
 , 汪嘉杨, 徐源蔚
, 汪嘉杨, 徐源蔚成都信息工程大学, 资源环境学院, 成都 610225
收稿日期: 2017-07-03; 修回日期: 2017-10-15; 录用日期: 2017-10-15
基金项目: 国家自然科学基金(No.51679155)
作者简介: 李祚泳(1944-), 男, 教授, E-mail:lizuoyong@cuit.edu.cn
通讯作者(责任作者): 李祚泳, E-mail:lizuoyong@cuit.edu.cn
摘要: 为了建立不同环境系统皆能规范、统一、简洁、实用的回归支持向量机预测模型,针对传统的回归支持向量机预测模型存在结构不能普适、规范和统一及用于大样本、多因子预测会出现学习效率低、求解精度差的局限,提出适用于环境系统预测量及其影响因子参照值和规范变换式的设计原则和方法,使规范变换后的影响因子皆"等效"于同一个规范影响因子;为提高样本的预测精度,还提出预测样本的模型输出的误差修正法.在对环境系统的预测量及其影响因子进行规范变换的基础上,由有m个规范影响因子的每个建模样本生成m个"等效"训练样本,从建模样本中,选择各影响因子的最大规范值组成训练样本集的"参考样本",计算核函数中每个训练样本相对于"参考样本"的范数;并应用优化算法优化模型参数,建立适用于预测量及其影响因子规范值的仅有2个或3个支持向量的两种简单结构的回归支持向量机预测模型.将基于规范变换的两种简单结构的回归支持向量机模型与相似样本误差修正法相结合,用于河津大桥监测断面6个样本的COD月平均值预测,并与多种传统预测模型和方法进行了比较.结果表明:对同一个预测样本,两种模型的预测值十分接近;此外,两种预测模型用于6个样本预测,其相对误差绝对值的平均值分别为2.09%、2.79%,均远小于传统的投影寻踪回归预测的41.63%、支持向量机预测的40.99%、灰色神经网络预测的25.94%和马尔可夫预测的10.16%;而两种预测模型对异常样本预测的最大的相对误差绝对值分别为5.85%、5.13%,更加远远小于传统的4种预测模型的169.07%、180.45%、68.44%、41.96%.两种基于规范变换的回归支持向量机预测模型简洁、普适、规范和统一,避免了"大样本数困难",提高了学习效率和模型的预测精确度,对其他预测建模法也有借鉴作用.
关键词:环境系统规范变换预测模型回归支持向量机核函数
Environmental system prediction using regression support vector machines based on standard transformation and error correction
LI Zuoyong
, WANG Jiayang, XU Yuanwei College of Resources Environment, Chengdu University of Information Technology, Chengdu 610225
Received 3 July 2017; received in revised from 15 October 2017; accepted 15 October 2017
Supported by the National Natural Science Foundation of China (No. 51679155)
Biography: LI Zuoyong(1944—), male, professor, E-mail: lizuoyong@cuit.edu.cn
*Corresponding author: LI Zuoyong, E-mail:lizuoyong@cuit.edu.cn
Abstract: The purpose of this study was to build a universal, normative, simple and unified model of regression support vector machines, which can meet environment system predictions. The predictive model of traditional regression support vector machines has limits, which of the structure can not be universal, standardized and unified, the learning efficiency is low and the solution accuracy is poor for large sample and multi factor prediction. Therefore, the design principles and methods of reference values and the gauge transformation formula were proposed for predicting variable and its influencing factors of environment system, it makes all of the normalized influencing factors equivalent to the same normative influence factor. Furthermore, in order to improve the prediction accuracy of samples, an error correction method was also proposed for the model output of the predicted samples. On the basis of gauge transformations for the predictive variable and its influencing factors of environment system, each modeling sample with m canonical influence factors formed m training samples. Furthermore, from the modeling samples, the maximum values of the normative values of each influence factor was selected as the "reference sample" of the training sample set, and the norms of each training sample in a kernel function relative to the "reference sample" were calculated. Then, the optimization algorithm was used to optimize the model parameters, two types of NV-SVR models for environment system prediction were built:the NV-SVR(2), which was suitable for the case involved any 2 support vectors and the NV-SVR (3), which was suitable for the case involved 3 support vectors. The regression support vector machine models of two simple structures based on normative canonical transformation, which were combined with the error correction method of similar samples, were used to predict the average monthly COD of 6 samples in Hejin bridge monitoring section, and were compared with a variety of traditional forecasting models and methods. The results show that for the same forecast sample, the predicted values of the two models are very close. In addition, two prediction models were used for the prediction of 6 samples, and the average values of relative error absolute values were 2.09% and 2.79% respectively, were far less than 41.63%, 40.99%, 25.94% and 10.16% of the prediction models of traditional projection pursuit regression, support vector machine, grey neural network and Markov respectively. The maximum relative error absolute values of the two prediction models for abnormal samples were 5.85% and 5.13% respectively, much smaller than 169.07%, 180.45%, 68.44% and 41.96% of the traditional 4 prediction models, respectively. Two types of NV-SVR, which avoid the difficulties of large sample size, improve learning efficiency and forecasting accuracy of models, are simple, universal, standard and unified. The two models are also useful for other prediction modeling and methods.
