1.Advanced Laser Technology Research Center, Hebei University of Technology, Tianjin 300401, China 2.Hebei University of Engineering, Handan 056038, China
Fund Project:Project supported by the National Natural Science Foundation of China (Grant No.11904073), the Natural Science Foundation of Hebei Province, China (Grant No. F2019402351), the Youth Top-notch Project of Hebei Provincial Education Department, China (Grant No. BJ2020028), and the Science and Technology Program of Hebei Province, China (Grant No. 20371802D)
Received Date:28 May 2020
Accepted Date:09 July 2020
Available Online:03 December 2020
Published Online:20 December 2020
Abstract:There is serious noise interference in the decryption process of the joint transform correlator (JTC) optical encryption system, so the quality of the decrypted image cannot meet the accuracy requirements in most cases. The quality of decrypted image can be improved to a certain extent when the phase key is designed by the Gerchberg-Saxton algorithm and the iterative algorithm fuzzy control algorithm, but the complexity of the design process is inevitable and the quality of the decrypted image still needs improving. Recently, the in depth learning technology has attracted the attention of scholars in the fields of computer vision, natural language processing and optical information processing. In order to deal with the noise interference in the JTC optical encryption system, combining the current deep learning method, in this paper we propose a new denoising method for JTC optical image encryption system based on in depth learning, the dense modules are added into the generated network to enhance the reuse of feature information and improve the performance of the network. The latest self-attention mechanism area is added into the network to distinguish the weights of different channels and learn the relationship between channel and channel, so that the network can selectively strengthen the useful feature information but suppress useless feature information. The density module and the channel attention module are integrated into a DCAB synthesis module, which can effectively extract the image feature information and improve the performance of the network. The receptive field of the convolution kernel is enlarged by two down-sampling and the feature map is restored to its original size by two up-sampling. The VGG-19 is used to extract high-frequency details and texture features of images, meanwhile, the non-adversarial loss and mean-square error (MSE) loss are added into the loss function to reduce the difference among the image samples. The quality of noise-reduced images in this method are obviously better than that of the existing denoising algorithms by evaluating intuitive visual observation or SSIM (structural similarity), PSNR (peak signal to noise ratio) and MSE. The results of numerical calculation and simulation experiments show that this method can greatly eliminate the influence of noise on the JTC optical image encryption system, and effectively improve the effectiveness and feasibility of JTC optical image encryption system for high-quality image encryption. Keywords:optical image encryption/ deep learning/ information security/ neural networks/ joint transform correlator
本文提出的深度学习生成对抗网络结构包括生成网络和判别网络两部分. 生成网络主体采用基于编码器和解码器的U-net[15]架构, 包括5个由注意力模块和密集模块组成的密集通道注意力模块(DCAB). 其中注意力模块可以使网络将注意力集中在需要侧重的信息, 从而忽略无用信息, 而密集模块用于减少网络参数和提升网络容量, 以及复用图像样本的特征信息. 密集模块和注意力机制通过残差[16]的方式结合. 同时网络中增加了跳跃连接来弥补因为网络深度增加而导致的梯度弱化问题. 传统深度学习方法平等的对待各通道信息, 会浪费计算资源, 抑制网络的性能, 为了解决这一问题, 使网络自适应的学习到各通道的特征信息, 本文使用注意力机制[17]来对各通道之间关系建模, 增强网络性能, 其通道注意力模块如图4所示. 图 4 通道注意力模块, 其中x表示特征图, c表示特征图(通道)数量, ${w_{\rm{1}}}$和${w_{\rm{2}}}$分别表示降维前后的权重, $\sigma $是sigmod激活函数, $p({x_c})$表示全局池化功能 Figure4. Channel attention (CA), Where x is the feature map, c is the channel, ${w_1}$ and ${w_2}$ are the weight set of low-dimension, $\sigma $ is the sigmod activation function and $p({x_c})$ is global pooling function.





