在NoC上实现高效多播最首要的任务是进行多播应用的任务映射。现已有很多科研人员对有线NoC的任务映射进行了研究,提出了利用蚁群算法、遗传算法、离散粒子群算法和NAGA-II等对延时或功耗进行优化的映射策略。传统的多播数据通过多播树(Multicast Tree, MT)传播,已有的多播树构造算法包括最短路径多播树的Dijkstra算法[5]、Bellman-Ford算法[6]、最小代价多播树的KMB算法[7]和MPH算法[8]等。然而由于多播树自身结构的局限性,无法实现多播传输的最大容量。Ahlswede等[9]用网络编码技术对网络中间节点接收到的信息进行“融合”处理,从而使网络的数据传输速率逼近多播容量的极限。张思为[10]提出了一种基于局部总线的NoC架构,首次将网络编码引入NoC。Shalaby[11]和Vonbun[12]等验证了在NoC上采用蝶形网络编码的设计用于路由跳数和数据包存活数上的性能优势。然而,蝶形结构是网络编码中最简单的一种结构,只适用于多播业务信源和信宿都为2的情况,应用范围受限,故缺乏通用性。为了解决此问题,本文从网络编码的原理出发,提出了一种适用于多播业务的无线NoC平台,利用网络编码构造与任务映射的相对独立性,设计出采用网络编码的无线NoC的两步映射算法,以降低延时、减小功耗与提高网络传输效率为目标,建立了基于网络编码的无线NoC资源映射模型与网络编码映射模型。仿真结果表明,在多种多播业务模式下,与普通无线NoC相比,本文提出的网络架构及映射算法能够至少节约6%的功耗,并得到16%的吞吐率增益,同时具有较小的复杂度开销。
1 网络编码原理 假定多播网络G(V, E)的信源产生的信息用符号向量x=(x1, x2, …, xh)表示,h为多播的最大理论传输容量,信宿接收的信息由符号向量y=(y1, y2, …, yh)表示。对于线性网络编码,其链路传输的信息、网络节点接收与发送的信息均为信源信息x中各元素的线性组合,即yi=qi1x1+qi2x2+…+qihxh=fei·x T,i=1, 2, …, h,fei为信宿的第i条接收边ei上的全局编码向量,qij为转移变量,用矩阵表示,可得
 | (1) |
式中:Q为转移矩阵,当其可逆,信宿可译码得出信源信息x,即x=(Q -1 y T)T。
为了实现简单,采用线性网络编码,在中间节点与信宿节点进行的编码操作被简化为对接收到的数据进行模二加运算。模二加运算是数字电路中最基本的异或运算,在集成电路里实现非常简单,而信宿节点收到多条入边送来的数据包后,交给其处理节点进行译码操作,还原为信源信息,不会增加路由节点的复杂度,因此在无线NoC上应用网络编码的实现复杂度非常低。
2 无线NoC平台 2.1 互联模型 无线NoC中,每个节点上放置一个低功耗UWB天线,通过无线射频接口将数据高速广播到相邻节点。天线的广播范围决定了无线NoC的拓扑。当节点以网格形式放置,并且天线的传输距离为网格中相邻2个节点之间的距离时,该网络的拓扑为有线NoC中最常用的Mesh拓扑。本文以Mesh拓扑为例进行研究。不失一般性,该平台设计与映射算法也可以应用在其他NoC拓扑上。图 1为无线Mesh NoC互联结构示意图。每个无线路由节点(R)与一个处理节点(PE)相连,路由节点间采用双向数据传递。
 |
| 图 1 无线Mesh NoC互联结构示意图 Fig. 1 Schematic of wireless Mesh NoC interconnection architecture |
| 图选项 |
2.2 路由机制 与有线NoC类似,数据路由与网络拓扑有关,例如Mesh拓扑可采用xy路由,数据包从源到目的先沿着x轴方向传输,再沿着y轴方向传输。具有网络编码功能的节点必然需要额外的逻辑资源进行编码,面积和功耗相比也会较大。出于复杂度考虑,在NoC上会采用较简单的网络编码结构,其对应的编码节点个数较少,因此仅需要为网络中部分路由节点增加编码操作逻辑。
综上所述,网络中的无线路由节点分为2类:编码节点(进行网络编码的节点)和非编码节点(不进行网络编码的节点)。编码节点对接收到的来自多条链路的数据包进行网络编码操作,然后广播转发;而非编码节点直接将接收到的数据进行广播转发。为了保证数据快速地从源扩散到目的,并且避免死锁,采用最短路径算法,即数据包在x轴或y轴方向上只能沿着从源节点到目的节点的方向进行传输,而不能进行反向传输。
