全文HTML
--> --> -->近年来, 随着深度学习技术和硬件技术法发展, 已有研究人员将深度学习算法运用到混沌时间序列的预测中, 文献[7]用长短期记忆网络(long short-term memory, LSTM)搭配合适的组合策略, 验证了在低维情况下LSTM在混沌时间序列预测上能够取得较好的效果; 文献[8]则进一步验证了使用LSTM预测混沌时间序列不仅能够取得较好的预测效果, 且预测模型具有较好的鲁棒性. 结合混沌理论和经验模态分解, 文献[9]使用LSTM搭建预测模型, 取得了可靠性高的预测结果, 且预测模型具有一定的泛化能力. 文献[10]利用卷积神经网络(convolutional neural networks, CNN)训练连续和离散的低维混沌时间序列生成一个分类器, 使其能够识别并分类高维状态下的混沌时间序列.
相比最小支持向量机(LSSVM)[11,12]、极端学习机[3,13]等传统机器学习算法, LSTM和CNN等深度学习算法具有更强大的学习能力, 在处理回归问题上, 对非线性数据具有很好的逼近能力. 因此, 为了进一步提高混沌时间序列的预测精度, 本文结合混沌系统的相空间重构理论, 提出一种基于深度学习算法的混沌时间序列混合预测模型(Att-CNN-LSTM). 首先, 将获取的时间序列进行数据预处理, 即重构相空间和数据归一化. 然后提出利用注意力机制捕获CNN的相空间特征和LSTM的时间特征, 并对输出结果进行权衡, 给出预测结果. 最后将提出的预测模型分别应用于Logistic、Lorenz和太阳黑子混沌时间序列, 仿真实验结果表明本文提出的预测模型可以有效地对混沌时间序列进行预测, 且与其他预测方法相比, Att-CNN-LSTM模型具有更高的预测精度.
2
2.1.重构相空间
重构相空间理论的出现为混沌时间序列的预测提供了理论基础, 在重构相空间的基本思想中, 系统中任一变量的变化是由相互作用着的其他变量所决定的, 因此任一变量的发展变化都蕴含着其他变量发展变化的信息[14]. 根据Packard等[15]提出的理论, 使用动力系统中某一变量的延迟坐标即可重构相空间, Takens[16]则证明了在合适的嵌入维下, 即可恢复原动力系统的维数. 为实现相空间的重构, 使用互信息法(mutual information)[17]确定延迟时间
设有时间序列






2
2.2.数据归一化
在深度学习中, 对数据集尤其是对非线性的回归数据集进行归一化操作是非常有必要的预处理步骤, 因为归一化操作不仅可以消除量纲, 将数据统一到相同的尺度上, 还可以提升模型的收敛速度和预测精度. 本文利用归一化将相空间域数据集和原始混沌时间序列数据集都统一到(0, 1)范围之间, 归一化函数可表示为
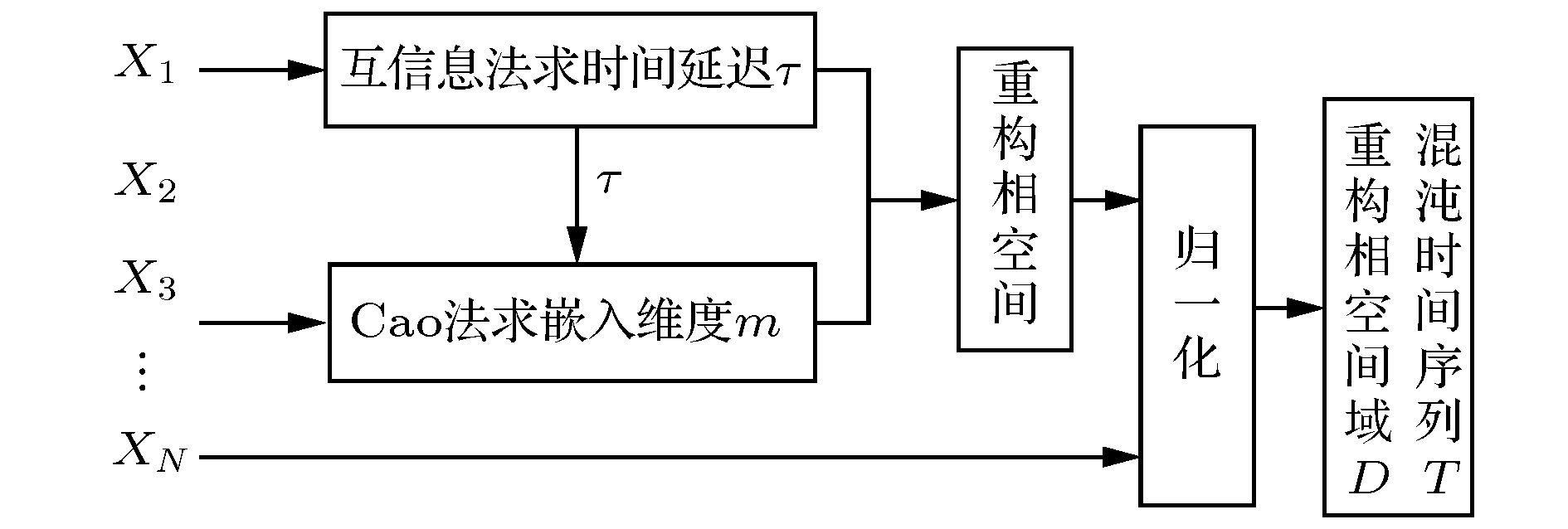 图 1 数据预处理过程
图 1 数据预处理过程Figure1. The process of data preprocessing.
