深度图像动作识别任务主要有如下难点:①深度图像中的噪声,以及在遮挡情况下关节位置估计的误差;②识别动作需要对整体视频的特征进行融合;③人体动作执行的多样性.其中①和③共同构成了动作特征较大的类内差异.
针对上述问题,文献[6]用直方图的形式表达关节特征,并用隐马尔可夫模型识别动作;文献[7]以提出的时间-空间特征作为动作识别的基础,用朴素贝叶斯最近邻(Nave Bayes Nearest Neighbor,NBNN)分类器完成动作分类;文献[8]通过学习动作的关键关节集合提高动作特征区别力,并用Fourier变换融合时间信息,最后用基于多核学习的支持向量机(Support Vector Machine,SVM)识别动作;文献[9]提出由关节位置、速度和加速度组成的动作特征,学习得到动作关键帧,通过判别关键帧的相似性预测动作类别;文献[10]提出一种有区别力的词典学习方法,并基于稀疏编码和时间金字塔匹配(Temporal Pyramid Matching,TPM)的方法识别动作.上述方法均取得了较好的识别率.
然而在实际动作识别任务中,方法的计算复杂度和能否方便地扩展可识别动作类别也是值得关注的问题,前者影响系统的实时性,后者决定系统的可扩展性,如人机交互系统中用户添加或更改动作的含义,以及视频监控中添加被监控的动作种类等.文献[10]中词典学习方法较为复杂,且在扩展可识别动作类别时需要进行全局优化,重新学习词典;文献[8]中方法需要为每一类动作设置不同参数来选取关键关节集合,使得算法难以自动扩展可识别动作类别;文献[9]中的方法在上述两方面均做出一定的改进,但是由于识别过程需要计算每一帧特征与全部训练样本的距离并排序,这在训练样本增大或可识别动作类别增加时将会极大地提高计算复杂度.
针对动作特征类内差异较大,以及现有算法在计算复杂度和扩展可识别动作类别方面的不足,本文提出一种基于局域性约束线性编码(Locality-constrained Linear Coding,LLC)的人体动作识别方法.算法将人体关节的位置、速度和加速度作为局部动作特征;采用LLC对局部动作特征求解稀疏表达,其词典由K-means分别对每类数据训练的子词典组合而成,并利用词典元素类别对编码系数进行降维;最后分别用TPM和线性SVM融合动作特征和识别动作.
1 局部动作特征1.1 不变性关节特征视频中t帧第i个人体关节的位置表示为pi(t)=(px(t),py(t),pz(t)).由于人体相对于摄像机的位置和姿态都是任意的、未知的,因此用于描述动作的特征必须具有旋转和平移不变性,用如下方式取得特征对旋转和平移的不变性[8]:
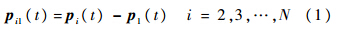
式中:N为关节总数;p1为基准关节.
1.2 局部动作特征为体现动作的局部动态特性,对每一帧的关节位置数据计算运动姿态描述子(moving pose descriptor)[9],即每一个关节的位置、速度和加速度.对于t时刻,这一帧视频的局部动作特征可表示为
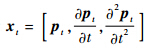 .关节点的速度和加速度可分别由式(2)、式(3)近似计算:
.关节点的速度和加速度可分别由式(2)、式(3)近似计算: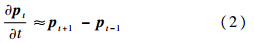
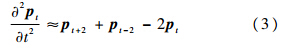
由于在深度图中估计出的关节位置具有较为严重的噪声,首先对每一关节位置曲线进行高斯滤波,抑制噪声对速度和加速度的影响.
尽管局部动作特征具有很强的表达力,但并不适合直接用于分类.仍以MSR-Action3D数据库为例,图 1显示了特征的类内差异,其中实线和点划线分别代表“挥手”动作中两个视频中同一关节的x轴坐标曲线,可看出两组数据在关节位置上有较大差异,则在速度和加速度上同样具有较大差异.
 |
| 图 1 同类动作的特征差异Fig. 1 Variance between features of the same class actions |
| 图选项 |
2 动作特征表达LLC[11]是应用于图像分类领域的无监督特征学习方法,LLC通过学习的方法获得特征的稀疏表达,从而使特征更加具有区别力且线性可分.
