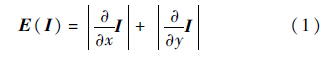
式中:x,y为横、纵坐标.实际上,它是灰度图的梯度的模,反映了图像灰度在某个像素上的变化速率.由于计算机里的数字图像是离散的,计算它的像素梯度模时常用梯度模算子来进行卷积计算,如图 1 所示为Sobel算子示意图.
 |
| 图 1 Sobel算子示意图Fig. 1 Sobel operator schematic |
| 图选项 |
接下来就是借助重要性图对图像进行操作.设
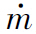 为每行删去的像素个数(其中m为原始图像每行的像素数目,m′为处理后图像每行的像素数目),则操作方式分为w步,每步删去图像中的一条缝(Seam线),一条竖直缝可定义为
为每行删去的像素个数(其中m为原始图像每行的像素数目,m′为处理后图像每行的像素数目),则操作方式分为w步,每步删去图像中的一条缝(Seam线),一条竖直缝可定义为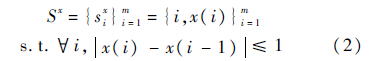
式中:x:[1,2,…,m]→[1,2,…,n]是一个映射;i为行号;xi为列号;si为第i条缝.找到垂直方向能量最小的Seam线即最优缝s*,把它删除,对图像的质量影响最小.
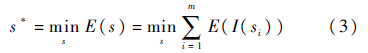
式中:s为一条缝;I(si)为图像像素值.寻找的方法是使用动态规划从重要性图的第二行遍历至最后一行,然后进行回溯找到这条最优Seam线的路径.只需进行w次最优Seam线的查找和删除即可.Seam Carving的局限性在于:算法复杂度较高;采用的能量函数过于简单;Seam线容易穿过重要物体导致变形,如图 2 所示.
 |
| 图 2 裁剪线方法Fig. 2 Seam Carving method |
| 图选项 |
Avidan和Shamir提出Seam Carving技术后,该技术被广泛引用并改进,例如文献[5, 6, 7, 8, 9, 10, 11, 12, 13],从不同角度对Seam Carving方法进行改进,当然其核心思想依旧是利用动态规划寻找最优Seam线后将其删除.1.2 连续性的方法简单缩放技术借助正向映射[14]将原始图像的像素映射到新图像的特定位置,或者逆向映射[14]从原始图像中找到新图像像素的对应点,然后利用插值法构造新图,可归为连续性的图像缩放方法.与简单缩放技术不同的是,Image Warping将图像分成不同区域,对不同区域进行程度不一的缩放处理.Image Warping的方法通常设计一个客观评价函数来评判某一变形对图像整体的保护效果,通过最优化这个函数,获得最优的变形结果.2008年的Siggraph Asia会上,Wang等提出了OSS(Optimized Scale-and-Stretch)缩放技术[15].该方法将原图像划分成网格状(包含网格线和网格点),将缩放问题转换为寻找满足几何约束的新网格点位置,用式(4)来衡量单个网格的形变程度.

