由于互联网应用的普及,网上资源具有海量性特点,互联网已经成为各行业数据重要的信息源。互联网信息提取[5-6]从传统的信息提取中衍生出来,它将整个互联网空间作为信息源,即从格式复杂、无结构的Web页面中识别出用户感兴趣或有价值的数据[7],并表示成一种语义清晰的结构化形式,使用户和程序能够更方便地查询和使用数据。信息提取技术,依据其自动化程度由低到高,依次分为手工信息提取、半自动信息提取和全自动信息提取[8]。文献[9]以形式化的方法定义了数据的一致性(consistency)、正确性(correctness)、完整性(completeness)和最小性(minimality),而数据质量被定义为这4个指标在信息系统中得到满足的程度。Inmon[10]指出,数据质量是指信息和数据可作为规定应用的可信资料来源的程度,就是在正确的时间、正确的地点,将正确信息的正确集合提供给正确人员,用来支撑决策。
面向应急响应的互联网地震灾情信息处理特点体现为:① 应急响应紧迫,需要系统立刻生成告警信息,并启动互联网信息处理;② 地震事件相关的网页数据具有生命周期性特点,信息提取具有时效性;③ 互联网信息存在大量重复和冗余,需要进行有效的数据筛选。因此,海量互联网信息手动处理几乎不可能,要求处理流程必须自动化。基于此,面向强震应急响应的互联网信息处理包括信息提取、网页信息清洗、灾情数据时序统计、Web灾情信息摘要生成等几部分。
对于互联网上的灾情信息经过提取、清洗后生成可供决策支持的摘要,摘要生成方法研究取得了非常广泛的进展。基于查询的聚类和摘要生成方法对每类文档聚类,生成一个简洁且综合的符合用户查询的摘要[11];用机器学习方法通过检测用户-对象关系来建模,不同用户模型可以独立使用或以一个集成方式使用,对于相同信息源和查询,不同用户能够生成不同的摘要[12]。对于单文档和多文档摘要,预处理把文档分解成句子,选择出突出的句子,随后连接所有选中句子生成摘要[13]。通过语义角色标注假定变量结构来表示源文档的内容,基于优化的特性对假定变量结构分类来生成摘要内容[14]。以事件作为基本语义单元的生成式摘要方法,通过对事件聚类反应篇章的主题分布,并利用事件指导多语句压缩生成自然语句来构建摘要[15]。
对于互联网信息处理的研究涉及到广泛的领域,各种方法都做出相应的贡献,但对于地震应急响应领域研究尚显不足。本文将针对地震应急响应领域以地震事件相关互联网信息提取、灾情相关网页数据清洗、灾害信息时序统计和Web灾情数据摘要生成几部分加以论述。并在笔者所在课题组研发的应用软件系统“国际强震应用处置系统之互联网信息智能处理子系统”中应用上述方法,进行了工程实践与验证。
1 地震事件相关互联网信息提取 地震事件相关的互联网信息具有动态性特点,信息提取贯穿整个地震应急响应过程中,并最终收敛于相对稳定的信息集合。
1.1 相关概念定义 互联网信息提取所涉及的相关概念如下。
定义1??地震事件EthqkEvt=(ID, Time, Location, ThemeSet, Content)。对于一个具体地震事件ethqkevt, 可定义为ethqkevt=(id, t0, l, themeset, content)∈EthqkEvt。
其中:id∈ID为事件对象标识, ID为事件对象标识集合;t0∈Time为事件发生时间,Time为事件发生时间集合;l∈Location为事件发生的地点,Location为事件发生地点集合;themeset={themei|i=1, 2, …, m}∈ThemeSet为某次具体地震事件的互联网灾情信息主题词集合,ThemeSet为多个地震事件的嵌套集合; content∈Content为提取出的主题相关内容,Content为从互联网提取的地震事件相关内容集合。为了表示网页信息提取的动态性特点,用contentt∈Content表示地震事件后的t时刻(t>t0)提取的主题相关内容,Content内容随时间变化动态更新,在某一时刻最终收敛,内容相对不变。
定义2??互联网信息源WIS={WebPagei|i=1,2,…, m}。
其中:WebPagei (1≤i≤m)为互联网信息源中的某类网页。一个特定的信息源wis={webpageit|i=1, 2, …, m}?WIS,webpageit∈WebPagei为t时刻的一个特定网页。
通常某个灾情相关的互联网信息源包含若干类网页,本文所研究提取的网页通常是指地震行业专业网站网页和地震相关的新闻报道。
定义3??灾情信息网页对象webpage={(ID,WebURL, URI, Title, PageContent, Time)}。
其中:WebURL为灾情相关网站地址;URI为网页地址;Title为网页标题;PageContent为网页中的正文内容。