2.3 信道复用 无线NoC上,数据以局部广播的方式进行传播,某节点发送数据,其所有相邻节点都会收到。为了能让广播范围重叠的相邻节点同时传输数据,以达到在节点对不同路径到来的数据进行编码的目的,片上无线链路采用信道复用的方式,即用TDMA、FDMA、CDMA或它们的组合方式对冲突链路进行区分。这里以FDMA为例,为了避免冲突,传输域交叠的节点采用不同的载波发射频率,即与任一个节点相邻的各节点必须采用不同载波频率。
节点载波频率的分配问题是一个典型的边(点)着色问题。根据文献[13]的着色算法可确定载波个数χ的取值范围为
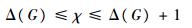 | (2) |
式中:Δ(G)为图G的顶点的最大度。
本文主要研究基于网络编码的映射问题,故暂不考虑信道仲裁和分配过程,即假设信道是逻辑独立的。
2.4 网络编码策略 数据在网络的传输过程中,不同节点送来的数据包由于经过的路径不同,以及网络拥塞等原因,到达同一节点的时间可能会不一致。而进行网络编码的路由节点必须在收到所有路径送来的数据包后才能进行编码操作。因此,当路由节点收到一条路径送来的数据后,需要将数据保存在缓存中,等待其他路径的数据到来后一起编码。若各条路径的数据到达时间差较大,则路由节点需要较大的缓存空间,对NoC有限的存储空间提出挑战。为了解决此问题,本文采用缓存感知的网络编码策略。网络的最优缓存大小为B0[14],如果多条路径的数据没有同时到达,则将先到的数据保存在缓存里,等待其他路径的数据都到达后进行编码发送。若等待的时间超过门限值,则先到达的数据无需进行网络编码,直接排队等待传输。这样既节约存储资源,又不会因为数据缓存等待造成额外的传输延时。
3 无线NoC映射过程 基于网络编码的无线NoC映射过程可分为2个步骤:①任务映射,即将各项任务分配到NoC的处理节点上;②编码映射,即确定网络编码系数以及编码节点在无线NoC拓扑上的位置。本节介绍任务流图(Task Graph,TG)、资源流图(Resource Graph,RG)和多播图等基本概念以及NoC映射过程。
3.1 任务流图 定义1??任务流图是由节点ui(

3.2 资源流图 定义2 ??资源流图是表示无线NoC互联信息的有向图,G2=G(T, R),节点数为|T|,边数为|R|。节点ti∈T(i=1, 2, …, |T|)表示无线NoC中的瓦片,包含路由节点和处理节点。有向边ri, j∈R(i, j=1, 2, …, |R|)表示从瓦片ti到瓦片tj的单向数据链路。
3.3 多播图 定义3 ??多播树是由任务流图中具有相同信宿的一组多播流构成的图。节点表示多播应用的信源或信宿,每棵多播树包含一个信源与多个信宿,边表示从多播信源到多系信宿的一条多播流,边的权值即多播流的通信流量。由任务流图所表征的系统中所有的多播树构成多播图。
3.4 任务映射和编码映射 任务映射是按一定的优化规则将任务流图中的各个任务分配到资源流图中的节点上,采用细颗粒度的任务划分,多个任务可同时分配到一个资源节点上。
编码映射是确定了多播信源和信宿在资源流图上的位置的基础上,按一定的优化规则,确定网络编码的结构以及编码节点在资源流图中的位置。每个路由节点最多分配一个编码节点,原因如下:若多个编码节点分配到同一个路由节点上,由于不同编码节点在网络编码结构上的位置不同,其链接链路与相邻节点也不同,因此流经这多个编码节点的数据流在经过不同的编码向量编码后,需要不同的链路发到不同的相邻编码节点去。此时,为了区分这几组不同的编码数据,需要在数据包里加入额外的信息进行标识,这会带来额外的逻辑开销。另外,会使得编码链路的映射变得复杂,不利于映射时的最优化选择。
映射过程中,如果选择的编码路径或编码节点不同,网络各条链路上传递的数据也不同,相应得到的网络通信性能与代价成本也会不同。编码节点与无线路由节点的映射是一对一的关系。图 2为基于网络编码的无线NoC映射示意图。
 |
| 图 2 基于网络编码的无线NoC映射示意图 Fig. 2 Schematic of wireless NoC mapping based on network coding |
| 图选项 |
4 问题描述和数学模型 4.1 优化目标 映射问题是一个多目标优化问题,涉及的优化目标包括低功耗、实时性与高网络吞吐率,下面分别对其进行分析。
1)芯片功耗
低功耗设计是芯片设计中需要着重考虑的问题。芯片功耗过大,将造成芯片过热、工作不稳定以及供电等问题。无线NoC的功耗分为2个部分:处理功耗和网络功耗。处理功耗是所有处理节点运行的功耗之和,即
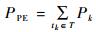
2)实时性
数字信号处理系统有实时性要求,本文用响应时间来描述系统的实时性。响应时间指从输入到输出的最长路径延时,其数学表达式为
