综上所述,传统设计模式实例恢复方法存在以下主要问题:① 没有采用交互式机制来获取更多有价值的专家反馈线索,从而导致大量假阳性与假阴性结果;② 采用全自动方法进行检测,制约条件过多,且不易于扩展;③ 大部分检测方法对结构型设计模式识别效果较好,而对行为型与创建型设计模式检测效果不够理想;④ 较难解决设计模式实例恢复的重叠问题。为此本文在Guéhéneuc等[21]提出基于约束满足问题(Constraint Satisfaction Problem, CSP)设计模式检测方法基础上提出一种基于多阶段交互式线索驱动的设计模式半自动检测方法,以调查表形式收集专家反馈知识,再将之按特征进行筛选与分类,形成3类不同的线索,而后通过在不同设计模式检测阶段增加线索来实现对检测结果的逐步求精,并通过4个开源项目对方法的识别效果进行了实验评估。
本文主要贡献为:① 提出一种多阶段可交互的设计模式半自动检测方法;② 依据专家知识的反馈,提出了线索概念;③ 按特征将线索分为静态线索、动态线索、专家经验线索3类,并将之转换为可执行的约束信息,有利于检测结果求精;④ 给出了方法的具体实现;⑤ 通过开源系统分阶段对检测结果进行了评估。
1 设计模式实例识别方法框架 图 1为设计模式实例识别流程。本文实现步骤分为线索表示及线索筛选2个主要阶段。其中,线索表示阶段依据Guéhéneuc等[21]提出CSP表示形式进行后续工作的开展,第2节中将对设计模式的CSP表示形式进行详细描述。线索筛选阶段主要对CSP描述的设计模式实例候选者分静态线索阶段、动态线索阶段及专家经验线索阶段依次进行筛选,直至最终的设计模式实例识别成功。
 |
| 图 1 设计模式实例识别流程 Fig. 1 Design pattern instance identification flowchart |
| 图选项 |
1.1 线索表示阶段 线索表示阶段又分为Guéhéneuc等[21]提出的传统CSP表示及本文方法获取的交互式线索驱动表示。
1) 传统方法CSP表示:① 通过工具DEMIMA[18]对目标源码进行抽取;② 将其结果通过工具Z3[22]转换为CSP的表示形式。
2) 基于交互式线索驱动方法表示:① 以调查表、问卷等形式获取有价值的线索;② 对反馈的线索进行筛选;③ 线索通过工具Z3[22]转换为CSP表示形式。
1.2 线索筛选阶段 将线索表示阶段获得的CSP形式,依据静态线索、动态线索、专家经验线索特点进行分类,并通过逐步增加这3类线索对设计模式检测结果进行筛选,直至取得最终的设计模式候选者集。
2 基于CSP的设计模式表示 Guéhéneuc等[21]提出基于CSP的设计模式检测方法,该方法以约束集形式表示设计模式实例的抽象模型,抽象模型可由类、方法、属性及其之间的关系元素构成。约束集解析器以源码分析的结果作为输入,通过处理后的输出结果与设计模式约束集进行匹配,从而得到设计模式实例的候选参与者。
从基于传统CSP表示的设计模式实例检测角度考虑,抽象模型集分为3类,依次为变量集(Variables)、约束集(Constraints)、域集(Domain)。
2.1 变量集 变量集包括不同设计模式中的类、接口等角色。
图 2(a)为一个标准的Abstract Factory模式,其变量集V可表示为式(1), 而图 2(b)为State模式,其变量集V可表示为式(2)。
 |
| 图 2 Abstract Factory模式与State模式类图 Fig. 2 Class diagram of Abstract Factory pattern and State pattern |
| 图选项 |
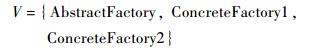 | (1) |
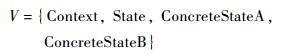 | (2) |
2.2 约束集 约束集C可以发现变量集V中不同角色间的关系,进而构成设计模式实例的抽象模型。本文以Guéhéneuc等[21]在表 1中提出的约束集符号定义为基础,表 2描述了State模式的约束集。依据表 1的符号描述说明,表 2中02行表示存在一个超类扮演state角色,03行表示一个具体类与state类存在继承关系,04行~08行依次对约束集进行表示,详见注释,最终形成了标准的State模式约束集。
表 1 约束集符号类型[21] Table 1 Constraint set notation classes[21]
| 符号 | 描述 |
| super-class() | 表示超类 |
| sub-class() | 表示子类 |
| has-method(c1, m2) | 类c1中有方法m2 |
| abst-class(c1) | 类c1是一个抽象类 |
| abst-method(m1) | 方法m1是一个抽象的方法 |
| Interface(c1) | c1接口的方法都是抽象方法 |
| protected-method(m2) | 表示一个可保护的方法m2 |
| final-method(m1) | 方法m1是最终方法 |
| par-Declared(c1, par1) | 在c1类中申明数据类型par1 |
| par-Parent(c2, par1) | 数据类型par1的类型是c2 |
| same-Signature(m1, m2) | 方法m1与方法m2同名 |
| dominate(m1, m2) | 调用方法m2前须先调用m1 |
| inh(c2, c1) | 类c2 inherit类c1 |
| aggre(c1, c2) | 类c1与类c2存在聚合关系 |
| invoke(m1, m2) | 方法m1调用方法m2 |
| asso(c1, c2) | 类c1与类c2存在关联关系 |
| override(c2, m1) | 类c2的m1方法被重写 |
表选项
表 2 State模式约束集表示 Table 2 Constraint set representation of State pattern
| 01 | State Design Pattern: |
| 02 | super-class(state-role)//存在超类 |
| 03 | inh(concrete-class-role, state-role)//继承关系 |
| 04 | aggre(context-class-role, state-role)//角色间聚合关系 |
| 05 | has-method(state-role, abstr-method)//类中存在方法 |
| 06 | abst-method(abstr-method)//类中存在抽象方法 |
| 07 | override(concrete-class-role, abstr-method)//方法重写 |
| 08 | Not(state-role==context-class-role)//角色是否一致比较 |
表选项
2.3 域集 域集D是源码元素及其关系的集合,可通过解析源码的抽取结果获得。图 3给出一个用例类图,通过约束解析器处理的结果见表 3。
 |
