HTML
--> --> -->A new observation network with elevated observation positions could help to mitigate the aforementioned problems. Fortunately, many mobile communication towers with a height greater than 40 m above ground level (AGL) have been built recently across China (> 1 per 30-km × 30-km area on average). This network of towers provides a cost-effective option to build a new observing network at elevated heights. To assess whether such an observing system is able to improve weather forecasts, a series of observing system simulation experiments (OSSEs) were performed using the Advanced Research version of the Weather Research and Forecasting (WRF) model and its RUC data assimilation system. In this study, we assume that the new observations (i.e., virtual mobile communication tower?based observations) were taken at 40 m AGL, and we compare them with the observations at 2?10 m AGL from the existing conventional weather stations.
This paper is structured as follows. The methods, choice of model parameters, and details of the experimental design are introduced in section 2. In section 3, a set of OSSE results highlighting the utility of this new observing network are discussed. Conclusions and future directions are provided in section 4.
2.1. Data
Normally, testing a new observation network requires weather forecast experiments conducted over three months both in summer and winter with a high temporal resolution. (Dumelow, 2003; Errico and Privé, 2014). Considering the high computational costs, we conducted such experiments only for January and June 2016. The initial conditions (ICs) and boundary conditions (BCs) for the experiments were based on the 6-h analysis (0.5° × 0.5° resolution) of the Global Forecast System (GFS) of the National Centers for Environmental Prediction (NCEP).The Advanced Research version of the WRF model and its RUC data assimilation system, based on the three-dimensional variational (3DVAR) approach (NOAA, 2012), were used for this research. WRF is designed both for atmospheric research and operational applications. It offers a flexible and computationally efficient platform for operational forecasting, while reflecting recent advances in physics, numerical methods, and data assimilation schemes (Skamarock et al., 2008). The RUC system can assimilate recent observations to provide frequent updates of current conditions and short-range forecasts. OSSEs were used to assess the impact of the new virtual observations (Arnold and Dey, 1986; Masutani et al., 2006).
The NECP FNL (final) Operational Global Analysis data are available on a 0.5° grid. These data are prepared operationally every 6 h to provide the ICs and BCs for a nature run generating the “truth”. This product is from the Global Data Assimilation System, which continuously collects observations from the Global Telecommunication System, and other sources. All observations in this study were derived from this “truth”. The version of the model used for the nature run was WRF-ARW 3.7.1, which has a 3-km × 3-km grid for the study domain. The ICs and BCs of the experiment run were provided by the GFS but using a different model version and domain grid, i.e., WRF-ARW 3.6.1 and a 9-km × 9-km grid, respectively. To make the ICs of the experiment different from the truth, some random noise was added to the ICs and BCs of the experiment run (Wu et al., 2013), which is elaborated in the experiment design section. The background error covariance was estimated using the National Meteorological Center method, by taking the differences between forecasts of different lengths at identical times (Parrish and Derber, 1992). The May to April of 2015 differences between the 12-h forecast and the 24-h forecast were used to estimate the background error covariance. The control variables of the CV7 option in the 3DVAR system were used in the experiments, because those control variables (u, v) are more suitable for data assimilation when the observing network is more dense (Sun et al., 2016). In the CV7 option, temperature, surface pressure, pseudo relative humidity (humidity divided by its background value), and the velocity components U and V (instead of the original streamfunction ψ and velocity potential χ) were used as the control variables. In this study, the nature run was used as the truth to evaluate the accuracy of forecasts.
Several experiments were conducted with ICs and BCs generated by adding randomly perturbations to the GFS initial and BCs using the WRF data assimilation system. The standard deviations of the perturbations were roughly 1.2 K for temperature, 3 m s?1 for wind, and 0.3 g kg?1 for the water vapor mixing ratio (Barker et al., 2004; Hu et al., 2017). Assimilating observations according to different ICs can improve the reliability of the results. Here, we describe the model vertical levels and the details of the RUC. The observations made at heights of dozens of meters may have large effects at low levels; therefore, the setup of modeled levels usually has a greater density in the planetary boundary layer (PBL). There are full 35 sigma levels in the vertical direction, with 10 sigma levels below 3 km and 5 sigma levels below 100 m. For each experiment, we used the RUC to assimilate eight time points over 24 h, and subsequently performed a 36-h forecast (see Fig. 1). The assimilation window was 1.5 h before and after the analysis time. Table 1 lists the configurations used in the model. These configurations were similar to those of the Beijing RUC assimilation forecast system (Dong et al., 2011). The RUC data assimilation system implements a radius of influence for observations; if the radius becomes too large, the effects of local observations could lead to errors. For example, in the model default scheme, an observation can affect the variables within 100?150 km. However, in reality these observations could not affect these variables over such a long distance, especially in the case of the near-surface observations, so in our experiment the radius of influence was set to 50 km. The use of a smaller radius of influence could result in further improvement, but this is a topic for future studies.
 Figure1. The rapid update cycle (RUC). The cold start was run at 0000 UTC every day over the experimental period; it assimilates the observations eight times and then generates a 36-h forecast.
