如今,基于给定文本生成图像任务的实现都是基于从大量的图像数据中学习并模拟其数据的分布形式来生成尽可能接近真实的图像,尤其在对抗生成网络(Generative Adversarial Networks, GAN)[2]的火热发展下,借助其来实现文本生成图像的任务已经成为了主流选择,目前也有许多生成效果优秀的模型被提出。在这一研究方面,研究者所关注的重点是如何能够提高生成模型生成图片的真实性、清晰度、多样性、解析度等问题,这些将直接影响生成模型的质量和性能,并关系到生成模型能否有效投入到实际应用当中。
然而如果考虑到实际应用,图像好看,或者有足够的美观度也是一项重要的需求。比如为平面广告设计配图,对图像的要求不仅是清晰、真实,还应该拥有较高的美观度,从而能够吸引人的眼球,提高广告的关注度。可以说,如果能够实现提高此类模型生成图片的美观度,则在实际应用场景中将会给用户带来更加良好的使用体验,从而提高此类应用的质量。遗憾的是,现在对文本生成图像GAN的研究很少关注生成图像的美观质量,现有文献中也并未发现有将美学评判与图像生成相结合的研究,这成为了本文研究的动机。
由此引出另一个问题:如何评判一幅图像的美观度。图像的美观度评判实际上是一项带有主观性质的任务,每个人因不同的阅历、审美观甚至所处环境、情感状态等多方面因素的影响,对同一幅图像有可能会给出完全不同的评价。然而,面对互联网空间与日俱增的图片数量,借助人力对其进行美观度的评价是不切实际的。因此,研究借助计算机进行自动化图像美观度评判成为了计算机视觉领域另一项研究课题,至今也有许多研究者提出了实现原理各异且效果优良的美观度评判模型。借助这些模型,可以对目标图像进行分类或评分,给出尽可能接近符合多数人评价标准的评判结果。
借此,本文致力于研究从美观度的角度对文本生成图像GAN的生成结果进行优化的方法。本文的贡献和创新点如下:
1) 从实际应用的角度出发,将生成结果美观度加入评价文本生成图像GAN模型生成结果的评价指标,以目前受到较高认可度的文本生成图像GAN模型——StackGAN++[3]为基础,从美观度的角度对其生成结果进行评估,以观察其生成结果的美观度质量。
2) 将美观度评判模型融入该GAN的生成模型当中,通过增添美学损失的方式改造生成模型,从而在模型训练过程中加入美学控制因素,引导模型生成美观度更高的结果。本文提出的改进方法使得模型生成图像的总体美学质量(以IS(Inception Score)为评价指标[4])提高了2.68%,其生成图像结果整体的美观度指标提高了3.17%。
1 相关工作 1.1 美观度评判模型 随着网络空间中图片数量的急速增长,在图片检索领域为了能够更好地为用户甄选返回图像的质量、给用户返回更高质量的搜索结果,对图片按美学质量进行分类的需求逐渐增加。图片所附带的数据标签(如喜欢该图的人的数量、图片内容等)可以作为美观度评价的一类较为有效的标准,但大部分的图片并不存在类似这样的标签,虽然如今有许多研究已能够做到给图片准确高效地进行标签标注[5],然而即使每幅图片均被标注了足够用以进行评判的标签,图片庞大的数量又使得人工评判工作量巨大,因此需要能够对图片进行美观度评判的模型,由计算机来完成这一任务。
受到心理学、神经科学等领域中对人类美学感知的研究成果启发,计算机视觉领域的研究者们通过模拟、复现人类处理接收到的图像视觉信息的过程,设计实现了一系列自动评判图片美学质量的模型[6]。图像美观度评判模型一般遵循一个固定的流程:首先对输入图像进行特征提取,然后借助提取的特征,利用训练好的分类或回归算法获得相应的结果。
特征提取则是其中非常重要的一环,因为特征信息是对图像美学质量的概括,其决定了美观度评判模型的精确度。选取得当的特征既能提高模型评判的精确度,又能减少不必要的计算量,因为不同特征对于图像美学质量的贡献度是不同的[7]。早期的研究中,研究者们通常选择以绘画、摄影所用的美学规则理论和人的直观感受为依据,自主设计所要提取的特征,比如清晰度、色调、三分规则等。这类方法的好处是直观、易于理解,但缺点在于所设计的特征通常不能很全面地描述图像美学信息,而且设计特征对于研究者的工程能力和相关领域知识了解程度都有较高的要求。