1.2 地震事件相关互联网信息提取的收敛性 互联网上地震事件相关的灾情信息具有生命周期,所有信息源中新增网页随时间增加而减少,直至没有新增网页出现。
设某个地震事件产生时刻为t0,相关信息源wis中灾情相关网页更新时间序列为t0, t1, …, ti, ti+1, …,ti+1=ti+Δt,Δt为更新网页时间间隔。对应该时间序列提取的地震相关正文内容信息集合为contentt0, contentt1,…, contentti, contentti+1, …,contentt0为?。
分别计算此集合序列的上、下极限, 公式分别为式(1) 和式(2)。
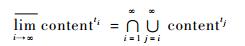 | (1) |
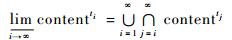 | (2) |
如果上极限和下极限都存在并且相等,即
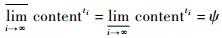
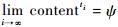
1.3 地震事件相关互联网信息提取算法 对于互联网信息提取算法,给定地震灾害事件ethqkevt,主要的算法描述为
算法1??EERWE(Earthquake Event Related Webpages’ Extraction)
输入:地震事件ethqkevt=(id, t0, l, themeset, content);地震灾情信息源集合WIS;地震相关信息递减时刻经验性界定估值N。
输出:灾情信息contenttend,分时刻的灾情信息统计报告reportt0, reportt1, …, reporttend。
1 ??contentt0←?; i←0
2 ??for each ti do
3 ????content1ti ←ISExtraction(wis1)||
??????content2ti ←ISExtraction(wis2)||…
??????||contentmti←ISExtraction(wism)
4????contentti←content1ti∪content2ti∪…∪contentmti
5 ??contentti←EESRC(contentti)
6 ??reportti←EEDITS(contentti)
7 ??if ti≥tN then
??????disti+1←ContentDistance(contentti-1, contentti)
8 ????if disti+1=-1 then
9??????tend←ti
10??contenttend←contentti
11 ????return contenttend
12????end if
13??end if
14??i←i+1
15 end for
其中:content1ti←ISExtraction(wis1)||content2ti ←ISExtraction(wis2)||…||contentmti←ISExtraction(wism)为每个信息源中的相关网页信息提取;EESRC(contentti)为对ti时刻提取出来的网页对象做重复记录的检测及去重;EEDITS(contentti)为对文本内容集合contentti进行灾情数据时序统计;ContentDistance(contentti-1, contentti)为计算相邻网页内容集合contentti-1和contentti的距离disti+1,若距离disti+1为-1则表示相邻时刻网页内容集合之间的距离数列极限存在,信息提取收敛。
2 灾情相关网页数据清洗 用传统算法对互联网中的海量数据查重,其算法的时间复杂度和空间复杂度偏高。在地震应急响应领域应考虑到数据与地震事件相关度应具有不同优先级。因此本文提出一种改进的数据记录去重算法,具体表现为:定义数据属性优先级并计算相应的权值;对数据记录聚类,然后对所有类单独完成多次匹配。
定义4??权重。
对于某次地震相关数据集D={di|0≤i≤n},其属性向量P=(P1, P2, …, Pk, …, Pm),Pk为第k个属性,每个属性赋予不同值代表该属性的重要程度,称为属性的权重。对应于属性向量P的权重向量可表示为W=(W1, W2, …, Wk, …, Wm),则任一数据di可表示为(di1, di2, …, dik, …,dim)。记录的相同属性值越多,并且相同属性的权重值越大,则记录的相似度越高。
2.1 属性字段权重计算 计算地震数据集属性字段权重的算法分3步:① 行业专家为各个属性字段指定优先级;② 取各专家指定属性字段优先级的均值作为该属性的最终优先级;③ 采用RC(Rank-Centroid)算法[16]计算各属性字段的权重,属性Pk的权重Wk算法见式(3)。
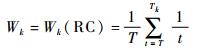 | (3) |
