传统的B/S数据查询系统采用每次查询都去数据库服务器中获取数据的方式。一方面,每次查询都要在整个数据库中进行检索,查询范围很大,造成了较大的延迟,且每次查询去数据库服务器获取数据的方式势必需要在数据库服务器和应用服务器间反复传输大量相同的数据,从而造成了不必要的网络负担。另一方面,对于正在测试中的型号,数据库服务器还需进行动态的海量测试数据录入工作,而每次查询都检索数据库的方式对数据库服务器的访问过于频繁,严重影响系统的性能。为了保证服务器的稳定性和数据录入的完整性,降低数据查询对服务器的资源占用是很重要的。
采用Web缓存解决上述问题是一个行之有效的方法,Web缓存在改善Web性能方面有很重要的作用。通过将可能再次被访问的对象放在距离用户更近的地方的方式,Web缓存可以很好地提高Web性能,如减小响应时间、减小网络带宽的使用以及减轻原始服务器的工作负载等[1]。同时,适合特定应用环境的高效缓存替换算法对系统的性能和用户的体验也将产生极大的影响。缓存替换算法主要以最小化损耗(如总体损耗、平均延时、失误率和字节失误率)为标准[2],根据文献[3-4]所述,缓存替换算法中设计价值函数的主要影响因素包括:①访问频率:对象被引用的总次数;②最近访问时间:对象被引用的最后一次时间;③花费:从原始服务器获取对象所需的资源花费;④大小:对象的大小;⑤过期时间:对象过期的时间;⑥修改时间:对象最近被修改的时间。
在缓存替换算法中,可以综合考虑以上影响因素。根据分析,缓存替换算法主要有5种类型[3]:①基于LRU(Least Recently Used)的算法[5]。这类算法包括LRU、LRU-Threshold、Pitkow/Reckers strategy、SIZE[6]、LRU-Min、EXP1、Value-Aging、HLRU、PSS(Pyramidal Selection Schema)[4]、LRU-LSC、Partitioned LRU等。这类算法的优点是较易实现,且时间复杂度低。但简单的LRU变体没有很好地考虑对象大小的影响,也没有考虑访问频率的影响。②基于LFU(Least Frequently Used)的算法。这类算法包括LFU、DS-LFU[7]、LFU-Aging、LFU-DA(LFU with Dynamic Aging)[8]、σ-Aging、swLFU等。这类算法需要一个较为复杂的缓存管理,同时还存在缓存污染的问题。可能同时会有多个对象有相同的频率计数值,在这种情况下,就得需要另外的因素来确定移除哪个对象。③综合考虑了最近访问时间和访问频率两者的影响,有些算法可能还会加入其他因素。这类算法包括[3]LRFU、SLRU、SF-LRU、Generational Replacement、LRU*、LRU-Hot、LRU-SP、CSS(Cubic Selection Scheme)、HYPER-G等。如果设计合理,这类算法就可以避免上述基于访问频率的算法和基于最近访问时间的算法的缺点。但因为特殊的处理过程,大部分这类算法会引入额外的复杂度。只有LRU*和Generational Replacement算法试图尽量简单地将频率和LRU结合起来,但是它们没考虑对象大小的影响。④基于函数的缓存替换算法,这类算法可以通过选择合适的加权参数,来优化其性能。这类算法包括GD(Greedy Dual)-Size、GDSF[9]、GD*、Ser-ver-assisted cache replacement、TSP(Taylor Series Prediction)、Bolot/Hoschka’s strategy、MIX、M-Me-tric、HYBRID、LNC-R-W3、LRV、LUV、LR(Logistic Regression)-Model等。它们可以考虑多个影响因素来处理不同的工作负载情况。但这类算法的缺点是如何选择合适的加权参数,这是一个十分困难的任务。在对函数值的计算中可能会引入新的问题。⑤使用随机决策来寻找被替换的对象[3]。这类算法包括RAND、HARMONIC、LRU-C[10]、LRU-S、Randomized replacement with general value functions等。这类算法的优点是易于实现,在进行插入和删除对象时,不需要特殊的数据结构。不足之处在于难于进行评估,如运行在同一个Web请求跟踪上的不同仿真实例的结果,可能仅存在些细微的差异。
除了上面给出的传统缓存替换算法之外,近年来,有些研究者提出了一些“智能的”或者“有适应性的”缓存替换算法。例如,文献[11]提出了一种基于多Markov链预测模型的Web缓存替换算法PGDSF-AI,首先将Web中具有不同浏览特征的用户分为多类, 为每一类用户建立类Markov链, 进一步建立多Markov链预测模型,然后利用该模型对当前的用户请求预测, 进而组成预测对象集,当缓存空间不足时, 选取键值最小且不在预测对象集中的对象替换。文献[12]通过语义的方式来增加命中率,利用语义分段、探查查询、剩余查询等来描述语义缓存,构建了分段感知访问的动态语义缓存模型。文献[13]首先通过Web日志挖掘得到预测模型,来获取每个Web对象将来可能被访问的频率,然后将此频率加入到经典Web缓存替换算法GDSF中。同样,文献[14]也通过Web挖掘的方式来改进Web缓存。文献[15]给出了3个基于机器学习的智能Web代理缓存替换算法:SVM-LRU、C4.5-GDS、SVM-GDSF。在常规的缓存替换算法中加入智能方式,用机器学习的智能来预测和判断此Web对象是属于不会被访问的对象类还是将要被再次访问的对象类。
上述几种算法的共同缺点是:计算复杂度和时间复杂度较高,同时占用系统资源也多,且都需要预先进行大数据量的训练,才能获取一定的智能性或者适应性,综合考虑其系统的整体性价比不高[16];并且主要是针对是万维网中的普通用户访问Web网页、多媒体等的情况下。上述算法都有自己的优势以及不足,存在所谓的“足够好”的缓存替换算法[3, 17](在基本性能指标上可以取得比较好的结果),但是无法给出一种在任何应用环境中都能表现出较好性能的算法[18],甚至无法给出最好的一些算法[3]。这是因为网络环境是不确定的、动态的,不同应用的不同Web访问特性,以及工作负载变化不尽相同,且不同缓存系统需要考虑的设计因素及设计目标不尽相同。因此,在设计和选择缓存替换算法时,需针对具体应用的工作负载变化特点。没有哪一种缓存替换策略是能够在任何网络情况下都能很好地适应的,所以如何使得置换策略能够依据不同的访问特性和网络情况采取最适合的缓存替换算法,成为了缓存替换领域研究的热点[17]。
