��FDTD���ģ���м����е�Ч�����������˽ṹ�������������Эͬ������Ӧ�ԸĽ��������棬2004��Su��[2]�����MPI��OpenMP��ϵķ�ʽ��SGI Origin2000����ϵͳ��ʵ����FDTD���м��㣻2005�����Ļ���[3]�о���FDTD�����㷨ʵ�֡��߽����ݽ�����ʽ������Ч�ʵ����⣬ʹ��200�����ϴ������ﵽ90%���ϵIJ���Ч�ʣ�2004��Krakiwsky[4]��2007��Adams[5]�ȷֱ�չ�˵���ͼ�δ�����Ԫ(GPU)��Intel��AMD�������ıȶԲ��ԣ�2009��Du��[6]��չ�˻���CUDAƽ̨����άFDTD������ԣ��ó�����C�����д����CPUϵͳ�²��ԣ�ʵ����10���ļ��ٱȣ�2008����褵�[7]�����Su[2]�����Ļ�[3]�ȵĹ�������Pentium4 CPU��ɵ�PC��Ⱥϵͳ��ʵ���˳��߳��µIJ��з�����2010��Komatitsch��[8]��GPU��Ⱥ��(192��)ģ�����������CPU������������ʮ����2010��Jacobsen��[9]��Lincolnϵͳ��ȡ��8�߳�CPU�汾130*�����ܣ�2012��Nagaoka��Watanabe[10]����3���ڵ�(һ��21��NVIDIA TESLA C2070 GPU)���30%�IJ���Ч�ʣ�2011��Yang��[11]����Tesla C1060��Tesla S1070��ɵķ������ϳɹ�������ð��������˷��ȳ���2012��Kim��Park[12]����GPU���ԣ����GPU��Kernel�������ۼ���Ч�ʣ� 2013��Xu��[13]ʹ��64��NVIDIA Tesla K20m(GPU)������άFDTD���ԣ��õ�67.5%�IJ���Ч�ʺ�3.1�ļ��ٱ�(�����Intel XEON E5-2670 CPU)��Yang��[11]��GPU��Ⱥ��(5��)�о�OpenMP+CUDA��ϱ��ģ�ͣ�������������MPI+CUDA���ơ���ǰ�˵Ĺ����з��֣���Щ��PCϵͳ�۸���ڰ���Ⱥ�ԵIJ��Բ�û�еõ��㷺ʹ�ã����㵥Ԫ������Ҳ�������ӣ�ģ�ͺ��㷨�IJ���Ч����ؽ����ߣ�PC֮��������ٶȳ�Ϊƿ�������㵥Ԫ��ĸ���ƽ��Ҳ��Ϊ��Ҫ����֮һ����ͨ��PC��֧�ֵ�GPU�����������Դ��С���ޣ��ﲻ��������ݹ�ģ�dz������������GPU�ͼ�Ⱥ�ļ�������ؽ�����ϣ����ؿ�����GPUͨ�ü���ķ�Χ��ʹ�ò��м������ܵõ��������������Ҫͨ�����㸴�ӵ��ߴ�ƽ̨���Լ����㷨�IJ���Ч�ʺͼ���Ч����
���Ļ��ڷֲ�ʽƽ̨��չһ���µ�FDTD�����㷨�о��������Ϻ���ͨ��ѧ�����ܼ�������GPU��Ⱥ���Ϻ�������������ĵġ�ħ�������ó���������Լ����ҳ�������������ĵġ��������⡱�������������ƽ̨��չ���ԡ�ʵ��ƽ̨����NVIDIA Tesla M2070(GPU)��NVIDIA Tesla K20m(GPU)����Ⱥʹ��MellanoxInfiniband FDR��������Intel Xeon E5-2670�ȼ����豸��
1 FDTD �㷨��� 1.1 ��άFDTD�������� FDTD�㷨��Maxwell���ȷ��������ʱ��Ϳռ����ɢ���õ����ƵIJ�ַ��̣��ò�ַ��̵Ľ���ƴ���ԭ���̵Ľ⡣���������У���Ҫ��֤�������������Ժ��ȶ��ԡ��о��ı����ռ���=0,��m=0(��Ϊ���ʵĵ����,��mΪ���ʵĴ����)����Maxwellת��Ϊ6���������̣�
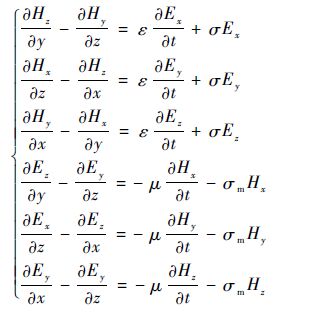 | (1) |
ʽ�У�E(Ex,Ey,Ez)Ϊ�糡ǿ�ȣ�H(Hx,Hy,Hz)Ϊ�ų�ǿ�ȣ��������ֱ�Ϊý�ʵĴŵ��ʺͽ�糣����
����Yee�����Ԫ��ԭ������ʽ(1)��ɢ�õ�[14]
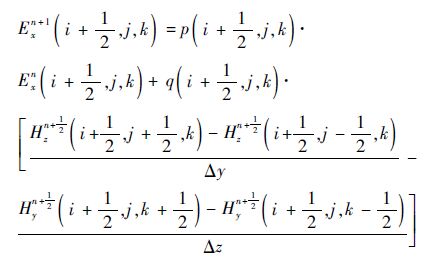 | (2) |
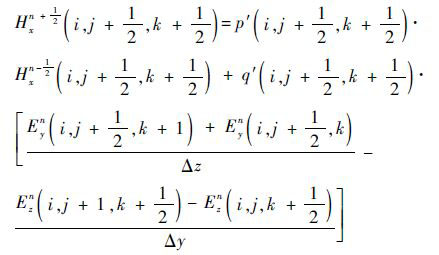 | (3) |
ʽ��:
 |
��x����y�ͦ�zΪ�ռ䲽������tΪʱ�䲽����ͬ�����Եõ�Eyn+1��Hyn+ 1 2 ��Ezn+1��Hzn+ 1 2 ���̣��γ���ά��������FDTD��ַ����顣����ʱ�䲽��ֵȡ����ǰһʱ�̿ռ䲽����ʱ�䲽���糡�ʹų���ֵ��
1.2 ��ֵ�ȶ��Ժ�ɫɢ FDTD��ַ�����ֻ����ɢ������⣬��ɢ����Ҫȷ��������Ľ����������ȶ��ģ�����x����y����z�ͦ�t����һ��������[15]������
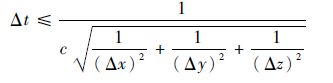 | (4) |
ʽ�У�cΪ����еĹ��١���������FDTD�㷨��Courant�ȶ�������Ҳ�Ǧ�t�������Լ�������������x=��y=��z=��(���趨Ϊ������Ԫ���߳�)ʱ����õ�
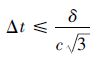 | (5) |
��ʽ(5)���Կ�����ʱ��仯��Ӧ�ò����ڹⲨ��YeeԪ���Խ��߳��ȵ�1/3��ʱ�䡣
1.3 ���ձ߽����� ���IJ���Mur���ձ߽���ģ���Ų������ͨ���ضϱ߽磬ȷ�����ռ������ռ��Ч��ʹ����߽����н��IJ��ڱ߽紦���֡������н���������������Զ��������Mur���ձ߽��Ƕ�Engquist-Majda���ձ߽��һ�ֽ��ơ�����άCartisian����ϵ�£�Mur���ձ߽�ĵ�����ʽΪ(��EzΪ��)[16]
 | (6) |
������ɢ���覤x=��y=��z=�����õ�
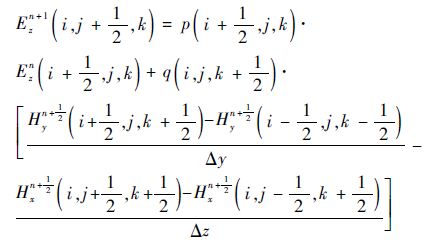 | (7) |
����3���߽�Ҳ���������ƴ�������ijһʱ�̵ij�ֵ���������������Ϳ��Եõ���ʱ��仯�ĵ�ų���ֵ�ķֲ�������������̼�ͼ 1��
 |
| ͼ 1 FDTD�㷨���� Fig. 1 FDTD algorithm flow |
| ͼѡ�� |
2 �㷨���в��� 2.1 ����ͨ�ż����� ���ڶ�GPU�ļ���ƽ̨��CUDA��ʵ�ֶ�ÿ��GPU�Ŀ��ƣ��������İ�Kernel��ִ�С��Դ�ķ����븴�ơ�CUDA5.0��ƽ̨�涨��������߳̿ɶ�һ���豸���в�����һ�������߳̿���һ���豸��Ϊʵ��FDTD�Ķ�GPU���е��Ƽ�GPU֮������ݴ��䣬���ǵ�GPU֮�䲻��ֱ�ӽ������ݣ�ֻ�����ڴ潻�����ݣ�����ֻ��ҪΪ�߽������ͨ�ŷ���CPU�ڴ棬��������ͨ��ʱ���������Ƿ�������Լ�ѡ����ʱ����ͬʱ����GPU���ڴ�����ͨ�ŵ����ԣ������о��������������ͨ�ŷ�������ͬ�����ݴ��䷽�����첽���ݴ��䷽��(��ͼ 2)���ڶ����ַ������о��з��֣�ͬ�����ݴ���Ҫ�����ݵĴ������GPU����������Yee����ֵ�ĵ��ƺ���У�ÿһ�α߽����ݵĴ��䶼��Ҫ�����������H(����E)��ֵ�ĸ�����ɺ���У�ͬ���ڽ���E(����H)��ֵ�ĸ���ǰҲ��Ҫ�ȴ��������ݵ���ɣ�Ҫ�����ݵĴ����GPU��CPU���ٴ�CPU������һ��GPU���Ӷ�Ӱ������ļ���Ч�ʣ� �첽���ݴ��䷽��ʵ����GPU�ڲ��Ķ�����IJ��м����GPU���м��㣬ʵ���˼��������ݴ���IJ��У���ʵ���˼��������������������У���Ȼ��ͬ�����ݴ��䷽����Ϊ���ӣ�����Ч�ؼ��������ݴ�����ռ��ʱ�����������˲���Ч�ʡ����ԣ�����ѡ��ʹ���첽���ݴ��䷽�������ǵ�FDTD��ֵ�ĸ��½�����Ҫ����Χ���ļ��������������Ա߽����ݵ�ͨ�ſ��ԺͲ���������ij�ֵ����ͬ�����У�ʹ��CUDA�е���(Stream)���ƻ��ƺ��첽�ڴ渴�ƺ������й�����
 |
| ͼ 2 �첽���ݴ��估���㷽�� Fig. 2 Asynchronous data transmission andcomputing solutions |
| ͼѡ�� |
Stream����˳��ִ��һϵ�в��������������п����кܶ��Stream������һ��Stream�����������Stream����ִ�в�����Ҳ����˳�����ͬʱִ�в�������һ��Stream�ļ����������Streamͨ�Ŵ��䲢�����У������GPU����Դ��ʹ���ʡ�Streamͨ������һ��CudaStream_t���������壬������Kernel�ͽ����ڴ渴�ƺö����룬��ͬ�Ķ��������Ӧ��ͬ��Stream���������ö��Stream���������в�����ѡȡ���е�����Stream������ԭ����������һ��StreamΪStream_1������һ��StreamΪStream_2��Stream_1���ֱ߽糡ֵ�ĸ���������ͨ�Ŵ��䣬���е�����ͨ�Ŵ��䲿��ʹ��CudaMemcpy2DAsync����ִ�С�Stream_1�ĸ��¿����˼�����Դ�ij�����ã����������������٣�ͬʱ��֤������Stream���ص�ƽ���Լ�GPU������������Stream_1����ͨ�Ŵ��䲿�ֺ�Stream_2�ļ��㲿�ֿ���ͬʱ���С����ǣ��첽���ƺ��������õ��ڴ����ҳ������(page-locked)������ǰ��GPU�ɼ������Խ��ұ߽�H��ֵ��CPU�ڴ渴�Ƶ�GPU n+1�Ŀɼ��ڴ������Լ�����߽�E��ֵ��CPU�ڴ渴�Ƶ�GPU n-1�Ŀɼ��ڴ������DZ�Ҫ�ġ���ϸ���̼�ͼ 3��
