| |
|
| 基于高层信息特征的重叠语音检测 |
| 马勇1,2, 鲍长春1 |
1. 北京工业大学 电子信息与控制工程学院, 北京 100124;
2. 江苏师范大学 物理与电子工程学院, 徐州 221009 |
|
| Overlapping speech detection using high-level information features |
| MA Yong1,2, BAO Changchun1 |
1. School of Electronic Information and Control Engineering, Beijing University of Technology, Beijing 100124, China;
2. School of Physics and Electronic Engineering, Jiangsu Normal University, Xuzhou 221009, China |
| |
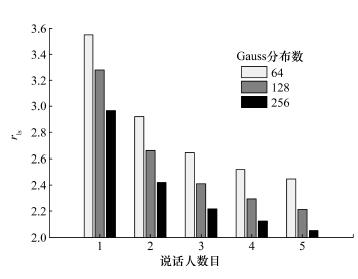
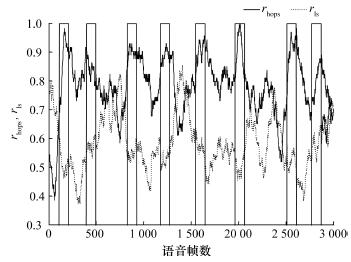
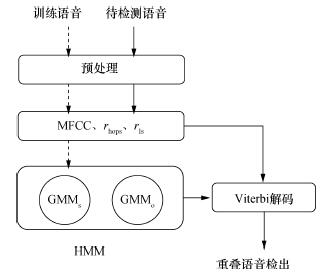
| 摘要重叠语音是影响说话人分割性能的主要因素之一。该文提出了基于语音高层信息特征的重叠语音检测方法以提高说话人分割效果。首先用通用背景模型(universal background model,UBM)提取语音的语言学高层信息特征,并融合这些特征和Mel频率倒谱系数(Mel frequency cepstral coefficient,MFCC)特征建立隐Markov模型(hidden Markov model,HMM)检测重叠语音,然后对处理后的语音进行说话人分割。实验结果表明:对于由TIMIT语音库生成的数据集,该方法对重叠语音检测的错误率比单一采用MFCC特征有显著降低,而且说话人分割性能有明显的提高。 |
| 关键词 :重叠语音检测,高层信息特征,说话人分割 |
| Abstract:Overlapping speech is one of the main factors influencing the performance of speaker segmentation. This paper presents an overlapping speech detection method using a high-level information feature to improve the speaker segmentation results. A linguistic high-level information feature of the speech is extracted using the universal background model (UBM). Then, a hidden Markov model (HMM) is trained using the Mel frequency cepstral coefficients (MFCC) and the high-level information to detect overlapping speech. The result is then used for the speaker segmentation of the pre-processed speech. Tests on a dataset generated from the TIMIT database show that the error ratio for overlapping speech detection is significantly lower than the reference method using just the MFCC feature. The speaker segmentation is also significantly improved. |
| Key words:overlapping speech detectionhigh-level information featurespeaker segmentation |
| 收稿日期: 2016-06-18 出版日期: 2017-01-20 |
|
| 通讯作者:鲍长春,教授,E-mail:baochch@bjut.edu.cnE-mail: baochch@bjut.edu.cn |
| [1] | Shriberg E, Stolcker A, Baron D. Observations on overlap:Finding and implications for automatic processing of multi-party conversation[C]//Proc 7th European Conference on Speech Communication and Technology. Aalborg, Denmark:ISCA, 2001:1359-1362. |
| [2] | Sinclair M, King S. Where are the challenges in speaker diarization[C]//Proc International Conference on Acoustics, Speech, Signal and Signal Processing. Vancouver, Canada:IEEE, 2013:7741-7745. |
| [3] | 马勇, 鲍长春. 说话人分割聚类研究进展[J]. 信号处理, 2013, 29(9):1190-1199.MA Yong, BAO Changchun. Advance in speaker segmentation and clustering[J]. Journal of Signal Processing, 2013, 29(9):1190-1199. (in Chinese). |
| [4] | Kotti M, Moschou V, Kotropoulos C. Speaker segmentation and clustering[J]. Signal Processing, 2008. 88(5):1091-1124. |