本节主要介绍Att-CNN-LSTM模型的框架结构, 如图2所示, 主要包括如下细节:
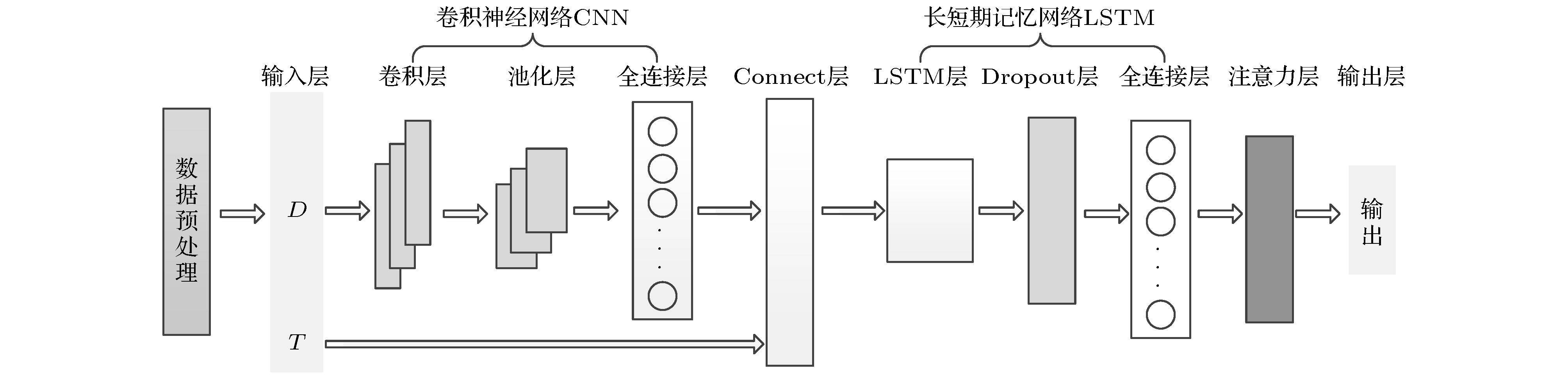 图 2 Att-CNN-LSTM模型
图 2 Att-CNN-LSTM模型Figure2. Att-CNN-LSTM model.
(1)数据预处理: 先对序列进行重构相空间, 然后进行归一化处理;
(2)卷积神经网络层: 处理网络输入的重构相空间域D, 进行卷积操作, 获取空间特征并输入到Concatenate层;
(3)长短期记忆网络层: 将Concatenate层融合得到的张量输入到LSTM中, 网络根据CNN提取的空间特征获取时空特征;
(4)注意力层: 计算CNN和LSTM获取的时空特征的权重, 获得序列的完整特征表示, 根据特征计算预测数值.
2
3.1.卷积神经网络CNN
卷积网络[19], 又称卷积神经网络, 是一种特殊的深度学习神经网络, 常用于处理具有已知网格状拓扑的数据[20], 在时间序列分析、计算机视觉和自然语言处理等领域有着广泛的运用. 根据处理数据流的不同, CNN可以分为一维卷积、二维卷积和三维卷积, 其中一维卷积在时间序列分析和自然语言处理领域运用较多, 本文采取的CNN结构就属于一维卷积神经网络[21], 如图3所示. 不管是何种CNN, 其组成主要包括基本的输入层和输出层, 核心操作部分为卷积层、池化层(亦称采样层)和全连接层. 在一维卷积中, 卷积的作用可以理解为提取数据在某一方向的平移特征, 在时间序列的分析中则表现为提取序列的特征, 在这里卷积操作的本质是循环乘积与加和, 其数学表达如下: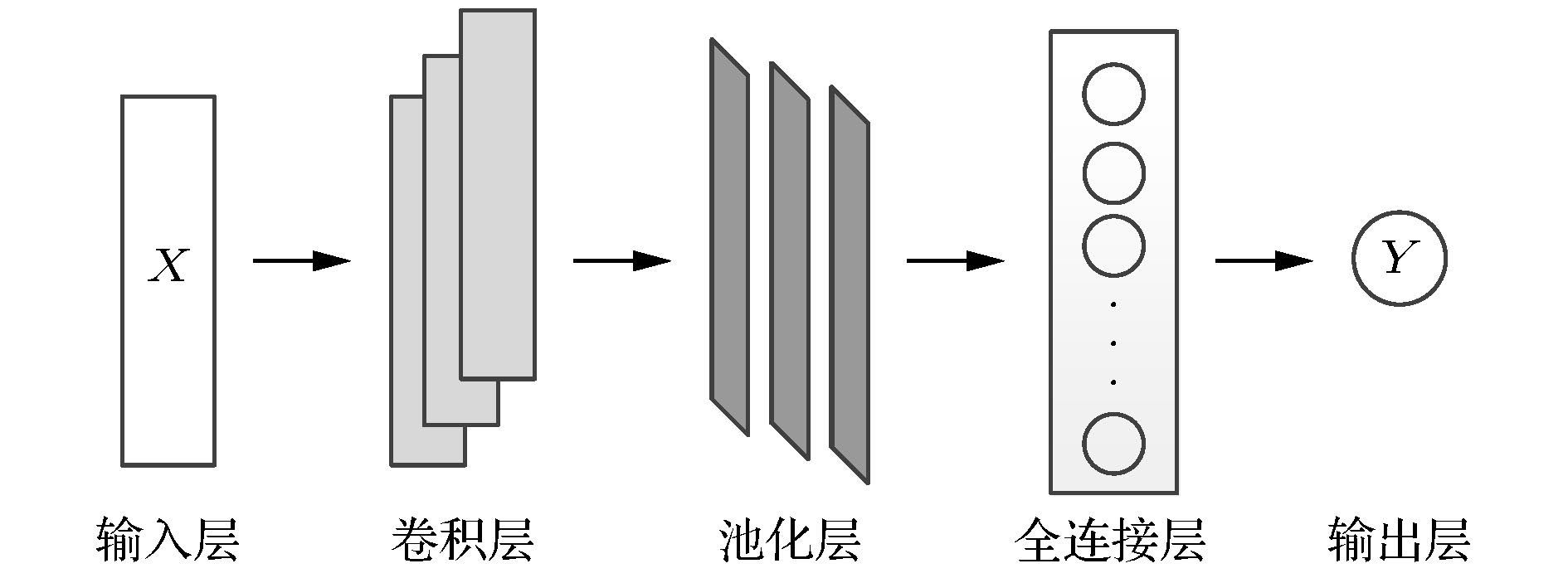 图 3 一维卷积网络
图 3 一维卷积网络Figure3. One dimensional convolutional network.