| 图 3 用例类图 Fig. 3 Example class diagram |
| 图选项 |
表 3 基于CSP的实例域集表示 Table 3 Domain set representation of an example by CSP
| 01 | has-method(Tool, method1)//Tool类中存在方法method1 |
| 02 | has-method(Tool, method2)//Tool类中存在方法method2 |
| 03 | abst-class(selectAbstractTool)//selectAbstractTool是抽象类 |
| 04 | inh(Tool, createTool)//createTool与Tool类存在继承关系 |
| 05 | inh(Tool, cancelTool)//cancelTool与Tool类存在继承关系 |
| 06 | inh(Tool, selectAbstractTool) |
| 07 | inh(Tool, cancelTool) |
| 08 | inh(selectAbstractTool, ConcreteTool1) |
| 09 | inh(selectAbstractTool, ConcreteTool2) |
| 10 | inh(selectAbstractTool, ConcreteTool1) |
| 11 | inh(selectAbstractTool, ConcreteTool2) |
| 12 | has-method(createTool, createTool.method1) |
| 13 | has-method(createTool, createTool.method2) |
| 14 | has-method(cancelTool, cancelTool.method1) |
| 15 | has-method(cancelTool, cancelTool.method2) |
| 16 | has-method(selectAbstractTool, selectAbstractTool.method1) |
| 17 | has-method(selectAbstractTool, selectAbstractTool.method2) |
| 18 | has-method(ConcreteTool1, ConcreteTool1.method1) |
| 19 | has-method(ConcreteTool1, ConcreteTool1.method2) |
| 20 | has-method(ConcreteTool2, ConcreteTool2.method1) |
| 21 | has-method(ConcreteTool2, ConcreteTool2.method2) |
| 22 | has-method(receiver, receiver.operation) |
| 23 | same-Signature(createTool.method1, Tool.method1) |
| 24 | same-Signature(createTool.method2, Tool.method2) |
| 25 | same-Signature(cancelTool.method1, Tool.method1) |
| 26 | same-Signature(cancelTool.method2, Tool.method2) |
| 27 | same-Signature(selectAbstractTool.method1, Tool.method1) |
| 28 | same-Signature(selectAbstractTool.method2, Tool.method2) |
| 29 | aggre(DrawControl, Tool) |
| 30 | asso(Toolclient, selectAbstractTool) |
| 31 | asso(createTool, receiver) |
| 32 | invoke(createTool.method2, receiver.operation) |
| |
表选项
表 3中,01行与02行表示工具Tool类中存在2个不同的方法method1与method2,03行表示存在一个selectAbstractTool的抽象类,而04行~11行表示角色间存在继承关系,12~22行表示各个类中存在不同方法,23行~28行表示存在同名的方法,29行~32行依次表示角色间存在聚合、关联、方法调用等关系。
2.4 候选者集 CSP约束集映射域集D中的元素及关系成为参与者角色,表 4描述了图 3中参与者与设计模式的映射关系。例如,候选者DrawControl扮演了State模式中的Context角色,候选者Tool扮演了State模式中的State角色,而候选者createTool、cancelTool、selectAbstractTool都扮演了State模式中的ConcreteState角色。然而这些候选者集中仍可能存在假阳性结果。为此本文在Guéhéneuc等[21]提出基于CSP设计模式检测方法基础上,通过增加线索对传统CSP方法取得的候选者集做进一步的筛选。
表 4 基于CSP的实例候选者集表示 Table 4 Candidate set representation of an example by CSP
| (1) State模式: |
| Context: DrawControl |
| State: Tool |
| ConcreteState: createTool, cancelTool, selectAbstractTool |
| (2) Abstract Factory模式: |
| AbstractFactory: selectAbstractTool |
| ConcreteFactory: ConcreteTool1, ConcreteTool2 |
| Client: Toolclient |
表选项
3 基于线索的设计模式实例表示 针对传统CSP方法检测结果精确性不高的问题,本文提出一种融入专家经验的线索概念。线索实质是对设计模式参与者角色及其关系进行条件约束,侧重专家经验的反馈,该过程有助于发现自动检测方法难以挖掘的有效信息,并有助于对传统CSP方法检测结果的进一步求精。
3.1 线索的形成 当获取了专家的反馈信息后,研究者依据共性结果的占有率进行筛选,优先选择占有率较高的,并转换为CSP形式的线索,线索可以是简单的静态约束信息,也可以是难以挖掘的动态约束信息等。本文中挖掘线索的过程是可迭代的,这有利于积累更多有用的约束信息,从而引导约束解析器取得更精确的结果。
3.2 线索的分类 本文按功能将线索分为3类。
1) 静态线索
静态线索指设计模式实例中的类、方法、属性及继承关系等信息。静态线索能为用户提供更多构建不同设计模式的角色信息,并有助于减少设计模式的候选者集。传统的设计模式识别工具只能检测基本的设计模式静态信息,而一些专家反馈的复杂线索很难被挖掘,这类线索需要通过对表 1中给出的符号定义进行组合,并通过工具Z3[22]编译后实现,表 5给出了部分静态线索。