2.1 编码方法LLC是基于局部坐标编码(Local Coordinate Coding,LCC)[12]的一种快速方法,其基本思想为:对待编码特征x,使用距离x最近的k个词典元素的线性组合表达特征,其中k远小于词典元素个数.LLC的优化函数为
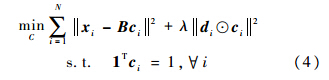
式中:xi为输入的特征向量;B为通过学习得到的词典,可以简单使用K-means学习得到;ci为待优化的特征的编码系数;λ为LLC中的惩罚因子;di的定义为
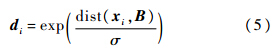
式中:dist(xi,B)=[dist(xi,b1),dist(xi,b2),…dist(xi,bM)]T,M为词典元素个数;dist(xi,bj)为xi与bj之间的欧氏距离;σ为调整局部位置约束权重的下降速度;⊙表示向量对应元素的乘法;1Tci=1保证了LLC的平移不变性.式(4)具有式(6)~式(8)形式的解析解:
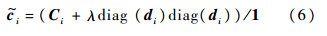
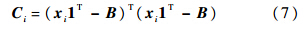

式中
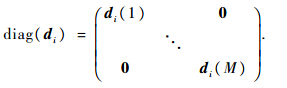
文献[12]证明,满足特征的局域性位置约束必然能够满足特征的稀疏性,而满足稀疏性则不一定能够满足局域性位置约束.局部位置约束与稀疏编码(Sparse Coding,SC)的稀疏性约束区别如图 2所示,稀疏性约束旨在保证重构性的前提下使编码系数L0范数尽量小,其对特征的重构策略如图 2(a),而LLC的重构策略如图 2(b).可以看出,由于距离特征最近的k个词典元素与特征同类别的概率很大,而LLC的局域性约束使用距离特征最近的元素表达特征,因此特征的稀疏表达具有更强的区别力.
 |
| 图 2 稀疏编码与LLC示意图Fig. 2 Illustration of sparse coding and LLC |
| 图选项 |
2.2 词典学习与文献[11]中采用K-means直接对所有训练数据训练一个词典不同,采用K-means分别对每类数据学习得到子词典,再将所有子词典组合起来作为LLC的词典,在扩展可识别动作类别时有如下优势:
1) 仅对新扩展类别的数据进行K-means聚类即完成词典学习,无需全局优化,文献[8, 10]均需全局优化完成扩展类别后的词典学习.
2) 参数设置简单,仅需设置K-means聚类个数,文献[8]需要对每类数据设置不同的两个参数,文献[10]则需设定5个参数.
此外,根据局部动作特征的特点选用相关系数作为K-means中的相似性度量方法.
2.3 编码系数的降维方法由于深度图像动作识别样本相对较小(20类动作共284个视频),当选择较大词典时容易使分类器过拟合,而较小的词典又难以保证编码系数的区别力.为保证词典的大小不受限制,利用词典元素的类别对编码系数进行降维.
首先使用K-means分别对每一类动作的训练数据学习得到带有动作类别标签的词典元素,然后对第i帧视频的局部动作特征,在词典上求解LLC的编码系数ci,降维后的向量αi为与动作类别数相同维数的列向量,则αi的第j个元素为
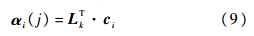
式中:Lk为维数与词典元素个数相同的列向量,若词典中第j个元素对应的动作类别为k,则Lk(j)=1,否则Lk(j)=0.
