Fund Project:Project supported by the National Natural Science Foundation of China (Grant Nos. 71571186, 61703416) and the Postgraduate Innovation Project of Hunan Province, China (Grant No. CX20190041)
Received Date:22 October 2020
Accepted Date:15 November 2020
Available Online:21 April 2021
Published Online:20 April 2021
Abstract:The structure and the function of network interact with each other. The function of network is often reflected as the dynamic process on the network. The dynamic process on the network is reflected by the behavior data in the network. Therefore, it is possible to reconstruct the network structure according to the observed data. This paper aims to solve the problem of how to restore the network topology according to the observable discrete data on the network. In this paper, an algorithm to infer the possibility of edge connection between nodes is proposed by using the similarity degree of each node corresponding to each discrete datum, and by reconstructing each local topology of the network through multiple discrete data, and by superposing the local topology obtained from multiple data, the global topology of the whole network is reconstructed finally. The data in the network are generated by SIR (Susceptible Infective Removed) model with infection probability of 0.2 and recovery probability of 1. Each time, a single node is selected as the infected node, and the final infection state of the network is counted as a network datum. In order to verify the feasibility and accuracy of the algorithm, the network reconfiguration experiments are carried out in small world, scale-free and random networks. Through the network reconstruction experiments in the networks of three different types and different scales, we can see that the performances of network reconstruction algorithm in different types of networks are different, and the average degree of network will affect the requirements for data of the network reconstruction algorithm. In order to verify the applicability of the algorithm, network reconstruction experiments are carried out on three practical networks. The results show that the algorithm can be applied to the reconstruction of large-scale networks. In order to show the accuracy of the algorithm more intuitively, we analyze the network reconstruction error after each network reconstruction experiment. The experiment shows that with the gradual increase of network data, the network reconstruction error gradually decreases and finally approaches to 0. In a nutshell, the algorithm we proposed in this work has good applicability and accuracy, and is suitable for different types of network topology reconstructions. Keywords:network reconstruction/ complex networks/ dynamics/ discrete data
如图6所示, 在不同节点规模的WS小世界网络重构实验过程中, 随着实验数据的增加, 网络重构实验的多边重构误差$ {e}_{\rm{FP}} $和少边重构误差$ {e}_{\rm{FN}} $逐渐减小, 最终趋近于0, 该实验误差分析进一步说明了本文算法的准确性. 图 6 不同规模的WS小世界网络重构误差分析 Figure6. Error analysis of WS small world network reconstruction with different scales.
为了研究网络平均度值对网络重构效果的影响, 对WS小世界网络, 分别对网络平均度值为4, 6和8(即$ \langle k\rangle $ = 4, $ \langle k\rangle $ = 6和$ \langle k\rangle $ = 8)的网络进行了网络重构实验, 实验结果如图7所示. 从图7可以看到, 随着网络平均度值的增加, 要达到相同的网络重构效果, 需要的网络数据量更多, 原因是网络的平均度值越大网络中各个节点的连边数量越多, 则网络整体的连边数量也随之增加, 所以需要更多的网络数据来重构网络. 从网络节点数量为200—600 (即WS200—WS600)的重构效果可以发现, 网络平均度值为$ \langle k\rangle $ = 6的重构效果在相同网络数据情况下的重构效果比网络平均度值为$ \langle k\rangle =4$ 的网络重构效果好, 原因可能是WS小世界网络具有较高的集聚性, 因此网络平均度值在一定范围内对网络数据的需求量较少, 即相同数量的网络数据能够很好地被节点及其邻居节点“利用”. 图 7 WS小世界网络不同平均度值对网络重构实验效果的影响 Figure7. Influence of different average degrees of WS small world network on network reconstruction experiment.
34.2.2.BA无标度网络实验 -->
4.2.2.BA无标度网络实验
从图8可以看出, 与WS小世界网络类似, 随着网络数据的增加网络重构效果也越来越好. 图9展示了实验误差曲线, 总体上来说网络重构误差随着实验数据的增加逐渐减小. 从图10可以看出, 在相同网络数据的情况下, 网络平均度值越大, 网络的重构效果越差, 且平均度值越大网络重构需要的数据越大. 图 8 不同规模的BA无标度网络重构实验效果 Figure8. Experimental results of BA scale-free network reconstruction with different scales.
图 9 不同规模的BA小世界网络重构误差分析 Figure9. Error analysis of BA scale-free network reconstruction with different scales.
图 10 BA无标度网络不同平均度值对网络重构实验效果的影响 Figure10. The influence of different average degree values of BA scale-free network on network reconstruction experiment.
34.2.3.ER随机网络实验 -->
4.2.3.ER随机网络实验
图11展示了不同规模的ER随机网络重构效果, 相比同等规模的WS小世界和BA无标度网络, ER随机网络需要更多的网络数据. 图12展示了两种重构误差的变化情况, 可以发现, 两种重构误差变化的趋势基本一致, 误差随实验数据的增加逐渐减小. 除此之外, 对具有不同平均度值的ER随机网络进行网络重构实验, 发现网络重构的效果与网络的平均度值基本没有关系, 从图13可以发现三条曲线基本重合. 图 11 不同规模的ER随机网络重构实验效果 Figure11. Experimental results of ER random network reconstruction with different scales.
图 12 不同规模的ER小世界网络重构误差分析 Figure12. Error analysis of ER random network reconstruction with different scales.
图 13 ER随机网络不同平均度值对网络重构实验效果的影响 Figure13. Influence of different average degree of ER random network on network reconstruction experiment.
34.2.4.三种网络对比实验 -->
4.2.4.三种网络对比实验
为了更直观地比较不同网络重构效果, 同时对WS, BA和ER网络进行网络重构实验, 实验结果见图14. 从图14可以看出, 在相同网络数据下可以发现WS和BA网络的重构效果类似, ER网络则需要更多的网络数据. 图 14 三种不同网络在相同数据下的重构效果对比 Figure14. Comparison of reconstruction effects of three different networks under the same data.




