随着连续干扰消除(SIC)技术的提出,基于竞争的多用户接入协议性能得到提升。文献[4]提出CRDSA(Contention Resolution Diversity Slotted ALOHA)协议,每个用户在每帧中重复发送2个复制包,每个复制包包头中包含另一个复制包发送的位置信息,只要其中一个复制包被接收或恢复,就可以将另一个复制包造成的干扰消除掉。相比于ALOHA协议,CRDSA协议吞吐率峰值提升到0.55,并且CRDSA协议被应用在DVB-RCS中。文献[5]在CRDSA协议基础上提出IRSA(Irregular Repetition Slotted ALOHA)协议,对每帧中发送的复制包数进行优化,由固定的两包优化为服从一定概率分布。但是IRSA协议中,并没有考虑用户QoS需求,并且在高链路负载下,吞吐率急速下降。另外一些关于在随机接入中应用连续干扰消除研究在文献[6-8]中提出。
在大量突发业务中,有一些定期位置报告信息,对实时性等没有很高要求;而有些业务涉及到安全威胁等信息,要求快速准确地传输,因而需要更多的保护。文献[9]提出的PR-ALOHA(R-ALOHA with Priority)协议,对不同优先级数据进行了不等错误保护。PR-ALOHA协议中,每帧固定留有一部分时隙只提供给高优先级用户接入,降低高优先级数据碰撞概率,提高高优先级用户吞吐率。但是PR-ALOHA协议中,碰撞的数据包依然被丢弃,信道资源没有得到有效利用。
针对上述IRSA协议在高链路负载吞吐率急速下降,ALOHA和PR-ALOHA协议在低链路负载吞吐率低等问题,本文提出了一种具有自适应不等差错保护性能的多用户接入方法。该方法在低链路负载情况下,用户可以接入任一时隙,以达到吞吐率最大;而在高链路负载情况下,某些固定时隙只允许高优先级用户接入,保证高优先级数据的有效传输。
1 系统模型 卫星多用户接入模型如图 1所示。
 |
| 图 1 多用户接入系统模型 Fig. 1 System model of multi-user access |
| 图选项 |
假设卫星每一帧被分为n个时隙,共有m个用户发送数据。时隙和用户均被分为r个不同优先级:优先级1,优先级2,…,优先级r,且优先级级别由高到低。在低链路负载情况下,所有用户可以选择一帧中任一时隙中发送数据;在高链路负载情况下,每个用户只能发送到具有相同优先级或者更低优先级的时隙中。例如优先级为2的用户,可以发送到优先级为2, 3, …, r的时隙中。本文着重对高链路负载情况下不同用户的吞吐率性能进行分析。
假设多用户接入过程中,数据包丢失仅仅是因为碰撞引起的,即某一数据包被恢复,其造成的干扰可以消除掉。这样假设是合理的,因为使用高性能的信道编码如turbo-cliff可以使得在较高信噪比的情况下,数据包不会因比特错误而被删除掉[10]。对于衰落信道下,可用停止集思想进行进一步分析[11],此假设依然是有效的。此外,本文不考虑捕获效应等对接入过程造成的影响。
本文给出4个参数定义:
定义1??链路负载G,代表平均每个时隙中传输的数据包数(用户数目与时隙数目的比值),即
 | (1) |
定义2??丢包率q,代表平均每个数据包未被成功传输的概率,即接收端未能恢复出的数据包数与用户发送数据包数的比值。
定义3??链路负载门限G*,门限值被定义为使得连续干扰消除过程能够进行并能恢复出碰撞数据包时的最大链路负载值,可由式(2)推导得出[11]
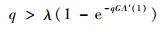 | (2) |
式中:λ为用户的边度分布;Λ′(1)为平均每个用户每帧发送的数据包数。
定义4??吞吐率T,代表平均每个时隙中数据包传输正确的概率(正确传输的数据包数目与时隙数目的比值),即
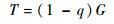 | (3) |
2 连续干扰消除 分集接入指用户的每一个数据包被重复发送多次,在每一个复制包中包头位置都包含其他复制包的位置信息。多用户随机接入与连续干扰消除过程如图 2所示。图 2(a)中,用户2发送2个复制包分别为U2_1和U2_2,接收端一旦成功接收到U2_2,就可以得知用户2在时隙2中发送了包含相同信息的数据包,即此时U2_1可看作已知。连续干扰消除的思想是将已知的信息作为干扰消除掉,从而恢复出碰撞的数据包。接收端根据U2_2的信息,将U2_1造成的干扰消除掉,恢复出用户3的数据包。
 |
| 图 2 多用户随机接入与连续干扰消除过程 Fig. 2 Random multi-user access and successive interference cancellation process |
| 图选项 |
连续干扰消除过程可以使用二分图进行描述,如图 2(b)所示。圆圈代表用户,方块代表时隙,其中灰色方块表示来自不同用户的数据包发生了碰撞。数据传输过程用圆圈到方块的连线表示,例如圆圈处有2条线分别连到不同方块,代表用户的度值为2,进入方块的连线来自2个不同的用户,代表时隙的度值为2。