式中:i、j为网格的顶点;f为网格;E(f)为网格的边;v为图像里的初始顶点;v′为网格形变后的顶点;sf为缩放因子.Du(f)值越小说明形变程度越小.该方法还考虑了另一个衡量值Dl,用来衡量网格弯曲程度,在此不加说明.该方法就是通过寻找使图像总体形变量最低的网格点位置v′来获取最优结果的.在OSS的基础上,Hu等增加了控制网格大小的变量[16],即在式(4)中加入变量a,通过调整a,可以控制图像中主体对象的大小.2 有上限的列缩放本文提出一个新的图像缩放的方法,是一种基于内容的连续的图像适配显示技术.该方法的主要贡献在于:1) 它是一个算法复杂度低,且效果不错的图像缩放方法.2) 提出了相应的客观评判标准和最优化参数a.为了简单起见,且不失一般性,这里只讨论对图像进行水平方向上缩小的情况.本文的方法包含4个步骤:1) 计算图像的重要性图.2) 处理使得同一列中每个像素的重要性一致.3) 通过机器学习的方式获得最优参数,借此确定每一列的缩放比.4) 根据每一列的缩放比,进行图像缩放得到目标尺寸的图.下面介绍该方法的原理与实现.2.1 重要性图重要性图是一个和原图尺寸一样的矩阵.一般可将数值归一化至0~1之间.数值越接近1,表示该像素的重要程度越高.离散方法Seam Carving[3]里用梯度图作为重要性图,即把图像里物体边缘看成是重要部分,删去那些与周围像素混合得很好的像素.然而梯度图不能完全反映出图像的重要部分,容易导致Seam线穿过重要物体,例如一张人脸.显著性图(Saliency图)则能较好地解决这个问题.本文借助Harel的方法[1]来计算Saliency图,称之为GBVS图.这个方法能很好地预测人眼对图片的视觉定位,更好地体现一张图片的重要部分或隐藏了不重要部分.然而本文用到的重要性图不是梯度图,也不是显著性图,而是将两者结合,既考虑物体整体的重要性,又考虑物体边缘的重要性.假设IE表示图像I的梯度图,IS表示GBVS图,IO表示本文的重要性图,要将IE和IS结合,可以用矩阵点乘的方式[15]表示为式(5).

这里的
 表示两矩阵同一位置的对应元素相乘(矩阵点乘).但是通过实验发现,这样的方法缺陷明显(图 3(h)),究其原因,是因为相乘的方法得到的结果IO偏向于梯度图IE.对于图像中那些显著性突出(IS大)而梯度值小的部分,得到的重要性数值依然很小.因此,本文采用梯度图与GBVS图相加的方式[17]:
表示两矩阵同一位置的对应元素相乘(矩阵点乘).但是通过实验发现,这样的方法缺陷明显(图 3(h)),究其原因,是因为相乘的方法得到的结果IO偏向于梯度图IE.对于图像中那些显著性突出(IS大)而梯度值小的部分,得到的重要性数值依然很小.因此,本文采用梯度图与GBVS图相加的方式[17]:
+表示两矩阵对应像素相加.式(6)在保证准确找出重要物体的同时,加上物体的边缘信息,保证了重要物体边缘的僵硬性,一定程度上降低边缘线的变形程度.倘若边缘线是一条直线[13],这个加成对直线的保护也起到一定作用.图 3 展示了利用各种重要性图处理的结果,缩放比均为0.5.可以在运动员的右小腿上看出各图的差别.div class="figure outline_anchor">
 |
| 图 3 同一图片的不同重要性图及相应结果的对比Fig. 3 Comparison of different importance maps and corresponding results for the same image |
| 图选项 |
2.2 进一步处理重要性图2.1节里所得到的重要性图还不能用来处理图片,要借助重要性图来决定图像每一列的缩放比,用缩放比进行最终的缩放得到目标尺寸的图片.因此,用式(7)[18]来修改重要性图,设式(5)中得到的重要性图为E,则
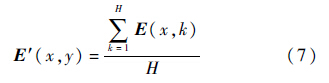
式中:k为列数;H为原图片的高度;E(x,y)为重要性图中第x行、第y列的值,也就是该位置像素的重要性值;E′(x,y)就是图像每列的重要性平均值,也可以直接写成E′(y),1≤y≤W,W为输入图像的宽度.因此,E′实际可以记为一个单行的矩阵.图 4(c) 为处理后的重要性图E.
 |
| 图 4 基于列的重要性图处理Fig. 4 Importance map processing based on columns of image |
| 图选项 |
倘若不进行重要性图的进一步处理,即不平均每一列的重要性,则会得到如图 5(b)所示的结果,造成严重的扭曲.原因是每个像素的重要性值不一样,在水平方向上的缩放尺度不一样,原本处于同一列的像素缩放之后可能位置会有所差异.另一方面,利用处理后的重要性图进行图像缩放,能有效地提高图像处理的效率,相比于计算每列的重要性均值需要的代价来说,之后进行缩放处理时所降低的代价显然要更大.由此只需把每一列像素当成一个像素来处理即可.如图 5(c) 所示为利用处理后的重要性图得到的结果.