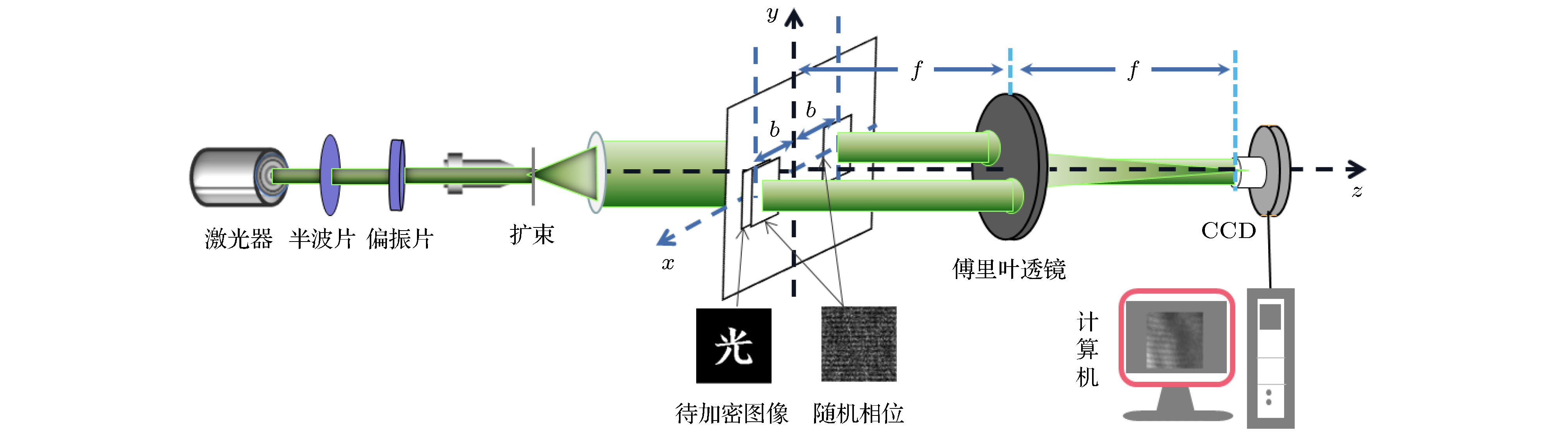 图 1 JTC光学图像加密系统(f是透镜焦距)
图 1 JTC光学图像加密系统(f是透镜焦距)













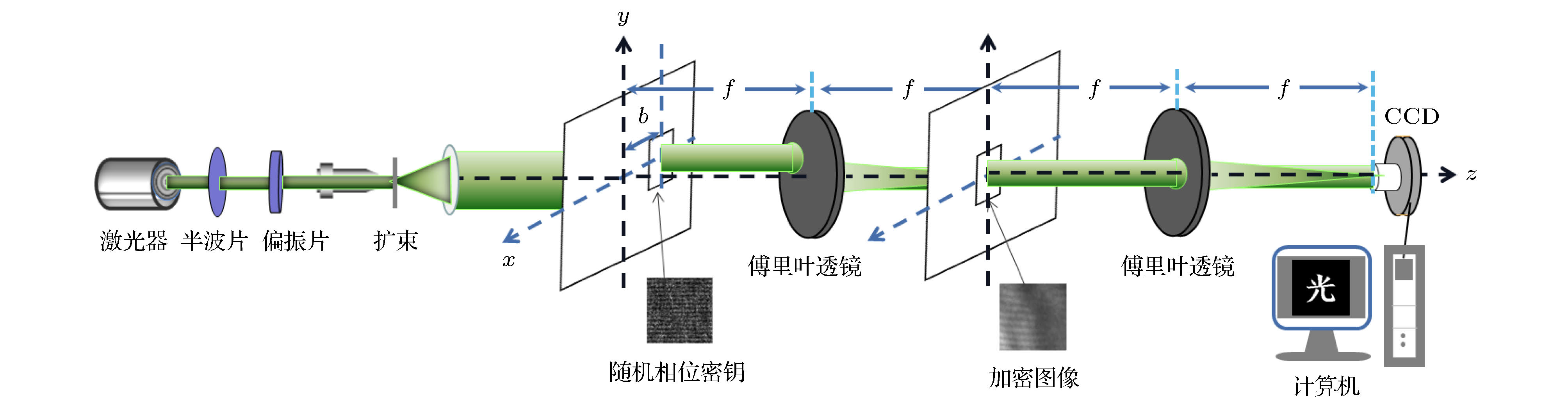 图 2 图像解密光学系统
图 2 图像解密光学系统



 图 3 (a)原始图像; (b)加密图像; (c)解密图像
图 3 (a)原始图像; (b)加密图像; (c)解密图像 图 4 通道注意力模块, 其中x表示特征图, c表示特征图(通道)数量,
图 4 通道注意力模块, 其中x表示特征图, c表示特征图(通道)数量, 