 图 1 网络初始二值数据矩阵
图 1 网络初始二值数据矩阵











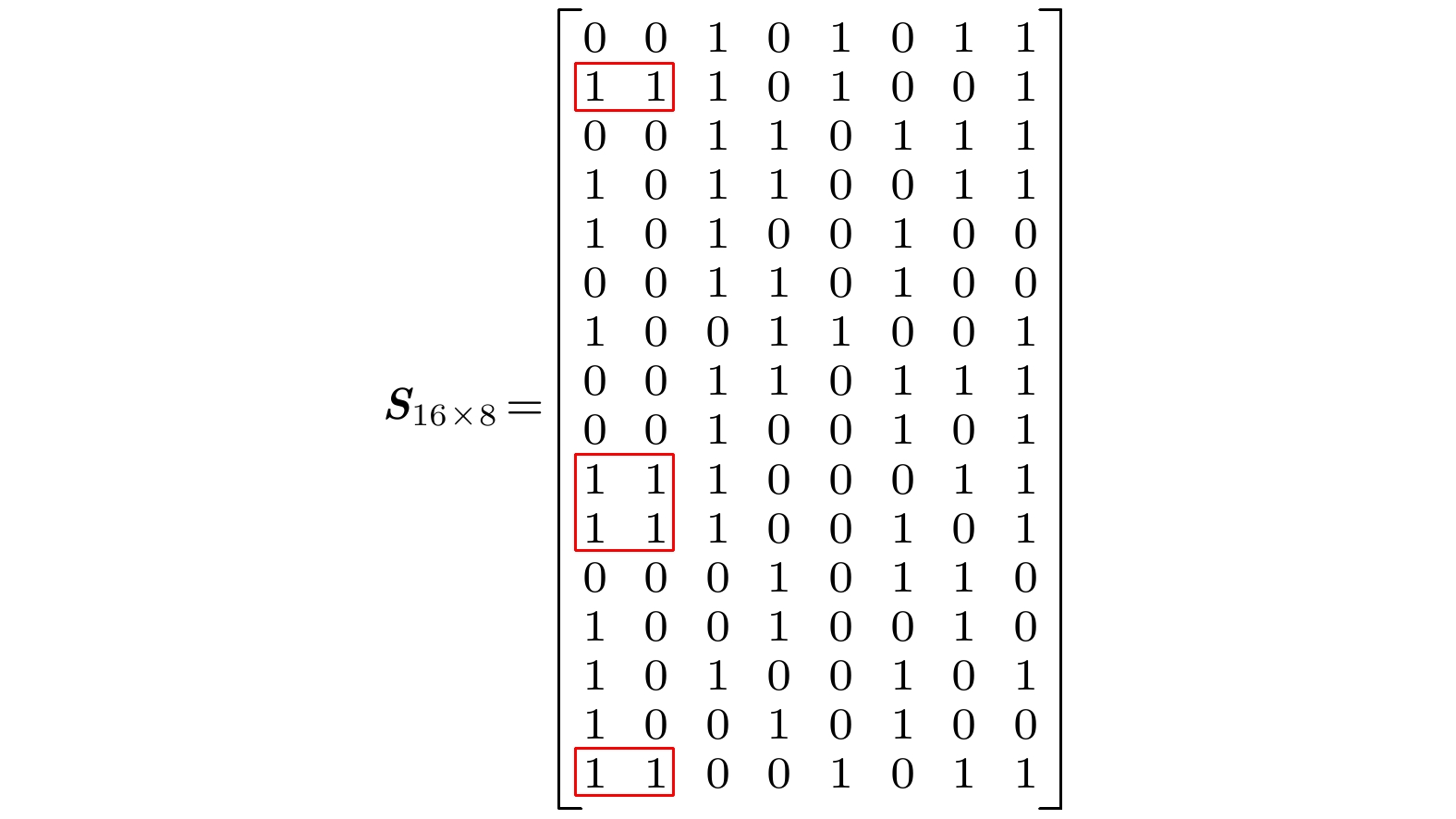 图 2 节点1和节点2的相同感染源数量
图 2 节点1和节点2的相同感染源数量



























 图 3 子图重构过程
图 3 子图重构过程




