近年来,卷积神经网络(Convolutional Neural Network,CNN)[16]在图像领域有很好的表现。其中,OverFeat[17]获得了极具竞争力的结果,其运用卷积网络有效实现了一个多尺寸输入的滑动窗口方法,可用于图像分类、目标定位和检测任务。基于CNN善于学习图像高层次特征的特点,科研人员希望利用CNN将航拍图像定位问题转化为图像分类问题,利用飞行区域的全部信息训练卷积网络,对航拍图像直接进行分类。本文将航拍图像定位问题转化为了一种图像分类问题,基于AlexNet提出了一个融合显著性特征的全卷积网络模型,同时自行制作了航拍图像数据集,提出一种邻域显著性参照定位策略来筛选分类结果,从而实现多尺寸航拍图像的定位。实验结果表明,本文模型提取图像特征的能力好于传统方法。同时,多尺寸航拍图像定位实验验证了本文方法的准确率。
1 多通道全卷积网络模型 本文在AlexNet[12]的基础上进行网络结构的改进,设计了一种基于特征融合的多通道全卷积网络模型,称为multi-channel AlexNet-FCN,其是有效支持多尺寸输入的滑动窗口分类器。
1.1 AlexNet-FCN AlexNet规定输入图像大小为224×224,当输入更大尺寸的图片时,网络会先将输入图片尺寸调整成规定大小。为了适应多尺寸输入,本文使用类似OverFeat[18]的方法,将AlexNet转换为全卷积形式的AlexNet,称为AlexNet-FCN,使其变为一个可以输入任意的不小于规定大小图像的滑动窗口分类器。
1.2 FCN的滑动窗口形式 全卷积网络在以滑动方式应用时本质上是高效的,因为窗口自然地共享重叠区域上共有的计算。对于AlexNet-FCN,滑动窗口大小为224×224,滑动窗口步长为32。
输入一张256×256大小的图像时,输出是一个N(类别个数)个通道的2×2大小的类别得分矩阵,如图 1所示。相当于在图像的垂直方向和水平方向上各进行2次滑窗,每个窗口分别映射到输入图像中的一个224×224大小的区域。
 |
| 图 1 FCN滑动窗口形式 Fig. 1 FCN sliding window |
| 图选项 |
1.3 显著性特征图突出稀疏的显著性区域 航拍图像含有大量的不显著特征,而不显著特征在不同航拍区域中可能差异很小,将稀疏的显著性区域突出为前景有助于提取可区别的特征。使用Image Signature[14]来标记航拍图像中稀疏的显著性区域,并生成显著性特征图(见图 2),用以进行后续的特征融合。
 |
| 图 2 航拍图像的显著性特征图 Fig. 2 Saliency feature map of aerial image |
| 图选项 |
1.4 multi-channel AlexNet-FCN结构 基于特征融合的思想,本文提出了一种称为multi-channel AlexNet-FCN的多通道特征融合CNN模型,结构如图 3所示。原始RGB航拍图像与其单通道特征图(本文使用Image Signature[14]生成显著性特征图)组合为一个四通道的输入层,经过卷积核为1×1的卷积层进行降维,将降维后的三通道特征图输入AlexNet-FCN。
 |
| 图 3 Multi-channel AlexNet-FCN示意图 Fig. 3 Schematic diagram of multi-channel AlexNet-FCN |
| 图选项 |
2 邻域显著性参照定位方法 针对包含多网格区域的航拍图像,本文提出了一种多尺寸图像定位方法,称为邻域显著性参照定位方法。
由于航拍图像中区域的连续性,一个正确预测的区域类别,其周围也应该存在正确预测的区域。基于邻域参照的思想,某个被预测区域的相邻区域的显著性越强,可以判断此区域越可能是正确的预测。因此本文提出了一种基于联通区域分析(connected-component analysis)和最大投票(majority vote)思想的邻域显著性参照定位方法,通过区域及其邻域信息来筛选分类结果,从而提高航拍图像定位的准确性,其主要包括4个步骤:类别得票数统计、区域显著性权重计算、预测概率邻域显著性参照加强和联通区域分析。
2.1 类别得票数统计 对于全卷积网络输出的类别得分图(class score map),将每个位置的所有通道中得分最高且大于阈值的类别作为一个预测分类结果。统计由类别得分图得到的所有分类结果,得到输入图像可能包含的若干个区域的类别及个数,并用一个表示网格区域类别间的真实位置关系的投票矩阵(vote map)来描述,投票矩阵中每个位置的值等于该位置所代表的区域类别的预测个数,未被预测的类别值为0。
2.2 区域显著性权重计算 为得到所有网格区域的显著性权重,先将恰好包含所有网格区域的航拍图像混合显著性特征图(Image Signature[14])输入训练好的multi-channel AlexNet-FCN,得到投票矩阵。由于越显著的区域越容易被识别,而投票矩阵描述了每个区域的判别个数,可以认为投票矩阵中每个位置的值表示了该区域的显著性高低,因此本文提出了一种区域显著性权重计算方法:
 | (1) |
式中:?(x,y,i,j)∈vote map代表网格区域中的一个位置; vi,j为区域判别个数;wi,j为计算显著性权重。
由此得到所有网格区域的显著性权重矩阵(saliency weight map),其大小与投票矩阵相同。一个如图 4(a)所示的投票矩阵的三维曲面图,得到的显著性权重矩阵如图 4(b)所示。其中,x、y代表相对位置,在投票矩阵中,z轴为投票矩阵中该位置所代表的区域类别的预测个数,显著性权重矩阵中z轴为显著性权重。