2
3.2.长短期记忆网络
循环神经网络(recurrent neural network, RNN)是常规前馈神经网络的扩展, 能够处理可变长度序列输入. RNN通过循环隐藏状态单元来处理可变长度序列, 但是RNN在训练时会出现梯度消失和梯度爆炸, 因此RNN很难捕获数据的长期依赖[22]. 为解决RNN梯度消失的难题Hochreiter和Schmidhuber [23]提出了长短期记忆网络, LSTM是一种门控循环神经网络, 是RNN的一种特殊表现形式, 能够很好地捕获数据之间的长期依赖[24].在LSTM单元结构中共有三个“门”: 遗忘门、输入门和输出门, 其结构如图4所示. 在LSTM中, 通过输入门








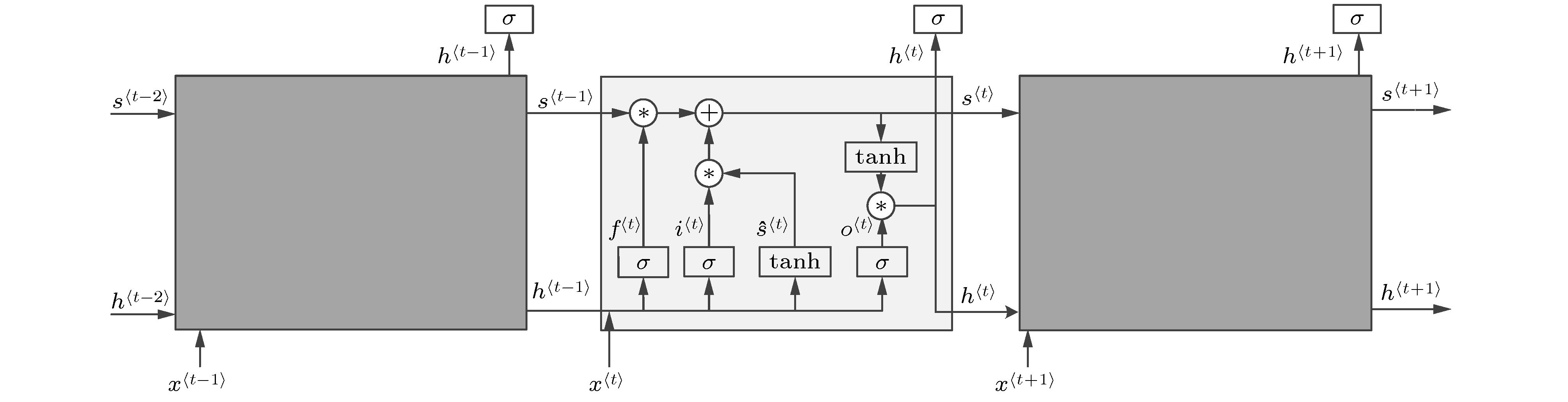 图 4 LSTM结构
图 4 LSTM结构Figure4. The structure of LSTM.



2
3.3.注意力机制
人类大脑在观察某一事物时, 往往会将注意力集中到事物的某些部分, 这些注意力集中的部分往往也是从事物上获取信息的关键, 这些信息对于认知同类事物有着很强的指引作用, 而注意力机制(attention mechanism)[25]就是一种模仿这一认知过程的特殊机制. 注意力机制在计算机视觉和自然语言处理领域的运用已经取得了较好的结果[26,27], 本文将注意力机制运用到时间序列的分析中.在混沌时间序列的分析中, 先用CNN提取序列的空间特征, 在用LSTM根据空间特征提取时空特征后, 过多或非关键的特征会影响最后的预测结果. 因此, 利用注意机制来提取序列的关键特征. 注意力机制可以简单地理解为一个加权求和器, 也可以理解为一个关键特征提取器, 它主要进行的是加权求和操作. 本文提出的注意力模型如图5所示, 向量c即为提取的关键特征, 其计算公式如下:
 图 5 注意力模型
图 5 注意力模型Figure5. Attention model.

为了获得权值




2
3.4.其 他
