针对图像或视频质量增强,国内外已有不少研究。Dong等[2]设计了减少噪声的卷积神经网络(Artifacts Reduction Convolutional Neural Network, ARCNN),减少了JPEG压缩图像所产生的噪声。之后,Zhang等[3]设计的去噪神经网络(Denoising Convolutional Neural Network, DnCNN),具有较深的网络结构,实现了图像去噪,超分辨率和JPEG图像质量增强。后来,Yang等[4]设计了解码端可伸缩卷积神经网络(Decoder-side Scalable Convolutional Neural Network, DSCNN),该结构由2个子网络组成,分别减少了帧内编码与帧间编码的失真。然而,上述方法都仅利用了图像的空域信息,没有利用相邻帧的时域信息,仍有提升空间。Yang等[5]尝试了一种多帧质量增强(Multi-Frame Quality Enhancement,MFQE)方法,利用空域的低质量当前帧与时域上的高质量相邻帧来增强当前帧。同等条件下,MFQE获得了比空域单帧方法更好的性能。
在视频序列中,尽管帧之间具有相似性,但仍存在一定的运动误差。Yang等[5]所提出的MFQE做法是首先借助光流网络,得到相邻帧与当前待增强帧之间的光流场;然后根据该光流场对相邻帧进行运动补偿,即相邻帧内的像素点,根据光流信息,向当前帧对齐,得到对齐帧;最后,将对齐帧与当前帧一起送入后续的质量增强网络。上述方法能够取得显著增益,但也有一些不足:
1) 视频帧之间的运动位移不一定恰好是整像素,有可能是亚像素位置,一般的做法是通过插值得到亚像素位置的像素值,不可避免地会产生一定误差。也就是说,根据光流信息进行帧间运动补偿的策略存在一定的缺陷。
2) MFQE利用了当前帧前后各一帧图像对当前帧进行增强,增强网络对应的输入为3帧图像,包括当前帧与2个对齐帧。视频序列由连贯图像组成,推测,如果在时域采纳更多帧则会达到更好效果,这就意味着需要根据光流运动补偿产生更多对齐帧,神经网络的复杂度与参数量也会急剧上升,并不利于训练与实现。
考虑到上述问题,本文提出一种基于时空域上下文学习的多帧质量增强方法(STMVE),该方法不再从光流补偿,而是从预测的角度出发,根据时域多帧得到当前帧的预测帧,继而通过该预测帧来提升当前帧的质量。在预测时,在不增加网络参数与复杂度的情况下,充分利用了近距离低质量的2帧图像、远距离高质量的2帧图像,显著提升了性能。
本文的主要贡献如下:
1) 在多帧关联性挖掘方面,与传统的基于光流进行运动补偿的方法不同,STMVE方法根据当前帧的邻近帧,得到当前帧的预测帧。具体地,使用自适应可分离的卷积神经网络(Adaptive Separable Convolutional Neural Network,ASCNN)[6],输入时域邻近图像,通过自适应卷积与运动重采样,得到预测帧。该方法极大地缩短了预处理时间,并且预测图像的质量也得到了明显的改善。
2) 在增强策略方面,提出多重预测的方式,充分利用当前帧的邻近4帧图像。将该4帧图像分为2类:近距离低质量的2帧图像与远距离高质量的2帧图像。这2类图像对当前帧的质量提升各有优势,设计神经网络结构并通过学习来结合其优势,获得更佳性能。
3) 在多帧联合增强方面,提出了一种时空域上下文联合的多帧卷积神经网络(Multi-Frame CNN,MFCNN),该结构采用早期融合的方式,采用一层卷积层将时空域信息融合,而后通过迭代卷积不断增强。整个网络利用全局与局部残差结构,降低了训练难度。
1 相关工作 1.1 基于单帧的图像质量增强 近年来,在提升压缩图像质量方面涌现出大量工作。比如,Park和Kim[7]使用基于卷积神经网络(Convolutional Netural Network, CNN)的方法来替代H.265/HEVC的环路滤波。Jung等[8]使用稀疏编码增强了JPEG压缩图像的质量。近年来,深度学习在提高压缩图像质量方面取得巨大成功。Dong等[2]提出了一个4层的ARCNN,明显提升了JPEG压缩图像的质量。利用JPEG压缩的先验知识以及基于稀疏的双域方法,Wang等[9]提出了深度双域卷积神经网络(Deep Dual-domain Convolutional netural Network, DDCN),提高了JPEG图像的质量。Li等[10]设计了一个20层的卷积神经网络来提高图像质量。最近,Lu等[11]提出了深度卡尔曼滤波网络(Deep Kalman Filtering Network,DKFN)来减少压缩视频所产生的噪声。Dai等[12]设计了一个基于可变滤波器大小的卷积神经网络(Variable-filter-size Residue-learning Convolutional Neural Network, VRCNN),进一步提高了H.265/HEVC压缩视频的质量,取得了一定性能。