而随着深度学习领域的不断发展,将卷积神经网络(Convolitional Neural Networks, CNN)应用于图像处理这一方式展现出了卓越的效果。借助CNN能够从大量的图像数据中学习到有力的图像特征表示,其所包含的信息量远超人工特征设计所设定的特征[8],从而使得CNN处理图像的方式在图像处理领域得到广泛应用,并逐渐成为主流选择的方法。深度学习方法应用于图像美观度评判的特征提取环节,主要有2种方式:第1种是借助已有的深度学习图像处理模型,利用其中间层特征作为评判依据,采用传统的分类或回归方法进行美观度评判;第2种是对已有的模型进行改造,使得其能够从图像数据中学习到新的隐藏的美学特征,并借此对图像的美观度作出评判。
本文采用的是Kong等[9]设计的美观度评判模型。该模型随AADB(Aesthetics and Attributes Database)数据集一同提出,其基于AlexNet[8]改造得来,通过提取图片的内容特征以及自定义的属性标签特征来帮助判断图像的美观度。此外,该模型吸收了Siamese网络[10]的结构,实现了接收两幅一组的图像作为输入并给出它们之间相对评分的功能,同时提出了2种对图像进行成对采样的训练方式来辅助增加结果的精确度。实验结果表明该模型在AVA(Aesthetic Visual Analysis)数据集上的判别准确率达到77.33%,超过了当时已有的许多模型的表现。作者并未对该模型进行命名,为方便说明,下文中统一用“AADB模型”对其进行代指。
1.2 文本生成图像GAN GAN的提出是机器学习领域一项重大的突破,其为生成模型的训练提供了一种对抗训练的思路。相比于传统的生成模型如变分自编码器、玻尔兹曼机,GAN优势有:其训练只需借助反向传播而不需要马尔可夫链、能够产生全新的样本以及更加真实清晰的结果、简化任务设计思路等,因此,其成为了现今机器学习领域十分火热的研究课题。
GAN的结构一般可分为两部分:生成器部分,负责接收一段随机噪声作为输入来生成一定的结果;判别器部分,负责接收训练数据或生成器生成的数据作为输入,判断输入是来自哪一方。生成器的最终目标是生成能够彻底欺骗判别器的数据,即判别器无法区分输入数据来自真实数据分布还是生成器拟合的数据分布;而判别器的最终目标是有效区分其输入来源,识别出来自生成器的输入。GAN的训练正是基于这种博弈的过程,令生成器和判别器二者之间进行对抗,交替更新参数,当模型最终达到纳什均衡时,生成器即学习到了训练数据的数据分布,产生相应的结果。
虽然GAN拥有良好的表现力和极大的发展潜力,但其本身还存在一些缺点,比如训练困难、无监督使得生成结果缺少限制、模式崩溃、梯度消失等问题。后续许多研究者对GAN从结构[11]、训练方法[12]或实现方法[13]上进行了改进,逐渐提高了GAN训练的稳定性和生成效果。此外,CGAN(Conditional GAN)[14]将条件信息与生成器和判别器的原始输入拼接形成新的输入,用以限制GAN生成和判别的表现,使得GAN生成结果的稳定性得到提高。
利用GAN来实现文本生成图像任务也是基于CGAN的思想,以文本-图像组合为训练数据,文本作为输入数据的一部分, 在生成器中与随机噪声拼接作为生成器的整体输入,在判别器中则用于形成不同的判断组合——真实图片与对应文本、真实图片与不匹配文本、生成器生成图片与任意文本并进行鉴别。文本数据通常会借助其他编码模型将纯文字信息转化为一定维数的文本嵌入向量,用以投入模型的训练计算当中。最先利用GAN实现文本生成图像任务的是Reed等[15]提出的GAN-INT-CLS模型,其吸收了CGAN和DCGAN(Deep Convolutional GAN)[11]的思想,同时提出改进判别器接收的文本-图像组合输入(新增真实图像与不匹配文本的组合)以及通过插值的方式创造新的文本编码向量两种方法来提高生成结果的质量和丰富度,生成了64×64大小的图像。随后该领域的一项重要突破是Zhang等[16]提出的StackGAN模型,该模型通过使用2个生成器的方式生成图像,首次实现了只借助给定文本的条件下生成256×256大小的图像。该模型中,第1个生成器接收随机噪声与文本向量的拼接来生成64×64大小的中间结果,第2个生成器则使用该中间结果与文本向量作为输入,这种方式可以实现利用文本信息对中间结果进行修正和细节补充,来获得质量更高的256×256大小图像的结果。