Figure1. The rapid update cycle (RUC). The cold start was run at 0000 UTC every day over the experimental period; it assimilates the observations eight times and then generates a 36-h forecast.| Parameter | Truth | Experiment |
| Domain center | 39.83°N, 116.39°E | 39.83°N, 116.39°E |
| X Y grid length | 3 km × 3 km | 9 km × 9 km |
| X Y grid points | 1389 × 1090 | 453 × 363 |
| Terrain resolution | 30 s (~900 m) | 30 s (~900 m) |
| Time step | 20 s | 60 s |
| Number of domains | 1 | 1 |
| Number of vertical levels | 35 | 35 |
| Microphysics option | Thompson scheme | Thompson scheme |
| Longwave radiation option | RRTM scheme | RRTM scheme |
| Shortwave radiation option | Dudhia | Dudhia |
| Boundary layer option | ACM2 (Pleim) PBL | ACM2 (Pleim) PBL |
| Cumulus option | ARW | ARW |
| PBL scheme | No | Kain?Fritsch |
| Surface observation assimilation | Quasi-Normal Scale | Quasi-Normal Scale |
| Ruggiero | Ruggiero | |
| Notes: RRTM, Rapid Radiative Transfer Model; PBL, planetary boundary layer; ARW, Advanced Research WRF. | ||
Table1. Experimental configuration.
2
2.2. Numerical simulation
To determine the key factors of the new observing system, a set of OSSEs and two statistical experiments was conducted. The setup of the nature run, observation assimilation and experiment run are described in this section.3
2.2.1. Analysis of terrain check
This experiment was designed to determine the number of observations passing the data assimilation system terrain quality control check after raising stations to higher positions. Many traditional weather stations cannot pass the data assimilation system quality control check because their heights are significantly lower than the corresponding model grid points; therefore, raising these stations to higher positions could allow more stations to pass the check. Here, we raised incrementally with 10-m intervals the present ground-based observing network from the ground to 100 m, and counted the number of observations that passed the quality control check each time.3
2.2.2. Analysis of interpolation error
In the surface observation data assimilation scheme of Ruggiero et al. (1996), the observations with heights ≤ 100 m below that of the corresponding model grid point are interpolated to the lowest model level using the model information, which is called background information. This process can introduce errors, but it is difficult to evaluate the magnitude of these errors because there are no corresponding observations. To investigate temperature and pressure interpolation errors, we used the observations based on the model terrain reduced by 100 m, with the background information taken from the original model terrain. The details are shown in Fig. 2, where Fig. 2a (original model terrain) shows the model information and Fig. 2b (model terrain reduced by 100 m) shows the virtual observations. Details of the equation and the use of observations below the model surface are provided in Appendix A. Figure2. How to calculate the interpolation error. Panel (a) is the model information and (b) is the virtual observation. L1 and L2 are the near-surface model information that would be used when the observation is below the lowest model level; (1) is an observation below the lowest model level; and (2) is the observation at the height of the lowest model level. The interpolation error is given by the difference between the observation at the lowest model level (2) and the estimated value of (1), which was interpolated to the lowest model level using the model information (L1 and L2).
Figure2. How to calculate the interpolation error. Panel (a) is the model information and (b) is the virtual observation. L1 and L2 are the near-surface model information that would be used when the observation is below the lowest model level; (1) is an observation below the lowest model level; and (2) is the observation at the height of the lowest model level. The interpolation error is given by the difference between the observation at the lowest model level (2) and the estimated value of (1), which was interpolated to the lowest model level using the model information (L1 and L2).3
2.2.3. Weather forecast experiments with new elevated observations
To determine the improvement due to a new observing network, the new station heights were set to 40 m. Because our lowest model level is about 10 m, observations below 10 m will be used as conventional surface observations, which observe temperature, humidity, pressure at 1?2 m, and wind at 10 m. There are about 628 meteorological stations in our domain grid, but most stations are located south or east of our domain (Fig. 3b). In our domain, the density of mobile communication towers is less than one per 30-km × 30-km area in the north of the domain, and better than one per 3-km × 3-km area in town areas. In order to find a proper station distribution of this new observing system, we conducted a number of sensitivity experiments testing the homogeneity of the network. We showed that the spatially homogeneous network produces better results compared to the non-homogeneous network. For the comparison, the number of virtual new stations needed to be close to the real ground-based stations. We chose the horizontal density for the new observations to be approximately 65 km× 65 km (Fig. 3a), with the model and data assimilation grid size being 9 km × 9 km. The observation error covariance matrix used for data assimilation included instrument errors, representativity errors, and operator errors (Waller et al., 2014). Observations at higher positions may have smaller representativity errors, because they are less affected by local environmental conditions. The representativity error of the new observations was set to 0.01 and that of the ground-based observations was set to 0.02. For example, the 0.01 representativity error increases the value of the error covariance matrix by 0.01. The final observations were obtained by adding perturbations (observation errors) to the truth. The perturbations were assumed to be random, with unbiased normal distributions. For example, both new observations (T, U, V, P, Q) and ground-based observations (T, U, V, P, Q) had random noise with a normal distribution, N(0,1), and with a standard deviation of 1 K for temperature, 1 m s?1 for wind, 1 Pa for pressure and 1 g kg?1 for humidity (Skamarock et al., 2008; Hu et al., 2017). We ran the experiment over January and July 2016. Both types of observations were taken from the “truth”. The setup of this experiment was shown in Table 2.| Observation type | Time | Density | Representative error |
| Ground-based observation | Jan and Jul 2016 | Fig. 3b | 0.02 |
| New observation | Jan and Jul 2016 | Fig. 3a | 0.01 |
Table2. Setup of the new observation continuous experiment.
