| 基于DTW的语音关键词检出 |
| 侯靖勇1, 谢磊1, 杨鹏1, 肖雄2, 梁祥智3, 徐海华2, 王磊3, 吕航1, 马斌3, CHNG EngSiong2,4, 李海洲2,3,4 |
| 1. 西北工业大学 计算机学院, 陕西省语音与图像信息处理重点实验室, 西安 710129, 中国; 2. 南洋理工大学 Temasek实验室, 新加坡; 3. 新加坡科技局 资讯通信研究院, 人类语言技术部, 新加坡; 4. 南洋理工大学 计算机工程学院, 新加坡 |
| Spoken term detection based on DTW |
| HOU Jingyong1, XIE Lei1, YANG Peng1, XIAO Xiong2, LEUNG Cheung-Chi3, XU Haihua2, WANG Lei3, LV Hang1, MA Bin3, CHNG EngSiong2,4, LI Haizhou2,3,4 |
| 1. Shaanxi Provincial Key Laboratory of Speech and Image Information Processing(SAIIP), School of Computer Science, Northwestern Polytechnical University, Xi'an 710129, China; 2. Temasek Lab, Nanyang Technological University, Singapore; 3. Institute for Infocomm Research, A*STAR, Singapore; 4. School of Computer Engineering, Nanyang Technological University, Singapore |
摘要:
| |||
| 摘要针对少资源语言的语音关键词检出技术受到了广泛关注。该文在基于动态时间规整(dynamic time warping,DTW)的关键词检出框架下,提出了基于音素边界的局部匹配策略,用以解决基于样例的语音关键词检出任务中的近似查询问题。在QUESST 2014评测数据上采用多种特征进行了实验验证。实验结果显示:基于音素边界的局部匹配策略不仅在近似查询T2和T3任务上的检出效果明显提升,在精确查询T1任务上也获得了有效提升。随后的系统融合实验表明,该策略能够大幅提升融合系统的性能。 | |||
| 关键词 :语音关键词检出,少资源语言,动态时间规整,局部匹配 | |||
| Abstract:Spoken term detection (STD) for low resource languages has drawn much interest. A partial matching strategy based on phoneme boundaries is presented here to solve the fuzzy matching problem in query-by-example spoken term detection with dynamic time warping. A variety of features were used to validate the strategy on the QUESST 2014 dataset. Tests show that this strategy is not only quite effective for fuzzy match tasks T2 and T3 but also effective for the exact match task T1. This strategy has significantly improved performance in fusion tests. | |||
| Key words:spoken term detectionlow resource languagesdynamic time warpingpartial matching | |||
| 收稿日期: 2016-06-25 出版日期: 2017-01-20 | |||
| |||
| 通讯作者:谢磊,教授,E-mail:lxie@nwpu.edu.cnE-mail: lxie@nwpu.edu.cn | |||
| 引用本文: |
| 侯靖勇, 谢磊, 杨鹏, 肖雄, 梁祥智, 徐海华, 王磊, 吕航, 马斌, CHNG EngSiong, 李海洲. 基于DTW的语音关键词检出[J]. 清华大学学报(自然科学版), 2017, 57(1): 18-23. HOU Jingyong, XIE Lei, YANG Peng, XIAO Xiong, LEUNG Cheung-Chi, XU Haihua, WANG Lei, LV Hang, MA Bin, CHNG EngSiong, LI Haizhou. Spoken term detection based on DTW. Journal of Tsinghua University(Science and Technology), 2017, 57(1): 18-23. |
| 链接本文: |
| http://jst.tsinghuajournals.com/CN/10.16511/j.cnki.qhdxxb.2017.21.004或 http://jst.tsinghuajournals.com/CN/Y2017/V57/I1/18 |
图表:
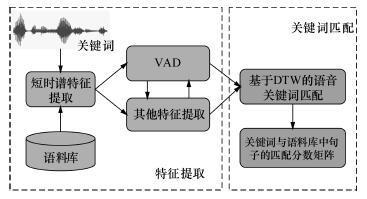 |
| 图1 关键词检出系统框架 |
 |
| 图2 普通全匹配SLN-DTW 算法示意图 |
 |
| 图3 基于边界的局部匹配SLN-DTW 算法示意图 |
 |
| 表1 全匹配、基于滑动固定窗的局部匹配、基于音素边界的局部匹配在QUESST任务的发展集和评估集上的结果 |
 |
| 表2 DTW融合系统与SS融合系统在评估集数据的对比 |
 |
| 表3 最终融合系统与BUT系统、SPL-IT系统在评估集数据的对比 |
参考文献:
| [1] | Mary P. Intelligence advanced research projects activity (IARPA)[Z/OL].[2015-03-20] http://www.iarpa.gov/index.php/research-programs/babel. |
| [2] | NIST. OpenKWS14 keyword search evaluation plan[Z/OL].[2015-03-20]. http://nist.gov/itl/iad/mig/upload/KWS14-evalplan-v11.pdf. |
| [3] | Tejedor J, Fapšo M, Sz ke I, et al. Comparison of methods for language-dependent and language-independent query-by-example spoken term detection[J].ACM Transactions on Information Systems, 2012,30(3):2317-2318. |
| [4] | 杨鹏, 谢磊, 张艳宁. 低资源语言的无监督语音关键词检测技术综述[J]. 中国图象图形学报, 2015,20(2):0211-0218.YANG Peng, XIE Lei, ZHANG Yanning. Survey on unsupervised spoken term detection for low-resource languages[J].Journal of Image and Graphics, 2015,20(2):0211-0218. (in Chinese) |
| [5] | Xu H, Yang P, Xiao X, et al. Language independent query-by-example spoken term detection using n-best phone sequences and partial matching[C]//2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) Proceedings. Brisbane, QLD, Australia:IEEE Press, 2015:5191-5195. |