表 5 静态线索 Table 5 Static clues
| 序号 | 线索描述 | 操作步骤 |
| S-Clue1 | 类A是类B的子类,且A中的方法m1能重写类B中的同名方法m | abst-class(B) abst-method(m) has-method(B, m) has-method(A, m1) inh(A, B) override(A, m) same-Signature(m, m1) |
| S-Clue2 | 类A是一个抽象类或接口 | class(A)=abst-class(A)∨ Interface(A) |
| S-Clue3 | 同一个类A中的方法m1调用另外一种方法m2 | class(A) has-method(A, m1) has-method(A, m2) invoke(m1, m2) |
表选项
以图 3为例,selectAbstractTool类为抽象类,该类中的方法method1与method2也为抽象方法,具体的实现需要通过ConcreteTool1与ConcreteTool2类中的方法method1与method2完成,传统的检测方法仅考虑类的继承关系,而没有进一步考虑类中方法是否为抽象方法?方法之间的调用先后顺序如何?依据表 5中的静态线索S-Clue1,故selectAbstractTool类不适合扮演State模式中的ConcreteState角色,进而筛选掉该不合适的候选参与者。
2) 动态线索
动态线索侧重设计模式角色间方法调用的顺序、参数传递等。动态线索难以通过源码验证,这些动态线索也可以通过增加约束信息来实现。表 6给出了部分动态线索。
表 6 动态线索 Table 6 Dynamic clues
| 序号 | 线索描述 | 操作步骤 |
| D-Clue1 | 在执行方法m2之前需要调用方法m1 | dominate(m1, m2) |
| D-Clue2 | 方法m1被方法m2调用,且必须在非同一个类中的方法m2终止运行之前 | class(A) class(B) has-method(A, m1) has-method(B, m2) invoke(m1, m2) dominate(m1, m2) |
| D-Clue3 | 类A中的方法m1在调用类B中的方法m2之前,必须先让类B中的方法m2调用类C的方法m3 | class(A) class(B) class(C) has-method(A, m1) has-method(B, m2) has-method(C, m3) dominate(m2, m3) dominate(m2, m1) invoke(m1, m2) invoke(m2, m3) |
表选项
以图 3为例,要实现类Tool中方法method2需依赖createTool类中的method2方法,但该方法需createTool类中的method2方法调用receiver类的operation方法之后才能实现,而传统的方法没有考虑不同类之间方法调用的顺序,依据表 6中动态线索D-Clue3, 故createTool类也不适合扮演State模式中的ConcreteState角色,从而进一步筛选掉静态线索阶段不能排除的候选参与者。
3) 专家经验线索
用户可以增加除静态线索与动态线索之外的专家经验线索,这些线索一般依靠专家的经验知识与直觉产生,没有固定的规律,专家经验线索也有助于用户识别或筛选不合适的设计模式候选参与者,表 7描述了部分专家经验线索。
表 7 专家经验线索 Table 7 Expert experience clues
| 序号 | 线索描述 | 操作步骤 |
| E-Clue1 | 子类中的方法不能重写父类中的重名方法 | class(A) has-method(m1) classes(A1, …, An) inh(A1, …, An, A) Not(override(A1, …, An, m1)) has-method(A1, …, An, m2) Not (same-Signature(m1, m2)) |
表选项
在依次经过3类线索分阶段逐步筛选后,图 3中的设计模式候选者集如表 8所示。createTool、cancelTool、selectAbstractTool 3个候选参与者只有cancelTool适合扮演ConcreteState角色,最终图 3恢复了一个State模式与一个Abstract Factory模式。
表 8 优化后的设计模式候选者 Table 8 Optimized design pattern candidates
| (1) State模式候选者: |
| Context: DrawControl |
| State: Tool |
| ConcreteState: cancelTool |
| (2) Abstract Factory模式候选者: |
| AbstractFactory: selectAbstractTool |
| ConcreteFactory: ConcreteTool1, ConcreteTool2 |
| Client: Toolclient |
表选项
4 专家知识获取 实验研究证明,软件设计者习惯于对目标工作进行科学的概念假设,而这些假设问题融入具体的软件设计方案后将带来积极的效果,一个合适策略的选择主要依赖于研究的目的及调查的条件[23]。为此本文中线索的获取以纸质调查表的形式进行。为了收集更有意义的调研反馈信息,选取了Apache ant v1.6.2、JhotDraw 6.0b1、QuickUML2001、Junit v3.8 4个开源系统中的4个方案,每个方案有3个基础选项,包括联系方式、调查对象的职业与对设计模式的熟悉程度。此外,每个方案中有6个专业选项题,而每个专业选项题可为一个线索的候选者,调查表如图 4所示。
 |
| 图 4 调查表 Fig. 4 Questionnaire |
| 图选项 |
这次调查共回收调查表512份,经统计有效结果共452份,具体结果如表 9所示。表中:VN(Very Negative)、N(Negative)、NS(Not Significant)、P(Positive)、VP(Very Positive)依次表示选择调查表中的5种选择结果。线索名由方案序列、线索序列及是否为阳性或阴性结果标识位共3部分组成。如表 9中线索名S1-C1-P,S表示方案(Scheme),S1即为方案1,C1中的C表示方案S1中的线索(Clue),C1表示为线索1,P表示阳性结果,N表示阴性结果。通过评议将4个方案中的24条线索依据阳性结果与阴性结果进行分类,并各有12条,此后将VP与P相加的结果按照降序进行排序,并选择保留阳性结果排名前8的线索。例如第1行S1-C1-P线索,由于该线索名的第3部分是“P”,即阳性线索,故只需计算其P与VP结果之和,其中P占比为40.5%,VP占比为29%,累加结果为69.5%。同理将表 9中VN与N的阴性结果相加进行排序,选择按降序排名前8的阴性结果作为线索。例如线索S1-C2-N,由于该线索名的第3部分为“N”,故只需计算其N与VN的阴性结果之和,其中N占比为54.2%, VN占比为22.4%,累加结果为76.6%。表 9中加粗的线索名表示筛选后有价值的线索。“排序”列中P1~P8表示阳性线索筛选结果降序前8名;同理,“排序”列中的N1~N8表示阴性线索筛选结果降序前8名。为此对共计16条线索进行了基于CSP的符号表示,这些线索已通过工具Z3[22]编译。