3 全局特征融合对一个由几十帧图像组成的动作视频,需要将每一帧特征融合起来识别动作,采用基于池化的时间金字塔匹配方法完成对全局动作特征的融合[8].时间金字塔的构建方法如图 3所示,将原有动作序列分为2n个子序列,以局部动作特征的编码向量为动作特征,对每一段子序列使用池化的方法计算得到2n个特征;将2n个特征分为2n-1个子序列,用池化方法直到2n-1个特征;重复上述步骤直到n=0,将池化后的特征串联起来即为整个动作的特征.
 |
| 图 3 时间金字塔匹配Fig. 3 Temporal pyramid matching |
| 图选项 |
采用的池化方法为[11]
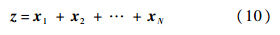

式中:x1,x2,…,xN为N帧动作的特征向量;z(j)为向量z中的第j个元素,z′为池化后的动作特征.
得到整个动作的特征后,只需使用训练数据训练线性SVM分类器,得到的分类器模型即可对测试集的动作数据完成分类.
4 实 验4.1 MSR-Action3D数据库MSR-Action3D数据库是由深度摄像机获取的动作数据库,其中包含high arm wave,horizontal arm wave,hammer,hand catch,forward punch,high throw,draw x,draw tick,draw circle,hand clap,two hand wave,side-boxing,bend,forward kick,side kick,jogging,tennis swing,tennis serve,golf swing,pick up & throw 20种动作,共有10个表演者,每个动作每人表演2~3次.视频帧率为15帧/s,分辨率为640像素×480像素.数据库中共有557个已分割的动作视频,其中每个动作视频的三维关节位置坐标使用实时的骨骼跟踪算法实现[2].
与其他使用该数据库的文献的实验方法相同,实验中将编号为1、3、5、7、9的动作表演者表演的动作视频作为训练数据,编号为2、4、6、8、10的表演者的动作视频作为测试数据,算法中线性SVM分类器使用LIBSVM[13],其参数由交叉验证确定,取C=1,此外LLC中λ=0.1,使用文献[11]中提出的LLC近似快速算法,最近邻的元素个数为10,LLC词典中每类动作的子词典元素个数为300,时间金字塔为4,2,1结构.实验结果表明:该算法在该数据库上达到的识别率为85.71%,其中10种动作的识别率为100%,混淆矩阵如图 4所示,颜色越深识别率越大.
 |
| 图 4 在MSR-Action3D数据库上的混淆矩阵Fig. 4 Confusion matrix on MSR-Action3D dataset |
| 图选项 |
识别率与其他方法的对比如表 1所示.由表 1可以看出,本文方法在动作识别率方面优于多种已有方法,且与文献[20]提出的方法达到了相似的效果.
表 1 MSR-Action3D数据库上的识别率比较 Table 1 Recognition accuracy comparison on MSR-Action3D dataset
| 方法 | 识别率/% |
| Recurrent Neural Network[14] | 42.5 |
| Dynamic Temporal Warping[15] | 54.0 |
| Hidden Markov Model[16] | 63.0 |
| Latent-Dynamic CRF[17] | 64.8 |
| Bag of 3D Points[18] | 74.7 |
| Histogram of 3D Joints[6] | 78.97 |
| Eigenjoints[7] | 82.3 |
| STOP Feature[19] | 84.8 |
| Random Occupy Pattern[20] | 86.2 |
| SC+TPM | 75.45 |
| 本文方法 | 85.7 |
表选项
此外,还对基于稀疏编码和时间金字塔匹配的识别算法进行了实验,以局部动作特征为动作特征,词典学习采用文献[21]中的方法,词典大小为400,编码系数的L0范数小于3,得到的识别率为75.45%,体现了使用LLC的有效性.
4.2 算法时间复杂度表 2列出了以每秒处理视频的速度作为评价标准的算法时间复杂度比较,本文算法在两种计算机配置下进行实验,每种配置下重复实验10次,分别得到平均处理速度488帧/s和761帧/s.
