallgren算法[19]等. 第二类是以有量子加速的Grover搜索算法[20]为基础的搜索及优化算法—可以在

量子算法与经典算法的很大一点不同是量子力学允许的量子操作、量子叠加和量子纠缠很难直接与直观经验建立联系, 甚至是反直觉的. 这极大地增加了量子算法设计的难度, 同时使得人们在经典计算算法设计上积累的经验很难被直接借用[16].
在开发设计量子算法时, 我们期待设计出能够相比于经典计算更高效的量子算法. 对于可以在量子计算机上以多项式时间解决的问题, 人们把它们归为BQP (bounded-error quantum polynomial time)复杂类. 目前人们还没有一个普适的理论来确定这类问题的边界, 在后文中我们将对此做更具体的介绍. 虽然通常人们不认为量子计算能够指数加速NP-complete问题, 但在具体算法设计中, 任何能够提升量子计算能力的设计方法和技巧都值得尝试[21]. 在量子计算的发展进程中, 我们也可以适当借鉴经典计算领域的发展. 设计出具有量子优势的量子算法还有待于量子研究领域与经典计算研究领域的深度交融.
Farhi等[22,23]在2001年提出了与量子线路模型相应的绝热量子计算模型—AQC (adiabatic quantum computation). 在绝热量子计算中, 我们首先会构造一个非平庸的问题哈密顿量, 其基态编码了我们关心问题的答案. 然后我们让系统从一个与问题哈密顿量非对易的平庸哈密顿量基态开始做演化, 一直演化到这个编码的问题哈密顿量. 如果整个演化过程是完全绝热的并且基态与激发态之间始终存在能级差[24], 我们最后也就能获得问题哈密顿量的基态, 即这个计算问题的正确解. 这也就将一个计算问题变成了一个哈密顿量求基态的问题. 绝热量子计算模型可以看作连续时间的量子计算, 其与离散时间的量子线路模型的等价性也在理论上得到了证明[25,26]. “演化体系哈密顿量”这一想法与量子模拟非常接近. 而人们在量子模拟及量子控制方面也具备了很多理论知识和实验经验[27–30]. 所以绝热量子计算概念的提出不但给我们提供了一种全新的普适量子计算框架, 而且有利于将我们对量子模拟的物理直觉与量子算法设计结合起来以打开新思路. 后文将详细介绍绝热量子计算的算法设计.
经典计算领域的算法设计复杂程度也在愈趋加大, 如何实现经典算法的自动化设计也变得越来越重要. 对于一个问题, 如果存在多种可以解决的算法, 那么如何高效地挑选一个最优的算法就非常关键. 这就涉及算法选择问题(algorithm selection)[31]; 而对于一个算法, 在不同的问题例子中如何去优化算法构型(algorithm configuration)[32]也相当重要. 我们将在后文中详细介绍机器学习在经典算法设计领域的应用. 另一方面, 近些年机器学习也在处理量子多体问题上, 特别是在物态的相分类[33–37]、多体波函数的表示及基态制备[38–41]、优化量子操控[42–45]等方向上有了一系列的应用.
虽然经典与量子算法的设计领域差别很大, 但两者的复杂性使得它们都面临着巨大挑战. 通过借鉴机器学习在经典算法设计与量子多体物理中的成功应用, 我们也希望机器学习方法能辅助量子算法设计. 这不仅会帮助我们设计出具有量子优越性的算法, 同时设计获得的量子算法也有望实现机器学习的量子加速[46]. 我们期待这两个领域的交融会碰撞出灵感的火花.
2
2.1.绝热量子计算
绝热量子计算作为一种普适的量子计算框架[22,23,25,26,47], 其原理是将一个计算问题变成量子体系求基态的问题. 设想有两个非对易的哈密顿量