航天器综合测试数据的特征具有:数据量大,数据与时间相关,时间密集,数据结构复杂。用户对数据查询的特征包括:所查询的数据具有很强的时间局域性,即通常主要查询某段时间内的数据;所查询的数据具有空间局域性,即所访问的数据往往只是数据库中数据很小的一部分数据[19]。而现有的Web缓存替换算法不能很好地适用于如航天器这类安全苛刻系统的综合测试数据查询系统。对于这类系统,需要设计和改进一种新的Web缓存替换算法来提高算法的缓存命中率,从而提高数据库服务器的资源利用率,减轻网络负载,提升系统的整体性能,改善用户体验,提高用户工作效率。
本文通过对如航天器这类安全苛刻系统综合测试数据特点和用户查询特征的分析,综合考虑实际应用需求特点,在对现有经典Web缓冲替换算法GDSF研究的基础上,结合Web数据流挖掘的相关技术和滑动时间窗口的思想,基于GDSF算法,设计面向安全苛刻系统测试数据查询的缓存替换算法GDSF-STW,并对其进行充分的实验分析,证明了该算法具有更好的性能,占用较少的系统资源,高效且运行稳定,具有一定的通用性。
1 问题提出 1.1 航天器综合测试数据特点及其查询特征 航天器综合测试数据库系统中保存着多种类型的测试数据,这些数据被存储在多种类型的数据库表中。典型的航天器综合测试数据表结构示例如表 1所示。综合测试数据以时间为主键,存储了该时间点上各参数的值[20-21]。航天器综合测试数据具有以下4个特点:
表 1 航天器综合测试数据表结构示例 Table 1 Spacecraft comprehensive testing data table structure example
| 字段名称 | 中文描述 | 数据类型 | 备注 | 填写举例 |
| TIME | 时间信息 | TIMESTAMP | 主键 | 2017-08-08 09:00:00.000 |
| X001 | X001 | NUMBER | 3.38 | |
| X002 | X002 | NUMBER | 9.88 | |
| ┇ | ┇ | ┇ | ┇ | |
| XXXX | XXXX | NUMBER | 38.08 |
表选项
1) 数据量大。每小时产生大约20 GB的数据,一天数据量大约可达500 GB。对于单个航天器型号,一年的数据总量通常能达到T数量级。
2) 数据结构复杂。航天器综合测试数据的数据类型繁多,所属分系统繁多且每个分系统又有多种参数,其数据结构十分复杂。这些复杂的数据被存储于多个数据库表中。
3) 数据与时间相关。在数据库中,业务数据以时间为主键;在逻辑上,数据具有时间相关性,即对数据进行查询分析时以时间为检索条件,强调一段时间内每个时间点上的数据情况以及整个时间段内数据的变化趋势。
4) 时间密集。每秒一条甚至多条数据,其导致即使查询较短时间区间时,仍有较大的查询结果集,如查询1 h的数据则至少有3 600条。
从宏观上来看,用户对航天器综合测试数据的查询具有一定的特征,主要包括在以下4个方面:
1) 所查询的数据具有很强的时间局域性。对于阶段总结时查询的情况,每天所查询的数据一般局限于之前的测试阶段(7~10 d),通常会按照一定的时间顺序对数据进行总结分析;对于边测试边查询的情况,其所查寻的数据一般局限于当天产生的数据,且查询的数据区间会随着时间顺序的推移而推移。
2) 多次访问。为了确保测试的准确性和测试的完备性,每个数据都会被多次访问。
3) 所查询的数据具有空间局域性。从存储空间角度来看,虽然数据库服务器存放当前型号到目前为止所有的综合测试数据,而用户所查询的数据局限在较短的测试时间内,因此所访问的数据是数据库中存储空间里很小的一部分,即具有空间局域性。
4) 存在一些高频访问对象。某些对象可能在一段时间内被访问的频率要远远大于其他对象被访问的频率,如对于有问题的地方,会被多人反复检查。
1.2 航天器综合测试数据查询问题分析 在B/S架构的Web应用查询系统中,数据查询是“激励”式的,即一次前端操作一次响应。由于航天系统的保密性要求,其数据是不允许备份在前端的普通PC机上的,同时由于结果数据集较大,也使得浏览器缓存结果的方式不可行。因此对于每次查询操作,必须从后台返回查询结果。结合前面对航天器综合测试数据的特征及用户查询特征的分析,为解决多次连接数据库重复传输相同数据的问题,从而减小网络流量,减轻数据库服务器的访问负载,并保证较好的用户查询响应时间,应该采用Web服务器缓存数据的方式。对于动态生成结果的应用环境,目前的文献中给出的常用方法并不完全适用于面向实时环境的航天器综合测试数据查询。本文采用的方法是:将用户在一个工作日内所访问的所有数据作为一个整体,将一个工作日内访问的数据的时间区间记为timeInterval=[begin, end],并将每个原始数据库表中处于区间timeInterval内的数据按整点在逻辑上划分成不同的小数据表,以这些小数据表为单位从数据库服务器获取数据,并将这些小数据表作为一个对象缓存于Web应用服务器上。因此,核心问题是以这些小数据库表作为Web对象,设计优秀的缓存替换算法,提高系统性能。
根据缓存在Web中所处位置的不同,Web缓存可分为原始服务器缓存、Web代理缓存和浏览器缓存[22],如图 1所示。其中,原始服务器缓存是服务器本身的缓存,Web代理缓存位于Web代理服务器上,浏览器缓存在用户端。Web代理服务器位于原始服务器和用户机之间,接收用户的请求并向用户返回请求结果,Web代理缓存被广泛应用于Web代理服务器上,其性能的好坏直接影响到Web访问性能。本文关注的缓存类型是Web代理缓存。对于安全苛刻系统这类复杂系统的综合测试数据系统,如航天器综合测试数据系统,目前的文献中给出的常用方法并不完全适用于面向实时环境的航天器综合测试数据查询。因此,设计一种优秀的缓存替换算法来提高系统的性能具有重要意义。
 |
| 图 1 Web缓存 Fig. 1 Web caching |
| 图选项 |