上述工作设计了不同的方法,在图像内挖掘了像素之间的关联性,完成了空域单帧的质量增强。由于没有利用相邻帧之间的相似性,这些方法还有进一步提升空间。
1.2 基于多帧图像的超分辨率 基于多帧的超分辨与基于多帧的质量增强问题有相似之处。Tsai等[13]提出了开创性的多帧图像的超分辨率工作,随后在文献[14]中得到了更进一步研究。同时,许多基于多帧的超分辨率方法都采用了基于深度神经网络的方法。例如,Huang等[15]设计了一个双向递归卷积神经网络(Bidirectional Recurrent Convolution Network, BRCN),由于循环神经网络能够较好地对视频序列的时域相关性进行建模,获取了大量有用的时域信息,相较于单帧超分辨率方法,性能得到显著提升。Li和Wang[16]提出了一种运动补偿残差网络(Motion Compensation and Residual Net,MCResNet), 首先使用光流法进行运动估计和运动补偿,然后设计了一个深度残差卷积神经网络结构进行图像质量增强。上述多帧方法所取得的性能超越了同时期的单帧方法。
Yang等[5]提出利用时域和空域信息来完成质量增强任务,设计了一种MFQE的增强策略。首先,利用光流网络产生光流信息,相邻帧在光流信息的引导下,得到与当前待增强帧处于同一时刻的对齐帧;然后,该对齐帧与当前待增强帧一同输入质量增强网络。受上述工作的启发,本文提出了一种更加精准和有效的基于多帧的方法,以进一步提升压缩视频的质量。
2 时空域上下文学习多帧质量增强 如图 1所示,所提方法的整体结构包括预处理部分与质量增强网络。其中,预处理部分采用ASCNN网络,其输入相近多帧重建图像,分别生成关于当前帧的2个预测帧;然后,这2个预测帧与当前帧一起送入质量增强网络,经过卷积神经网络的非线性映射,得到增强后的当前帧。
 |
| 图 1 时空域上下文学习的多帧质量增强方法 Fig. 1 Approach for multi-frame quality enhancement using spatial-temporal context learning |
| 图选项 |
2.1 光流法与ASCNN 挖掘多帧之间关联性的关键是对多帧之间的运动误差进行补偿。光流法是一种常见的方法。本文对光流法与基于预测的ASCNN的计算复杂度与性能进行了对比。
1) 使用光流法进行预处理
f(t-1)→t表示2帧图像(Xt-1d、Xtd,t>1)。首先,通过光流估计网络HFlow得到的光流;然后,对得到光流与Xt-1d进行WARP操作,得到对齐帧Xta;最后,将Xta和Xtd一起送入卷积神经网络,可得到t时刻的质量增强帧。
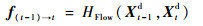 | (1) |
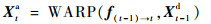 | (2) |
2) 使用ASCNN进行预处理
设Xt-1d与Xt+1d分别为t-1和t+1时刻已经解码得到的重建帧,将该2帧作为ASCNN的输入,得到t时刻的预测帧Pt,1e;同理,将Xt-2d和Xt+2d输入ASCNN,可以得到t时刻的另一个预测帧Pt, 2e,即
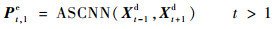 | (3) |
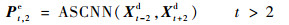 | (4) |
光流法的典型实现是FlowNet[17]。本文选取了4个测试序列,每个序列测试50帧,比较了FlowNet 2.0与ASCNN的时间复杂度,如表 1所示。对于2个网络,分别输入2帧图像,并得到各自的预处理时间。经过预处理,光流法得到2帧对齐图像,ASCNN得到1帧预测帧。值得注意的是,由于FlowNet 2.0网络参数量较大,当显存不足时,每帧图像被分成多块进行处理。从表 1可以看出,FlowNet 2.0的预处理耗时约为ASCNN的10倍。