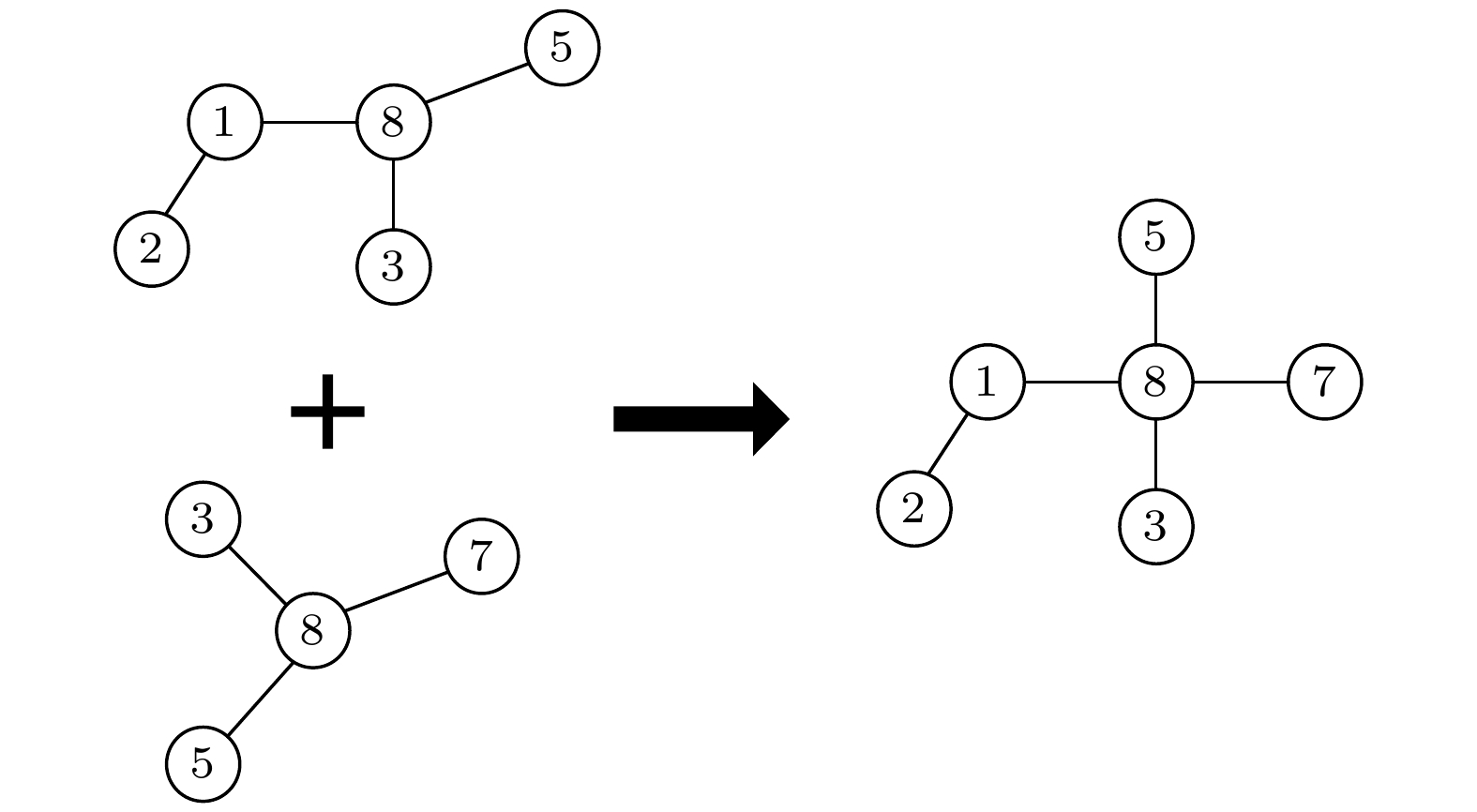 图 4 子图叠加过程
图 4 子图叠加过程



















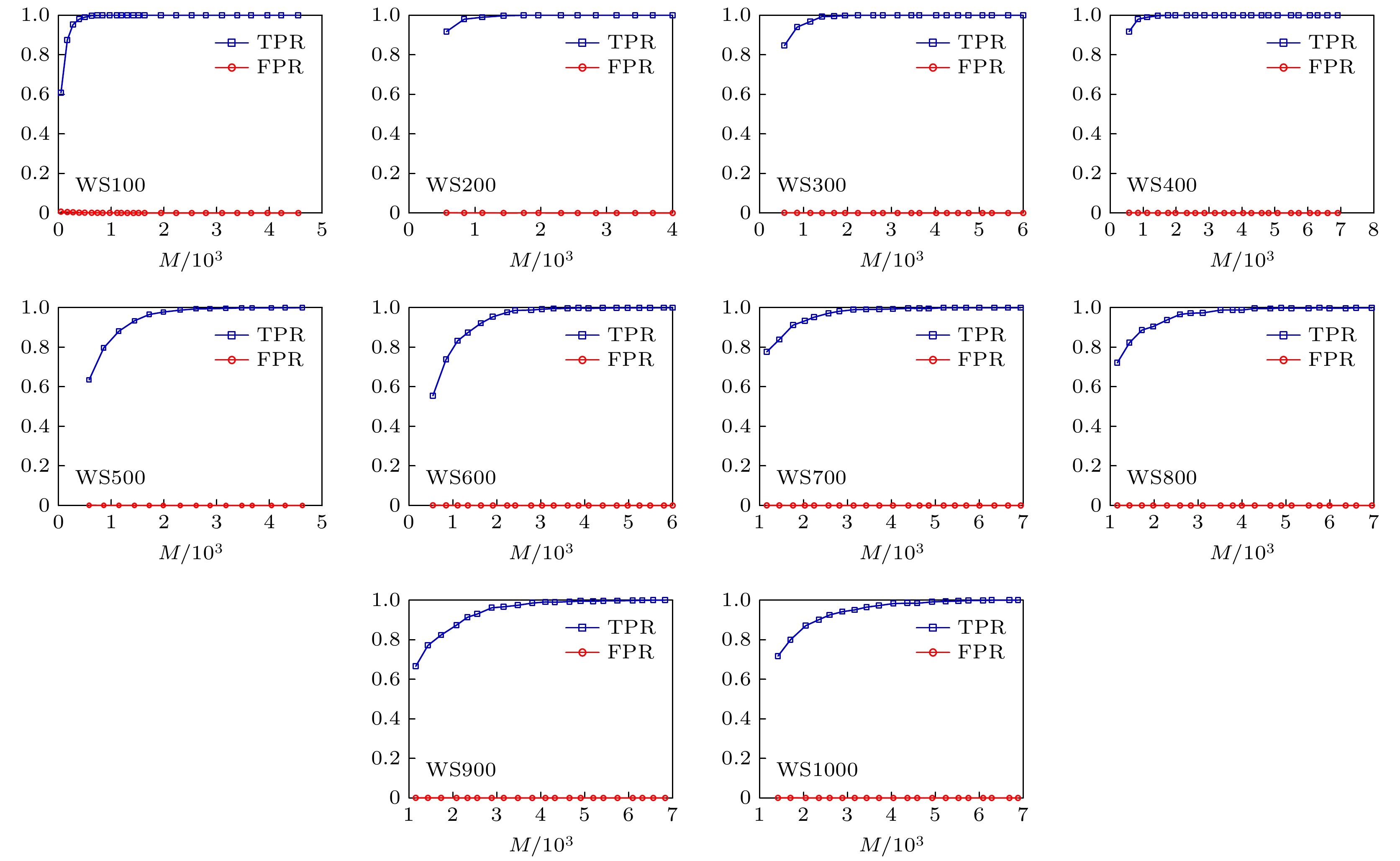 图 5 不同规模的WS小世界网络重构实验效果
图 5 不同规模的WS小世界网络重构实验效果