 |
| 图 5 不同重要性图得到的结果对比Fig. 5 Comparsion of results obtained with different importance maps |
| 图选项 |
2.3 获得每一列的缩放比重要性图的作用就是指导之后的图像缩放处理.与Seam Carving不同的是,Seam Carving直接删去重要性低的像素,是一种离散的方法.本文的方法是一种连续的方法,对于重要性低的像素并非直接删去,而是分配以较低的缩放比.将初始图像的每个像素的宽度设为1,处理后的每个像素的宽度表示为S(x,y).分配给同一列像素的重要性值是一样的,因此它们的缩放比也是一样的[18].
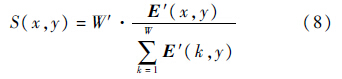
式中:W′为目标图像的宽度.所有列的目标宽度的和满足:
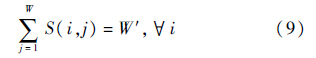
本文打算对S(x,y)设置一个上限a,当计算得到的S(x,y)超过阈值a时,则将该像素(列)的目标宽度设置为a.于是,像素的目标宽度进一步写为
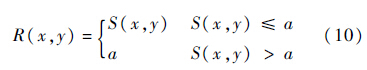
若未设上限,缩放后的图像中存在太大的物体容易造成失真.例如,当目标图像的缩放比为0.8(接近1)时,即W′=0.8W,S(x,y)很有可能大于1,这显然不能让人接受(图 6(b) ).更极端的情况是,当缩放比为1时(图 6(c)),直接用S的值来分配每列的宽度,得到的结果和原图是不一样的,显然这也不是最优的处理结果.另一方面,若没有对目标列宽进行上限限制,图像中一部分会被过分压缩,导致图像变形,如图 6中女生的右手.
 |
| 图 6 不设处理后像素宽度上限的缺陷Fig. 6 Defect of no upper limit of width for processed pixel |
| 图选项 |
若有上限限制,这样的变形程度会小得多.但阈值a取何值时效果最好并不清楚,这也是本文要解决的问题之一.图 7是以缩放比为0.5,取一系列不同的a值得到不同结果图的一组实验.
 |
| 图 7 不同处理后像素宽度上限的结果对比Fig. 7 Comparsion of results with different upper limit of processed pixel width |
| 图选项 |
2.4 确定最优阈值阈值a的选择是本文的重点,如果不对a进行过多讨论,直接取a=1实为不错的选择[18],因为a=1保证了缩放后图像里的物体不会比初始图中对应的物体大.然而,图像通常会存在部分缩放比较大,且没超过1的列,在图像经过阈值a=1的限制后,它们的目标宽度会得到补偿,从而更接近1,这也容易造成图像的失真,因为它的宽度远比整张图像的缩放比大,特别在缩放比较小的情况下.而且还会造成原始图像信息的丢失,特别是重要物体与背景之间的对比信息的丢失.因此,选取最优的a,就是要在图像的重要部分和不重要部分间做一个权衡,既要尽量保持重要部分与初始状态的相似性,又要适当保护不重要部分,即保留原始图像中各个物体间的对比信息.对于图像I,若其目标缩放比为1(当然这是没有意义的),容易知道最优的处理结果就是保持原图像不变,用本文的方法来处理,就是取a=1,此时每列的宽度变化为0.当图像缩放比不为1时,最终每列的变化程度之和不可能为0,这就是造成图像形变的直接原因.理想的结果只有在缩放比为1的时候能实现.于是,本文定义了式(11)用来衡量图像总体变形程度.