表 9 线索的选择 Table 9 Selection of clues
| 线索名 | VN占比/% | N占比/% | NS占比/% | P占比/% | VP占比/% | 排序 |
| S1-C1-P | 0 | 10.2 | 20.3 | 40.5 | 29 | P8 |
| S1-C2-N | 22.4 | 54.2 | 10.4 | 10.6 | 2.4 | N5 |
| S1-C3-N | 41.3 | 26.7 | 21.4 | 10.6 | 0 | |
| S1-C4-P | 0.9 | 6.1 | 40.3 | 31.5 | 21.2 | |
| S1-C5-P | 4.1 | 9.6 | 23.2 | 41.5 | 21.6 | |
| S1-C6-P | 1.2 | 3.1 | 19 | 44.6 | 32.1 | P4 |
| S2-C1-P | 8.2 | 8.9 | 30.9 | 26.6 | 25.4 | |
| S2-C2-P | 1 | 3.1 | 10.2 | 49.6 | 36.1 | P2 |
| S2-C3-N | 36.8 | 29.5 | 28 | 3.7 | 2 | |
| S2-C4-N | 29.5 | 41.8 | 19 | 7.2 | 2.5 | N8 |
| S2-C5-N | 37.1 | 46.3 | 8 | 6.6 | 2 | N3 |
| S2-C6-P | 0 | 11 | 19 | 48.7 | 21.3 | P7 |
| S3-C1-N | 37.8 | 48.4 | 12.3 | 1.4 | 0.1 | N2 |
| S3-C2-N | 22 | 47.6 | 16.3 | 8.1 | 6 | |
| S3-C3-N | 29.6 | 49.4 | 17.6 | 3.1 | 0.3 | N4 |
| S3-C4-P | 0.2 | 2.1 | 19.1 | 57.3 | 21.3 | P3 |
| S3-C5-P | 3 | 7.3 | 18.6 | 51.9 | 19.2 | P5 |
| S3-C6-P | 0.8 | 7.9 | 20.2 | 61.3 | 9.8 | P6 |
| S4-C1-P | 4.1 | 12.6 | 19.7 | 42.3 | 21.3 | |
| S4-C2-N | 35.6 | 52.6 | 9 | 2.3 | 0.5 | N1 |
| S4-C3-P | 6.6 | 12.6 | 18.8 | 46 | 16 | |
| S4-C4-N | 41.6 | 34.9 | 9.9 | 9.2 | 4.4 | N6 |
| S4-C5-P | 0.2 | 0.2 | 1 | 49.6 | 49 | P1 |
| S4-C6-N | 22.9 | 49.8 | 21.5 | 4.2 | 1.6 | N7 |
表选项
5 实验设计与分析 为评估本文的有效性,选用Junit v3.8等4个开源系统进行了设计模式检测实验。表 10描述了这些开源系统的特征参数,而选择这些开源软件系统的依据是:① 系统采用了不同的设计模式进行开发,使得待检测的模式实例具备多样性;② 众多科研工作者皆以此为例进行设计模式检测实验,并存在一个或多个相似的基准例子,方便结果比较;③ 这些系统是开源的项目,可以免费进行设计模式识别,从而降低成本;④ 这些系统有典型的差异性,因此更具代表性。执行实验的操作系统采用Windows XP,CPU为AMD速龙Ⅱ X4 650, 主频3.2 GHz,内存16 G。
表 10 开源系统特征参数 Table 10 Characteristic parameters of open source system
| 系统名称 | 类数 | 千行代码的数目 |
| JhotDraw 6.0b1 | 300 | 19 |
| Junit v3.8 | 56 | 4 |
| Apache ant v1.6.2 | 79 566 | 895 |
| QuickUML2001 | 8 792 | 203 |
表选项
5.1 实验指标 实验评估采用精确率(Pr)、召回率(R)、F-score(F)等指标。此外,也应意识到当待测试系统规模较大时,假阳性FP(False Positive)、假阴性FN(False Negative)的检测结果易产生误差。精确率Pr和召回率R的检测结果决定本文方法的效果,而精确率和召回率又依赖真阳性TP(True Positive)、假阳性FP和假阴性FN 3个重要指标。
1) 真阳性TP:表示正确模式实例检测结果为正确。
2) 假阳性FP:表示错误模式实例检测结果为正确。
3) 假阴性FN:表示正确模式实例检测结果为错误。
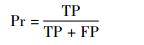 | (3) |
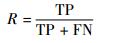 | (4) |
Petterson等[19]提出了融合精确率Pr与召回率R的F-score指标,式(5) 中W为权值,其值给定为2.8,F-score值与设计模式实例恢复的效果成正比。
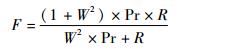 | (5) |
5.2 开源系统设计模式指标值 为方便检测结果的交叉比较,并考虑到设计模式的创建型、行为型及结构型分类[2],依据参考文献[12, 18-19]的结果,项目组成员在此基础上以人工的形式对表 10中4个开源系统的Adapter等4种具有代表性的3类设计模式进行了复核,并通过多次同行评议后给出了表 11的基准结果。
表 11 开源系统中设计模式基准 Table 11 Benchmark of design patterns in open source systems
| 系统名称 | 设计模式 | 模式实例数 |
| Apache ant v1.6.2 | Adapter | 65 |
| State | 4 | |
| Command | 4 | |
| Singleton | 3 | |
| JhotDraw 6.0b1 | Adapter | 35 |
| State | 3 | |
| Command | 2 | |
| Singleton | 2 | |
| QuickUML2001 | Adapter | 38 |
| State | 2 | |
| Command | 1 | |
| Singleton | 1 | |
| Junit v3.8 | Adapter | 14 |
| State | 0 | |
| Command | 0 | |
| Singleton | 2 |
表选项
5.3 3类线索分阶段检测实验 本文旨在检测设计模式实例抽取过程中线索对结果的影响。实验将在原有的CSP检测结果基础上分静态线索、动态线索及专家经验线索阶段逐步进行检测实验,为取得最佳效果,实验允许每个阶段增加线索的过程可迭代。