 |
| ͼ 3 �첽���ݴ��估�������� Fig. 3 Asynchronous data transmission and computing flows |
| ͼѡ�� |
2.2 ����Ч������ ����һ��ʱ�䲽��ͨ����Ҫ��ʱ��Ϊ
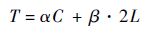 | (8) |
ʽ�У���Ϊͨ���ӳ�ʱ�䣻CΪͨ�Ŵ�������Ϊ�������ʣ�LΪE/Hͨ�������������������ļ��㷽ʽΪ
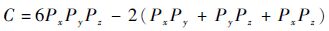 | (9) |
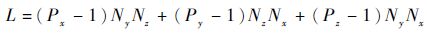 | (10) |
ʽ��:Px��Py��Pz�ֱ�Ϊx��y��z�����ϵ�����ֵ;Nx��Ny��Nz�ֱ�Ϊx��y��z�����ϵ���������
��ʽ(8)��ʽ(9)���Կ�������ͨ��������Lһ��ʱ����ͬ�����˷ֲ������ܻᵼ��ͨ�Ŵ���C�IJ�ͬ��������ʱ��T�IJ�ͬ��
�����5000AΪ������=1.8��2.5 ��s����=1/1.656 3 Gb/s�����������Ϊ1 000��1 000��1 000���ܺ���Ϊ1 000����ôͨ����Ӧʱ��(9.72 ms)��ͨ��ʱ��(121 ms)��ԼСһ�������������������ģ�µ�ͨ����Ӧʱ��Ϊ��Ҫ���ء��������̵�ͨ����Ϊ
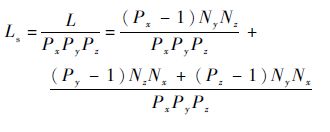 | (11) |
ʽ(11)���Գ���Nx��Ny��Nz���õ�
 | (12) |
��ʽ(12)��֪�����ҽ���
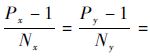

һ����ԣ��ڵ��ڵĽ��̼�ͨ��ʱ��Ͻڵ���ͨ��ʱ��ҪС�����ڵ��ںͽڵ����ֽ�ͨ��ʱ��������ͬ���ʶ����������������˵�C��L�����ʱ����Ҫ���ǿ�ڵ����̵�ͨ�����Ĵ�С������ͨ��3���Ż��������˲��Ի�ò���FDTD�㷨��Ч�ʣ��������£���ѡ������ʹ����ͨ��������L��С����ʽ(10)��С����ͨ���������൱������£�ѡ���ڵ�ͨ���ٵ����˽ṹ���ۿ�ڵ�ͨ�����൱ʱ��ѡ��ͨ�Ÿ��ؽ�Ϊ��������ˡ�
2.3 GPU����ʵ�� GPU������и߶Ȳ��еĶ�Stream����ܹ���Ϊ��ʵ��FDTD������٣����������CPU����������²�ͬ�ķ�ʽ���÷�ʽ�ȿ�ʵ�ֶ��������ͬ���������£��������GPU���ָ���ִ�л��ƣ��Ӷ�ʵ�ֶ�Stream�ĸ�Чʹ�ã�ͬʱ���������豸�ڴ�Ķ�д��ʱ��
��GPU��ʵ��FDTD�����㷨˼·(��ͼ 4)���������ٹ��̿��Է�Ϊ�����֣�����ʼ�����֡��첽���ݵĴ��估���㲿�֡����(���δ���)���֡�CUDA��ʼ�����߳���ÿ�������γ�һһ��Ӧ��ӳ�䣬�Ӷ���FDTD��ά�����Ϊһ����ά�����顣һ���������Ӧһ��һά�Ĺ�������ù�����(localID)������(groupID)ȷ�������ڻ����е�λ�ã�ʵ�ּ���ʱ��ֵ�Ķ�λ���첽���ݵĴ��估���㲿��Ϊ��ʵ�ֹ�����֮������ݹ��������㵥Ԫ�ڴ�ռ���첽/ͬ��������������Ҫ����YeeԪ��(��������)�빤��������ݽ������Ӷ������˶��ڴ�����ģ��ӿ��˶����ݵķ���ʱ�䡣�ò��ְ���GPU��CPU֮����ڴ渴�ơ�����Kernel(E-Kernel��H-Kernel)�Լ����㲿�֣��Dz���ʵ�ֵĺ��IJ��֡�
 |
| ͼ 4 GPU�������� Fig. 4 GPU acceleration flow |
| ͼѡ�� |