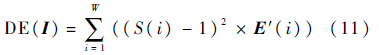
并称式(11)为形变能量公式.可以看出,形变能量DE值越大,说明目标图像和原图的差距越大.对于任意图像I,可以得到图像每列像素的缩放比S(y),进一步获得该图像的形变能量,能量越小,图像缩放的效果越好.有了形变能量,就可以借助它来寻找最优阈值a.一张图像I,对于一个目标缩放比s′,取不同的a值会得到不同的结果.对于本文的方法,由于有了阈值a的限制,R才是最终分配给每一列的目标宽度,形变能量可进一步写为

接下来目标就是选择最优的a,使得图像I的形变能量最小.本文中,对于单张图片I,采用穷举的方式求出最优a.穷举a从缩放比s开始,以0.01的步长增加到1,计算每个a值下的形变能量,选取形变能量最低的a为最优a,记为a*.显然,a值的选取十分重要,若太小,会使得图中的重要部分被过度压缩,例如图 8(b)和图 8(c)中的荷花.而本文通过穷举,获得使形变能量值(式12)最小的a值,用该a得到的图 8(d)效果最好.然而,若每次处理图片都需要穷举的方式来寻找a*,将耗费较多时间.因此本文采用机器学习的方法来获得a*.
 |
| 图 8 宽度变为原来的50%时,不同a得到的结果Fig. 8 Results of different a when width is 50% of original width |
| 图选项 |
2.5 图像特征提取和机器学习特征是一幅图像中让人感兴趣的部分,它可以是图像的颜色特征、纹理特征或是形状特征.特征提取往往是图像处理的第一步,针对不同的问题,提取相应的图像特征,将有利于后续步骤的进行.错误的特征提取将导致整个算法的失败.不同的a会影响需要进一步改变的S(y),a越小,需要被限制的S(y)越多.为了利用图像特征值来获得a*,需要满足特征值相近的图像具有相近的a*.S(y)是由重要性图E得来的,E(y)则是指图像的第y列的平均重要性值.图像的重要性值分布不同,对应的a*也会不同,因此以和E有关的因素作为图像特征是可取的.另外,假想有两张图片,它们的重要性图不同,不同之处仅在于列的顺序不一样,这样由式(12)得到的a*还会是一样的,即a的取值与E从左至右的顺序是无关的,只和它的大小有关.于是本文选取E的分布直方图(见图 9)作为图像的特征进行提取:1) 找到E里的最大值:
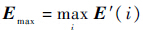 .2) 归一化处理:
.2) 归一化处理: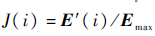 .3) 得到的J取值范围为0~1之间的小数,将0~1分为100段,每段长0.01,令k表示第k段,k=1,2,…,100.4) 令
.3) 得到的J取值范围为0~1之间的小数,将0~1分为100段,每段长0.01,令k表示第k段,k=1,2,…,100.4) 令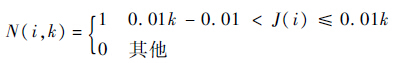
若J)=0时,N(i,1)=1.5) HN(k)表示J里落入第k段范围(1 ≤ k ≤ 100,k∈Z)的列数:HN(k)=∑Wi=1N(i,k).6) 得到分布直方图H,直方图的第k列(1≤k≤100,k∈Z)H(k)表示HN(k)占总列数的百分比:
 .7) 将该直方图的100个数作为图像I的特征值.