分析表 12的结果发现,传统的CSP识别技术对State与Singleton模式的识别效果不够理想,2种模式的F指标平均值皆为0%,而Command模式F指标平均值也仅为23%,值得注意的是,Adapter模式的识别效果相对较好,虽然4个开源系统检测后的Adapter模式F指标平均值达到74%,但仍然存在大量的假阳性结果FP与假阴性结果FN。
表 12 传统CSP方法检测与静态线索阶段检测结果 Table 12 Detection results of design pattern in traditional CSP method and static clue stage
| 设计模式 | 测试系统 | 传统CSP方法阶段 | 静态线索阶段 | |||||||||||
| TP个数 | FP个数 | FN个数 | Pr/% | R/% | F/% | TP个数 | FP个数 | FN个数 | Pr/% | R/% | F/% | |||
| Adapter | Apache ant v1.6.2 | 46 | 22 | 18 | 68 | 72 | 72 | 60 | 16 | 4 | 79 | 94 | 92 | |
| JhotDraw 6.0b1 | 30 | 12 | 5 | 71 | 86 | 84 | 33 | 10 | 2 | 77 | 94 | 92 | ||
| QuickUML2001 | 27 | 15 | 11 | 64 | 71 | 70 | 30 | 12 | 8 | 71 | 79 | 78 | ||
| Junit v3.8 | 10 | 6 | 4 | 63 | 71 | 70 | 11 | 5 | 3 | 69 | 79 | 78 | ||
| 平均值 | 66.5 | 75 | 74 | 74 | 86.5 | 85 | ||||||||
| State | ]Apache ant v1.6.2 | 0 | 22 | 4 | 0 | 0 | 0 | 18 | 4 | 0 | 0 | |||
| JhotDraw 6.0b1 | 0 | 18 | 3 | 0 | 0 | 1 | 16 | 2 | 6 | 33 | 22 | |||
| QuickUML2001 | 0 | 13 | 2 | 0 | 0 | 0 | 6 | 2 | 0 | 0 | ||||
| Junit v3.8 | 0 | 0 | 0 | 0 | 4 | 0 | 0 | |||||||
| 平均值 | 0 | 0 | 0 | 1.5 | 11 | 22 | ||||||||
| Command | Apache ant v1.6.2 | 1 | 6 | 3 | 14 | 25 | 23 | 1 | 4 | 3 | 20 | 25 | 24 | |
| JhotDraw 6.0b1 | 0 | 4 | 2 | 0 | 0 | 0 | 1 | 2 | 0 | 0 | ||||
| QuickUML2001 | 0 | 4 | 1 | 0 | 0 | 0 | 3 | 1 | 0 | 0 | ||||
| Junit v3.8 | 0 | 6 | 0 | 0 | 0 | 3 | 0 | 0 | ||||||
| 平均值 | 3.5 | 8.3 | 23 | 5 | 6.3 | 24 | ||||||||
| Singleton | Apache ant v1.6.2 | 0 | 8 | 3 | 0 | 0 | 0 | 1 | 4 | 2 | 20 | 33 | 31 | |
| JhotDraw 6.0b1 | 0 | 6 | 2 | 0 | 0 | 0 | 0 | 3 | 2 | 0 | 0 | |||
| QuickUML2001 | 0 | 4 | 1 | 0 | 0 | 0 | 0 | 3 | 1 | 0 | 0 | |||
| Junit v3.8 | 0 | 4 | 2 | 0 | 0 | 0 | 1 | 3 | 1 | 25 | 50 | 45 | ||
| 平均值 | 0 | 0 | 0 | 11.3 | 20.8 | 38 | ||||||||
表选项
为解决上述问题,本文在静态线索阶段增加了源码结构类、属性、方法、继承关系等线索,从而使检测结果的正确性有所提高。例如,静态线索阶段Adapter模式的F指标平均值由原来的74%上升到85%,而State、Command、Singleton模式的识别效果F指标平均值依次为22%、24%、38%,较传统基于CSP的检测方法有所提高。
为进一步提高检测结果的精确率,本文继续在表 13动态线索阶段增加涉及源码角色间方法调用、参数传递等约束信息的线索引入,从而使得该阶段4个设计模式的平均精确率Pr及平均F值较静态线索阶段有质的提高。分析表 12和表 13的结果发现,动态线索阶段Adapter模式的F指标平均值由静态线索的85%上升到95%,而其精确率Pr指标平均值也由原来静态阶段的74%上升到85%,而State、Command、Singleton模式的识别指标F值较静态线索阶段也有所提高,依次提升为63%、82.3%、88%,该阶段假阳性结果FP与假阴性结果FN显著降低。
表 13 动态线索阶段与专家经验线索阶段检测结果 Table 13 Detection results of design pattern in dynamic clue stage and expert experience clue stage
| 设计模式 | 测试系统 | 动态线索阶段 | 专家经验线索阶段 | |||||||||||
| TP个数 | FP个数 | FN个数 | Pr/% | R/% | F/% | TP个数 | FP个数 | FN个数 | Pr/% | R/% | F/% | |||
| Adapter | Apache ant v1.6.2 | 63 | 12 | 1 | 84 | 98 | 96 | 64 | 0 | 1 | 100 | 98 | 98 | |
| JhotDraw 6.0b1 | 34 | 7 | 1 | 83 | 97 | 95 | 35 | 0 | 0 | 100 | 100 | 100 | ||
| QuickUML2001 | 38 | 6 | 0 | 86 | 100 | 98 | 38 | 0 | 0 | 100 | 100 | 100 | ||
| Junit v3.8 | 13 | 2 | 1 | 87 | 93 | 92 | 14 | 0 | 0 | 100 | 100 | 100 | ||
| 平均值 | 85 | 97 | 95 | 100 | 99.5 | 99.5 | ||||||||
| State | Apache ant v1.6.2 | 3 | 12 | 1 | 20 | 75 | 57 | 3 | 0 | 1 | 100 | 75 | 77 | |
| JhotDraw 6.0b1 | 3 | 3 | 0 | 50 | 100 | 90 | 3 | 0 | 0 | 100 | 100 | 100 | ||