绝热量子计算在被提出之时就将目标指向解决NP-complete和NP-hard问题[22,23]. 而后, 对其是否能够超越经典计算的质疑也接踵而来—因为对于这类NP-complete和NP-hard问题, 其最小能隙呈指数减小, 所以绝热量子计算需要的时间是指数增长的. 其并不能做到相比于经典算法的指数加速, 但可能在系数因子上会比经典的算法更优[50–55].
2
2.2.哈密顿量编码
本节将介绍绝热量子计算哈密顿量编码与自旋玻璃问题的关联. 也将介绍三个典型计算问题的哈密顿量构造方法.3
2.2.1.哈密顿量编码与自旋玻璃问题
在理论和实验中, 总可以将绝热量子计算的哈密顿量编码为伊辛自旋模型的量子形式[56,57]. 一个经典的伊辛自旋模型可以写作:






这样的问题哈密顿量构造与物理中的自旋玻璃模型可以一一对应. 自旋玻璃问题是一个在凝聚态物理和统计及计算物理领域中悠久且丰富的物理问题[58–60]. 自旋玻璃问题和NP(nondeterministic polynomial) 问题的联系也备受关注. 这种关联给了我们从物理角度来理解计算中的困难的机会[61–63]. Karp[64]在1972年研究发现21个组合及图论计算问题都可以在多项式时间归约到一个NP-complete问题上, 也就证明了它们都是NP-complete问题. Lucas[65]研究了这些典型NP-complete问题如何编码为自旋玻璃形式的问题哈密顿量. 一般人们也会把这类编码后的问题叫作QUBO (quadratic unconstrained binary optimization) 问题.
3
2.2.2.基于绝热量子计算的Grover搜索算法
基于线路模型的Grover搜索算法被证明具有超越经典搜索算法的平方加速[20]. 这个搜索问题是指在











3
2.2.3.基于绝热量子计算的3-SAT算法
布尔可满足性问题(Boolean satisfiability problem)中含有n个布尔变量















3
2.2.4.基于绝热量子计算的质因数分解算法
质因数分解问题是希望将一个大数N分解为两个质因数p和q, 也就是实现


2
2.3.绝热量子计算与BQP复杂类
自从Shor[5]提出质因数分解的多项式算法以来, 量子计算领域获得了更广泛的关注, 也涌现出许多不同新的研究方向. 然而不同于量子计算复杂度理论、量子密码学以及量子纠错等领域的快速发展, 量子算法设计作为量子计算研究的核心问题之一, 特别是设计出相比经典算法具有指数加速的量子算法, 并没有如人们想象中那样顺利推进. 对于这一现象, Shor[16]指出, 一个可能的原因, 是由于人们没有像设计经典算法一样好的直觉设计量子算法. 而找到能充分展现量子计算机超越经典计算机能力的BQP问题具有十分重要的现实意义.在计算复杂度理论中, BQP问题是指在量子计算机上存在多项式规模的量子线路并且出错概率小于1/2求解的一类判定问题(decision problem)[80], 简言之, 就是能在量子计算机上在多项式时间内求解的问题. 与其类似的经典计算问题是BPP(bounded-error probabilistic polynomial time)问题, 它被定义为能在多项式时间内被概率图灵机以有界的错误率求解的判定问题. 虽然在具体问题中, 如质因数分解[5]、二次符号权重计数问题(quadratically signed weight enumerator problem)[81]、琼斯多项式估计(approximation of Jones polynomials)[82,83], local Hamiltonian本征值采样问题(LHES)、相位估计采样问题(PES)、酉矩阵平均本征值估计(LUAE)[84]等问题上量子计算可以做到指数加速, 但BQP计算复杂类的边界仍然是未解决的理论问题. 在量子计算机上可以高效解决的问题仍有待进一步探索.
前文提到, 由于人们缺少量子世界观以及量子线路模型难以提供好的算法设计直觉, 那么绝热量子算法会是寻找BQP问题的一条途径. 量子线路模型被证明能以多项式量级的步骤转换为一个绝热量子算法[25]. 因此利用量子线路模型定义的BQP问题, 也可以等价地在绝热计算机上定义. 若对于要求解的问题有已知的量子线路算法, 那么可以根据已知的线路模型中的一系列门操作构造出初始哈密顿量和问题哈密顿量, 使得问题哈密顿量的基态为历史态



