摘要: 经典计算机的运算能力依赖于芯片单位面积上晶体管的数量, 其发展符合摩尔定律. 未来随着晶体管的间距接近工艺制造的物理极限, 经典计算机的运算能力将面临发展瓶颈. 另一方面, 机器学习的发展对计算机的运算能力的需求却快速增长, 计算机的运算能力和需求之间的矛盾日益突出. 量子计算作为一种新的计算模式, 比起经典计算, 在一些特定算法上有着指数加速的能力, 有望给机器学习提供足够的计算能力. 用量子计算来处理机器学习任务时, 首要的一个基本问题就是如何将经典数据有效地在量子体系中表示出来. 这个问题称为态制备问题. 本文回顾态制备的相关工作, 介绍目前提出的多种态制备方案, 描述这些方案的实现过程, 总结并分析了这些方案的复杂度. 最后对态制备这个方向的研究工作做了一些展望.
关键词: 态制备 /
量子机器学习 /
编码 English Abstract Quantum state preparation and its prospects in quantum machine learning Zhao Jian 1 ,Chen Zhao-Yun 1 ,Zhuang Xi-Ning 1,3 ,Xue Cheng 1 ,Wu Yu-Chun 1,2 ,Guo Guo-Ping 1,2,3 1.CAS Key Laboratory of Quantum Information, University of Science and Technology of China, Hefei 230026, China Fund Project: Project supported by the National Key Research and Development Program of China (Grant No. 2016YFA0301700), the National Natural Science Foundation of China (Grant No. 11625419), the Anhui Initiative in Quantum Information Technologies, China (Grant No. AHY080000), and the Strategic Priority Research Program of the Chinese Academy of Sciences (Grant No. XDB24030600)Received Date: 21 May 2021Available Online: 12 July 2021Published Online: 20 July 2021Abstract: The development of traditional classic computers relies on the transistor structure of microchips, which develops in accordance with Moore's Law. In the future, as the distance between transistors approaches to the physical limit of manufacturing process, the development of computation capability of classical computers will encounter a bottleneck. On the other hand, with the development of machine learning, the demand for computation capability of computer is growing rapidly, and the contradiction between computation capability and demand for computers is becoming increasingly prominent. As a new computing model, quantum computing is significantly faster than classical computing for some specific problems, so, sufficient computation capability for machine learning is expected. When using quantum computing to deal with machine learning tasks, the first basic problem is how to represent the classical data effectively in the quantum system. This problem is called the state preparation problem. In this paper, the relevant researches of state preparation are reviewed, various state preparation schemes proposed at present are introduced, the processes of realizing these schemes are described, and the complexities of these schemes are summarized and analyzed. Finally, some prospects of the research work in the direction of state preparation are also presented.Keywords: state preparation /quantum machine learning /encoding 全文HTML --> --> --> 1.