如图2所示, Att-CNN-LSTM模型中添加了Concatenate层和Dropout层, 其中Concatenate层是为了将卷积神经网络的输出, 即序列的空间特征与原序列T进行特征融合. 在深度学习模型中加入Dropout层很常见, 其作用主要是为了防止模型训练时出现过拟合, 进而提升模型的鲁棒性和泛化能力.为验证Att-CNN-LSTM模型的预测能力, 利用Logistic、Lorenz和太阳黑子混沌时间序列进行实验, 并与未加入注意力机制的CNN-LSTM模型、单一的LSTM和CNN模型, 以及LSSVM模型进行误差对比. 为了评价预测误差, 除了采用常用的均方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE)外, 再引入一个在评价时间序列预测性能中常用的均方根百分比误差(RMSPE), 即:


2
4.1.Logistic时间序列预测
Logistic混沌映射方程为


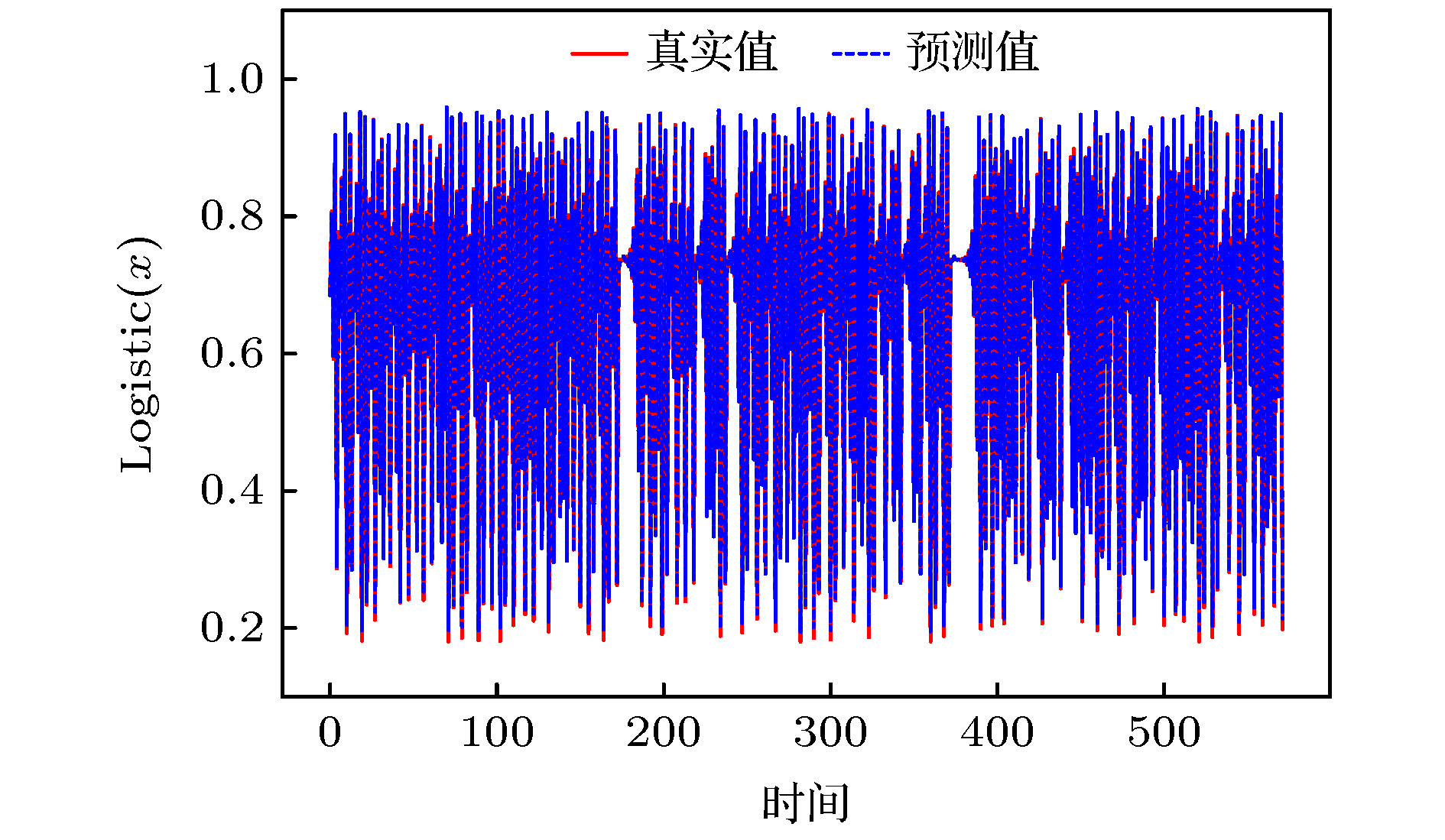 图 6 Logistic序列预测
图 6 Logistic序列预测Figure6. Logistic series prediction.
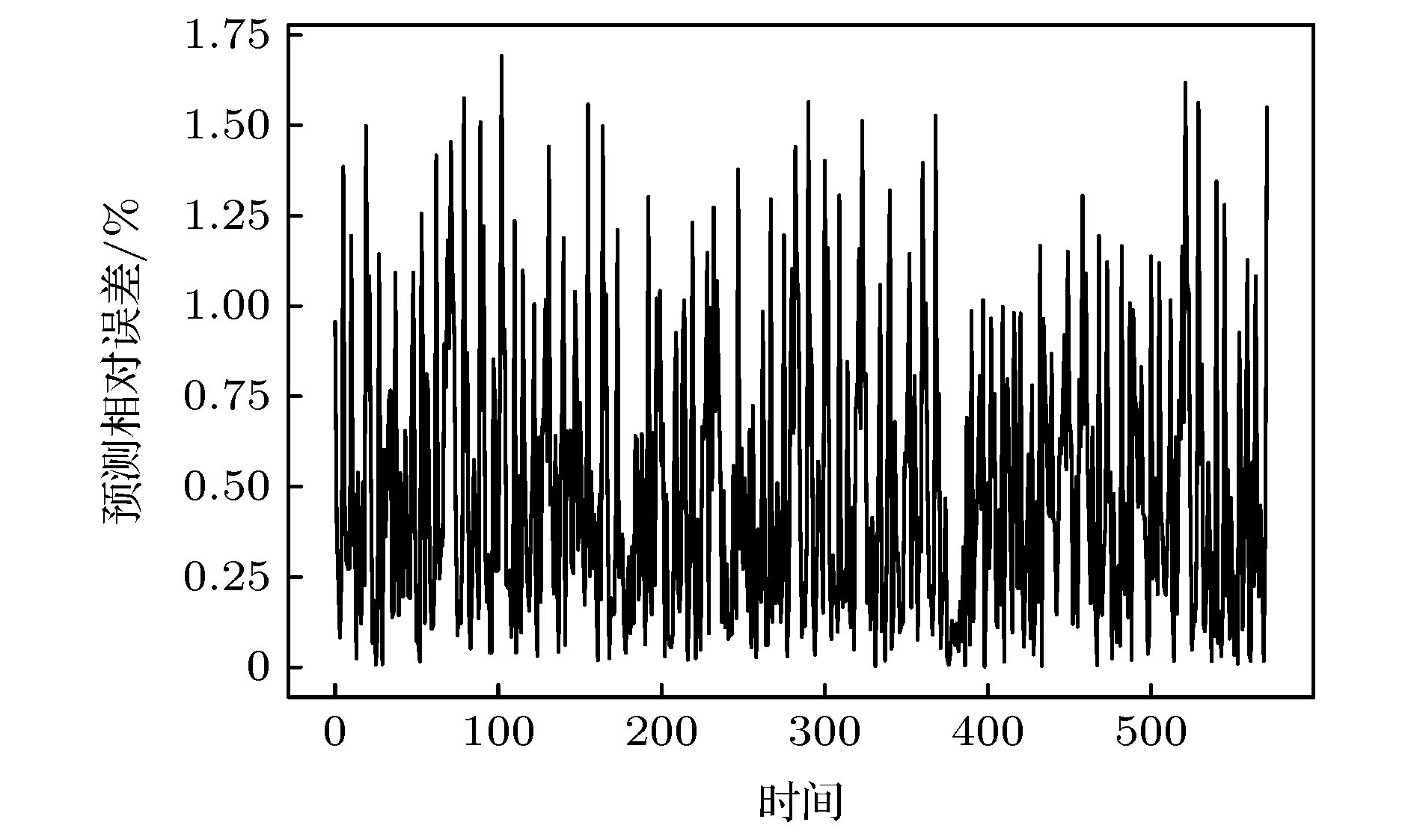 图 7 Logistic序列预测相对误差
图 7 Logistic序列预测相对误差Figure7. Logistic series prediction relative error.
| RMSE | MAE | MAPE | RMSPE | |
| Att-CNN-LSTM | 0.003503 | 0.002935 | 0.5305 | 0.6767 |
| CNN-LSTM | 0.006856 | 0.005444 | 1.1064 | 1.7795 |
| LSTM | 0.006169 | 0.005316 | 1.1595 | 1.6887 |
| CNN | 0.004670 | 0.003849 | 0.8802 | 1.4019 |
| LSSVM | 0.009158 | 0.004307 | 1.3623 | 3.8604 |
表1模型误差对比
Table1.Model error comparison.