Key words: environment systemnormative transformationprediction modelregression support vector machineskernel function
1 引言(Introduction)众所周知, 人类赖以生存的环境的现状和未来关系到人类的生存和发展, 关系到社会的文明和整体的和谐.但调查显示:依据国家空气质量新标准, 我国2013年监测的74个城市中, 只有3个城市空气质量达标;118个城市地下水监测数据基本清洁的只占3%;国家地表水监测断面中, Ⅳ ~Ⅴ类和劣Ⅴ类水质占比超过60%.可见, 我国环境质量的现状不容乐观, 而且环境状况还有不断恶化的趋势.因此, 我们迫切需要掌握环境污染现状及未来发展趋势, 保护、管理和规划好我们的生存环境空间.为此, 需要建立能用于环境预测的数学模型.不过, 预测建模尤其是较多影响因子的预测建模远比评价建模复杂.这是因为:首先评价通常是静态的;而预测是动态的.其次, 评价只需依据制订的指标评价分级标准, 对评价对象的状态作出判断, 评判结果容易满足实况;而预测需要由系统的状态变量的过去和现状的已有资料, 预测变量的未来变化趋势, 预测结果要求精准、可信, 但由于预测变量往往受多种复杂因素的影响, 其预测结果常常难以满足实际需要稳定的预测精度.
多年来, 国内外****提出了可变集合(Chen et al., 2013)、集对分析(金菊良等, 2009)、Copul函数(陈晶等, 2015)、分段线性表示KNN算法(王保良等, 2016)及其他多种预测的模型和方法(黄思等, 2015;Thoe et al., 2012).其中BP神经网络(Palani et al., 2008;Liu et al., 2014;陈媛等, 2010;金菊良等, 2015;胡健伟等, 2015)、投影寻踪(PP)(Xiaoni et al., 2008;冯兆澍, 2015)和支持向量机(SVM)(Liu et al., 2013;Tan et al., 2012; Moura et al., 2011;崔东文等, 2016)等模型是最常用的预测模型.但BP网络预测模型存在过拟合、学习效率低和易陷入局部极值的缺陷(Wang et al., 2004);传统的投影寻踪回归预测模型的编程和计算难度随影响因子数的增加而迅速增长, 存在“维数灾难”;此外, BP神经网络隐层节点数的选择和投影寻踪岭函数个数的选择, 均依赖设计者的经验和先验知识, 使用不便.
与BP神经网络、投影寻踪模型相比, 虽然回归支持向量机模型(support vector regression, SVR)能使经验风险和置信范围同时最小, 具有泛化能力好和不受高维、非线性和小样本数的限制, 克服了维数祸根, 在有限样本情况下, 理论上也能获得最优解(Noori et al., 2012).但模型结构和计算的复杂性随样本数n和影响因子数m的增加而迅速增大, 同样存在算法编程复杂、运算量大、收敛速度过慢及全局最优解仍依赖部分参数的初始范围设置, 因而实用性亦受限.虽然有****提出了SVR模型的改进预测建模法(笪英云等, 2015), 在给出预测的同时给出预测的置信区间.不过, 对复杂的预测问题, 模型的预测精度尤其是对异常样本的预测精度仍不高, 而且对不同样本数和因子数的建模, 不能规范和统一.因此, 建立适用于多因子和大样本的环境系统预测的普适、规范、简洁、实用的SVR模型具有十分重要的理论意义和实用价值.为此, 若适当设置环境系统的预测量及其影响因子的参照值和规范变换式, 并对它们的原始数据进行规范变换, 使规范变换后的所有影响因子皆“等效”于同一个规范影响因子, 将任意多个因子和任意多个样本的SVR预测建模问题简化为仅是对“等效”规范因子的简单2维(或3维)预测建模问题, 从而使传统SVR预测模型结构得到极大简化.进一步将规范变换的SVR预测模型与相似样本模型输出的误差修正法相结合, 应用于河津大桥监测断面的COD月平均预测.结果表明:基于规范变换与误差修正的的SVR模型不仅避免了“大样本数困难”, 提高了学习效率, 而且对样本预测的相对误差绝对值的平均值和最大的相对误差绝对值, 都远小于传统的投影寻踪回归(PPR)模型、传统SVR模型、灰色神经网络模型和马尔可夫等多种预测模型的预测结果, 尤其能极大地提高异常样本的预测精确度.
