在MBT中,扩展有限状态机(Extended Finite State Machine, EFSM)与有限状态机(Finite State Machine, FSM)是2种最为通用的测试模型,其中EFSM一直被作为SDL、UML、Simulink等建模语言的底层行为模型使用,它是在FSM的基础上引入了变量、操作以及状态迁移的谓词条件,因而相比于FSM更加适合于描述诸如嵌入式及通信协议软件等复杂应用系统[2]。目前基于EFSM模型的测试主要存在以下两方面的挑战:一是如何生成可执行的测试路径; 二是路径对应的测试数据的生成。本文主要对第二方面的问题进行了研究。
近年来,随着基于搜索的软件测试技术不断发展,启发式算法在自动生成测试数据中的应用获得了很大进展,这些方法中以对遗传算法(GA)的研究最为广泛。如文献[3-4]通过基本遗传算法来选取EFSM模型的测试数据。文献[5]为提高测试数据生成效率,在基本遗传算法中增加了局部搜索方法用以加快算法收敛速度。文献[6]在计算个体适应度过程中,充分考虑了分支距离和个体未覆盖条件的比率,提高了搜索的成功率。除遗传算法外,一些其他方法也被用于测试数据的自动生成[7-9]。在组合优化问题中,搜索空间的大小往往决定了问题的复杂程度,搜索空间越大,找到目标解的时间开销就越大,上述算法都是在输入变量的全空间内寻找测试数据,因而搜索效率有待进一步提高。
对此,文献[10]提出一种变量的动态域削减方法,该方法通过分支谓词动态减小变量取值范围,缩减了搜索区间。文献[11]则通过削减区间和分段梯度下降方法来获取EFSM模型的测试数据,在无法得到确定解时,这种方法也可为人工选取测试数据提供一个较小的输入变量取值范围。与上述减小变量取值区间的方法不同,文献[12]提出,若待测程序对应控制流图中某一输入变量的变化将不影响未来路径的方向,则可以固定该变量的取值,从而通过减少变量的个数减小搜索空间。文献[13]则从理论与实验两方面验证了不相关变量的减少可以有效提高爬山算法及遗传算法的搜索效率。文献[14]在这些研究的基础上指出,可以通过分离与部分输入变量相关的子路径,并固定被穿越子路径的变量取值以达到减小搜索空间的目的,但并未实现可分路径的自动判定及分离方法。文献[15]通过分析变量与待测程序节点及测试路径的关系给出了可分路径的判断与分离算法,但该方法在判定变量间的依赖关系时,未区分程序节点的前后顺序,只要变量间存在赋值关系便判定为具有依赖关系,且只给出了将可分路径分为两部分的算法,通用性有待提高。
总结以上研究可以发现,现有的搜索空间缩减方法自动化程度较低,且大多针对程序语言,而对EFSM模型的研究较少。实际上在EFSM测试数据搜索过程中,只要输入变量对测试路径未来迁移的谓词条件无影响时,便可以固定该变量的取值,并将其从变量集合中分离出去。因此,减小EFSM测试数据的搜索空间需要解决的主要问题有:
1) 如何判定输入变量与谓词条件是否有依赖关系。
2) 存在无关输入变量时,怎样分离该变量。
本文从变量的角度出发,通过分析EFSM中变量与状态迁移的依赖关系,研究测试数据生成中无关输入变量的判定与分离方法,从而减小遗传算法搜索空间,提高EFSM测试数据生成效率。
1 EFSM模型及问题建模 1.1 EFSM模型 扩展有限状态机M由一个六元组构成,表示为M=(S, S0, I, O, T, V),其中S为该EFSM的状态集合,S不能为空,S0为初始状态,I为输入消息集合,O为非空的输出消息集合,T为状态迁移集合,V为变量的集合。集合T中的每一个元素t由五元组(Sstart, i, g, φ, Send)组成,其中Sstart为迁移t的出发状态,i∈I为t的输入消息,g为迁移t执行的谓词条件,φ则由变量的赋值语句或输出语句组合而成,Send为状态迁移t的到达状态。EFSM中的变量V由三元组(Iv, Cv, Ov)构成,其中Iv为输入变量集合,Ov为输出变量集合,Cv为环境变量集合,输入变量的取值可以人为进行控制,而输出变量和环境变量则不受测试人员控制,它们的取值由迁移中的相应操作来决定。EFSM模型中的测试路径(Test Path, TP)定义为一个迁移序列,即LTP=[t1, t2, …, tn],其中{t1, t2, …, tn}?T,LTP对应的谓词条件序列LGP=[g1, g2, …, gn],若tk为路径LTP中的状态迁移,gk为tk中的谓词条件则分别表示为tk→LTP,gk→LGP。
图 1为一种自动取款机(Automatic Teller Machine,ATM)的EFSM模型[4],该模型的输入变量集合Iv={z, y, w, h, β1, β2, β3},其中z代表输入密码,y、w及h分别为存款、取款及转账金额,β1、β2及β3表示用户选择了某一操作。模型中ATM主要提供3种服务:存款、取款及转账。当需要使用这3种服务之一时,用户需要输入相应的银行卡密码z,并记录密码错误的次数N,若错误次数已达3次则返回初始界面,否则选择菜单要使用的语言,继续相应操作,模型中其他变量的含义为:Bs与Bc表示2种不同类型账户的余额,Zp为正确的银行卡密码。假设选择LTP=[t1, t4, t5, t23]作为目标测试路径,当EFSM处于迁移t4的出发状态S1时,接收到特定的输入Pin(z),z∈Iv,只有在谓词条件(z==Zp)为真时,迁移t4才会执行,并且状态由S1转换到S2。基于EFSM模型的测试数据自动生成即讨论如何自动选取这些触发谓词条件的输入变量的值。