 Figure3. Design of the mobile communication tower observation network (a) and the sites of real surface observation stations in the domain grid (b).
Figure3. Design of the mobile communication tower observation network (a) and the sites of real surface observation stations in the domain grid (b).3
2.2.4. New observation ensemble experiment
This experiment used ensembles to assess the effect of the new observations on a heavy rainfall process. In this experiment, the representativity error and the random noise of observations were the same as in the previously described experiment. The new observations had a representativity error of 0.01 and surface observations an error of 0.02. Both new observations (T, U| Observation type | Time | Density | Members | Representative error |
| Ground-based observation | 19?21 July 2016 | Fig. 3b | 30 | 0.02 |
| New observation | 19?21 July 2016 | Fig. 3a | 30 | 0.01 |
Table3. Setup of the new observation ensemble experiment.
3
2.2.5. Observation interval idealized experiment
This experiment was used to compare the effect of observation intervals on weather forecasts. A 9 km × 9 km model grid was used to assimilate observations with resolutions of the new observing network and the ground-based observing network separately. In the new network, the stations were located on the nodes of a 65 km × 65 km grid (Fig. 3a). For the ground-based network, the stations in the domain are shown in Fig. 3b. Both types of observations for this experiment were assumed to be perfect, i.e., there were no observation errors and the differences were assumed to be due to the different networks. The setup of this experiment was shown in Table 4.| Parameter | Value |
| Observation error | No |
| Observation height (m) | 40 |
| Experiment time | July 2016 |
Table4. Setup of observation interval idealized experiment. The observation interval is a variable and other parameters are constants as show in the table. The intervals are shown in Fig. 3a and 3b.
3
2.2.6. Observation height idealized experiment
This experiment assessed the effect of observation height on weather forecasts. Three observation heights were tested: ground-based observation height, 30 m, and the new network observation height of 40 m. The observations for these experiments were assumed to be perfect, i.e. there were no observation errors, and the observation interval was held constant. The data assimilation model grid was 9 km × 9 km and the observation interval was 65 km × 65 km. The setup of this experiment was shown in Table 5.| Parameter | Value |
| Observation error | No |
| Observation interval (km) | 30 × 30 |
| Experiment time | July 2016 |
Table5. Setup of observation height idealized experiment. The observation height is a variable and other parameters are constants as shown in the table. The heights are AGL 10 m, 30 m and 40 m.
3
2.2.7. Representativity error in the idealized experiment
Actual observation networks are never perfect, i.e., they contain observation errors. This experiment investigated the effect of representativity error on weather forecasts. It was assumed that observations with a higher observing height may have a smaller representativity error. The experiment was designed to assimilate observations obtained at the same observation height and observation interval but with different representativity errors, which were 0.01, 0.02 and 0.03. Then a 9 km × 9 km model grid was used to assimilate the 65 km × 65 km observation interval. The setup of this experiment was shown in Table 6.| Parameter | Value |
| Observation height (m) | 40 |
| Observation interval (km) | 30 × 30 |
| Experiment time | July 2016 |
Table6. Setup of representativity error idealized experiment. The representativity error is a variable and other parameters are constants as shown in the table. The errors are 0.01, 0.02, and 0.03.
The threat score (TS) and the root-mean-square error (RMSE) of (U, V, T, P, Q) were determined to evaluate the experiment results. All RMSEs were calculated as the “forecast minus truth” and then averaged. Wind was considered as a vector, and thus the zonal and meridional components were verified. The TS was used to quantify the precipitation forecast.
3.1. Improvements in weather forecasts due to assimilating observations with a height of 40 m
Arnold and Dey (1986) summarized the history of OSSEs and discussed the design of future experiments. Dutta et al. (2015) concluded that OSSEs offer the advantage of a predefined “true” atmospheric state, allowing for sensitivity studies in a controlled environment. Developing a new instrument designed for installation on mobile communication towers is a complex process; therefore, using virtual observations to discuss the potential effect of this new observation system is reasonable.First, the analysis of the terrain check experiment was used to study whether raising the existing weather stations to a higher position would allow more weather stations to pass the terrain quality control check. Table 7 presents statistical information regarding the number of stations that can pass the terrain check at different heights. More stations could be used by the model (i.e., passing the quality control check) with the increasing station height. Table 8 shows similar results for the whole of China. Overall, these results showed that raising stations to higher positions could enable more stations to be used. For example, by raising these stations to 40 m, ~5.6% more stations could be used in our domain, and 7.2% in China overall.
| Height | Passing stations (n) | Passing rate (%) | Passing increase (%) |
| 0 m | 409 | 64.8 | 0 |
| 20 m | 430 | 68.1 | 3.3 |
| 40 m | 444 | 70.4 | 5.6 |
| 60 m | 457 | 72.4 | 7.6 |
| 80 m | 460 | 72.9 | 8.1 |
| 100 m | 463 | 73.4 | 8.6 |
Table7. Number of surface observations passing the quality control check after raising observation station heights in the domain. The reference is the observations at 0 m AGL. The number of total observations is 628.
| Height | Passing stations (n) | Passing rate (%) | Passing increase (%) |
| 0 m | 1049 | 48.6 | 0 |
| 20 m | 1128 | 52.2 | 3.6 |
| 40 m | 1205 | 55.8 | 7.2 |
| 60 m | 1257 | 58.2 | 9.6 |
| 80 m | 1308 | 60.6 | 12 |
| 100 m | 1310 | 60.6 | 12 |
Table8. Number of surface observations passing the quality control check after raising observation station heights throughout China. The reference is the observations at 0 m AGL. The number of total observations is 2160.
