端到端延迟是评估网络实时性能的重要指标[11],可以采用不同的建模方式实现以CBS算法为基础的AVB网络延迟的性能评估。网络演算[12]是一种广泛应用的网络实时性能评估手段,通过对AVB网络到达曲线和服务曲线进行建模,可以实现最坏延迟分析[13],文献[14]在极小加代数下进一步考虑最小服务曲线和最大服务曲线模型,给出了网络演算理论下的完整AVB端到端延迟评估模型,并认为AVB网络能够提供实时性能保障;部分****采用了形式化验证的方法[15]进行AVB性能评估,通过将最坏情况下的网络延迟计算过程转化为时间分析模型[16-17],得到AVB延迟关键参数,并与AVB流量传输需求进行对比,得出AVB网络可以确保关键嵌入式系统定时性能的结论[18]。
现有的研究工作在评价AVB网络的实时性能时,采用的是AVB流模型的CBS算法。当考虑到数据帧在输出端口的实际排队和调度过程时,其调度行为典型具有离散特征,并表现为以帧为调度单位。基于此,本文提出一种帧模型的CBS整形改进算法,并将帧模型与流模型的端到端延迟分析结果进行对比,研究帧模型下网络延迟上界的紧性。
本文首先介绍AVB协议的基本概念,然后给出了最坏情况的延迟计算方法,接着分别推导了流模型和帧模型的延迟计算公式,同时,在车载场景中对这2种模型的端到端延迟性能进行对比分析,最后给出验证结果和结论。
1 基本协议 1.1 精确时间同步协议 精确时间同步协议(generalized Precision Time Protocol,gPTP)中定义了一个最优主时钟算法(Best Master Clock Algorithm,BMCA)[19]用于标识出AVB网络的主时钟,并且gPTP是一种由硬件实现的时间同步机制,它通过路径延迟测算和补偿将主时钟时戳信息匹配到网络中的各个节点上,最终实现整网的时间同步效果。
1.2 流预留协议 流预留协议(Stream Reservation Protocol,SRP)主要用于AVB网络中传输流量的带宽分配与管理,它在网络中定义了2类终端节点:Talker和Listener,Talker作为源节点,会产生待传输的流量,Listener作为目的节点,负责接收流量。SRP协议主要包含预留(Reservation)和注册(Registration)两部分,Talker在传输前会根据SRP预定传输带宽,只有网络带宽足够可用并被Listener注册成功后,AVB流量才可以确认传输。
SRP中定义的带宽预留大小的计算方法为
 | (1) |
式中:MaxFrameSize为流量所对应的数据帧长度;CMI为数据帧的发送周期;MIF为一个发送周期内的帧个数。
协议中推荐将音视频流(AVB流量)分为2类:SR_A和SR_B,并且建议最大75%的网络带宽可用于AVB流量传输,剩余的25%带宽要用于“尽力传输”(Best Effort,BE)类型流量的传输。
1.3 排队及转发协议 排队和转发协议(Forwarding and Queuing for Time-Sensitive Streams,FQTSS)在网络中用于流量整形和优先级排队管理。如图 1所示,在AVB网络中,AVB流量比BE流量的优先级高,同时,AVB流量的不同优先级(SR_A和SR_B)会先采用CBS算法完成各自的流量整形,并且在整形的过程会有不同优先级AVB流量对应信用量的产生和消耗,而BE流量不参与CBS的整形过程,然后再以严格优先级排队规则(Strict Priority Queuing,SPQ)对网络节点中的所有类型流量进行调度。
 |
| 图 1 AVB中流量排队及转发过程 Fig. 1 Queuing and forwarding for AVB streams |
| 图选项 |
SR_A和SR_B在排队传输时依赖2个带宽保障参数idleSlopeA/B和sendSlopeA/B:idleSlopeA/B为AVB流量在节点处等待传输时信用量的增加速率,sendSlopeA/B为AVB流量正在传输时信用量的减小速率,C为总带宽传输速率,三者的关系为
 | (2) |
SR_A和SR_B在网络中要使用CBS算法分别计算各自的信用量CreditA和CreditB,图 2所示的CBS算法的详细规则如下:
 |
| 图 2 CBS算法 Fig. 2 CBS algorithm |
| 图选项 |
1) 只有CreditA/B≥0时,AVB流量才能获得传输机会。
2) 当AVB流量(SR_A或SR_B)到达时,如果节点中正在传输其他优先级流量,这个AVB流量所对应的CreditA/B将在排队的过程中以idleSlopeA/B的速率得到积累,并且最大积累量不超过hiCreditA/B。
3) 当AVB流量正在传输时,它的CreditA/B将会以sendSlopeA/B的速率减少,并且它能够减少到的最小值是loCreditA/B。
4) 如果CreditA/B为正,但此时输出端口中没有AVB流量等待传输,CreditA/B将直接设置为0。
5) 如果CreditA/B为负,此时的AVB流量无法进行传输,CreditA/B将会以idleSlopeA/B的速率恢复至0。
AVB音视频流传输的实际占用带宽可以根据数据帧长度和发送周期进行计算,idleSlopeA/B可以认为是系统设计者为SR_A和SR_B流量传输所配置的逻辑带宽,如何为AVB流量设计所匹配的idleSlopeA/B,涉及系统优化的问题。
最后,在设计优化时一定要保证AVB流量的最大占用带宽不超过网络总带宽传输速率C的75%:
 | (3) |
