目前基于序列图像的目标检测与分割,常用的方法[3]主要是帧间差分法、背景差分法和光流法等。其中,帧间差分法所形成的运动目标的轮廓往往是局部的、不连续的,虽然目前常用的三帧差分法对此有一定改善,但是分割效果仍然不理想。背景差分法的检测性能很大程度上依赖于背景模型的准确性。其中高斯混合模型(Gaussian Mixture Model,GMM)是目前背景差分法最为成功的方法之一,Zivkovic和van der Heijden[4]、Lin等[5]都针对此进行研究和改进。GMM模型对于微动的动态背景有一定的鲁棒性,但是通过更新学习的方式运算代价较大,并且不能适应背景变化较大的情况。近年来,光流法成为运动目标检测的研究热点。但由于该方法在运动边界处的计算误差较大,影响了目标检测与分割的精确性,需要通过其他方法降低运动边界的干扰。Xu等[6]提出了基于分割的变分光流估计方法,提高了光流估计的准确性;Liu等[7]又从光流方法的约束方程出发,提出的新的尺度不变特征变换(SIFT)流(Flow)估计方法,取得了不错的检测效果,但是都不能从根本解决动态场景和摄像机移动情况下的实际问题。
近年所兴起的视觉显著性方法,为目标检测提供了新的思路。目前,基于视觉显著性的目标检测方法可分为两大类[8]:第1类为基于视觉生理特性的显著性分析方法,Itti[9]视觉选择注意模型是该方法的代表;第2类为基于数学统计模型的显著性分析方法,其代表是Hou和Zhang[10]的残差法。在序列图像领域,Guo和Zhang[11]提出了相位谱四元数傅里叶变换法(Phase spectrum of Quaternion Fourier Transform,PQFT)用于计算视频序列的时空显著性。但该方法所形成的显著图只能对目标进行检测,其检测结果不利于目标的分割提取。
本文提出一种新的基于融合SIFT Flow特征的目标显著模型方法来检测在动态场景和摄像机移动下的序列图像目标。将基于SIFT Flow的图像特征引入到视觉显著模型中来,作为帧间运动特征信息,并结合利用图像国际照明协会(CIE)Lab空间内颜色和亮度的特征信息,利用改进的多尺度中心-环绕对比方法,通过线性融合生成基于序列图像的目标显著图。最后利用均值漂移(mean-shift)聚类算法和形态学处理实现对目标的精确分割。该算法提高了在动态场景与摄像机移动等复杂情况下目标检测与分割的适应能力,能够为以后识别过程的学习提供完整的、纯净的训练样本。
1 算法实现1.1 目标运动特征信息的获取经典的光流法中亮度恒定的假设通常会被光照变化和噪声破坏,难以得到准确的目标运动信息。而彩色图像提供了更丰富的光学信息,能有效克服序列图像光流场计算中的孔径问题[12, 13]。Liu等[7]在彩色图像的基础上提出了SIFT Flow,SIFT描述符的优点在于所提取的特征值能够保持尺度旋转和仿射不变性、稳定性,一定程度地提高了配准准确率。因此本文利用SIFT Flow[7]算法进行目标运动信息的获取。
基于光流框架的SIFT Flow算法,是通过计算图像中每个像素的SIFT特征,得到相邻2帧图像间点对点的像素对应关系,从而描述目标本身的运动场。其具体步骤如下。
1) 对图像的像素点进行特征提取。对图像中每个像素点p提取SIFT特征,从而生成特征向量s(p)。
2) SIFT运动流场W的计算。生成运动流场W,SIFT Flow的计算可总结为优化问题:
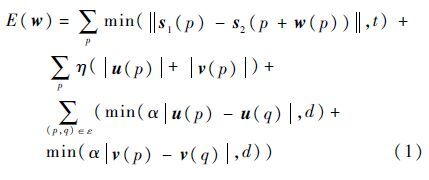
式中:E(w)为能量值;s1(p)为像素点p在S1的特征向量;s2(p+w(p))为像素点p在S2图像上移动w(p)的特征向量,w(p)为像素点p移动的光流矢量;t为阈值;η为控制函数(使其尽可能小);u(p)和v(p)为w(p)的2个矢量分量;α为匹配函数;q为像素点p的相邻点;ε为空间上像素的相邻区域;d为阈值;u(q)和v(q)为w(q)的2个矢量分量。式(1)右侧的3项子式分别对应需要考虑的3种情况:①相邻帧的像素点p按照SIFT特征向量s1(p)、s2(p)的相似程度进行匹配;②流速矢量应进行限制;③优先匹配像素点p的相邻区域。
3) SIFT Flow的优化过程。其优化过程采用由粗到精(coarse-to-fine)的匹配技术来解决直接计算优化效率不高的问题。其生成原理如图 1所示。其中灰色矩形代表在每层为k的金字塔搜寻pk的窗口。
 |
| 图 1 SIFT Flow粗到精优化过程 Fig. 1 Optimization process of SIFT Flow coarse-to-fine |
| 图选项 |
本文采用文献[14]中的光流可视化方法。如图 2(a)所示,图像中心表示静止的点为白色,向边缘方向运动的颜色越深,幅度越大。可视化的SIFT Flow结果如图 2(b)所示,完成目标运动特征信息的获取。
 |
| 图 2 运动信息获取结果 Fig. 2 Moving information retrieval results |
| 图选项 |
1.2 融合运动特征信息的目标显著图由于基于序列图像的动态场景目标检测对算法性能的要求较高,而所有基于生物学结构的算法如经典的Itti[9]算法都比较耗费计算资源,并且由于需要平滑和放缩特征图,会导致特征显著图清晰度和分辨率损失。而基于频域的算法如频谱残差(SR)方法虽然简单且计算速度快,但是生成的显著图效果一般,不利于后续的分割和识别工作。Achanta[15]和魏昱[16]等提出的多尺度中心-环绕对比方法则不缩放特征图,通过改变感知单元的邻域大小,计算其在不同邻域上的局部对比度来实现显著性计算。该方法能够将整个目标区域一致的高亮出来,并且算法本身不会降低图像的分辨率。但是传统的该方法是直接利用像素的颜色特征值进行对比,不利于在复杂场景中的应用。本文在此基础上进行了改进,采用归一化直方图的方式对像素按照特征值进行归类,提高特征值之间的对比度和计算效率。