Furthermore, analysis of the interpolation error experiment was performed to assess whether raising the heights of weather stations may result in a reduction in interpolation error. Ruggiero et al. (1996) discussed in detail how to use these observations below the model terrain, but they did not discuss the interpolation error. Our statistical experiment on interpolation error yielded a general value for interpolation error at different heights. Determining the interpolation error of wind is difficult due to the complexity of the similarity theory of turbulence, so only temperature and pressure interpolation errors were examined. The results show the stations further from the lowest model level have larger interpolation errors; raising these stations close to the lowest model level could reduce the interpolation errors. Moreover, the interpolation uses background information that changes with time, so the interpolation errors of different cases may fluctuate. In Table 9, errors of ?100 m correspond to the observation at the surface that is 100 m lower than the model terrain. Thus, increasing the height by 40 m means raising the weather stations from ?100 m to ?60 m below the model terrain. Table 9 shows the interpolation error at different heights. On average, for weather stations below the model level, raising them by 20 m reduces the temperature interpolation error by ~0.01°C. The pressure interpolation error decreases rapidly as stations move closer to the lowest model level. For example, the error is reduced by ~0.33 hPa when raising the weather stations from 100 m to 60 m below the model level. The temperature interpolation error is reduced by ~0.02°C.
| Height | Temperature error (°C) | Pressure error (hPa) |
| ?100 m | 0.0856 | 1.1472 |
| ?80 m | 0.0758 | 1.0301 |
| ?60 m | 0.0631 | 0.8107 |
| ?20 m | 0.0384 | 0.4743 |
| ?10 m | 0.0234 | 0.1620 |
Table9. Temperature and pressure interpolation error at various heights below the model terrain. The minus sign indicates the height is below the lowest model terrain.
Third, the weather forecast experiment with new elevated observations (NW_exp) and the new observation ensemble experiment were used to address the question of whether raising the present ground-based observing network by 40 m could improve weather forecasting results. NW_exp shows that assimilating the new observation system leads to a detectable improvement to weather forecasts compared with ground-based observations. The monthly averaged TS improves by 0.01 (Table 10) and has a better forecast RMSE of model variables (U, V, T, RH). As Fig. 4a shows, the forecast temperature RMSE when assimilating new observations is smaller than when assimilating the ground-based observations, and this improvement lasts for the whole 36-h forecast time. This improvement could also be seen in the humidity forecast RMSE (Fig. 4b), zonal wind forecast RMSE (Fig. 4c), and the meridional wind forecast RMSE (Fig. 4d), being especially significant at the 18-h forecast time. Moreover, it was found that the significant improvement of RMSE when assimilating new observations mainly appears within 0?7 km AGL. The temperature forecast RMSE (Figs. 5a-c), meridional wind forecast RMSE (Figs. 5d-f), zonal wind forecast RMSE (Figs. 5g-i), and humidity forecast RMSE (Figs. 5j-l), all show that the forecast RMSE of assimilating new observations are smaller than ground-based observations. The closer to the assimilation time, the better the forecast RMSEs of the new observation. These improvements may be due to the improvement of the ICs after assimilating the new observations. The RMSEs of the ICs show that assimilating the new observations reduces the averaged RMSE of temperature ICs by 11% (Fig. 6a), the RMSE of humidity ICs by 6% (Fig. 6b), the RMSE of meridional wind ICs by 5% (Fig. 6c), and the RMSE of zonal wind ICs by 8% (Fig. 6d). In order to make clear whether these statistical differences are significant, the one-way analysis of variance method was used here and in all subsequent significance tests. The p-values of the F-test, including temperature, humidity and wind are all smaller than 0.05, which means the difference between the experiments is significant and these improvements are reliable. Thus, assimilating new observations could improve the accuracy of weather forecasts by improving the ICs compared with assimilating the ground-based weather stations.
 Figure4. Vertical averaged forecast temperature RMSEs for NW_exp. The black dotted line represents the RMSE for assimilating the ground-based observation and the red line represents the RMSE for assimilating the new observations: (a) forecast RMSE for temperature; (b) RMSE for humidity; (c) RMSE for zonal wind; (d) RMSE for meridional wind.
Figure4. Vertical averaged forecast temperature RMSEs for NW_exp. The black dotted line represents the RMSE for assimilating the ground-based observation and the red line represents the RMSE for assimilating the new observations: (a) forecast RMSE for temperature; (b) RMSE for humidity; (c) RMSE for zonal wind; (d) RMSE for meridional wind. Figure5. Vertically averaged forecast RMSEs for NW_exp. The black dotted line represents the forecast RMSE for assimilating the ground-based observation and the red line represents the forecast RMSE for assimilating the new observations. Panels (a?c) are the forecast RMSEs for temperature at the 3-, 6- and 9-h forecast time; panels (d?f) are the RMSEs for humidity; panels (g?i) are the RMSEs for zonal wind; and panels (j?l) are the RMSEs for meridional wind.