表 1 光流法(FlowNet 2.0)与ASCNN预处理时间对比 Table 1 Pre-processing time comparison of optical flow method (FlowNet 2.0) and ASCNN
| 序列 | 分辨率 | 预处理时间/s | |
| FlowNet 2.0 | ASCNN | ||
| BQSquare | 416×240 | 255 | 108 |
| PartyScene | 832×480 | 1085 | 111 |
| BQMall | 832×480 | 1144 | 104 |
| Johnny | 1280×720 | 2203 | 116 |
| 平均耗时 | 1172 | 110 | |
表选项
此外,本文对比了上述2种预处理之后分别得到的对齐帧Xta与预测帧Pte的主观质量,如图 2所示(POC表示播放顺序, PSNR表示峰值信噪比),选取了测试序列BasketballDrill的第4、5、6帧来进行说明。图 2(a)为FlowNet 2.0,POC 4向POC 5对齐,得到对齐帧;图 2(b)为FlowNet 2.0,POC 6向POC 5对齐,得到对齐帧;图 2(c)为ASCNN,POC 4和POC 6预测,得到预测帧。由图 2(a)、(b)可见,光流法生成的对齐帧中,“篮球”产生了重影,这是由光流信息不精准造成的,而ASCNN的预测帧弥补了这一缺陷。从其客观指标来看,ASCNN得到的预测帧的PSNR也较高。
 |
| 图 2 光流法(FlowNet 2.0)与ASCNN预处理得到的输出图像的主观图 Fig. 2 Subjective quality comparison of output image preprocessed by optical flow method (FlowNet 2.0) and ASCNN |
| 图选项 |
2.2 多帧质量增强网络 多帧质量增强网络MFCNN的结构如图 3所示,网络结构内部的参数配置如表 2所示。在MFCNN中,HCFEN为粗特征提取网络(Coarse Feature Extraction Network,CFEN),分别用于提取Pt,1e、Xtd和Pt, 2e的空间特征:
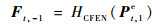 | (5) |
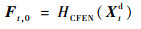 | (6) |
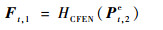 | (7) |
 |
| 图 3 早期融合网络结构及其内部每个残差块的结构 Fig. 3 Structure of proposed early fusion network and structure of each residual block in it |
| 图选项 |
表 2 多帧质量增强网络结构 Table 2 Structure of proposed quality enhancement network
| 卷积层 | 滤波器大小 | 滤波器数量 | 步长 | 激活函数 |
| Conv 1/2/3 | 3×3 | 64 | 1 | Relu |
| Conv 4 | 1×1 | 64 | 1 | Relu |
| 残差块×7 | 1×1 | 64 | 1 | Relu |
| 3×3 | 64 | 1 | Relu | |
| 1×1 | 64 | 1 | Relu | |
| Conv end | 5×5 | 1 | 1 |
表选项
为进一步利用Pt,1e和Pt,2e的时域特征信息,将Ft,-1、Ft,0和Ft,1特征级联,得
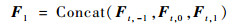 | (8) |
然后,送入Conv 4,将所级联的特征进一步融合,同时使用1×1大小的卷积核来降该层的参数量:
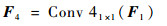 | (9) |
最后,经过7个残差网络[18]的残差块,得到特征矩阵为F7。在MFCNN的最后输出层,加入Xtd形成全局残差学习结构:
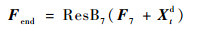 | (10) |
在训练该网络时,对于给定的一个训练集{(Pt,1e, (i), Xtd, (i), Pt,2e, (i)), Y(i)}i=1N, N为训练集中训练数据的个数,Y(i)为原始图像,定义损失函数:
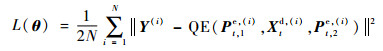 | (11) |
式中:θ为权重参数的集合;QE(Pt,1e, (i), Xtd, (i), Pt,2e, (i))为所获得的质量增强之后的图像。训练中,通过小批量梯度下降算法和反向传播来优化目标方程。
3 实验结果与分析 3.1 实验条件 本文的训练与测试环境为i7-8700K CPU和Nvidia GeForce GTX 1080 TI GPU。所有实验都基于TensorFlow深度学习框架。本文使用118个视频序列来训练神经网络,并在11个H.265/HEVC标准测试序列进行测试。每个序列都使用HM16.9在Random-Access(RA)配置下图像组(Group of Pictures,GOP)大小设置为8,量化参数分别设置为22、27、32、37,并获得重建视频序列。
3.2 实验结果比较与分析 1) 与传统光流法的对比
本文采用基于早期融合的质量增强网络结构,对5种预处理方法的性能进行了对比,以图 4所示的第2帧图像为例,包括:
 |
| 图 4 以图像组为单位对低质量图像进行增强 Fig. 4 Enhancing low-quality images for each GOP |
| 图选项 |
① 使用光流法对前后t±2帧进行运动补偿,分别得到对齐帧,利用两帧对齐帧对当前帧进行增强。
② 使用ASCNN利用前后t±2帧预测当前帧,利用该预测帧对当前帧进行增强。
③ 结合①与②,利用两帧对齐帧与一帧预测帧对当前帧进行增强。
④ 使用光流法对前后t±2帧进行运动补偿,分别得到对齐帧,使用ASCNN利用前后t± 1帧预测当前帧,利用两帧对齐帧与一帧预测帧对当前帧进行增强。
⑤ 使用ASCNN,分别利用前后t±1与t±2帧预测当前帧,根据所得到的两帧预测帧对当前帧进行增强。
表 3给出了上述几种方法的性能对比,其中t+n代表与t时刻相隔n帧。可见,使用ASCNN,将2对相邻帧生成当前时刻的2个预测帧的方式,取得了最优的性能。
表 3 5种预处理方式所获得的PSNR性能指标对比 Table 3 PSNR performance indicator comparison by five pre-processing strategies ?
| 序列 | H.265/HEVC | FlowNet 2.0(t-2, t+2) | ASCNN(t-2, t+2) | FlowNet 2.0(t-2, t+2)+ASCNN (t-2, t+2) | FlowNet 2.0(t-2, t+2)+ASCNN (t-1, t+1) | ASCNN(t-2, t+2)+ASCNN(t-1, t+1) |
| BQMall | 31.00 | 31.35 | 31.38 | 31.20 | 31.23 | 31.46 |
| BasketballDrill | 31.94 | 32.35 | 32.32 | 32.16 | 32.19 | 32.39 |
| FourPeople | 35.59 | 36.23 | 36.20 | 36.00 | 36.04 | 36.32 |
| BQSquare | 29.21 | 29.59 | 29.62 | 29.32 | 29.35 | 29.65 |
| 平均值 | 31.94 | 32.38 | 32.38 | 32.17 | 32.20 | 32.46 |
表选项
2) 与不同网络结构的对比
本文设计了多种形态的网络结构,并对其性能进行了对比。如图 5所示,分别设计了直接融合、渐进融合2种方式,并与本文的早期融合进行了对比。
 |
| 图 5 直接融合网络和渐进融合网络与所提出的早期融合网络的对比 Fig. 5 Comparison of direct fusion networks and slow fusion networks with proposed early fusion networks |
| 图选项 |
3种结构的区别在于,直接融合方法直接将多帧信息级联作为网络输入,渐进融合方法逐渐地级联卷积特征图。将这3种结构设计成具有相近的参数量,实验结果如表 4所示。可见,渐进融合比直接融合的性能平均提高了0.03dB,而早期融合比渐进融合又能够提升0.04dB。
表 4 三种网络结构的PSNR性能指标对比 Table 4 PSNR performance indicator comparison of three network structures ?
