1.School of Microelectronics, Xidian University, Xi’an 710071, China 2.Science and Technology on Reliability Physics and Application Technology of Electronic Component Laboratory, Guangzhou 510610, China
Fund Project:Project supported by the National Defense Basic Scientific Research Program of China (the Stability Support Fund of the State Administration of Science, Technology and Industry for National Defense) (Grant No. 614280620200201), the National Natural Science Foundation of China (Grant Nos. 62074121, 62034002), the Natural Science Foundation of Shaanxi Province, China(Grant No. 2019GY-010), Scientific Research Program Funded by Shaanxi Provincial Education Department, China (Grant No. 20JY018), and the Fundamental Research Funds for the Central Universities (Grant Nos. XJS191101, XJS191106)
Received Date:30 September 2020
Accepted Date:06 November 2020
Available Online:26 March 2021
Published Online:05 April 2021
Abstract:With the improvement of the integration and power density of three-dimensional integrated microsystem, it is imperative to simultaneously investigate the multi-field coupling analysis of electrical design and thermal management. This paper is to investigate a three-dimensional integrated microprocessor system and realize the rapid electrothermal analysis of the system through an improved dual cell method (DCM). This method decomposes the constitutive matrix into a constant matrix and a temperature-dependent matrix by introducing the coupling of leakage power and material coefficients with temperature. In the calculation, only the temperature-dependent matrix needs to be updated and assembled, which makes the calculation speed faster than the traditional finite element method. The simulation results show that the speed of the proposed algorithm is improved by about 30% compared with that of the traditional finite element method. After considering the thermal coupling factors of material coefficient and leakage power, the hot spot temperature of the system increases by 20.8 K compared with before coupling. Finally, the algorithm proposed in this paper is used to study the layout of three-dimensional integrated microprocessor system. The influence of TSV array conventional layout and centralized layout under the processor core(core-layout) on the hot spot temperature of upper and lower chips are compared, and the influences of uneven power distribution on the two layouts are studied. The results show that compared with the conventional layout of TSV array, the core-layout can reduce the hot spot temperature of processor, but it will aggravate the hot spot problem of DRAM at the same time. And when the power is not evenly distributed on the four cores, the hot spot of DRAM under the core-layout will be more seriously affected. In conclusion, the algorithm model proposed in this paper can quickly analyze the electrothermal coupling problem of 3D integrated microsystem, realize the hot spot prediction of the system, and provide theoretical guidance for designing the chip layout of 3D integrated microsystem. Keywords:three-dimensional integrated microsystem/ dual cell method/ electrothermal coupling/ finite element method
$k\left( T \right) = \sum\limits_0^4 {{c_n}{T^n}},\;\;{T_0} \leqslant T \leqslant {T_1},$
其中${c_n}$为插值系数, 具体数值参考文献[4,10]. 引入耦合项${I_{\rm{sub}}}\left( T \right)$, $k\left( T \right)$后, (7)式的整体传热方程可改写为与温度相关的形式:
${{{\mathit{\boldsymbol{G}}}}^{\rm{T}}}{{\mathit{\boldsymbol{M}}}}\left( {k\left( T \right)} \right){{\mathit{\boldsymbol{GT}}}} = {{\mathit{\boldsymbol{q}}}}\left( {{I_{\rm{sub}}}\left( T \right)} \right).$
由(11)式可知, 在每次温度迭代计算时, 需要重新计算每个单元的本构矩阵${{\mathit{\boldsymbol{M}}}}\left( {k\left( T \right)} \right)$和载荷列阵${{\mathit{\boldsymbol{q}}}}\left( {{I_{\rm{sub}}}\left( T \right)} \right)$并重新组装. 对于DCM, 每个单元本构矩阵M为6 × 6的矩阵, 相比于有限元4 × 4的传热矩阵K计算量更大, 组装时间更长. 因此本文对DCM的整体传热方程做了进一步的改进. (5)式中的本构矩阵${{\mathit{\boldsymbol{M}}}}\left( {k\left( T \right)} \right)$可以分解为
${{\mathit{\boldsymbol{M}}}}\left( {k\left( T \right)} \right) = k\left( T \right) \cdot \tilde{{\mathit{\boldsymbol{S}}}}{{\mathit{\boldsymbol{P}}}} = \tilde{{\mathit{\boldsymbol{S}}}}(k\left( T \right){{\mathit{\boldsymbol{P}}}}).$
为了比较两种布局的温度分布, 首先将处理器的四个Core功率设置为均匀分布, 采用改进的DCM对两种布局结构进行电热耦合仿真分析. 如图8所示采用Core-布局结构时, 处理器芯片的热点温度下降了2.20 K. 而与此同时图9所示DRAM芯片的热点温度为370.93 K, 相比3.1节仿真得到的常规布局热点温度上升了4.30 K. 这是由于TSV阵列作为重要散热路径, Core-布局结构会将处理器高功率Core区域产生的热量传导到下层, 使得处理器芯片温度下降的同时让DRAM芯片的整体温度上升. 对比TSV阵列常规布局的情况, Core-布局使得处理器芯片热点温度下降2.73%, 而使得DRAM芯片的热点温度上升5.85%. 考虑到高温会导致DRAM的晶体管电荷损失加快, 使得数据丢失. 因此在选择布局方式时, 需要综合考虑处理器芯片的降温情况与DRAM芯片的升温情况. 图 8 两种不同TSV阵列布局时处理器的温度分布 Figure8. Temperature distributions of processors with two different TSV arrays.