多用户的随机接入与干扰消除过程类似于LT(Luby Transform)码的编解码过程,用户的数据包作为信息符号,时隙作为编码符号,但其中存在有一些差异。在LT码编码过程中,可以设计编码符号度分布,以及定义每个信息符号参与编码的概率,达到不等差错保护的目的。在多用户随机接入过程中,接入用户的度分布(等效为信息符号的度分布)是可控的,由于随机性,时隙的度分布(等效为编码符号的度分布)是不能确定的。
在LT码中实现不等差错保护主要有2种方案:在文献[12]中,重要的信息符号被赋予更大的参与编码的概率;在文献[13]中,含有重要信息的编码符号被赋予较小的度值。在本文提出的具有不等差错保护的多用户接入方法中,高优先级数据只允许高优先级用户接入,以此达到控制编码符号度值的目的。
定义多用户接入过程中的度分布(本文度分布均默认为节点度分布):Λ(x)为每个用户重复发送数据包的度分布,Ψ(x)为每个时隙接收到的用户数量的度分布。Λ(x)和Ψ(x)可表示为
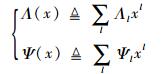 | (4) |
式中:Λl为每个用户重复发送l个数据包的概率;Ψl为每个时隙接收到l个用户数据包的概率。Λ′(1)=
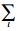
度分布还可以用边度分布来描述:
 | (5) |
式中:λl为一个边连接到度值为l的用户节点的概率;ρl为一个边连接到度值为l的时隙节点的概率。
边度分布与节点度分布之间的关系可表示为
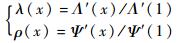 | (6) |
3 链路负载估计及自适应调整 为了实现对用户的接入控制,首先需要知道链路负载,即接入的用户数量。在非协同的多用户随机接入过程中,每帧活跃的用户数量不能精确已知,但是可以通过对上一帧接收到的数据包碰撞情况估算出链路负载。
每个用户根据度值随机选择发送的时隙(每个用户每帧平均发送Λ′(1)个数据包),在接收端收到的数据包数服从二项分布。根据二项分布定理,某个时隙被某一个用户占用的概率为P=Λ′(1)/n,可以得到以下几个概率值:
PI定义为空闲时隙的概率,即一个时隙里没有用户数据包接入,可表示为
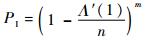 | (7) |
PS定义为成功时隙的概率,即一个时隙里只有一个用户数据包接入,接收端直接得到用户信息,可表示为
 | (8) |
PC定义为碰撞时隙的概率,即一个时隙里有2个或多个用户数据包接入导致信息碰撞,可表示为
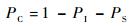 | (9) |
根据上述概率,可以得到一帧中空闲时隙数的期望值ain, m,成功时隙数的期望值asn, m,碰撞时隙数的期望值acn, m,分别为
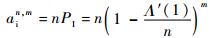 | (10) |
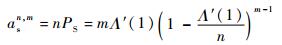 | (11) |
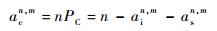 | (12) |
目前已有多种链路负载估计算法,例如Vogt算法、Cratio算法、Schoute算法和Low Bound算法。Vogt算法可以做出误差相对较为小且稳定的估计,因此本文采用Vogt算法来估计用户的数目。
 | (13) |
式中:d为估计误差;ci、cs、cc分别表示上一帧中成功时隙数、空闲时隙数、碰撞时隙数。
根据链路负载,自适应调整接入策略,调整过程如图 3所示。
 |
| 图 3 自适应调整过程 Fig. 3 Adaptive adjustment procedure |
| 图选项 |
用户向接收端发送数据后,首先,数据接收端根据时隙碰撞情况进行链路负载估计。其次,接入控制器用来决定接入策略:在低链路负载情况下(G<G*),各用户端可以选择任意时隙发送数据;在高链路负载情况下(G≥G*),进行接入调整,即用户端在其被允许的时隙内接入数据。最后,用户为发送的数据包随机选择度值。
4 理论分析 4.1 与或树分析与不等差错保护 在与或树中[14],所有位于偶数深度(0, 2, 4, …, 2l-2)上的节点称为“或节点”,因为它们会把所有其子节点的值进行逻辑“或”运算;而所有位于奇数深度(1, 3, 5, …, 2l-1)上的节点称为“与节点”,因为它们会把所有其子节点的值进行逻辑“与”运算。假定每个叶子节点的值被独立地赋予“0”或者“1”。设每个或节点拥有i个子节点的概率为λi,而每个与节点拥有i个子节点的概率为ρi,则与或树根节点为0的概率qi可由i次迭代获得
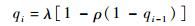 | (14) |
式中:λ(x)=
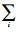
