1 负载及特征描述1.1 IaaS云平台负载IaaS云平台资源调度能耗研究领域中,从资源的提供者和消费者2个视角进行考虑,一方面,物理主机和虚拟机是资源的提供者,物理主机的过载和欠载2个状态,直接影响了IaaS云平台的SLA违反率和能耗成本;另一方面,应用负载是IaaS云平台消耗物理资源的直接反映,是资源消耗者的直接反映.因此,可以应用负载分析方法进行IaaS云平台SLA违反率和能耗成本方面的研究.当前,由于商业竞争等原因,可供研究分析的大规模的云计算数据集非常少,造成使用负载分析手段的局限.幸运的是,2009年Yahoo公开了M45生产集群的日志数据集[2].同年,Google公布Google Cloud trace日志数据集[3],尤其在该数据集的第2版中,包含的信息更加丰富,且数据更加规范,本研究将以此数据集作为研究负载.其中包括12 532台物理主机的29天的大约250 GB的虚拟机负载数据.负载数据包括CPU、内存、网络等负载数据,系统采样时间为300 s,相关数据格式和细节参见文献[4].
1.2 负载特征应用负载是IaaS云平台消耗物理资源的直接反映,而Google Cloud trace提供了可供研究的数据基础.从大量真实的系统数据集中分析出可供使用的负载特征,是进行本研究的基础.进行分析研究前,首先进行负载模型定义.负载模型具体由式(1)~式(7)确定:
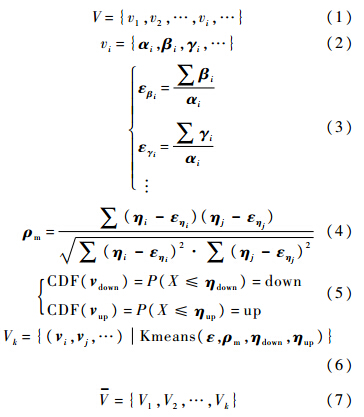
式中,V为虚拟机应用负载的集合;vi为具体每一个负载,具体表示为式(2),由多个维度确定,包括负载长度、CPU使用率、内存使用率、网络使用率等,分别用α,β,γ和ω表示.负载长度(α)使用工作量总量的MI值计量,CPU(β)和内存(γ)使用对该负载使用量的采样计量.进而,云负载可以被描述成一个虚拟机负载的集合V.而负载集合V是由每一个由α,β,γ的采样向量定义的负载vi组成的.式(3)~式(5)给出了4个负载特征ε,ρm,ηdown和ηup.其中ε为负载采样样本均值(负载使用率的平均波动幅度),ηup和ηdown分别为负载累积分布在对应概率阈值下的负载阈值,而定义ρm为负载采样样本的互相关系数,计算方法如式(8)所示:
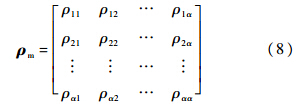
式(6)给出了负载特征的聚类分析过程,通过使用K-means聚类算法依据负载特征对负载进行分类.其中Vk就是K类负载集合V的子集之一,如式(7)所示.这样该负载模型的组成和关系可以如下形式化关系表示:
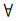 v1,v2,…,vi,…∈V,ε,ρm,ηdown,ηup, 有Kmeans(ε,ρm,ηdown,ηup){V1,V2,…,Vk},其中Vk ⊆ V.这就是负载模型的数学表示,模型的正确性和优劣通过实验验证.
