
 , 李文超, 陈龙
, 李文超, 陈龙 东北大学秦皇岛分校 控制工程学院, 河北 秦皇岛 066004
收稿日期:2020-08-18
基金项目:河北省自然科学基金资助项目(F2019501044)。
作者简介:顾德英(1964-),男,辽宁新民人,东北大学秦皇岛分校教授。
摘要:针对低照度环境下车道线检测准确率低和稳定性差的问题, 提出了一种基于模型融合的低照度车道线检测算法.采用基于ALTM(adaptive local tone mapping)算法改进的颜色平衡算法做数据增强处理, 有利于车道线特征的提取; 融合改进的Deeplabv3+模型和Unet模型, 有效降低了过拟合现象; 使用实例分割得到分割后的车道线图像.实验证明, 改进的Unet模型和Deeplabv3+模型的mean_IOU(mean intersection-over-union)值分别达到了0.625, 0.646, 较原始模型分别提高了2%和4.6%, 最终融合结果提升了0.01%.提升了低照度环境下车道线检测的稳定性和准确性.
关键词:低照度环境车道线检测数据增强模型融合实例分割
Method of Lane Line Detection in Low Illumination Environment Based on Model Fusion
GU De-ying, WANG Na
, LI Wen-chao, CHEN Long School of Control Engineering, Northeastern University at Qinhuangdao, Qinhuangdao 066004, China
Corresponding author: WANG Na, E-mail: 1871692@stu.neu.edu.cn.
Abstract: Aiming at the problem of low accuracy and poor stability of lane line detection in low illumination environment, an algorithm of lane line detection in low illumination environment based on model fusion was proposed. The improved color balance algorithm based on ALTM(adaptive local tone mapping) algorithm is adopted for data enhancement processing, which is beneficial for the extraction of lane line features. The improved Deeplabv3+model and Unet model are fused to reduce the overfitting. The segmented lane line image is obtained by instance segmentation. The experimental results show that the mean_IOU(mean intersection-over-union) values of the improved Unet model and Deeplabv3+model reach 0.625 and 0.646, respectively, which are 2% and 4.6% higher than the original model. The final fusion result increased by 0.01%. The stability and accuracy of lane line detection are promoted in low illumination environment.
Key words: low illumination environmentlane line detectiondata enhancementmodel fusioninstance segmentation
交通环境的低照度情况会降低驾驶者识别车道线的准确度, 形成安全隐患.因此, 从当前道路图像中准确、快速地检测出车道线信息十分重要.
低照度环境下车道线检测问题, 国内外的****进行了很多相关研究, 并取得一定的研究成果[1-6].2010年, Lee等[2]提出SVLM算法, 一种局部的图像增强算法, 缺点是没有完全兼顾图像的全局信息, 对光照复杂的图像增强效果不佳.2011年, Dong等[3]提出去雾技术实现低照度图像的增强, 该算法实现了良好的视觉效果且算法效率高;缺点是场景不连续会存在块瑕疵, 该算法对暗区域增强不足, 对亮区域有过饱和现象.2013年, 韩殿元[4]提出一种改进的直方图均衡化算法, 该算法解决了传统直方图法灰度级过度合并细节易丢失的问题, 但对彩色图像会有颜色失真现象.同年, Zhou等[5]提出一种同时增强全局亮度及局部对比度的方法, 该算法有效地克服了灰度变换中自适应的问题, 但对亮度较暗的图像有待改善.2014年, 肖进胜等[6]提出一种改进的带色彩恢复的多尺度Retinex算法, 该算法可改善色彩失真、噪声放大等问题, 但算法复杂度较高, 无法应用于实时处理中.综上所述, 低照度环境下图像检测技术虽然取得了一定的成果, 但视觉系统在低照度环境下的检测性能仍被颜色失真、算法复杂度高、细节丢失等问题困扰.
为提高低照度环境下车道线检测的准确性与稳定性, 本文提出基于模型融合的低照度环境下车道线检测方法.针对光照不均、阴影遮挡等因素对算法效率的影响, 采用改进的颜色平衡算法进行数据增强, 然后利用改进的Deeplabv3+模型和Unet模型进行融合, 解决了颜色失真、算法复杂度高、细节丢失等问题, 从而提升了低照度环境下的检测准确率.