图 9 Core-布局时DRAM温度分布图 Figure9. DRAM temperature distributions in core-layout.
表2不同功率分配时仿真时间 Table2.Improving simulation time of DCM and FEM with different power allocation.
结合图11和图12的统计结果, 发现处理器芯片在内侧核高功率的Case6下热点最高, 功率均匀分配时热点温度最低. DRAM芯片在Case1下的热点温度最高, 功率均匀分配时的热点温度最低. 由此可见在Core功率分布不均匀时会加剧热点问题, 因此处理器工作时应尽量保持各核功率分布均匀能有效降低整个微系统的热点温度. 同时发现单侧两个Core处理大功率事务的Case1以及单核处理大功率事务的Case5, Case6情况下, 整个微系统的热点温度均会显著升高, 因此在系统设计时应尽量避免这种情况. 图 11 不同功率分配下处理器芯片最高温度 Figure11. Maximum temperature of processor chip under different power allocation.
图 12 不同功率分配下DRAM芯片最高温度 Figure12. Maximum temperature of DRAM chip under different power allocation.

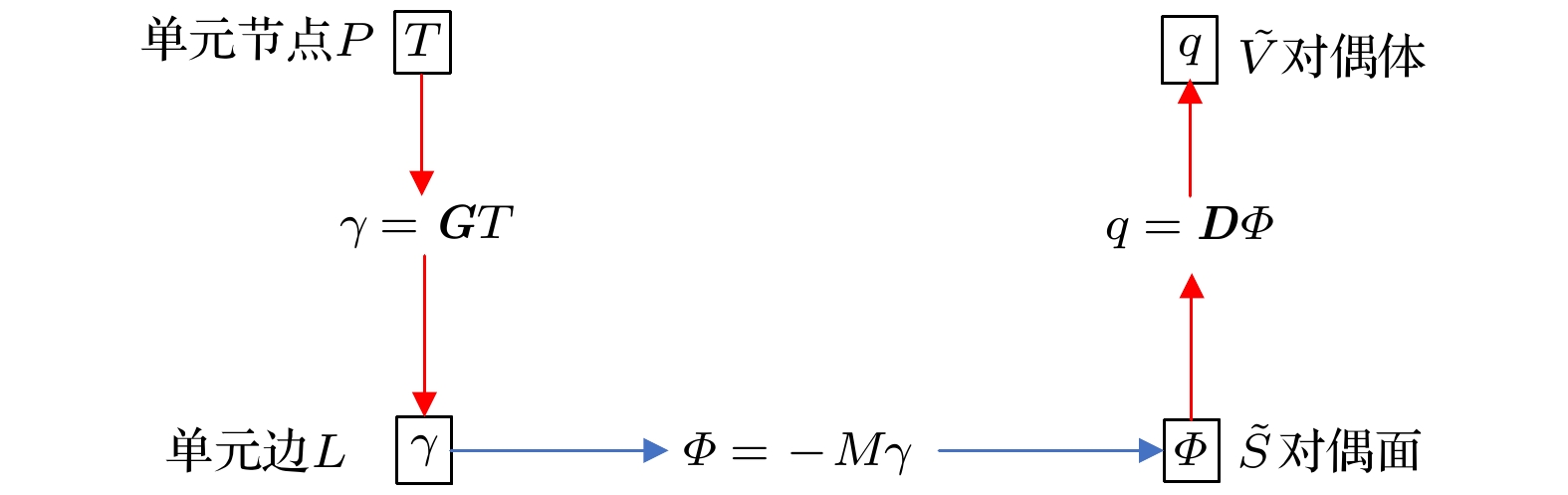 图 1 DCM求解传热问题流程图
图 1 DCM求解传热问题流程图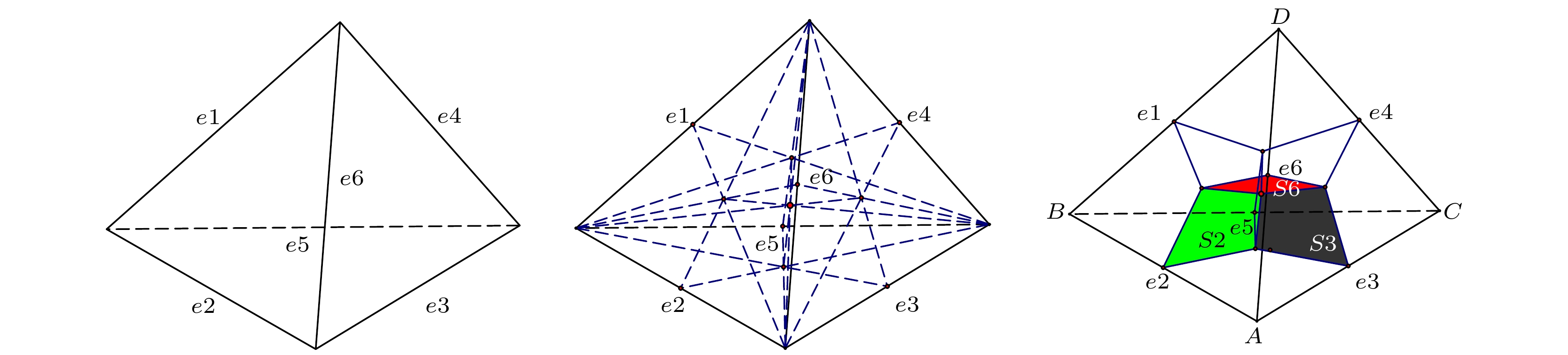 图 2 对偶单元构建过程