2
3.1.机器学习分类
1956年的达特茅斯会议中, “用机器来模仿人类学习以及其他方面的智能”的观点被首次提出[86]. 机器学习往往面对的是大量的数据, 通过学习来拟合出其中的复杂关系. 我们期待机器能自行学会数据中的关联, 并能给出符合人类逻辑认知甚至超越人类能力的预判. 近些年来, 机器学习在图像识别[87]、自然语言处理[88]以及策略游戏[89]等方面表现出令人称叹的能力, 其中非常值得一提的就是误差逆传播算法(error back propagation)[90]在多层神经网络中的应用. 一个多层神经网络可被分为输入层、隐藏层和输出层, 其中每一个隐藏层和输出层的神经元中都含有激活函数(可被激活或抑制来模仿生物的神经元机能). 在训练时我们将信号逐层向前传递直到输出层, 而后将误差逆传递来更新权重. 我们期待训练好的网络会有很强的表示能力与泛化能力. 也即是, 对于一个完全陌生的输入数据, 网络也能给出符合预期甚至超越人类认知的判断. 机器学习的方法主要有三大类[91]: 监督学习、无监督学习和强化学习. 监督学习中具有代表性的是处理“分类”和“回归”问题. 需要给机器大量的带标签数据. 机器通过学习数据特征和标签的关联, 获得对新数据进行预测的能力. 如果预测的结果是离散的, 就属于“分类”; 如果预测的结果是连续的, 就属于“回归”. 对于无监督学习, 给机器的是不带标签的数据, 也就是希望机器能够自己发现数据之间的共同特征, 将相关的部分归为一类进行“聚类”. 强化学习[89]则是让智能体与环境进行有探索地交互来训练获得最大奖励. 智能体在某一个状态