从图6和图7中可以看出, Att-CNN-LSTM对Logistic时间序列的预测取得了较好的结果, 不仅能够预测序列变化的趋势, 且真实值和预测值之间的误差较小, 说明本文提出的模型取得了较高的预测精度. 如表1所列, 与CNN-LSTM, LSTM, CNN和LSSVM等模型的预测误差对比, Att-CNN-LSTM的各项预测误差均为最小, 说明本文提出的模型预测精度高, 预测性能较好. 与未引入注意力机制的CNN-LSTM预测模型相比, Att-CNN-LSTM对预测精度的提升较为明显, 说明注意力机制在模型中提取到了序列的关键时空特征, 使得预测结果更加准确. 值得注意的是, 单一的CNN和LSTM模型的预测结果优于CNN-LSTM混合模型, 说明混合模型下的非关键特征在一定程度上降低了预测精度, 这也说明了注意力模型在CNN-LSTM混合模型中具有重要的作用. 此外单一的CNN预测模型在Logistic数据集上的预测表现优于单一的LSTM模型, 说明CNN在Logistic序列高纬度相空间下提取的空间特征好于LSTM提取的时间特征, 从Att-CNN-LSTM模型与这两个单一模型的对比中, 可以发现仅依赖单一的时间或空间特征, 难以获得精度较高的预测结果, 而注意力模型提取关键时空特征能够提升预测精度, 是一个较为理想的预测方法.
为了更全面地对比本文提出的Att-CNN-LSTM模型的预测性能, 表2中列出了各个模型的训练和预测时间. 不难看出, 在模型的训练阶段, 单一的CNN, LSTM和LSSVM预测模型所用的时间较小, 分别为59.5, 48.8和215.4 s. 相比之下, 混合模型因为模型较为复杂, 所需进行的运算更多, 所以训练时间用时较多, 其中Att-CNN-LSTM用时312.7 s, CNN-LSTM用时302 s. 但是在测试阶段, 各个模型所用时间相差不大, 虽然单一模型的预测用时仍比混合模型短, 但是都控制在0.6 s以内. 综合各个模型的预测误差表现, 本文提出的预测模型具有较高的性价比, 且预测优势明显.
| 模型 | Att-CNN-LSTM | CNN-LSTM | CNN | LSTM | LSSVM |
| 训练时间 /s | 312.7 | 302 | 59.5 | 48.8 | 215.4 |
| 预测时间 /s | 0.53 | 0.49 | 0.25 | 0.21 | 0.47 |
表2模型运行时间对比
Table2.Model running time comparison.
2
4.2.Lorenz时间序列预测
Lorenz混沌映射方程为



| RMSE | MAE | MAPE | RMSPE | |
| Att-CNN-LSTM | 0.0679 | 0.0521 | 1.2182 | 2.1102 |
| CNN-LSTM | 0.2445 | 0.1229 | 3.8849 | 14.7893 |
| LSTM | 0.5152 | 0.3901 | 13.6767 | 43.7676 |
| CNN | 0.5356 | 0.3811 | 11.0032 | 33.5251 |
| LSSVM | 0.5101 | 0.3652 | 9.3543 | 35.5644 |
表3模型误差对比
Table3.Model error comparison.
| 模型 | Att-CNN-LSTM | CNN-LSTM | CNN | LSTM | LSSVM |
| 训练时间 /s | 184.6 | 193.9 | 84.28 | 51.21 | 202.4 |
| 预测时间 /s | 0.47 | 0.55 | 0.20 | 0.23 | 0.45 |
表4模型运行时间对比
Table4.Model running time comparison.
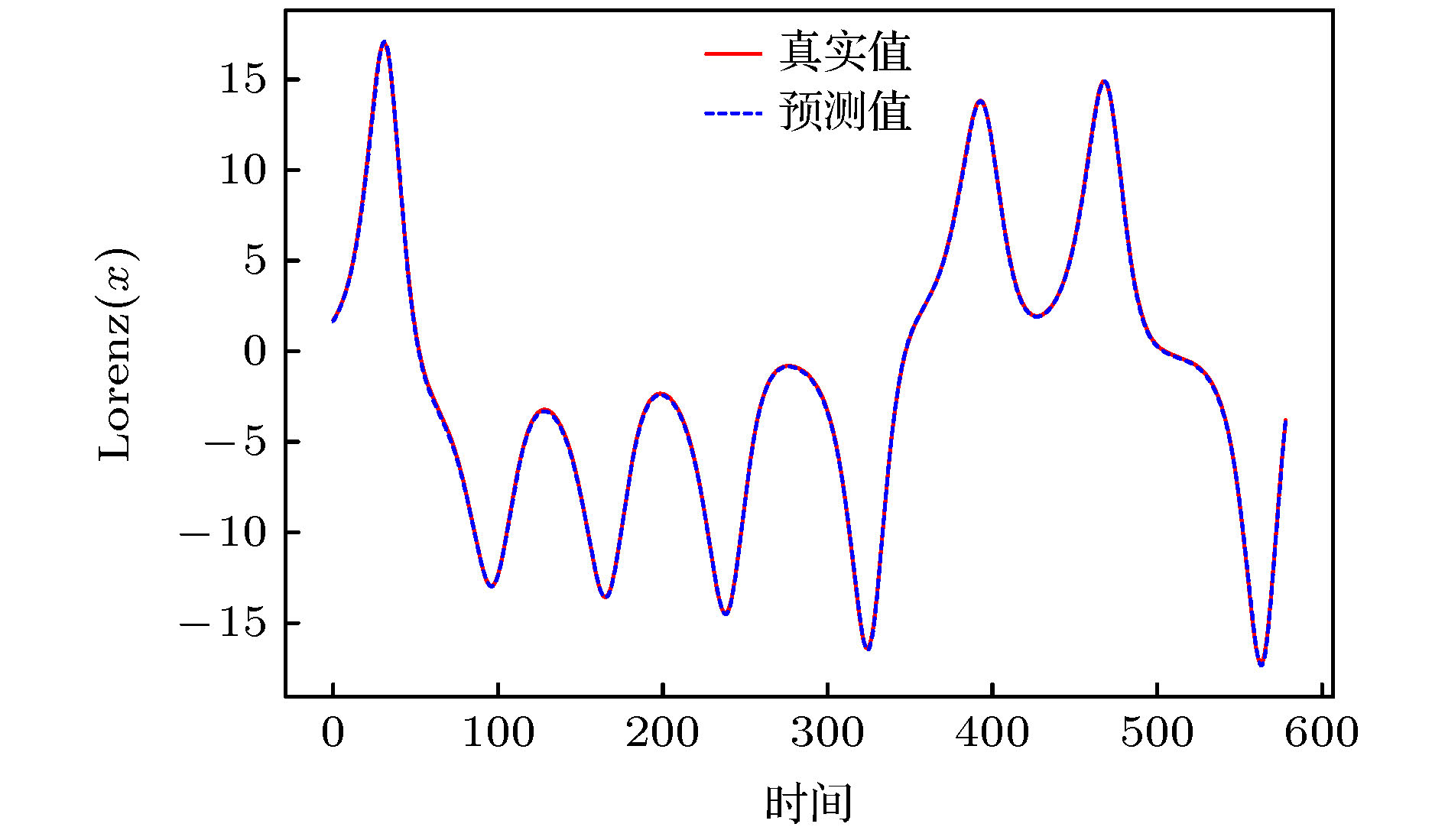 图 8 Lorenz(x)序列预测
图 8 Lorenz(x)序列预测Figure8. Lorenz(x) series prediction.