| QuickUML2001 | 1 | 4 | 1 | 20 | 50 | 43 | 2 | 0 | 0 | 100 | 100 | 100 | ||
| Junit v3.8 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | |||||||
| 平均值 | 22.5 | 75 | 63 | 100 | 91.7 | 92.3 | ||||||||
| Command | Apache ant v1.6.2 | 3 | 3 | 1 | 50 | 75 | 71 | 4 | 0 | 0 | 100 | 100 | 100 | |
| JhotDraw 6.0b1 | 2 | 1 | 0 | 67 | 100 | 95 | 2 | 0 | 0 | 100 | 100 | 100 | ||
| QuickUML2001 | 1 | 2 | 0 | 33 | 100 | 81 | 1 | 0 | 0 | 100 | 100 | 100 | ||
| Junit v3.8 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | |||||||
| 平均值 | 37.5 | 91.7 | 82.3 | 100 | 100 | 100 | ||||||||
| Singleton | Apache ant v1.6.2 | 2 | 1 | 1 | 67 | 67 | 67 | 3 | 0 | 0 | 100 | 100 | 100 | |
| JhotDraw 6.0b1 | 2 | 1 | 0 | 67 | 100 | 95 | 2 | 0 | 0 | 100 | 100 | 100 | ||
| QuickUML2001 | 1 | 1 | 0 | 50 | 100 | 90 | 1 | 0 | 0 | 100 | 100 | 100 | ||
| Junit v3.8 | 2 | 0 | 0 | 100 | 100 | 100 | 2 | 0 | 0 | 100 | 100 | 100 | ||
| 平均值 | 71 | 91.75 | 88 | 100 | 100 | 100 | ||||||||
表选项
专家经验线索阶段主要依据专家经验和直觉将一些动态线索与静态线索难以发现的常用知识引入,该阶段进一步排除了假阳性结果FP与假阴性结果FN,识别结果也更加精确,此阶段后Adapter、State、Command、Singleton 4种模式的F指标平均值依次为99.5%、92.3%、100%、100%。
综合表 12与表 13数据发现以下2个问题:
1) 传统的CSP检测方法对4个测试系统中Adapter模式的检测效果较好,而对State、Command、Singleton模式的检测结果不理想。分析原因发现,Adapter属于结构型模式,State、Command属于行为型模式,Singleton属于创建型模式。Gamma将设计模式分为结构型、行为型、创建型3类[1],分析3类设计模式特征发现,行为型模式存在难以追踪的复杂控制流、方法调用机制及参数传递方式等,而创建型模式存在委托等难以复用的关系,以至于很难被共享,可理解为较难发生设计模式实例识别中的重叠问题,而结构型模式使用组合类及对象的方式获得详细的信息,并采用继承机制组合接口,这种方式使其结构具有更强的可扩展性,也更容易被检测。
2) 表 13中,Apache ant v1.6.2系统中在专家经验线索阶段Adapter模式的平均F值为99.5%,经研究发现,该模式在此阶段的FN值为1,即存在一个假阴性结果。经深入研究后发现,由于Adapter与Command模式结构较为相似, 致使Adapter模式被错误识别为Command模式。此外,表 13中,Apache ant v1.6.2系统中在专家经验线索阶段State模式的F值为77%,经研究发现,该模式在此阶段的FN值为1,即也存在一个假阴性结果。由于State与Strategy[1]模式结构较为相似, 致使State模式被错误识别为Strategy模式。
综上所述,上述问题归因于:① 相近设计模式实例之间角色的重叠原因;② 设计模式变体的影响;③ 缺乏对源码中动态数据流的及时分析,导致缺乏对方法调用、参数传递等操作的跟踪与识别。虽然本文方法能够一定程度上解决设计模式实例的重叠问题,但仍不能完全避免假阳性结果与假阴性结果,下一步工作将在上述问题基础上继续深入研究,并发现更多有价值的线索,以取得更好的识别效果。
表 14描述了Apache ant v1.6.2等4个测试系统中Adapter等4个模式实例存在重叠问题的数目,而最后一行统计了4个测试系统中不同设计模式实例发生重叠的总数, 4个测试系统总共识别的Adapter、State、Command及Singleton重叠实例数依次为11、2、3、1。图 5描述了表 14中4种设计模式重叠实例被成功识别的百分比。其中,Adapter模式的实例重叠情况较明显为65%,而深入思考发现Adapter模式属于结构型模式,结构型模式依据组合类及对象以获得更复杂的结构信息,并采用继承机制来组合接口或实现,这样的特点使其结构具有更大的可扩展性,也更容易被识别。
表 14 4个系统设计模式实例重叠统计 Table 14 Design pattern instance overlap statistics in four systems
| 测试系统 | 重叠实例数 | |||
| Adapter | State | Command | Singleton | |
| Apache ant v1.6.2 | 4 | 1 | 1 | 1 |
| JhotDraw 6.0b1 | 2 | 1 | 1 | 0 |
| QuickUML2001 | 4 | 0 | 1 | 0 |
| Junit v3.8 | 1 | 0 | 0 | 0 |
| 结果统计 | 11 | 2 | 3 | 1 |
表选项
 |
| 图 5 4种模式重叠实例识别所占百分比 Fig. 5 Identification percentage of four types of pattern overlapping instances |
| 图选项 |
表 15给出了部分表 14中共享了设计模式的实例。例如,State模式实例与Stratgey[1]模式实例存在重叠,而CH.ifa.draw.framework.DrawingView同时扮演State模式中的Context角色与Stratgey[1]模式中的Context角色,CH.ifa.draw.framework.Painter也同时扮演State模式中的State角色以及Stratgey[1]模式中的Stratgey角色,这属于设计模式中部分角色共享模式实例的情况。此外,Command模式实例属于角色完全共享模式实例的情况,因为Command模式实例与Adapter模式实例发生了完全重叠,其中CH.ifa.draw.util.Command同时扮演了Command模式中Command角色及Adapter模式中Target角色,CH.ifa.draw.framework.DrawingView扮演了Command模式中的Receiver角色及Adapter模式中的Target角色,CH.ifa.draw.util.CommandButton扮演了Command模式中的Invoke角色及Adapter模式中的Adaptee角色。