 |
| 图 1 ATM的扩展有限状态机模型 Fig. 1 Extended finite state machine model of ATM |
| 图选项 |
1.2 问题建模 EFSM中测试数据的生成问题可描述为:
1) 选取一个待测软件的EFSM模型M。
2) 选取M中的一条测试路径LTP作为目标测试路径。
3) 设待测模型M中输入变量的取值空间为D,求取测试数据X∈D,使得以X作为输入,在动态执行EFSM模型时,所能经过的路径为LTP。
使用遗传算法自动获取EFSM的测试数据,需要将其建模为一种最优化问题。
将不同的测试数据代入到LTP中所实际经过的路径与目标测试路径接近的程度作为各个测试数据的适应度[3],记为Fi(X),i=1, 2, …, n。依据适应度函数,对于EFSM模型中测试数据生成问题就可以建立如式(1)所示的最小化模型:
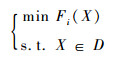 | (1) |
本文主要讨论了如何判定和分离不影响测试数据生成的无关输入变量,从而通过缩减搜索空间D,在自动获取测试数据的同时提高搜索效率。
2 无关变量的自动判定 EFSM模型中,将不影响测试子路径谓词条件的变量称为无关变量,由于测试路径中变量与变量、谓词条件与变量间存在有复杂的联系,因此无关变量的判定需要深入分析变量与状态迁移间的关系。
2.1 变量与状态迁移的关系 由1.1节可知,EFSM中的状态迁移是一个五元组,其中与变量存在依赖关系的元素包括迁移中的赋值语句或输出语句φ以及迁移执行的谓词条件g,由于输出语句仅进行变量的输出操作,并不会影响变量的取值,因此变量与状态迁移的关系可以划分为变量与赋值语句及谓词条件中其他变量的关系(简称为变量与变量的关系),以及谓词条件与变量的关系两部分。
2.1.1 变量与变量的关系 设待测EFSM模型M的变量集合V={x0, x1, …, xn-1},迁移集合T={t0, t1, …, te-1},目标测试路径LTP=[t0, t1, …, tm-1],有以下定义:
定义1??设迁移td∈T,若?xi∈V,xj∈V,使得td的赋值语句中变量xi的取值取决于变量xj,表示为xi=f(xj)d,则在迁移td中xi直接依赖于xj;若?xi∈V,xj∈V,使得td的谓词条件中既包含xi又包含xj,则在td中xi与xj相互直接依赖,即xi=f(xj)d,xj=f(xi)d。
定义2??在目标测试路径LTP中,设迁移td→LTP,若?xi∈V,xj∈V,xk∈V,使得td中变量xi直接依赖于xk,但并不直接依赖于xj,即xi=f(xk)d,但在td之前迁移tb(tb→LTP,b < d)中xk直接依赖于xj,即xk=f(xj)b,则称在td中变量xi间接依赖于变量xj。
为方便描述定义1中的直接依赖关系,可以为模型M的每一迁移建立变量间的直接依赖矩阵,而间接依赖关系在针对不同的目标测试路径时其依赖矩阵有所不同,且关系复杂,后文将给出通过图的连通性判断变量间是否存在间接依赖关系的方法。
定义3??对于模型M,设迁移td∈T,则td中变量间的直接依赖矩阵可以由n维方阵Pd=(pij)n×n表示,其中n为集合V中变量的个数,矩阵Pd中的元素pij定义如下:
 | (2) |
2.1.2 谓词条件与变量的关系 状态迁移中的谓词条件是影响有效测试数据生成的关键所在,它是由一系列条件表达式及其合取或析取的形式组成。设待测EFSM的变量集合V={x0, x1, …, xn-1},迁移集合T={t0, t1, …, te-1},目标测试路径LTP=[t0, t1, …, tm-1],LTP对应的谓词条件序列LGP=[g1, g2, …, gm-1],对于谓词条件与变量的依赖关系也可分为直接与间接2种,分别见定义4与定义5。
定义4??设迁移td∈T,若?xi∈V使得td的谓词条件gd(gd→LGP)中包含变量xi,则认为变量xi的取值将对谓词条件能否满足造成影响,即gd对xi存在直接依赖关系。
定义5??在目标测试路径LTP中,设迁移td→LTP,若对于迁移td的谓词条件gd(gd→LGP),?xi∈V,xj∈V使得gd直接依赖于变量xj,而不直接依赖于变量xi,但在td之前迁移tb(tb→LTP,b < d)中变量xj依赖于xi,即xj=f(xi)b,则认为变量xi的取值将间接的对谓词条件gd能否满足造成影响,即谓词条件gd对变量xi存在间接依赖关系。
对于目标测试路径LTP中谓词条件与变量的直接或间接依赖关系在本文中统称为二者具有依赖关系,这种关系也可建立相应的依赖矩阵进行描述。
定义6??在目标测试路径LTP中,设迁移td→LTP,td的谓词条件gd(gd→LGP)与变量xi∈V的依赖关系可以由n×m维矩阵Q=(qij)n×m表示,其中n为集合V中变量的个数,m为LTP包含迁移的个数,矩阵Q中的元素qij定义如下:
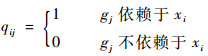 | (3) |