首先将图像由RGB颜色空间转为CIE Lab颜色空间[17]后进行特征提取。其3个特征分别记为L(X)、a(X)和b(X),SIFT Flow特征的幅值记为M(X)。建立四维特征向量空间:
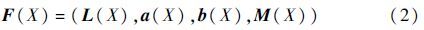
设输入的序列图像为Ii,其中i=1,2,…,N,N为序列图像的帧数。在Ii上施加一个感知单元,以光栅扫描的方式对整个图像进行处理。通过在每个感知单元内构建F(X)的直方图并进行平滑,通过直方图的统计得到特征分布概率,为保证计算尺度的一致性,经过归一化处理来计算显著值。
设F(X)的每一条特征通道为QF(X),并假设随机变量L(X)、a(X)、b(X)和M(X)在任何一个感知单元是相互独立的。将感知单元分为2个不相交的部分,一个矩形内核R1和四周边界R2,假设R1是显著部分而R2是背景部分。设$$\dot h$$R1(t(X))和$$\dot h$$R2(t(X))为直方图的归一化形式,其中t(X)表示特征向量L(X)、a(X)、b(X)和M(X)中的一个。
在这4个特征通道中,通过计算图像中像素的特征值分别在区域R1和R2的平均值,并采用欧式距离计算特征距离D。设像素x为R1和R2的中心,则每一个特征通道的显著值可表示为归一化直方图的形式:
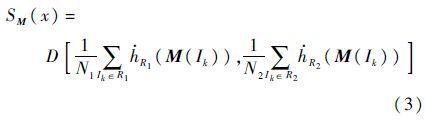

式中:N1和N2分别为R1和R2中的像素个数;Ik为像素在图像中的位置;SM(x)、SL(x)、Sa(x)和Sb(x)分别为M、L、a和b通道的显著值。在本文中设定多尺度滑动窗口的长宽大小分别为{20,10;40,30;70,50},内核R1为一个像素块,其余部分为R2。
本文采用线性方式来融合像素点所提取的显著性值,因此最后的显著值表示为
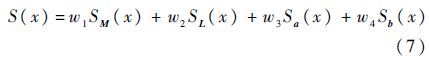
式中:权值w1~w4为通过线下训练获得的经验值,分别设定w1=0.3,w2=0.21,w3=0.24,w4=0.26。
1.3 目标分割目标精确分割方法是把第2.2节得到的序列图像的目标显著图,利用mean-shift算法进行目标分割。Mean-shift的图像分割在本质上是一种通过mean-shift聚类的无监督图像分割方法,这种分割方法能够有效地得到图像中物体的轮廓信息。最后通过形态学的膨胀和腐蚀去除分割后的空洞和孤点。本文运用结构元素[0 1 0;1 1 1;0 1 0]进行5次膨胀,并使用半径为10的圆盘形结构元素进行腐蚀。算法的分割结果如图 3所示。
 |
| 图 3 算法分割结果 Fig. 3 Segmentation result of algorithm |
| 图选项 |
2 算法总结本文提出的算法是基于融合SIFT Flow特征显著模型的动态场景目标检测与分割。算法将SIFT Flow特征的运动信息融合到空间显著性模型中,其运动特征信息和空间特征信息可以互为补充,弥补各自不足,避免了单一方法在动态场景下都会出现的背景误检和目标轮廓不够清晰的情况。因此该算法不受动态复杂场景或摄像机移动等复杂条件的影响,获得的目标可靠且具有清晰的轮廓边缘,分割结果较完整,有利于后续的识别工作。整体算法实现流程如图 4所示。
 |
| 图 4 本文算法流程 Fig. 4 Flowchart of proposed algorithm |
| 图选项 |
算法具体步骤如下:①对相邻2帧图像利用SIFT Flow算法获取运动特征信息;②将图像转换为CIE Lab颜色空间,结合SIFT Flow算法估计出的运动特征信息,构建四维特征向量空间F(X)=(L(X),a(X),b(X),M(X))。利用多尺度中心-环绕对比,让感知单元在图像内以光栅扫描的方式滑动,利用每一个像素中各个特征平滑后的归一化直方图来计算显著值,将4个特征显著图进行线性融合生成包含运动信息的动态场景目标显著图;③对生成的显著图运用mean-shift算法和形态学处理实现目标分割提取。
3 实验分析本文针对动态复杂背景与摄像机移动平台这2个动态应用场景,分别选取数据库进行实验。首先进行本文算法的质量评价,然后在2个数据库中与其他参考算法进行对比分析,最后通过查全率、查准率和F-measure方法客观评价算法性能,并进行算法复杂度分析。实验的硬件平台为3.20 GHz,2.00 GB的个人计算机,软件平台为MATLAB 2013a。
3.1 算法质量评价进行动态复杂背景检测实验的图像数据库来源于Freiburg-Berkeley Motion Segmentation数据库(FBMS dataset)[18],该数据库所提供的是动态场景和摄像机微移动情况下的序列图像,并且由人工精确标注了真值(Ground Truth)用于进行检测效果的对比。部分实验结果如图 5所示。
 |
| 图 5 本文算法FBMS数据库的测试结果 Fig. 5 Test results of proposed method of FBMS dataset |
| 图选项 |
表 1为测试序列图像相关信息及检测难点。
表 1 测试序列图像相关信息及检测难点Table 1 Information of test image sequences and difficulties in detection