v1,v2,…,vi,…∈V,ε,ρm,ηdown,ηup, 有Kmeans(ε,ρm,ηdown,ηup){V1,V2,…,Vk},其中Vk ⊆ V.这就是负载模型的数学表示,模型的正确性和优劣通过实验验证.2 聚类分析2.1 K-means聚类算法K-means聚类算法被提出已经超过50年历史,但目前为止,其仍然是应用最广泛的划分聚类算法之一[5].K-means容易实施、简单、高效等优点成为其广泛流行的主要原因[6].K-means聚类算法有数据子集数目K、初始聚类质心选取、相似性度量3个参数[7].通常选取欧氏距离作为相似性和距离判断准则,计算聚类内各点与聚类质心ci的距离平方和,目标函数为
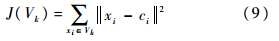
对于一般的数据维数和类别个数,K-means聚类算法是一NP难优化问题[8].K-means聚类算法是一个贪心算法,在多项式时间内,仅能获得局部最优,而不可能获得全局最优.即使这样,对于一个启发式算法已经足够了.此外,基于网格聚类[9]和模型聚类[10]也被众多****所研究,同时给本文以很大启示.
2.2 改进K-means聚类分析2.2.1 层次K值选取K-means算法中K值的选取尤为重要,其改进研究中,K值的选取研究占有了很大比重,尤其是K值自动选择成为新的研究热点[11].K值有2种极限情况:当K=1时,聚类划分为1类,为对象全体;当K=n(n为对象总数)时,聚类划分为n类,每个对象元素都是划分类的中心.本研究根据1.2节中分析的负载样本特征,使用层次划分的方法进行K值选取,具体过程如图 1所示.图 1中树的每一个节点表示一个聚类划分,每一个箭头表示划分为新的聚类划分.本研究采用递增K值逐步推演的方法,随着K值的增加,欧式距离D缩小的比率没有明显增加的时候,作为终止条件.本例中,选取K=6.
 |
| 图 1 负载特征分层聚类分析及K值选取Fig. 1 Hierarchical cluster analysis of workload characterisitic and K value choosing |
| 图选项 |
2.2.2 特征聚类初始质心选取聚类初值的选取是K-means聚类算法的关键步骤.常见的方法是随机选取初值,但是这样簇集合的质量常常很差[12].本文的研究采用了3种方法进行了实验比较得出适合负载特征聚类的方法.处理选取初始质心(Centroids)问题的第1种常用技术是增加运行迭代次数,每次使用随机初始质心.这种策略简单,但是效果不好,取决于数据集和聚类的个数.第2种选择初始质心的方法,随机地选择第1个点,然后,对于每个后继初始质心,选择离已经选取过的初始质心最远的点.使用这种方法的缺点是得到的聚类不够稳定.第3种方法是,取一个样本,并使用层次聚类技术对它聚类.从层次聚类中提取K个簇集合,并用这些簇的中心作为初始值.这样得到的聚类比较稳定.本研究分别对此3种方法进行实验,如图 2所示.
 |
| 图 2 选择初始质心3种方法比较结果Fig. 2 Comparison results of three methods for initial centroid selection |
| 图选项 |
图 2是采用了200个样本点,依次使用3种方法进行K值为3的聚类(聚类分别为Cluster1,Cluster2和Cluster3,质心为Centroids).可以清楚地看到经过图 2(c)的初始质心选择方法聚类结果最佳.因此,综合3个方法的优缺点,层次聚类选取初始质心的方法是针对云负载样本特征进行聚类分析的方法中最合适的.本研究选用第3种方法作为K-means聚类算法的初始质心选取方法.
2.2.3 特征层次聚类通过使用Google Cloud Trace第2版数据集作为研究对象,选取29天1 000个虚拟机的CPU和内存使用率负载数据,每个负载长度α取288×300 s(86 400 s为1天).经过CDF的特征提取,得到4个负载特征ε,ρm,ηdown和ηup.首先,依据负载的互相关系数ρm把VM样本总体分为规律性和不规律性2类(如图 1所示).不规律性负载体现在负载波动规律性差,ρm中相关系数ρ值偏小,一般小于0.3.从而,不容易判断下一时间段的负载.互相关系数ρm体现在不同天的负载相关性.其次,依据负载η(CPU(β)或者内存(γ)等)的累积均值ε,把规律性负载和不规律性负载分别分为2类,如图 1中K-means聚类分析K=4的情形.图 3即是使用负载特征ε和ρm进行分层K-means聚类分析K=4的聚类分析结果.其中,选取100个虚拟机的14天的CPU使用率负载采样样本作为负载,累积负载均值是14天中每天CPU负载均值求和得到的;匹配的P-value值表示求同一虚拟机负载在不同14天中对应的互相关系数后满足P-value小于0.5时,匹配P-value的对数.Cluster1和Cluster2对应规律性负载的聚类,而Cluster3和Cluster4对应非规律性负载的聚类,聚类之间的区别是对应负载的高低.