下面介绍与节点和或节点类型均不一致的与或树分析。不同优先级的用户具有相同的边度分布λ,具有优先级为k的时隙的边度分布为ρk。由于接入用户和时隙均具有不同的优先级,所以每个或节点和与节点均分别地含有不同类型的子节点。在第i次迭代中,某个优先级为j的或节点含有优先级为k的子节点的概率为wjk,某个优先级为k的与节点含有优先级为m的子节点的概率为ukm。则与或树具有优先级j的根节点为0的概率ql, j可由l次迭代获得
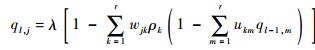 | (15) |
式中:λ(x)=
4.2 多用户接入过程 用户和时隙均具有不同优先级,则不同优先级时隙接收到的碰撞数据包数是不同的。假设优先级为k的用户所占的比例为Puser(k),优先级为k的时隙占时隙数的Pslot(k)。显然得到
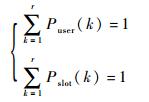 | (16) |
用户只能发送数据包到具有相同优先级或者更低优先级的时隙中,所以每个时隙中包含具有相同优先级或者更高优先级的数据包。具有不同优先级的时隙包含的平均碰撞数据包数可以表示为
 | (17) |
由二项分布定理可知,优先级为k的时隙,接收到l个用户数据包的概率为
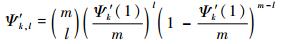 | (18) |
因此时隙的度分布可以表示为
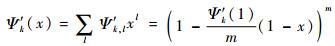 | (19) |
用户数量趋近于无穷(m→∞),二项分布趋向于泊松分布,泊松分布的参数为Ψ′k(1)。多用户接入过程中的度分布和边度分布分别表示为
 | (20) |
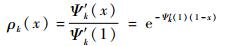 | (21) |
wjk定义为
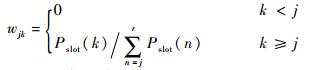 | (22) |
ukm定义为
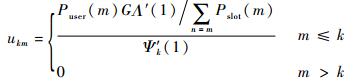 | (23) |
考虑只2个优先级的情况,假设接入用户的度分布为Λ(x)=0.5x2+0.28x3+0.22x8,不同优先级用户所占比例为Puser=(0.5, 0.5),不同优先级时隙所占比例为Pslot=(0.5, 0.5)。根据上述分析,可以得到
 |
5 实验结果 本文将所提出的具有不等差错保护的多用户随机接入方法与ALOHA和IRSA进行对比。接入用户度分布设置为Λ(x)=0.5x2+0.28x3+0.22x8,此时链路负载门限为G*=0.938[5]。假设所有数据包具有相同的长度,帧长值固定为2 000 (即每帧中包含2 000个时隙)。最大迭代次数设置为Imax=200,每个仿真点结果在相同条件下取100次实验的平均值。
分析丢包率和吞吐率性能时,将用户和时隙分为高低2个优先级,不同优先级用户所占比例Puser为(0.5, 0.5),不同优先级时隙所占比例Pslot分别设置为(0.5, 0.5),(0.4, 0.6)和(0.6, 0.4)。链路负载变化由0.1~2.0,并且将仿真结果与分析结果进行对比。
5.1 链路负载估计性能 首先本文分析了链路负载由0.1~2.0变化范围内,负载估计的均值和均方差,如表 1所示。
表 1 链路负载估计均值和方差 Table 1 Traffic load estimate mean and variance
| 负载 | 均值 | 均方差 |
| 0.2 | 0.200 | 0.007 |
| 0.4 | 0.400 | 0.013 |
| 0.6 | 0.601 | 0.017 |
| 0.8 | 0.799 | 0.025 |
| 1.0 | 1.006 | 0.038 |
| 1.2 | 1.203 | 0.053 |
| 1.4 | 1.408 | 0.080 |
| 1.6 | 1.616 | 0.119 |
| 1.8 | 1.824 | 1.954 |
| 2.0 | 0.140 | 0.165 |
表选项
仿真结果表明,估计的链路负载接近实际链路负载,估计均方差随着负载G变大而增加。
图 4给出了链路负载G=0.938时的估计概率分布图,其概率密度分布可以近似为一个均值和均方差随G变化的高斯分布。
 |
| 图 4 G=0.938时链路负载估计概率分布 Fig. 4 Traffic load estimation density at G=0.938 |
| 图选项 |
5.2 丢包率性能 丢包率性能如图 5所示,根据式(16)进行迭代,得到丢包率的理论值曲线,由图中analysis曲线表示。simulation曲线为模拟协议中碰撞与连续干扰消除过程得到的仿真结果。UE_0505_L曲线为提出的协议中Pslot=(0.5, 0.5)时低优先级用户丢包率性能,UE_0505_H曲线为Pslot=(0.5, 0.5)时高优先级用户丢包率性能。
 |
| 图 5 不同优先级用户丢包率性能对比 Fig. 5 Comparison of packet loss probability performance of users with different priorities |
| 图选项 |