2 预测量及其影响因子的规范变换(Canonical transformations of predictive variables and their influencing factors)为了建立不同影响因子都能规范、统一的环境系统预测模型(为叙述简便, 以下将“影响因子”简称“因子), 只需对环境系统样本预测量及其因子的原始数据, 采用如式(1)和式(2)所示的规范变换, 使满足变换后的建模样本预测量及各因子的最小规范值xjm′(或 yjm′)和最大规范值xjM′(或 yjM′)分别被限定在[0.10, 0.24]和[0.40, 0.55]较小范围内, 因而用式(1)和式(2)规范变换后的m个因子皆可视为与某一个规范因子“等效”.可见, 规范变换的目的为:借助规范变换, 将m个多因子的n个样本的复杂高维建模问题转化为“等效”规范因子的(n × m)个样本的简单低维建模问题.
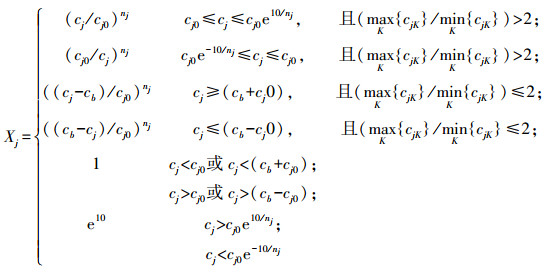 | (1) |
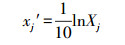 | (2) |
在初步确定nj的基础上设定cj0, 若能使由式(1)和式(2)计算得到的因子(或预测量)的最小值的规范值xjm′(或yjm′)和因子j(或预测量)的最大值的规范值xjM′(或yjM′)能分别被限定在[0.10, 0.24]和[0.40, 0.55]范围内, 则cj0被确定;否则, 需对初步设定的cj0作适当调整, 直至因子(或预测量)的最小规范值和最大规范值满足上述要求为止.在满足上述条件下, cj0应尽可能设置为简洁美观、计算简便的实数.
3 适用于规范变换的环境系统预测的回归支持向量机模型(Regression support vector machine model for prediction of environmental systems with canonical transformations)3.1 回归支持向量机模型的基本形式线性化是解决非线性复杂问题的一种常用手段.回归支持向量机的基本思想是:将样本空间训练数据集非线性映射到一个高维乃至无穷维的特征空间(Hilbert空间), 用在高维特征空间中得到问题的线性解去“等效”原样本空间中问题的非线性解.将其用于函数逼近的最大特点是:在实际求解过程中, 只需适当选用一个核函数k(xi, xj) “等效”替代内积运算, 从而极大地简化了计算.样本i的回归支持向量机(SVR)模型的计算输出yi如式(3)所示(李祚泳等, 2013).
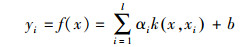 | (3) |
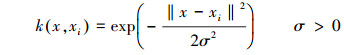 | (4) |
3.2 环境系统预测的回归支持向量机建模① 目标函数式的设计
为了优化SVR模型(式(3)), 需设计如式(5)所示的优化目标函数式(李祚泳等, 2016).
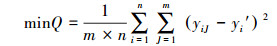 | (5) |
② 分别构建具有2个和3个支持向量的NV-SVR预测模型.
训练样本的组成:欲建立适用于m个规范因子的n个建模样本的回归支持向量机(normalized value support vector regression, NV-SVR)预测模型, 由于规范变换后的m个因子“等效”于同一个规范因子, 因此, 具有m(j=1, 2, ……, m)个规范因子的n(i=1, 2, ……, n)个样本的NV-SVR预测建模可转化为“等效”规范因子的m×n个训练样本的NV-SVR预测建模问题.若将规范变换后的第i个建模样本的第1个和第2个规范因子, 第2个和第3个规范因子, ……, 第m个和第1个规范因子分别组成NV-SVR预测模型的m个训练样本;类似, 将规范变换后的第i个建模样本的第1个、第2个和第3个规范因子, 第2个、第3个和第4个规范因子, ……, 第m个、第1个和第2个规范因子分别组成NV-SVR预测模型的m个训练样本.两种情况皆是m个规范因子的n个建模样本组成NV-SVR模型的m×n个训练样, 而且, 由同一个建模样本i所组成的m个训练样本皆对应于该建模样本预测变量的同一个规范值yi′.此外, 若再以n个样本各因子的最大规范值xjM′组成NV-SVR模型核函数中的恒定中心矢量, 则由同一个建模样本组成的m个训练样本与恒定中心矢量构成的样本之间的范数值差异较小, 而不同建模样本的m个训练样本与恒定中心矢量构成的样本之间的范数值差异则可能较大.在满足优化目标函数式(5)条件下, 依据 N=m×n个训练样本, 应用优化算法对NV-SVR模型表示式(3)中参数优化, 分别可得优化后对m×n个训练样本(亦即m个因子的n个建模样本)都适用的由2个支持向量构成的NV-SVR(2)模型及由3个支持向量构成的NV-SVR(3)模型.