在StackGAN的理论基础上,Zhang等[3]提出了StackGAN++模型。该模型使用3个生成器-判别器组以类似树状的方式连接,其中3个生成器分别对应生成64×64、128×128、256×256大小的图像,第1个生成器以文本向量和随机噪声的拼接为输出,之后每一个生成器接收前一个生成器生成的图像结果与文本向量作为输入,生成下一阶段的图像结果;每一个判别器接收对应阶段的生成器的输出与文本向量进行判别,计算条件生成损失。此外,Zhang等[3]引入了无条件生成损失,即计算在不使用文本信息的情况下生成图片的损失,与条件生成损失相结合,引导模型的训练,最终进一步提高了生成图片的质量。本文即选用了该模型进行基于美学评判的优化改进研究。
此后文本生成图像GAN的研究多在类似StackGAN++的多阶段生成模式基础上,通过加入各种辅助信息来帮助生成器生成更好的结果,如AttnGAN(Attentional GAN)[17]引入了注意力机制,分析对比生成图像与对应文本之间的特征相似度,并利用对比结果辅助生成器的训练;Cha等[18]则通过引入感知损失的方式,从图像特征层面进行对比来辅助生成器更好地学习到训练数据的分布。
2 StackGAN++的美学质量分析 在提出基于美学评估的对StackGAN++模型的优化方法之前,需要了解该模型目前生成结果的美学质量如何。本节将利用AADB模型对其进行初步测量。
本节实验使用的StackGAN++模型是基于Caltech-UCSD Birds 200鸟类图像数据库2011版训练的鸟类图像生成模型,其测试数据集中包含2 933张图像,每张图像对应10条文本说明,其中文本数据需经过char-CNN-RNN模型编码。Zhang等[3]给出了其模型源码的github地址(https://github.com/hanzhanggit/StackGAN-v2)。
本文实验运行于Ubuntu 16.04操作系统,使用GeForce GTX 1080 Ti显卡进行训练。软件环境方面,本实验利用Adaconda2搭建python2.7虚拟环境,并需要安装Pytorch1.0以及caffe1.0(分别对应StackGAN++以及AADB模型运行所需)。
2.1 测试数据集生成结果的美观度分布 首先针对测试数据集所产生的样本进行美观度评判,观察其分布状况。理论情况下,训练数据集中包含了29 330条语句对应的嵌入向量,经由生成模型后获得29 330张图像结果,实际运行中由于StackGAN++模型所采用的批处理训练策略,最终生成图像数量为29 280张,但从整体数量的规模来看并不影响对于其整体美观度评价的判断。利用AADB模型获得生成图像的美学分数,其分布如图 1所示。
 |
| 图 1 StackGAN++在测试数据集上的美学分数分布 Fig. 1 Distributions of aesthetic score of images generated by StackGAN++ using test dataset |
| 图选项 |
由AADB模型计算得出的美学分数集中于[0, 1]区间,在特殊情况下会超过1。为了便于标注美学分数的分布区间,在绘制区间分布柱状图时,将由AADB模型获取的美学分数(超过1的截断至0.999 9)乘以10,这种表示方法也符合实际生活中人工评判时的常用取值范围选择;在展示降序分布时则直接采用模型输出的结果范围来标注分数坐标轴。图 1(a)表明,原始StackGAN++在测试数据集上生成图像的美学分数集中在5~8的区间段内,占总体的78.6%,其中6~7区间段内的图像数量最多,占整体结果数量的33.9%。而图 1(b)表明,在5~8区间段内,图像的美学分数变化呈现出均匀平缓的变化趋势,并没有出现在某一节点大幅变动的情况。