2 GDSF算法 GDSF算法是目前应用最广泛的缓存替换算法之一,是被公认为“足够好”的缓存替换算法,具有较好的缓存命中率。GDSF算法综合考虑了Web对象访问频率、对象的大小和获取对象所需的代价的影响,并且通过老化因子的设置,将Web访问的时间局域性特征对缓存替换的影响很好地融合到了算法中。但GDSF算法不能很好地适应数据流的快速变化,因而不能取得足够好的缓存命中率。Web应用是典型的数据流应用[23-24],在Web数据流变化较快的环境中(如航天器综合测试数据查询应用中)。本文在GDSF算法的基础上,引入了数据流挖掘中在滑动时间窗口上挖掘频繁模式所使用的一些方法,提出了GDSF-STW算法,改进了GDSF算法的频率计数方法,并引入了过期事务的概念,使得算法有一定的适应性,实现较好的缓存命中率,提高缓存系统的性能。
GDSF算法使用以下函数计算每个Web对象的特征值:
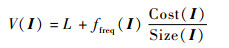 | (1) |
式中:I为Web对象;V(I)为Web对象I的特征值;L为老化因子,初始值为0,当缓存替换发生时,L被赋值为最近一次被替换出去的对象的特征值;ffreq(I)为对象I的频率计数,即该对象在过去的所有访问请求中被请求的次数,对象I缓存命中时,其对应的计数加1,否则ffreq(I)=1;Size(I)为对象I的大小;Cost(I)为取回对象I所需花费的代价。
当需要缓存替换时,具有最小特征值的对象将会被替换出去。从式(1)可以明显看出,GDSF算法综合考虑了对象访问频率ffreq(I)、对象大小Size(I)和获取对象所需的代价Cost(I)的影响。此外,还考虑了对象访问的时间局域性特征。每次缓存命中时,都会更新对象的特征值V,在发生缓存替换时,将老化因子L的值更新为被逐出对象中最大的特征值V,由此可见,老化因子L的值将是逐步递增的,这就使得最近命中的对象要比那些长时间没有访问到的对象,在特征值的老化因子部分要大,这就将对象访问的时间局域性的影响融合到了算法中。但并没有考虑用户更关心的是最近的事务,而那些很久的事务对用户现在所查询的事务影响很小了,而对那些较远的历史事务进行处理所需要的资源开销却是巨大的。所以,某一时间段内的事务数据可能更重要。而应用滑动时间窗口模型就能够应对数据过期的问题。下面给出本文提出的GDSF-STW算法。
3 GDSF-STW算法 3.1 相关概念 设C={I1, I2, …, In, …, Im}为数据项的集合。
定义1??事务Tj={Ix, Iy, …, Iz}为C的一个子集,即Tj?C,每个事务有一个标识符,称为TID。事务中的数据项是无序的,可以任何顺序排列。
定义2??数据流DS={T1, T2, …, Tj, …, Tm}由按时间顺序连续排列的事务组成,事务的数量可能是无限的,且其事务按时间到达的先后顺序分配TID,每个事务的TID是唯一的。
定义3??滑动时间窗口SW[25-26]是数据流DS中最近N(N≥0)个事务的序列,事务在滑动时间窗口中的先后顺序与其在数据流DS中的先后顺序是一致的。根据N是可变的还是固定的,可将滑动时间窗口分为可变长度滑动时间窗口和固定长度滑动时间窗口。常用的可变长度滑动时间窗口主要是基于时间的滑动时间窗口,即窗口中保存最近时间范围(如1 h)内的事务。可对滑动时间窗口进行的操作应该包括从滑动时间窗口中删除最旧的事务以及向滑动时间窗口中添加新的事务,但对于固定长度滑动时间窗口,当窗口中的事务数量达到N之后删除和插入操作必须是成对进行的,可变长度滑动时间窗口[27]则没有这方面的限制。
本文对Web点击流进行分析,用户一次Web点击所请求的对象的集合用一个事务来表示,而集合中的每个数据项用一个Web对象来表示。所有事务按请求到达的先后顺序所组成的数据流就称为Web点击流。
3.2 算法描述 GDSF-STW算法的特征值函数可以表述为
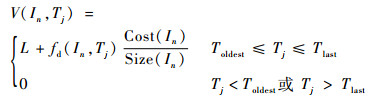 | (2) |
式中:V(In, Tj)为事务Tj到达时对象In的特征值;fd(In, Tj)为事务Tj到达时对象In的衰减支持数;Toldest≤Tj≤Tlast和Tj < Toldest或Tj>Tlast表示滑动时间窗口,从而引入了过期事务对算法的影响。
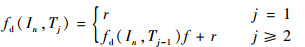 | (3) |
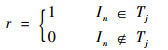 |
Web对象访问具有时间局域性,即被访问的对象距现在越近,将来被访问的可能性越越大。也就是说,Web点击流总会随着时间的推移发生变化,最近产生的事务所蕴含的知识通常比历史事务中所蕴含的知识更有价值[28]。因此,可采用文献[29-30]中提出的时间衰减模型支持数计算方法来逐步减轻历史事务的影响。记数据项在单位时间内的衰减比率为衰减因子f(0 < f≤1),记事务Tj到达时数据项In的衰减支持数为fd(In, Tj),则数据项In的衰减支持数可由式(3)得到。
3.3 算法流程 在介绍算法流程之前,先给出算法中用到的数据结构。
1) 滑动时间窗口。基于时间的滑动时间窗口用于保存最近可变时间段time内到达的事务队列。滑动时间窗口的成员用一个数据结构SwItem来表示,字段包括提交时间subTime和事务TID。当一个新的事务Tj到达时,则需要更新滑动时间窗口,将该事务的提交时间及该事务的TID封装到SwItem对象,并将其插入队列尾部。然后从队首开始检查,删除所有已经过期的事务。用oldestTid和newestTid分别表示滑动时间窗口队首事务和队尾事务TID(newestTid减去oldestTid等于滑动时间窗口的长度time)。
2) 对象信息Hash表fdHash。用来保存Web对象的衰减支持数及相关的其他信息,以键值对的形式表示。以Web对象名称为主键,值是一个称为Item_Node的数据结构,即 < Item_Name, Item_Node>。Item_Node包含5个数据域:tid(最近的包含Item_Name对象的事务TID)、fd(In, Tj)(衰减支持数)、size(In)(对象大小)、V(In, Tj)(对象特征值)、Cost(In)(从原始服务器获取对象的花费)。记录tid是为了判断过期事务和计算对象的衰减支持数。
当一个新的事务Tj到达时,对于该事务中的每一个对象In,GDFS-STW算法流程描述如下:
步骤1??若对象In缓存命中,即In已存在于缓存中,则更新对象In的衰减支持数fd(In, Tj)=fd(In, Tj)fj-tid+1(f值为1时表示不衰减)。更新对象In最近被包含的TID:tid=j。使用式(2)更新对象In的特征值V(In, Tj)。Used值保证不变。算法对该对象的处理结束。
若对象In不存在于缓存中,则对象In的衰减支持数fd(In, Tj)=1;对象In最近被包含的TID:tid=j;使用式(2)计算对象In的特征值V(In, Tj);将对象In的相关信息保存至对象信息Hash表fdHash中;Used=Used+Size(In)。
步骤2??若Used≤TotalSize,表示缓存中有足够的空间保存对象In,此时直接将对象In存入缓存中,算法对该对象的处理结束。
若Used>TotalSize,表示缓存空间不够,此时需进行缓存替换。从对象信息Hash表fdHash中逐个找出过期对象(对于fdHash中的一个Item_Node,若Item_Node.tid < oldestTid,则该节点对应的对象为过期对象), 找到一个过期对象Ie后,执行以下步骤:从缓存中清除对象Ie;Used=Used-Size(Ie);将对象Ie的相关信息从对象信息Hash表fdHash中清除;继续寻找下一个过期对象;重复上述步骤,直至Used≤TotalSize或者fdHash中已不存在过期对象。
步骤3??若Used≤TotalSize,说明移除过期对象Ie后,有足够大的缓存空间存储对象In。将对象In放入缓存中,算法对该对象的处理结束。
若Used>TotalSize,说明移除所有的过期对象后,仍没有足够的缓存空间存储对象In。此时,遍历对象信息Hash表fdHash,选择最小的k(k≥1)个特征值(特征值相同时优先选择最近包含tid最小的对象),找到其对应的对象I1,I2,…,Ik,它们满足如下3个条件:
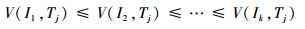 | (4) |
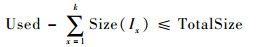 | (5) |
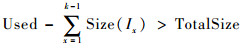 | (6) |
步骤4??老化因子L被赋值为V(I1, Tj),V(I2, Tj),…, V(Ik, Tj)中的最大值V(Ik, Tj),即
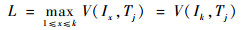 | (7) |
步骤5??从缓存中移除对象I1,I2,…,Ik,并按式(8)更新Used的值:
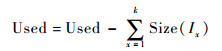 | (8) |
从对象信息Hash表fdHash中,清除对象I1, I2, …, Ik的相关信息。
将对象In存入缓存中,算法对该对象的处理结束。如此循环,直至对事务Tj中所有的对象处理完毕后,返回事务请求的对象集合,算法结束。
GDSF-STW算法的流程如图 2所示。
 |
| 图 2 GDSF-STW算法流程图 Fig. 2 GDSF-STW algorithm flowchart |
| 图选项 |
GDSF-STW算法使用了数据流挖掘中滑动时间窗口模型的相关概念。滑动时间窗口模型的最初灵感来源是:由于内存大小有限,保存数据流中的所有事务是不可行的,且对所有历史事务进行处理的时间开销也是不可接受的,而用户更关心最近的事务。应用滑动时间窗口模型能够应对数据过期的问题。
4 实验设计及分析 4.1 实验设计
4.1.1 实验环境 本文中,算法实验运行在DELL台式机上,CPU型号为Intel酷睿四核i5,型号7500,CPU频率为3.4 GHz,4 GB物理内存,500 G SATA3硬盘,硬盘转速为7 200 r/min。操作系统为Microsoft Windows 7,实验中的算法均采用Java语言实现。
4.1.2 实验数据 本文采用轨迹驱动[1, 31]的方法来对GDSF-STW算法进行仿真实验。实验数据来源于航天器综合测试数据查询系统的服务器所记录的查询日志信息。由于原始的查询日志信息中有些信息不能够对外公布,且有很多冗余信息需要去除。本文中使用经过处理的Web查询日志文件,文件命名规范为:WebLog_+日志编号,每个日志文件中存放21条查询记录,记录格式如表 2所示。航天器综合测试数据有很多数据类型(即数据流),数据量巨大,为了方便实验操作,选取其中一部分具有代表性的数据流数据进行实验。上述日志文件中,每条记录代表一次查询,被看作是一个事务,一个事务通常需要访问多个Web对象。为了方便缓存替换算法处理,将上述日志文件进行解析得到事务文件,每个日志文件对应解析为一个事务文件,事务文件命名格式为:TransactionFlow+对应日志文件的编号,每条日志记录解析为一条事务记录,事务记录的格式如表 3所示。实验中使用2017-03-10—2017-03-24共15天的日志数据,由于日志数据统计信息表占用篇幅过大,此处省略。
表 2 日志记录格式 Table 2 Logging format
| 日志记录 参数 | 参数列表 说明 | 日志记录 参数示例 |
| 查询提交时间 | 查询参数列表包括多行,每行表示一条参数信息 | 2017-03-19 08:08:31 |
| 航天器型号 | XXXXXXXX | |
| 测试阶段 | PHASE1 | |
| 查询开始时间 | 2017-03-18 21:06:48 | |
| 查询结束时间 | 2017-03-18 23:09:16 | |
| 是否查询源码信息 | true | |
| 查询参数个数 | 3 | |
| DATE1, XX, XX, XX, …; | ||
| 查询参数列表 | DATE2, XX, XX, XX, …; | |
| DATE3, XX, XX, XX, …; |
表选项
表 3 事务记录格式 Table 3 Transaction record format
| 事务记录项 | 事务记录项说明 | 事务记录项示例 |
| 查询提交时间 | 事务TID随查询提交时间的增长而增长,相邻2个 | 2017-03-19 08:08:31 |
| 查询事务的TID相差1 | ||
| 事务TID | 999888 | |