表 15 JhotDraw中共享了模式的实例 Table 15 Instances of shared pattern in JhotDraw
| (1) State模式实例: //共享部分实例角色 |
| Context: CH.ifa.draw.framework.DrawingView |
| State: CH.ifa.draw.framework.Painter |
| (2) Comand模式实例: //共享全部实例角色 |
| Command: CH.ifa.draw.util.Command |
| Receiver:CH.ifa.draw.framework.DrawingView |
| Invoke: CH.ifa.draw.util.CommandButton |
表选项
5.4 比较实验设计 5.3节中将本文方法与基于CSP的检测方法通过精确率、召回率、F-score指标分阶段进行了比较实验,为进一步检验本文方法,还增加了参考文献[8, 12-13, 15, 18]中提出的方法进行F-score比较实验。
由于在传统的CSP方法基础上融入了交互式线索,并分3个阶段逐步消除假阴性与假阳性结果,由表 16 F-score值可以看出本文方法取得了较好的效果。
表 16 F-score指标比较 Table 16 F-score index comparison
| 检测方法 | 精确率平均值/% | 召回率平均值/% | F-score平均值/% |
| 本文方法 | 100 | 97.8 | 97.95 |
| 文献[8] | 93.8 | 62.1 | 64.57 |
| 文献[12] | 91.14 | 67.21 | 69.27 |
| 文献[13] | 67.76 | 82.11 | 80.19 |
| 文献[15] | 93.65 | 71.82 | 73.77 |
| 文献[18] | 38.74 | 100 | 84.83 |
表选项
6 结论 针对传统设计模式实例恢复结果不够精确及不易于扩展等问题,本文提出一种多阶段交互式线索驱动的设计模式识别方法。
1) 在抽取Guéhéneuc等[21]提出约束满足问题(CSP)方法结果的基础上,将调研取得的专家经验进行反馈,并进一步形成可自定义的线索,避免了不易扩展的问题。
2) 通过线索的约束作用,以迭代的形式分阶段对检测结果进行筛选,避免设计模式实例识别的假阴性与假阳性结果,使得精确率显著提高。
3) 在设计模式实例重叠问题检测方面取得了较好的效果,使得设计模式识别结果进一步优化。
在下一步工作中将对专家经验知识的采样、筛选及如何将演化计算等技术融入设计模式检测展开研究。此外,为了检验本文研究的效果, 将通过更多的开源系统进行验证。
参考文献
| [1] | ZHANG C, BUDGEN D. What do we know about the effectiveness of software design patterns?[J].IEEE Transactions on Software Engineering, 2012, 38(5): 1213–1231.DOI:10.1109/TSE.2011.79 |
| [2] | SCANNIELLO G, GRAVINO C, RISI M, et al. Documenting design-pattern instances:A family of experiments on source-code comprehensibility[J].ACM Transactions on Software Engineering and Methodology, 2015, 24(3): 1–41. |
| [3] | AMPATZOGLOU A, FRANTZESKOU G, STAMELOS I. A methodology to assess the impact of design patterns on software quality[J].Information and Software Technology, 2012, 54(4): 331–346.DOI:10.1016/j.infsof.2011.10.006 |
| [4] | AMPATZOGLOU A, CHARALAMPIDOU S, STAMELOS I. Research state of the art on GoF design patterns:A mapping study[J].Journal of Systems and Software, 2013, 86(7): 1945–1964.DOI:10.1016/j.jss.2013.03.063 |
| [5] | FONTANA F A, MAGGIONI S, RAIBULET C. Design patterns:A survey on their micro-structures[J].Journal of Software:Evolution and Process, 2013, 25(1): 27–52.DOI:10.1002/smr.v25.1 |
| [6] | FONTANA F A, MAGGIONI S, RAIBULET C. Understanding the relevance of micro-structures for design patterns detection[J].Journal of Systems and Software, 2011, 84(12): 2334–2347.DOI:10.1016/j.jss.2011.07.006 |
| [7] | ZANONI M, FONTANA F A, STELLA F. On applying machine learning techniques for design pattern detection[J].Journal of Systems and Software, 2015, 88(5): 102–117. |
| [8] | 肖卓宇, 何锫, 余波, 等. 基于FCA与CBR的设计模式检测[J].山东大学学报(工学版), 2016, 46(2): 22–28. XIAO Z Y, HE P, YU B, et al. Design patterns detection based on FCA and CBR[J].Journal of Shandong University (Engineering Science), 2016, 46(2): 22–28.DOI:10.6040/j.issn.1672-3961.1.2015.046(in Chinese) |