�����㷨��GPU����ΪЭͬ���㴦������CPU����Ϊ������������չ���ֺ˵�Эͬ���й��������ǵ�CPU�����ڴ�������ǿ������GPU������ִ�и߶��̻߳��IJ��е��ص㣬��չ����ķ���͵��ȡ�CUDA���߳��Ѿ����������չ�������Ա�֤��һ��������������ڲ�ͬ��������ͬӲ���Ͽ�չ���㡣��Kernel�����߳�����(Grid)���߳̿�(Block)���߳�(thread)����ģʽ��֯��Grid��һϵ��blockִ��ָ��ļ��ϣ�ÿ��block֮���Dz��еĹ�ϵ�����Ա�ͬʱִ�У���������֮�䲻��ͨ�š�
CPU�˵�ÿ�����㵥Ԫ����������Ҫ��/д��Ӧ��ȫ���ڴ�������ʵ�ִ���������ÿ��ѭ���ı������¡�OpenCL�IJ��з��������ڽ�ʸ���ķ�������֤ÿ�ζ����ڴ��3�������ܹ�ѡ�浽�Ͽ�ľֲ��洢����Ϊ�ˣ���Ҫ����Ԫ�ķô�����ģ���������ݿ�ô档�Ľ���Ĵ洢��ʽʵ�����������߳�һһ��Ӧ�Ĺ�ϵ�����ַ�ʽҲ�����뵽��Kernel�ڲ��ڽ�ʸ�����Ż��������ֲ��洢����˽�мĴ���ʵ��ÿ���̵߳IJ�������CUDA��Grid��ʵ���˶��̶߳���ͬȫ�ִ洢���ķ��ʣ�ͬʱҲ���Է���ֻ���洢���������ͳ����洢������ͼ 5��
 |
| ͼ 5 �ֲ��洢�����ڽ�ʸ�� Fig. 5 Local memory and built-in vector |
| ͼѡ�� |
3 ���Աȶ������ FDTD��������Ϻ���ͨ��ѧ�����ܼ�������GPU��Ⱥ��չ���ԡ�ʵ��ƽ̨����NVIDIA Tesla M2070(GPU)��NVIDIA Tesla K20m(GPU)����Ⱥʹ��MellanoxInfiniband FDR��������Intel Xeon E5-2670(CPU��8�ˣ�2.6 GHz��Ƶ��2G����)��������50��GPU����ڵ㣬ÿ���ڵ�������NVIDIA Tesla K20m��ͬʱ��������Intel Xeon E5-2670�������ı�̻���MPIͨ��ƽ̨��ʹ��Intel MPI 4.1.0�⣬Intel icpc 13.0.1��������CUDA5.0ƽ̨��FDTD�����CPU���ֻ����Ϻ�������������ĵġ�ħ�������ó��������(����ʵ��1��CPU�˵ļ���)�Լ����ҳ�������������ĵġ��������⡱�������������ƽ̨(���й�ģ����ͻ��1��CPU��)��չ���ԡ�
3.1 CPU����
3.1.1 ����ʱ����� FDTD��CPU�㷨�У�����ִ��ʱ��һ����������ܵõ�һ����ij�ֵ��Ϊ�˵õ����������ֵ�����������ѭ���ķ�ʽ����ʱ�������ڵ糡���� E �ʹų����� H ��������Ķ���ѭ����(���� 1)��ʵ�����ݵĹ�ģΪ256��256��256�����ż�������������ӣ�����E������E����߽硢����H������H����߽������ʱ������������ӣ������µ�Чԭ��(huygens)��������������ʱ��Ƚ��������١���Ҫ����Ϊ��CPU�㷨�У���˵�������̺����֮��������ķ���͵ȴ���ʱ�䣬ͨ�źķ���һЩʱ�䡣���������ڼ�������ж�˵IJ������м����˼���ʱ�䣬���������ܵ�ʱ��ķѱ�����û��̫��ı仯���ܵĺķ�ʱ�����ڼ��١�
�� 1 CPU��Ҫ��������ʱ��������� Table 1 CPU main function run time ratio analysis
| ���� | ����ʱ�����/% | |||||
| ����E ���� | ����E ����߽� | ����H ���� | ����H ����߽� | ���µ� Чԭ�� | ���� ���� | |
| 1�� | 17.1 | 7.5 | 16.8 | 10.2 | 25.5 | 22.0 |
| 4�� | 17.2 | 7.5 | 17.1 | 10.3 | 24.9 | 21.6 |
| 8�� | 17.4 | 7.6 | 17.2 | 10.4 | 24.6 | 21.5 |
| 16�� | 17.5 | 7.6 | 17.4 | 10.5 | 24.4 | 21.3 |
| 32�� | 17.7 | 7.8 | 17.9 | 10.6 | 24.0 | 20.8 |
| 64�� | 17.9 | 8.1 | 18.2 | 10.9 | 23.4 | 20.5 |
��ѡ��
3.1.2 ȷ�Բ��� FDTD�ڼ�����ߴ�ƽ̨������װ�������ߵ��˰˷ɻ�ƽ̨ʱ��������ϵͳ���临�ӣ����г�ǧ�������ߵ�Ԫ������ϸС�ṹ������һ�廯ģ�Ͷ��ػ�ƽ̨��������ϵͳ������ֵģ������൱����Ѷȡ���ͼ 6��ʾ����ϵͳ������ϸС�ṹ�Ͱ����н��ʣ�����ʱ�����ȶ���������Ҫ����ϸ�����ʷ֣����ɻ�ƽ̨���Կ����ǽ����������ʷ�ʱ���Բ��ô������������������ʵ��Эͬ���㡣�ȼ�������ϵͳ�ķ������⣬�õ�FDTD�������ϵĵ������Ȼ��ͨ���������Ƶõ���������������ӱ߽��ϵ����䳡�����÷��䳡��ΪԤ����ƽ̨������Դ������Ԥ����ƽ̨���������µķ��䣻�����ߵ�ֱ�ӷ��䳡�ͻ��������������µķ��䳡����ʸ���������㡣
 |
| ͼ 6 FDTD�������� Fig. 6 FDTD computing grid |
| ͼѡ�� |
��ͼ 7��ʾ������Դ���������ʾ�������ڵ� FDTD�����ü��������������ߵ�ϸС�ṹ�ͽ��ʵĴ��ڶ���Ҫ��ϸ�����֣�����������ʾƽ̨���ڵļ����ü���������Ŀ�꼸�γߴ���ͬ����Ҫ���Ĵ����ļ�����ڴ棬������ʹ�ü�Ⱥ�����µĶ��CPU���м��㡣
 |
| ͼ 7 ��������Ļ��� Fig. 7 Dividing the computational domain |
| ͼѡ�� |
��������������һ��ż���ӣ�ͨ���������������������۲��õ��Ľ������Ϊ�Ƚϣ�ͼ 8�����˱����㷨�ļ������ͽ�����Ա�ͼ��ͬʱ����FDTD�������õĻ������߷��䷽��ͼ�;�����(MoM)�������Ա�(��ͼ 9)��������ʾ�������Ǻϣ�ͬʱҲ֤��FDTD�㷨��ȷ�ԡ�
 |
| ͼ 8 �����������ƺ�����۲�㳡ֵ�ͽ�������ıȽ� Fig. 8 Comparison between subdomain observation pointfield values and analysis results after near extrapolation |
| ͼѡ�� |
 |
| ͼ 9 FDTD�������õĻ������߷��䷽��ͼ�;������ıȽ� Fig. 9 Comparison between FDTD calculated airborneantenna radiation pattern and moment method |
| ͼѡ�� |
3.2 GPU���ٲ���
3.2.1 ���ٲ��Լ��Աȷ��� �� 2������Mur���ձ߽������¡����CUDA �̡߳����Ԫ���µļ��ٱȡ�
�� 2 Mur���ձ߽������µļ��ٱ� Table 2 Acceleration ratio of Mur absorption boundary
| Yee Ԫ���� | CUDA ģ�� | CPU ʱ��/ms | GPU ʱ��/ms | ���ٱ� |
| 32��32��32 | 8��8 | 1.57 | 0.24�A | 6.54 |
| 64��64��64 | 16��16 | 14.16 | 0.78 | 18.10 |
| 128��128��128 | 32��32 | 118.28 | 2.37 | 49.90 |
| 256��256��256 | 64��64 | 975.31 | 17.89 | 54.50 |
| 512��512��512 | 128��128 | 7 843.85 | 150.87 | 51.90 |
| 1 024��1 024��1 024 | 256��256 | 62 748.45 | 1 394.18 | 45.00 |
��ѡ��
���� 2���Կ��������м���ļ��ٱ��������������������һ��������������ϵ�����ٱ����ֵ������������107������Ȼ���С�����ǵ�ʱ�䲽�ĵ��Ӻ�CPU�ں˵ĵ�������Ҫ����ʱ�䣬ʵ���ϣ�������Ŀ�ٵ�ʱ���ٱ�Ҳ��С�����ǣ�����ʱ������ϱ���һ�������ٱ����ż����������ӵ�һ���̶Ⱥ������ڸǷ��ʵ��ӳ٣��Ӷ�����������ٱ��½��������
ѡȡYeeԪ�����Ĺ�ģΪ256��256��256����չ1�ˡ�4�ˡ�16�ˡ�NVIDIA Tesla M2070��NVIDIA Tesla K20 m����ʱ��ԱȲ��ԡ�CPU��˲���MPI���ݵ��Ⱥ�ͨ�ţ�GPUʹ��OpenCL���ȣ�һ��CPU�˿���һ��GPU,Ҳ������һ��MPI���̿���һ��GPU����ͼ 10�ɼ����ڸ�Ԫ������GPU�����CPU�ļ��ٱȴﵽ8.89����Ȼ��CPU�������£�����ʱ�����ź���������Ѹ�ټ��٣�����Ч�ʿ�����ߣ�����Ҳ�ﲻ��GPU�ļ������ܡ�
 |
| ͼ 10 1�ˡ�4�ˡ�16�ˡ�NVIDIA Tesla M2070��NVIDIA Tesla K20 m�������ܶԱ� Fig. 10 Comparison of computing performance among 1 core,4 cores,16 cores,NVIDIA Tesla M2070 and NVIDIA Tesla K20m |
| ͼѡ�� |
ͼ 11��ʾ�����ڸ�YeeԪ������ģ�µĸ���GPU�Ż��ĺ��ĺ�����CPU�����ж�Ӧ������ִ��ʱ��Աȡ����ݱ�������Ҫ����������ʱ�� ����� 1��ʱ��ٷֱȷֲ����ɣ�����E��H��������ܶȽϸߣ����ٱ�Ҳ�ϴﵽ6���ࡣ
 |
| ͼ 11 1�ˡ�4�ˡ�16�ˡ�NVIDIA Tesla M2070��NVIDIA Tesla K20m����ʱ��Ա� Fig. 11 Comparison of computing time among 1 core,4 cores,16 cores,NVIDIA Tesla M2070 and NVIDIA Tesla K20m |
| ͼѡ�� |
ѡȡYeeԪ�����Ĺ�ģΪ512��512��512���ֱ�ʹ��2��12��24��48��72��NVIDIA Tesla K20m���м��ٲ��ԡ����Խ����ͼ 12��ʾ(����GPU���١���ʾδʹ���Ż��������˲��Ի�õIJ���Ч�ʣ���GPU���١���ʾʹ�����Ż��������˲��Ի�õIJ���Ч��)�����������GPU�IJ���Ч�����ź��������ӳ����½������ƣ��Ż��������˲��ԶԲ���Ч�ʵ�������һ�������ã��Ż�Ч������GPU���������Ӷ��Գ�������48��GPUʱ�ﵽ��ã�Ȼ��ʼ�½���ԭ��֮һ�����ǣ������������������˼���ʱ��ij��̣���������ı����������ͨ��ʱ��ij��̣���GPU��������ʱ��ͨ��ʱ��ļ��ٳ̶Ƚ�С��������ʱ��ļ��ٳ̶Ƚϴ����ߵı�ֵ�仯��ԭ��֮�������ǣ���GPU�����й����д���host��device֮���������ݴ��䣬�����˼���ʱ�䡣���ԣ���GPU�������ӵ�����£����������ʱ�������ĵ���ʱ��ı��������ͣ����¼��ٱȼ�С������Ч���½���
 |
| ͼ 12 ����GPU���ٱ��벢��Ч�ʶԱ� Fig. 12 Comparison of acceleration ratio and parallelefficiency with and without GPU |
| ͼѡ�� |
3.2.2 �����в��� ��һ��2��2������Ϊ����ģ�ͽ��������Ż��о������ڼ�Ⱥƽ̨�Ͻ����˲��ԡ���ģ�ͼ�MPI������������ʾ��ͼ��ͼ 13�����Բ���������Ƶ��Ϊ4.97 GHz��xp=14 mm��yp=9.6 mm��xd=15 mm����r=4.34��h=0.8 mm��xg=60 mm��yg=60 mm��xf=3.6 mm�������СΪdx=dy=dz=0.4 mm��
 |
| ͼ 13 ��ģ�ͼ�MPI������������ʾ��ͼ Fig. 13 Schematic diagram of micro-strip model andMPI progress virtual topology |
| ͼѡ�� |
�����Ե�����������Ϊ1 200��1 200��300��ʱ�䲽Ϊ2 000��������������Ϊ128(CPU)��96(GPU)�������еķ���ͼ��ͼ 14��ʾ����������ҵ����HFSS�����������˶Աȣ��Ǻ����á����ٱȺͲ���Ч��������ͼ 15��ʾ��
��ͼ 15�п��Կ�������16��Ϊ�������ٱȴﵽ7�����ϣ�FDTD���г�����32���µIJ���Ч�ʿɴ�80%���ϡ���48��Ϊ�������ٱȴﵽ10�����ϣ�FDTD���г���IJ���Ч��Ҳ�ɴ�70%���ϣ����ͬCPU��GPU���Ի����Ǻϡ�
 |
| ͼ 14 2��2�����з���ͼ Fig. 14 2��2 micro-strip array pattern |
| ͼѡ�� |
 |
| ͼ 15 ���ٱȺͲ���Ч��������ı仯 Fig. 15 Acceleration ratio and parallel efficiency varywith number of cores |
| ͼѡ�� |