NV-SVR预测模型的输出式:为了优化具有2个和3个支持向量的NV-SVR模型的αi、核参数σ和常参数b, 在满足优化目标函数式(5)条件下, 将上述各自生成的N=m×n个训练样本分别代入有2个或3个支持向量的NV-SVR模型计算式(3), 用优化算法对αi、σ和b反复迭代优化.当优化目标函数式(5)不再减小或满足预先设置的精度要求时, 停止迭代, 得到优化后适用于影响因子规范值的具有2个和3个支持向量的NV-SVR(2)和NV-SVR(3)预测模型, 分别如式(6)、(7)所示.
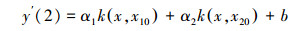 | (6) |
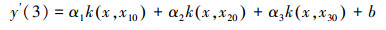 | (7) |
3.3 NV-SVR预测模型的可靠性分析由于环境系统的NV-SVR预测模型都是构筑在若干参数基础上的, 这些参数又是依据模型影响因子的输入数据cj及其预测变量的输出数据来确定的.而获得的输入、输出数据具有的误差必然导致预测模型的参数估计存在一定的不确定性, 这些不确定性对NV-SVR模型预测结果有一定的影响, 其影响程度(模型的可靠性)可以通过对模型核函数的输出k的灵敏度分析予以确定(郑彤等, 2003).灵敏度通常是指一个系统的输出对于该系统的输入的响应程度.(郑彤等, 2003).据此灵敏度定义, 影响因子值的相对误差Δcj/cj与核函数输出k的相对误差Δk/k之间有如下关系.
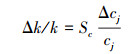 | (8) |
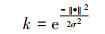 | (9) |
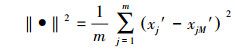 | (10) |
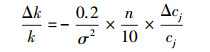 | (11) |
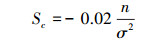 | (12) |
3.4 预测样本模型输出的误差修正法为使预测样本尤其是异常预测样本(或检测样本)的预测(或检测)值更接近实际值, 某些情况下需对预测(或检测)样本的模型输出值进行误差修正.其基本思想和方法为:依据相似原因产生相似结果的原则(金菊良等, 2009), 从建模样本集中, 找出与预测(或检测)样本x的模型输出值yx′最接近的一个或多个相似样本的模型输出值ys′及拟合相对误差rs′;并按照比例基本定理, 用比例计算公式(13)计算出预测(或检测)样本x的模型输出值yx的估计相对误差rx′;再由式(14)计算预测(或检测)样本x修正后的模型输出值yxr′;最后, 由规范变换式(1)和(2)的逆运算, 计算预测(或检测)样本x的预测值yx.
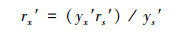 | (13) |
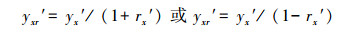 | (14) |
① 依据规范变换式的设计原则和方法, 设置规范变换式对预测量及其影响因子进行规范变换;
② 以各影响因子的最大规范值组成样本集的“参考样本”, 计算核函数中每个样本与“参考样本”之间的欧氏距离(均方根距离)范数;
③ 优化建立仅以2个或3个核函数为基函数(即支持向量)的简单的NV-SVR预测模型(类似于建立以核函数为自变量的二元或三元回归方程);
④ 为提高预测样本尤其是异常预测样本的预测精度, 用相似误差修正法(四则运算)对预测样本模型输出值进行误差修正;
⑤ 最后由规范变换式的逆运算, 计算出预测样本值.
4 基于NV-SVR模型的河津大桥监测断面COD预测(Prediction of COD in monitoring section of Hejin Bridge based on NV-SVR model)4.1 预测量COD及其影响因子的参照值和变换式河津大桥监测断面2005—2010年枯水期月平均COD(y)及关联度高的水温(x1)、BOD5(x2)、NH3-N(x3)、挥发酚(x4)4个因子的监测数据, 见表 1(薛鹏松等, 2012).依据规范变换式的设计原则和方法, 设置如式(15)所示的变换式, 由式(15)和式(2)计算出COD的规范值yi′及各因子的规范值xi′.其中, COD的规范值 yi′如表 1所示.