式中:T为专家指定最低优先级,数值最小;Tk为属性Pk的最终优先级。
2.2 数据集聚类 针对某次地震从互联网提取的数据集,按权重最高的属性字段进行聚类,从而形成若干小数据集,采用LP算法[17]聚类过程为:① 将元素d1, d2, …, dn分别插入初始为空的集合S1, S2, …, Sn,分别计算集合间彼此的相似度sim;② 当sim≥γ(阈值),则合并为一个集合;③ 对未执行聚类的集合进行聚类,直至不存在未执行过聚类的单元素集合。
2.3 字段匹配 字段匹配算法用于计算不同记录同一属性字段之间的相似度。先把各属性中的字符串分解为多个具有独立意义的原子串,再分别比较不同记录同一属性的每个原子串的相似度,最后计算出不同记录的字段相似度。
在地震应急响应领域,把文本串和数字作为独立的原子串处理,如“死亡25人”。字段相似度的算法如式(4) 所示。
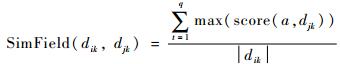 | (4) |
式中:a为记录dik中的原子串,与djk中的所有原子串匹配后,score(a, djk)为计算所得相似度,且0≤score(a, djk)≤1;|dik|为记录dik的长度;q为记录dik的原子串个数。
2.4 清洗重复记录 对于不同组的重复记录,选择包含与主题词相关度高的属性值的记录,从中选取网页更新时间最近的予以保留,其余删除。生成完整的无重复的数据集。
灾情相关网页数据检测和清洗描述如下。
算法2??EESRC(Earthquake Event Similarity Record Clearing)
输入:数据集content,属性向量P=(P1, P2, …, Pk, …, Pm)。
输出:处理掉重复记录后的数据集。
1 ??W1, W2, …, Wm←Weight(P)
2??S1, S2, …, Sn←Clustering(content)
3??flag1, flag2, …, flagn←0
4??for each S←S1, S2, …, Sn do
5????选取排序关键字key
6????S′←sort (S, key)
7????for each pi∈S′, 1≤ i ≤|S′|do
8??????for each pj∈S′, i≤ j ≤|S′| do
9????????if SimRecord(pi, pj) >γ then
10??????????if flagi=0 and flagj=0 then
11????????????flagi←i; flagj←i
12??????????else
13????????????if flagi=0 then flagi←flagj
14????????????else flagj←flagi
15????????????end if
16????????????end if
17??????????end if
18????????end for
19??????if满足多趟查找结束条件then return
20??????end if
21????end for
22????依据flag1, flag2, …, flagn处理重复记录
23??end for
3 地震灾害数据时序统计 3.1 地震应急响应领域的词典定义 在地震应急响应领域,涉及3个方面的数据内容:灾情方面、灾区方面、处置需求。每一方面由多个相关关键词组成。本文中采用XML定义词典。
定义5??词典。
<Dictionary>
? <Word type="灾情">
? <Word> <MainWord> 死亡 </MainWord>
? <SameWord> 丧生 </SameWord>
? </Word>
?…
? <Word> …</Word>
<Word type="灾区方面">
? <Word> <MainWord> 山体滑坡 </MainWord>
? </Word>
?…
</Dictionary>
其中:MainWord标签为主词;SameWord标签为同义词。把主词与同义词权重之和作为内容(content)中主题词的权重。
3.2 数据集中权重高的生词提取 在互联网信息提取过程中,把高权重的生词做为新的主题词处理。
处理的主要步骤为
1) 把词典中的主词(mainword)添加到主题词集合中,计算各个主题词在内容(content)中的权重。
2) 计算内容(content)中分词处理后的词项权重。
3) 若其权重大于主题词权重平均值,则取出该词项作为生词加入到主题词集合中。
具体算法如下所示:
算法3??HighWeightWordExtracting (Dictionary, content)
输入:词典Dictionary, 地震时间相关互联网信息提取内容content。
输出:主题词集合Word。
1??Word←?