4 �� �� ���Ļ��ڷֲ�ʽƽ̨��չһ���µ�FDTD�����㷨�о��������Ϻ���ͨ��ѧ�����ܼ�������GPU��Ⱥ���Ϻ�������������ĵġ�ħ�������ó���������Լ����ҳ�������������ĵġ��������⡱�������������ƽ̨��չ���ԡ�ʵ��ƽ̨����NVIDIA Tesla M2070(GPU)��NVIDIA Tesla K20m(GPU)����Ⱥʹ��MellanoxInfiniband FDR��������Intel Xeon E5-2670�ȼ����豸���㷨��ͨ�Ź����в����첽���ݴ��䷽����ʹ��CUDA�е���(Stream)���ƻ��ƺ��첽�ڴ渴�ƺ������й����������GPU����Դ��ʹ����,ͬʱ�����˼�����Դ�ij�����ã����ö��Stream���������в��������������������٣�ͬʱ��֤������Stream���ص�ƽ���Լ�GPU���������������Ļ���GPU����Ч�ʽ������о������ݴ����IJ������ݣ��õ�Ч�������ľ��鹫ʽ(Ŀǰ������ص����������ᵽ�����������Ч�ʣ�Ҳû�й̶��ļ��㹫ʽ������ѭ)���ܽ������3���Ż��������˲��ԡ�
ͨ����CPU��GPU�Լ�CPU��GPU�Ļ��ʹ�ò��ԣ�֤�������㷨���̵߳ĵ���ˮƽ�����ĺ��������ٶȵȷ�������������������ͨ��ִ��ʱ����������������ڼ��ٱȡ�����Ч�ʷ�����һ������ߣ�ͬʱҲ������
1) FDTD�ڼ�����ߴ��ر����и�������ϵͳ��ƽ̨ʱ���������ߵ�Ԫ���г�ǧ�����ϸС�ṹ������һ�廯ģ�Ͷ��ػ�ƽ̨��������ϵͳ������ֵģ������൱����Ѷȡ������ڱ�֤�ȶ��������£����Կ�չ����Դ��������ʷ���ʽ��ͬʱ��Բ�ͬ�������Эͬ���ķ���(�����ǵ��㷨��Эͬ��Ҳ�����Ƕ��㷨��Эͬ���)��
2) ��GPU�����й����д���host��device֮���������ݴ��䣬�����˼���ʱ�䡣������Ӱ�������������̵����������Ӱ�죬������ЩӰ���ԭ������Щ���Լ�GPU��CPU���ִ��ʱ��MPI֮�������ͨ���Ƿ���������������ֵ�ú��ڽ�һ���о���
�����
| [1] | YEE K S. Numerical solution of initial boundary value problems involving Maxwell's equations in isotropic media[J].IEEE Transactions on Antennas and Propagation, 1966, 4(14): 302�C307. |
| [2] | SU M F,EI-KADY I,BADER D A,et al.A novel FDTD application featuring OpenMP-MPI hybrid parallelization[C]//Proceedings of the International Conference on Parallel Processing,2004 ICPP 2004.Piscataway,NJ:IEEE Press,2004:373-379. |
| [3] | YU W H, Y J, SU T, et al. A robust parallel conformal finite-difference time-domain processing package us in the MPI library[J].IEEE Antennas and Propagation, 2005, 47(3): 39�C59.DOI:10.1109/MAP.2005.1532540 |
| [4] | KRAKIWSKY S E,TURNER L E,OKONIEWSKI M M.Acceleration of finite-difference time-domain (FDTD) using graphics processor units (GPU) [C]//Proceedings of the IEEE MITTS International Microwave Symposium Digest.Piscataway,NJ:IEEE Press,2004,2:1033-1036. |
| [5] | ADAMS S,PAYNE J,BOPPANA R.Finite difference time domain (FDTD) simulations using graphics processors[C]//Proceedings of the DoD High Performance Computing Modernization Program Users Group Conference.Piscataway,NJ:IEEE Press,2007:334-338. |