 |
| 图 4 三维曲面样例 Fig. 4 3D surface sample diagram |
| 图选项 |
2.3 预测概率邻域显著性参照加强 测试时,将大于224×224的航拍图像混合显著性特征输入训练好的网络,得到输入类别得分图及投票矩阵,已知投票矩阵中每个位置代表一个区域,对于任意区域,其预测概率为
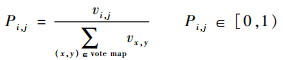 | (2) |
式中:Pi,j为预测概率。对每个位置(i,j)∈vote map(见图 5),有8个邻域,组成邻域预测概率的集合为:Gi,j={Pi-1,j-1,Pi-1,j,Pi-1,j+1,Pi,j-1,Pi,j,Pi,j+1,Pi+1,j-1,Pi+1,j,Pi+1,j+1}。2.2节中得到的领域显著性权重:Si,j={Wi-1,j-1,Wi-1,j,Wi-1,j+1,Wi, j-1,Wi,j,Wi,j+1,Wi+1,j-1,Wi+1,j,Wi+1,j+1},其中不在投票矩阵中的邻域的概率和显著性权重均设置为0。
 |
| 图 5 显著性权重示意图 Fig. 5 Schematic diagram of saliency weight |
| 图选项 |
对?(i,j)∈vote map,根据该位置及其8个邻域的预测概率,以及显著性权重,计算其加强概率为
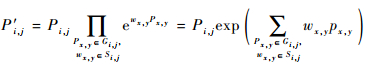 | (3) |
标准化后得到
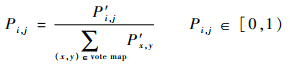 | (4) |
为加强概率。
2.4 联通区域分析 已知概率矩阵中所有不为0的位置组成若干连通区域,由于航拍图像中区域相邻的特性,可以认为概率矩阵中拥有最大概率和的连通区域所包含位置的类别即为输入航拍图像的定位结果,并且按照联通区域中每个区域的概率高低排列定位结果的优先级,概率越高优先级越高。若不存在唯一的拥有最大概率和的连通区域,则对概率矩阵反复进行邻域显著性参照加强,直到得到唯一连通区域。
例如,一个概率矩阵的热力图如图 6所示。其中,x、y轴表示相对位置,z轴表示热力值,热力值越高且越聚集的位置可判断为预测正确的区域,即拥有最大概率,可得按照概率降序的定位结果为{12×15, 11×15, 12×17, 12×16, 11×16, 11×17, 10×15}。
 |
| 图 6 概率矩阵热力图 Fig. 6 Heat map of probability matrix |
| 图选项 |
3 实验与结果分析 3.1 数据准备 本文从Google Earth软件获取了黑龙江省哈尔滨市地区某2个不同时间下的卫星图像作为航拍数据,区域范围如图 7所示。将图像划分为37×27(行×列)个大小相同的正方形网格区域,每个区域图片像素值为256×256。为了后续数据增强的需要,去掉最外层网格后共得到35×25张图片,作为要分类的875类区域,每一类图片用其所在行列号标记。
 |
| 图 7 哈尔滨市的航拍图像 Fig. 7 Aerial image of Harbin |
| 图选项 |
本文采用了一种填充周围真实区域的旋转方法对图像进行随机旋转,同时对图像进行一定范围内的随机颜色抖动,以及对图像进行一定范围内的高斯模糊和椒盐噪声,用以增强数据并模拟真实环境。
通过以上方法,将每类数据的数量增加到500张,得到875类区域的数据共437 500张,其中训练集、验证集、测试集比例为8:1:1。
3.2 单尺寸训练与对比实验 采用3.1节中的数据集作为训练集,网络定义输入大小为224×224,当训练时输入大于定义的图片时,先将输入图片做224×224的随机裁剪。本文训练集大小为256×256,经过随机裁剪后进行训练,可以增强网络对局部图像信息的分类能力,提高准确率。本文在单尺寸下分别训练了AlexNet-FCN和multi-channel AlexNet-FCN,在训练multi-channel AlexNet-FCN时,分别混合Hog[19]和LBP[19]特征作为网络的输入。
为了验证第2节设计训练的卷积网络对单一网格图像的分类能力,并与传统方法进行对比,本文从Google Earth上再次获取了3.1节中地区的另一时间的卫星图像,并划分为同样的875个网格图像,将每个网格图像进行一次随机旋转来模拟某时间下无人机飞行时的航拍图像。将旋转后的875张图像作为查询图像集,将3.1节中875类内部数据的原始网格图像作为标准图像集,这样每张查询图像都与某两张标准图像所属类别相同。分别将查询图像集输入训练好的AlexNet-FCN和multi-channel AlexNet-FCN,得到每张查询图像输出的类别得分图,其中数值越大的类别越可能是该查询图像的所属类别。对每张标准图像和查询图像分别用具有旋转不变性的SIFT[7]、SURF[8]、ORB[9]提取特征,并计算每张查询图像与标准图像的相似度,相似度越高代表两张图像越相近,越可能是同一类别。统计得到查询图像集的准确率如表 1所示,可知使用CNN对单一网格图像进行分类的效果远好于传统特征,且CNN对每张航拍图像的平均处理速度远快于传统方法;在CNN模型中,混合显著性特征的multi-channel AlexNet-FCN具有最好的分类效果,其准确率达到了95.4%。
表 1 查询图像集准确率 Table 1 Query image set accuracy