图 2 对偶单元构建过程







































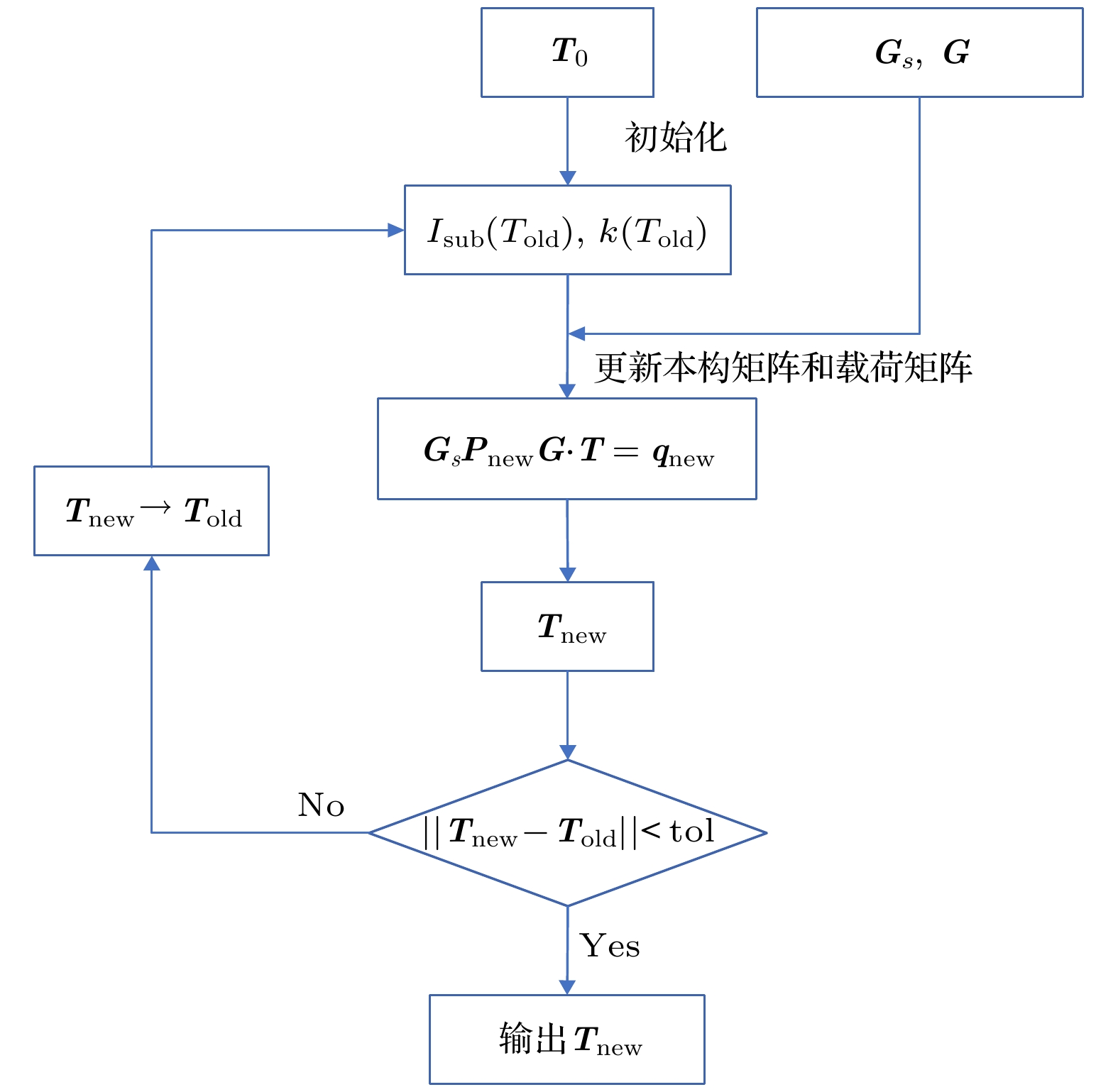 图 3 迭代算法流程图
图 3 迭代算法流程图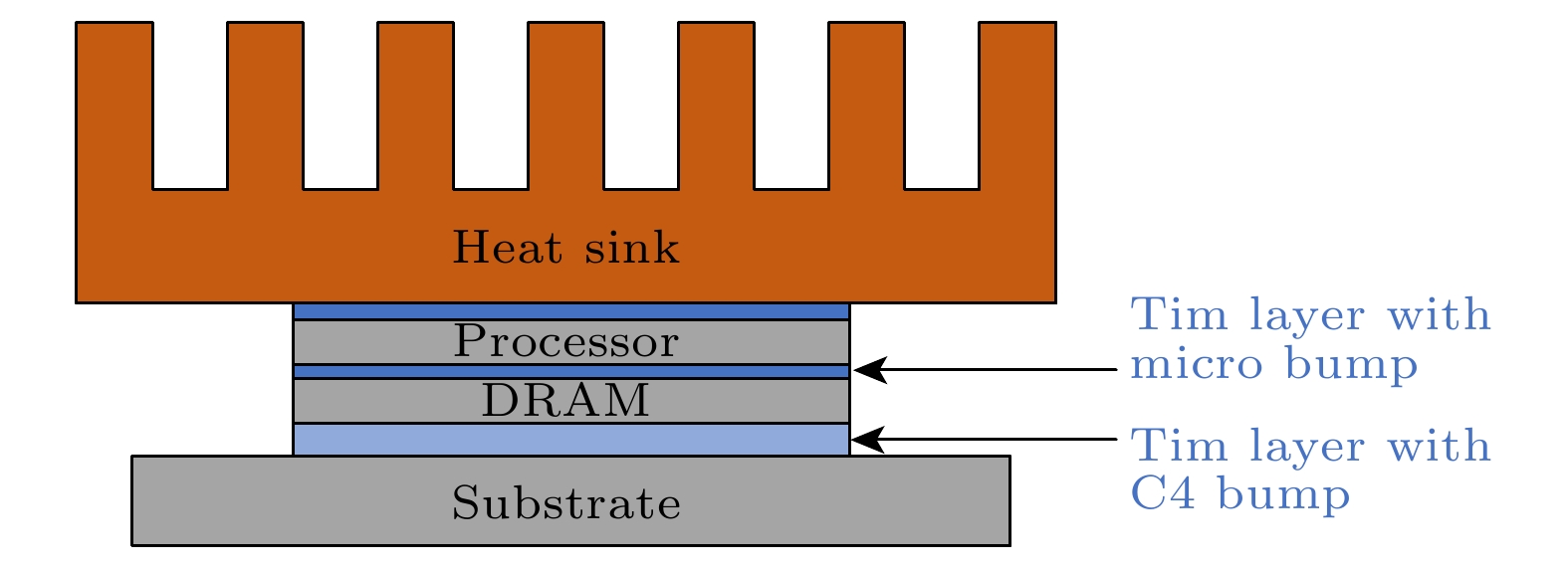 图 4 三维集成微处理器系统结构示意图