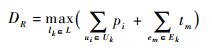 | (3) |
式中:集合L={lk|k=1, 2, …, |L|}包含任务流图中从输入节点到输出节点之间所有路径;Uk为路径lk上的任务节点集;Ek={em}为lk上的直连边集;tm=ti, j为任务i到任务j的通信时间。
3)网络吞吐率
网络传输性能用网络吞吐率来衡量。为评估网络编码的效果,定义网络吞吐率为单位时间内网络中传递的多播信息量,其计算式为
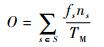 | (4) |
式中:fs(s∈S)为多播图中源节点s到单个目的节点的通信量,S为源节点集合;ns为源节点s对应的目的节点个数;TM为多播任务的传输时间。
4.2 任务映射 任务映射采用多目标优化遗传算法NSGA-II求解最优方案[15-16],优化目标是功耗和响应时间同时最小化,即
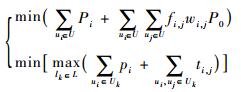 | (5) |
式中:P0为传输单比特数据一跳的功耗;wi, j为从节点i到节点j的跳数;fi, j为从节点i传到节点j的数据流量。
因为这一阶段还没有进行网络编码的设计,没有获得编码的信息,所以功耗和响应时间的计算里不考虑网络编码带来的影响。
从实际情况出发,对任意的任务映射TM:DFG→RG,本映射平台的约束条件如下:
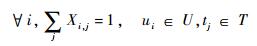 | (6) |
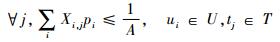 | (7) |
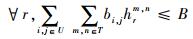 | (8) |
 | (9) |
式中:Xi, j为任务i与处理节点j的映射关系;bi, j为节点i到节点j通信所需的最小带宽;hrm, n为链路r是否在从节点i到节点j的路由路径上;B为链路带宽;T∞为有环网络的迭代边界;A为数据注入率。
式(6)约束每个任务只能映射到一个处理节点上,式(7)保证分配到同一处理节点的任务的总运算时间满足数据注入率要求,式(8)为带宽约束,式(9)为迭代边界约束,有环网络的迭代边界T∞不能超过数据注入率A的倒数。
4.3 编码映射 由第3.4节可知,编码映射是在已知多播图和任务映射结果的基础上,在资源流图上构造网络编码向量的过程。编码映射包含以下步骤:
1)根据任务映射方案,将任务流图的多播图G1映射到资源流图上得到资源流图的多播图G2,如图 3(a)所示。
2)去掉G2中没有交叉关系的多播流,仅保留具有胶连关系的多播流,构成简化的多播图G3,如图 3(b)所示。
 |
| 图 3 简化多播图的实例 Fig. 3 An example of simplified multicast graph |
| 图选项 |
具有胶连关系的多播任务指具有相同信宿,并且相互之间有交叉的多播流。由此,多播流在传输路径上可能发生冲突。网络编码用来提高冲突链路的数据传输效率,如果数据传输没有冲突,则无法发挥效果,因此本文仅对有冲突的多播任务进行网络编码设计。图 3给出了本步骤的一个简单实例。G2中原本有2组多播流,一组的信源是瓦片t1,信宿是瓦片t8、t9和t14;另一组的信源是t3,信宿是t4、t8和t9。从G2中可以看出,多播流t3→t4是孤立的,与其他多播流都不相交;而多播流t1→t14虽与t3→t9有交叉关系,但没有其他流和它共享信宿,故剔除这2条多播流,得到简化的多播图G3。
3)用NSGA-II选取最优多播路由路径,并对最优路径的各条边构造全局网络编码向量,确定编码节点位置。本文中网络拓扑是已知的,故采用多项式时间算法快速构造多播路径上各条链路的网络编码向量。该算法包括2个步骤:①为每个目的节点寻找网络中h条边不相交的路的集合(h为源节点个数);②为步骤①中所找的路构造全局编码向量。在最短路由算法下,步骤①的寻路过程若采用遍历搜索,搜索空间巨大,因此采用NSGA-II进行优化选路,同时将边不相交作为约束条件,使得优化结果满足多项式时间算法的要求。步骤②的全局网络编码向量构造算法的详细步骤可参见文献[17-18]。
编码映射的优化目标为最大化通信性能增益(网络吞吐率)和最小化编码代价(功耗),即
 | (10) |
式中:PC为网络编码的功耗;Ptr为多播数据传输功耗。
由于编码操作是在无线路由节点上进行的,编码方案不会对处理节点的功耗造成影响,因此本文优化功耗只考虑网络编码的功耗PC和多播数据传输功耗Ptr。