| [9] | CHIHADA A, JALILI S, HASHEMINEJAD S M H, et al. Source code and design conformance, design pattern detection from source code by classification approach[J].Applied Soft Computing, 2015, 26(1): 357–367. |
| [10] | YU D, ZHANG Y, CHEN Z. A comprehensive approach to the recovery of design pattern instances based on sub-patterns and method signatures[J].Journal of Systems and Software, 2015, 88(5): 1–16. |
| [11] | YU D, ZHANG Y, GE J, et al.From sub-patterns to patterns:An approach to the detection of structural design pattern instances by subgraph mining and merging[C]//2013 IEEE 37th Annual Computer Software and Applications Conference (COMPSAC).Piscataway, NJ:IEEE Press, 2013:579-588. |
| [12] | DONG J, ZHAO J, SUN Y. A matrix based approach to recovering design patterns[J].IEEE Transactions on Systems, Man and Cybernatics, 2009, 39(6): 1271–1282.DOI:10.1109/TSMCA.2009.2028012 |
| [13] | BERNARDI M L, CIMITILE M, DI LUCCA G. Design pattern detection using a DSL-driven graph matching approach[J].Journal of Software:Evolution and Process, 2014, 26(12): 1233–1266.DOI:10.1002/smr.v26.12 |
| [14] | SABO M, PORUB?N J. Preserving design patterns using source code annotations[J].Journal of Computer Science and Control Systems, 2009, 32(2): 53–56. |
| [15] | RASOOL G, PHILIPPOW I, MADER P. Design pattern recovery based on annotations[J].International Journal of Advances in Engineering Software, 2010, 41(4): 519–526.DOI:10.1016/j.advengsoft.2009.10.014 |
| [16] | RASOOL G, M?DER P. A customizable approach to design patterns recognition based on feature types[J].Arabian Journal for Science and Engineering, 2014, 39(12): 8851–8873.DOI:10.1007/s13369-014-1449-0 |
| [17] | GARLAN D, MONROE R, WILE D.ACME:An architecture description interchange language[C]//CASCON'97 Proceedings of the 1997 Conference of the Centre for Advanced Studies on Collaborative Research, 2010:159-173. |
| [18] | GUéHéNEUC Y G, ANTONIOL G. DeMIMA:A multilayered approach for design pattern identification[J].IEEE Transactions on Software Engineering, 2008, 34(5): 667–684.DOI:10.1109/TSE.2008.48 |
| [19] | PETTERSON N, L?WE W, NIVRE J. Evaluation of accuracy in design pattern occurrence detection[J].IEEE Transactions on Software Engineering, 2010, 36(4): 575–590.DOI:10.1109/TSE.2009.92 |
| [20] | 肖卓宇, 何锫, 黎妍. 基于设计模式角色的附加关系检测研究[J].计算机应用研究, 2015, 32(7): 2042–2045. XIAO Z Y, HE P, LI Y. Study on the additional relationships based on design pattens's roles[J].Application Research of Computers, 2015, 32(7): 2042–2045.(in Chinese) |
| [21] | GUéHéNEUC Y G, GUYOMARC'H J Y, SAHRAOUI H. Improving design-pattern identification:A new approach and an exploratory study[J].Software Quality Journal, 2010, 18(1): 145–174.DOI:10.1007/s11219-009-9082-y |
| [22] | KITCHENHAM B A, PFLEEGER S L, PICKARD L M, et al. Preliminary guidelines for empirical research in software engineering[J].IEEE Transactions on Software Engineering, 2002, 28(8): 721–734.DOI:10.1109/TSE.2002.1027796 |
| [23] | MERA S, BJ?RNER N.DKAL and Z3:A logic embedding experiment[M]//BLASS A, DERSHOWITZ N, REISIG W.Fields of logic and computation.Berlin:Springer, 2010:504-528. |