通过定义4~定义6可知,谓词条件与变量间的依赖矩阵描述了变量在该测试路径中的生存周期,因此存在以下性质:
性质1??设待测EFSM中输入变量集合为Iv?V,若?i∈[0, n-1],使得矩阵Q中的第i行元素均为0,则对于测试路径LTP,xi∈V为无关变量;若?i∈[0, n-1],对于?j∈[u, m-1]矩阵Q中元素qij=0,而对j=u-1时元素qij≠0,其中u∈[1, m-1],则在LTP的子路径L′TP=[tu, tu+1, …, tm-1]中xi∈V为无关变量,若同时xi∈Iv则在LTP或L′TP中可以固定输入变量xi的取值并从Iv中将其分离,并将tu-1定义为变量xi的起始分离迁移。
证明??Q中的第i行元素描述了测试路径LTP中每一迁移的谓词条件与变量xi的依赖关系,这种依赖包括直接与间接依赖,若?i∈[0, n-1],对?j∈[u, m-1]元素qij=0,其中u∈[0, m-1],则由定义6可知xi与迁移序列L′TP=[tu, tu+1, …, tm-1]中任意迁移的谓词条件不存在依赖关系,即变量xi的取值与L′TP中的谓词条件能否满足无关,所以xi为无关变量,若同时xi∈Iv,则在L′TP中可以固定xi的取值为常数并将其分离。????证毕
2.2 自动判定无关变量的实现方法 2.1节中给出了变量与状态迁移间的关系,由性质1可知对于一条测试路径中是否存在无关变量,取决于谓词条件与变量间的依赖矩阵Q,对于谓词条件与变量的直接依赖关系,可以通过扫描谓词条件中是否包含该变量得到,而间接依赖关系需要依靠2.1.1节中变量与变量的关系进行判断,下面给出依赖矩阵Pd与矩阵Q的计算方法。
算法1??变量间直接依赖矩阵Pd计算方法
输入:EFSM的变量集合V={x0, x1, …, xn-1},迁移集合T={t0, t1, …, te-1}。
输出:直接依赖矩阵P0, P1, …, Pe-1。
步骤1??选择某一未建立依赖矩阵的迁移td∈T,建立n维方阵Pd并初始化元素为0。
步骤2??扫描迁移td中的每一赋值语句,若?xi∈V,xj∈V使得xi等于一个含有变量xj的表达式,即xi的取值会受到xj的影响,则令pij=1。
步骤3??扫描迁移td的谓词条件,若?xi∈V,xj∈V使得条件中即包含xi又包含xj,表明迁移td中变量xi与xj相互直接依赖,则令pij=pji=1。
步骤4??输出矩阵Pd,判断EFSM中是否有未建立直接依赖矩阵的迁移,若有转到步骤1。
步骤5??算法结束。
通过算法1即可得到待测EFSM所有状态迁移中变量间的直接依赖矩阵,而矩阵Q的计算需要先建立测试路径的每一迁移之前所有迁移中变量间的关系图G,变量间的关系图实质上为一种有向图,因而可以采用图论中的邻接矩阵进行表示,其建立方法如下:
算法2??关系图G的建立方法
输入:EFSM变量集合V={x0, x1, …, xn-1},变量间直接依赖矩阵P0, P1, …, Pe-1,目标测试路径LTP=[t0, t1, …, tm-1]。
输出:关系图的邻接矩阵序列R=[R0, R1, …, Rm-1]。
步骤1??选择某一未建立关系图的迁移td→LTP,以变量x0, x1, …, xn-1作为有向图的n个顶点,建立td的关系图Gd。
步骤2??扫描LTP中td及其之前迁移对应的变量间直接依赖矩阵P0, P1, …, Pd,若某一矩阵中存在元素pij=1,表明变量xi∈V直接依赖于变量xj∈V,则从顶点xj向顶点xi建立一条有向边。
步骤3??将Gd转化为邻接矩阵Rd并输出,判断LTP中是否还有未建立关系图的迁移,若有转到步骤1。
步骤4??算法结束。
建立关系图后,依据该有向图可以得到以下性质:
性质2??利用算法2生成的关系图Gd中,若变量xj到xi存在一条通路,则xj与xi在迁移td或td之前迁移中存在依赖关系,且变量xi依赖于xj。
证明??在测试路径LTP中,若在迁移td或td之前,变量xi直接依赖于变量xj,即xi=f(xj),依据算法2可知,从顶点xj到xi之间存在一条有向边,则xj到xi显然是连通的;若在迁移td或td之前,变量xi间接依赖于xj,即xi=f(x1), x1=f(x2), …, xq=f(xj),由算法2可知,在xj到xq,xq到xq-1, …, x1到xi之间分别存在一条有向边,因此xj到xi存在通路xj, xq, xq-1, …, x1, xi,即xj到xi连通。??????证毕
根据性质2,即可求出依赖矩阵Q。
算法3??矩阵Q的计算方法
输入:EFSM变量集合V={x0, x1, …, xn-1},目标测试路径LTP=[t0, t1, …, tm-1],LTP对应的谓词条件序列LGP=[g0, g1, …, gm-1],邻接矩阵序列R=[R0, R1, …, Rm-1]。
输出:依赖矩阵Q。
步骤1??选择LGP中某一未扫描的谓词条件gj,扫描gj是否包含变量xi∈V,若包含表明gj直接依赖于xi,则依据定义6,令qij=1。
步骤2??若qij=1,则使用深度优先搜索算法判断邻接矩阵Rj-1中变量xk(xk∈V,k≠i)是否有到xi的通路,若存在通路表明gj间接依赖于xk,依据定义6,令qkj=1。
步骤3??判断LGP中是否还存在未扫描的谓词条件,若有转到步骤1。
步骤4??输出矩阵Q,算法结束。