由于给定任务流图时,多播的通信量和目的节点数是已知的,因此网络吞吐率的大小与多播任务的传输时间TM,即各条多播流传输时间Ts, d中的最大值相关。考虑网络编码的影响,多播流传输时满足网络编码的数据会编码后传输,其余未编码数据在规定的路由算法下依次传输。因而多播流传输时间为这两部分数据传输时间之和。编码数据和未编码数据的网络传输时间的数学表达式分别为
 | (11) |
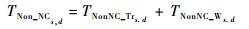 | (12) |
式中:TNC_Trs.d和TNC_Ws.d分别为编码数据在无线信道上的传输时间和由信道冲突造成的排队等待时间;TNonNC_Trs.d和TNonNC_Ws.d分别为未编码数据在无线信道上的传输时间和冲突等待时间;TCs.d为数据在路由节点进行网络编码的时间。
在无线NoC平台上,各参数的计算式如下:
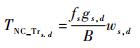 | (13) |
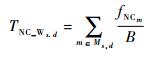 | (14) |
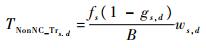 | (15) |
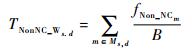 | (16) |
式中:gs, d为多播流中编码数据的比例;Ms, d为路径上路由节点集合;fNCm和fNon_NCm分别为在路径上节点m处与本路径编码数据和未编码数据相冲突的其他路径数据量之和。
5 仿真性能评估 为了验证本文提出算法的性能,本节首先对具有多播业务的通信系统进行建模及性能分析;同时,评估了本文算法在获得性能提升时付出的开销情况,包括路由器的实现复杂度问题与映射算法的执行复杂度问题。
5.1 性能分析 4×4 MIMO-OFDM通信接收系统可抽象为图 4所示的任务流图形式,包含32个任务,根据其功能不同,分为4类节点:A类节点(同步与解调)、B类节点(MIMO信道估计)、C类节点(MIMO迭代检测)和D类节点(LDPC译码)。其中,MIMO迭代检测器向LDPC译码器发送的是多播数据。任务节点的处理负载由各节点算法的乘加运算量等价得到,节点的处理负载及节点间的通信流数据[19]详见表 1和表 2。
 |
| 图 4 MIMO-OFDM接收端任务流图 Fig. 4 Task graph of MIMO-OFDM receiver |
| 图选项 |
表 1 任务节点的负载量 Table 1 Work Loads of each task
| 节点类型(节点标号) | 处理负载/ms |
| A (1~4) | 10.1 |
| B (5) | 21.4 |
| C (6~28) | 6.3 |
| D (29~32) | 13.2 |
表选项
表 2 任务间的通信流量 Table 2 Traffic flows among tasks
| 通信流类型 | 链路 | 通信流量/(Mb·s-1) |
| 单播 | A→B | 3.253 12 |
| 单播 | B→C | 1.689 60 |
| 单播 | C→D | 0.084 48 |
| 多播 | C→D | 0.084 48 |
表选项
由网络编码的定义可知,信宿能译码的充要条件是其输入链路上有h条边的全局编码向量线性无关。因此,在确定的网络拓扑下,信源个数的上界是确定的,即:h≤max(αi),αi为信宿节点i的度,h为信源个数。Mesh拓扑中节点的最大出度和入度为4,在这个约束条件下,考察2源2宿(多播1)、3源3宿(多播2)和4源4宿(多播3)这3种多播应用,如图 4所示。
由于缓存空间限制,当不同多播流到来时间差较大时,无法进行网络编码。定义如下参数:编码比例α=fC/f0为衡量编码效率的指标,fC为经过网络编码操作的多播流量,f0为多播总通信量。目标SoC平台采用32 nm工艺的无线Mesh NoC结构,取Bmax=20 Gb/s,处理核满负载功率p0=50 mW,线性负载功耗模型,片上无线传输每比特能耗e0=2.7 pJ[4]。遗传算法的主要参数设置如下:种群规模为100,代沟为0.9,交叉与变异概率分别为0.5和0.1,迭代100次。算法采用MATLAB编程,外加系统的遗传算法工具箱gatbx,仿真结果如下:
1)将采用了网络编码的本文算法与未采用网络编码的现有的最短路径多播树算法进行比较,图 5(a)给出了5×5 Mesh(拓扑1)下2种算法在网络吞吐率和功耗上的性能对比。图 5(b)给出了10×10 Mesh(拓扑2)下2种算法在网络吞吐率和功耗上的性能对比。为便于量化网络吞吐率和功耗的优化程度,图 5中对数据进行了如下归一化处理:
 | (17) |
 | (18) |
 |
| 图 5 多播应用在5×5 Mesh与10×10 Mesh的性能对比 Fig. 5 Performance comparisons of multicast application on 5×5 Mesh and 10×10 Mesh |
| 图选项 |
式中:Onormalized为归一化吞吐率;ONC为采用网络编码NoC吞吐率;Pnormanized为归一化功耗;P为NoC功耗;PNC为采用网络编码NoC功耗。
在2源2宿条件下,2类拓扑下本文算法比现有的最短路径多播树算法的网络吞吐率分别提高了49%和33%,功耗分别降低了16%和15%;在3源3宿条件下,2类拓扑下本文算法比现有的最短路径多播树算法的网络吞吐率分别提高了20%和33%,功耗分别降低了14%和25%;在4源4宿条件下,2类拓扑下本文算法比现有的最短路径多播树算法的网络吞吐率分别提高了16%和43%,功耗分别降低了6%和12%。证明采用了网络编码的NoC可以获得性能的大幅提高。
在3源3宿、4源4宿条件下,拓扑2比拓扑1的网络吞吐率分别提高了13%和27%,功耗降低了11%和6%。在2源2宿条件下,拓扑2比拓扑1的网络吞吐率降低了16%,功耗提高了1%。说明网络中存在多个多播业务应用时,网络规模的增大可进一步提高NoC的性能。原因在于当任务流中包含较多多播时,网络规模越大,编码映射中路由路径的选择越多,更容易实现多个多播的网络编码,从而提高网络吞吐率并降低网络功耗。但当网络中多播均已实现网络编码时,网络规模的增大反而会增大数据的传输时间和传递次数,从而降低网络吞吐率并增加功耗。因此,网络规模必须和多播应用的规模适应,才能使NoC的性能达到最优。
2)比较不同编码比例下的性能增益,结果如图 6所示。可以看出,随着编码比例的增大,吞吐率增益与功耗节省呈准线性规律增长。因此,可采用并行调度技术使得到达网络编码节点的不同路径的数据尽可能同时到达,提高网络编码的比例,以获得最大的性能增益。其中,吞吐率增益和功耗节约计算公式如下:
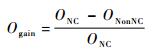 | (19) |
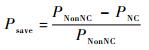 | (20) |
 |
| 图 6 多播应用在不同编码比例下的性能增益 Fig. 6 Performance enhancement of multicast application under different encoding ratios |
| 图选项 |
5.2 路由节点的实现复杂度分析 在对路由节点进行建模实现时,考虑到是否进行网络编码对射频与天线接入部分没有影响,故在建模时忽略这部分,仅对路由转发这部分功能进行建模与比较。基于网络编码的无线节点的交换模块的结构示意如图 7所示,其中阴影部分是编码功能模块,根据网络编码系数控制开关k1~k5的通断,将编码后的数据送到复用器,根据仲裁结果进行数据发送。
 |
| 图 7 无线节点的交换模块示意图 Fig. 7 Schematic of switch architecture of wireless router |
| 图选项 |
用Verilog HDL建立路由节点的功能模型,在Synopsys的Design Compiler下面用90 nm工艺进行综合,从综合结果的面积和功耗分析可知,与普通无线NoC的路由节点相比,基于网络编码的无线NoC路由节点的功耗和面积略有增加,分别为0.06%和0.8%。相对于第5.1节讨论的传输延时和功耗性能提高而言,这样的附加开销是较小的、可接受的。
5.3 映射算法的执行时间分析 在MATLAB平台上,采用本文提出的算法在网络拓扑为5×5 Mesh和10×10 Mesh下映射MIMO-OFDM接收端,得到一个映射结果的时间分别为28.484 6 s和62.840 2 s;相比普通映射算法的8.162 6 s和10.081 6 s,分别多耗时3倍和6倍。考虑到映射算法是离线执行的,只有在NoC承载应用的开始时刻执行一次,其后应用持续处理时无需执行映射算法,因此算法执行时间的略微增加是可接受的,不会降低NoC的性能。
6 结论 本文提出了一种网络编码在无线NoC上的应用机制,并且给出了将具有多播流的任务流图映射到无线NoC平台上的实现算法,经实验验证表明:
1)与普通无线NoC相比,本文提出的网络编码方法及映射算法具有很好的网络性能,功耗方面,至少节约6%,网络吞吐率方面,能提高至少16%。