1 改进的颜色平衡算法ALTM算法[1]: 一种基于Retinex理论的高动态图像的色调映射技术.该算法由全局自适应和局部自适应组成.局部提升中采用引导滤波器替换高斯滤波器, 弱化光晕伪影影响;使用基于场景亮度值的对比度增强因子实现再现性以及动态范围的压缩;引用一种自适应非线性偏移量提升对数函数的非线性强度.其中, Retinex算法[7]是一种光照补偿的图像增强方法, 可同时实现图像的全局和局部对比度增强.该算法的本质是基于灰度假设, 但是, 均匀颜色区域违背了灰度假设理论, 所以处理后的图像存在颜色失真问题.局部提升部分实际使用中也会存在过度曝光问题.HDR[8](high-dynamic range)是同一场景中根据每一个曝光的时间点与最佳细节相对应的连续拍摄的曝光量不同的图像.虽然ALTM算法有效地改善了低光照图片的视觉效果, 但该方法耗时较长, 不适合应用于车道线实时检测系统中.
因此, 本文提出了一种改进的颜色平衡算法, 主要对RGB(red-green-blue)空间进行亮度调整, 计算出调整系数, 然后采用全局的自适应策略, 解决了低照度的车道线图像存在的低亮度、低对比度、伪影等问题.该算法有效地改善了视觉质量, 同时提升了运算速度, 原始算法最快约26 ms处理1张图片, 本文算法20 ms左右处理1张图片, 优于原始算法, 实时性分析见图 1.
图 1(Fig. 1)
 | 图 1 实时性分析Fig.1 Real time analysis |
输入图像的亮度值:
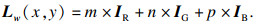 | (1) |
输入图像亮度值的最大值:
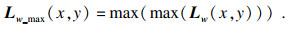 | (2) |
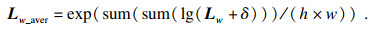 | (3) |
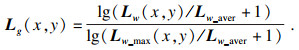 | (4) |
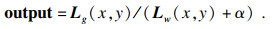 | (5) |
图 2(Fig. 2)
 | 图 2 实践效果图(前两排为处理前图像, 后两排为处理后图像)Fig.2 Practical effect figures (the first two rows are images before processing, and the last two rows are images after processing) |
2 模型融合算法原始模型采用paddle提供的Deeplabv3p模型, 并且融合了2个基于Resnet残差模块的Unet网络: Unet_base, Unet_sample, 融合后的均值交并比为0.635 47.本文基于原始模型裁减了网络, 采用改进的Deeplabv3+模型, 并且只保留一个Unet模型.融合策略采取求均值的方式, 因为深度学习在应用过程中普遍存在过拟合现象, 根本原因是训练数据量不能支撑复杂的模型, 导致模型泛化难度加大.但如果对结果取均值, 在一定程度上可以减轻过拟合现象, 进而对未知数据有更好的推广.整体网络结构图如图 3所示.
图 3(Fig. 3)
 | 图 3 整体网络结构图Fig.3 Overall network structure diagram |
2.1 改进的Deeplabv3+Chen等[9]提出Deeplabv3+模型, 通过Encoder-Decoder进行多尺度信息的融合, Encoder模块捕获高级语义信息,Decoder模块由Xception模块获得低级语义信息, 再逐渐恢复空间信息.本文精简了Deeplabv3+模型的网络结构(见图 4), 主干网络使用Xception_65模块, 有效提高了分割的速度和精度.且在原始模型中添加1个Decoder2, 将Xception_65的结果result2和Encoder的结果投入到Decoder1中, 再将Xception_65的结果result1投入到Decoder2中, 最后通过3*3卷积和上采样处理得出预测值.这样做可以将低级语义信息与高级语义信息统一处理, 更加细化低照度图像的分割结果.
图 4(Fig. 4)
 | 图 4 改进的Deeplabv3+网络结构Fig.4 Improved Deeplabv3+network structure |
2.2 改进的UnetRonneberger等[10]提出Unet网络, 基于FCN修改并扩大了网络框架, 卷积层有19个, 4次max_pool, 4次up_conv, Encoder依次降低pool层空间维度, Decoder依次恢复图像的细节和空间维度.Encoder和Decoder之间的连接用于Decoder修复细节信息.通过研究发现, 增加分支能够提高输出的分辨率.因此, 本文在Unet中融入残差网络的思想, 添加分支结构(见图 5): 对Unet的编码器部分conv0~conv3分别加入3, 4, 4, 2层卷积;对解码器部分decode1~decode 4依次加入2, 3, 3, 2层卷积, 在decode5部分引入Resize_Bilinear层.最终输入与输出分辨率相同, 实现了低照度图像的分辨率零损失.