引 言 机器学习是一门人工智能领域的科学, 其通过计算机学习训练已知的数据, 并利用训练好的数据模式预测未知数据的信息. 随着计算机性能的不断增强, 机器学习对数据的处理能力也不断提升, 被广泛应用到各个领域[1 ] . 这包括图像识别[2 ,3 ] 、人脸识别[4 -6 ] 等分类问题, 也包括最优决策问题, 如Alpha Go[7 ] , Alpha Zero[8 ] 的围棋对弈等. 经典数据有许多处理和训练方式, 如神经网络、聚类等方法. 为了准确提取未知数据的特征, 训练方式的选择需要参考相应的数据类型. 当处理大规模的数据时, 为了获取数据特征, 往往采取深度学习的学习方式, 如包含数十亿权重的神经网络[9 ] , 这充分展示了深度学习在处理大数据时的效果.[10 ] . 量子机器学习包括用经典机器学习的方法处理量子物理中的问题和用量子计算的方式解决经典机器学习的问题. 前者需要将量子物理中的量子态转换为经典数据, 再用经典机器学习的方法来提取数据信息, 如构造经典神经网络训练这些经典数据后, 得到某些量子态的特征. 后者在处理经典数据时, 某些步骤中的计算过程可以通过量子态的酉变换来辅助实现, 这其中不可避免地需要将经典数据对应成量子态.[11 ,12 ] . 态制备的种类有很多, 大部分是将经典数据转换为了量子态, 也存在一些将经典数据映射到哈密顿量的方式. 态制备种类的选择直接影响了执行机器学习算法的选择, 这意味着不同的态制备方法决定了提取经典数据信息的差异, 影响了后续在量子系统里的操作, 影响整个机器学习算法的计算复杂度. 同时, 态制备作为量子机器学习的其中一部分, 其制备精度和成功率会影响整个机器学习算法的有效性.[13 ] . 基于解线性方程组的量子算法, 有量子主成分分析算法[14 ] , 可用于聚类和特征识别; 也有支持向量机算法[15 ] , 用于对大规模的数据分类问题. 这类量子算法的共同点都是为了解决实际的经典问题, 需要以经典数据为输入和输出. 这可以分为三个步骤: 首先运用态制备将经典数据转为量子态, 再用量子计算机对量子态进行酉变换, 最后多次地量子测量概率性得到一个经典结果. 整个算法的复杂度受各个步骤的影响, 本文仅列出不同态制备方式的复杂度. 如果考虑量子算法的复杂度, 可通过量子线路的语言, 对所需的基本量子操作, 即基本量子门计数得到所有门的个数. 类比于经典算法的分类方式, 量子算法分为不含黑箱(oracle)的显式算法和含黑箱的算法. 前者的复杂度指的是所有基本量子门个数, 后者往往勿略黑箱的执行时间而考虑黑箱的执行次数, 称为质询复杂度. 一般地, 若数据规模是$ \mathcal O(N) $ 的, 量子基本门的时间层数是$\mathcal O({\rm{Poly}}(\log N))$ 的, 称量子算法的执行时间是有效的. 在每个时间层, 允许多个量子比特同时执行一次量子基本门. 同样的数据规模, 若用到的量子比特是$\mathcal O({\rm{Poly}}(\log N))$ 的, 称量子算法的比特数是有效的. 量子基本门的个数受量子比特数和时间层数的影响, 在一个时间层至多有量子比特数的量子门同时执行, 故显式算法的复杂度上界为量子基本门的时间层数与比特数的乘积.[12 ] . 基底编码用于处理二值数据向量, 将数据编码到量子态的基底上; 振幅编码是最为常见的态制备方式, 将数据编码到量子态的振幅上, 数据向量可以是连续变量, 数据特征信息体现到量子态的振幅大小; 量子抽样编码可以看成前两种编码的结合, 是对在整个计算基基底的经典概率分布进行振幅编码, 对于某个给定的经典概率分布, 量子抽样编码退化为了振幅编码. 上述由经典数据编码到量子态的过程, 在量子系统中也可以视为从初态到目标量子态的一种酉变换. 广义上讲, 可以称从经典数据到酉变换的过程为编码, 如由经典数据决定量子系统演化哈密顿量的方式也可以看成一种编码, 这种编码称为哈密顿量编码.[16 ] 的工作谈起, 其将满足条件可积的一种数据分布制备成了量子态, 制备过程依赖于经典函数的有效计算, 且没有给出量子线路语言, 编码的有效性需进一步探讨. Kaye等[17 ] 以类似的方式得到了任意量子态的制备, 给出了可称之为含黑箱的量子线路. Soklakov和Schack[11 ] 于2005年用其他形式的黑箱给出了在一定限制条件下的有效的概率性算法. 振幅编码中不得不提到量子随机存取存储器(quantum random access memory, QRAM)的方法, 这是一种从已知量子态出发, 由经典数据直接得到新的量子态的过程.符号说明 文中希尔伯特空间用$ \mathcal H $ 表示, 任意的单位化向量$|\psi\rangle \! \in\! \mathcal H$ 表示量子态, 其中$|0\rangle \!=\! (1,0)^{\rm{T}}$ , $|1\rangle = (0, 1)^{\rm{T}}$ . 泡利算符用${{\sigma}}_x, {{\sigma}}_y$ 和${{\sigma}}_z$ 表示, ${\sigma}_x = \begin{bmatrix} 0 & 1\\ 1 & 0\end{bmatrix}$ , ${\sigma}_y = \begin{bmatrix} 0 & -{\rm i}\\ {\rm i} & 0\end{bmatrix}$ , ${\sigma}_z = \begin{bmatrix} 1 & 0\\ 0 & -1\end{bmatrix}$ . 