2)本文算法带来的性能开销非常小,相比普通无线NoC,路由节点的面积和功耗分别仅增加了0.8%和0.06%。
参考文献
| [1] | LIN J, WU H T, SU Y, et al. Communication using antennas fabricated in silicon integrated circuits[J].IEEE Journal of Solid-State Circuits, 2007, 42(8): 1678–1687.DOI:10.1109/JSSC.2007.900236 |
| [2] | SASAKI N, FUKUDA M, KIMOTO K, et al.CMOS UWB transmitter and receiver with silicon integrated antennas for inter-chip wireless interconnection[C]//Proceedings of 2008 IEEE on Radio and Wireless Symposium.Piscataway, NJ:IEEE Press, 2008:795-798. |
| [3] | ZHAO D, WANG Y. SD-MAC:Design and synthesis of a hardware-efficient collision-free QoS-aware MAC protocol for wireless network-on-chip[J].IEEE Transactions on Computers, 2008, 57(9): 1230–1245.DOI:10.1109/TC.2008.86 |
| [4] | ZHAO D, WANG Y, LI J, et al.Design of multi-channel wireless NoC to improve on-chip communication capacity[C]//Proceedings of 5th IEEE/ACM International Symposium on Networks on Chip.Piscataway, NJ:IEEE Press, 2011:177-184. |
| [5] | DIJKSTRA E W. A note on two problems in connexion with graphs[J].Numerische Mathematik, 1959, 1(1): 269–271.DOI:10.1007/BF01386390 |
| [6] | BERTSEKAS D P, GALLAGER R G. Data networks[M].2nd edEnglewood Cliffs: Prentice-Hall, 1992: 396-398. |
| [7] | KOU L, MARKOWSKY G, BERMAN L. A fast algorithm for Steiner trees[J].Acta Informatica, 1981, 15(2): 141–145.DOI:10.1007/BF00288961 |
| [8] | TAKAHASHI H, MATSUYAMA A. An approximate solution for the Steiner problem in graphs[J].Math Japonica, 1980, 24(6): 573–577. |
| [9] | AHLSWEDE R, CAI N, YEUNG R W, et al.Network information flow theory[C]//Proceedings of 1998 IEEE International Symposium on Information Theory.Piscataway, NJ:IEEE Press, 1998:186. |
| [10] | 张思为.网络编码在基于局部总线的NoC的应用研究[D].成都:电子科技大学, 2010:24-34.ZHANG S W.Application research on network coding based on NoC with local bus[D].Chengdu:University of Electronic Science and Technology of China, 2010:24-34(in Chinese). |