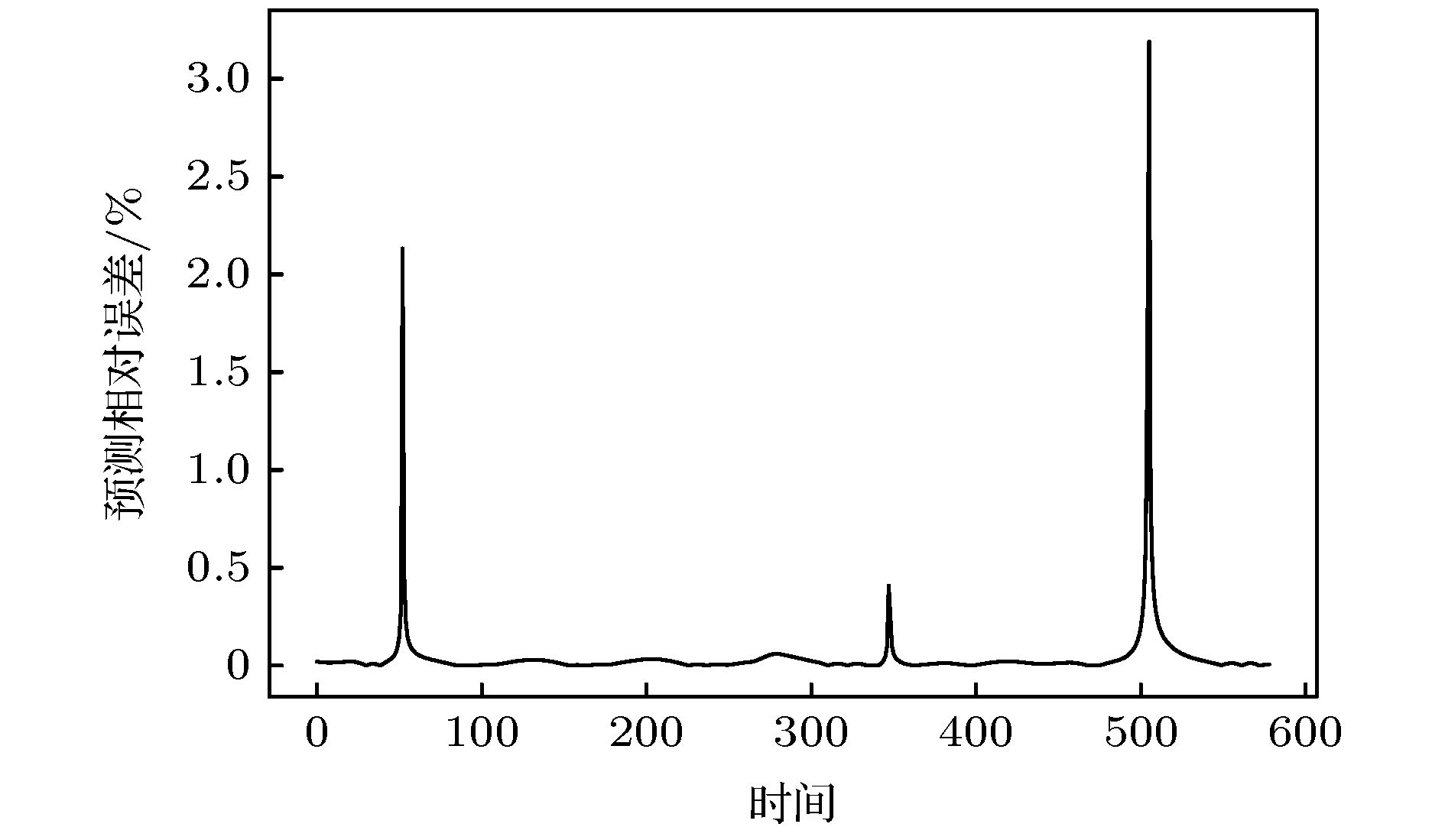 图 9 Lorenz(x)序列预测相对误差
图 9 Lorenz(x)序列预测相对误差Figure9. Lorenz(x) series prediction relative error.
图8和图9所展示的Lorenz(x)序列预测结果很好地表现了Att-CNN-LSTM的预测性能, 在预测集上, 模型的预测结果误差较小, 精度较高, 非常接近真实值. 从表2中也能看出, 在Lorenz样本集上本文提出的Att-CNN-LSTM模型表现依然出色, 且Att-CNN-LSTM的预测性能明显优于CNN-LSTM, LSTM, CNN和LSSVM等模型, RMSE, MAE, MAPE和RMSPE四项预测指标分别降低至0.00679, 0.0521, 1.2182和2.1102, 相比其他模型精度提升较为明显. 不同于在Logistic样本集上的表现, CNN-LSTM在Lorenz样本集上的表现虽然不如Att-CNN-LSTM模型, 但是却优于单一的CNN和LSTM模型, 各项预测指标也下降较多. 在单一模型中, 在RMSE指标下LSTM的预测性能略好于CNN, 但在其他指标下其预测性能略低于CNN, 此外, LSSVM的综合表现优于CNN和LSTM. 在运行时间方面, 单一的预测模型在训练和测试阶段所用时间依然低于混合模型, 但时间差距有所缩小. 此外, 在Lorenz样本集上, Att-CNN-LSTM模型的运行时间低于CNN-LSTM模型, 综合考虑下, 本文提出的模型依然具有较高的预测性能.