 |
| 图 3依据ε和ρm的K=4聚类分析结果Fig. 3 Results of clustering analysis using ε and ρm when K=4 |
| 图选项 |
最后针对规律性负载进行ε,ηdown和ηup负载特征进行更细粒度的K-means聚类分析(如图 1中K=4进一步聚类的情形所示).图 4中所示为规律性负载进一步聚类成正常重载(Cluster4)、异常重载(Cluster3)、正常轻载(Cluster2)和异常轻载(Cluster1)4个簇集.正常与异常的区别体现在依据CDF累积分布特征ηup和ηdown的分布.因此,这个聚类分析结果为应用负载资源调度提供了基础.
 |
| 图 4 4组负载特征聚类结果Fig. 4 Clustering results of four groups of workload characteristics |
| 图选项 |
3 资源调度算法经过IaaS平台上的负载特征聚类分析,把负载消耗的资源量分析清楚,有的放矢地把虚拟机部署到合适的物理主机上,以达到降低违反SLA的可能性和节约能耗的目标.目前,改进BFD算法[13]是应用最普遍的资源调度算法,而本文研究的基于负载特征聚类分析的资源调度算法将与文献[14]中的改进BFD算法进行比较.下面给出本文研究的负载特征聚类资源调度算法伪代码和步骤描述.1. Input:hostList,vmList2. Output:allocation of Vms3. vmList.workloadClusteringVmPower()4. foreach vm in vmList do5.foreach host in hostList do6.If host has enough resources for vm then7.vm.power←
 8. foreach vm in vmList do9.minPower ← MAX10.allocatedHost ← NULL11.foreach host in hostList do12. If host has enough resources for vm then13.power ← getpower(host;vm)14.If power < minPower then15.allocatedHost ← host16.minPower ← power17.If allocatedHost,NULL then18.allocation.add(vm,allocatedHost)19. return allocation负载特征聚类资源调度算法步骤第1和第2行为算法输入与输出,第3行为VM列表得到负载分析的聚类结果,第4~7行为每个VM尝试找到最合适的物理主机资源,第8~16行实现聚类的虚拟机分配到最优能耗的物理主机上.由于聚类时考虑到使用率和阈值的关系(具体参见第2节聚类分析内容),所以保证了降低违反SLA的可能性.
8. foreach vm in vmList do9.minPower ← MAX10.allocatedHost ← NULL11.foreach host in hostList do12. If host has enough resources for vm then13.power ← getpower(host;vm)14.If power < minPower then15.allocatedHost ← host16.minPower ← power17.If allocatedHost,NULL then18.allocation.add(vm,allocatedHost)19. return allocation负载特征聚类资源调度算法步骤第1和第2行为算法输入与输出,第3行为VM列表得到负载分析的聚类结果,第4~7行为每个VM尝试找到最合适的物理主机资源,第8~16行实现聚类的虚拟机分配到最优能耗的物理主机上.由于聚类时考虑到使用率和阈值的关系(具体参见第2节聚类分析内容),所以保证了降低违反SLA的可能性.4 实验及结果4.1 实验平台本实验平台选用CloudSim3.03工具包作为实验模拟平台,它支持按需资源配置,易于扩展,并广泛为研究者认可[15].首先,创建一个数据中心,包括800个异构物理节点,其中,惠普ProLiant服务器ml110 G4,惠普ProLiant ml110 G5服务器,惠普ProLiant dl120 G5服务器,惠普ProLiant dl180 G5服务器各占总数的1/4.服务器的功耗数据由SPEC官方给出[16].其次,每个服务器运行在1 GB/s的网络带宽下,虚拟机的特点与类型为亚马逊EC2实例类型:高CPU实例(2 500 MIPS,0.85 GB);大内存实例(2 000 MIPS,3.75 GB);小实例(1 000 MIPS,1.7 GB);微小实例(500 MIPS,613 MB).本实验负载特征样本采取在Hadoop集群上应用Map-Reduce并行计算的方法,处理近20亿条记录,相比传统数据库的效率提高30倍.