1.4 音视频桥接系统 音视频桥接系统是AVB网络的总体构成框架,目前在进一步的完善中,相关的研究工作一直在进行,以期实现AVB网络实时性能的进一步扩展。例如,实现高优先级对低优先级流量传输的抢占机制[20],使得高优先级任务获得更小的端到端延迟等。
2 最坏延迟分析 评估AVB网络的实时性能, 主要衡量消息m在网络中传输时,m对应产生的所有流量i在最坏情况下的端到端延迟,在本文的计算方法中,将消息的最坏延迟内容分为下面几种关键延迟。
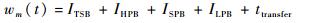 | (4) |
1) 流量整形延迟ITSB:CBS算法中规定,只有当流量i的Crediti≥0时,流量才能够获得传输的机会,ITSB就是Crediti从loCrediti以Ri的速率恢复至0过程中的等待延迟[17],其表达式为
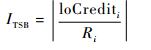 | (5) |
2) 高优先级流量阻塞延迟IHPB:流量i到达网络节点后,需要等待所有高优先级流量传输完毕,才能获得传输机会。
 | (6) |
式中:hp(i)为节点中所有高优先级流量的集合;hj(wm(t))为这些高优先级流量所产生的阻塞延迟。如果节点中存在多条的高优先级消息,则
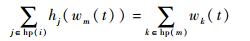 | (7) |
式中:hp(m)为节点中所有高优先级消息的集合; wk(t)为其中的一条消息所产生的阻塞延迟。
3) 相同优先级流量阻塞延迟ISPB:如果节点中存在相同优先级的不同消息,这些消息之间也会产生阻塞延迟。
 | (8) |
式中:sp(i)为节点中所有相同优先级的不同消息对应流量的集合;sj(wm(t))为这些流量所产生的阻塞延迟。在最坏情况下,多条的相同优先级消息所产生的阻塞延迟为
 | (9) |
式中:sp(m)为节点中所有相同优先级消息的集合;wl(t)为其中的一条消息所产生的阻塞延迟。
4) 低优先级阻塞延迟ILPB:AVB网络中规定,高优先级流量对正在传输的低优先级流量是不可抢占的;在最坏情况下,当高优先级流量恰好稍晚于最大帧长的低优先级流量到达时,它得到的最大阻塞延迟为
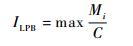 | (10) |
式中:Mi为所有的低优先级流量的最大帧长。
5) 消息传输延迟ttransfer:SR_A和SR_B的传输延迟主要取决于它们能分配得到的逻辑带宽idleSlopeA/B,而CBS算法还决定了流量是否能够获得传输的机会,对于最大突发度为σ的流量的持续传输过程,流量要先积累Credit获得传输的机会, 随后Credit在传输中消耗,这个积累消耗过程会不断进行,直到消息完成传输。
 | (11) |
式中:∑表示流量持续不断传输时传输延迟的积累。
3 帧模型的改进对比 3.1 流模型 在CBS流模型的延迟计算方法中,如图 3所示,流量的排队整形是把流量看作连续比特流持续变化的过程,CBS算法会计算出与流量相对应的信用量的变化。
 |
| 图 3 流模型下的CBS Fig. 3 CBS based on stream model |
| 图选项 |
3.1.1 SR_A延迟分析 SR_A流量的优先级最高,在最坏情况下,它的低优先级阻塞ILPBA为
 | (12) |
SR_A被低优先级流量阻塞的过程中,其积累的hiCreditA为
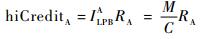 | (13) |
根据CBS算法,SR_A从loCreditA恢复至0过程的整形延迟ITSBA为
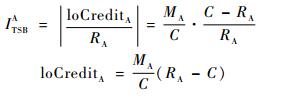 | (14) |
式中:当CreditA恰为0时,节点输出端口开始传输最后一帧数据MA,当传输结束后,SR_A的CreditA便是最小的loCreditA。
综上可得,SR_A在节点中的延迟为
 | (15) |
式中:ttransferA为流量在hiCreditA时能够持续不间断传输的最大时间。
 | (16) |
3.1.2 SR_B延迟分析 在最坏情况下,SR_B流量被低优先级流量阻塞的延迟ILPBB为
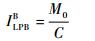 | (17) |
高优先级流量阻塞延迟IHPBB为
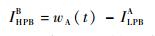 | (18) |
当SR_B被阻塞时,其积累的hiCreditB为
 |
SR_B从loCreditA恢复至0过程的整形延迟ITSBB为
 | (19) |
综上可得,SR_B在节点中的延迟为
 | (20) |
式中:ttransferB为流量在hiCreditB时能够持续不间断传输的最大时间。
 | (21) |
式中:当SR_B和BE的最大数据帧长相等时,等式ILPBB=ILPBA成立,此时:
 | (22) |
3.1.3 BE延迟分析 BE流量不参与整形过程,也不存在低优先级流量的阻塞,其高优先级流量的阻塞延迟为
 | (23) |
BE的传输延迟为
 | (24) |
 | (25) |
3.2 帧模型 在实际网络中,考虑数据排队和调度的离散特性,提出帧模型的延迟计算方法,帧模型是以网络节点中传输的数据帧个数来计算信用量变化的模型,信用量的变化会呈现如图 4中的阶梯状规律曲线。帧模型与流模型延迟分析的主要区别是:在帧模型中,只有信用量足够可用时,输出端口才能完整传输一帧数据,最终在帧模型中得到的延迟评估结果会比流模型减少δ,帧模型中每帧数据的传输相应减小的信用量大小为
 | (26) |
 |