| 测试序列 | 直接融合 | 渐进融合 | 早期融合 |
| BQMall | 31.39 | 31.42 | 31.46 |
| BasketballDrill | 32.32 | 32.35 | 32.39 |
| RaceHousesC | 29.36 | 29.38 | 29.41 |
| 平均值 | 31.02 | 31.05 | 31.09 |
表选项
该实验证明了对每个输入帧使用更多独立滤波器,可以更好地甄别当前帧与预测帧的重要性。但随着网络深度的增加,渐进融合方法会引入更多参数。因此,相同等参数量的情况下,与早期融合方法相比,渐进融合网络深度较浅,很可能产生欠拟合问题,无法达到同等性能。
3) 与单帧质量增强方法的对比
采用ASCNN,分别对前后帧进行预测,具体地,分别使用ASCNN利用前后距离近质量低的两帧图像(如图 4的第1帧与第3帧)、前后距离远质量高的两帧图像(如图 4的第0帧与第4帧),得到当前帧的两帧预测帧,这两帧预测帧与当前帧一起送入所提出的早期融合网络,得到最终增强的图像。
如表 5所示,本文所提出的STMVE始终优于仅使用空域信息的单帧质量增强方法。具体地,相较于H.265/HEVC,STMVE在量化参数为37、32、27、22分别取得了0.47、0.43、0.38、0.28dB的增益,相较于单帧质量增强方法,分别获得0.16、0.15、0.15和0.11dB的性能增益。
表 5 不同方法的PSNR性能指标对比 Table 5 Comparison of PSNR performance indicator among different methods?
| 量化参数 | 类别 | 测试序列 | H.265/HEVC | 单帧质量增强 | STMVE方法 | 相对单帧的提升 | 相对H.265/HEVC的提升 |
| 37 | C | BasketballDrill | 31.94 | 32.14 | 32.39 | 0.25 | 0.45 |
| BQMall | 31.00 | 31.17 | 31.46 | 0.29 | 0.46 | ||
| PartyScene | 27.73 | 27.73 | 27.94 | 0.21 | 0.21 | ||
| RaceHorses | 29.08 | 29.23 | 29.41 | 0.18 | 0.33 | ||
| D | BasketballPass | 31.79 | 32.02 | 32.37 | 0.35 | 0.58 | |
| BlowingBubbles | 29.19 | 29.30 | 29.51 | 0.21 | 0.32 | ||
| BQSquare | 29.21 | 29.28 | 29.65 | 0.37 | 0.44 | ||
| RaceHorses | 28.69 | 28.93 | 29.18 | 0.25 | 0.49 | ||
| E | FourPeople | 35.59 | 36.03 | 36.32 | 0.29 | 0.73 | |
| Johnny | 37.34 | 37.61 | 37.80 | 0.19 | 0.46 | ||
| KristenAndSara | 36.77 | 37.21 | 37.43 | 0.22 | 0.66 | ||
| 平均值 | 31.67 | 31.97 | 32.13 | 0.16 | 0.47 | ||
| 32 | 平均值 | 34.31 | 34.59 | 34.74 | 0.15 | 0.43 | |
| 27 | 平均值 | 37.06 | 37.28 | 37.43 | 0.15 | 0.38 | |
| 22 | 平均值 | 39.89 | 40.06 | 40.17 | 0.11 | 0.28 |
表选项
4) 与多帧质量增强方法的对比
本文也与MFQE的结果进行了对比,结果如表 6所示,其中,ΔPSNR代表STMVE与MFQE的PSNR之差。随机选取了4个测试序列,在量化参数为37时,测试其前36帧。结果表明,所提出的STMVE方法平均比MFQE高出0.17dB。在参数数量上,MFQE的参数量约为1715360,而STMVE的参数量为362176,仅为MFQE的21%。可见,所提出的网络虽然具有较少参数,但仍获得了较高性能。
表 6 STMVE方法与MFQE的PSNR性能指标对比 Table 6 PSNR performance indicator comparison between proposed method and MFQE?