4.2 结果与分析实验统一采用MAD-MMT迁移策略[17],对聚类调度算法和改进BFD算法进行比较.实验场景选择第2节中2周(14天)负载数据之外的15天1 000个虚拟机的负载数据集,进行参数为SLA违反率、能耗和虚拟机迁移数比较实验.图 5所示,15天1 000个VM负载数据集在本实验场景下运行的每天违反SLA的百分率.其中,聚类调度算法与改进BFD算法相比较在降低SLA违反率方面,平均有38.6%的提高,也就是说用户可以避免超过1/3性能下降的风险.
 |
| 图 5 SLA违反率实验结果Fig. 5 Experimental results of SLA violation rate |
| 图选项 |
经过SLA违反率参数的比较,可以看到聚类调度算法在用户SLA方面的优势.而在节约能耗方面,通过同场景实验得到图 6所示的结果.结果显示,聚类调度算法比改进BFD算法在每一天都有明显的能耗节省,平均每天节省13.72%.
 |
| 图 6 物理主机能耗实验结果Fig. 6 Experimental results of energy consumption of physical hosts |
| 图选项 |
VM的迁移会造成额外的能耗,所以降低VM的迁移次数也是节能的关键因素之一.通过同场景实验,2种算法的VM迁移次数如图 7所示.通过比较可以知道聚类调度算法的明显优势.
 |
| 图 7 虚拟机迁移次数实验结果Fig. 7 Experimental results of migration times of virtual machines |
| 图选项 |
通过以上对聚类调度算法与改进BFD算法的比较实验分析,本文提出的资源调度算法在保证性能的前提下,能够大幅度减少虚拟机迁移次数,减少了因虚拟机过度迁移产生的额外能耗,因此,可以判断聚类调度算法更为节能,在降低SLA违反率方面更优.这项研究可以与作者联系,获得完整的算法和数据下载,为在研究中实验可以复现.
5 结 论本文的贡献是依据大规模云环境负载数据集的特点,对云环境负载进行特征提取并进行聚类分析,把最优的资源给最亟需的资源需求方.依据这个思路提出基于负载特征聚类的资源调度算法,对IaaS云平台资源进行合理调度,达到降低SLA违反率和节能的目的.经实验与改进BFD算法比较验证表明:1) 在降低SLA违反率方面,平均有38.6%的提高,即用户可以避免超过1/3性能下降的风险.2) 在降低能耗方面,平均每天节省13.72%的能耗.3) 在减少虚拟机迁移次数方面,每天减少1 000~2 000次之间,大大减少了IaaS云平台额外的开销.未来研究将继续进行负载特征提取和预测的研究,解决IaaS云平台上的能耗问题是最为重要的努力方向.