在Bloch 球上, 单比特的绕A 轴旋转门 $R_A(\theta) = $ ${\rm{ e}}^{-{\rm i}\theta \sigma_A/2} = \cos{(\theta/2)}I-{\rm i}\sin{(\theta/2)}\sigma_A$ , 其中$A = x, $ $ y, z$ .2.编码方式 这里给出态制备的问题模型. 对给定的经典数据, 不妨假定数据集$ \mathcal D\subset\mathcal R^n $ 是有限集, $ |D| = l $ , 每个数据$x = (x_1, \cdots, x_n)\in\mathcal D$ , 用一个单射f 将D 的所有子集构成的集合, 记为$ 2^{\mathcal D} $ , 映射到某个希尔伯特空间$ \mathcal H^m $ , 使得对$ \mathcal D'\subset\mathcal D $ , $ f(\mathcal D')\in\mathcal H^m $ . 称f 为态制备, 其中$ \mathcal H^m $ 中的元素都视为单位向量, 对应量子态. 例如, $\mathcal D = \{x_1 = (1, 0),\; x_2 = (0, 1)\}$ , 可以找到一种态制备的映射, 使得$ f(\{x_1\}) = |10\rangle $ , $ f(\{x_2\}) = |01\rangle $ , $ f(\mathcal D) = 1/\sqrt 2(|10\rangle+|01\rangle) $ .2.1.基底编码 2.1.基底编码 这类编码中, 限定所有数据是二元向量, 或二值化处理后的经典数据是二元向量, 即$ \mathcal D\subset\{0, 1\}^n $ . 对任意数据集的子集$ \mathcal D'\subset \mathcal D $ , $ \mathcal D' = \{x^j\}_{j = 1}^{l'} $ , $x^j = $ $ (x_1^j, \cdots, x_n^j)$ ,$ \mathcal O(n) $ . 制备的思路是运用迭代法.$|\psi_1\rangle = \dfrac{1}{\sqrt{l'}}|x^1\rangle|0\rangle^{\otimes n}_1 |0\rangle_2\!+\!\sqrt{\dfrac{l'-1}{l'}}|0\rangle^{\otimes n} $ $ |0\rangle^{\otimes n}_1 |1\rangle_2$ . 注意到这里增加了两个寄存器, 其中第一个寄存器为了存放$ |x^2\rangle $ , 第二个寄存器放置辅助比特标记位置.$|\psi_1'\rangle \!=\! \dfrac{1}{\sqrt{l'}}|x^1\rangle|0\rangle^{\otimes n}_1 |0\rangle_2 \!+\! \sqrt{\dfrac{l'\!-\! 1}{l'}} |x^2\rangle^{\otimes n} $ $ |x^2\rangle^{\otimes n}_1 |1\rangle_2$ . 这里的操作是一系列并行的X 门和单比特受控门.$|\psi_{12}\rangle = \dfrac{1}{\sqrt{l'}}(|x^1\rangle+|x^2\rangle)|0\rangle^{\otimes n}_1 |0\rangle_2+ $ $ \sqrt{\dfrac{l'-2}{l'}}|0\rangle^{\otimes n}|0\rangle^{\otimes n}_1 |1\rangle_2$ . 这里的操作涉及对上一步含$ |x^2\rangle $ 的态进行受控Y 操作, 含$ |x^2\rangle $ 态的振幅也成为$ 1/\sqrt{l'} $ , 再进行退计算的操作还原即可得到.$ |\psi_{1\dots l'}\rangle $ , 即得到$ f(D') $ .2.2.振幅编码 -->2.2.振幅编码 这类编码要求的数据不再是二元向量, 可以是任意实数. 对于任何$ D' = \{x^j\}_{j = 1}^{l'} $ , $x^j = (x_1^j, \cdots, x_n^j)$ ,C 为归一化常数, $C = \sqrt{\displaystyle\sum\nolimits_{j = 1}^{l'}\displaystyle\sum\nolimits_{i = 1}^n (x_i^j)^2}$ . 可以看出, 如果对数据集中所有数据振幅编码, 当$ ln $ 是$ 2 $ 的幂次时, 只需要$ \log(ln) $ 个量子比特便可以编码$ ln $ 个振幅. 例如, $ ln = 4 $ 时, 只需制备一个2 bit的量子态, 使得在四个计算基$ |00\rangle, |01\rangle, |10\rangle $ 和$ |11\rangle $ 上的振幅为数据大小即可. 振幅编码问题可以简化为, 给定一个单点集合$X = \{x = (x_0, \cdots, $ $ x_{N-1})\}\subset\mathcal R^N$ , N 为$ 2 $ 的幂次, 使得在忽略归一化常数的条件下2.2.1.显式的编码 -->2.2.1.显式的编码 1)用$ \log N $ 个量子比特编码.$ \mathcal O(N) $ . 假定制备出的量子态的每个振幅的大小已知, 即每个计算基上测量得到相应的结果的概率$ p^{\log N}_i = x_i^2/\|x\|^2 $ 已知, 并且我们定义边际概率$p^{k}_i = \displaystyle\sum\limits_{i' = 2 i, 2 i+1} p^{k+1}_{i'}$ , $k = 1, \cdots, $ $ \log N- 1$ , 如图1 所示.