表 2 算法运行速度 Table 2 Computing speeds of algorithms
| 方法 | 计算机配置 | 运行环境 | 速度/ (帧·s-1) |
| 文献[9] | — | — | 200~500 |
| 本文方法 | Intel Dual-Core E5800 3.2GHz,2G内存 | Matlab R2012b | 488 |
| 本文方法 | Intel Core i7 3632QM 2.2GHz,4G内存 | Matlab R2013b | 761 |
表选项
文献[10]未提供算法运算速度,然而算法中采用文献[22]的稀疏编码方法,需要迭代8次,其运算复杂度为Ο(M×K),其中M为词典元素个数,K为编码系数中非零元素数;而LLC编码方法具有解析解,文献[11]给出LLC快速近似解的计算复杂度为Ο(M+K2),由于M≥K,因此LLC的时间复杂度低于文献[22]的稀疏编码方法[13],即本文方法时间复杂度低于文献[10]方法.同样地,文献[20]在提取Random Occupy Patterns特征后采用稀疏编码方法,并用SVM分类动作,根据上文对LLC和稀疏编码间运算复杂度的比较,文献[20]的算法时间复杂度高于本文方法.
文献[9]中算法速度没有给出计算机配置与运行环境,其速度慢于本文方法;此外,由于文献[9]中方法需要计算特征与所有训练样本距离并排序,其复杂度为Ο(M·lgM),其中M为训练样本个数,因此在样本变大时将增加运算的时间复杂度,本方法则不存在这一问题.
4.3 编码系数降维方法的有效性为表明对LLC编码系数的降维方法的有效性,在不对编码系数降维的情况下,计算出LLC词典元素个数变化时的动作识别率,如图 5所示.
 |
| 图 5 词典元素个数对识别率的影响Fig. 5 Impact on the recognition accuracy of dictionary size |
| 图选项 |
由图 5可以看出,识别率随着词典元素个数增多有逐渐上升的趋势,但是均低于82%.此外,得到的SVM分类器支持向量均为280个左右(训练样本为284个),出现了严重的过拟合.而通过利用词典元素类别对编码系数降维,在4.1节中提到的条件下,SVM分类器的支持向量个数为111个,且识别率为85.7%.
5 结 论提出了一种基于LLC的动作识别方法,通过在MSR-Action3D数据库上进行实验,得到以下结论:
1) 采用LLC对局部动作特征求解稀疏表达,增强了特征的区别力,从而解决了动作特征类内差异较大的问题,取得较高识别率;由于LLC具有解析解,保证了算法具有较低的运算复杂度.
2) 采用K-means分别对每类数据训练子词典,使算法可以方便地扩展可识别动作类别,此外,利用词典元素类别对编码系数进行降维,避免了词典较大情况下分类器的过拟合现象.
3) 一些相似的动作识别率仍然较低,可以进一步研究LLC的词典学习方法,以达到更高识别率.
参考文献
| [1] | 郑韡, 沈旭昆.基于连续数据流的动态手势识别算法[J].北京航空航天大学学报, 2012, 38(2):273-279. Zheng W, Shen X K.Algorithm based on continuous data stream for dynamic gesture recognition[J].Journal of Beijing University of Aeronautics and Astronautics, 2012, 38(2):273-279(in Chinese). |
| Click to display the text | |
| [2] | 史骏, 陈才扣.基于马氏距离的半监督鉴别分析及人脸识别[J].北京航空航天大学学报, 2011, 37(12):1589-1593. Shi J, Chen C K.Mahalanobis distance-based semi-supervised discriminant analysis for face recognition[J].Journal of Beijing University of Aeronautics and Astronautics, 2011, 37(12):1589-1593(in Chinese). |
| Click to display the text | |
| [3] | Weinland D, Ronfard R, Boyer E.A survey of vision-based methods for action representation, segmentation and recognition[J].Computer Vision and Image Understanding, 2011, 115(2):224-241. |
| Click to display the text | |
| [4] | Shotton J, Girshick R, Fitzgibbon A, et al.Efficient human pose estimation from single depth images[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(12):2821-2840. |
| Click to display the text | |
| [5] | Jhuang H, Gall J, Zuffi S, et al.Towards understanding action recognition[C]//Proceedings of IEEE International Conference on Computer Vision (ICCV).Piscataway, NJ:IEEE Press, 2013:3192-3199. |
| Click to display the text | |
| [6] | Xia L, Chen C C, Aggarwal J K.View invariant human action recognition using histograms of 3d joints[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops(CVPRW).Piscataway, NJ:IEEE Press, 2012:20-27. |
| Click to display the text | |
| [7] | Yang X, Tian Y L.Eigenjoints-based action recognition using naïve bayes nearest neighbor[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops(CVPRW).Piscataway, NJ:IEEE Press, 2012:14-19. |
| Click to display the text | |
| [8] | Wang J, Liu Z, Wu Y, et al.Mining actionlet ensemble for action recognition with depth cameras[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway, NJ:IEEE Press, 2012:1290-1297. |
| Click to display the text | |