| [5] | Otterson S, Ostendorf M. Efficient use of overlap information in speaker diarization[C]//Proc Conference Automatic Speech Recognition & Understanding, Kyoto, Japan:IEEE, 2007:683-686. |
| [6] | Roakye K, Hornero B, Vinyals O, et al. Overlapped speech detection for improved diarization in multi-party meetings[C]//Proc International Conference on Acoustics, Speech, Signal and Signal Processing. Las Vegas, NV, USA:IEEE, 2008:4353-4356. |
| [7] | Roakye K, Vinyals O, Friedland G. Improved overlapped speech handling for speaker diarization[C]//Proc International Speech Communication Association. Florence, Italy:ISCA, 2011:941-944. |
| [8] | Zelenak M, Segura C, Luque J, et al, Simultaneous speech detection with spatial features for speaker diarization[J]. IEEE Transaction on Audio, Speech and Language Processing, 2012, 20(2):436-446. |
| [9] | Geiger J T, Eyben F, Evans N, et al. Using linguistic information to detect overlapping speech[C]//Proc International Speech Communication Association. Lyon, France:ISCA, 2013:941-944. |
| [10] | Yella S H, Bourlard H. Overlapping speech detection using long-term conversational features for speaker diarization in meeting room conversations[J]. IEEE Transaction on Audio, Speech and Language Processing, 2014, 22(12):1688-1700. |
| [11] | Reynolds D, Quatieri T, Dunn R. Speaker verification using adapted Gaussian mixture models[J]. Digital Signal Processing, 2000, 10(1):19-41. |
| [12] | Delacourt P, Wellekens C J. DISTBIC:A speaker-based segmentation for audio data indexing[J]. Speech Communication, 2000, 32(1):111-126. |
| [1] | 张鹏远, 计哲, 侯炜, 金鑫, 韩卫生. 小资源下语音识别算法设计与优化[J]. 清华大学学报(自然科学版), 2017, 57(2): 147-152. | | [2] | 解焱陆, 张蓓, 张劲松. 基于音高映射合成语音的汉语双字调声调训练[J]. 清华大学学报(自然科学版), 2017, 57(2): 170-175. | | [3] | 王建荣, 张句, 路文焕, 魏建国, 党建武. 机器人自身噪声环境下的自动语音识别[J]. 清华大学学报(自然科学版), 2017, 57(2): 153-157. | | [4] | 张劲松, 王祖燕. 元音部分对中日被试汉语普通话鼻韵母知觉的影响[J]. 清华大学学报(自然科学版), 2017, 57(2): 164-169. | | [5] | 高莹莹, 朱维彬. 面向情感语音合成的言语情感描述与预测[J]. 清华大学学报(自然科学版), 2017, 57(2): 202-207. | | [6] | 李煦, 屠明, 吴超, 国雁萌, 纳跃跃, 付强, 颜永红. 基于NMF和FCRF的单通道语音分离[J]. 清华大学学报(自然科学版), 2017, 57(1): 84-88. | | [7] | 陈萧, 徐波. 改进的用于口语处理的基频提取算法[J]. 清华大学学报(自然科学版), 2017, 57(1): 95-99. | | [8] | 宋鹏, 郑文明, 赵力. 基于特征迁移学习方法的跨库语音情感识别[J]. 清华大学学报(自然科学版), 2016, 56(11): 1179-1183. | | [9] | 郭武, 马啸空. 复杂噪声场景下的活动语音检测方法[J]. 清华大学学报(自然科学版), 2016, 56(11): 1190-1195. | | [10] | 梁维谦, 郑方, 郑佳春, 朴志刚. 一种改善言语清晰度的子带自适应降噪算法[J]. 清华大学学报(自然科学版), 2016, 56(11): 1173-1178. | | [11] | 邢安昊, 张鹏远, 潘接林, 颜永红. 基于SVD的DNN裁剪方法和重训练[J]. 清华大学学报(自然科学版), 2016, 56(7): 772-776. | | [12] | 李海峰, 房春英, 马琳, 张满彩, 孙佳音. 病理语音的S变换特征[J]. 清华大学学报(自然科学版), 2016, 56(7): 765-771. | | [13] | 徐敬德, 崔慧娟, 唐昆. 结合信源和信道的多级矢量量化联合优化算法[J]. 清华大学学报(自然科学版), 2015, 55(8): 826-830. |
|