29 280张生成结果的平均美学分数为0.628 28。根据AADB模型作者给出的评判标准,一张图片的分数超过0.6则可以认为是一张好图片,低于0.4则认为是一张差图片,在两者之间认为是一张一般性质图片,而本文出于后续实验样本划分的考虑,将好图片的下限标准提高至0.65,差图片的上限标准提高至0.5。由此来看,模型的平均结果处于一般质量的区间,说明原模型的整体生成结果从美观度的角度来讲仍然存在可以提升的空间。本文从全部生成结果中选择美学分数最高以及最低的图片各10张的结果,交由真人进行主观评判,其结果均与美学分数表现出对应关系,即认为最高分数的10张图片拥有较高的美观度,而最低分数的10张图片则评价一般或交叉表明AADB模型给出的美学分数对图像美观度的评价能较好地符合人的直观感受。
2.2 固定文本批量生成图像结果的美观度分布 如果想要达成提高生成模型美观度质量的目标,一个简单的想法是,可以对同一条语句,一次性批量生成大量的图片,按美观度模型给出的分数进行降序排序,从中选出分数最高图像作为输出结果,或以分数排序最靠前(分数最高)的一定数量的图像作为输出结果,再交由模型使用者自行判断选择最终的结果。这种方法虽然存在严重的效率问题,但易于实现且非常直观。其中的问题在于确定生成图像的数量,因为随着生成图像数量的增加,其多样性也会随之增加。也更容易出现更多美观度高的图像结果,但进行美观度评判以及排序选择的时间消耗也会随之增加,因此若选择此种做法作为优化方法,需要在生成结果质量以及模型运行效率之间寻求一个平衡点。
基于以上考虑,除对测试集整体进行美观度评判以外,还从中选择一批(实验设定为24)数量的文本输入数据,针对每一条文本数据生成不同数量的图片来观察其美学分数的分布。选择100、200、350、500、750、1 000共6种生成数量,针对选定的文本数据生成对应数量的图像,利用AADB模型计算生成结果的美学分数。图 2展示了其中一条文本的结果。结果表明,美学分数在各个区间的分布状况是相近的,基本不受一次性生成数量的影响。6组结果都表现出生成图像的美学分数集中于5~7的区间内的分布状况,且随着生成数量的增加,高分图像的出现频率也越来越高。表 1展示了6组分布结果中最高分数图像的分数与分数前10高图像的平均分数,表明了一次性生成数量越多,即使是处于高分分段的图像其整体的质量也会得到提高,也验证了本节第一段所述的情况。但面对最高分数的情况,因生成模型会以随机噪声作为输入来生成图像,这导致了其对生成结果的不可控性,所以生成结果会出现一定的扰动,使得最高分图像的分数与生成数量之间并不存在确定的正相关关联性。
 |
| 图 2 原模型输入同一文本在不同生成数量情况下的美学分数分布 Fig. 2 Disrtributions of aesthetic score of images generated by the same text in original model with different generating quantities |
| 图选项 |
表 1 不同生成数量情况下最高分数与前10平均分数 Table 1 Highest aesthetic score and average of top 10 aesthetic score when generating different quantities of images
| 图像生成数量 | 最高分数 | 前10平均分数 |
| 100 | 0.892 8 | 0.769 8 |
| 200 | 0.804 2 | 0.775 3 |
| 350 | 0.845 1 | 0.788 9 |
| 500 | 0.843 9 | 0.797 8 |
| 750 | 0.858 4 | 0.815 5 |
| 1 000 | 0.954 8 | 0.859 2 |
表选项
3 基于美学评判的图像生成优化 原始的StackGAN++模型采用了3组生成器-判别器组合,以类似树状的方式进行连接,每一个生成器生成不同尺寸的图像,并作为下一个生成器输入数据的一部分。其中每一个生成器的损失LGi(i=1, 2, 3)计算式为
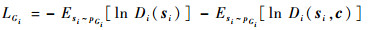 | (1) |
式中:pGi为生成器Gi学习到的数据分布;si为生成器Gi生成的结果;c为文本向量;Di为与生成器Gi对应的判别器,其接收单个输入si或双输入si和c,输出相应的判别结果;E[·]表示期望函数。