参考文献
| [1] | Wang X L, Liu Z H.An energy-aware VMs placement algorithm in cloud computing environment[C]//Intelligent System Design and Engineering Application(ISDEA),2012 Second International Conference on.Piscataway,NJ:IEEE,2012:627-630. |
| Click to display the text | |
| [2] | Yahoo. M45 supercomputing project[EB/OL].Pittsburgh:Carnegie Mellon University,2009[2014-07-04].http://research.yahoo.com/node/1884. |
| Click to display the text | |
| [3] | Google. Google Cluster data V2[EB/OL].California:Googlecode,2011(2014-11-17)[2014-07-04].http://code.google.com/p/googleclusterdata/wiki/ClusterData2011. |
| Click to display the text | |
| [4] | Brown R. Report to congress on server and data center energy efficiency:public law 109-431[J].Lawrence Berkeley National Laboratory,2008:1-137. |
| Click to display the text | |
| [5] | Anil K J. Data clustering:50 years beyond K-means[J].Pattern Recognition Letters,2010,31(8):651-666. |
| Click to display the text | |
| [6] | Zhang W, Yang H I,Jiang H Y,et al.Automatic data clustering analysis of arbitrary shape with K-means and enhanced ant-based template mechanism[C]//36th IEEE Annual International Computer Software and Applications Conference.Washington,D.C.:IEEE Computer Society,2012:452-455. |
| Click to display the text | |
| [7] | 孙吉贵,刘杰, 赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61. Sun J G,Liu J,Zhao L Y.Research on clustering algorithm[J].Journal of Software,2008,19(1):48-61(in Chinese). |
| Click to display the text | |
| [8] | Mahajan M, Nimborkor P,Varadarajan K.The planar K-means problem is NP-hard[J].Lecture Notes in Computer Science,2009,5431:274-285. |
| Click to display the text | |
| [9] | 陈宁,陈安, 周龙骧.基于密度的增量式网格聚类算法[J].软件学报,2002,13(1):1-7. Chen N,Chen A,Zhou L X.Incremental clustering algorithm based on density[J].Journal of Software,2002,13(1):1-7(in Chinese). |
| Click to display the text | |
| [10] | Gupta H, Srivastava R.k-means based document clustering with automatic “k” selection and cluster refinement[J].International Journal of Computer Science and Mobile Applications,2014,2(5):7-13. |
| Click to display the text | |
| [11] | 李凯,李昆仑, 崔丽娟.模型聚类及在集成学习中的应用研究[J].计算机研究与发展,2007,44(z2):203-207. Li K,Li K L,Cui L J.Study of model clustering and its application to ensemble learning[J].Journal of Computer Research and Development,2007,44(z2):203-207(in Chinese). |
| Cited By in Cnki (326) | |
| [12] | Polczynski M, Polczynski M.Using the k-means clustering algorithm to classify features for choropleth maps[J].Cartographica:The International Journal for Geographic Information and Geovisualization,2014,49(1):69-75. |
| Click to display the text | |
| [13] | Coffman Jr E G, Csirik J,Galambos G,et al.Bin packing approximation algorithms:survey and classification[M].Handbook of Combinatorial Optimization.New York:Springer,2013:455-531. |
| Click to display the text | |
| [14] | Hong S, Zhang D,Lau H C,et al.A hybrid heuristic algorithm for the 2D variable-sized bin packing problem[J].European Journal of Operational Research,2014,238(1):95-103. |
| Click to display the text | |
| [15] | Wang L, Lan Y Q,Xia Q X.Using CloudSim to model and simulate cloud computing environment[C]//Computational Intelligence and Security(CIS),2013 9th International Conference on.Emeishan:IEEE,2013:323-328. |
| Click to display the text | |
| [16] | SPEC. SPECpower_ssj2008[EB/OL].Texas:Standard Performance Evaluation Corporation,2008(2013-3-21)[2014-07-04].http://www.spec.org/power/docs/SPECpower-Device_List.html. |
| Click to display the text | |
| [17] | Beloglazov A, Buyya R.Optimal online deterministic algorithms and adaptive heuristics for energy and performance efficient dynamic consolidation of virtual machines in cloud data centers[J].Concurrency and Computation:Practice and Experience,2012,24(13):1397-1420. |
| Click to display the text |