| 访问Web对象个数 | 189 | |
| XXXXXXXX_DATE1_XX_XX_XX_8_1000000xxxx | ||
| Web对象列表 | Web对象列表用来记录Web对象的名称,每一行表 | XXXXXXXX_DATE2_XX_XX_XX_9_1000000xxxx |
| 示一个Web对象 | ┇ | |
| XXXXXXXX_DATEn_XX_XX_XX_3_100000xxxxx |
表选项
4.1.3 性能指标 常用的衡量缓存性能的指标[13, 17, 32]主要包括命中率HR(Hit Ratio)、字节命中率BHR(Byte Hit Ratio)和延迟节省率DSR(Delay Saving Radio)。本文使用最常用的命中率HR作为衡量缓存替换算法的性能指标。请求的Web对象总数目用N表示,σi表示第i个对象是否在缓存中命中,若命中则σi=1,否则σi=0。
命中率HR定义为:在缓存中命中的对象数与总请求对象数的百分比,计算公式为
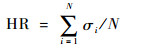 |
4.2 实验分析 从3.2节的算法描述中可知,GDSF算法与GDSF-STW算法所使用的参数中,老化因子L、对象的频率计数ffreq(In)、对象的衰减支持数fd(In, Tj)及对象大小Size(In)的定义都很明确,而取回对象所需花费代价Cost(In)的度量比较复杂,花费可以使用从原始服务器获取对象的时间延迟、取回对象需要的经济花费(如一些付费的对象和付费链路)、需要经历的跳数(hops)等,也可以综合考虑多种花费信息,实际应用中往往是根据缓存系统的目标来定义Cost(In)的值,根据文献[33],如果要使命中率最大化,则定义Cost(In)=1。在航天器综合测试数据查询中,由于原始数据存放于同一台服务器,Web服务器与数据服务器同处于内网环境,因此从原始服务器取回不同对象的时间花费相差不大,且无需考虑收费情况,为了取得较高的命中率,Cost(In)的值被定义为1。下面通过实验分析衰减因子f及滑动时间窗口大小STW_SIZE对GDSF-STW算法性能的影响。
4.2.1 命中率与衰减因子的关系 在考虑衰减因子f对算法性能的影响时,应先屏蔽滑动时间窗口大小STW_SIZE的影响。根据航天器综合测试数据查询系统的实际查询特征,用户每天查询的时间通常在8:00—20:30之间,当STW_SIZE被设置为780 min,一天之内就不存在过期事务,即滑动时间窗口不会发挥作用。因此本节实验中,STW_SIZE被设置为780 min。文献[17]显示,在缓存相对容量达到20%时,缓存替换算法可以取得较好的命中率,因此,本节实验中,设置缓存容量TotalSize的相对大小为20%。GDSF-STW算法针对2017-03-10—2017-03-19每天的日志数据进行实验,在衰减因子分别设置为0.94、0.95、0.96、0.97、0.98、0.99、0.991、0.992、0.993、0.994、0.995、0.996、0.997、0.998、0.999、1时,缓存的命中率HR值如图 3所示。可以清晰地看出命中率随衰减因子的变化趋势。衰减因子取值在0.996~0.997范围内时,可以取得最好的命中率。衰减因子取值在0.94~0.996时,命中率随着衰减因子的增加而递增。衰减因子取值在0.997~1时,命中率随着衰减因子的增加而递减,平均命中率也呈现相同的规律。衰减因子对算法命中率的影响比较明显的主要原因是:航天器综合测试数据查询系统的用户所查询的数据具有很强的时间局域性,而衰减因子可以加速将历史较久数据的特征值减小,从而更好地适应航天器综合测试数据查询系统的用户查询特征。
 |
| 图 3 命中率与衰减因子的关系 Fig. 3 Relationship between hit ratio and decay factor |
| 图选项 |
4.2.2 命中率与滑动时间窗口大小的关系 通过4.2.1节的实验分析可知,衰减因子取值在0.996~0.997范围内时,GDSF-STW算法可以取得最好的命中率,本节实验中,取f=0.996。缓存容量TotalSize仍取总访问量的20%。本实验使用2017-03-10—2017-03-19共10天的日志数据进行实验。根据4.2.1节所述系统的查询特点,当STW_SIZE大于或等于780 min,系统不存在过期事务,因此,本实验取STW_SIZE分别为780、720、660、600、540、480、420、360、300、240、180、120、60、30、20、10、9、8、7、6、5、4、3、2 min。图 4为命中率与滑动时间窗口大小的关系曲线。可以明显看出,滑动时间窗口大小在600 min递减至8 min的过程中,GDSF-STW算法都能取得较好的命中率,且性能指标保持稳定。当滑动时间窗口大于600 min,命中率下降,说明通过添加滑动时间窗口来判断过期事务,在一定程度上可以提高算法的性能指标。当滑动时间窗口小于2 min时,命中率变得极不稳定,迅速下降。这是因为时间过短,许多与用户正在查询的事务有关的其他事务也被过早地扔出去了;而当滑动时间窗口大小达到8 min时,GDSF-STW算法就能取得较好的命中率,且性能指标保持稳定。这说明航天器综合测试数据查询系统的用户查询某相关事务的时间一般会维持在2 min以上、8 min以下,且经常在某一小段时间内存在一些高频访问对象。滑动时间窗口在600 min递减至8 min的过程中,命中率指标保持稳定状态,这是因为一次事务查询中通常涉及到很多的对象,因此较短时间范围内的事务中便包含了大多数的对象,这样就使得较短时间范围内有较多对象为非过期对象。而在较小的滑动时间窗口情况下,算法所需的存储空间和需要被存储事务数量都较少,从而可以降低算法的空间复杂度,因此在保证算法性能基本不变的前提下,应尽量选择较小的时间窗口。从图 4可以看出,滑动时间窗口大小为10 min时,此时间点的前后算法性能均很稳定,因此对于航天器综合测试数据查询系统中的特征,滑动时间窗口大小可选择为10 min。
 |
| 图 4 命中率与滑动时间窗口大小的关系 Fig. 4 Relationship between hit ratio and sliding window size |