| 名称 | 实验抽取帧 | 目标检测难点 |
| cars | 50,51 | 复杂、动态场景相似前景 |
| cats | 9,10 | 多目标 |
| horses | 7,8 | 复杂、动态场景摄像机运动 |
| people1 | 29,30 | 动态场景摄像机运动 |
| people2 | 1,2 | 多目标复杂、动态场景 |
表选项
为了充分说明算法的有效性,从以下4个方面进行本文算法的质量评价,该质量评价是目前显著图算法公认的评价体系[19],包括:
1) 突出的最为显著的物体:通过图 6(b)和图 6(d)进行对比,本文算法有效地突出了显著物体,和Ground Truth中的显著物体表达一致。
2) 一致的高亮整个显著物体:从图 6(c)中可看出,本文算法较好地克服了目标本身的表面纹理影响,且保持了目标内部的显著程度一致,可有效地将显著物体区域和背景区域完全分离。
3) 精确符合物体的边界:从图 6(d)可看出,本文算法分割出的区域有着良好的边界,有利于后续的分割与识别任务。
4) 较高的抗噪性和全分辨率:本文算法能够忽视原始图像中噪声、纹理和颜色的影响,且分辨率和原图像的分辨率一致,有利于本文算法的实际应用。
 |
| 图 6 FBMS数据集各算法检测结果对比 Fig. 6 Comparison of test results of different algorithms in FBMS dataset |
| 图选项 |
3.2 动态复杂背景对比实验为了充分说明算法的优势,将本文算法与三帧差分法、GMM背景差分法、SIFT Flow算法以及PQFT法的检测结果进行比较,实验检测结果如图 6所示。
从图 6(a)可以看出,在背景扰动和摄像机运动变化的情况下,三帧差分法的检测结果十分不理想,对简单场景cats的检测结果中目标轮廓不清晰,没有完全的突出目标;而对cars、horses、people1和people2的检测结果中,目标所在区域完全淹没在背景中,其扰动的背景(如树木随风的摆动等)也同样被检测出来,而且由于摄像机的运动变化,导致整个背景无法剔除。从图 6(b)可以看出,GMM背景差分法虽然对摄像机的抖动有一定的鲁棒性,但对于动态背景和摄像机较大的运动的情况,运动目标和摄像机的相对速度可能不大,而背景却产生相对运动。因此检测结果出现了目标漏检,而背景有大量虚警的情况。从图 6(c)可以看出,SIFT Flow算法也是由于场景的干扰和摄像机的移动,导致cars、horses和people2不能准确地检测出目标轮廓,无法确保目标的完整性;而cats出现了丢失目标的情况;people1则无法完全剔除背景。而从图 6(d)可以看出,运用PQFT法分割后的结果其轮廓与范围不利于目标的完整提取;从图 6(e)可以看出,本文算法的检测结果相比其他算法优势较明显,很好地保证了目标边缘的清晰性和完整性,对场景的变化具有鲁棒性,并且在多目标的情况下也能较好地完成检测任务。
3.3 摄像机移动对比实验为验证算法在移动平台上的有效性和优越性,运用本文算法和其他4种算法对Video Verification of Identity数据集(VIVID dataset)中的航拍图像分别进行处理,结果如图 7所示。从图 7(b)和图 7(c)可以看出,三帧差分法、GMM背景差分法由于航拍导致背景和移动平台产生了相对运动,已经不能检测出前景目标。从图 7(d)和图 7(e)可以看出,SIFT Flow算法虽然相对前 2种方法效果要好,但是中间2个车辆被检测为一体,轮廓边缘也不够锐利;而PQFT算法的检测结果则是目标范围较大。从图 7(f)可以看出,本文算法在平台移动的航拍过程中,对于较小目标仍然可以检测并分割,并对航拍这种动态场景也具有鲁棒性,这对于实际应用具有重要意义。
 |
| 图 7 VIVID数据集航拍图像实验结果对比 Fig. 7 Comparison of test results of aerial images in VIVID dataset |
| 图选项 |
3.4 客观评价与算法复杂度分析实验最后利用客观的评价方法——本文提出算法进行了测试。本文通过查准率(precision)和查全率(recall)将本文算法和三帧差分法、GMM背景差分法、SIFT Flow算法以及PQFT算法进行比较。其中FBMS dataset计算的结果由和图片给定的Ground Truth对比得出,VIVID dataset由于没有给出Ground Truth,本文给定图片中运动车辆即为前景目标。为了更好地衡量本算法性能,利用F-measure[20]算法来同时评价二者。F-measure的定义为

式中:P为查准率;R为查全率;β2=0.3。计算结果如图 8所示。从柱状图比较结果可以看出,本文提出的算法明显优于其他算法,其检测结果更加精确。
 |
| 图 8 查准率、查全率和F-measure柱状图 Fig. 8 Bar graph of precision,recall and F-measure |
| 图选项 |
通过对以上2个数据库进行各算法的实验结果对比,本文算法在分割的完整性和精度上有明显的优势,但同时也损失了一定的计算效率。其主要原因是为了保证在动态复杂背景中进行有效的检测和分割,在获取运动信息时采用了效果较好的SIFT Flow算法,虽然进行了一定的优化,但仍然消耗时间较多,这也是本文算法今后需要进一步提高的重要方面。其算法耗时统计结果如表 2所示。
表 2 算法耗时对比Table 2 Comparison of time consumption of different algorithms