算法3中的步骤1检测了谓词条件与变量是否存在直接依赖关系,而步骤2依据定义5可知是检测了二者是否存在间接依赖关系,因而通过算法3得到的矩阵Q为谓词条件与变量间的依赖矩阵。在得到矩阵Q后,根据性质1便可以获取无关输入变量及其对应的起始分离迁移。
图 2为EFSM模型中的一条测试路径。以该路径为例考察本文提出的无关变量判定算法,该测试路径LTP=[t1, t2, t3, t4],对应的谓词条件分别为g1={a < 5 && b > 2}、g2={a > 2}、g3={c==3}、g4={d≥1},赋值语句φ1={b=a+d}、φ2={a=b+a, c=b+d}、φ3={b=c-a}、φ4={d=c+a},变量集合V=Iv={a, b, c, d},首先依据算法1计算t1~t4迁移中变量间的直接依赖矩阵分别为
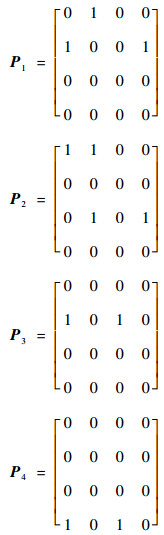 |
 |
| 图 2 EFSM中的一条测试路径 Fig. 2 A test path in EFSM |
| 图选项 |
依据算法2及依赖矩阵P分别做出{t1}、{t1, t2}、{t1, t2,t3}、{t1, t2,t3, t4}中变量与变量间的关系图G,如图 3所示。
 |
| 图 3 不同变量间的关系图 Fig. 3 Relationship diagram among different variables |
| 图选项 |
依据关系图可以建立对应的邻接矩阵序列R=[R1, R2, R3, R4],得到R后根据算法3便可以计算依赖矩阵Q:
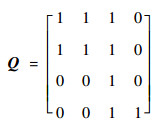 |
根据矩阵Q及算法3可以得出:变量{a, b, c, d}的取值会对迁移t3的谓词条件能否满足造成影响,而迁移t4的谓词条件仅受变量d的影响,由于{a, b, c, d}均为输入变量,因此对于LTP的子路径L′TP=t4来讲,变量{a, b, c}属于无关输入变量,可以分离,其起始分离迁移为t3,而变量d对应的起始分离迁移为t4,说明其在整个测试路径中不能分离。
3 无关输入变量的自动分离方法 3.1 自动分离方法及测试数据生成过程 基于无关输入变量分离与遗传算法的EFSM测试数据生成过程如图 4所示。
 |
| 图 4 EFSM测试数据生成的实现过程 Fig. 4 Implementation process of EFSM test data generation |
| 图选项 |
设待测EFSM模型M包含的输入变量为Iv={x1, x2, …, xn},变量的取值空间为D,选取M中的一条目标测试路径LTP=[t0, t1, …, tm-1],设遗传算法产生的初始种群包含k个个体,不同个体对应的测试数据分别为X1, X2, …, Xk,不同个体以其对应测试数据作为输入,在动态执行EFSM模型时,所能实际经过的路径分别为LTP1, LTP2, …, LTPk,以|LTP|表示相应路径的路径长度(路径所包含迁移的个数),由1.2节可知,实际经过的路径长度越长,该个体的适应度值越好。无关输入变量的分离方法为:在每一次迭代中,搜索种群中经过路径长度最长的个体i,其对应的测试数据为Xi,考察LTPi中是否包含可分离输入变量xj对应的起始分离迁移,若包含则可以在所有个体中去除变量xj,在之后的迭代中xj的取值以常数c0代替,c0为个体i中xj的取值,即c0∈Xi。
以图 2为例,设遗传算法在迭代到某一次时,种群中适应度值最好个体所经过的路径为[t1, t2, t3],其对应测试数据X={a=3, b=7, c=4, d=0},由于该个体所经过的路径包含变量a、b、c的起始分离迁移t3,因此可以固定这3个变量为常数,常数值为{a=3, b=7, c=4},并从所有个体中将它们分离,在以后的迭代中遗传算法仅需搜索变量d的值即可。
3.2 性能分析 本文通过分离测试路径中的无关输入变量以达到减小搜索空间的目的,从而提升测试数据生成效率,设待测EFSM中的输入变量Iv={x1, x2, …, xn},不同变量的输入域分别为D1, D2, …, Dn, 则遗传算法的搜索空间为
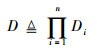 | (4) |
当遗传算法在分别迭代t1, t2, …, tm次时,种群中最优个体可以分离某些输入变量,若在不同迭代次数时可分离的变量分别为{x1, x2, …, xj(t1)},{xj(t1)+1, xj(t1)+2, …, xj(t2)}, …, {xj(tm-1)+1, xj(tm-1)+2, …, xj(tm)},且0 < j(t1) < j(t2) < … < j(tm) < n,则此时搜索空间将分别变为
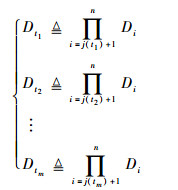 | (5) |
设该测试路径目标解的空间为Dr,则D, Dt1, Dt2, …, Dtm及Dr的关系可以用图 5表示。由图 5可知,随着分离变量的增多,搜索空间逐渐减小,在更小的搜索空间内进行搜索,将显著提高遗传算法的搜索效率[16]。
 |
| 图 5 不同搜索空间之间的关系 Fig. 5 Relationship between different search spaces |