| 测试序列(36帧) | MFQE | STMVE方法 | ΔPSNR |
| PartyScene | 26.95 | 27.39 | 0.44 |
| BQMall | 30.39 | 30.64 | 0.25 |
| Johnny | 36.84 | 36.87 | 0.03 |
| BlowingBubbles | 28.97 | 28.93 | 0.04 |
| 平均值 | 30.79 | 30.96 | 0.17 |
表选项
5) 主观质量对比
本文还比较了经不同方法处理后得到的图像的主观质量,如图 6所示。经观察可见,与H.265/HEVC和单帧质量增强方法相比,所提出的STMVE方法能够明显改善图像的主观质量,图像的细节被更好地保留下来,主观质量提升明显。
 |
| 图 6 不同方法获得图像的主观质量对比 Fig. 6 Subjective quality comparison of reconstructed pictures enhanced by different methods |
| 图选项 |
4 结论 本文提出了一种时空域上下文学习的多帧质量增强方法基于STMVE。与以往基于单帧质量增强的方法不同,STMVE方法充分利用了当前帧的邻近4帧图像的时域信息。与传统的基于光流法的运动补偿方式不同,本文提出了利用预测帧增强当前帧的质量;为充分挖掘时域信息,提出了多帧增强的早期渐进融合式网络结构。其次,针对所提出的STMVE方法,分别就预处理方式、网络组合结构、质量增强方法及主观质量进行了分析,并设计实验与以往方法进行了对比。大量的实验结果表明,与其他方法相比,本文所提出的STMVE方法在主观质量与客观质量上都有显著优势。
参考文献
| [1] | CISCO.Cisco visual networking index: Global mobile data traffic forecast update[EB/OL]. (2019-02-18)[2019-07-08]. https://www.cisco.com/c/en/us/solutions/collateral/service-provider/visual-networking-index-vni/white-paper-c11-738429.html. |
| [2] | DONG C, DENG Y, CHANGE LOY C, et al.Compression artifacts reduction by a deep convolutional network[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2015: 576-584. |
| [3] | ZHANG K, ZUO W, CHEN Y, et al. Beyond a Gaussian denoiser:Residual learning of deep CNN for image denoising[J]. IEEE Transactions on Image Processing, 2017, 26(7): 3142-3155. DOI:10.1109/TIP.2017.2662206 |
| [4] | YANG R, XU M, WANG Z.Decoder-side HEVC quality enhancement with scalable convolutional neural network[C]//2017 IEEE International Conference on Multimedia and Expo(ICME).Piscataway, NJ: IEEE Press, 2017: 817-822. |
| [5] | YANG R, XU M, WANG Z, et al.Multi-frame quality enhancement for compressed video[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2018: 6664-6673. |
| [6] | NIKLAUS S, MAI L, LIU F.Video frame interpolation via adaptive separable convolution[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2017: 261-270. |
| [7] | PARK W S, KIM M.CNN-based in-loop filtering for coding efficiency improvement[C]//2016 IEEE 12th Image, Video, and Multidimensional Signal Processing Workshop(IVMSP), 2016: 1-5. |
| [8] | JUNG C, JIAO L, QI H, et al. Image deblocking via sparse representation[J]. Signal Processing:Image Communication, 2012, 27(6): 663-677. DOI:10.1016/j.image.2012.03.002 |
| [9] | WANG Z, LIU D, CHANG S, et al.D3: Deep dual-domain based fast restoration of jpeg-compressed images[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 2764-2772. |
| [10] | LI K, BARE B, YAN B.An efficient deep convolutional neural networks model for compressed image deblocking[C]//2017 IEEE International Conference on Multimedia and Expo (ICME).Piscataway, NJ: IEEE Press, 2017: 1320-1325. |
| [11] | LU G, OUYANG W, XU D, et al.Deep Kalman filtering network for video compression artifact reduction[C]//Proceedings of the European Conference on Computer Vision (ECCV).Berlin: Springer, 2018: 568-584. |
| [12] | DAI Y, LIU D, WU F.A convolutional neural network approach for post-processing in HEVC intra coding[C]//International Conference on Multimedia Modeling.Berlin: Springer, 2017: 28-39. |
| [13] | TSAI R. Multiframe image restoration and registration[J]. Advance Computer Visual and Image Processing, 1984, 11(2): 317-339. |
| [14] | PARK S C, PARK M K, KANG M G. Super-resolution image reconstruction:A technical overview[J]. IEEE Signal Processing Magazine, 2003, 20(3): 21-36. DOI:10.1109/MSP.2003.1203207 |
| [15] | HUANG Y, WANG W, WANG L. Video super-resolution via bidirectional recurrent convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 1015-1028. DOI:10.1109/TPAMI.2017.2701380 |
| [16] | LI D, WANG Z. Video superresolution via motion compensation and deep residual learning[J]. IEEE Transactions on Computational Imaging, 2017, 3(4): 749-762. DOI:10.1109/TCI.2017.2671360 |
| [17] | ILG E, MAYER N, SAIKIA T, et al.FlowNet 2.0: Evolution of optical flow estimation with deep networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 2462-2470. |
| [18] | HE K, ZHANG X, REN S, et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 770-778. |