图 4 三维集成微处理器系统结构示意图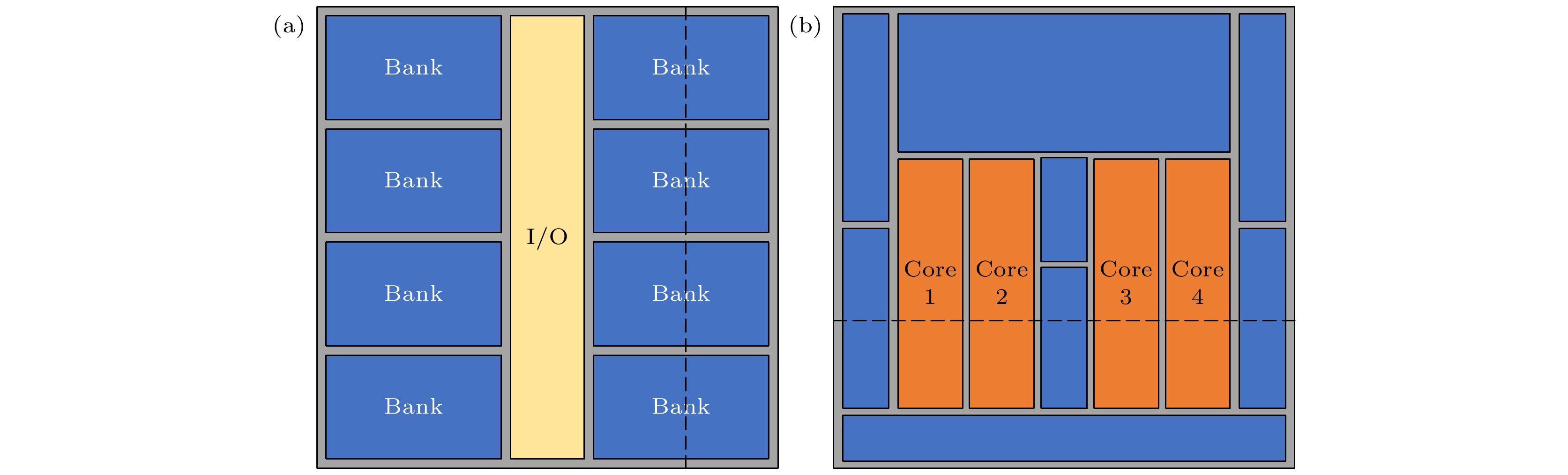 图 5 工作区域分布图 (a) DRAM芯片; (b) Intel i7处理器芯片
图 5 工作区域分布图 (a) DRAM芯片; (b) Intel i7处理器芯片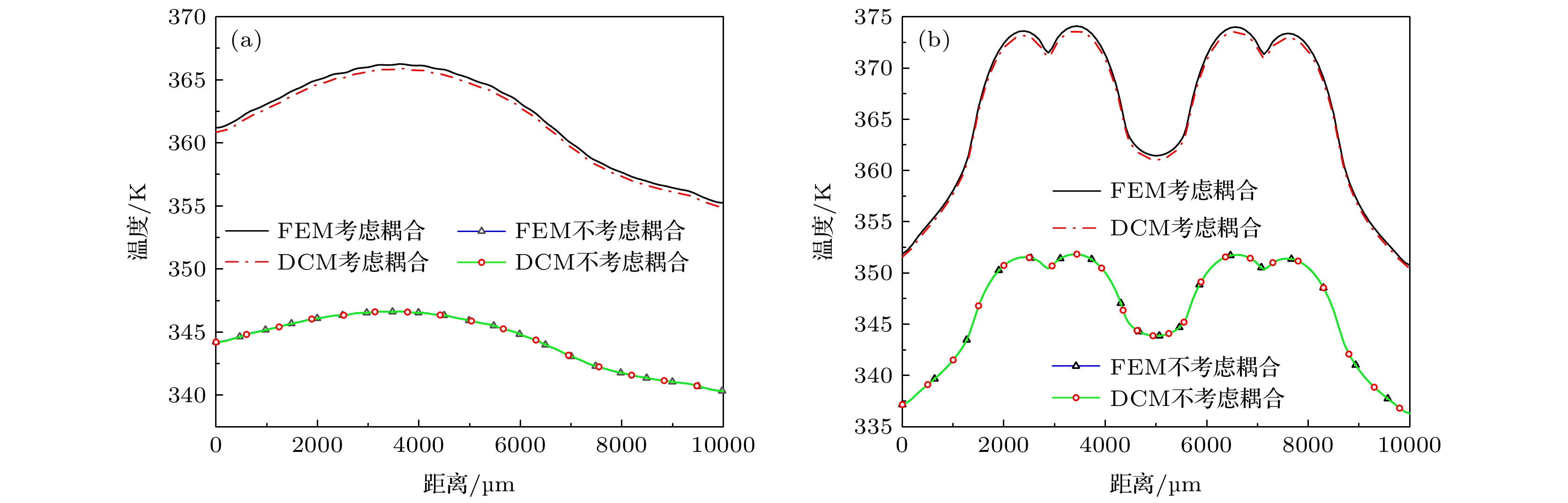 图 6 不考虑耦合与考虑耦合时芯片温度分布 (a) DRAM; (b) 处理器
图 6 不考虑耦合与考虑耦合时芯片温度分布 (a) DRAM; (b) 