 图 5 密集通道注意力模块
图 5 密集通道注意力模块
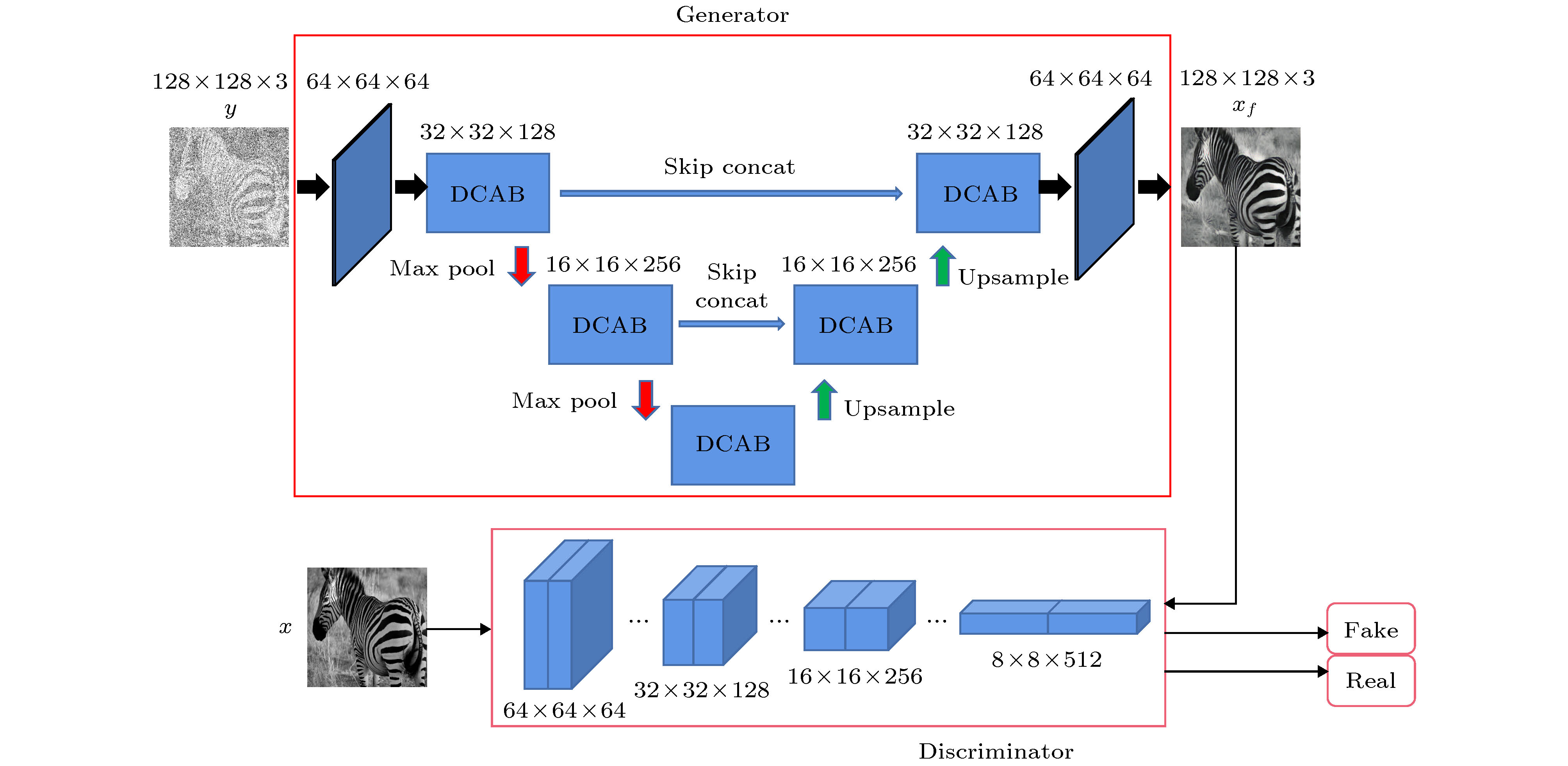 图 6 整体网络结构
图 6 整体网络结构
























 图 7 (a1)?(f1)原始的图像; (a2)?(f2)经过光学加密的噪声图像; (a3)?(f3)本文提出算法去噪图像; (a4)?(f4)为BM3D去噪图像; (a5)?(f5) pix2pix去噪图像
图 7 (a1)?(f1)原始的图像; (a2)?(f2)经过光学加密的噪声图像; (a3)?(f3)本文提出算法去噪图像; (a4)?(f4)为BM3D去噪图像; (a5)?(f5) pix2pix去噪图像