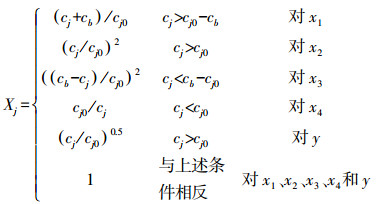 | (15) |
| 表 1 河津大桥监测断面的地表水中因子的监测数据、COD及规范值和模型输出值及相对误差绝对值 Table 1 Monitoring data and normalized values of COD and factors of surface water in monitoring section of Hejin Bridge as well as model output values and relative error absolute values | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
表 1 河津大桥监测断面的地表水中因子的监测数据、COD及规范值和模型输出值及相对误差绝对值 Table 1 Monitoring data and normalized values of COD and factors of surface water in monitoring section of Hejin Bridge as well as model output values and relative error absolute values
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
式中, y和x1、x2、x3、x4参照值cj0分别设置为:0.05和0.15、5、2、0.8;x1、x3的阈值cb分别为0.5、40(因子单位:水温(℃); 其它因子单位(mg·L-1)).
4.2 基于NV-SVR的COD(y)预测模型输出表示式分别选取表 1中前22个样本和后6个样本作为NV-SVR的建模样本和预测(检测)样本.分别将表 1中每一个建模样本的相继2个因子规范值或相继3个因子规范值各组成4个训练样本, 每一个建模样本组成的4个训练样本相应的NV-SVR模型期望输出值皆相同, 即为该建模样本COD的平均规范值yi0′.以全部建模样本各个因子的最大规范值xjM作为分量值, 组成一个恒定的参照样本(中心矢量).在NV-SVR建模过程中, 每个训练样本在NV-SVR模型的第1个核函数中对应的参照样本的各个分量值皆为该样本的第1个因子的最大规范值x1M′;在第2个核函数中对应的参照样本的各个分量值皆为该样本的第2个因子的最大规范值x2M;在第3个核函数中对应的参照样本的各个分量值皆为该样本的第3个因子的最大规范值x3M′;而同一模型的所有核函数中的核参数σ均相同.在满足目标函数式(5)条件下, 将前22个建模样本组成的4×22=88个训练样本规范值分别带入NV-SVR(2)模型(式(6))及NV-SVR(3)模型(式(7))的优化程序中, 用免疫进化算法对支持向量αi、核参数σ和常参数b反复迭代优化(倪长健等, 2003).当优化目标函数式满足
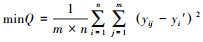
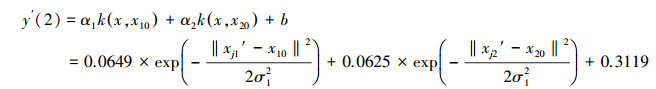 | (16) |
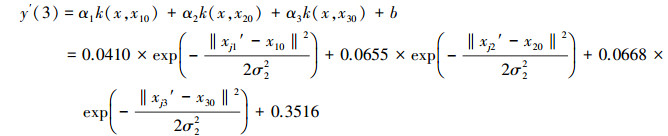 | (17) |
4.3 预测样本模型输出的误差修正及修正后的COD预测值从表 1可知, 与23*检测样本的两种模型输出相似的有8*、13*两个建模样本;与24*检测样本的两种模型输出相似的有12*、14*、16*三个建模样本;与25*检测样本的两种模型输出相似的有8*一个建模样本;与26*检测样本的两种模型输出相似的有19*一个建模样本;与27*检测样本的两种模型输出相似的有14*一个建模样本;与28*检测样本的两种模型输出相似的有4*、6*、18*三个建模样本.按式(13)和式(14)进行误差修正后的6个检测样本COD的两种模型的预测输出值, 如表 2所示.再由式(2)和式(15)的逆运算, 计算出两种模型对6个检测样本的COD预测值, 亦见表 2.而两种模型的6个检测样本的预测值的相对误差绝对值及其平均值和最大值如表 3所示.为了比较, 表 2和表 3中还分别列出了笔者用传统的PPR模型和传统的SVR模型对该6个检测样本的预测值和预测值的相对误差绝对值及其平均值和最大值.其中, 传统的PPR模型的预测变量归一化变换式为:yi′=(yi -21.2)/ 180, 优化得到PPR预测模型的4个影响因子在投影方向上的投影分量值分别为:βi1= 0.1255, βi2= 0.4562, βi3= 0.1984和βi4= 0.2006;传统的SVR模型的预测变量变换式为:Yi = (cy-20)/2, 优化得到SVR预测模型中的4个支持向量对应的系数分别为:α1= 3.707, α2= -1.320, α3= -3.107和α4= 0.293, 阈值b= 0.3513, 核函数参数2σ2= 0.0211.表 3中还列出文献(薛鹏松等, 2012)中用灰色神经网络法(Grey-ANN)和马尔科夫(Markov)修正法对该6个样本预测的相对误差绝对值及其平均值和最大值.从表 2可见, 对同一个检测样本, 两种结构的NV-SVR预测模型的预测值彼此相差甚小, 而且都十分接近实际值;而传统的PPR模型和传统的SVR模型的预测值却相差甚远.从表 3可见, 两种结构的NV-SVR预测模型对6个样本预测的相对误差绝对值的平均值和最大相对误差绝对值都远远小于传统的PPR模型、传统的SVR模型、灰色神经网络模型及马尔科夫修正模型的预测结果, 其中, 比前3种传统的预测模型的预测精度提高了一个数量级以上, 尤其是对异常样本(比如26*检测样本)的预测效果更加明显.