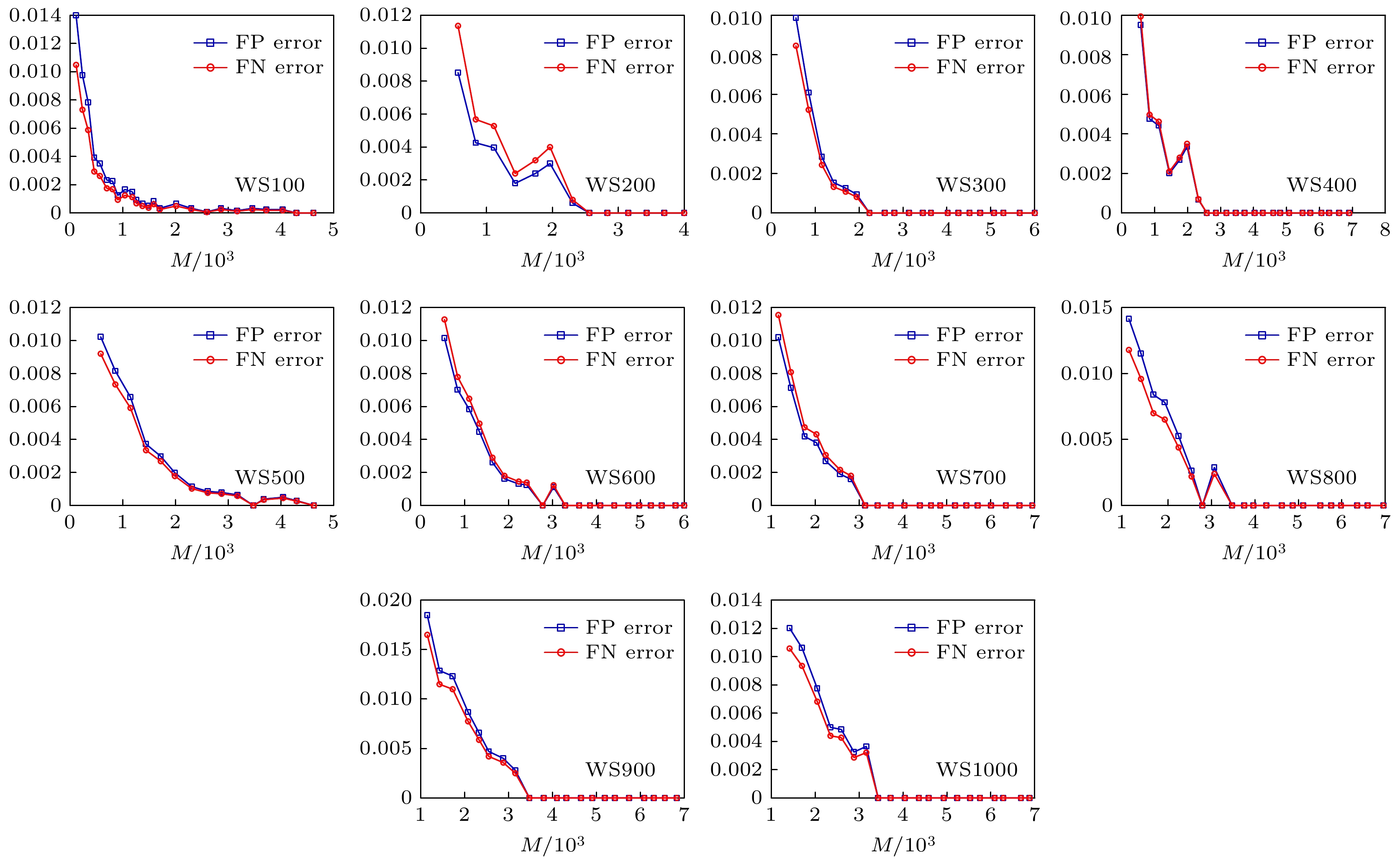 图 6 不同规模的WS小世界网络重构误差分析
图 6 不同规模的WS小世界网络重构误差分析




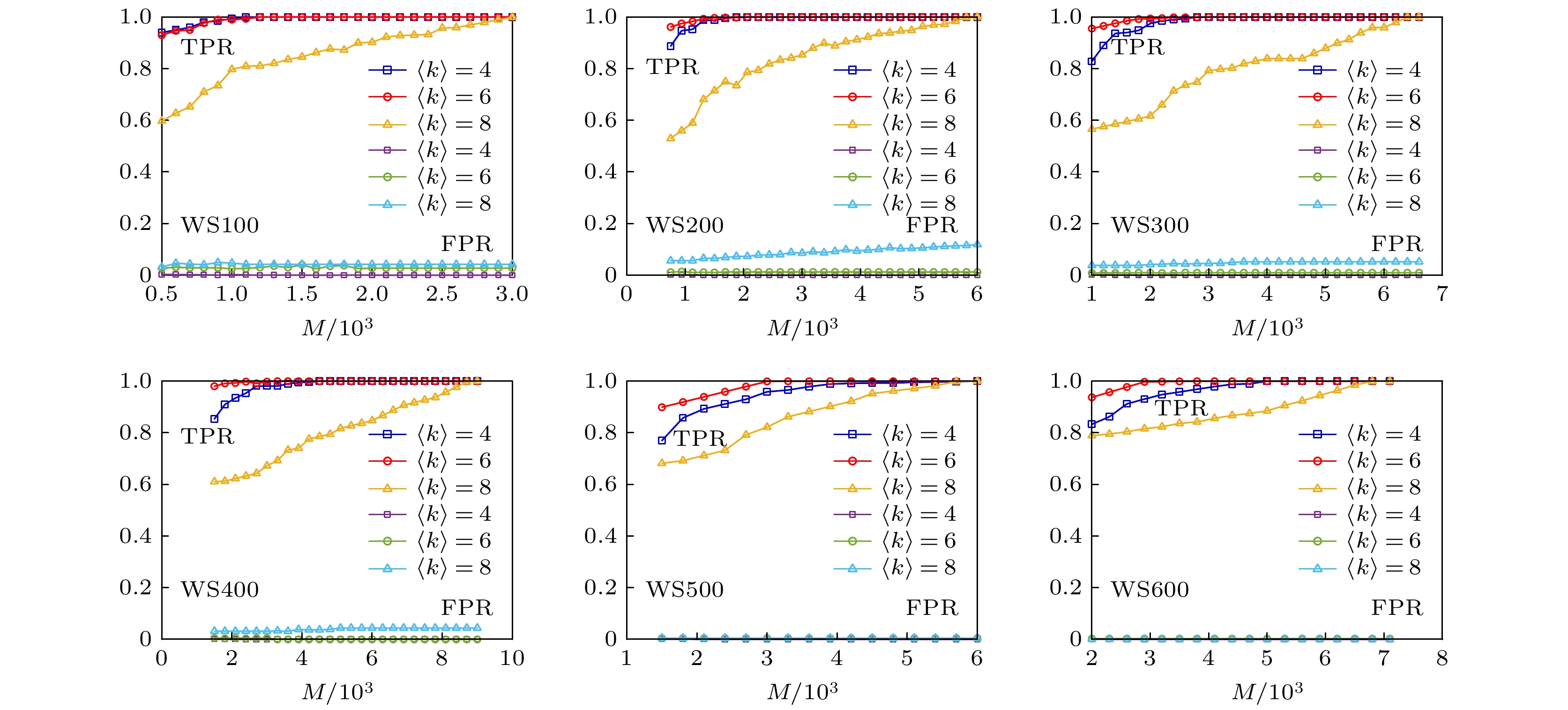 图 7 WS小世界网络不同平均度值对网络重构实验效果的影响