| [9] | Zanfir M, Leordeanu M, Sminchisescu C.The moving pose:An efficient 3D kinematics descriptor for low-latency action recognition and detection[C]//Proceedings of IEEE International Conference on Computer Vision(ICCV).Piscataway, NJ:IEEE Press, 2013:2752-2759. |
| Click to display the text | |
| [10] | Luo J, Wang W, Qi H.Group sparsity and geometry constrained dictionary learning for action recognition from depth maps[C]//Proceedings of IEEE International Conference on Computer Vision(ICCV).Piscataway, NJ:IEEE Press, 2013:1089-1816. |
| Click to display the text | |
| [11] | Wang J, Yang J, Yu K, et al.Locality-constrained linear coding for image classification[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway, NJ:IEEE Press, 2010:3360-3367. |
| Click to display the text | |
| [12] | Yu K, Zhang T, Gong Y.Nonlinear learning using local coordinate coding[C]//Advances in Neural Information Processing Systems.La Jolla, CA:Neural Information Processing Systems Foundation, 2009:1-9. |
| Click to display the text | |
| [13] | Chang C C, Lin C J.LIBSVM:A library for support vector machines[J].ACM Transactions on Intelligent Systems and Technology(TIST), 2011, 2(3):27. |
| Click to display the text | |
| [14] | Martens J, Sutskever I.Learning recurrent neural networks with Hessian-free optimization[C]//Proceedings of the 28th International Conference on Machine Learning(ICML).New York:International Machine Learning Society(IMLS), 2011:1033-1040. |
| Click to display the text | |
| [15] | Müller M, Röder T.Motion templates for automatic classification and retrieval of motion capture data[C]//Proceedings of the ACM SIGGRAPH.New York:ACM, 2006:137-146. |
| Click to display the text | |
| [16] | Lv F, Nevatia R.Recognition and segmentation of 3-d human action using hmm and multi-class adaboost[C]//Proceedings of European Conference on Computer Vision(ECCV).Berlin, Heidelberg:Springer, 2006:359-372. |
| Click to display the text | |
| [17] | Morency L, Quattoni A, Darrell T.Latent-dynamic discriminative models for continuous gesture recognition[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ:IEEE Press, 2007:1-8. |
| Click to display the text | |
| [18] | Li W, Zhang Z, Liu Z.Action recognition based on a bag of 3d points[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops(CVPRW).Piscataway, NJ:IEEE Press, 2010:9-14. |
| Click to display the text | |
| [19] | Vieira A W, Nascimento E R, Oliveira G L, et al.Stop:space-time occupancy patterns for 3d action recognition from depth map sequences[C]//Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications.Berlin, Heidelberg:Springer, 2012:252-259. |
| Click to display the text | |
| [20] | Wang J, Liu Z, Chorowski J, et al.Robust 3d action recognition with random occupancy patterns[C]//Proceedings of European Conference on Computer Vision(ECCV).Berlin, Heidelberg:Springer, 2012:872-885. |
| Click to display the text | |
| [21] | Mairal J, Bach F, Ponce J, et al.Online dictionary learning for sparse coding[C]//Proceedings of the 26th Annual International Conference on Machine Learning.New York:ACM, 2009:689-696. |
| Cited By in Cnki (0) | Click to display the text | |
| [22] | Lee H, Battle A, Raina R, et al.Efficient sparse coding algorithms[C]//Advances in Neural Information Processing Systems.La Jolla, CA:Neural Information Processing Systems Foundation, 2006:801-808. |
| Click to display the text |