| 方法 | 输入 | 准确率/% | 所用环境 | 平均运行时间/s |
| AlexNet-FCN | RGB | 94.1 | 0.017 | |
| multi-channel AlexNet-FCN | RGB+显著特征 RGB+HOG RGB+LBP | 95.4 94.6 94.2 | GPU: Titan X Pytorch | 0.022 0.191 0.034 |
| SIFT SURF ORB | RGB | 63.3 73.6 61.9 | CPU: E5-2670 | 37.865 31.25 44.586 |
表选项
在查询图像集中随机选取10类区域,并分别旋转50个角度来模拟飞行时采集的航拍图像,作为表 1中4种全卷积网络的输入,4个全卷积网络模型的ROC曲线如图 8所示。分类器越靠近左上方,性能越好,可以看出multi-channel AlexNet-FCN效果最好。
 |
| 图 8 ROC曲线 Fig. 8 ROC curves |
| 图选项 |
3.3 多尺寸航拍图像定位实验 为了验证本文方法对多尺寸航拍图像的定位能力,对使用邻域显著性参照定位策略和不使用邻域显著性参照定位策略2种方法进行了对比实验。
召回率和准确率是2种常用的精度指标。准确率即正确的正例的数量与被归类为正例的数量的比,其值越高则代表定位识别率越精准。召回率也称查全率,是真正例数与真正例、假反例数之和的比值,该值越高则代表识别结果查全效果越好。二者共同反映了识别的效果。
本文从Google Earth上获取了图 7所示区域的另一时间的卫星图像,通过第2节的方法得到投票矩阵。使用邻域显著性参照定位策略得到概率矩阵,对概率矩阵进行基于最大投票的连通区域分析。分别取每张测试图像定位结果中优先级最高的k个类别作为识别结果,对于图像所包含的占整个网格区域某个比例范围的若干区域,分别计算其准确率与召回率,其中k的最大值为测试图像能包含的完整网格区域的最大个数。分别截取512×512大小和768×768大小的测试集,当阈值为0.99时,2种方法得到的top-k下的平均准确率如表 2和表 3所示,平均召回率如表 4和表 5所示。
表 2 航拍图像为512×512大小时top-k下的准确率 Table 2 Accuracy at top-k when aerial image size is 512×512
| 是否使用邻域显著性参照定位 | 区域所占完整网格比例/% | 准确率/% | |||
| k=1 | k=2 | k=3 | k=4 | ||
| 否 | 100 | 67.3 | 39.5 | 26.6 | 19.9 |
| ≥80 | 81.2 | 68.1 | 49.3 | 38.0 | |
| ≥60 | 83.9 | 74.1 | 56.0 | 43.6 | |
| ≥40 | 85.1 | 76.0 | 58.3 | 45.5 | |
| ≥20 | 85.6 | 77.1 | 59.8 | 46.7 | |
| ≥0 | 86.1 | 77.9 | 61.1 | 47.9 | |
| 是 | 100 | 69.4 | 40.1 | 27.0 | 20.3 |
| ≥80 | 83.1 | 69.0 | 49.9 | 38.2 | |
| ≥60 | 85.3 | 75.0 | 56.7 | 44.0 | |
| ≥40 | 86.3 | 77.0 | 59.0 | 45.8 | |
| ≥20 | 86.7 | 77.8 | 60.4 | 47.1 | |
| ≥0 | 87.1 | 78.5 | 61.6 | 48.3 | |
表选项
表 3 航拍图像为768×768大小时top-k下的准确率 Table 3 Accuracy at top-k when aerial image size is 768×768
| 是否使用邻域显著性参照定位 | 区域所占完整网格比例/% | 准确率/% | |||
| k=1 | k=2 | k=3 | k=4 | ||
| 否 | 100 | 65.7 | 62.1 | 59.6 | 55.4 |
| ≥80 | 94.6 | 93.3 | 91.3 | 88.2 | |
| ≥60 | 95.7 | 94.9 | 93.3 | 90.5 | |
| ≥40 | 96.8 | 95.8 | 94.3 | 91.7 | |
| ≥20 | 97.2 | 96.2 | 94.8 | 92.3 | |
| ≥0 | 97.6 | 96.6 | 95.3 | 93.2 | |
| 是 | 100 | 68.8 | 65.8 | 57.5 | 51.0 |
| ≥80 | 95.7 | 94.2 | 89.2 | 84.3 | |
| ≥60 | 96.6 | 95.7 | 91.3 | 87.4 | |
| ≥40 | 97.6 | 96.5 | 92.4 | 88.8 | |
| ≥20 | 97.8 | 96.7 | 92.8 | 89.6 | |
| ≥0 | 98.1 | 97.1 | 93.5 | 90.0 | |
表选项
表 4 航拍图像为512×512大小时top-k下的召回率 Table 4 Recall rate at top-k when aerial image size is 512×512
| 是否使用邻域显著性参照定位 | 区域所占完整网格比例/% | 召回率/% | |||
| k=1 | k=2 | k=3 | k=4 | ||