| 图选项 |
4 实验 为了验证采用本文方法对遗传算法搜索效率的影响,将采用全空间搜索(Global Space Search,GSS)的传统遗传算法[3]与本文无关输入变量分离(Irrelevant Input Variables Separation,IIVS)的遗传算法进行对比,2种方法均采用二进制编码、轮盘赌选择、使用单点交叉及单点变异,算法的一些其他参数为:交叉概率0.75,变异概率0.1,初始种群规模25,最大迭代次数50 000代。此外,为进一步验证IIVS方法的优势,本文还对使用IIVS方法的随机算法(Random Algorithm,RA)与全空间搜索的随机算法[17]进行了比较,与遗传算法中无关输入变量的分离方法类似,IIVS-RA也是在每次迭代中判断实际经过的路径是否包含可分离输入变量的起始分离迁移,若包含则在以后的搜索过程中固定该变量的取值,以此达到分离无关变量的目的,实验中这2种随机算法的最大迭次数均设置为300 000。
上述4种算法均是使用Java语言在Eclipse环境下编写运行,实验计算机的主频为2.3 GHz,内存为4 GB。将实现后的方法应用于ATM、INRES[4]及Cashier[18]3组模型的测试数据生成,其中ATM的EFSM模型如图 1所示。
为了从EFSM模型中选取实验路径,实验首先挑选出一些执行逻辑较为复杂的可行路径作为候选路径[8],然后对候选路径进行预处理,将不同迁移输入变量表中相同名称的变量采用不同的符号表示[11],最后使用2.2节中自动判定无关变量的实现方法,从候选路径中筛选出包含有无关变量的路径,即最终的实验路径,筛选后的实验路径数目及无关变量判定算法所花费的时间如表 1所示。
表 1 实验模型及相关参数 Table 1 Relevant parameters of experimental models
| 模型 | 状态个数 | 迁移个数 | 候选路径 | 实验路径 | 判定时间/ms |
| ATM | 10 | 28 | 44 | 43 | 703 |
| INRES | 7 | 16 | 23 | 18 | 570 |
| Cashier | 12 | 20 | 49 | 22 | 713 |
表选项
采用4种算法对所有实验路径在不同的输入变量取值区间内分别进行15次实验,统计相应的平均迭代次数及平均运行时间,结果如表 2所示。由表 2可以得出,使用本文方法后,遗传算法所需平均迭代次数仅为GSS-GA的14.1%~55.3%,除变量取值范围为[0, 2 047]的INRES与Cashier模型外,使用IIVS-RA的平均迭代次数是GSS-RA的27.5%~85.6%,比较各算法的平均迭代次数可以得出IIVS-GA在生成测试数据时所需的次数最少。时间开销方面,虽然IIVS方法在搜索测试数据时需要判断并分离目标测试路径中的无关输入变量,但由表 1可知,这部分时间在测试数据生成时间中所占的比例很小,由于搜索空间的不断减小,使得最终的平均运行时间大量减少。实验结果显示, IIVS-GA所需平均运行时间最低时仅为GSS-GA方法的14.5%,最高为75.9%,除变量取值范围为[0, 2 047]时的INRES与Cashier模型外,IIVS-RA所需平均运行时间是GSS-RA方法的26.3%~84.8%,对4种方法的平均运行时间进行比较后可以看出,IIVS-GA生成测试数据时需要的时间开销最少。表 2中GSS-RA的平均迭代次数及平均运行时间有时会随着变量数据范围的增大反而减小,这是由于当数据范围变大时,该方法在指定迭代次数内大多只能针对简单路径生成有效测试数据,因而迭代次数及运行时间有可能变小甚至小于启发式算法。
表 2 不同算法的平均迭代次数与平均运行时间 Table 2 Average number of iterations and average running time for different algorithms
| 模型 | 数据范围 | 平均迭代次数 | 平均运行时间/ms | |||||||
| GSS-RA | IIVS-RA | GSS-GA | IIVS-GA | GSS-RA | IIVS-RA | GSS-GA | IIVS-GA | |||
| [0, 511] | 117292.1 | 42033.1 | 533.5 | 137.7 | 4119.2 | 1146.2 | 1013.3 | 262.0 | ||
| ATM | [0, 1023] | 166786.7 | 99062.8 | 946.7 | 224.3 | 4294.9 | 2534.4 | 1609.2 | 602.1 | |
| [0, 2047] | 197291.8 | 106831.6 | 1649.7 | 427.3 | 5072.7 | 2831.9 | 2639.8 | 905.3 | ||
| [0, 511] | 113718.0 | 97355.6 | 4826.7 | 889.3 | 12041.5 | 5275.4 | 11040.9 | 2255.5 | ||