2
3.2.机器学习在经典算法设计中的应用
随着经典算法设计变得越来越复杂, 机器学习也被用在设计经典算法上. 1976年Rice[31]就提出了“算法选择问题”, 他将“算法选择问题”与“没有免费午餐定理”[96]相提并论—对于任何算法, 想要其表现好于其他算法就必须付出代价. 换句话说, 即没有一个普适的最好算法来解决一大类问题. 在面对拥有多种求解算法的一类问题(特别是NP-hard问题)中, 不同问题实例的求解效果不尽相同. 如何挑选出其中最好的算法就显得非常关键[97]. 下面通过回顾在经典领域的自动化算法设计, 期待能对量子算法的设计有一些启发.在早期工作中, 人们通过将算法选择问题映射为马尔科夫决策过程, 利用强化学习选择算法来使得算法运行时间最短[98]以及并行不同算法加速求解组合搜索问题[99]. 为了预测不同算法在具体问题求解中的所需时间, 需要根据人类专家知识预先选择出可能影响问题计算时间的特征, 将一系列问题的特征和和真实算法所需运行时间作为数据集, 通过学习利用回归方式预测每个算法在具有某些特征的问题上求解所需时间[100,101]. 值得一提的是, 连续多年蝉联SAT比赛冠军的SATzilla[102]在处理3-SAT问题时会利用预设的求解算法在短时间内求解那些简单的问题实例. 而对于那些没有在短时间内被求解的问题实例, 其将根据问题特征来挑选出预测的最好算法进行求解. 曾经用于分类的元学习(meta-learning)也被运用到算法选择中[103], 不同的机器学习方法在算法选择问题上的表现也得到了评估和对比[104]. 机器学习在推荐系统(特别是在购物网站)中的成功应用也推动了自动化算法推荐系统的出现[105].
与算法选择问题相应的, 算法本身就具有许多可被调整的参数. 手动对大量的参数进行“调参”不仅费时也非常依赖于专业知识. 算法构型的设计[32]就是在高维参数空间中选择出最佳的算法构型参数. 目前已开发的一系列算法构型设计工具包[106–109]都可以给出优化的固定参数算法构型. 但人工智能算法在计算过程中需要不断迭代, 最佳的算法参数一般会随着整个程序运行的时间而发生变化. 为此, 利用强化学习[110]以及基于启发式算法[111]的动态算法构型设计框架也被提出.
算法选择问题是希望获得一个选择机制以在面对新的问题实例时挑选出最佳的算法, 而算法构型设计是对算法本身的参数做优化. 在经典计算算法设计上人们也有将两者进行融合[112]以获得对困难问题的高效计算.
2
3.3.量子与经典组合算法
量子算法的设计与研究并不是一蹴而就的. 在研究与设计量子算法的过程中, 人们也会将经典算法中的一些思想与手段加以利用, 进而设计出量子与经典的组合算法. 一般地, 这些组合算法按照形式可以分为以下两类.其一是利用量子系统具有的优越性来实现一些经典算法, 其中具有代表性的是量子机器学习(quantum machine learning, QML). 量子机器学习领域主要研究如何借助量子系统中的叠加与纠缠等性质来实现经典机器学习算法的加速[113]. 在机器学习算法中, 有很多算法本质上都可以分解为基于矩阵的一些线性代数运算. 在这些线性代数运算中, 对于傅里叶变换[5]、寻找矩阵特征值与特征向量[15]以及求解线性方程组[114,115]等运算, 都有着相比经典算法有指数或者多项式级别加速的量子算法. 这一系列具有量子加速的线性代数运算(quantum basic linear algebra subroutines, qBLAS)[113]可以加速许多机器学习领域中的算法, 例如最小二乘法[116]、梯度下降法与牛顿法[117]、半正定规划[118]、主成分分析[119]、拓扑分析[120]、支持向量机[121]等. 在这些机器学习算法的实现中, 为了避免经典数据的输入与读取成为限制算法效率的瓶颈, 量子随机读取内存(quantum random access memory, qRAM)[122]技术被提出, 并旨在极大地提升数据读取的效率. 量子机器学习的另一大研究领域是利用量子模拟器或可编程量子线路以建立量子深度学习网络(deep quantum learning network)[123,124]. 基于玻尔兹曼分布的量子玻尔兹曼机(quantum Boltzmann machine)将神经网络表示成为伊辛模型下量子自旋及其间的相互作用, 通过训练和优化过程使得量子系统可以学习到数据的概率分布[125]. 相较于经典版本, 量子玻尔兹曼机可以更有效地加速训练过程[126], 同时在自旋相互作用模型的选取上也更具灵活性[125]. 除此之外, 量子机器学习不仅可以和经典机器学习一样接收经典信息并进行处理, 还可以直接处理量子系统与量子过程产生的量子信息[113].
其二则是将量子态的制备、演化与测量过程与经典的优化算法相结合, 利用经典计算机调节并优化量子计算过程中的相应参数. 其中具有代表性的算法有量子近似优化算法(quantum approximate optimization algorithm, QAOA)与变分量子本征求解(variational quantum eigensolver, VQE)算法. 量子近似优化算法, 最初由Farhi与Goldstone[127]在2014年提出, 主要被用于解决一些NP-hard的组合优化问题. 一般地, 量子计算机的演化过程可以用