图 5(Fig. 5)
 | 图 5 改进的Unet网络结构Fig.5 Improved Unet network structure |
3 结果及分析本次研究共采用了50 000张低照度图片做数据集, 为提升训练的可靠性, 将数据集打乱分配, 训练集占80%, 测试集占20%, 且保证每轮次的训练数据集不同, 有利于提高在实际环境中不同场景的适应能力.原始数据集中包含三个部分, 其中road 03中40%左右的图像存在曝光严重问题, 删除了该部分, 训练过程中均值交并比的值提高了0.005~0.01.选取768×256的分辨率, 训练过程采用可变学习率策略, 根据训练的实际情况对学习率的大小进行调整, mean_IOU的值提升了0.01~0.015.损失函数采用了bce+dice的方式, 这种方式比单一bce提升0.01左右.
本文依据均值交并比mean_IOU来判断最终结果是否合格.mean_IOU: 首先计算每种车道线类别的IOU, 然后计算类间平均值.交并比IOU用于计算真实和预测的相关度, 相关度越高, 该值越高.
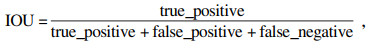 | (6) |
 | (7) |
在表 1和表 2中,bce+dice表示二分类交叉熵(binary-cross-entropy)损失函数和dice损失函数的叠加,该处理方式使图像分割更加清晰,而在表格最后一列中均值交并比的值表明,本文方法在低照度环境下不论从单一网络的成绩还是融合模型的成绩均高于原始模型.
表 1(Table 1)
| 表 1 本文模型数据记录 Table 1 Model data records in this paper |
表 2(Table 2)
| 表 2 原始模型数据记录[9-10] Table 2 Original model data records |
4 结语本文提出的数据集增强和网络优化的方法性能优于原始算法, 使用颜色均衡算法做数据增强相比于原始数据增强具有更强的判别性, 可以更好地检测、识别低照度环境下的车道线.学习率的可变性与网络的精简性可以使模型检测精度上升, 实现交并比重叠率提高, 定位效果更好, 使网络具有更强的泛化性.实验表明, 该算法有效地克服了光照不均、阴影遮挡等因素造成的检测困难, 基本解决了颜色失真、算法复杂度高、细节丢失等问题, 明显提升了低照度环境下的检测准确率.
参考文献
| [1] | Ahn H, Keum B, Kim D, et al.Adaptive local tone mapping based on Retinex for high dynamic range images[C]//IEEE International Conference on Consumer Electronics.Las Vegas, NV: IEEE, 2013: 153-156. |
| [2] | Lee S, Kwon H, Han H, et al. A space-variant luminance map based color image enhancement[J]. IEEE Transaction on Consumer Electronics, 2010, 56(4): 2636-2643. DOI:10.1109/TCE.2010.5681151 |
| [3] | Dong X, Wang G, Pang Y, et al.Fast efficient algorithm for enhancement of low lighting video [C]//IEEE International Conference on Multimedia and Expo.Barcelona: IEEE, 2011: 1-6. |
| [4] | 韩殿元. 低照度下视频图像保细节直方图均衡化方法[J]. 计算机仿真, 2013, 30(8): 233-236. (Han Dian-yuan. Videoimage detail preserving histogram equalization method under low illumination[J]. Computer Simulation, 2013, 30(8): 233-236.) |
| [5] | Zhou Z G, Sang N, Hu X R. Global brightness and local contrast adaptive enhancement for low illumination color image[J]. Optik-International Journal for Light and Electron Optics, 2014, 125(6): 1795-1799. DOI:10.1016/j.ijleo.2013.09.051 |
| [6] | 肖进胜, 单姗姗, 段鹏飞, 等. 基于不同色彩空间融合的快速图像增强算法[J]. 自动化学报, 2014, 40(4): 697-705. (Xiao Jin-sheng, Shan Shan-shan, Duan Peng-fei, et al. Fast image enhancement algorithm based on different color space fusion[J]. Acta Automata Sinica, 2014, 40(4): 697-705.) |
| [7] | 李武劲, 彭怡书, 欧先锋, 等. 基于改进Retinex算法的低照度图像增强方法[J]. 成都工业学院学报, 2020, 23(2): 20-25. (Li Wu-jin, Peng Yi-shu, Ou Xian-feng, et al. Low illumination image enhancement method based on improved Retinex algorithm[J]. Journal of Chengdu University of Technology, 2020, 23(2): 20-25.) |
| [8] | Stathaki T. Image fusion algorithms and applications[M]. New York: Academic Press, 2008: 1-520. |
| [9] | Chen L C, Zhu Y K, Papandreou G, et al.Encoder-decoder with atrous separable convolution for semantic image segmentation [C]//European Conference on Computer Vision.Munich, 2018: 833-851. |
| [10] | Ronneberger O, Philipp F, Thomas B.U-Net: convolutional networks for biomedical image segmentation[C]//Medical Munich: Image Computing and Computer Assisted Intervention.Munich: Springer, Cham, 2015: 234-241. |