2
4.3.太阳黑子时间序列预测
在Logistic和Lorenz这两个理论混沌系统中, Att-CNN-LSTM表现出了较好的预测性能, 为验证其在真实动力系统的表现, 采用太阳黑子时间序列检验其预测性能. 本文采集了1749-2019年的太阳黑子数据, 共有3252条数据, 经过相空间重构后, 产生3094组样本数据, 训练集和测试集仍以8:2比例划分, 即前80%作为训练集后20%作为测试集. 预测结果和误差如图10和图11所示, 表5和表6则列出了Att-CNN-LSTM模型和其他模型的预测结果对比.| RMSE | MAE | MAPE | RMSPE | |
| Att-CNN-LSTM | 20.1829 | 17.1827 | 32.8167 | 42.3529 |
| CNN-LSTM | 30.5652 | 21.4093 | 67.4343 | 56.7217 |
| LSTM | 24.9137 | 18.2815 | 49.5862 | 62.6939 |
| CNN | 24.8534 | 18.4677 | 65.3480 | 44.1892 |
| LSSVM | 27.3271 | 19.4373 | 43.0987 | 56.6781 |
表5模型误差对比
Table5.Model error comparison.
| 模型 | Att-CNN-LSTM | CNN-LSTM | CNN | LSTM | LSSVM |
| 训练时间 /s | 309.2 | 291.3 | 76.5 | 53.3 | 237.9 |
| 预测时间 /s | 0.39 | 0.43 | 0.15 | 0.25 | 0.59 |
表6模型运行时间对比
Table6.Model running time comparison.
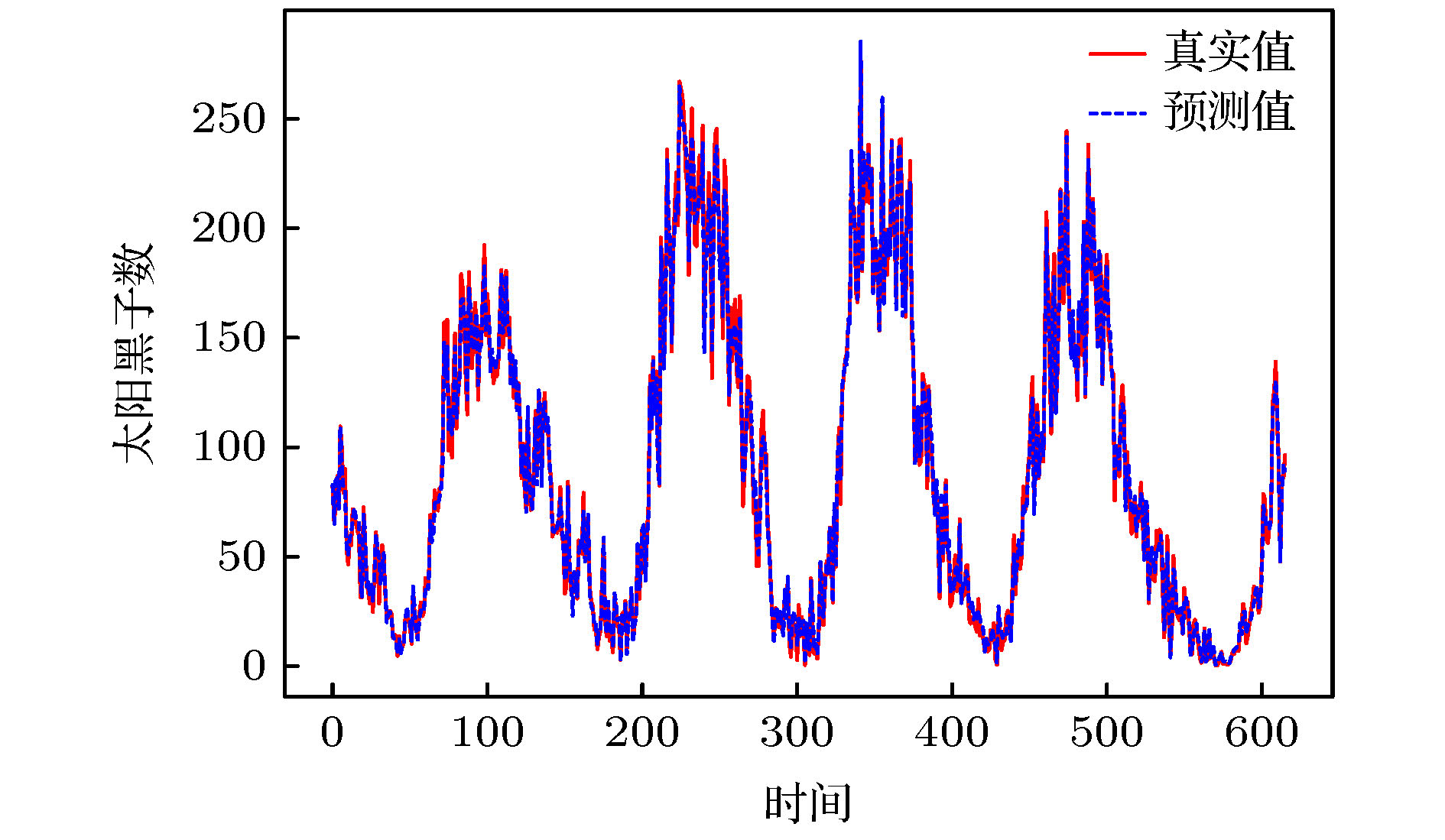 图 10 太阳黑子序列预测
图 10 太阳黑子序列预测Figure10. Sunspot series prediction.