| [11] | SHALABY A, GOULART V, RAGAB M E S.Study of application of network coding on NoCs for multicast communications[C]//Proceedings of IEEE 7th International Symposium on Embedded Multicore SoCs.Piscataway, NJ:IEEE Press, 2013:37-42. |
| [12] | VONBUN M, WALLENTOWITZ S, FEILEN M, et al.Evaluation of hop count advantages of network-coded 2D-mesh NoCs[C]//Proceedings of 23rd International Workshop on Power and Timing Modeling, Optimization and Simulation.Piscataway, NJ:IEEE Press, 2013:134-141. |
| [13] | REINHARD D. Graph theory III[M].New York: Springer-Verlag, 2005: 111-126. |
| [14] | CHEN W, LETAIEF K B, CAO Z. Buffer-aware network coding for wireless networks[J].IEEE/ACM Transactions on Networking, 2012, 20(5): 1389–1401.DOI:10.1109/TNET.2011.2176958 |
| [15] | CHEN Y, HU J, LING X.Topology and mapping co-design for complex communication systems on wireless NoC platforms[C]//Proceedings of 8th IEEE Conference on Industrial Electronics and Applications.Piscataway, NJ:IEEE Press, 2013:1442-1447. |
| [16] | 陈亦欧, 胡剑浩. 面向无线NoC平台的拓扑与映射联合设计[J].微电子学, 2012, 42(6): 846–849.CHEN Y O, HU J H. Co-design of topology and mapping for wireless NoC platform[J].Journal of Microelectronics, 2012, 42(6): 846–849.(in Chinese) |
| [17] | LAUFER R, DUBOIS-FERRIèRE H, KLEINROCK L. Polynomial-time algorithms for multirate anypath routing in wireless multihop networks[J].IEEE/ACM Transactions on Network-ing, 2012, 20(3): 742–755.DOI:10.1109/TNET.2011.2165852 |
| [18] | YAZDI S M S, SAVARI S A.A deterministic polynomial time algorithm for constructing a multicast coding scheme for linear deterministic relay networks[C]//Proceedings of 45th Annual Conference on Information Sciences and Systems.Piscataway, NJ:IEEE Press, 2011:1-6. |
| [19] | 陈亦欧, 胡剑浩, 陈庚生. 面向实时复杂系统的基于片上网络多核平台的映射技术研究[J].计算机应用研究, 2012, 29(7): 2589–2592.CHEN Y O, HU J H, CHEN G S. Energy and performance-aware mapping for real-time complex system based on NoC platform[J].Journal of Application Research of Computers, 2012, 29(7): 2589–2592.(in Chinese) |