2??for each wordi, 1≤i≤N, wordi∈Dictionary do
3????weighti←TF(mainword)*IDF(mainword)
4????weighti←weighti+
????????∑ TF(sameword)*IDF(sameword)
5????Word←Word∪{wordi}
6??end for
7??j←1
8??for each w do
9????weight←TF(w)*IDF(w)
10?????if weight>average(weight1, weight2, …, weightN) then
11????????wordN+j←w, weightN+j←weight
12????????Word←Word∪{wordN+j}
13????????j←j+1
14????end if
15??end for
其中:TF(mainword)为mainword在地震事件相关提取内容content中出现的频率;IDF(mainword)为content中包含mainword的记录数目的反频率;TF(mainword)*IDF(mainword)计算主词mainword在content中的权重;∑TF(sameword)*IDF(sameword)计算该主词的所有同义词sameword在content中的权重之和,将该主词与其所有同义词的权重相加作为该主题词在content中的权重。average(weight1, weight2, …, weightN)为主题词集合中属于词典中的主题词在content中的权重的平均值,N为上述主题词的个数。
3.3 地震灾害主题词时序统计 使用二分法对地震灾害主题词进行时序统计,取数据集中网页更新时间最早的时间点与当前系统时间中间的时间段,平均切分成2个时间段,然后分别再次递归使用二分法针对各个小时间段内主题词进行时序统计,直至该时间段时长小于最小时间间隔或者该时间段内主题词的频数小于最小密度,则作为叶子节点结束切分。最终生成一棵以切分结果为节点的二叉树,并返回该二叉树的根节点。
在描述具体的算法步骤前,需要先定义作为时序统计切分结果的时序对象TimeTrace,定义为七元组。
定义6??时序对象TimeTrace=(Word, PageSet, TL, TR, LeftSon, RightSon, WPAGE),对一个具体的时序对象timetracetltr,可定义为timetracetltr=(word, contenttltr, tl, tr, leftson, rightson, wpage)∈TimeTrace。
其中:timetracetltr为一个具体的tl到tr时间段内的时序对象,tl∈TL,TL为统计时间段开始时间集合,tr∈TR,TR为统计时间段结束时间集合;word∈Word为一个主题词,Word为主题词典Dictionary中主题词集合;contenttltr?PageSet为网页更新时间在tl到tr时间段内的互联网信息提取内容集合,PageSet为全部互联网信息提取内容的嵌套集合;leftson∈LeftSon为该时序对象在时序统计中时间划分的左子节点,LeftSon为左子节点集合;rightson∈RightSon为该时序对象在时序统计中时间划分的右子节点,RightSon为右子节点集合;wpage∈WPAGE为该时间段内该主题词出现频率最高的代表网页对象,WPAGE为互联网提取的网页集合。主要的算法步骤描述为
1) 取起始时间和结束时间,若该时间段长小于最小时间间隔或者其主题词出现的频率小于最小密度,则取出该主题词出现频率最高的网页对象作为该时序对象的代表文本并返回。
2) 否则,取从起始时间到结束时间这一时间段的中间时刻,把该时间段平均分为2段时间,并分别对2段时间递归进行该主题词的时序统计分析。
3) 合并2个时间段的时序对象。
详细的算法步骤如下所示:
算法4??TimeAnalysis(word, tl, tr, contenttltr)
输入:主题词word,起始时间tl,结束时间tr,tl到tr时间段之内的地震事件相关内容集合contenttltr。
输出:该段时间内的时序对象timetracetltr。
1??if tr-tl < 最小时间间隔or count < 最小密度
??????then
2??????wpage←word //出现频率最高的网页对象
3??????timetracetltr←(word, contenttltr, tl, tr, null, null, wpage)
4??else
5????m←(tl+ tr)/2
6????timetracetlm←TimeAnalysis(word, tl, m, contenttlm )
7????timetracemtr←TimeAnalysis(word, m, tr, contentmtr)
8????timetracetltr←merge(timetracetlm, timetracemtr)
9??end if