图 1 当$ N = 8 $ 时所有的边际概率Figure1. The marginal probabilities for $ N = 8 $ .$ \theta^k_i = 2\arccos \sqrt{p^{k+1}_{i/2}/p^k_i} $ ($k = 0, \cdots, n- 1$ ; $ i = 0, \cdots, 2^k-1 $ ), 则态制备的整个迭代流程图可以参看图2 .图 2 $ N = 8 $ 时用$ \mathcal O(N) $ 的时间制备$ f(X) $ Figure2. Preparation for $ f(X) $ in $ \mathcal O(N) $ time for $ N = 8 $ .$ \log N $ 个量子比特编码时, 每个基底前的振幅都不能并行运算, 导致了这个方法的运行时间为$ \mathcal O(N) $ . 如果这些多重受控操作可以并行操作, 运行时间将大大降低.N 个量子比特编码. 基于减少运行时间的考量, 可以增加量子比特, 使得编码振幅的基底选择性更多, 从而增加并行运算的可行性. 这里选取W 态的基底, 得到态制备的映射为$ Y(\theta)|01\rangle = \cos(\theta/2)|01\rangle+\sin(\theta/2)|10\rangle $ , $ Y(\theta)|10\rangle = -\sin(\theta/2)|01\rangle+\cos(\theta/2)|10\rangle $ , 这类似于对单比特量子门$ R_Y(\theta) $ 在$ |0\rangle $ 和$ |1\rangle $ 上的操作, 故将$ Y(\theta) $ 定义为由符号“$ \times $ ” 控制的$ R_Y(\theta) $ 量子门. 这里直接给出$ N = 8 $ 时的整个迭代过程, 详见图3 .图 3 $ N = 8 $ 时用$ \mathcal O(\log N) $ 的时间获取振幅Figure3. Acquiring the amplitudes in $ \mathcal O(\log N) $ time for $ N = 8 $ .2.2.2.含黑箱的编码 -->2.2.2.含黑箱的编码 这类编码不考虑黑箱构造的问题, 有两大类制备方案.[16 ] 和Kaye等[17 ] 的工作$ \{p_i\}_{i = 0}^{N-1} $ , 目标制备$ |\psi\rangle = \sqrt{p_i}|i\rangle $ . 等价于给定单点集$\{x = (x_0, \cdots, x_{N-1}), x_i \geqslant 0\}$ , 满足归一化条件$\displaystyle \sum\nolimits_i x_i^2 = 1$ . 制备的思路与显式编码相同, 都是运用迭代法, 为了描述方便, 仍然采用边际概率的记号$p^{k}_i = \displaystyle\sum\nolimits_{i' = 2 i, 2 i+1} p^{k+1}_{i'}$ , $k = 1, \cdots, \log N-1$ .$ |\psi_1\rangle = \sqrt{p_0^1}|0\rangle+\sqrt{p_1^1}|1\rangle $ . 这一步操作只需要一个单比特门即可.$|\psi_2\rangle = \sqrt{p_0^2}|00\rangle+\sqrt{p_1^2}|01\rangle+\sqrt{p_2^2}|10\rangle+ $ $ \sqrt{p_3^2}|11\rangle$ . 该步骤的思路是运用迭代法, 具体来讲, 首先, 令$f(0) = \dfrac{p_0^2}{p_0^2+p_1^2}$ , $f(1) = \dfrac{p_2^2}{p_2^2+p_3^2}$ 表示条件概率, 在1)的基础上加上一个寄存器, 用来存储条件概率, 即$ \theta_i = \arccos \sqrt{f(i)} $ . 这一步操作并未指明寄存器量子比特的数量与执行时间. 可以视为以f 为黑箱的一步操作. 原文中该步骤的有效实现需要f 为条件可积函数, 并要求在经典计算中对f 这步黑箱操作是有效计算的. 那么从经典计算机到量子计算机, 通过辅助量子比特将经典计算转变为可逆计算并退计算等一系列操作, 一定存在时间复杂度与经典运算的时间复杂度相同的量子线路, 使得该步骤可以有效实现[18 ] . 接着, 再增加一个寄存器, 受控于$ \theta_i $ 的操作, 得到$ |\psi_2\rangle $ 的振幅信息, 即$ \theta_i $ 擦除, 这步操作的量子比特数量与执行时间及存储$ \theta_i $ 相同, 同样是含f 的黑箱操作, 得到$ |\psi_2\rangle $ .$ |\psi_k\rangle $ 得到$ |\psi_{k+1}\rangle $ , 最终得到$ |\psi_{\log_2 N}\rangle $ , 即目标量子态$ |\psi\rangle $ .[17 ] 的态制备方法与Grover类似, 给出了量子线路的语言. 其中对存储$ \theta_i $ 的步骤进行细化, 在已知$ |\psi\rangle $ 的前提下, 将(1 )式改写为$ \theta_i $ 的获得需要整个态$ |\psi\rangle $ 的各个分量的值, 并未给出黑箱操作的具体构造, 在这一点上与Grover的算法没有本质区别.N 规模的量子态, 是不可能用$ \mathcal O(n) $ 的量子比特在有效时间完成的. 因此, 我们往往考虑黑箱的执行次数, 称为质询复杂度, 以此来衡量含黑箱算法的计算复杂度. Kaye 的算法对于任意的量子态都可以制备, 并且从含黑箱的角度看出是以(2 )式为黑箱的振幅编码, 该编码方式具有有效的质询复杂度. 