表 2(Table 2)
| 表 2 6个检测样本的两种NV-SVR模型误差修正后的模型输出值、预测值及传统的PPR和SVR模型预测值 Table 2 The output values of models after error correction and the predictive values of two NV-SVR models l as well as the predictive values of traditional PPR and SVR models for the 6 test samples | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
表 2 6个检测样本的两种NV-SVR模型误差修正后的模型输出值、预测值及传统的PPR和SVR模型预测值 Table 2 The output values of models after error correction and the predictive values of two NV-SVR models l as well as the predictive values of traditional PPR and SVR models for the 6 test samples
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
表 3(Table 3)
| 表 3 6个检测样本的多种预测模型的预测相对误差的绝对值及其平均值和最大值 Table 3 The relative error absolute values and their average values as well as the maximal values of multiple prediction models for the 6 test samples | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
表 3 6个检测样本的多种预测模型的预测相对误差的绝对值及其平均值和最大值 Table 3 The relative error absolute values and their average values as well as the maximal values of multiple prediction models for the 6 test samples
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5 比较与讨论(Comparisons and discussion)5.1 NV-SVR预测模型与NV-SVR评价模型的规范变换式的比较基于规范变换的预测模型与基于规范变换的评价模型的规范变换式(1)和(2)的形式虽然完全相同(李祚泳等, 2015), 但规范变换式中的字母的意义、参数的确定和适用对象有本质区别:a)变换式(1)在评价模型中仅用于评价指标的变换, 而在预测模型中对影响因子和预测变量皆需要进行变换;b)变换式(1)中幂指数nj在评价模型中由各指标的最高与最低分级标准值的比值大小确定, 只要依据的评价标准确定, 其选取与评价的实际具体问题无关;而在预测模型中则必须由实际问题的建模样本各影响因子(或预测变量)的最大值与最小值的比值确定, 随问题的不同而不同;c)参照值cj0在评价模型中, 必须满足由式(1)和式(2)计算得到的指标的各级标准规范值都应在各级标准相应的限定变化范围内;而在预测模型中, 只需满足由式(1)和式(2)计算得到的各影响因子(或预测变量)的最大规范值与最小规范值能在相应的限定变化范围内即可.由于参照值cj0在评价模型中选取的限制条件远比在预测模型中选取的限制条件苛刻得多, 尤其当评价指标数目和评价标准分级数目较多时, 常常需要反复多次调整cj0才能满足要求.因而预测模型中的cj0比评价模型中的cj0更容易确定.因此, 尽管预测模型比评价模型要多进行预测变量的规范变换, 以及幂指数nj的确定随问题的不同而不同, 但nj的确定十分简单.因此, 总的说来, 预测模型变换式的设计比评价模型变换式的设计简便、快捷.
此外, 对一个实际预测问题, 参照值cj0和变换式(1)设计的具体形式虽然也有一定程度的不确定性, 但只要能满足规范变换条件以及优化迭代能达到目标函数值要求的精度, 则优化得到的两种结构的NV-SVR预测模型一般就能满足实用需要, 因而模型是稳定、有效的.
5.2 NV-SVR预测模型与传统的SVR预测模型的比较NV-SVR预测模型除同样具有传统的SVR模型在避免维数灾难、防止过拟合、克服局部极值及特别适用于小样本容量建模等方面的优势外, 还具有以下特点:
① 传统的SVR预测模型通常采用极差归一化公式对预测变量及其影响因子的原始数据进行各自独立的线性变换, 变换前、后的预测变量和影响因子的数值特性不发生改变;而NV-SVR预测模型采用规范变换, 该变换要求变换后的预测变量及其各个影响因子的最小规范值和最大规范值都要分别被限定在[0.10, 0.24]和[0.40, 0.55]范围内.由于规范变换后的不同影响因子规范值皆呈现近似相同的变化规律, 因而规范变换后的各影响因子皆可视为同一个“等效”规范因子, 从而将复杂的非线性多因子(高维)SVR预测建模问题简化为“等效”规范因子的简单低维SVR建模问题.