该损失计算方式由两部分组成,前一部分计算生成器不利用文本向量生成图像的损失,即无条件损失,该部分用以监督生成器生成更加真实的、使判别器认为来自于真实数据分布的数据;后一部分计算生成器利用了文本向量生成图像的损失,即条件损失,该部分用来监督生成器生成符合输入文本描述的图像,即保证文本与图像之间的一致性。在StackGAN++的理论描述中,Zhang等[3]认为每一个生成器生成的图像虽然大小不同,但都是基于同一条文本生成的,所以它们彼此之间应该保持相似的色彩和基本结构,并提出了色彩一致性损失用来保证3个生成器生成图像之间拥有较高的色彩一致性。但经过实验作者发现在基于文本生成的模式下,色彩一致性所起到的作用十分微弱,因为其对生成结果的约束力要远远小于文本-图像一致性的约束,即式(1)中的Esi~pGi[ln Di(si, c)]。式(2)为生成器的总体损失(下文称为对抗损失)计算公式,用于训练过程中的梯度计算。
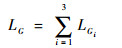 | (2) |
受到Johnson等[19]提出的感知损失的启发,本文将AADB模型与StackGAN++的生成器结合,用于在生成模型训练过程中提供辅助训练信息,达成从美学角度来优化生成模型的目的。具体地,在式(2)的基础上,加入一项新定义的损失——美学损失Laes, 其计算式为
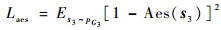 | (3) |
式中:Aes函数表示使用AADB模型计算生成结果s3的美学分数。2.1节中,AADB模型计算得出的美学分数存在超过1的情况,因此在计算美学损失时,会对模型返回的美学分数进行判断,如果其超过了1,则将其截断至0.999 9。该损失实际计算了最后一阶段生成器G3生成结果的美学分数与1之间的欧几里得距离,最小化该损失即最小化生成结果美学分数与1之间的差距,代表了生成结果美学质量的提升。最后,加入了美学损失后新的生成器损失计算公式为
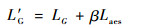 | (4) |
式中:β为美学损失的权重,用来控制其在总体损失中所占的比例,β越大则美学损失所占的比例越大。β为0时,模型即还原为StackGAN++。
由于美学损失的作用是引导生成器生成美观度更高的图像,而对抗损失则是控制整个训练过程以及生成结果的关键,保证了生成器能够生成符合文本描述的真实图像,这是文本生成图像模型最基本的目的,因此β值的选择应当在保证在训练过程中美学损失起到的调控作用不会压过对抗损失的前提下对生成结果的美观度产生影响。
4 实验与性能评估 选取不同的美学损失权重β进行训练,以IS作为训练获得模型的质量的衡量指标,在保证IS与原模型相比不降低的前提下,观察其生成结果的美观度分布情况。IS是借助Inception Model[20]计算得出的用来衡量GAN图像生成效果的最常用指标之一,通常情况下其数值越大代表GAN生成的图像具有更高的多样性和真实性,进而代表生成图像的总体质量更好。在文本生成图像GAN领域,IS被广泛用来进行不同GAN之间的效果对比。
本节所使用的环境与第2节对StackGAN++本身进行美学质量分析的实验环境相同,故此处不再赘述。模型训练过程采用批训练策略,每个批包含24条文本嵌入向量,每一个时期(epoch)中包含368个批的训练过程,下文将一个批完成一次训练的过程称为一步(step)。训练过程包含600个时期,并于每2 000步的时间节点保存一次模型参数,以便于训练完成后根据保存时模型的表现选取效果最好的模型。本文提出的优化方法的实现流程如图 3所示。
 |
| 图 3 基于美学评判的文本生成图像优化方法实现流程 Fig. 3 Procedure of text-to-image synthesis optimization based on aesthetic assessment |
| 图选项 |