其中:merge(timetracetlm, timetracemtr)将2个具体的时序对象timetracetlm和timetracemtr进行合并,生成的时序对象timetracetltr为(word, contenttlm∪contentmtr, tl, tr, leftson, rightson, wpage),leftson指向timetracetlm,rightson指向timetracemtr,wpage为word在tl到tr时间段内出现频率最高的网页对象。
3.4 灾害信息时序统计算法描述 算法5??EEDITS(Earthquake Event Disaster Information Timing Statistics)
输入:数据集content。
输出:时序统计图。
1??定义主题词典Dictionary
2??Word←HighWeightWordExtracting (Dictionary, content)
3??M←Word中的主题词数目, starttime←after{地震发生时间t0, content中最早的网页更新时间}, endtime←content中最晚的网页更新时间
4??for each wordi, 1≤i≤M do
5???timetracetltr←TimeAnalysis(wordi, starttime, endtime, content)
6??end for
7???生成时序统计图
其中:HighWeightWordExtracting (Dictionary, content)将词典中的主题词和content中权重大的生词组成统计的主题词集合,after{地震发生时间t0, content中最早的网页更新时间}表示统计开始时间取2个时间中更新的时间,TimeAnalysis(wordi, starttime, endtime, content)针对于主题词在starttime到endtime时间段内的content集合进行时序统计。
4 Web灾情数据摘要生成 对提取的网页摘要生成前首先需要进行预处理。首先,将HTML文档通过浏览器解析成DOM树,然后通过HtmlParser解析提取出网页正文,从DOM树中通过网页去噪得到摘要分析的正文,最后将正文划分成句子的组合。接下来采用摘要生成算法进行摘要生成。
多文档摘要生成算法用于地震相关文档生成的主要算法之一,使用TextRank算法提取出每篇文档的摘要句。先将文本句子拆分,过滤掉文档中“的、了”等常见的停用词,将此句子的集合按关键词所在的句子位置进行权重计算,一般网页段落的首尾句为关键句,加入摘要句集合,例如句子若包含地震地点名称,则说明该句子包含描述地震的重要信息,可以提取出该句子中的数字作为死亡人数、建筑物倒塌等数据,生成随时间发布的网页信息走势图,最终可以插入到文档中。对于一个文档F,可定义为一个n维向量。
定义7??文档F=F(w1, w2, …, wi, …, wn)。
其中:n为文档内容的词语总数;wi为每一个词语的权重。
对于用户趣向内容的可定义为一个向量。
定义8??用户趣向向量U=U((y1, u1), (y2, u2), …, (yi, ui), …, (yn, un))。
其中:yi为用户感兴趣的词语;ui为yi的权重。
通过计算上述2个向量的夹角的余弦值,得出文档与用户趣向相似度。相似度越大,表示该文档满足用户的需求程度越大,相似度如式(5) 所示。
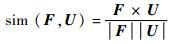 | (5) |
多文档摘要生成是根据文档中的主题词,先用余弦相似度计算出哪些文档可以比较接近用户的需求。对于向量U用地震应急响应主题词,如“地震、死亡、伤亡、建筑物倒塌”等,加上地点,如“北川、雅安”等及相应权重表示用户兴趣度高的向量,计算出比较相似的文档集合。
如用p1进行余弦度计算表示想找出“汶川地震”关键词比较相似的文档集合,p2进行余弦度计算表示想找出“北川建筑物倒塌”关键词比较相似的文档集合,p3进行余弦度计算表示想找出“捐助”关键词比较相似的文档集合,其中0≤p1,p2,p3≤1,为余弦相似度值。根据用户对用户趣向向量U的不同定义,在网页信息处理时对数据库中关于该地震事件的搜索结果进行分类。
分类后得到A类、B类等,如果对A类中包含较多主题词的文档,其中句子权重最高,则选择该网页为代表A类的文档,再对文档中的句子进行提取。
5 应用系统案例 针对笔者所在课题组研发的应用软件系统“国际强震应用处置系统之互联网信息智能处理子系统”,应用上述方法进行了研发工作。其系统架构如图 1所示。
 |
| 图 1 互联网信息智能处理子系统组织架构 Fig. 1 Architecture of subsystem of Internet information intelligent processing |
| 图选项 |
互联网信息智能处理子系统主要包括搜索层、处理层、存储层、服务层等几个层次构成。其中,搜索层主要利用搜索引擎对专业地震信息网站、综合信息网站、核心网站实现互联网搜索、内容维护、采集源维护以及搜索模板管理等工作。然后提交处理层进行信息的后续处理工作;处理层主要实现对采集的网页内容进行信息提取、过滤、分拣以及统计等工作及主题字典管理。利用分类结果更新主题队列、有关词频统计以及提取生词,最终完成互联网信息的搜索与处理;存储层主要对样本分析模板库、本体词典库、信息库以及快照库实现统一的存储与访问管理;服务层面向用户及其他子系统提供信息访问服务,包括信息自定义查询、信息统计、话题追踪以及任务管理等几个功能。