处理器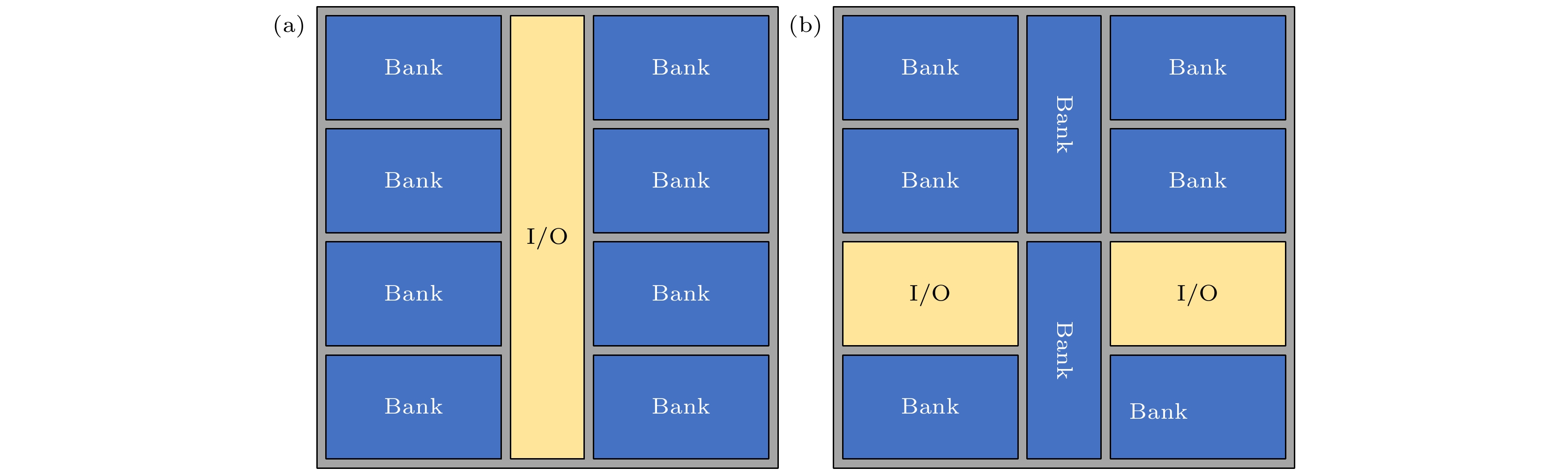 图 7 两种不同的TSV阵列布局 (a) 常规布局; (b) Core-布局
图 7 两种不同的TSV阵列布局 (a) 常规布局; (b) Core-布局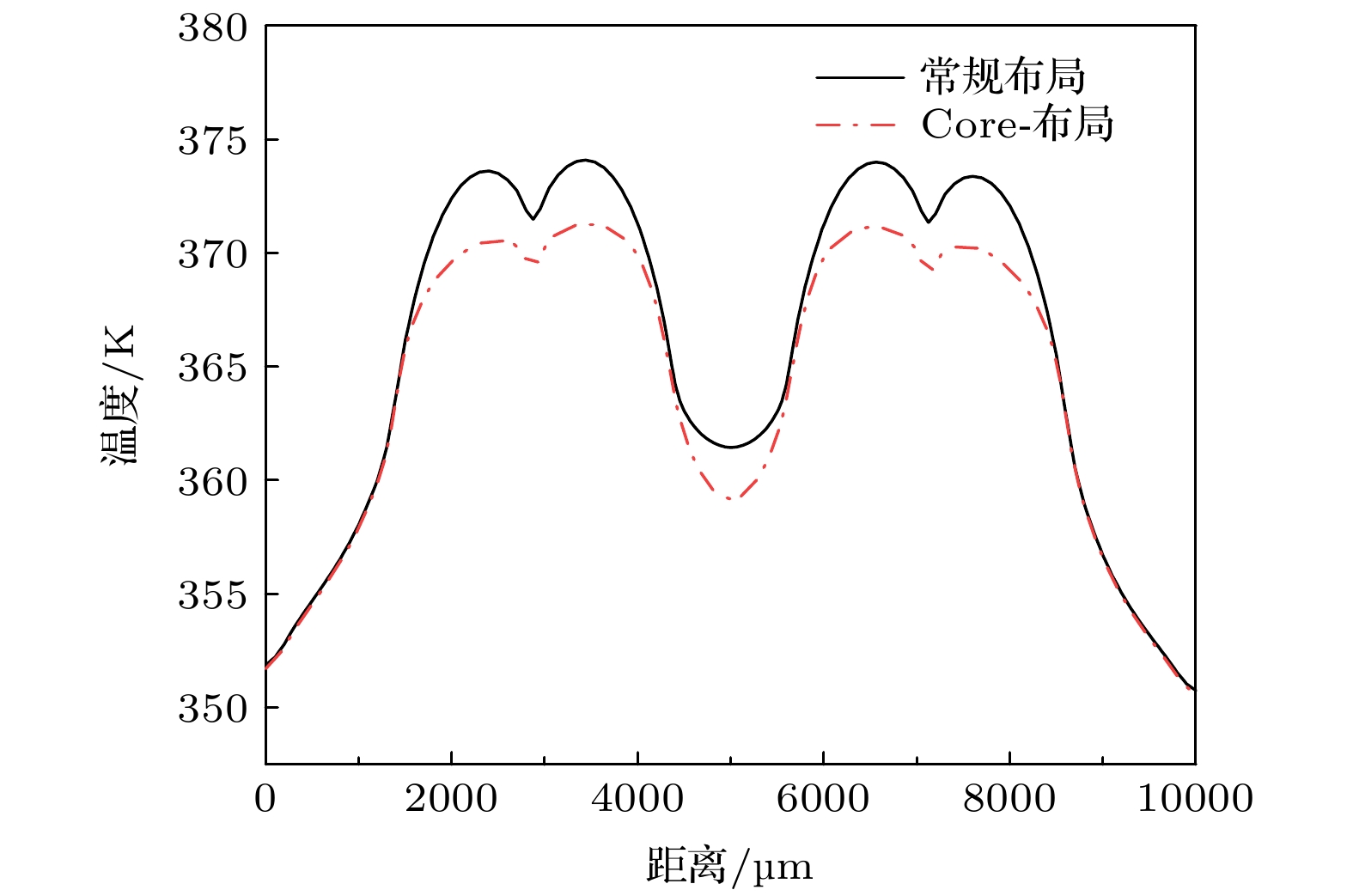 图 8 两种不同TSV阵列布局时处理器的温度分布
图 8 两种不同TSV阵列布局时处理器的温度分布 图 9 Core-布局时DRAM温度分布图