仿真结果表明,仿真结果与理论分析一致。ALOHA协议丢包率随链路负载增加而增大。在低链路负载情况下,IRSA协议中连续干扰消除过程可以恢复出绝大部分碰撞数据包;链路负载超过门限值时(用户度分布为Λ(x)=0.5x2+0.28x3+0.22x8时,门限值G*=0.938),连续干扰消除过程失败,导致丢包率急速上升。而本文提出的具有不等差错保护的多用户随机接入方法,在低链路负载下,丢包率接近0,性能优于ALOHA协议;在高链路负载下高优先级数据丢包率性能优于IRSA协议。
5.3 吞吐率性能 系统吞吐率性能如图 6所示,分别为时隙分配比例为(0.5, 0.5),(0.4, 0.6),(0.6, 0.4)的性能曲线。吞吐率的理论值曲线由式(16)和式(4)推导得出,由图中analysis曲线表示。simulation曲线为模拟协议中碰撞与连续干扰消除过程得到的仿真结果。
 |
| 图 6 不同优先级用户吞吐率性能对比 Fig. 6 Comparison of throughput performance of users with different priorities |
| 图选项 |
与丢包率曲线趋势一致,当链路负载超过门限值时,IRSA协议吞吐率迅速下降并接近0。本文提出的具有不等差错保护的多用户随机接入方法在门限值附近,吞吐率也有所下降。在门限值处,采用自适应方法,高优先级数据包可以发送到任一时隙,而低优先级数据包只可以发送到低优先级时隙中,低优先级数据包译码率受影响,导致吞吐率下降。吞吐率下降一段后,又趋于平缓,因为高优先级时隙中只包含高优先级数据包,链路负载刚达到门限值时,在高优先级时隙中负载并没有饱和,随着链路负载增加,高优先级时隙利用率增加直到饱和,所以存在变缓再下降的变化趋势。
由3组仿真结果表明,在高链路负载情况下,高优先级数据分配的高优先级时隙比例越高,其吞吐率峰值越高,但吞吐率下降速度越快。
本文提出的具有不等差错保护的多用户随机接入方法,采用自适应的方法,在低链路负载情况下,每个数据包随机选取所有时隙,与IRSA相比吞吐率性能不损失,与ALOHA协议相比可有效避免碰撞引起的丢包;在高链路负载下,高优先级数据包分配更多时隙传输,其数据吞吐率性能优于IRSA协议,略低于ALOHA协议。
6 结论 为保证高链路负载下高优先级用户数据有效传输,本文提出了一种具有不等差错保护作用的多用户随机接入方法,经理论分析与实验表明:
1) 协议可对链路负载进行估计,接入用户根据负载变化进行自适应调整。
2) 协议在低链路负载下,避免碰撞引起的丢包,保证吞吐率性能不下降;在高链路负载下,尽可能保证高优先级用户的数据传输。
本文所提出的不等差错保护多用户随机接入方法可用于遥测遥控数据通信中,在链路拥塞情况下,尽可能多传输有效信息。
参考文献
| [1] | TASAKA S. Multiple-access protocols for satellite packet communication networks:A performance comparison[J].Proceedings of the IEEE, 1984, 72(11): 1573–1582.DOI:10.1109/PROC.1984.13054 |
| [2] | ABRAMSON N.The ALOHA system:Another alternative for computer communications[C]//Proceedings of the Fall Joint Computer Conference.New York:ACM, 1970:281-285.https://dl.acm.org/citation.cfm?id=1478502 |
| [3] | CELANDRONI N, FERRO E, GOTTA A. RA and DA satellite access schemes:A survey and some research results and challenges[J].International Journal of Communication Systems, 2014, 27(11): 2670–2690. |
| [4] | CASINI E, DE GAUDENZI R, HERRERO O R. Contention resolution diversity slotted ALOHA (CRDSA):An enhanced random access schemefor satellite access packet networks[J].IEEE Transactions on Wireless Communications, 2007, 6(4): 1408–1419.DOI:10.1109/TWC.2007.348337 |
| [5] | LIVA G. Graph-based analysis and optimization of contention resolution diversity slotted ALOHA[J].IEEE Transactions on Communications, 2011, 59(2): 477–487.DOI:10.1109/TCOMM.2010.120710.100054 |