| 目标检测方法 | 平均耗时/s |
| 三帧差分法 | 3.23 |
| GMM背景差分法 | 4.68 |
| SIFT Flow算法 | 30.34 |
| PQFT法 | 1.69 |
| 本文算法 | 31.67 |
表选项
4 结 论本文将融合SIFT Flow运动信息特征的视觉显著模型与图像分割方法相结合,提出了一种在复杂动态场景与摄像机移动情况下目标检测与分割算法。经实验验证表明:
1) 在动态复杂背景和摄像机移动的条件下,该算法有较高的精确性,所形成的显著图中目标的整体信息得到更好的保留与突出,能够有效地进行目标检测与分割。
2) 在测试的2个数据库中,该算法的查全率分别达到了78.15%和97.68%,查准率分别达到了82.42%和90.12%,相比传统算法有较大的优势。
3) 该算法在分割的完整性和精度上有明显的优势,但同时也损失了一定的计算效率。
因此如何提高算法的实时性以及改进算法以适应更复杂的场景,是进一步的研究方向。
参考文献
| [1] | POJALA C,SOMNATH S.Neighborhood supported model level fuzzy aggregation for moving object segmentation[J].IEEE Transactions on Image Processing,2014,23(2):645-657. |
| Click to display the text | |
| [2] | 黎万义,王鹏,乔红.引入视觉注意机制的目标跟踪方法综述[J].自动化学报,2014,40(4):561-576. LI W Y, WANG P,QIAO H.A survey of visual attention based methods for object tracking[J].Acta Automatica Sinica,2014,40(4):561-576(in Chinese). |
| Cited By in Cnki (12) | |
| [3] | 解晓萌. 复杂背景下运动目标检测和识别关键技术研究[D].广州:华南理工大学,2012:1-30. XIE X M.Research on key techniques of moving object detection and recognition in complex background[D].Guangzhou:South China University of Technology,2012:1-30(in Chinese). |
| Cited By in Cnki (9) | |
| [4] | ZIVKOVIC Z, VAN DER HEIJDEN F.Efficient adaptive density estimation per image pixel for the task of background subtraction[J].Pattern Recognition Letters,2006,27(7):773-780. |
| Click to display the text | |
| [5] | LIN H H, CHUANG J H,LIU T L.Regularized background adaptation:A novel learning rate control scheme for Gaussian mixture modeling[J].IEEE Transactions on Image Processing,2011,20(3):822-836. |
| Click to display the text | |
| [6] | XU L, CHEN J N,JIA J Y.A segmentation based variational model for accurate optical flow estimation[C]//Proceedings of the 10th European Conference on Computer Vision.Berlin:Springer,2008,5302(1):671-684. |
| Click to display the text | |
| [7] | LIU C, YUEN J,TORRALBA A.SIFT Flow:Dense correspondence across scenes and its applications[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(5):978-994. |
| Click to display the text | |
| [8] | CHEN X, ZHAO H W,LIU P P,et al.Automatic salient object detection via maximum entropy estimation[J].Optics Letters,2013,38(10):1727-1729. |
| Click to display the text | |
| [9] | ITTI L. Automatic foveation for video compression using a neurobiological model of visual attention[J].IEEE Transactions on Image Processing,2004,13(10):1304-1318. |