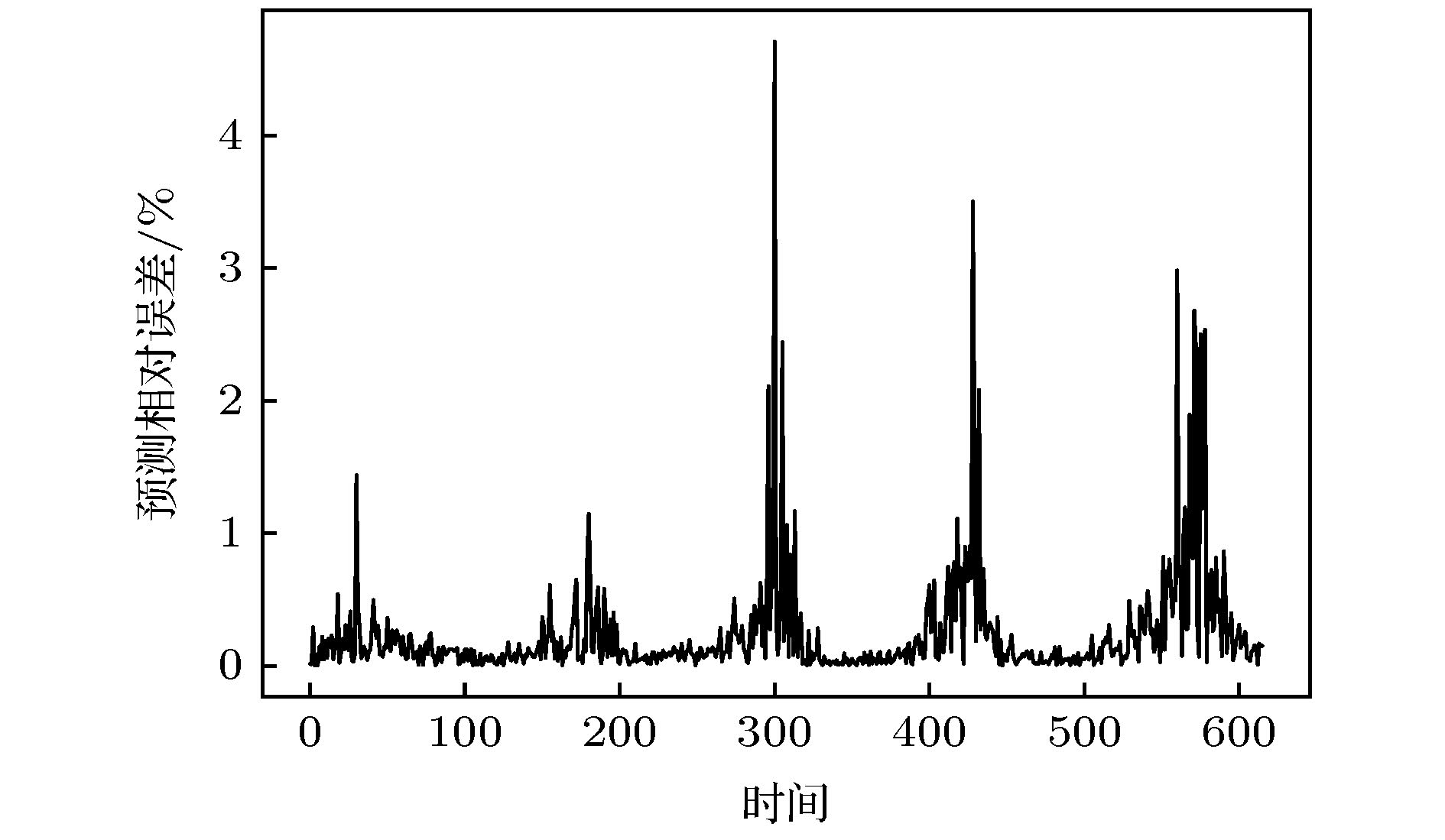 图 11 太阳黑子序列预测相对误差
图 11 太阳黑子序列预测相对误差Figure11. Sunspot series prediction relative error.
从图10和图11中可以看出, Att-CNN-LSTM模型在太阳黑子时间序列的预测上仍然具有较好的表现, 能够很好地预测序列的变化趋势, 尽管有部分时间点的预测误差达到了4.7%, 但是总体误差依然保持在较低的水平. 如表3所列, 虽然Att-CNN-LSTM模型在真实数据集上的预测提升不如对Logistic和Lorenz等理论数据集, 但是其预测误差仍低于其他模型. 相比其他预测模型, Att-CNN-LSTM至少降低了19%的RMSE值, 6%的MAE值, 23%的MAPE值和4%的RMSPE值, 预测精度提升依然较为明显. 此外, CNN, LSTM和LSSVM的综合预测性能相差不多, 但是都优于CNN-LSTM模型. 在运行时间方面, 虽然Att-CNN-LSTM模型的训练时间多于其他模型, 但是其预测时间为已低至0.39 s. 综合各模型的预测误差和运行时间分析, 本文提出的模型依然具有较好的预测性能.
2
4.4.讨 论
由4.1—4.3节的实验和分析可知, 本文提出的Att-CNN-LSTM模型在Logistic, Lorenz和太阳黑子三个混沌时间序列上取得了优于其他模型的预测性能. 在Att-CNN-LSTM模型中, CNN模型可以提取混沌时间序列重构相空间下的空间特征, LSTM则根据CNN提取的空间特征提取原时间序列的时空特征, 而注意力模型对CNN-LSTM提取的时空特征进行筛选, 对重要的特征赋予高权重, 并弱化非关键特征, 这对预测精度的提升起到了重要作用. 在混沌时间序列的高维重构相空间内, 混沌系统的内在信息被挖掘出来, 但是并非所有信息都有利于预测, 过多的非关键的信息会影响到预测精度. 原始的混沌时间序列虽然蕴含着混沌系统的时序特征, 但在复杂的混沌系统中, 仅仅依靠时序特征很难获取精度较高的预测结果. 此外, 若同时考虑混沌系统的空间和时间特征, 所涉及的信息和特征会很多, 那些不重要的信息和特征会对预测造成负面影响, 不利于预测精度的提升.实验中发现, Logistic和太阳黑子混沌时间序列拥有较高的相空间展开维度, 其所在的混沌系统较为复杂, 而Lorenz的展开维度相对较低, 其动力系统相对简单. 混合模型CNN-LSTM在高维相空间下的预测精度明显不如单一的CNN和LSTM模型, 但是在低维情况下, CNN-LSTM的预测精度又明显优于单一预测模型, 这说明在复杂的混沌系统下, 过多的信息和非关键特征影响了预测精度, 而注意力模型能够通过提取关键特征解决这些问题, 使得预测精度有所提升, 三个预测实例也很好地证明了本文提出的注意力模型能够提升混合模型CNN-LSTM预测性能.