| INRES | [0, 1 023] | 163962.1 | 121408.1 | 7024.9 | 2978.3 | 18129.9 | 15383.2 | 16062.7 | 11007.0 | |
| [0, 2047] | 87049.8 | 227285.3 | 8193.6 | 4532.3 | 7820.7 | 16493.2 | 20004.8 | 15192.9 | ||
| [0, 511] | 87653.0 | 24091.4 | 870.0 | 122.8 | 3482.4 | 915.7 | 1229.9 | 211.7 | ||
| Cashier | [0, 1 023] | 77864.8 | 41564.1 | 1343.7 | 220.4 | 3046.8 | 1348.6 | 2807.9 | 406.6 | |
| [0, 2 047] | 32290.5 | 51415.0 | 1918.3 | 327.6 | 1241.3 | 1842.8 | 3624.3 | 629.7 | ||
表选项
为进一步评估各算法性能,统计实验过程中这4种方法的成功率如表 3所示,对于这3组测试模型,GSS-RA的成功率最低时仅为16.4%,最高92.4%,使用IIVS-RA后,成功率提高至74.7%~99.4%。与随机算法相比,遗传算法对于ATM及Cashier模型的所有测试路径均可以100%找到测试数据,而对INRES模型,GSS-GA最低时的成功率为85.0%,最高98.6%,使用IIVS-GA后可进一步提高到98.2%~100.0%。比较各算法的成功率可得,IIVS-GA在生成测试数据时的成功率最高,GSS-RA最低,其余2种方法则介于二者之间。
表 3 不同算法的成功率 Table 3 Success rate of different algorithms
| 模型 | 数据范围 | 成功率/% | |||
| GSS-RA | IIVS-RA | GSS-GA | IIVS-GA | ||
| [0, 511] | 91.6 | 99.4 | 100.0 | 100.0 | |
| ATM | [0, 1 023] | 54.4 | 97.1 | 100.0 | 100.0 |
| [0, 2 047] | 16.4 | 88.2 | 100.0 | 100.0 | |
| [0, 511] | 61.4 | 94.0 | 98.6 | 100.0 | |
| INRES | [0, 1 023] | 56.1 | 88.8 | 90.9 | 100.0 |
| [0, 2 047] | 26.7 | 74.7 | 85.0 | 98.2 | |
| [0, 511] | 92.4 | 98.7 | 100.0 | 100.0 | |
| Cashier | [0, 1 023] | 70.5 | 98.1 | 100.0 | 100.0 |
| [0, 2 047] | 55.2 | 95.9 | 100.0 | 100.0 | |
表选项
为考察使用IIVS方法后遗传算法的稳定性,从ATM模型的实验路径中随机挑选4条测试路径进行进一步实验,路径的相关信息如表 4所示。以这4条路径作为测试路径,使用GSS-GA与IIVS-GA分别进行100次实验,输入变量取值范围为[0, 1 023],统计2种方法生成有效测试数据时所需的迭代次数并绘制为箱线图,结果如图 6所示。
表 4 目标测试路径与可分离输入变量及其起始分离迁移 Table 4 Target test path with its separable input variables and initial separation transitions
| 目标测试路径 | 可分离输入变量及其起始分离迁移 |
| LTP1=[t1, t4, t5, t8, t17, t21, t10, t7, t13] | (β2, β3, h)→无; z→t4; w→t17; β1→t21; y→t13 |
| LTP2=[t1, t4, t6, t7, t14, t16, t9, t25, t28] | y→无; z→t4; w→t14; β1→t16; (β2, β3, h)→t28 |
| LTP3=[t1, t4, t5, t25, t27, t30, t26] | (w, y)→无; z→t4; (β2, β3, h)→t27; β1→t30 |
| LTP4=[t1, t4, t6, t8, t18, t22, t10, t7, t12] | (w, β2, β3, h)→无; z→t4; y→t18; β1→t12 |
表选项
 |
| 图 6 迭代次数对比 Fig. 6 Iteration number comparison |
| 图选项 |
图 6中垂直延伸线(胡须)两端分别表示迭代次数的最大观测值(Mmax)及最小观测值(Mmin),其中最小观测值为算法执行100次中所需迭代次数实际的最小值,而最大观测值则由上四分位数l3与下四分位数l1一同决定,其计算方式如式(6)所示:
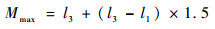 | (6) |