本文选取β=45, 0, 0.000 1,分别进行了训练。选择45是因为,观察StackGAN++训练时生成器的对抗损失发现对抗损失与美学损失的比值在50左右。因此,当β = 45时,对抗损失与经权重放大的美学损失在数值上比较接近;1与0.0001是基于经验的选择,取β=1时美学损失与对抗损失平权,而β =0.000 1则是参考了Cha等[18]提出的感知损失的权重选取。训练完成后,对应每个β取值各形成了一组于不同时间节点保存的模型,分别从中选取IS分数最高的模型作为对应取值下的结果模型。在对选定的模型进行美学质量评判之前,需要先考察它们所生成的图片的总体质量,以确保在引入了美学损失后没有出现模型生成图像质量下降的情况。表 2展示了3种取值对应模型与原模型的IS数据,其中β为0即代表未引入美学损失的原始StackGAN++模型。
表 2 不同β取值对应模型的IS Table 2 IS of models using different β
| β | IS |
| 0 | 4.10±0.06 |
| 45 | 4.05±0.03 |
| 1 | 4.13±0.05 |
| 0.000 1 | 4.21±0.03 |
表选项
通过对比,当β=0.000 1时,模型在IS上取得最高的数值,并且超过了原始模型的IS,表明美学损失的引入还起到了提高模型生成效果的正面效应。这是可以理解的,因为当生成器生成了一幅效果很差的图像,例如模糊不清或主体扭曲变形,此时美观度评判模型将会给出较低的分数,使得美学损失增大并导致生成器总损失增大。此外,当β=45时,模型的IS分数降低,表现为生成器生成图像的质量有所下降。对β=45时获得的模型所生成的图像进行人工评判的结果也反映出这时生成图像出现了更多的模糊、失真等不良结果。因此,β=45的情况已无继续讨论的价值,此后美学层面的实验和数据统计也不再考虑此种情况。当β=1时,模型的IS与原模型相比十分接近,还需通过美学分数的分布对比来确定在此情况下美学损失是否起到了优化的作用。
为了验证美学损失是否对生成模型结果的美学质量起到了优化作用,接下来计算了使用β=1,0.000 1这2种情况的模型在测试数据集上生成的29 280张图像的美学分数分布情况;同时针对一个批的24条文本嵌入向量,每条文本生成1 000张图像,计算其美学分数的分布,数据结果如图 4所示(这里选出一条文本生成的1 000张图像的美学分数分布进行展示)。表 3展示了2种β取值下模型在测试数据集上的生成结果的美学分数,同时一并列出了原模型在测试数据集上生成结果的美学分数作为对比。从表中可知,当β=0.000 1时,由测试数据集生成的图像其平均美学分数与原模型相比提高了3.17%;表 4给出了原模型与β=0.000 1优化模型分别生成的24组针对同一条文本的1 000幅图像平均美学分数对比情况,也可以发现大部分文本生成结果的美学分数与原模型的生成结果相比有所提高。同时由图 4所示的美学分数分布情况也能看出,此时高分段图像的数量增加,较低分段图像的数量减少,表明美学损失起到了调控生成结果美观度的作用。图 5展示了原模型与β=0.000 1的优化模型使用4条文本对应生成的1 000张图像中等距抽取10张图像的结果(每个分图第1行为原模型,第2行为优化模型,每个模型对每条文本均生成1 000张图像),每行图像从左到右按美学分数从高到低的顺序排列,从中可以直观感受到,经过美学优化的生成模型所生成的图像结果在色彩对比度、整体色调、背景虚化简单化等方面均有一定优势,反映了其美观评价相比原模型有所提升。
 |
| 图 4 不同β取值情况下测试数据生成结果与选定一条文本的生成结果美学分数分布 Fig. 4 Distributions of aesthetic scores of images generated by models with different β using texts from test dataset and chosen text |
| 图选项 |
表 3 不同β取值对应模型的美学分数对比 Table 3 Comparison of aesthetic scores of models using different β
| β | 测试集平均分数 |
| 0 | 0.628 3 |
| 1 | 0.600 6 |
| 0.000 1 | 0.648 2 |
表选项