| 否 | 100 | 67.3 | 79.1 | 79.8 | 79.8 |
| ≥80 | 46.1 | 72.3 | 76.9 | 78.2 | |
| ≥60 | 29.7 | 51.3 | 57.1 | 58.9 | |
| ≥40 | 20.0 | 35.8 | 41.3 | 43.0 | |
| ≥20 | 14.8 | 26.8 | 31.6 | 33.1 | |
| ≥0 | 8.6 | 15.5 | 18.2 | 19.0 | |
| 是 | 100 | 69.4 | 80.3 | 81.1 | 81.1 |
| ≥80 | 47.2 | 73.4 | 77.9 | 78.9 | |
| ≥60 | 30.1 | 51.8 | 57.8 | 59.3 | |
| ≥40 | 20.3 | 36.2 | 41.8 | 43.3 | |
| ≥20 | 15.0 | 27.1 | 31.9 | 33.3 | |
| ≥0 | 8.7 | 15.6 | 18.3 | 19.1 | |
表选项
表 5 航拍图像为768×768大小时top-k下的召回率 Table 5 Recall rate at top-k when aerial image size is 768×768
| 是否使用邻域显著性参照定位 | 区域所占完整网格比例/% | 召回率/% | |||
| k=1 | k=2 | k=3 | k=4 | ||
| 否 | 100 | 21.5 | 40.5 | 58.1 | 72.3 |
| ≥80 | 16.6 | 32.6 | 47.9 | 61.5 | |
| ≥60 | 12.6 | 25.0 | 36.9 | 47.7 | |
| ≥40 | 10.1 | 20.0 | 29.5 | 38.2 | |
| ≥20 | 8.1 | 16.0 | 23.7 | 30.8 | |
| ≥0 | 5.6 | 11.0 | 16.3 | 21.0 | |
| 是 | 100 | 22.6 | 43.1 | 61.5 | 75.1 |
| ≥80 | 16.8 | 32.9 | 48.5 | 62.3 | |
| ≥60 | 12.8 | 25.3 | 37.3 | 48.1 | |
| ≥40 | 10.2 | 20.1 | 29.7 | 38.5 | |
| ≥20 | 8.2 | 16.1 | 23.8 | 31.0 | |
| ≥0 | 5.6 | 11.1 | 16.4 | 21.3 | |
表选项
从实验结果可知,在多尺寸航拍图像定位中,使用邻域显著性参照定位时效果更好,即对于航拍图像,本文方法可以准确识别出其包含的大部分区域的类别,且图像包含的上下文信息越多,定位准确率越高。
4 结论 本文利用飞行区域的全部信息将航拍图像定位问题转化为了图像分类问题,通过使用飞行区域内带有位置标记的网格图像制作训练集。基于AlexNet提出了一种融合显著性特征的多通道全卷积网络模型(multi-channel AlexNet-FCN),实现了一个支持多尺寸输入的滑动窗口分类器,并提出了一种邻域显著性参照定位策略来筛选分类结果,从而实现多尺寸航拍图像的定位。实验证明,本文方法训练的卷积网络对单一网格图像分类准确率可以达到95.4%,实现了多尺寸航拍图像包含的大部分网格的准确定位, 很好地适应了航拍图像的旋转特性。后续可以通过扩充更多时间和尺度的数据集,来提高卷积特征对航拍图像的适应能力。
参考文献
| [1] | PREWITT J M S.Object enhancement and extraction[M]//LIPKIN B S, ROSENFELD A.Picture processing and psychopictorics.Salt Lake City: Academic Press, 1970: 75-149. |
| [2] | MARR D, HILDRETH E. Theory of edge detection[J]. Proceedings of the Royal Society of London, 1980, 207(1167): 187-217. |
| [3] | CANNY J. A computational approach to edge detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1986, 8(6): 679-698. |
| [4] | HARRIS C, STEPHENS M.A combined corner and edge detector[C]//4th Alvey Vision Conference, 1988: 117-151. |
| [5] | SMITHSM, BRADYM. SUSAN-Anewapproachtolowlevel image processing[J]. Intemational Joumal of Computer Vision, 1997, 23(1): 45-78. |
| [6] | MIKOLAJCZYK K, SCHMID C.An affine invariant interest point detector[C]//Proceedings of European Conference on Computer Vision.Berlin: Springer, 2002: 128-142. http://www.springerlink.com/content/d946wrklrq1fnpjh |