| 图 4 帧模型下的CBS Fig. 4 CBS based on frame model |
| 图选项 |
3.2.1 SR_A延迟分析 类似于流模型,SR_A流量的低优先级阻塞

 | (27) |
SR_A被低优先级流量阻塞的过程中,其积累的
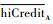
 | (28) |
根据CBS算法,SR_A的信用量从loCreditA恢复至0过程的整形延迟
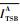
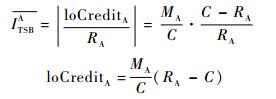 | (29) |
式中:当CreditA恰为0时,节点的输出端口开始传输最后一帧数据MA,传输结束后,SR_A的CreditA便是最小的loCreditA。
SR_A在节点中的延迟为
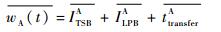 | (30) |
式中:
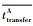
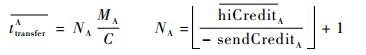 | (31) |
式中:NA的计算要对公式中的变量进行下取整,是节点中通过的数据帧个数。
3.2.2 SR_B延迟分析 SR_B流量被低优先级流量阻塞的延迟
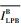
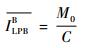 | (32) |
SR_B被高优先级流量所阻塞的延迟为
 | (33) |
SR_B被阻塞时,其积累的

 | (34) |
根据CBS算法,SR_B的信用量从loCreditB恢复至0过程的整形延迟
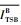
 | (35) |
SR_B在节点中的延迟为
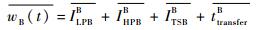 | (36) |
式中:

 | (37) |
式中:NB的计算要对公式中的变量进行下取整,是节点中通过的数据帧个数。
3.2.3 BE延迟分析 在帧模型中,BE的延迟与流模型相似:
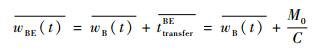 | (38) |
4 应用案例分析 未来的车载驾驶控制技术在安全性因素的考虑下,会采用更多的传感器来采集周边环境的数据,这些传感器探测得到的数据需要实时传输进行处理[2],如车载音视频消息和控制导航消息的传输,这些消息对网络中的传输延迟提出了很高的要求。针对这些车内联网的应用场景,建立了图 5所示的网络拓扑模型[13]来评估本文中改进的帧模型效果,并将其与流模型的结果进行对比。
 |
| 图 5 网络拓扑模型[13] Fig. 5 Network topology model[13] |
| 图选项 |
在上面的网络拓扑模型中,网络的链路带宽C为100 Mbit/s,网络中存在2个交换机(Switch Front/Back)节点,前、后、左、右4个相机模块(Front/Rear/Left/Right Camera)用于采集输出视频类消息(VS),前置模块(HU)是车中内置的综合显示功能模块;总控制模块(CU)通过控制类消息(CS)与其余各功能模块互相通信,并且其余各模块都能发送/接收CS消息;VS的源端是4个相机模块,VS先在顶层模块(TV)中汇聚,然后再传输到HU中显示;同时,后相机模块(RC)还会将它的VS直接传输到HU中显示;HU向后置模块(RU)中传输导航类型消息(MVS),根据SRP的中带宽预留的计算方法,各消息的带宽配置情况如表 1所示[13]。
表 1 流量配置表 Table 1 Traffic configuration
| 消息类型 | 带宽/(Mbit·s-1) | 最大帧长/byte | 突发量/byte |
| SR_A(CS) | 0.512 | 64 | 640 |
| SR_B(VS) | 16.97 | 1 522 | 70 012 |
| BE(MVS) | 15.70 | 1 522 | 65 446 |
表选项
网络中消息的端到端延迟与传输路径和节点带宽配置密切相关,在图 5中,最小的CS消息的端到端延迟存在于RU与CU之间,最大的CS消息的端到端延迟存在于HU与CU之间。
同理,可以分析得到VS和MVS各自消息的端到端延迟情况。对于VS,最小的延迟存在于直接同步显示的RC与HU之间,最大的延迟是在前/左/右3个相机模块中任一个的VS到TV的传输汇聚路径里,在这条传输路径中,4个VS消息都要通过交换机Switch Back的输出端口,如果这4个VS信号的消息同时到达,产生的竞争排队情况会导致VS消息最坏延迟情况的发生。MVS消息在网络中的优先级最低,属于BE类型流量,MVS从HU传输到RU。图 6为场景中计算得到的流模型与帧模型的端到端延迟评估结果。
 |
| 图 6 端到端延迟结果对比 Fig. 6 Comparison of end-to-end latency results |
| 图选项 |
针对图 6的对比结果,从横向上看,帧模型与流模型2个计算方法中的CS、VS与MVS端到端延迟大小与消息优先级有关,2种模型的总体变化趋势是一致的;CS消息的优先级最高,在CBS算法下,CS在网络节点的输出端口排队等待其他消息传输的可能性很小,在最坏条件下只受到低优先级消息最长帧情况的影响;而VS消息的优先级低于CS,在CBS算法下,它在网络节点中需要等待高优先级的CS消息传输完成之后,才可能获得传输的机会,因而得到的延迟结果会比CS大,MVS消息优先级最低,会等待更多的高优先级CS与VS消息才能获得传输机会。