图 7 WS小世界网络不同平均度值对网络重构实验效果的影响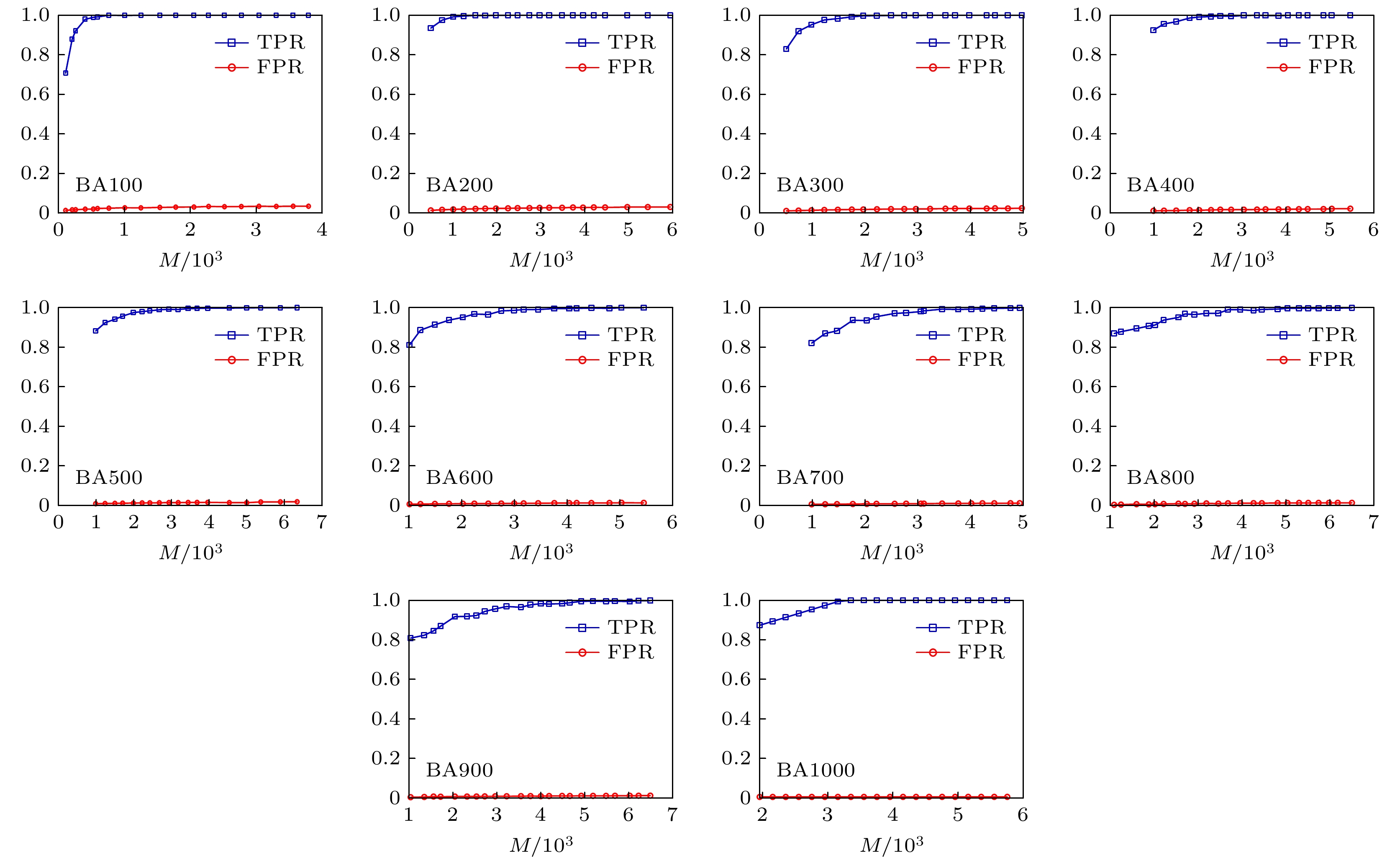 图 8 不同规模的BA无标度网络重构实验效果
图 8 不同规模的BA无标度网络重构实验效果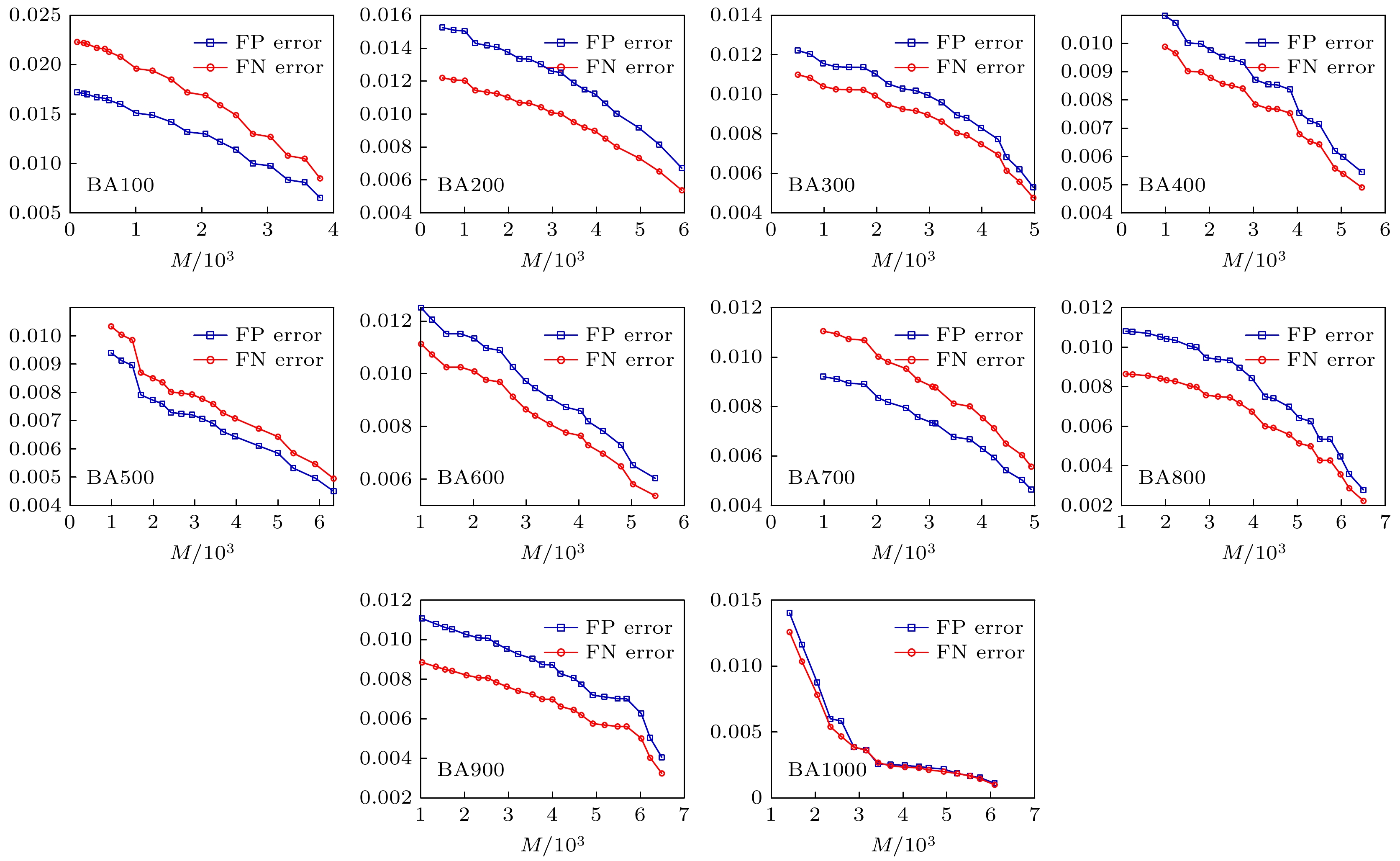 图 9 不同规模的BA小世界网络重构误差分析