不过, 值得说明的是Grover和 Kaye的算法原文中并没有指明是含黑箱的算法. 给定数据集X , 制备过程可以视为含黑箱的量子算法. 若是未指明某个数据集上的经典数据, 对数据集中的元素随机化处理, 如数据集中的元素满足某种概率分布函数g , 对这种分布的态制备问题可能是有效的, 因为g 的参数可能不依赖于n . 这种含黑箱的编码比较广泛, 将在2.3 节的量子抽样编码中再次提及.[11 ] 的工作$X = \{x = (x_0, \cdots, $ $ x_{N-1})\}\subset\mathcal C^N$ , N 为$ 2 $ 的幂次, 这里$x_i = |x_i|{\rm{e}}^{{\rm i}\alpha_i}$ , $\alpha_i\in $ $ [0, 2\pi)$ , 但$ |x_i| $ 不可以全相等. 理想的量子态为x 各个分量实部的差异, 如果各个分量$ |x_i| $ 大小都比较接近, 那么编码执行时间会很快. 另一方面是对制备量子态结果保真度和成功率的要求, 如果对态制备的结果要求严苛, 会导致执行时间变慢. 令$ \gamma, \lambda, \eta\in(0, 1) $ , 如果对任意的数据分量$x_i^2 < {1}/{\eta N}$ , 以不小于$ 1-\gamma $ 的成功率制备的近似态为$ |\tilde\psi\rangle $ , 满足$ |\langle\tilde\psi|\psi\rangle| = 1-\lambda $ , 所需要的计算复杂度为$ \mathcal O(P(\log_2 N\cdot\gamma^{-1}\lambda^{-1}\eta^{-1})) $ .2.2.3.QRAM -->2.2.3.QRAM 量子随机存取存储器(QRAM)是类比于经典内存存取数据的一种装置, 可以将经典数据存储到相干的量子态各个分量地址中. 在读取量子态的任意一个分量时, 每个分量地址上都需要附带经典数据的信息:$\displaystyle \sum\nolimits_i\psi_i|i\rangle $ , 分量都需要存储经典数据地址信息. 第二个寄存器是数据寄存器, 用于存储经典数据X . 这种装置类似于(1 )式, (2 )式的操作方式, 故一定程度上, QRAM的模型包含了Grover和Kaye等的态制备工作. 例如在量子推荐系统算法中[19 ] , 概率分布被提前储存到QRAM中, Grover的算法也可以实现. 理论上, QRAM的模型可以通过增加大量的比特数来减小执行时间. QRAM通过二分的树状图和桶队结构(bucket-brigade)来实现, 这种实现方式可以做到$ \mathcal O(n) $ 的时间复杂度, 但量子比特数是$ \mathcal O(N) $ 的. QRAM的量子线路语言实现方式种类较多[20 ,21 ] . 人们在后续的工作中更关心哪一种QRAM的实现方式更具有噪声的抗性和可拓展性, Hann[22 ] 给出了一种关于噪声抗性的论证.1 )式, (2 )式以及QRAM的直接形式(4 )式都是将经典数据存储到辅助比特上, 每个分量对应的辅助比特上都有经典数据的信息. 特别地, 如果辅助比特可以写成二进制数, 这种变换称为数字编码. 与之对应的, Mitarai称振幅编码为模拟编码[23 ] , 并介绍了数字编码和模拟编码的转换关系. 利用这种数模转换的关系, 可以得到振幅编码的具体形式.X , QRAM可以将$x = (x_0, \cdots, x_{N-1})$ 存储到等权叠加的量子态上, 忽略归一化, 得到6 )式中的受控旋转操作可以将$ x_i $ 表示为t 比特的二进制数, 分别对辅助比特做控制$ R_Y(\pi/2^t) $ 类似的操作来实现. 最后一步进行后选择的操作, 对辅助比特进行测量, 当测量到$ |1\rangle $ 态时, 制备失败. 需要重复这个算法的流程, 直到测量值$ |0\rangle $ . 当测量值为$ |0\rangle $ 态时, 成功制备, 成功率可以计算, 得到7 )式得到的量子态与目标态还多了数据寄存器的数据, 需要擦除. 这步擦除数据是退计算的过程, 也是QRAM里(5 )式的逆操作, 即2.3.量子抽样编码 -->2.3.量子抽样编码 本节介绍基底编码和振幅编码的一种混合编码方式——量子抽样编码. 振幅编码的数据集X 是单点集, $X = \{x = (x_0, \cdots, x_{N-1})\}$ , 如果用$ \mathcal \log N $ 个量子比特, 时间复杂度为$ \mathcal O(N) $ . 在量子抽样编码中, 给定一种概率分布, 不妨假定为$g(x^\prime), \; x^\prime\in $ $ [0, N]$ , 表示量子态的在每个基底的概率为$p_i = $ $ \displaystyle\int_i^{i+1} g(x^\prime){\rm{d}}x^\prime$ , $p_i\geqslant0, \sum p_i = 1$ . 数据集仍为单点集$X = \{x = (x_0, \cdots, x_{N-1})\},\; x_i = \sqrt{p_i}$ . 目标量子态是X 对应的振幅编码$ g(x^\prime) $ 得到新的量子态, 与一般的振幅编码相比, 这类编码的$ g(x) $ 参数可能与N 无关. 可以通过对分布函数$ g(x^\prime) $ 做一些限制, 得到关于某些函数性质有关的态制备方法.[16 ] 的工作中, 作者进一步提出对于很大一类被称为“对数凸”的函数, 都可以通过这种编码方式进行制备, 这其中包括常见的正态分布和指数分布. 除了Grover的工作, Kitaev和Webb[24 ] 也分析了高斯分布的量子态制备. 