| [7] | LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110. |
| [8] | BAY H, TUVTELLARS T, VAN GOOL L.SURF: Speeded up robust features[C]//Proceedings of the European Conference on Computer Vision.Berlin: Springer, 2006: 404-417. http://link.springer.com/chapter/10.1007/11744023_32 |
| [9] | RUBLEE E, RABAUD V, KONOLIGE K, et al.ORB: An efficient alternative to SIFT or SURF[C]//IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2012: 2564-2571. http://www.researchgate.net/publication/221111151 |
| [10] | HAUSDORFF F. Grundzüge der mengenlehre[M]. Von Veit: Grundzüge der mengenlehre, 1914: A34-A35. |
| [11] | HUTTENLOCHER D P, KLANDERMAN G A, RUCKLIDGE W J. Comparing images using the Hausdorff distance[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1993, 15(9): 850-863. |
| [12] | DUBUISSON M P, JAIN A K.A modified Hausdorff distance for object matching[C]//Proceedings of the 12th International Conference on Pattern Recognition.Piscataway, NJ: IEEE Press, 1994: 566-568. http://www.researchgate.net/publication/3684010_A_modified_Hausdorff_distance_for_object_matching |
| [13] | ZHAO C, SHI W, DENG Y. A new Hausdorff distance for image matching[J]. Pattern Recognition Letters, 2005, 26(5): 581-586. |
| [14] | BELONGIE S, MALIK J, PUZICHA J, et al.Shape context: A new descriptor for shape matching and object recognition[C]//Proceedings of the 13th International Conference on Neural Information Processing Systems.Cambridge: MIT Press, 2000: 831-837. http://www.researchgate.net/publication/2353535_Shape_Context_A_new_descriptor_for_shape_matching_and_object_recognition |
| [15] | BELONGIE S, MALIK J, PUZICHA J. Shape matching and object recognition using shape context[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(4): 509-522. |
| [16] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2012, 60(6): 84-90. |
| [17] | SERMANET P, EIGEN D, ZHANG X, et al.OverFeat: Integrated recognition, localization and detection using convolutional networks[EB/OL].(2013-12-21)[2019-02-10].https: //arxiv.org/abs/1312.6229. |
| [18] | HOU X, HAREL J, KOCH C. Image signature:Highlighting sparse salient regions[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(1): 194-201. |
| [19] | OJALA T, PIETIK?INEN M, M?ENP?? T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7): 971-987. |