Figure5. Vertically averaged forecast RMSEs for NW_exp. The black dotted line represents the forecast RMSE for assimilating the ground-based observation and the red line represents the forecast RMSE for assimilating the new observations. Panels (a?c) are the forecast RMSEs for temperature at the 3-, 6- and 9-h forecast time; panels (d?f) are the RMSEs for humidity; panels (g?i) are the RMSEs for zonal wind; and panels (j?l) are the RMSEs for meridional wind. Figure6. Monthly-averaged initial condition (IC) RMSEs for NW_exp after data assimilation: RMSE for temperature (a), zonal wind (b), meridional wind (c), and humidity (d). The black dotted line represents the RMSE with assimilating the ground-based observations and the red line represents the RMSE with assimilating the new observations.
Figure6. Monthly-averaged initial condition (IC) RMSEs for NW_exp after data assimilation: RMSE for temperature (a), zonal wind (b), meridional wind (c), and humidity (d). The black dotted line represents the RMSE with assimilating the ground-based observations and the red line represents the RMSE with assimilating the new observations.| Observation type | Little rain | Moderate rain | Heavy rain | Rainstorm |
| Random | 0.431 | 0.609 | 0.468 | 0.542 |
| Ground-based observations | 0.433 | 0.616 | 0.448 | 0.476 |
| New observations | 0.438 | 0.613 | 0.485 | 0.582 |
Table10. The threat scores of 12-h accumulated rainfall for different types of observations. 0.1 mm ≤ little rain < 10 mm; 10 mm ≤ moderate rain < 24.9 mm; 24.9 mm ≤ heavy rain < 49.9 mm; 49.9 mm ≤ rainstorm.
To better illustrate the improvements, we chose a heavy rainfall case from NW_exp using 30 ensembles, with the respective experiment called the new observation ensemble experiment. The ensemble experiment had similar results as NW_exp, improving the forecast. New observations could reduce the temperature averaged forecast RMSE for levels within 0?7 km AGL, as shown in Figs. 7a-c. Figures 7d-f show that at low levels (below 7 km) the temperature averaged forecast is always improved because the averaged forecast RMSE for the experiment assimilating new observations is always smaller than that of ground-based observations. The same improvement can also be seen in the plots of zonal wind averaged forecast RMSE (Fig. 8), meridional wind averaged forecast RMSE (Fig. 9), and humidity averaged forecast RMSE (Fig. 10). In these figures, the top three panels all show that new observations lead to a smaller averaged forecast RMSE within 0?7 km AGL, and the bottom three panels show that this improvement at the low level persists throughout the forecasting period. These results have passed the significance test, with their p-values of the F-test being smaller than 0.05. Furthermore, assimilating new observations (Figs. 11a-d) can also improve the 12-h accumulated rainfall forecast, by improving the accuracy of the maximum precipitation center and reducing “false” precipitation compared with ground-based observations. As shown by the red box, the pattern of the maximum precipitation center for new observations is similar to that for ground-based observations, but with the values closer to the “truth”. At the same time, we find the “false” precipitation for the new observations experiment is smaller, which means the new observations could reduce the “false” precipitation. From the TS table, we can see that the TS of new observations is bigger than that of ground-based observations, so that the forecast is more accurate (Table 11).
 Figure7. Ensemble-averaged temperature RMSE for the new observation ensemble experiment. Panels (a?c) are the vertical temperature RMSEs at the 3-, 6- and 9-h forecast times; panels (d?f) are the temperature RMSEs for 10 m, 40 m and 3 km AGL. The red line represents the RMSE for assimilating new observations and the black dotted line represents the RMSE for assimilating ground-based observations.
Figure7. Ensemble-averaged temperature RMSE for the new observation ensemble experiment. Panels (a?c) are the vertical temperature RMSEs at the 3-, 6- and 9-h forecast times; panels (d?f) are the temperature RMSEs for 10 m, 40 m and 3 km AGL. The red line represents the RMSE for assimilating new observations and the black dotted line represents the RMSE for assimilating ground-based observations. Figure8. As in Fig. 7, but for the ensemble-averaged zonal wind RMSE of the new observation ensemble experiment.