图 9 不同规模的BA小世界网络重构误差分析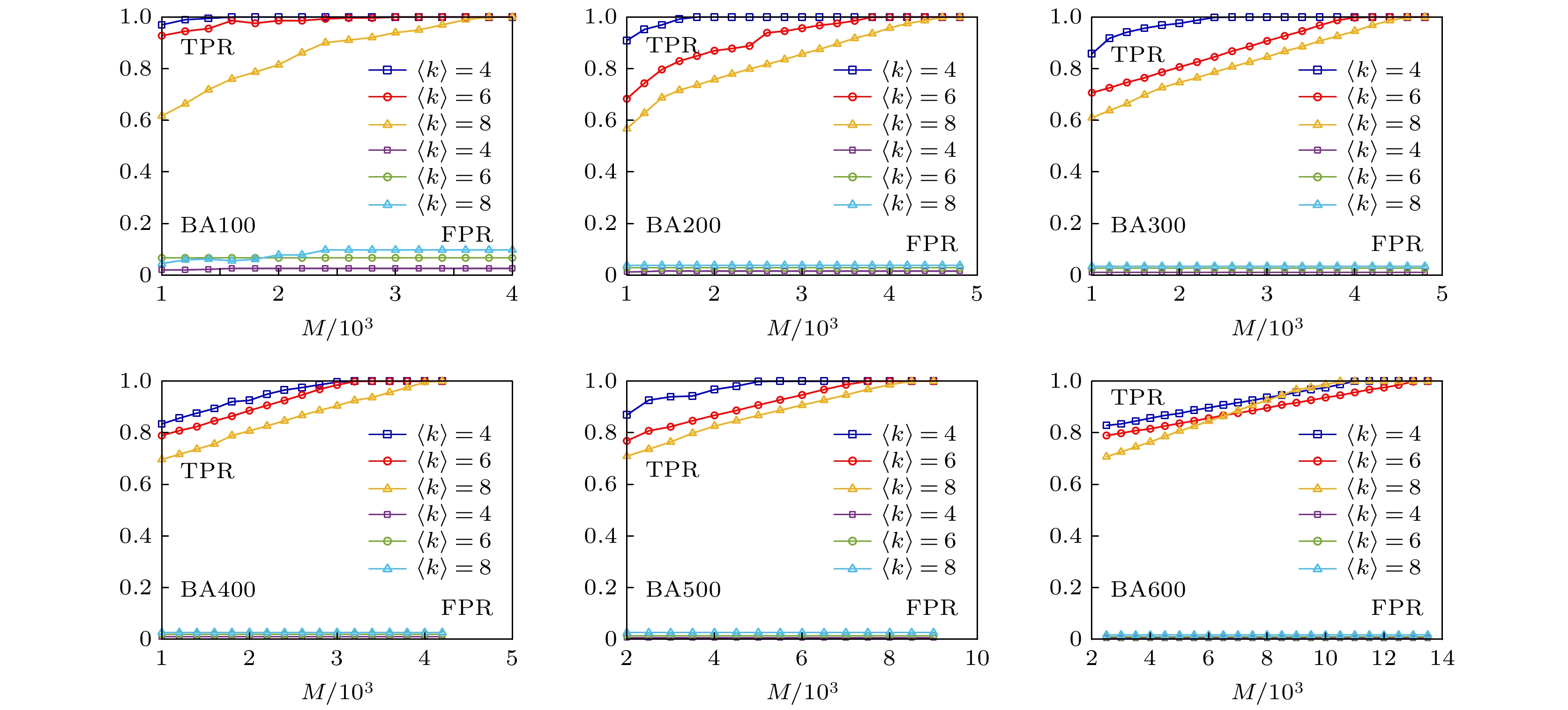 图 10 BA无标度网络不同平均度值对网络重构实验效果的影响
图 10 BA无标度网络不同平均度值对网络重构实验效果的影响 图 11 不同规模的ER随机网络重构实验效果
图 11 不同规模的ER随机网络重构实验效果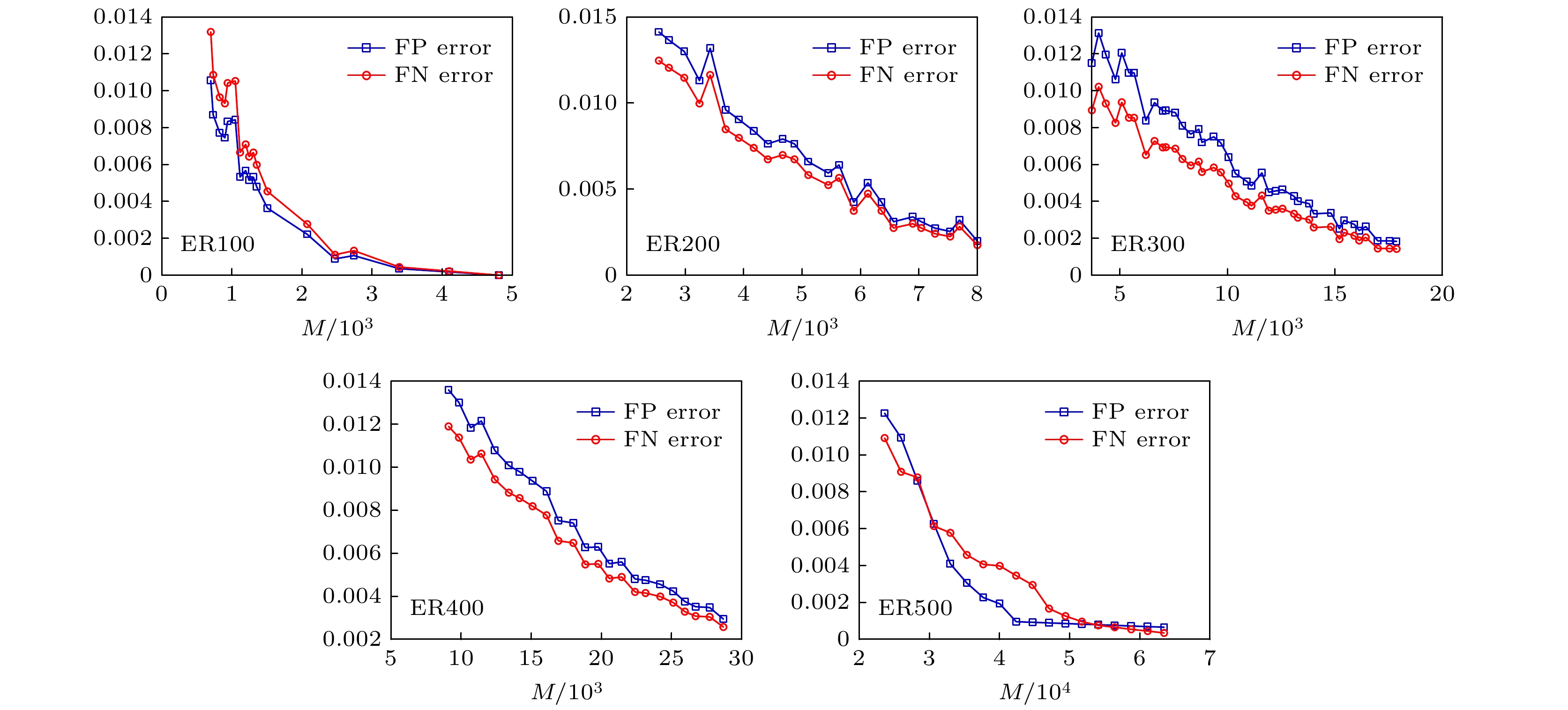 