对于这4条测试路径,本文方法迭代次数的中位数均要小于相应传统方法的对应值。为考察不同方法的稳定性,可以通过比较箱长大小(上下四分位数间的距离)及最小值到最大值的区间范围来衡量迭代次数的波动范围,波动范围越大,表示该方法的稳定性越差。由图 6可知本文方法在上述2个指标上均要优于传统方法,这说明与全空间搜索的遗传算法相比,本文方法的稳定性要更好一些。
5 结论 本文通过深入分析EFSM模型中变量与变量、谓词条件与变量间的依赖关系,提出了一种无关输入变量的判定与分离方法。在使用遗传算法自动生成EFSM中指定路径的测试数据时,当种群中的最优个体实际经过的路径包含有可分离输入变量的起始分离迁移,便可以将该变量固定为常数,并将其从所有个体中分离出去。
针对ATM、INRES、Cashier三个EFSM模型进行实验后的结果表明:
1) 无关输入变量的自动判定与分离方法是有效的,这种方法可以逐渐缩减搜索算法的搜索空间,提高随机算法与遗传算法的搜索效率。
2) 与在全空间搜索下的遗传算法相比,本文方法对目标路径集生成测试数据的成功率更高,所需迭代次数及运行时间更少,稳定性更好。
参考文献
| [1] | 苏宁, 郭俊霞, 李征, 等. 基于EFSM不定型切片测试用例自动生成的研究[J]. 计算机研究与发展, 2017, 54(3): 669-680. SU N, GUO J X, LI Z, et al. EFSM amorphous slicing based test case generation[J]. Journal of Computer Research & Development, 2017, 54(3): 669-680. (in Chinese) |
| [2] | SAEED A, HAMID S H A.Extended finite state machines-based testing using metaheuristic search-based techniques: Issues, and open challenges[C]//Software Engineering Conference.Piscataway, NJ: IEEE Press, 2016: 25-30. |
| [3] | ZHAO R, HARMAN M, LI Z.Empirical study on the efficiency of search based test generation for EFSM models[C]//International Conference on Software Testing.Washington, D.C.: IEEE Computer Society, 2010: 222-231. |
| [4] | KALAJI A S, HIERONS R M, SWIFT S. An integrated search-based approach for automatic testing from extended finite state machine (EFSM) models[J]. Information and Software Technology, 2011, 53(12): 1297-1318. DOI:10.1016/j.infsof.2011.06.004 |
| [5] | TURLEA A, IPATE F, LEFTICARU R.A hybrid test generation approach based on extended finite state machines[C]//International Symposium on Symbolic and Numeric Algorithms for Scientific Computing, 2016: 173-180. |
| [6] | LU G, MIAO H. An approach to generating test data for EFSM paths considering condition coverage[J]. Electronic Notes in Theoretical Computer Science, 2014, 309(22): 13-29. |
| [7] | 周艺斌, 殷永峰, 李骁丹, 等. 基于程序变异的Simulink模型测试方法[J]. 北京航空航天大学学报, 2015, 41(3): 391-397. ZHOU Y B, YIN Y F, LI X D, et al. Simulink model testing method based on program mutation[J]. Journal of Beijing University of Aeronautics and Astronautics, 2015, 41(3): 391-397. (in Chinese) |
| [8] | ZHANG J, YANG R, CHEN Z, et al.Automated EFSM-based test case generation with scatter search[C]//International Workshop on Automation of Software Test.Piscataway, NJ: IEEE Press, 2012: 76-82. |