5.1 信息提取算法收敛性实验验证 实验选取2014年10月7日21时49分云南景谷地震,对本节中提出的地震应急救援领域互联网信息提取算法的收敛性进行验证。选用中国地震局、美国地质调查局(USGS)、凤凰网、人民网、新华网、新浪网、BBC几个网站作为信息源,从地震发生时刻起,采用本文提出的互联网信息提取算法对云南景谷地震的信息进行提取。同时,为评估信息提取效果,在地震发生时刻起,在各个信息源中一直进行爬虫抓取,提取了34 970张网页作为实验样本。设定充分大的N,取一周时间与信息源更新网页时间间隔的比值,经统计,相关信息网页更新时间间隔设为5 min,则取N值为2 016,地震发生一周的时间后计算相邻时刻信息提取内容的距离,当N为2 541时收敛,其content内容变化如图 2所示。
 |
| 图 2 内容提取收敛性 Fig. 2 Content extraction convergence |
| 图选项 |
从图 2中的实验结果表明,地震应急响应领域互联网信息提取在大约地震发生一周之后逐渐开始收敛。地震应急响应领域专家主要包括科学研究专家、管理人员和现场救援人员。在进行震后应急响应的相关研究时,重点研究震后一周左右时间内的地震发展概况来辅助地震救援。现场救援人员在地震领域的黄金72 h之内争取尽量多地救出伤员,72 h之后继续营救,在一周左右的时间之后现场救援工作也逐渐收尾。管理人员在地震发生之后制定救援方案,并在之后的一周左右的时间内,调整各项救援工作安排。实验结果与领域专家的经验正好吻合,验证了互联网信息提取过程的收敛性,即验证了其时效性。
5.2 相似重复记录清洗实验 查找相似重复记录算法的效性指标有查全率和查准率。Xa为原数据集真实存在的重复记录集合,Xb为识别出来的重复记录集合,则查准率表示为|Xa∩Xb|/|Xb|,查全率表示为|Xa∩Xb|/|Xa|。分别选取云南景谷地震、四川康定地震真实地震案例数据,对其内容进行插入、删除、替换和交换等操作,并按照100%、200%、300%的比例引入重复元素形成3个重复度逐渐增大的数据集,然后计算其平均查全率和查准率。本文提出的算法与近邻记录排序方法(Sorted Neighborhood Method,SNM)和多趟近邻排序算法(Muli-Pass sorted Neighborhood,MPN)[18-19]算法相比较,在查全率、查准率上进行实验,针对不同冗余度的数据进行清洗的实验结果如表 1所示。本文提出的相似重复记录清洗算法的查全率查准率保持在95%左右,表现较好。
表 1 3种算法查全率、查准率对比 Table 1 Comparison of recall ratio and precision ratio among three algorithms
| % | ||||||
| 冗余度 | 查全率 | 查准率 | ||||
| SNM | MPN | 本文 | SNM | MPN | 本文 | |
| 100 | 80 | 90 | 94 | 83 | 88 | 93 |
| 200 | 79 | 91 | 96 | 88 | 89 | 95 |
| 300 | 76 | 90 | 95 | 90 | 90 | 95 |
表选项
5.3 灾害信息时序统计 选取云南景谷真实地震案例作为地震事件样本,选取其经过数据清洗之后的数据集作为本部分实验样本,为便于分析,词典中仅定义少量主题词,即泥石流、海啸2个主题词,提取出生词余震、消防、泥石流、救灾、灾区、救援、受伤、慈善、记者、得主、广播,最终的时序统计分析图如图 3所示。
 |
| 图 3 地震事件时序统计 Fig. 3 Time series statistics of earthquake events |
| 图选项 |
5.4 摘要生成 选取2015年4月25日尼泊尔8.1级地震为例,系统生成的Office Word版的摘要文档如图 4所示;相关舆情简报如图 5所示。
 |
| 图 4 摘要文档 Fig. 4 Summary document |
| 图选项 |
 |
| 图 5 舆情简报 Fig. 5 Public opinion briefing |
| 图选项 |
对于面向地震应急响应的互联网信息智能处理,本文提出了一套完整的方法,并得出基于特定地震事件的摘要生成及舆情简报,为地震应急响应提供了决策支持的依据。
6 结论 本文针对地震应急响应互联网信息智能处理展开了研究,研究结果如下:
1) 基于对地震应急救援领域应用需求与相关技术的全面调研和深入分析,首先定义了事件模型、网页对象模型,然后针对应急需求,在分析网页更新的规律和生命周期后,提出了互联网信息提取过程的收敛性定义,通过引入极限,定义收敛性来刻画互联网信息提取过程的时效性。
2) 分析了地震事件特点,提出了一种支持动态收敛性的互联网信息提取算法EERWE,并对其中的关键步骤进行研究,将标准向量空间模型改进为多向量空间模型,并扩展定义了互联网信息时效性,使其具有动态性,能够准确评估具有时效性特点的互联网信息提取效果。