| 图选项 |
4.2.3 命中率与缓存容量的关系 根据4.2.1节和4.2.2节对GDSF-STW算法不同参数的实验分析,本节实验中,设置滑动时间窗口大小为10 min,衰减因子f=0.996,分别对缓存容量1%、2%、3%、4%、5%、10%、15%、20%、25%、30%进行实验。实验使用的日志数据为2017-03-20—2017-03-24共5天的日志记录。由图 5看出,命中率随着缓存容量的增加快速增加,当缓存相对容量达到30%时,命中率可超过0.7。
 |
| 图 5 命中率与缓存容量的关系 Fig. 5 Relationship between hit ratio and cache capacity |
| 图选项 |
4.2.4 与其他算法对比 本节实验中,设置GDSF-STW算法中的滑动时间窗口大小为10 min,衰减因子f=0.996。实验中使用的日志数据为2017-03-20—2017-03-24共5天的日志记录。分别对GDSF-STW、GDSF、LFU、LFU-DA、LRU设置缓存容量为1%、2%、3%、4%、5%、10%、15%、20%、25%、30%进行实验。图 6为各算法命中率随缓存容量变化的曲线。因为针对航天器综合测试数据查询系统的用户查询特征引入了衰减因子和滑动时间窗口机制,所以从图中可以看出,GDSF-STW算法的命中率优于其他算法。
 |
| 图 6 各算法命中率与缓存容量的关系 Fig. 6 Relationship between hit ratio and cache capacity among multiple algorithms |
| 图选项 |
5 结论 本文针对航天器综合测试数据查询系统中数据的特征,分析了用户的查询特征,在充分调研了国内外缓存技术研究进展的前提下,结合Web数据流挖掘的相关技术,设计了一个面向航天器综合测试数据查询系统的缓存替换算法——GDSF-STW。
1) 给出了算法实现的具体流程,并使用实际运行环境中的查询日志记录数据,进行了轨迹驱动的仿真实验。
2) 进行了充分的实验分析,并与现有的典型缓存替换算法进行实验对比,证明了本文算法具有更好的性能。
进一步的主要工作有:①采用DEA(Data Envelopment Analysis)方法对算法的有效性进行系统性评估研究;②收集除航天器综合测试数据外的其他领域数据,如股票交易、视频网站、新闻网站等一些数据量大、变化快且大众用户更关心的最新数据变化情况的应用,探讨本文提出的GDSF-STW算法在这些领域数据的应用和扩展。
参考文献
| [1] | KASTANIOTIS G, MARAGOS E, DOULIGERIS C, et al. Using data envelopment analysis to evaluate the efficiency of Web caching object replacement strategies[J].Journal of Network and Computer Applications, 2011, 35(2): 803–817. |
| [2] | ALI W, SHAMSUDDIN S M, ISMAIL A S. A survey of Web caching and prefetching[J].International Journal of Advances in Soft Computing and its Applications, 2011, 3(1): 18–44. |
| [3] | PODLIPNIG S, B?SZ?RMENYI L. A survey of Web cache replacement strategies[J].ACM Computing Surveys(CSUR), 2003, 35(4): 374–398.DOI:10.1145/954339 |
| [4] | CHENG K, KAMBAYASHI Y. Advanced replacement policies for WWW caching[C]//1st International Conference on Web-Age Information Management(WAIM 2000). Berlin: Springer, 2000: 239-244. |
| [5] | 张震波, 杨鹤标, 马振华. 基于LRU算法的Web系统缓存机制[J].计算机工程, 2006, 32(19): 68–70. ZHANG Z B, YANG H B, MA Z H. Web cache mechanism based on LRU algorithm[J].Computer Engineering, 2006, 32(19): 68–70.DOI:10.3969/j.issn.1000-3428.2006.19.025(in Chinese) |
| [6] | BRESLAU L, CAO P, FAN L, et al. Web caching and Zipf-like distributions: Evidence and implications[C]//18th Annual Joint Conference of the IEEE Computer and Communications Societies. Piscataway, NJ: IEEE Press, 1999, 1: 126-134. |
| [7] | SELVAKUMAR S, SAHOO S K, VENKATASUBRAMANI V. Delay sensitive least frequently used algorithm for replacement in Web caches[J].Computer Communications, 2004, 27(3): 322–326.DOI:10.1016/S0140-3664(03)00215-9 |
| [8] | YANG Q, ZHANG H H. Integrating Web prefetching and cach-ing using prediction models[J].World Wide Web, 2001, 4(4): 299–321.DOI:10.1023/A:1015185802583 |