文献[25 ]给出了一种基于矩阵积态(matrix product state)方法, 得到了当$ g(x^\prime) $ 为光滑可微且导函数有界时的编码方式. 该算法需要$ \mathcal O(n) $ 个量子比特, 执行时间为$ \mathcal O(n) $ . 实验方面Vazquez和Woerner[26 ] 给出了基于量子振幅放大算法简化态制备的方法, 并在IBM的物理比特上展示了实现了该算法.[27 ] , 给定经典数据的分布, 利用含参数的量子线路生成一种量子分布, 再由对抗识别器对量子分布采样, 反复调整, 直到识别不出经典数据分布与生成的分布, 训练完毕. 数值模拟过程中所需要的量子门数量控制在$ \mathcal O(P(n)) $ . 也有其他机器学习相关的工作, 如Arrazola等[28 ] 用含参线路在光量子计算机模拟器演示了许多量子态的生成, 如ON态和 GKP态. 值得一提的是, 此类统计分布的态制备问题, 在量子蒙特卡罗模拟算法中处于非常核心的地位[29 ] , 而后者已经被证明在很多金融和其他模拟问题中显示出量子优越性[30 -32 ] .2.4.哈密顿量编码 -->2.4.哈密顿量编码 经典数据转为量子态的另一种方案是将经典数据的信息编码到某个量子系统的哈密顿量中, 运用哈密顿模拟的方式代替将经典数据转为量子态的方法[33 ] . 记经典数据集为$X = \{x = (x_0, \cdots, $ $ x_{N-1})\}$ , 记对应的哈密顿量为$ H_x $ , 表明哈密顿量依赖于经典数据的选择. 则对于量子系统的初态$ |\psi\rangle $ , 演化时间为t , 得到演化后的量子态为[18 ] . 考虑一个n 量子比特的量子系统, 哈密顿量可以分解为一些哈密顿量的和, 即$H = \displaystyle\sum\nolimits_{i = 0}^{L-1}H_i$ , 其中$ H_i $ 为较易模拟的哈密顿量, $ L = \mathcal O(P(n)) $ . 由Trotter公式[33 ] ,n 充分大时, 可以用多次的演化${\rm{e}}^{-{\rm i} H_it/n}$ 来实现量子模拟. $ H_i $ 常见的选择是泡利算符.H 出发. 1) 由经典数据确定哈密顿量H , 如经典数据为动能、势能函数决定的参量; 2) 在某个量子系统中选定基底, 确定哈密顿量的矩阵元; 3) 哈密顿量模拟. 模拟过程包含哈密顿量的分解, 需要确定$ H_i $ . Matto等 [34 ] 用格雷码序的方式对经典数据进行哈密顿量编码, 是一种比特数有效的编码方案. 另一类是从分解后的哈密顿量$ H_i $ 出发. 1) 选定$ H_i $ , 由经典数据得到每个$ H_i $ 的系数; 2) 在某个量子系统中选定基底, 确定哈密顿量$ H_i $ 的矩阵元; 3) 得到总的哈密顿量, 即为经典数据的哈密顿量编码. 例如用第二类的方法, 假定经典数据$x = $ $ (x_0, \cdots, x_{4^n-1})$ , 我们将经典数据x 编码到n 粒子哈密顿量中, 以泡利算符和单位算符在计算基上的表示为基底, 基底个数为$ 4^n $ , 总的哈密顿量为3.复杂度 当数据规模为$ \mathcal O(N) $ 时, 基底编码的执行时间为$ \mathcal O(N) $ 次, 需要的量子比特数为$ \mathcal O(N) $ , 复杂度为$ \mathcal O(N^2) $ . 振幅编码适用范围广, 其中显式振幅编码的复杂度为$ \mathcal O(N)\log{N} $ , 对于含黑箱的振幅编码, 仅考虑质询复杂度, 可以做到有效制备, 即在一定条件下质询复杂度可以达到$ \mathcal O(\log(N)) $ , 但黑箱的执行时间在实际操作中需要考量. QRAM的编码方式从已知量子态获取经典数据得到新的量子态, 这个过程中需要$ \mathcal O(N) $ 个量子比特, 但执行时间可以做到$ \mathcal O(n) $ . 而量子抽样编码也是直接从量子态出发, 比较目标量子态与量子初态的差异得到新的量子态, 比特数和时间有效性都可以实现, 这是由于给出的分布函数可以不依赖于数据量规模. 在哈密顿量编码中, 哈密顿量的合理选择可使得编码方式中的比特数有效, 执行时间取决于哈密顿量的矩阵形式和哈密顿量模拟的精度. 进一步的, 考虑到量子比特数和时间执行次数的平衡和取舍, 噪声抗性等因素, 态制备问题应该被仔细斟酌. 以上的复杂度分析可参看表1 . 编码方式 数据类型 比特数 执行时间 基底编码 二值数据 $\mathcal O(N)$ $\mathcal O(N)$ 显式振幅编码 计算基$|i\rangle$上编码 连续变量 $\mathcal O(\log N)$ $\mathcal O(N)$ $|2^i\rangle$上编码 连续变量 $\mathcal O(N)$ $\mathcal O(\log N)$ 含黑箱振幅编码 Grover和Kaye 连续变量 $\mathcal O(\log N)$ — Soklakov和Schack 连续变量 $\mathcal O(\log N)$ $\mathcal O({\rm{Poly}}(\log N))^*$ QRAM 连续变量 $\mathcal O(N)$ $\mathcal O(\log N)$ 量子抽样编码 分布函数 $\mathcal O(\log N)$ $\mathcal O(\log N)$ 哈密顿量编码 连续变量 $\mathcal O(N)/\mathcal O(\log N)$ $\mathcal O({\rm{Poly}}(\log N))^*$ 注: *同时受保真度和成功率的影响.