Figure8. As in Fig. 7, but for the ensemble-averaged zonal wind RMSE of the new observation ensemble experiment.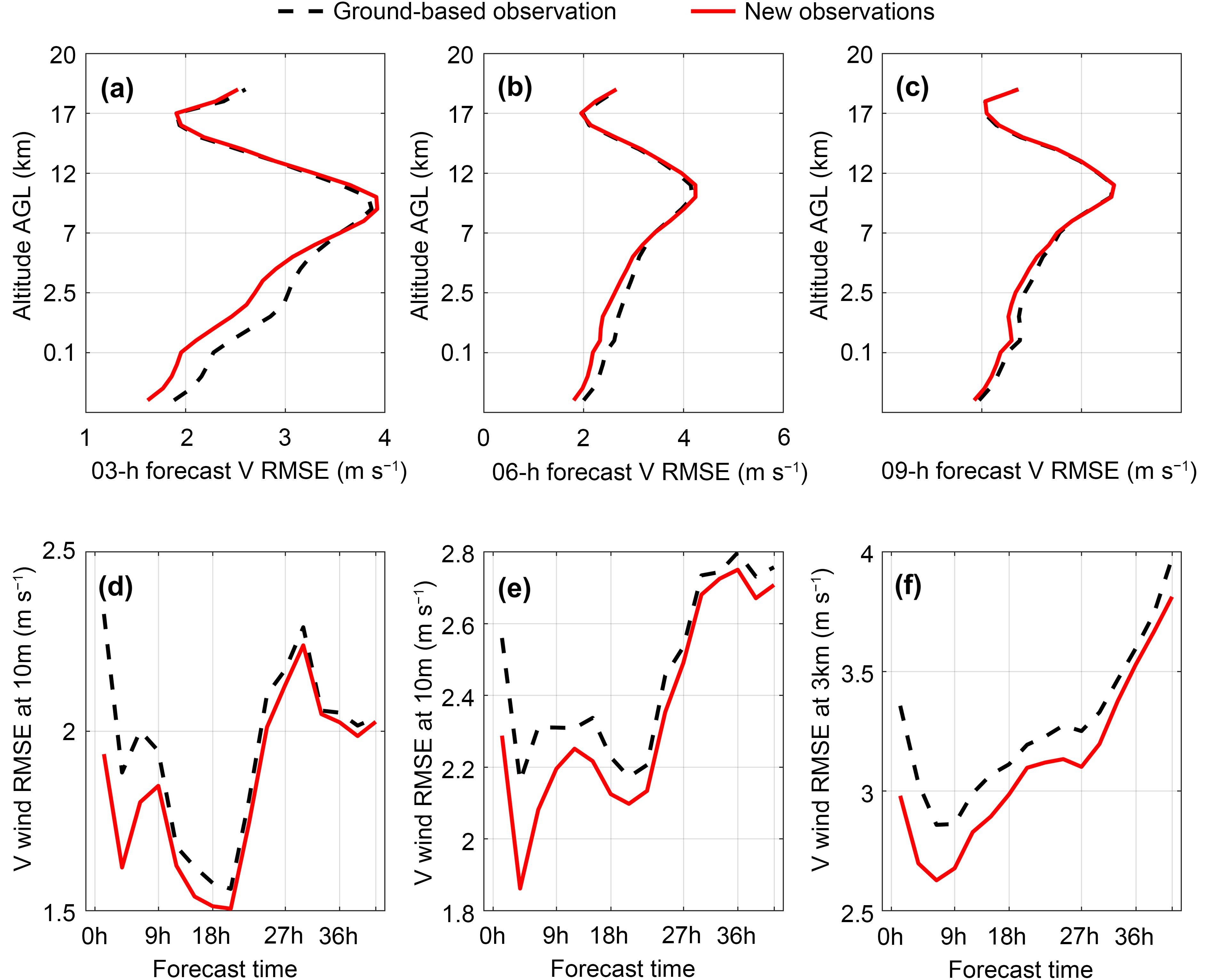 Figure9. As in Fig. 7, but for the ensemble-averaged meridional wind RMSE of the new observation ensemble experiment.
Figure9. As in Fig. 7, but for the ensemble-averaged meridional wind RMSE of the new observation ensemble experiment. Figure10. As in Fig. 7, but for the ensemble-averaged humidity wind RMSE of the new observation ensemble experiment.
Figure10. As in Fig. 7, but for the ensemble-averaged humidity wind RMSE of the new observation ensemble experiment.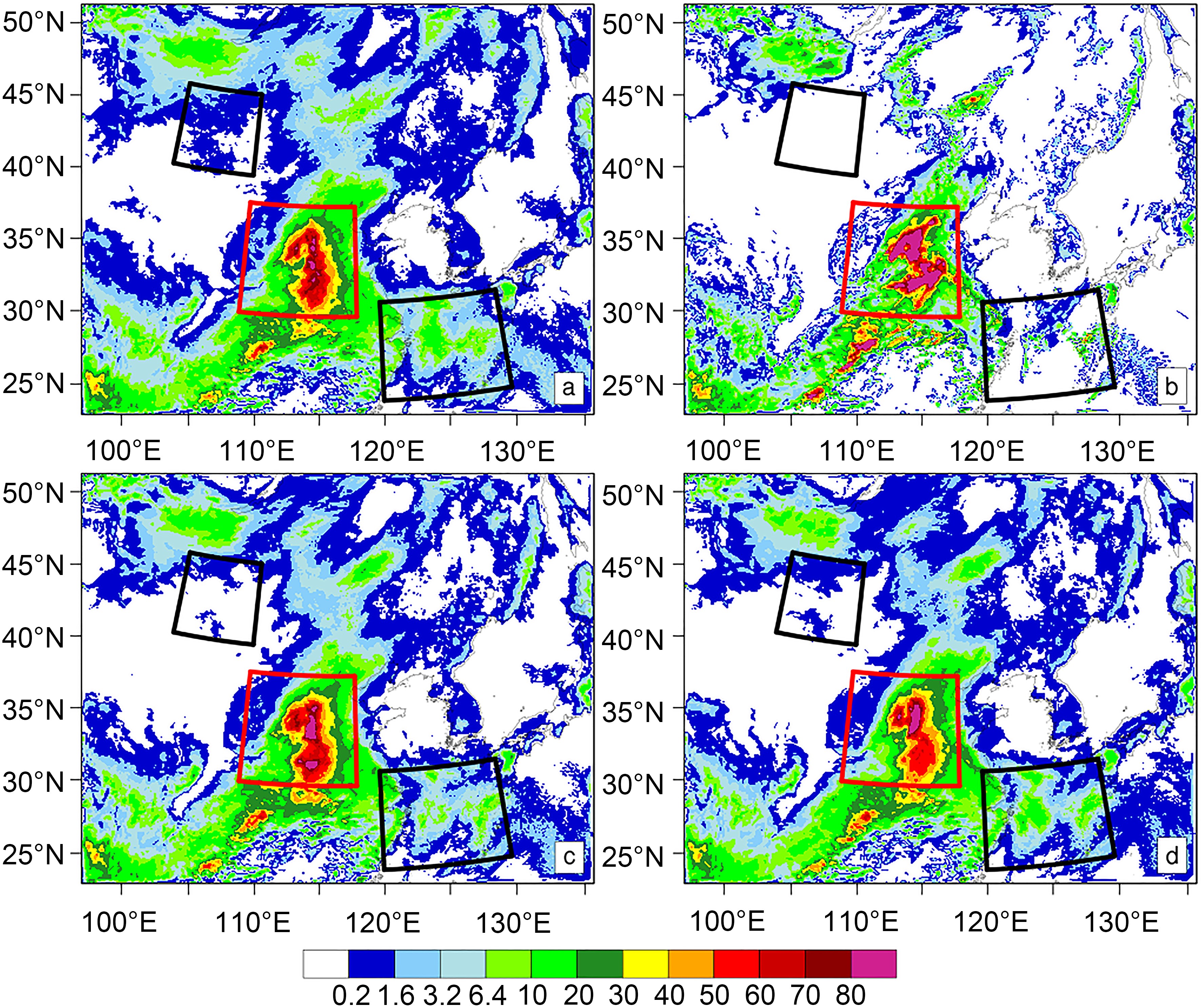 Figure11. Ensemble-averaged 12-h accumulated rainfall (mm) of the new observation ensemble experiment. Panel (a) is the 12-h accumulated rainfall of no data assimilation; (b) is the ensemble-averaged 12-h accumulated rainfall of the “truth”; (c) is the average 12-h accumulated rainfall of the assimilation of new observations; and (d) is the average 12-h accumulated rainfall of the assimilation of ground-based observations. The red box shows the improvement of max accumulated rainfall and black box shows the improvement of false accumulated rainfall.
Figure11. Ensemble-averaged 12-h accumulated rainfall (mm) of the new observation ensemble experiment. Panel (a) is the 12-h accumulated rainfall of no data assimilation; (b) is the ensemble-averaged 12-h accumulated rainfall of the “truth”; (c) is the average 12-h accumulated rainfall of the assimilation of new observations; and (d) is the average 12-h accumulated rainfall of the assimilation of ground-based observations. The red box shows the improvement of max accumulated rainfall and black box shows the improvement of false accumulated rainfall.In the previous discussions we showed how observations taken at higher positions improve weather forecasting. Next, we consider the causes for this improvement. Many previous studies have documented that progress in data assimilation and the improvement of model accuracy are two main ways to improve weather forecasts. The accuracy of the modeled PBL structure is critically dependent on the accuracy of the ICs, as well as several other factors (Alapaty et al., 2001). Data assimilation is