表 4 原模型与优化模型使用24条文本生成1 000张图像的平均美学分数对比 Table 4 Comparison of average aesthetic score of 1 000 images generated by original models and optimized models using 24 different texts
| 编号 | 平均美学分数 | 对比提升量 | |
| 原模型 | β= 0.000 1 | ||
| 1 | 0.592 9 | 0.619 2 | +0.026 3 |
| 2 | 0.586 6 | 0.618 0 | +0.031 4 |
| 3 | 0.567 1 | 0.617 0 | +0.049 9 |
| 4 | 0.574 1 | 0.543 3 | -0.030 8 |
| 5 | 0.581 9 | 0.551 5 | -0.030 4 |
| 6 | 0.551 0 | 0.518 8 | -0.032 2 |
| 7 | 0.602 4 | 0.622 1 | +0.019 7 |
| 8 | 0.568 8 | 0.546 7 | -0.022 1 |
| 9 | 0.598 7 | 0.627 9 | +0.029 2 |
| 10 | 0.616 6 | 0.589 0 | -0.027 6 |
| 11 | 0.600 8 | 0.613 8 | +0.013 0 |
| 12 | 0.551 1 | 0.622 7 | +0.071 6 |
| 13 | 0.700 7 | 0.691 3 | -0.009 4 |
| 14 | 0.586 2 | 0.659 6 | +0.073 4 |
| 15 | 0.586 8 | 0.623 2 | +0.036 4 |
| 16 | 0.595 1 | 0.622 7 | +0.027 6 |
| 17 | 0.621 7 | 0.634 5 | +0.012 8 |
| 18 | 0.555 0 | 0.579 2 | +0.024 2 |
| 19 | 0.585 9 | 0.597 4 | +0.011 5 |
| 20 | 0.568 9 | 0.567 3 | -0.001 6 |
| 21 | 0.598 8 | 0.640 5 | +0.041 7 |
| 22 | 0.579 4 | 0.547 7 | -0.031 7 |
| 23 | 0.558 7 | 0.593 0 | +0.034 3 |
| 24 | 0.589 0 | 0.541 9 | -0.047 1 |
表选项
 |
| 图 5 从原模型与优化模型对4条文本各生成的1 000幅图像中等距抽取图像对比 Fig. 5 Comparison of systematic sampling results of images generated by original model and optimized model using 4 chosen texts (1 000 images for each text and each model) |
| 图选项 |
5 结论 本文提出了一种基于美学评判的文本生成图像GAN的优化方法,利用美观度评判模型获得生成器生成图像的美学分数,计算该生成图像的美学损失,与模型本身的对抗损失以适当的权重关系相结合,作为该生成器新的损失并重新训练模型,最后对获得的新模型生成的图像进行了美学质量的统计与和原模型的对比。实验所得结论如下:
1) 经过本文方法获得的生成模型,其生成结果的美观度与原模型相比得到了提升,同时IS分数也有所提高,表明美学损失能够起到提高生成模型质量的作用。
2) 该方法同时也存在一定的局限性:首先,利用本文方法选取的美学损失权重只适用于本文实验所用的鸟类数据集,而如果需要在其他数据集上应用本文方法,除了原始模型需要更换以外,权重的选取也需要全部从头开始,这也与文本生成图像类GAN和美学模型本身的性质有关;其次,权重选取尚未找到一个公式化的方法,都是借助经验来试探性的选择。
未来的工作将分为2个部分,一是基于文中的实验继续调整美学损失的权重,寻找最佳的参数以使得生成结果能进一步提高;二是寻找其他美学损失的计算方式,以使得美学因素能够取得更好的训练调控效果。
致谢 感谢耀萃基金数据智能创新联合实验室(InfleXion Lab)提供的帮助!