Peruzzo等[135]在2014年提出的变分量子本征求解算法, 则是为了解决量子化学领域的相关问题. 变分量子本征求解算法借助变分原理, 通过预先拟设(ansatz)来选择量子初态与量子线路, 并在量子演化后利用哈密顿量平均(Hamiltonian averaging)的手段估计能量期望值, 最终利用经典的非线性优化过程优化参数直至寻找到符合要求的近似解[136]. 尽管理论上传统求解特征值的量子相位估计算法有着很好的性能, 但它对于量子系统的相干性有着很高的要求. 相对地, 变分量子本征求解算法对于相干性的要求大大降低[135]. 目前, 在不同的量子计算硬件上, 变分量子本征求解算法可以很好地求解





2
3.4.机器学习在量子控制中的应用
经典最优控制理论通常需要对物理系统建立一个数学模型, 其基本目的是控制系统来根据参考轨迹运动或者根据目标函数优化系统的动力学[142]. 但如果这个数学模型过于复杂以至于无法解析得到参考路径之时, 那么机器学习就是一个可供选择的方式[143,144]. 与经典控制类似的量子控制在量子计算与量子信息的应用中起到至关重要的作用, 其核心是控制量子动力学过程向既定的方向(比如特殊的量子态)去演化, 简单来说就是对量子系统的控制[27].对于传统的贝叶斯优化, 需要知道系统动力学的知识[145]. 而在机器学习方法下, 可以将量子系统视为一个黑箱—此时量子控制的策略会根据系统结果的输出, 来近似知道对应的动力学过程[146,147]. 人们可以利用机器学习在量子计算及量子测量中进行量子调控[148–153], 实现在高维量子多体系统中的非凸优化[154,42], 以及利用神经网络对控制脉冲进行设计[155]等.
近些年, 强化学习在量子系统优化控制中的应用也备受关注. 如在量子线路模型中, 通过在强化学习的环境中加入不同的控制误差来训练优化智能体以实现普适的量子控制[43]. 另外, 强化学习在实现高保真度目标态的快速制备[45,156,157]、量子线路优化[158]、控制非平衡量子热力学过程[159]以及在量子开放系统中进行最优化控制并与传统优化方法进行对比[160–162], 结合强化学习与量子绝热捷径技术实现对单个量子比特进行更快更鲁棒地控制[163,164]等领域得到广泛应用.
机器学习(特别是强化学习)在有噪声的中等规模量子(NISQ)[73]控制中与传统量子优化方法, 如GRAPE[165]、CRAB[166]一并成为了新的一种量子最优化控制方法, 并且能够帮助人们对自旋玻璃物理以及对量子相变物理进行控制, 辅助建立更直观的物理图像[42,45,167].
必须要指出的是, 想要在复杂的量子多体系统中做到对整个能谱的全局认知本身就非常困难. 所以对于复杂量子多体体系, 很难解析地知道这些最小能隙的位置来局域地优化哈密顿量演化路径[170–172]. 而在经典及量子最优化控制部分的介绍中, 我们已经谈到可以尝试将复杂的物理系统看作黑箱, 利用机器学习来获取最优化的控制.
本节将具体介绍我们利用强化学习辅助设计绝热量子算法的一个工作[173]. 从前文的介绍中了解到绝热量子计算的表现与演化路径密切相关. 在接下来的内容中, 所说的绝热量子算法的设计就对应于绝热演化的路径设计. 我们在第2节中介绍了几个计算问题的哈密顿量编码方式. 而对于给定一个计算问题, 总有不同的问题实例. 如在Grover搜索问题中对不同的目标态的搜索以及在3-SAT问题中不同子句的选择, 这都会使不同问题实例具有不同的答案. 绝热算法设计或者说哈密顿量演化路径设计不能依赖于具体的某一个问题实例. 这也就有别于对具体目标量子态制备[45]以及实现快速的量子门操作[174,155,43], 如何学习并自动化设计绝热量子计算中哈密顿量演化路径以使得计算过程体现出量子优势就是一个量子算法设计问题[173,175,176]. 对此, 我们构造了自动化绝热量子算法设计框架, 如图1. 这一框架特别适合对那些很难被求解但容易被验证的问题进行绝热算法设计, 如Grover搜索问题、质因数分解问题、3-SAT问题等等. 在该框架中, 我们参数化哈密顿量演化路径为:
 图 1 强化学习辅助绝热量子算法设计的示意图[173]. 其中强化学习中的智能体(agent)根据绝热量子计算(AQC)输出的结果来获取奖励, 并根据深度神经网络近似表示的Q值表格来选择动作更新绝热量子算法
图 1 强化学习辅助绝热量子算法设计的示意图[173]. 其中强化学习中的智能体(agent)根据绝热量子计算(AQC)输出的结果来获取奖励, 并根据深度神经网络近似表示的Q值表格来选择动作更新绝热量子算法Figure1. Schematic diagram of the reinforcement learning approach for quantum adiabatic algorithm design[173]. The learning agent collects the reward according to the result obtained from adiabatic quantum computing (AQC) and produces an action to update the quantum adiabatic algorithm based on its Q table represented by a deep neural network.