3) 分析了地震救援领域的网页信息较容易出现的数据质量问题,提出了网页相似重复记录的检测和清洗算法EESRC,并进一步在清洗后的数据基础上,提出一种针对灾害信息随时间的变化进行时序统计的算法EEDITS,形成信息统计报告。
4) 提出了面向地震应急响应的摘要生成和舆情简报算法,可以生成针对某次地震的摘要以及舆情简报,为制定救援方案决策提供依据。
最后,通过应用于国际强震应用处置系统之互联网信息智能处理子系统,为地震应急响应提供了保障。
参考文献
| [1] | 中国地震局. 历史地震目录[EB/OL]. 北京: 中国地震局, 2016(2016-06-14)[2016-09-10]. http://www.cea.gov.cn/publish/dizhenj/468/496/index.html. China Earthquake Administration.The record of earthquake history[EB/OL].Beijing:China Earthquake Administration, 2016(2016-06-14)[2016-09-10].http://www.cea.gov.cn/publish/dizhenj/468/496/index.html(in Chinese). |
| [2] | 新华网. 四川汶川地震抗震救灾进展情况[EB/OL]. 北京: 新华网, 2008(2008-06-22)[2016-09-10]. http://news.xinhuanet.com/newscenter/2008-06/22/content_8417853.htm.Xinhuanet. Report on the earthquake rescue in Wenchan, Sichuan[EB/OL].Beijing:Xinhuanet, 2008(2008-06-22)[2016-09-10].http://news.xinhuanet.com/newscenter/2008-06/22/content_8417853.htm(in Chinese). |
| [3] | 赵亚辉. 汶川地震直接经济损失8 451亿元[EB/OL]. 北京: 人民网, 2008(2008-09-05)[2016-09-10]. http://society.people.com.cn/GB/41158/7805669.html. ZHAO Y H.Direct economic losses of 845 billion 100 million yuan in Wenchuan earthquake[EB/OL].Beijing:People, 2008(2008-09-05)[2016-09-10].http://society.people.com.cn/GB/41158/7805669.html(in Chinese). |
| [4] | 霍娜. 突发事件追踪报道信息提取的研究[D]. 太原: 山西大学, 2012: 19-25. HUO N.Research of sudden event information extraction of tracking reports[D].Taiyuan:Shanxi University, 2012:19-25(in Chinese). |
| [5] | HE J, GU Y Q, LIU H Y, et al. Scalable and noise tolerant web knowledge extraction for search task simplification[J].Decision Support Systems, 2013, 56(5): 156–167. |
| [6] | SLEIMAN H A, CORCHUELO R. A class of neural-network-based transducers for web information extraction[J].Neuro computing, 2013, 135(5): 61–68. |
| [7] | 侯明燕. 基于网页信息定位的数据抽取技术的研究[D]. 广州: 暨南大学, 2011: 32-37. HOU M Y.Data extraction technology research based on the location of Web information[D].Guangzhou:Jinan University, 2011:32-37(in Chinese). |
| [8] | AO J, ZHANG P, CAO Y N. Estimating the locations of emergency events from Twitter streams[J].Procedia Computer Science, 2014, 31: 731–739.DOI:10.1016/j.procs.2014.05.321 |