one way to ensure good ICs; therefore the following discussion focuses on how improving the IC observations made at 40 m can significantly improve the accuracy of temperature and humidity variables in the ICs in the PBL (Figs. 12a and b). The IC RMSE for new observations was significantly smaller than that for ground-based observations. Regarding the initial wind conditions, the accuracy improvement was more obvious than that for humidity and temperature, where new observations can be affected by wind at distances well beyond the PBL (Figs. 12c and d). In the ICs, this can reduce the average temperature RMSE by 11%, the average meridional wind RMSE by 5%, the average zonal wind RMSE by 14%, and the average humidity RMSE by 4%. These improvements under the ICs are due to data assimilation, rather than to any statistical analysis.
 Figure12. . As in Fig. 6, but for the ensemble-averaged initial condition RMSEs of the ensemble experiment after data assimilation.
Figure12. . As in Fig. 6, but for the ensemble-averaged initial condition RMSEs of the ensemble experiment after data assimilation.Figures 13a and b show the ensemble-averaged temperature error of levels 0?7 km AGL, which uses the analysis (ICs after data assimilation) minus the truth, followed by averaging the ensemble and levels. Figure 13a shows the temperature error of assimilating ground-based observations in ICs, and Fig. 13b presents that of new observations in ICs. The observed temperature error for new observations is smaller than that of the ground-based observations, especially south of 40°N. For zonal wind error, such improvement would be significant across the entire domain grid. The largest improvement occurred west of 120°E, especially near (37°N, 116°E) and (42°N, 114°E) (Figs. 13b and c). This positive effect was also observed for the ensemble-averaged meridional wind error and humidity error. South of 38°N and north of 42°N, the meridional wind error of new observations was smaller than that in the case of the traditional observations (Figs. 13d and e). The improved accuracy of the average values of humidity error also suggests that new observations could improve the accuracy of the humidity data in ICs south of 38°N and north of 42°N (Figs. 13f and g).