| Click to display the text | |
| [10] | HOU X D, ZHANG L Q.Saliency detection:A spectral residual approach[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2007:1-8. |
| Click to display the text | |
| [11] | GUO C L, ZHANG L M.A novel multire solution spatiotemporal saliency detection model and its applications in image and video compression[J].IEEE Transactions on Image Processing,2010,19(1):185-198. |
| Click to display the text | |
| [12] | 魏国剑, 侯志强,李武.融合颜色不变量的彩色图像光流估计算法[J].电子与信息学报,2013,35(12):2927-2933. WEI G J,HOU Z Q,LI W.Color image optical flow estimation algorithm fused with color invariants[J].Journal of Electronics & Information Technology,2013,35(12):2927-2933(in Chinese). |
| Cited By in Cnki (1) | |
| [13] | MANJUNATH N, ALLEN H,ERIK L M.Coherent motion segmentation in moving camera videos using optical flow orientations[C]//Proceedings of the IEEE Conference on Computer Vision.Piscataway,NJ:IEEE Press,2013:1577-1584. |
| Click to display the text | |
| [14] | MEER P. Robust techniques for computer vision[C]//Proceedings of Emerging Topics in Computer Vision.Upper Saddle River,NJ:Prentice Hall,2004:107-190. |
| Click to display the text | |
| [15] | ACHANTA R, ESTRADA F,WILS P,et al.Salient region detection and segmentation[C]//Proceedings of the International Conference on Computer Vision Systems.Piscataway,NJ:IEEE Press,2008:66-75. |
| Click to display the text | |
| [16] | 魏昱. 图像显著性区域检测方法及应用研究[D].济南:山东大学,2012:19-34. WEI Y.Research on image salient region detection methods and applications[D].Jinan:Shandong University,2012:19-34(in Chinese). |
| Click to display the text | |
| [17] | RAHTU E, KANNALA J.Segmenting salient objects from images and videos[C]//Proceedings of the 11th European Conference on Computer Vision.Berlin:Springer,2010:366-379. |
| Click to display the text | |
| [18] | PETER O, JITENDRA M,THOMAS B.Segmentation of moving objects by long term video analysis[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(6):1187-1200. |
| Click to display the text | |
| [19] | CHENG M M, NILOY J,HUANG X L,et al.Global contrast based salient region detection[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2011:409-416. |
| Click to display the text | |
| [20] | ACHANTA R, HEMAMI S,ESTRADA F.Frequency-tuned salient region detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2009:1597-1604. |
| Click to display the text |