| [9] | SHI L, ZHANG Y. Optimal model of Web caching[C]//4th International Conference on Natural Computation. Piscataway, NJ: IEEE Press, 2008, 7: 362-366. |
| [10] | STAROBINSKI D, TSE D. Probabilistic methods for Web cach-ing[J].Performance Evaluation, 2001, 46(2): 125–137. |
| [11] | 黄学雨, 钟艳青. 基于多Markov链预测模型的Web缓存替换算法[J].微电子学与计算机, 2014, 31(5): 36–40. HUANG X Y, ZHONG Y Q. Web cache replacement algorithm based on multi-Markov chains prediction model[J].Microelectronics & Computer, 2014, 31(5): 36–40.(in Chinese) |
| [12] | MA K, YANG B, YANG Z, et al. Segment access-aware dynamic semantic cache in cloud computing environment[J].Journal of Parallel and Distributed Computing, 2017, 110: 42–51.DOI:10.1016/j.jpdc.2017.04.011 |
| [13] | YANG Q, ZHANG H H, LI T Y. Mining Web logs for prediction models in WWW caching and prefetching[C]//Proceedings of the 7th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2001: 473-478. |
| [14] | SATHIYAMOORTHI V. A novel cache replacement policy for Web proxy caching system using Web usage mining[J].International Journal of Information Technology and Web Engineering (IJITWE), 2016, 11(2): 1–13.DOI:10.4018/IJITWE |
| [15] | ALI W, SHAMSUDDIN S M, ISMAIL A S. Intelligent Web proxy caching approaches based on machine learning techniques[J].Decision Support Systems, 2012, 53(3): 565–579.DOI:10.1016/j.dss.2012.04.011 |
| [16] | ELAARAG H. A quantitative study of Web cache replacement strategies using simulation[M]//ELAARAG H. Web proxy cache replacement strategies. Berlin: Springer, 2013: 17-60. |
| [17] | KASTANIOTIS G, MARAGOS E, DIMITSAS V, et al. Web proxy caching object replacement: Frontier analysis to discover the good-enough algorithms[C]//The 15th IEEE International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems. Piscataway, NJ: IEEE Press, 2007: 132-137. |
| [18] | OLANREWAJU R F, BABA A, KHAN B U I, et al. A study on performance evaluation of conventional cache replacement algorithms: A review[C]//20164th International Conference on Parallel, Distributed and Grid Computing (PDGC). Piscataway, NJ: IEEE Press, 2016: 550-556. |
| [19] | 高世伟, 吕江花, 乌尼日其其格, 等. 航天器测试需求描述及其自动生成[J].北京航空航天大学学报, 2015, 41(7): 1275–1286. GAO S W, LV J H, WUNIRI Q Q G, et al. Spacecraft test requirement description and automatic generation method[J].Journal of Beijing University of Aeronautics and Astronautics, 2015, 41(7): 1275–1286.(in Chinese) |
| [20] | 陈辉. 载人航天器综合测试数据平台的设计与实现[D]. 北京: 北京航空航天大学, 2007: 12-27. CHEN H. Design and implementation of integration test data platform for manned spacecraft[D]. Beijing: Beihang University, 2007: 12-27(in Chinese). |