.7) 将该直方图的100个数作为图像I的特征值. |
| 图 9 不同图片列能量分布直方图Fig. 9 Distribution histograms of different images of their energy columns |
| 图选项 |
以这100个特征作为机器学习的输入,输出为a*.100个特征中,第i个特征表示在重要性图E′里的W个数中,占最大值百分比介于(0.01i-0.01)和0.01i之间的列数占总列数的比例.因此,特征值相近的图片,对于同一个缩放比,具有相近的a*.径向基函数(Radical Basis Function,RBF)神经网络能够逼近任意的非线性函数,可以处理系统内的难以解析的规律性,具有良好的泛化能力,并有很快的学习收敛速度.由于并不能通过数学方式建立可靠的a*模型,因此本文采用MATLAB里神经网络工具箱里的RBF神经网络模型.素材为文献[19]里提供的80张图片.建立学习模型时输入的学习材料为80张图片的特征值,以及它们对应的a*,该a*通过穷举得到,满足式(12)中的形变能量最小.本文分别为不同缩放比建立模型.待处理图片I被输入后,程序提取I的100个特征值,选择目标缩放比对应的模型,模型的输入为这100个特征值,输出为该图片的最优阈值a*.有了a*之后,就可以得到图像I的缩放指示图R(单行矩阵),表明图像I中每列像素缩放后的目标宽度.表 1为不同缩放比时利用RBF学习法获得的a*与通过穷举获得的a*的比较,可以发现a*与穷举得到的十分接近.表 1 机器学习效果展示 Table 1 Effect display of machine learning
| 图片名 | 缩放化为0.5 | 缩放化为0.75 | ||||||
| 学习法 | 穷举法 | 学习法 | 穷举法 | |||||
| a* | DE值 | a* | DE值 | a* | DE值 | a* | DE值 | |
| Pigeons | 0.707 | 35.779 | 0.68 | 35.765 | 0.816 | 8.942 | 0.81 | 8.936 |
| Ski | 0.717 | 40.142 | 0.69 | 40.131 | 0.816 | 9.793 | 0.82 | 9.783 |
| Soccer | 0.667 | 21.618 | 0.65 | 21.615 | 0.833 | 4.923 | 0.83 | 4.921 |
| Stair | 0.677 | 32.924 | 0.67 | 32.924 | 0.844 | 7.846 | 0.84 | 7.834 |
| Suffer | 0.754 | 22.628 | 0.76 | 22.627 | 0.890 | 5.493 | 0.88 | 5.478 |
| Suffers | 0.725 | 10.159 | 0.76 | 10.138 | 0.865 | 2.582 | 0.84 | 2.566 |
| Tajmahal | 0.662 | 25.389 | 0.68 | 25.378 | 0.848 | 5.616 | 0.85 | 5.618 |
| Tiger | 0.723 | 23.329 | 0.73 | 23.324 | 0.885 | 4.930 | 0.89 | 4.923 |
| Tower | 0.683 | 46.562 | 0.67 | 46.558 | 0.837 | 10.655 | 0.84 | 10.648 |
| Trees | 0.660 | 23.893 | 0.65 | 23.892 | 0.808 | 5.843 | 0.81 | 5.839 |
| Towbirds | 0.626 | 27.734 | 0.66 | 27.725 | 0.807 | 6.721 | 0.81 | 6.720 |
| Venice | 0.670 | 12.713 | 0.71 | 12.699 | 0.835 | 3.054 | 0.84 | 3.053 |
| Volleyball | 0.703 | 17.651 | 0.73 | 17.643 | 0.874 | 3.829 | 0.86 | 3.809 |
| Waterfall | 0.668 | 21.983 | 0.70 | 21.945 | 0.841 | 5.214 | 0.84 | 5.216 |
| Wedding | 0.686 | 33.370 | 0.69 | 33.370 | 0.844 | 7.957 | 0.83 | 7.911 |
表选项
2.6 像素融合获得了图像 I 的缩放指示图后,就可以对图像做最后的处理.计算机中,每一列像素的宽度均为1,而缩放指示图里的值均为小数,因此需要进行像素融合.例如,假设图像 I 的列数W=5,缩放后的图像 I 的目标宽度为W′=3, I 的缩放指示图为R=[0.3,0.8,0.4,0.9,0.6],I (x,y)表示x行y列上的像素值,I (x,y)表示目标图里x行y列上的像素值,则像素融合的过程为

3 实验结果为了简单起见,本文讨论的都是将图片在水平方向上的缩小,以下实验是将原图在水平方向缩小50%得到的实验结果(见图 10).由图 10可以看出,剪裁(Cropping)方法(图 10(b))将原图的很多内容直接去除了,虽然保留下来的重要物体效果很好,但一些背景的缺失使得图像能传达的信息大量削减.且对于重要物体占据较大位置的图片来说,例如,第4行的人脸,Cropping直接将其部分截掉.Seam Carving方法(图 10(c))会使物体产生明显变形,特别体现在物体边缘的褶皱,例如第3幅图的屋顶,第4幅图的人脸发际线,也体现在Seam线过多地经过重要物体,例如最后一张图,鱼的身体被切割较多,使得重要物体与原始状态差距较大.形变(Warping)(图 10(d))的方法效果相对较好,但基于网格的处理方式容易使物体在同一列上的形变程度不一致,从而产生畸形,如第4行所示.另外基于网格的方式和复杂的最优求解在效率上不占优势.而本文的方法(图 10(e))在重要物体和背景物体间做了最优的取舍,重要物体被保护的同时较好地保留了背景信息,同时在算法效率上也具有优势.