 Figure13. Ensemble-averaged error for the new observation ensemble experiment at 0?7 km AGL, which uses the analysis (initial conditions after data assimilation) minus the truth, followed by averaging the ensemble and levels together: (a) temperature error (°C) with assimilating ground-based observations; (b) temperature error with assimilating new observations; (c, d) as in (a, b) but for meridional wind error (m s?1); (e, f) as in (a, b) but for zonal wind error (m s?1); (g, h) as in (a, b) but for humidity error (%).
Figure13. Ensemble-averaged error for the new observation ensemble experiment at 0?7 km AGL, which uses the analysis (initial conditions after data assimilation) minus the truth, followed by averaging the ensemble and levels together: (a) temperature error (°C) with assimilating ground-based observations; (b) temperature error with assimilating new observations; (c, d) as in (a, b) but for meridional wind error (m s?1); (e, f) as in (a, b) but for zonal wind error (m s?1); (g, h) as in (a, b) but for humidity error (%).2
3.2. Key factors in the new observation network
33.2.1. Effect of observation interval
Liu and Rabier (2003) showed that increasing the observation density can improve the forecast; however, increasing the observation density beyond a certain level results in little or no improvement in a global spectral model forecast. Several studies (e.g., Lazarus et al., 2002; Hou et al., 2015) have demonstrated the importance of surface stations in weather forecasting, but no information is available on the effect of the surface observation density on weather forecasting in mesoscale models. Here, we examine the effect of surface observation and new observation density on weather forecasting.Assimilating data gathered according to different observation intervals helped clarify the effect of observation interval on weather forecasting in this study. The results showed that observation density has a large effect on weather forecasting. The averaged RMSEs for wind ICs, temperature ICs, and humidity ICs differed significantly among the observation intervals. As the observation density increased, the averaged RMSE for temperature, humidity and wind in the ICs decreased substantially (Figs. 14a-d). The averaged density (station number/area) of the new observation network is much higher than that of the traditional ground-based weather stations north of 40°N. To the south of 40°N, the distance between the observation sites for traditional ground-based weather stations is smaller than the model grids in some places, which may result in little or no improvement due to adding new observations. This shows the distribution of new observations is more efficient than that of existing surface observations.
 Figure14. As in Fig. 6, but for the vertically averaged initial condition RMSEs of the observation height idealized experiment after data assimilation.
Figure14. As in Fig. 6, but for the vertically averaged initial condition RMSEs of the observation height idealized experiment after data assimilation.3
3.2.2. Effect of observation height
Observation height is another key factor that can affect weather forecasting. To examine this effect, we assimilated perfect observations taken at different weather station heights with the same ICs. Observations at higher heights reduced the RMSE of the ICs in the PBL. As shown in Fig. 15, the RMSE of assimilating new observations was smaller than that of assimilating ground-based observations. The improvement in the temperature error (Fig. 15a) and humidity error (Fig. 15b) of the ICs was significant in the PBL. The observation height is important for wind (Figs. 15c and d), where observations obtained at higher positions can improve the accuracy of wind variables in the ICs from the ground to 7 km AGL. Figure15. As in Fig. 6, but for the vertically averaged initial condition RMSEs for the observation height idealized experiment after data assimilation.
Figure15. As in Fig. 6, but for the vertically averaged initial condition RMSEs for the observation height idealized experiment after data assimilation.3
3.2.3. Effect of representativity errors
The difference between the observed and the true value is called observation error, and has an important impact on data quality. The observation error covariance matrix shows the same degree of instrumental error, so the differences between measured and true values can be attributed to representativity errors. A different model grid was used to assimilate the observations obtained at the same height but with different representativity errors. The results show that a smaller representativity error can reduce the RMSE in the ICs, especially for near-surface observation data assimilation. The mobile communication tower?based observation network is less affected by the environment and thus could possess smaller representativity errors.Several other aspects related to the proposed observing network could affect forecasting accuracy. It was found that the new observing network showed improvements in the key parameters of observation density, representativity error and observation height. The observation density improvement was more important than the reduction in representativity error and raising observation height, improving the variables’ accuracy of the ICs in the PBL. In summary, the reduced representativity error and elevated observation height had a positive effect on weather forecasting accuracy.
A developed network of mobile communication towers in China could serve as the infrastructure for a new weather station network operating at higher observation positions than the current network. Future studies will investigate new instruments designed for the tower installation, to allow stable and reliable measurements of meteorological parameters.
The pressure below the lowest model level will be determined using the above equation. P0 is the observation pressure, hm is the model height, h0 is the observation height, Tv is the average virtual temperature between the model and observations, R is the dry gas constant, g is the acceleration of gravity and e is the exponential function.
The temperature observation model used was:
where θ is the potential temperature, h is height, and P is pressure. Regarding the subscripts, 0 represents the observation position, m represents the model surface, and 100 hPa indicates the variable is at the height of 100 hPa less than surface pressure. δsfc is the difference between the interpolation potential temperature and observing potential temperature, R is the dry gas constant, Tm is the estimated temperature at model surface and Cp is the isobaric heat capacity.