② 传统的SVR预测模型计算复杂度虽然不取决于样本的因子数, 且最终只由αi不为“0”所对应的少数支持向量决定, 但模型初始设置待优化的支持向量αi个数需等于建模样本个数n, 而核函数中范数的计算量则随因子数m增多而加大.因此, 传统的SVR模型用于大样本、多因子预测建模学习效率低, 收敛速度慢.而且对不同建模样本数目, 需要建立不同结构的预测模型, 模型的结构(形式)不能普适、规范和统一;而NV-SVR预测模型的结构与因子数目m和建模样本数目n的多少皆无关, 对具有任意多个训练样本和任意多个因子数的NV-SVR预测建模, 皆只需对“等效”规范因子, 构建结构为2个或3个支持向量的两种简单结构的NV-SVR预测模型, 核函数中范数的计算也十分简单, 因而预测模型的结构简单、普适、规范和统一;编程和计算亦得到简化, 提高了模型学习效率.
③ 传统的SVR预测模型的性能受惩罚因子C(正则化参数)、核函数参数σ和不敏感系数e 3个参数的影响.其中, 核函数参数σ影响样本数据在高维特征空间中分布的复杂程度;训练样本产生的经验风险随惩罚因子C的增加而增加, 反之亦然;不敏感系数e用于控制支持向量个数.e值太小, 易出现过拟合, 且收敛速度慢;反之, 易导致欠拟合.两种情况都会使模型预测精度尤其是异常样本的预测精度下降.而惩罚因子C、核函数参数σ和不敏感系数e的选取尚无可靠的理论依据, 多凭经验、实验或优化方法得出.而NV-SVR预测模型的支持向量仅需2个或3个, 因此, 不需要不敏感系数e控制支持向量个数.并用常参数b替代惩罚因子C, 因此只需确定b和σ两个参数即可.
5.3 NV-SVR预测模型与传统的智能预测模型的比较NV-SVR预测模型与传统的神经网络ANN(BF、RBF、FNN)和投影寻踪回归(PPR)等智能预测模型的性能比较见表 4.
表 4(Table 4)
| 表 4 NV-SVR预测模型与传统的智能预测模型的性能比较 Table 4 Performance comparison of NV-SVR prediction model with the traditional intelligent prediction models | ||||||||||
表 4 NV-SVR预测模型与传统的智能预测模型的性能比较 Table 4 Performance comparison of NV-SVR prediction model with the traditional intelligent prediction models
| ||||||||||
6 结论(Conclusions)1) NV-SVR预测模型的预测变量及其影响因子的参照值和规范变换式的设置原则和方法具有简单性、规范性和可操作性特点.
2) 与传统的多种预测模型相比, NV-SVR预测模型提高了学习效率和模型求解精度.对多个样本预测的相对误差绝对值的平均值和最大相对误差绝对值都远远小于传统的预测模型的预测误差, 尤其能显著提高异常样本的预测精度.
3) 对同一个预测样本, 误差修正后的两种NV-SVR预测模型的预测值相差甚小, 而且皆与实际值十分接近, 表明模型稳定性较好.
4) NV-SVR的预测建模思想和方法为规范和简化任意系统的前向神经网络、BP网络、RBF神经网络、PPR模型和多元线性回归等预测建模均有借鉴和启迪作用;对时间序列预测建模也同样适用.
5) NV-SVR的预测模型在环境、水文水资源、地质、气象、经济、旅游、交通、工、农业、金融等诸多领域有广泛的应用前景.
致谢(Acknowledgements):感谢四川师范大学伍绍贵副教授(博士)对修改英文摘要提供的协助.