 |
| 图 10 不同方法的结果比较Fig. 10 Comparison of results using different methods |
| 图选项 |
表 2 利用形变能量公式(12)对本文获得的a*和文献[18]里默认的a=1进行对比,结果表明a*对应的形变能量较小,也就是说,图像在a*的处理下总体变形程度较小,得到的目标图像质量更优.将参数a直接设置为1,可能导致图中的重要物体保持不变,对于较小的缩放比,会使留给非重要物体的空间被过分压缩,造成图像失真.表 2 客观地反映了a=a*相较于a=1的优势.表 2 机器学习效果展示 Table 2 Effect display of machine learning
| 图像名 | 缩放比为0.5 | 缩放比为0.75 | ||
| a=1 | a=a* | a=1 | a=a* | |
| Pigeons | 35.902 | 35.779 | 10.865 | 8.942 |
| Ski | 40.282 | 40.142 | 11.848 | 9.793 |
| Soccer | 21.629 | 21.618 | 5.778 | 4.923 |
| Stair | 32.961 | 32.924 | 9.683 | 7.846 |
| Suffer | 23.368 | 22.628 | 7.064 | 5.493 |
| Suffers | 10.498 | 10.159 | 3.009 | 2.582 |
| Tajmahal | 25.413 | 25.389 | 7.399 | 5.616 |
| Tiger | 23.476 | 23.329 | 6.592 | 4.930 |
| Tower | 46.590 | 46.562 | 13.754 | 10.655 |
| Trees | 23.898 | 23.893 | 6.894 | 5.843 |
| Towbirds | 27.740 | 27.734 | 7.590 | 6.721 |
| Venice | 12.751 | 12.713 | 3.942 | 3.054 |
| Volleyball | 17.843 | 17.651 | 4.866 | 3.829 |
| Waterfall | 22.044 | 21.983 | 6.614 | 5.214 |
| Wedding | 33.465 | 33.370 | 9.412 | 7.957 |
表选项
4 结 论提出了一种新的图像适配显示方法.本文的方法通过机器学习的方法进行预处理后,在一维的尺度上对图像的每列分配比例因子,从而在保证效果的前提下提高算法效率.与其他方法相比:
1) 该方法在完成学习后,对图片处理仅是一维操作,复杂度低,效率高.2) 该方法得到的结果较为自然,形变更少.3)由于本方法是以列为单位进行处理,不同列的缩放比不同,因此倘若图中有斜线连续穿过多列就容易出现断裂或弯曲.或者当一个物体宽度较大时,由于各部分的缩放比不同,也容易出现变形.这些问题或许可以通过对重要性图的再改进得以解决.本文a仅仅设置了上限,以后的工作中,可以尝试加入下限限制,对保护不重要物体起到直接作用.本文的衡量方式只考虑图像每列变形程度的和,没有考虑到列的位置关系,而图像中物体的位置恰恰是人们对图像关注的重点之一.以后的工作中,也可以考虑使用更有针对性的形变衡量方式.