| [6] | Yang P, Xu H, Xiao X, et al. The NNI query-by-example system for MediaEval 2014[C]//Working Notes Proceedings of the MediaEval 2014 Workshop. Barcelona, Spain:CEUR-WS, 2014, 1263. |
| [7] | Yang P, Leung C C, Xie L, et al. Intrinsic spectral analysis based on temporal context features for query-by-example spoken term detection[C]//INTERSPEECH 2014 Proceedings. Singapore:IEEE, 2014:1722-1726. |
| [8] | Zhang Y, Glass J R. Unsupervised spoken keyword spotting via segmental DTW on Gaussian posteriorgrams[C]//Proceedings of the 2009 IEEE Workshop on Automatic Speech Recognition and Understanding. Merano, Italy:IEEE, 2009:398-403. |
| [9] | Anguera X, Rodriguez-Fuentes L J, Sz ke I, et al. Query by example search on speech at MediaEval 2014[C]//Working Notes Proceedings of the MediaEval 2014 Workshop. Barcelona, Spain:CEUR-WS, 2014, 1263. |
| [10] | Sz ke I, Skácel M, Burget L. BUT QUESST 2014 system description[C]//Working Notes Proceedings of the MediaEval 2014 Workshop. Barcelona, Spain:CEUR-WS, 2014, 1263. |
| [11] | 张卫强, 宋贝利, 蔡猛, 等. 基于音素后验概率的样例关键词检测算法[J]. 天津大学学报:自然科学与工程技术版, 2015,48(9):757-760.ZHANG Weiqiang, SONG Beili, CAI Meng, et al. A query-by-example spoken term detection method based on phonetic posteriorgram[J].Journal of Tianjin University Science and Technology, 2015,48(9):757-760. (in Chinese) |
| [12] | Proença J, Veiga A, Perdigão F. The SPL-IT query by example search on speech system for MediaEval 2014[C]//Working Notes Proceedings of the MediaEval 2014 Workshop. Barcelona, Spain:CEUR-WS, 2014. |
| [13] | Müller M. Information Retrieval for Music and Motion[M]. Berlin:Springer, 2007. |
| [14] | Anguera X. Speaker independent discriminant feature extraction for acoustic pattern-matching[C]//2012 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2012) Proceedings. Kyoto, Japan:IEEE Press, 2012:485-488. |
| [15] | Muscariello A, Gravier G, Bimbot F. Audio keyword extraction by unsupervised word discovery[C]//Proceedings of the 10th Annual Conference of the International Speech Communication Association, INTERSPEECH 2009. Brighton, UK:IEEE Press. 2009:2843-2846. |
| [16] | Schwarz P, Matejka P, Cernocky J. Hierarchical structures of neural networks for phoneme recognition[C]//2006 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2006. Toulouse, France:IEEE Press, 2006:I325-I328. |
| [17] | Wang H, Lee T, Leung C C. Unsupervised spoken term detection with acoustic segment model[C]//14th Annual International Conference on Speech Database and Assessments, Oriental COCOSDA 2011. Hsinchu, Taiwan, China:IEEE Press, 2011:106-111. |
| [18] | Wang H, Lee T, Leung C C, et al. A graph-based Gaussian component clustering approach to unsupervised acoustic modeling[C]//INTERSPEECH 2014. Singapore:IEEE Press, 2014:875-879. |
| [19] | Zhang Y, Chuangsuwanich E, Glass J R. Extracting deep neural network bottleneck features using low-rank matrix factorization[C]//2014 IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2014. Florence, Italy:IEEE Press, 2014:185-189. |
| [20] | Gupta V, Ajmera J, Kumar A, et al. A language independent approach to audio search[C]//Conference of the International Speech Communication Association (ICASSP) Proceedings. Florence, Italy:IEEE Press, 2011:1125-1128. |
| [21] | Rodriguez-Fuentes L J, Penagarikano M. MediaEval 2013 spoken web search task:system performance measures[Z/OL].[2015-03-20]. http://gtts.ehu.es/gtts/NT/fulltext/rodriguezmediaeval13.pdf. |
| [22] | Fiscus J G, Ajot J, Garofolo J S, et al. Results of the 2006 spoken term detection evaluation[C]//Proc SIGIR 2007. Amsterdam, Netherlands:ACM, 2007:51-57. |
相关文章:
| ||