同时,从纵向上看,帧模型下的端到端延迟结果更小;帧模型的CBS算法考虑了数据排队和调度的离散特性,与流模型的CBS相比,帧模型排除了流模型中数据实际不可调度的部分,扣除了相关延迟累计,这种优化的方法使得帧模型中CS与VS消息得到的延迟结果变小,因此帧模型CS与VS消息可以获得更为紧性的端到端延迟结果,并且相比于高优先级的CS消息,低优先级的VS消息排除了更多的延迟累计误差,因而帧模型下得到的VS消息紧性效果就更明显。MVS消息属于BE类型,不通过CBS算法进行整形,因而2种模型下的延迟结果只受到高优先级的CS与VS消息的影响,不会有较大的差异。
5 结论 本文针对AVB网络CBS整形算法延迟进行研究,在考虑了实际网络中数据排队与调度的离散特性情况下,提出一种改进的帧模型CBS算法,经过车载应用案例进行验证,得到:
1) 对AVB网络CBS整形算法的延迟进行分析,通过将阻塞情况分成高优先级阻塞和逻辑带宽阻塞等几个关键组成部分,得到了AVB网络中最坏情况下的端到端延迟计算方法。
2) 基于帧模型的CBS端到端延迟计算方法排除了流模型中数据实际不可调度部分的延迟累计,相比于流模型,其最坏延迟分析结果具有更好的紧性。
3) 帧模型的CBS算法对不同优先级AVB类型消息端到端延迟的改进具有不同的效果,考虑到高优先级消息对低优先级消息延迟分析中的非紧性影响的累加效应,消息的优先级越低,采用本方法获得的紧性评估的改善效果就越为明显。
参考文献
| [1] | IEEE.IEEE 802.1 AVB task group:IEEE 802.1 audio/video bridging(AVB)[R/OL].Piscataway, NJ:IEEE Press, 2012(2012-11)[2016-02-20].http://www.ieee802.org/1/pages/avbridges.html. |
| [2] | CAMEK A, BUCKL C, CORREIA P S, et al.An automotive side-view system based on Ethernet and IP[C]//Advanced Information Networking and Applications Workshops(WAINA).Piscataway, NJ:IEEE Press, 2012, 2012:238-243. |
| [3] | IMTIAZ J, JASPERNEITE J, HAN L.A Performance study of Ethernet audio video bridging (AVB) for industrial real-time communication[C]//ETFA.Piscataway, NJ:IEEE Press, 2009:1-8. |
| [4] | HEIDINGER E, GEYER F, SCHNEELE S, et al.A performance study of audio video bridging in aeronautic Ethernet networks[C]//7th IEEE International Symposium on Industrial Embedded Systems, SIES 2012.Piscataway, NJ:IEEE Press, 2012:67-75. |
| [5] | IEEE.IEEE standard for local and metropolitan area networks-audio video bridging (AVB) systems:IEEE Std 802.1BA[S].Piscataway, NJ:IEEE Press, 2011:1-45. |
| [6] | IEEE.IEEE standard for local and metropolitan area networks—Timing and synchronization for time-sensitive applications in bridged local area networks:IEEE Std 802.1AS-2011[S].Piscataway, NJ:IEEE Press, 2002:1-48. |
| [7] | IEEE.IEEE standard for local and metropolitan area networks, virtual bridged local area networks, amendment 14:Stream reservation protocol (SRP):IEEE Std 802.1Qat[S].Piscataway, NJ:IEEE Press, 2010:1-5. |
| [8] | IEEE.IEEE standard for local and metropolitan area networks, virtual bridged local area networks, amendment 12:Forwarding and queuing enhancements for time-sensitive streams:IEEE Std 802.1Qav[S].Piscataway, NJ:IEEE Press, 2009:1-87. |