参考文献
| [1] | BODNAR C.Text to image synthesis using generative adversarial networks[EB/OL].(2018-05-02)[2019-07-08].https://arxiv.org/abs/1805.00676. |
| [2] | GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al.Generative adversarial nets[C]//Advances in Neural Information Processing Systems.Cambridge: MIT Press, 2014: 2672-2680. |
| [3] | ZHANG H, XU T, LI H, et al.Stackgan++: Realistic image synthesis with stacked generative adversarial networks[EB/OL].(2018-06-28)[2019-07-08].https://arxiv.org/abs/1710.10916. |
| [4] | SALIMANS T, GOODFELLOW I, ZAREMBA W, et al.Improved techniques for training gans[C]//Advances in Neural Information Processing Systems.Cambridge: MIT Press, 2016: 2234-2242. |
| [5] | LI Z, TANG J, MEI T. Deep collaborative embedding for social image understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41(9): 2070-2083. |
| [6] | DENG Y, LOY C C, TANG X. Image aesthetic assessment:An experimental survey[J]. IEEE Signal Processing Magazine, 2017, 34(4): 80-106. DOI:10.1109/MSP.2017.2696576 |
| [7] | DATTA R, JOSHI D, LI J, et al.Studying aesthetics in photographic images using a computational approach[C]//European Conference on Computer Vision.Berlin: Springer, 2006: 288-301. https://rd.springer.com/chapter/10.1007/11744078_23 |
| [8] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E.ImageNet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems.Cambridge: MIT Press, 2012: 1097-1105. https://dl.acm.org/doi/10.5555/2999134.2999257 |
| [9] | KONG S, SHEN X, LIN Z, et al.Photo aesthetics ranking network with attributes and content adaptation[C]//European Conference on Computer Vision.Berlin: Springer, 2016: 662-679. https://link.springer.com/chapter/10.1007%2F978-3-319-46448-0_40 |
| [10] | CHOPRA S, HADSELL R, LECUN Y.Learning a similarity metric discriminatively, with application to face verification[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2005: 539-546. https://dl.acm.org/doi/10.1109/CVPR.2005.202 |
| [11] | RADFORD A, METZ L, CHINTALA S.Unsupervised representation learning with deep convolutional generative adversarial networks[EB/OL].(2016-01-07)[2019-07-08]. https://arxiv.org/abs/1511.06434. |
| [12] | SALIMANS T, GOODFELLOW I, ZAREMBA W, et al.Improved techniques for training gans[C]//Advances in Neural Information Processing Systems.Cambridge: MIT Press, 2016: 2234-2242. |
| [13] | ARJOVSKY M, CHINTALA S, BOTTOU L.Wasserstein gan[EB/OL].(2017-12-06)[2019-07-08].https://arxiv.org/abs/1701.07875. |
| [14] | MIRZA M, OSINDERO S.Conditional generative adversarial nets[EB/OL].(2014-11-06)[2019-07-08].https://arxiv.org/abs/1411.1784. |
| [15] | REED S, AKATA Z, YAN X, et al.Generative adversarial text to image synthesis[EB/OL].(2016-06-05)[2019-07-08].https://arxiv.org/abs/1605.05396. |
| [16] | ZHANG H, XU T, LI H, et al.Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2017: 5907-5915. https://arxiv.org/abs/1612.03242 |
| [17] | XU T, ZHANG P, HUANG Q, et al.Attngan: Fine-grained text to image generation with attentional generative adversarial networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2018: 1316-1324. https://arxiv.org/abs/1711.10485 |
| [18] | CHA M, GWON Y, KUNG H T.Adversarial nets with perceptual losses for text-to-image synthesis[C]//2017 IEEE 27th International Workshop on Machine Learning for Signal Processing (MLSP).Piscataway, NJ: IEEE Press, 2017: 1-6. https://arxiv.org/abs/1708.09321 |
| [19] | JOHNSON J, ALAHI A, LI F.Perceptual losses for real-time style transfer and super-resolution[C]//European Conference on Computer Vision.Berlin: Springer, 2016: 694-711. https://link.springer.com/chapter/10.1007/978-3-319-46475-6_43 |
| [20] | SZEGEDY C, VANHOUCKE V, IOFFE S, et al.Rethinking the inception architecture for computer vision[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 2818-2826. |