| [21] | 李先军. 面向航天器测试的测试语言及系统关键技术研究[D]. 北京: 北京航空航天大学, 2011: 12-27. LI X J. Research on key technologies of spacecraft test-oriented test language and system[D]. Beijing: Beihang University, 2011: 12-27(in Chinese). |
| [22] | 周扬发. Web代理服务器的缓存技术研究[D]. 北京: 北京邮电大学, 2014: 11-13. ZHOU Y F. Research on caching technology of Web proxy ser-ver[D]. Beijing: Beijing University of Posts and Telecommunications, 2014: 11-13(in Chinese).http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y2724873 |
| [23] | KREMPL G, ?LIOBAITE I, BRZEZIN'SKI D, et al. Open cha-llenges for data stream mining research[J].ACM SIGKDD Explorations Newsletter, 2014, 16(1): 1–10.DOI:10.1145/2674026 |
| [24] | MARGARA A, URBANI J, VAN HARMELEN F, et al. Streaming the Web:Reasoning over dynamic data[J].Web Semantics:Science, Services and Agents on the World Wide Web, 2014, 25: 24–44.DOI:10.1016/j.websem.2014.02.001 |
| [25] | GUO Y, WANG G, HOU F, et al. Recent frequent item mining algorithm in a data stream based on flexible counter windows[J].Journal of Software, 2014, 9(1): 258–263. |
| [26] | LI F, SUN Y, NI Z, et al. The utility frequent pattern mining based on slide window in data stream[C]//201215th International Conference on Intelligent Computation Technology and Automation(ICICTA). Piscataway, NJ: IEEE Press, 2012: 414-419. |
| [27] | JIANG X, PANG Y, PAN J, et al. Flexible sliding windows with adaptive pixel strides[J].Signal Processing, 2015, 110: 37–45.DOI:10.1016/j.sigpro.2014.08.004 |
| [28] | LIU X, IFTIKHAR N, XIE X. Survey of real-time processing systems for big data[C]//Proceedings of the 18th International Database Engineering & Applications Symposium. New York: ACM, 2014: 356-361. |
| [29] | GIANNELLA C, HAN J W, PEI J, et al. Mining frequent patterns in data streams at multiple time granularities[J].Next Generation Data Mining, 2003, 212: 191–212. |
| [30] | CHANG J H, LEE W S. Findingrecent frequent itemsets adaptively over online data streams[C]//Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. NewYork: ACM, 2003: 487-492. |
| [31] | PATIL J B, PAWAR B V. Trace driven simulation of GDSF# and existing caching algorithms for Web proxy servers[C]//The 9th WSEAS International Conference on Data Networks, Communications, Computers. Athens: WSEAS, 2007: 378-384. |
| [32] | 肖敬伟. 基于数据挖掘的缓存替换算法研究[D]. 北京: 北京交通大学, 2015: 11-13. XIAO J W. Cache replacement algorithms based on data mining[D]. Beijing: Beijing Jiaotong University, 2015: 11-13(in Chinese).http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y2915471 |
| [33] | CAO P, IRANI S. Cost-aware WWW proxy caching algorithms[C]//Proceedings of the USENIX Symposium on Internet Technologies and Systems Monterey. Berkeley: USENIX, 1997: 193-206. |