参考文献
| [1] | Harel J, Koch C, Perona P, et al.Graph-based visual saliency[C]//Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems.Vancouver, B.C.:NIPS, 2006:545-552. |
| Click to display the text | |
| [2] | Shamir A, Sorkine O.Visual media retargeting[C]//ACM SIGGRAPH ASIA 2009 Courses.New York:ACM, 2009. |
| Click to display the text | |
| [3] | Avidan S, Shamir A.Seam carving for content-aware image resizing[J].ACM Transactions on Graphics, 2007, 26(3):10. |
| Click to display the text | |
| [4] | Wolf L, Guttmann M, Cohen-Or D.Nonhomogeneous content-driven video-retargeting[C]//IEEE 11th International Conference on Computer Vision, ICCV 2007.Piscataway, NJ:IEEE Press, 2007, 10:14-21. |
| Click to display the text | |
| [5] | Dong W, Zhou N, Paul J C, et al.Optimized image resizing using seam carving and scaling[J].ACM Transactions on Graphics(TOG), 2009, 28(5):1-10. |
| Click to display the text | |
| [6] | Hwang D S, Chien S Y.Content-aware image resizing using perceptual seam carving with human attention model[C]//IEEE International Conference on Multimedia and Expo.Piscataway, NJ:IEEE Press, 2008:1029-1032. |
| Click to display the text | |
| [7] | Conge D D, Kumar M, Miller R L, et al.Improved seam carving for image resizing[C]//Proceedings of 2010 IEEE Workshop on Signal Processing Systems(SIPS).Piscataway, NJ:IEEE Press, 2010:345-349. |
| Click to display the text | |
| [8] | Domingues D, Alahi A, Vandergheynst P.Stream carving:An adaptive seam carving algorithm[C]//Proceedings of 2010 IEEE 17th International Conference on Image Processing(ICIP'2010).Piscataway, NJ:IEEE Press, 2010:901-904. |
| Click to display the text | |
| [9] | Conger D D, Kumar M, Radha H.Generalized multiscale seam carving[C]//Proceedings of 2010 IEEE International Workshop on Multimedia Signal Processing(MMSP).Piscataway, NJ:IEEE Press, 2010:367-372. |
| Cited By in Cnki (0) | Click to display the text | |
| [10] | Han J W, Choi K S, Wang T S, et al.Improved seam carving using a modified energy function based on wavelet decomposition[C]//Proceedings of 2009 IEEE 13th International Symposium on Consumer Electronics(ISCE'09).Piscataway, NJ:IEEE Press, 2009:38-41. |
| Click to display the text | |
| [11] | Rubinstein M, Shamir A, Avidan S.Improved seam carving for video retargeting[J].ACM Transactions on Graphics(TOG), 2008, 27(3):1-9. |
| Click to display the text | |
| [12] | Frankovich M, Wong A.Enhanced seam carving via integration of energy gradient functionals[J].IEEE Signal Processing Letters, 2011, 18(6):375-378. |
| Click to display the text | |
| [13] | Chang C H, Chuang Y Y.A line-structure-preserving approach to image resizing[C]//Computer Vision and Pattern Recognition(CVPR).Piscataway, NJ:IEEE Press, 2012:1075-1082. |
| Click to display the text | |
| [14] | 全红艳, 曹桂涛.数字图像处理原理与实现方法[M].北京:机械工业出版社, 2014:51-53. Quan, Cao G T.The principle and realization method of digital image processing[M].Beijing:Machinery Industry Press, 2014:51-53(in Chinese). |
| [15] | Wang Y S, Tai C L, Sorkine O, et al.Optimized scale-and-stretch for image resizing[J].ACM Transactions on Graphics(TOG), 2008, 27(5):118. |
| Click to display the text | |
| [16] | Hu W, Luo Z, Fan X.Image retargeting via adaptive scaling with geometry preservation[J].IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 2014, 4(1):70-81. |
| Click to display the text | |
| [17] | Liang Y, Liu Y J, Luo X N, et al.Optimal-scaling-factor assignment for patch-wise image retargeting[J].IEEE Computer Graphics and Applications, 2013, 33(5):67-78. |
| Click to display the text | |
| [18] | Sun K, Yan B, Gao Y.Lowcomplexity content-aware image retargeting[C]//Image Processing(ICIP), 2012 19th IEEE International Conference on.Piscataway, NJ:IEEE Press, 2012:2105-2108. |
| Click to display the text | |
| [19] | Rubinstein M, Gutierrez D, Sorkine O, et al.A comparative study of image retargeting[C]//Proceedings of ACM SIGGRAPH Asia 2010, SIGGRAPH Asia 2010.New York:ACM, 2010, 29(6):160. |
| Click to display the text |