| [9] | AEBI D, PERROCHON L.Towards improving data quality[C]//Proceedings of the International Conference on Information Systems and Management of Data.Delhi:Sarda, 1999:273-281. |
| [10] | INMON W H. DW2. 0: 下一代数据仓库的架构[M]. 王志海, 王建林, 译. 北京: 机械工业出版社, 2010: 174-180. INMON W H.DW2.0:The architecture for the next generation of data warehousing[M].WANG Z H, WANG J L, translated.Beijing:China Machine Press, 2010:174-180(in Chinese). |
| [11] | QUMSIYEH R, NG Y K. Enhancing web search by using query-based clusters and multi-document summaries[J].Knowledge and Information Systems, 2016, 47(2): 355–380.DOI:10.1007/s10115-015-0852-5 |
| [12] | VALIZADEH M, BRAZDIL P. Exploring actor-object relationships for query-focused multi-document summarization[J].Soft Computing, 2015, 19(11): 3109–3121.DOI:10.1007/s00500-014-1471-x |
| [13] | ALGULIYEV R M, ALIGULIYEV R M, ISAZADE N R. An unsupervised approach to generating generic summaries of documents[J].Applied Soft Computing, 2015, 34(9): 236–250. |
| [14] | KHAN A, SALIM N, KUMAR Y J. A framework for multi-document abstractive summarization based on semantic role labeling[J].Applied Soft Computing, 2015, 30(5): 737–747. |
| [15] | 王振超, 孙锐, 姬东鸿. 基于事件指导的多文档生成式摘要方法[J].计算机应用研究, 2016, 34(2): 343–346. WANG Z C, SUN R, JI D H. Event-guided method for abstractive multi-document summarization[J].Application Research of Computers, 2016, 34(2): 343–346.(in Chinese) |
| [16] | DEY D, SARKAR S, DE P. A distance-based approach to entity reconciliation in heterogeneous databases[J].IEEE Transactions on Knowledge and Data Engineering, 2002, 14(3): 567–582.DOI:10.1109/TKDE.2002.1000343 |
| [17] | 姚清耘, 刘功申, 李翔. 基于向量空间模型的文本聚类算法[J].计算机工程, 2008, 34(18): 39–44. YAO Q Y, LIU G S, LI X. VSM-based text clustering algorithm[J].Computer Engineering, 2008, 34(18): 39–44.DOI:10.3969/j.issn.1000-3428.2008.18.014(in Chinese) |
| [18] | HERNáNDEZ M A, STOLFO S J. Real-world data is dirty:Data cleansing and the merge/purge problem[J].Data Mining and Knowledge Discovery, 1998, 2(1): 9–37.DOI:10.1023/A:1009761603038 |
| [19] | HERNáNDEZ M A, STOLFO S J.The merge/purge problem for large databases[C]//Proceedings of International Conference on Management of Data.New York:ACM SIGMOD, 1995:127-138. |