| [9] | KAMKIN A, LEBEDEV M, SMOLOV S.An EFSM-driven and model checking-based approach to functional test generation for hardware designs[C]//East-West Design & Test Symposium.Piscataway, NJ: IEEE Press, 2017: 1-4. |
| [10] | OFFUTT A J, JIN Z, PAN J. The dynamic domain reduction procedure for test data generation[J]. Software Practice & Experience, 2015, 29(2): 167-193. |
| [11] | 张涌, 钱乐秋, 王渊峰. 基于扩展有限状态机测试中测试输入数据自动选取的研究[J]. 计算机学报, 2003, 26(10): 1295-1303. ZHANG Y, QIAN L Q, WANG Y F. Automatic testing data generation in the testing based on EFSM[J]. Chinese Journal of Computers, 2003, 26(10): 1295-1303. DOI:10.3321/j.issn:0254-4164.2003.10.012 (in Chinese) |
| [12] | KOREL B. Automated software test data generation[J]. IEEE Transactions on Software Engineering, 1990, 16(8): 870-879. DOI:10.1109/32.57624 |
| [13] | MCMINN P, HARMAN M, LAKHOTIA K, et al. Input domain reduction through irrelevant variable removal and its effect on local, global, and hybrid search-based structural test data generation[J]. IEEE Transactions on Software Engineering, 2012, 38(2): 453-477. |
| [14] | 张岩, 巩敦卫. 基于搜索空间自动缩减的路径覆盖测试数据进化生成[J]. 电子学报, 2012, 40(5): 1011-1016. ZHANG Y, GONG D W. Evolutionary generation of test data for path coverage based on automatic reduction of search space[J]. Acta Electronica Sinica, 2012, 40(5): 1011-1016. (in Chinese) |
| [15] | 廖伟志. 基于路径自动分割的测试数据生成方法[J]. 电子学报, 2016, 44(9): 2254-2261. LIAO W Z. Test data generation based on automatic division of path[J]. Acta Electronica Sinica, 2016, 44(9): 2254-2261. DOI:10.3969/j.issn.0372-2112.2016.09.034 (in Chinese) |
| [16] | 巩敦卫, 任丽娜. 回归测试数据进化生成[J]. 计算机学报, 2014, 37(3): 489-499. GONG D W, REN L N. Evolutionary generation of regression test data[J]. Chinese Journal of Computers, 2014, 37(3): 489-499. (in Chinese) |
| [17] | VILKOMIR S, ALLURI A, KUHN D R, et al.Combinatorial and MC/DC coverage levels of random testing[C]//IEEE International Conference on Software Quality, Reliability and Security Companion.Piscataway, NJ: IEEE Press, 2017: 61-68. |
| [18] | WANG Y, LI Z, ZHAO R. Dependence based model-healing[C]//Computer Software & Applications Conference. Washington, D.C.: IEEE Computer Society, 2015: 556-561. |