智能体中深度神经网络近似地表示Q值表格, 并用其来估计当前状态下选择不同动作的未来累积奖励. 在例如围棋游戏中, 智能体的动作是离散的. 而这里通过类似模拟退火的方式连续化了强化学习智能体的动作, 实现了自动化设计具有量子加速的绝热量子Grover搜索算法. 其中固定系统总的演化时间T与系统规模n的关系为

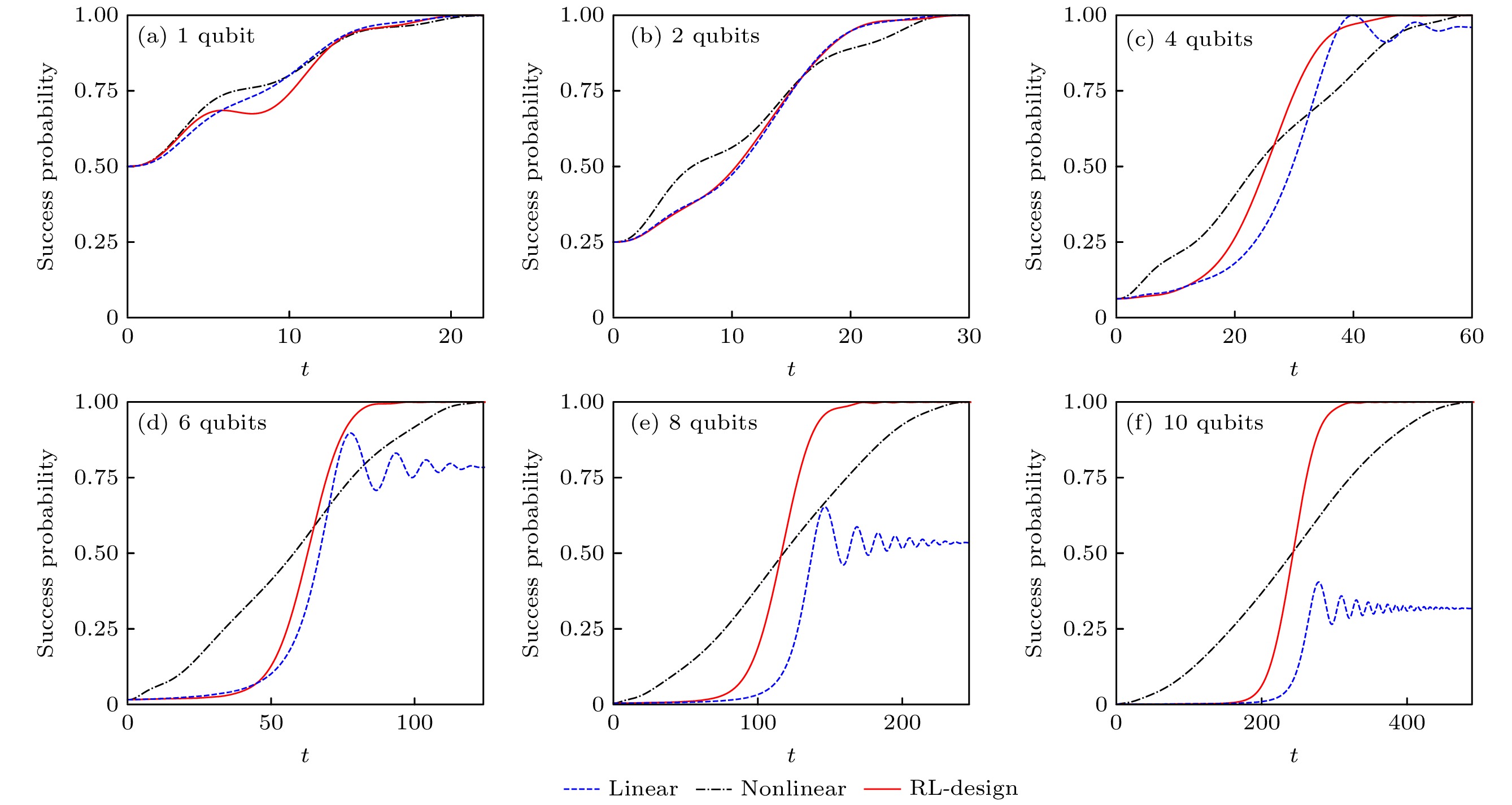 图 2 强化学习辅助设计的绝热量子算法在Grover搜索问题上的表现[173]. 其中成功概率(success probability)是演化终态与目标态交叠的平方, 总的演化时间T与系统规模n的关系为
图 2 强化学习辅助设计的绝热量子算法在Grover搜索问题上的表现[173]. 其中成功概率(success probability)是演化终态与目标态交叠的平方, 总的演化时间T与系统规模n的关系为
Figure2. Performance of reinforcement learning designed quantum adiabatic algorithm in success probability for Grover search problem[173]. The success probability is obtained by taking the square of wave-function overlap of the final evolved quantum state with the target state. The total adiabatic evolution time is chosen as