图 12 不同规模的ER小世界网络重构误差分析
图 12 不同规模的ER小世界网络重构误差分析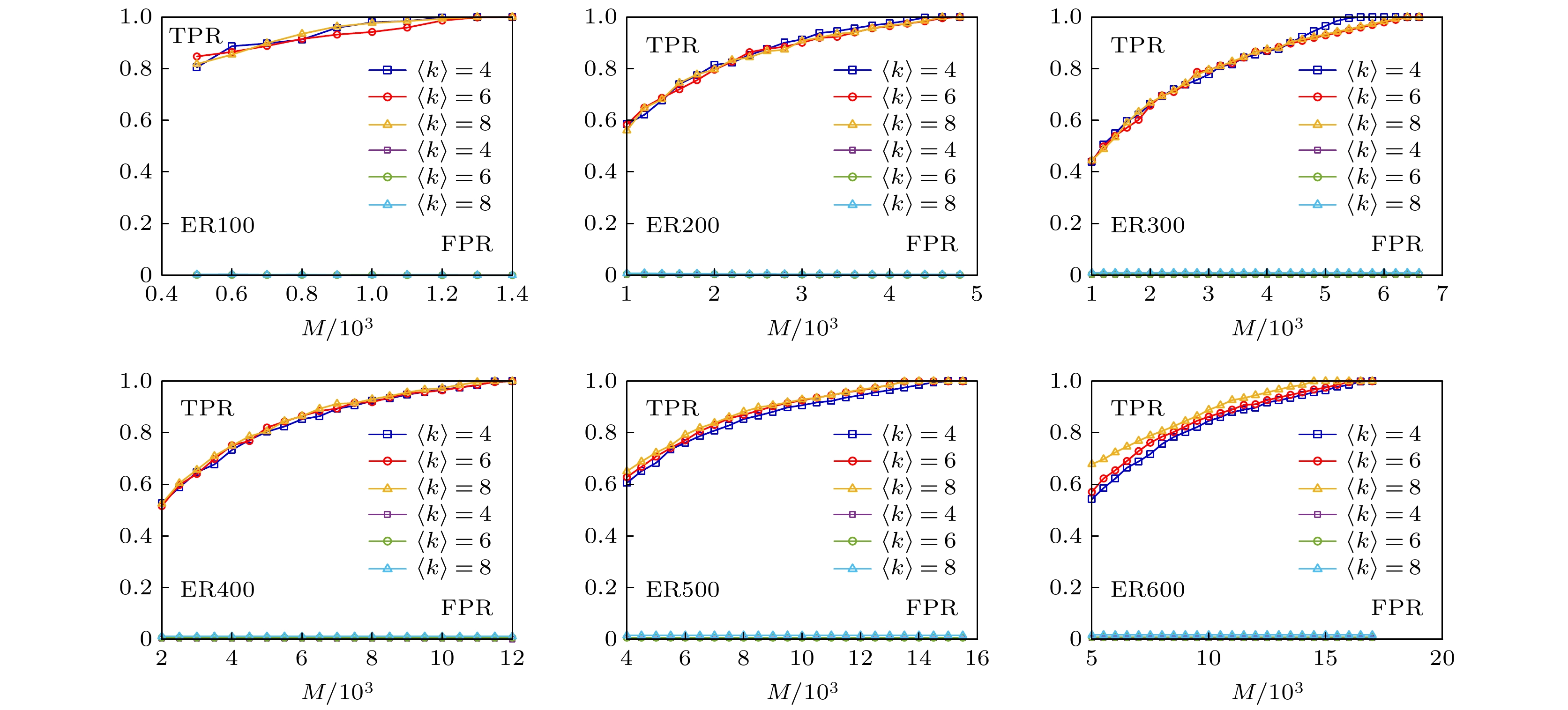 图 13 ER随机网络不同平均度值对网络重构实验效果的影响
图 13 ER随机网络不同平均度值对网络重构实验效果的影响 图 14 三种不同网络在相同数据下的重构效果对比