| [6] | STEFANOVIC C, PSTEFANOVIC C, POPOVSKI P. ALOHA random access that operates as a rateless code[J].IEEE Transactions on Communications, 2013, 61(11): 4653–4662.DOI:10.1109/TCOMM.2013.100913.130232 |
| [7] | PAOLINI E, LIVA G, CHIANI M. Coded slotted ALOHA:A graph-based method for uncoordinated multiple access[J].IEEE Transactions on Information Theory, 2015, 61(12): 6815–6832.DOI:10.1109/TIT.2015.2492579 |
| [8] | HASAN M N, ANWAR K.Massive uncoordinated multiway relay networks with simultaneous detections[C]//IEEE International Conference on Communication Workshop.Piscataway, NJ:IEEE Press, 2015:2175-2180.http://ieeexplore.ieee.org/document/7247504/ |
| [9] | ALSBOU N, HENRY D, REFAI H.R-ALOHA with priority (PR-ALOHA) in non ideal channel with capture effects[C]//2010 IEEE 17th International Conference on Telecommunications (ICT).Piscataway, NJ:IEEE Press, 2010:566-570.http://ieeexplore.ieee.org/document/5478849/ |
| [10] | PURWITA A A, ANWAR K. Massive multiway relay networks applying coded random access[J].IEEE Transactions on Communications, 2016, 64(10): 4134–4146. |
| [11] | ANWAR K.Graph-based decoding for high-dense vehicular multiway multirelay networks[C]//IEEE Vehicular Technology Conference.Piscataway, NJ:IEEE Press, 2016:1-5.http://ieeexplore.ieee.org/document/7504263/ |
| [12] | RAHNAVARD N, FEKRI F.Generalization of rateless codes for unequal error protection and recovery time:Asymptotic analysis[C]//2006 IEEE International Symposium on Information Theory.Piscataway, NJ:IEEE Press, 2006:523-527.http://ieeexplore.ieee.org/document/4036017/ |
| [13] | NEKOUI M, RANJKESH N, LAHOUTI F.A fountain code approach towards priority encoding transmission[C]//Proceedings of 2006 IEEE Information Theory Workshop (ITW'06).Piscataway, NJ:IEEE Press, 2006:52-55.http://ieeexplore.ieee.org/document/4119253/ |
| [14] | LUBY M, MITZENMACHER M, SHOKROLLAHI M A.Analysis of random processes via and-or tree evaluation[C]//Proceedings of the 9th Annual ACM-SIAM Symposium on Discrete Algorithms.New York:ACM, 1998:364-373.https://mathscinet.ams.org/mathscinet-getitem?mr=1642948 |