我们测试了强化学习在量子比特数量拓展过程中的表现, 如图3. 其中线性演化路径的结果非保真度(infidelity)增长得很快, 说明其计算表现能力不佳(前文中提到其被证明没有量子加速). 我们测试了将在10 qubits系统强化学习得到的路径直接用到11—16 qubits上, 发现虽然保真度会有下降但这也会比直接用线性路径更好. 而如果将在i qubits系统中强化学习得到的路径用到


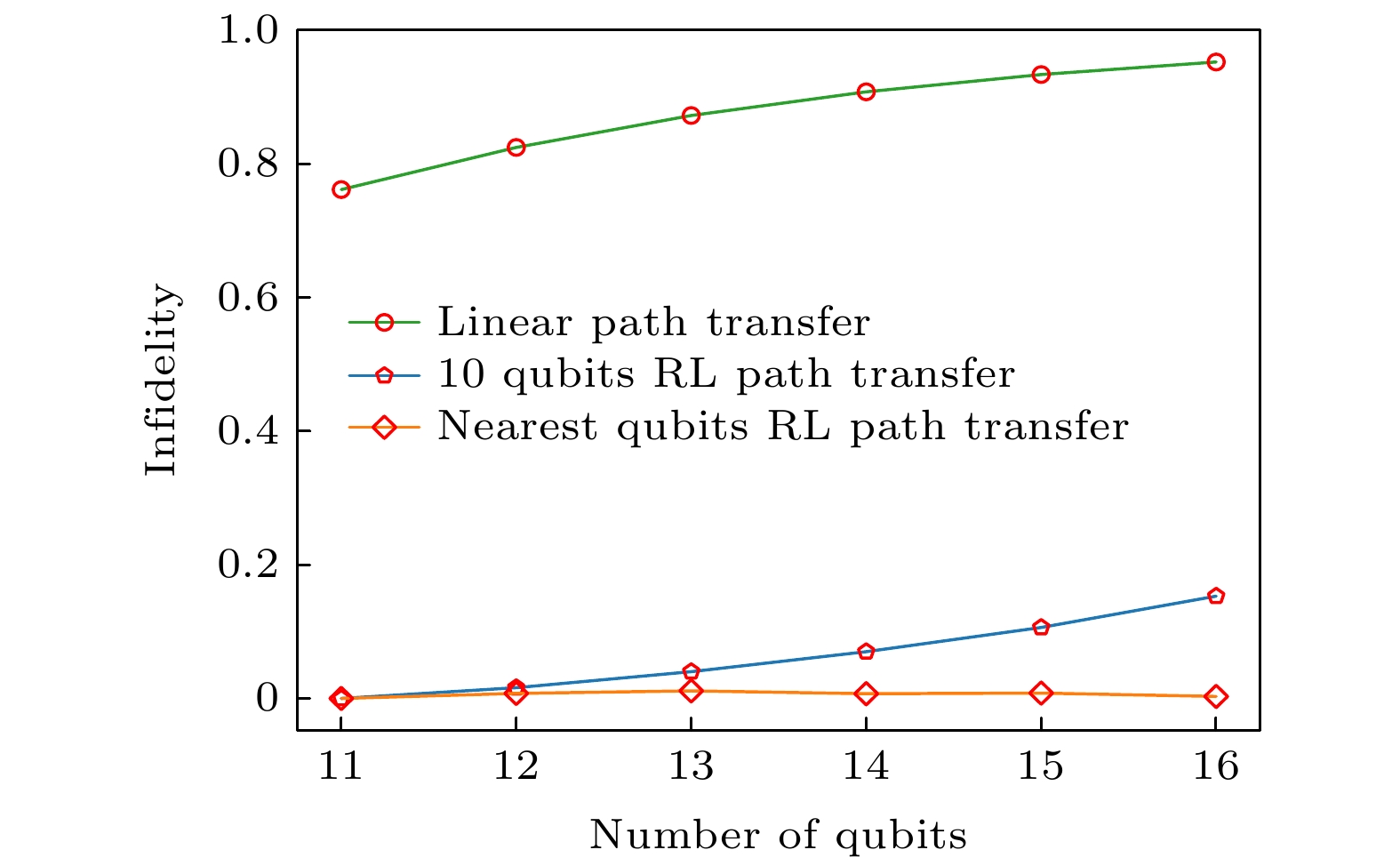 图 3 强化学习在Grover搜索问题的绝热量子算法设计中的拓展性[173]. 其中绿线是线性路径的表现, 蓝线是将10 qubits系统中强化学习学到的路径推广到更大系统, 橘线是将在n qubits系统强化学习获得的路径推广到
图 3 强化学习在Grover搜索问题的绝热量子算法设计中的拓展性[173]. 其中绿线是线性路径的表现, 蓝线是将10 qubits系统中强化学习学到的路径推广到更大系统, 橘线是将在n qubits系统强化学习获得的路径推广到
Figure3. Transferability of reinforcement learning based quantum adiabatic algorithm design for Grover search problem[173]. The green line denotes the infidelity of linear path. The blue line denotes the infidelity of the path obtained by training the 10 qubits system. The orange line denotes the performance of applying the path learned from the n qubits system to the

在对3-SAT这个NP-complete问题研究中, 我们对10 qubits系统且仅对包含3个子句的问题进行强化学习来获得绝热量子算法. 将这样设计得到的算法直接推广到其他不同子句数量的问题上, 其表现能力与一般的线性演化路径相比具有明显的提升. 这样获得的绝热算法具备一定的可迁移性[173].
在这个工作中[173], 我们利用强化学习优化设计了参数