图 14 三种不同网络在相同数据下的重构效果对比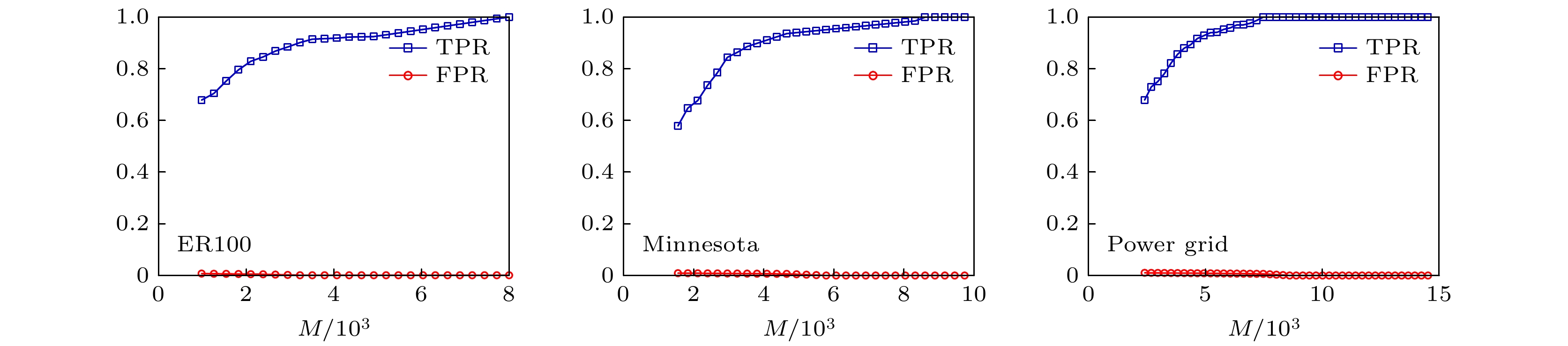 图 15 三个实际网络重构实验效果
图 15 三个实际网络重构实验效果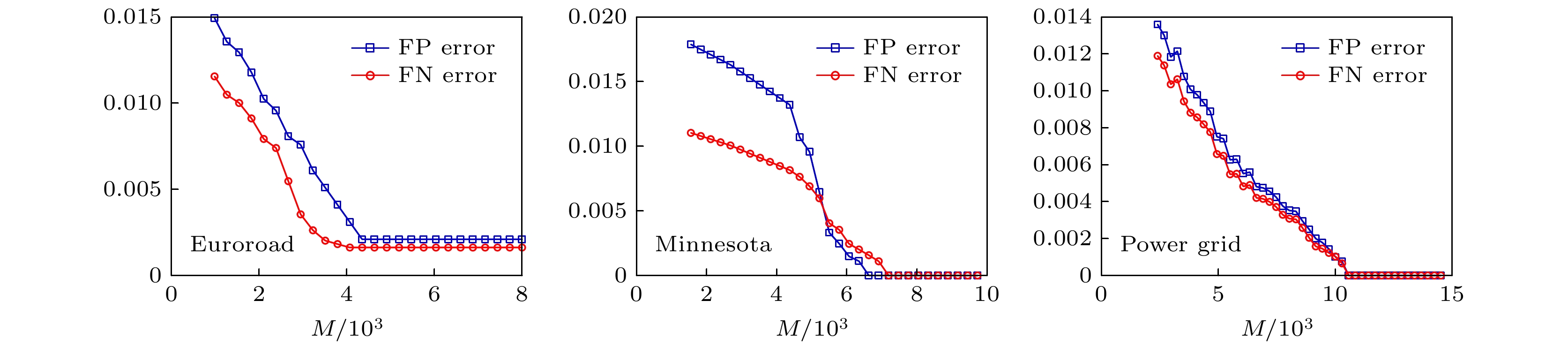 图 16 三个实际网络重构误差分析
图 16 三个实际网络重构误差分析