| [9] | GEYER F, HEIDINGER E, SCHNEELE S, et al. Evaluation of audio/video bridging forwarding method in an avionics switched Ethernet context[C]//18th IEEE Symposium on Computers and Communications, ISCC 2013.Piscataway, NJ:IEEE Press, 2013:711-716. |
| [10] | GEORGES J P, DIVOUX T, RONDEAU E.Strict priority versus weighted fair queueing in switched Ethernet networks for time critical applications[C]//Parallel and Distributed Processing Symposium.Piscataway, NJ:IEEE Press, 2005:141-148. |
| [11] | LIU J W. Real-time systems[M].New York: Pearson Education Group, 2003: 22-27. |
| [12] | LE B J Y, THIRAN P. Network calculus:A theory of deterministic queuing systems for the internet[M].Berlin: Springer Science & Business Media, 2001: 3-7. |
| [13] | RENE Q.Analysis of Ethernet AVB for automotive networks using network calculus[C]//IEEE Conference on Vehicular Electronics and Safety(ICVES).Piscataway, NJ:IEEE Press, 2012:61-67. |
| [14] | AZUA D, RUIZ J A, BOYER M.Complete modelling of AVB in network calculus framework[C]//Proceedings of the 22nd International Conference on Real-Time Networks and Systems.New York:ACM, 2014:55-56. |
| [15] | HENIA R, HAMANN A, JERSAK M, et al. System level performance analysis-the SymTA/S approach[J].IEE Proceedings:Computers and Digital Techniques, 2005, 152(2): 148–166.DOI:10.1049/ip-cdt:20045088 |
| [16] | AXER P, THIELE D, ERNST R, et al.Exploiting shaper context to improve performance bounds of Ethernet avb networks[C]//Proceedings of the 51st Design Automation Conference.Piscataway, NJ:IEEE Press, 2014:1-6. |
| [17] | DIEMER J, ROX J, ERNST R. Modeling of Ethernet AVB networks for worst-case timing analysis[J].IFAC Proceedings Volumes, 2012, 45(2): 848–853.DOI:10.3182/20120215-3-AT-3016.00150 |
| [18] | DIEMER J, THIELE D, ERNST R. Formal worst-case timing analysis of Ethernet topologies with strict-priority and AVB switching[C]//Industrial Embedded Systems(SIES).Piscataway, NJ:IEEE Press, 2012, 2012:1-10. |
| [19] | IEEE.IEEE standard for layer 2 transport protocol for time sensitive applications in a bridged local area network:IEEE Std 1722-2011[S].Piscataway, NJ:IEEE Press, 2011:1-57. |
| [20] | IMTIAZ J, JASPERNEITE J, WEBER K.Approaches to reduce the latency for high priority traffic in IEEE 802.1 AVB networks[C]//2012 9th IEEE International Workshop on Factory Communication Systems, WFCS 2012.Piscataway, NJ:IEEE Press, 2012:161-164. |