| [6] | DU L G,LI K,KONG F M.Parallel 3D finite difference time domain simulations on graphics processors with CUDA[C]//Proceedings of the International Conference on Computational Intelligence and Software Engineering (CISE '09).Piscataway,NJ:IEEE Press,2009:145-147. |
| [7] | LIU Y, LIANG Z, YANG Z Q. A novel FDTD approach featuring two-level parallelization on PC cluster[J].Progress in Electromagnetics Research-Pier, 2008, 80: 393�C408.DOI:10.2528/PIER07120703 |
| [8] | KOMATITSCH D, GODDEKE D, ERLEBACHER G, et al. Modeling the propagation of elastic waves using spectral elements on a cluster of 192 GPUs[J].Computer Science-Research and Development, 2010, 25(1-2): 75�C82.DOI:10.1007/s00450-010-0109-1 |
| [9] | JACOBSEN D A,THIBAULT J C,SENOCAK I.An MPI-CUDA implementation for massively parallel incompressible flow computations on multi-GPU clusters [C]//Proceedings of 48th AIAA Aerospace Sciences Meeting.Piscataway,NJ:IEEE Press,2010:1-16. |
| [10] | NAGAOKA T,WATANABE S.Accelerating three-dimensional FDTD calculations on GPU clusters for electromagnetic field simulation[C]//Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society(EMBC12).Piscataway,NJ:IEEE Press,2012:5691-5694. |
| [11] | YANG C T, HUANG C L, LIN C F. Hybrid CUDA,OpenMP,and MPI parallel programming on multi-core GPU clusters[J].Computer Physics Communications, 2011, 182(1): 266�C269.DOI:10.1016/j.cpc.2010.06.035 |
| [12] | KIM K H, PARK Q H. Overlapping computation and communication of three-dimensional FDTD on a GPU cluster[J].Computer Physics Communications, 2012, 183(11): 2364�C2369.DOI:10.1016/j.cpc.2012.06.003 |
| [13] | XU L, XU Y, JIANG R L, et al. Implementation and optimization of three-dimensional UPML-FDTD algorithm on GPU cluster[J].Computer Engineering & Science, 2013, 35(11): 160�C167. |
| [14] | TAFLOVE A, BRODWIN M E. Numerical solution of steady-state electromagnetic scattering problems using the time-dependent Maxwell's equation[J].IEEE Transactions on Microware Theory Techniques, 1995, 23(8): 623�C630. |
| [15] | GE D B, YAN Y B. Finite-difference time-domain method for electromagnetic wavess[M].3rd edXi'an: Xidian University Press, 2011: 37-38. |
| [16] | ENGQUIST B, MAJDA A. Absorbing boundary conditions for the numerical simulation of waves[J].Mathematics of Computation, 1977, 31(139): 629�C651.DOI:10.1090/S0025-5718-1977-0436612-4 |