参考文献
| Chen S Y, Xue Z C, Li M. 2013. Variable sets principle and method for flood classification[J]. Science China (Technological Sciences), 56(9): 2343–2348.DOI:10.1007/s11431-013-5304-4 |
| 陈晶, 王文圣. 2015. Copula预测方法及其在年径流预测中的应用[J]. 水力发电学报, 2015, 34(4): 16–21. |
| 陈媛, 胡恒, 王文圣. 2010. IEA-PNN模型在水质预测中的应用[J]. 水电能源科学, 2010, 28(5): 22–25. |
| 崔东文, 郑斌. 2016. 几种智能优化算法与支持向量机相融合的月径流预测模型及应用[J]. 人民珠江, 2016, 37(3): 18–25. |
| 笪英云, 汪晓东, 赵永刚, 等. 2015. 基于关联向量机回归的水值预测模型[J]. 环境科学学报, 2015, 35(11): 3730–3735. |
| 冯兆澍. 2015. 基于投影寻踪法的地下水涌水量预测[J]. 地下空间与工程学报, 2015, 11(2): 505–510. |
| 胡健伟, 周玉良, 金菊良. 2015. Bp神经网络洪水预报模型在洪水预报系统中的应用[J]. 水文, 2015, 35(1): 20–25. |
| 黄思, 唐晓, 徐文帅, 等. 2015. 利用多模式集合和多元线性回归改进北京PM10预报[J]. 环境科学学报, 2015, 35(21): 56–64. |
| 金菊良, 魏一鸣, 王文圣. 2009. 基于集对分析的水资源相似预测模型[J]. 水力发电学报, 2009, 28(1): 72–77. |
| 金菊良, 崔毅, 张礼兵, 等. 2015. 基于多智能体的城镇家庭用水量模拟预测分析[J]. 水利学报, 2015, 46(12): 1387–1397. |
| 李祚泳, 张正健. 2013. 基于回归支持向量机的指标规范值的水质评价模型[J]. 中国环境科学, 2013, 33(8): 1502–1508. |
| 李祚泳, 徐源蔚, 汪嘉杨, 等. 2015. 基于前向神经网络的广义环境系统评价普适模型[J]. 环境科学学报, 2015, 35(9): 2996–3005. |
| 李祚泳, 徐源蔚, 汪嘉杨, 等. 2016. 基于投影寻踪回归的规范指标的气象灾情评估[J]. 应用气象学报, 2016, 27(4): 480–487.DOI:10.11898/1001-7313.20160411 |
| Liu S Y, Tai H J, Ding Q S, et al. 2013. A hybrid approach of support vector regression with genetic algorithm optimization for aquaculture water quality prediction[J]. Mathematical and Computer Modeling, 58(4/3): 458–465. |
| Liu S Y, Xu S Q, Jiang Y, et al. 2014. A hybrid WA-CPSO-LSSVR model for dissolved oxygen content prediction in crab culture[J]. Engineering Applications of Artificial Intelligence, 29: 114–124.DOI:10.1016/j.engappai.2013.09.019 |
| Moura M, Zio C, Lins E, et al. 2011. Lailure and reliability prediction by support vector machines regression of time series data[J]. Reliability Engineering & System Safety, 96(11): 1527–1534. |
| 倪长健, 丁晶, 李祚泳. 2003. 免疫进化算法[J]. 西南交通大学学报, 2003, 38(1): 87–91. |
| Noori R, Barbassi A, Ashrafi K, et al. 2012. Active and online prediction of BOD5 in river systems using reduced-order support vector machine[J]. Environmental Earth Sciences, 67(1): 141–149.DOI:10.1007/s12665-011-1487-9 |
| Palani S, Liong S Y, Tkalich P. 2008. An ANN application for water quality forecasting[J]. Marine Pollution Bulletin, 56(9): 1586–1597.DOI:10.1016/j.marpolbul.2008.05.021 |
| Tan G H, Yan J Z, Gao C, et al. 2012. Prediction of water quality time series data based on least squares support vector machine[J]. Procedia Engineering, 31: 1194–1199.DOI:10.1016/j.proeng.2012.01.1162 |
| Thoe W, Wong S H C, Choo K W, et al. 2012. Daily prediction of marine beach water quality in Hong Kong[J]. Journal of Hydro-environment Research, 6(3): 164–180.DOI:10.1016/j.jher.2012.05.003 |
| Wang X G, Tang Z, Tamura H, et al. 2004. An improved bad-propagation algorithm to avoid the local minima problem[J]. Neuro Computing, 56(1): 455–460. |
| 王保良, 范昊, 冀海峰, 等. 2016. 基于分段线性表示最近邻的水质预测方法[J]. 环境工程学报, 2016, 10(2): 1005–1009.DOI:10.12030/j.cjee.20160276 |
| Qi X N, Liu Z G, Li D D. 2008. Prediction of the preformation of a shower cooling tower based on projection pursuit regression[J]. Application Thermal Engineering, 28(10): 1031–1038. |
| 薛鹏松, 冯民权, 邢肖鹏. 2012. 基于马尔科夫链改进灰色神经网络的水质预测模型[J]. 武汉大学学报(工学版), 2012, 45(3): 319–324. |
| 郑彤, 陈春云编. 2003. 环境系统数学模型[M]. 北京: 化学工业出版社. 31 |