图 9 Core-布局时DRAM温度分布图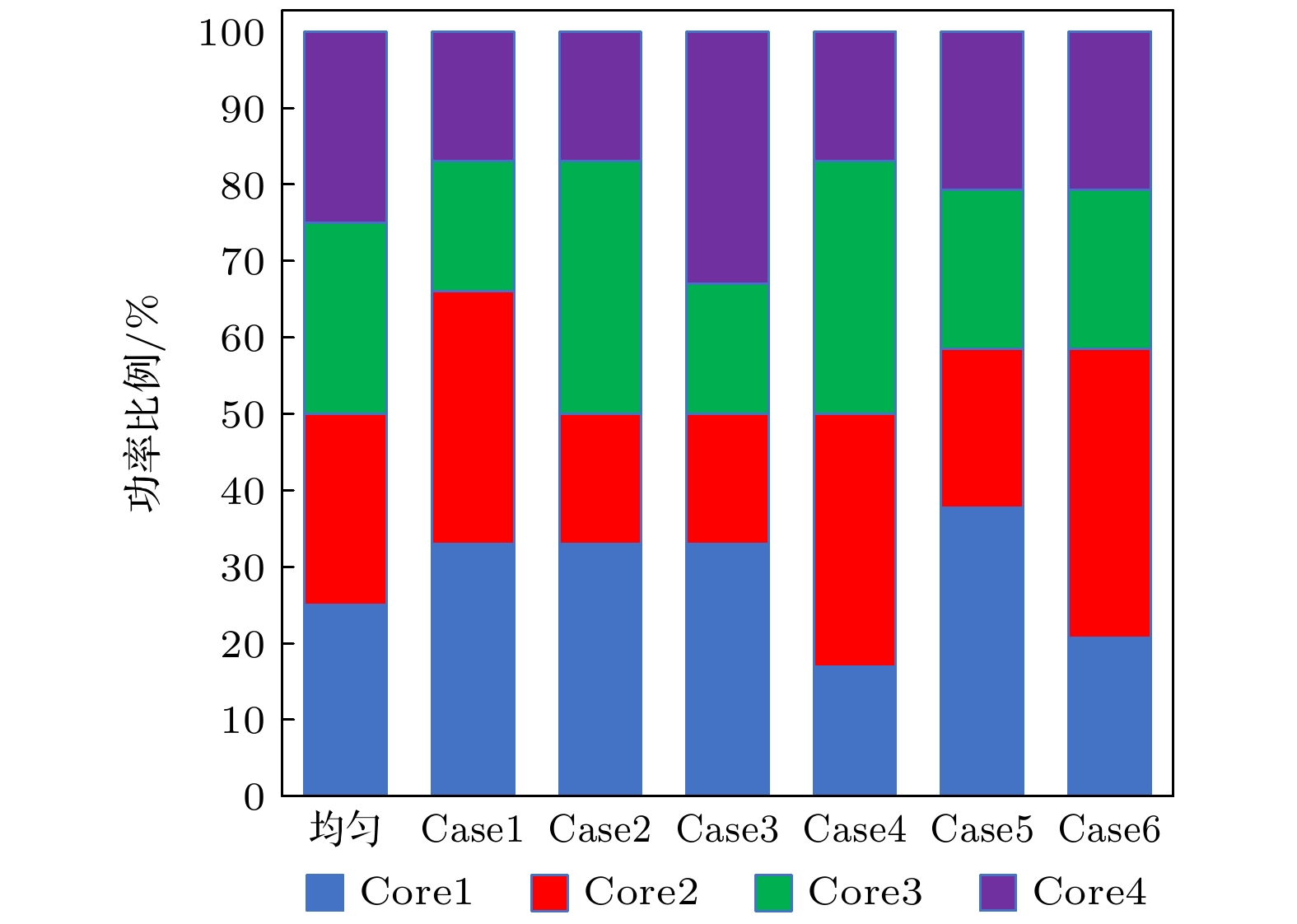 图 10 典型Core功率分配情况
图 10 典型Core功率分配情况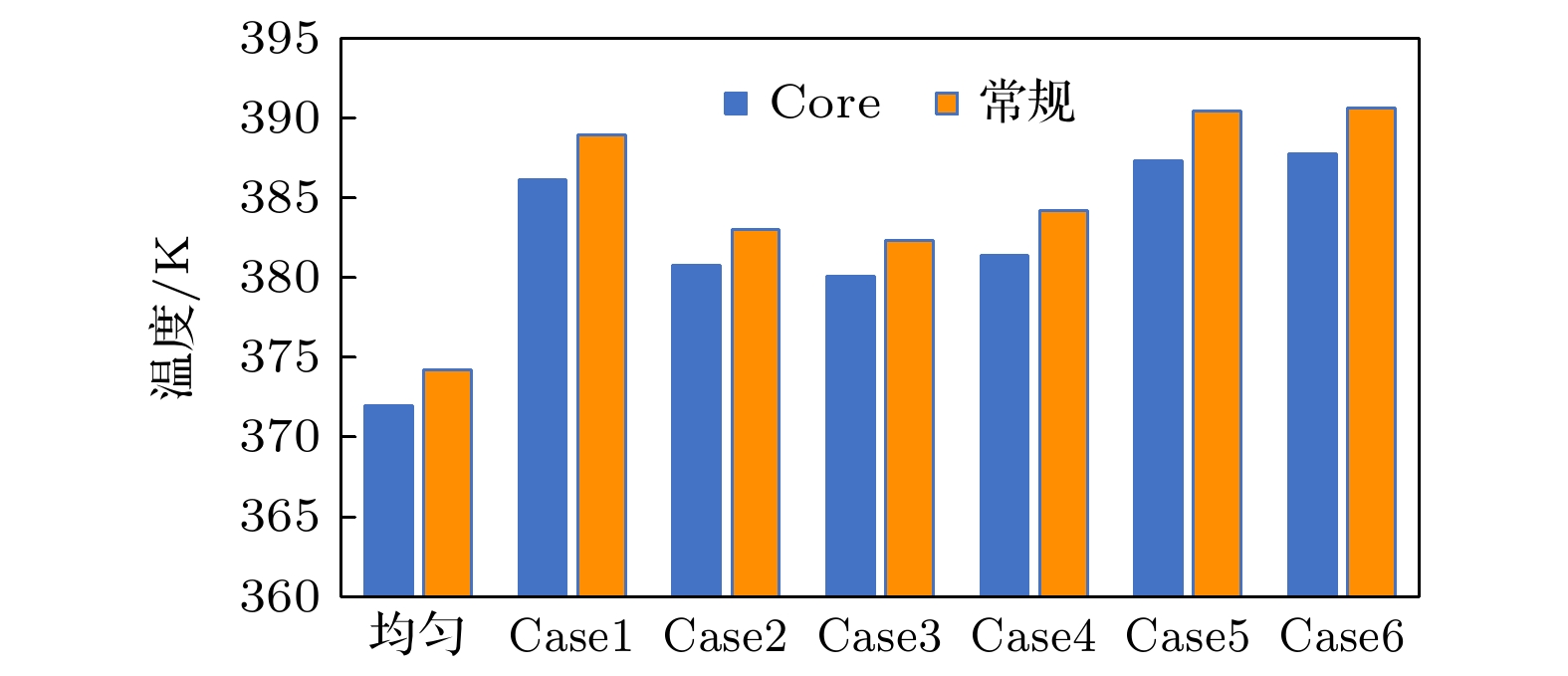 图 11 不同功率分配下处理器芯片最高温度
图 11 不同功率分配下处理器芯片最高温度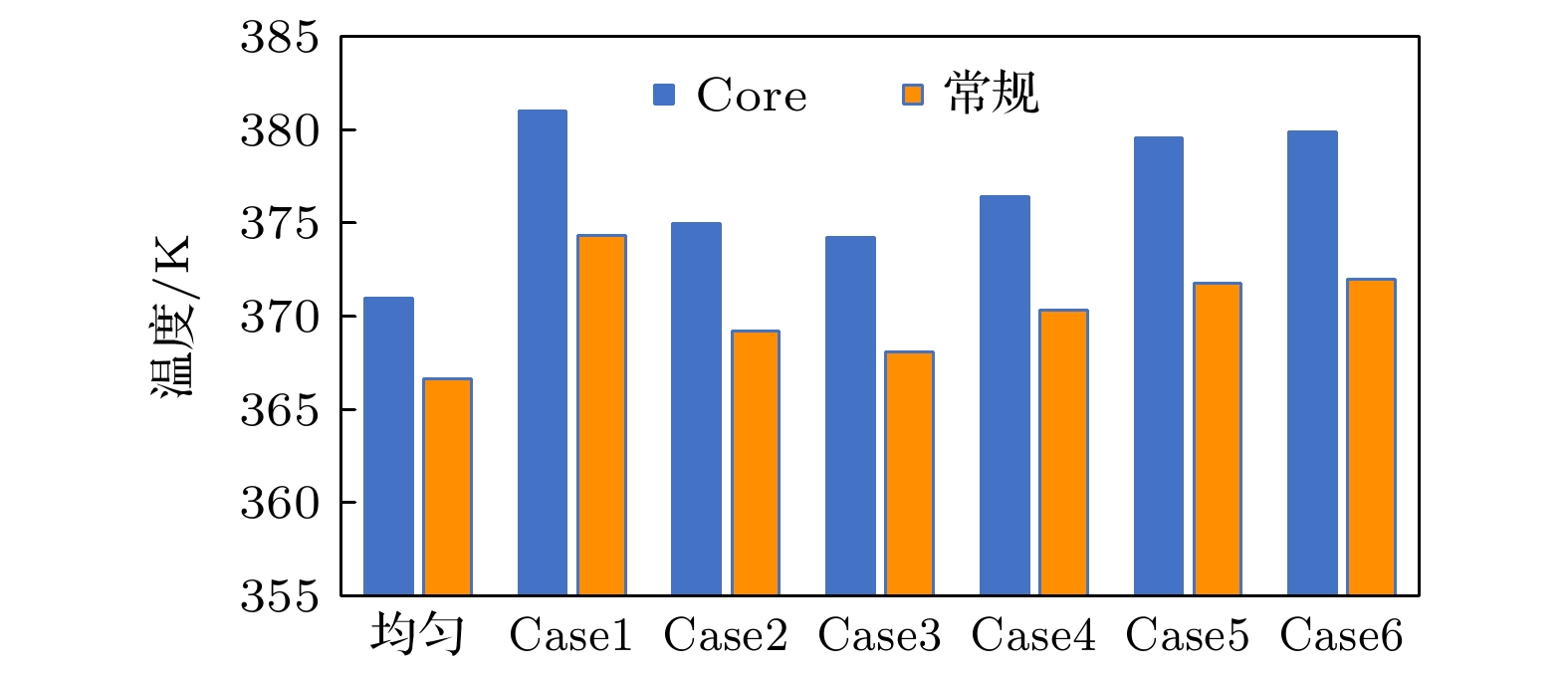 图 12 不同功率分配下DRAM芯片最高温度
图 12 不同功率分配下DRAM芯片最高温度