表1 态制备的不同编码方式的复杂度分析Table1. Complexity analysis of kinds of encoding methods for state preparations.4.研究前景和展望 在未来, 经典计算机芯片的工艺制程接近摩尔定律极限, 经典计算机的算力发展达到瓶颈期. 而大数据的处理使得算力需求呈快速增长趋势. 这之间算力的供需矛盾关系使得人们迫切地寻找新的计算模式. 研究量子机器学习的出发点是解决这种矛盾关系. 具体来说是希望在处理某一类问题时, 量子机器学习的方法能够大大缩短传统经典机器学习需要的时间, 继而在更广泛的问题中表现出加速能力. 量子计算机的实用化受限于量子比特、量子门的质量和量子操作系统等诸多实验因素, 故量子机器学习的研究大多停留在数值模拟或是构建理论模型的阶段. 在这个大背景下, 人们不过多关注量子机器学习中的物理实现.[27 ] , 利用含参数的量子线路生成一种分布并由对抗识别器采样, 机器学习的方式训练参数, 直到对抗识别器识别不出目标分布与生成的分布; Arrazola等[28 ] 采用的是光量子计算机模拟器, 利用自动微分法优化得到目标量子态; 最近Zhou等[35 ] 提出了一种自动微分的量子含参线路, 可以优化得到任意的量子态. 
































































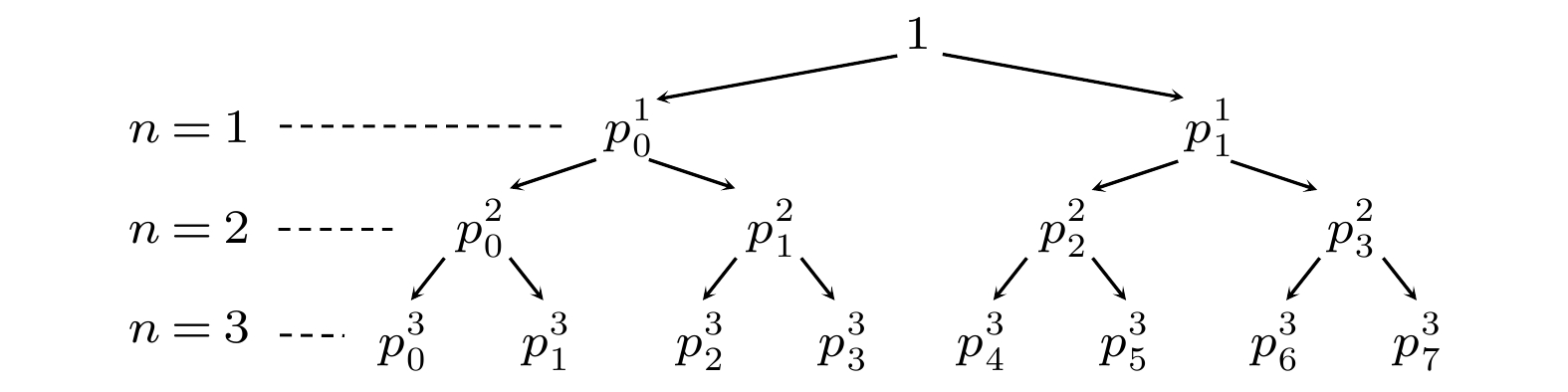 图 1 当
图 1 当




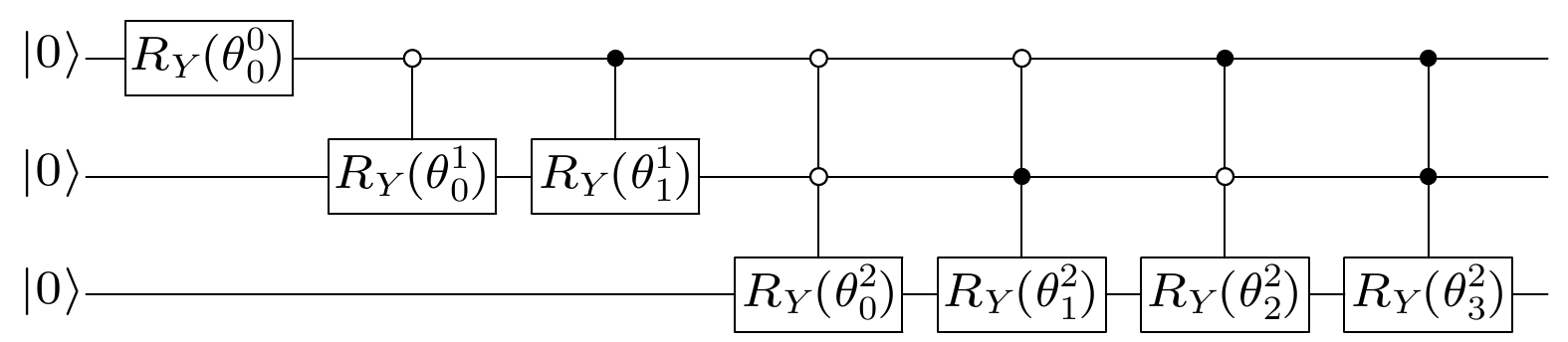 图 2
图 2 

















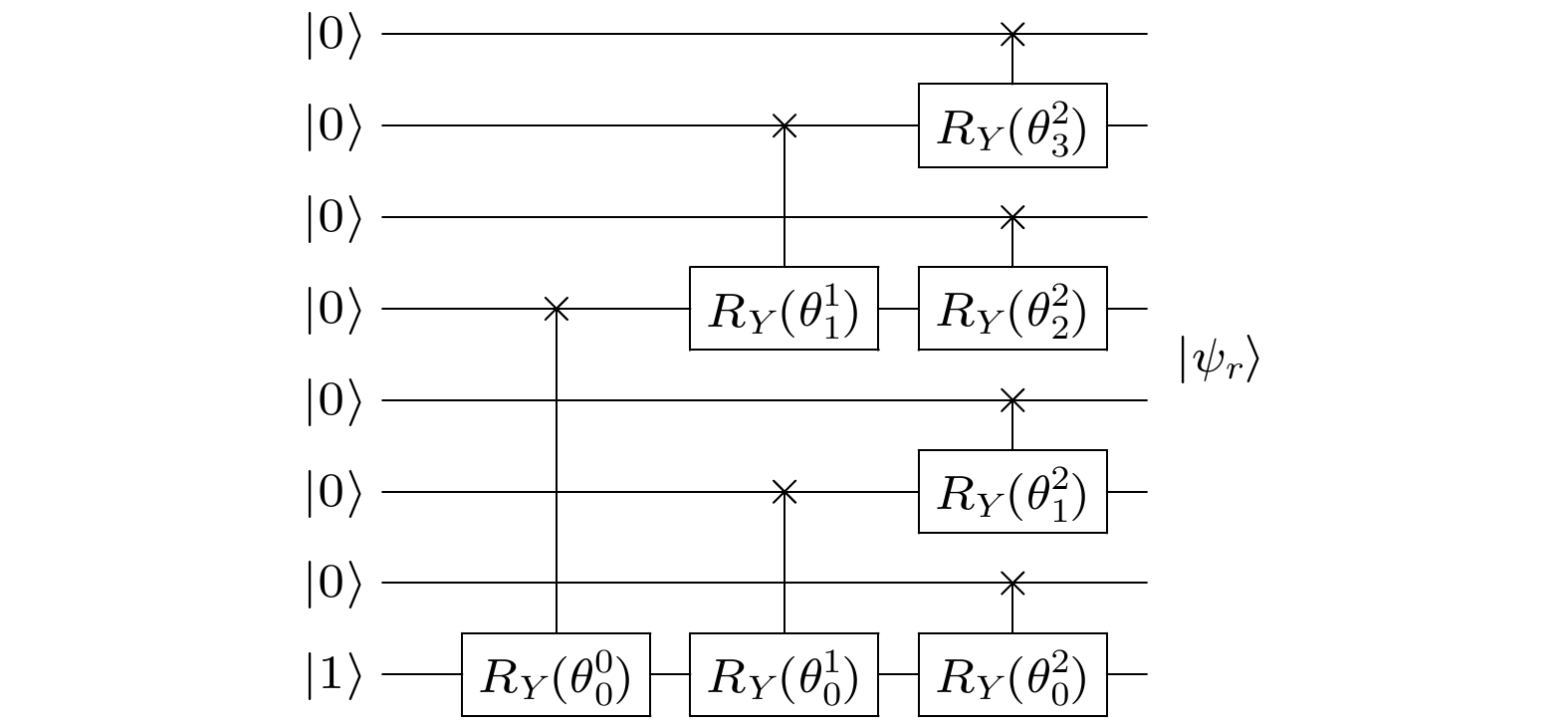 图 3
图 3 





























































































