全文HTML
--> --> -->水下无线传感器网络节点具有移动性, 导致网络节点始终处于时变状态. 在同步转发过程中, 节点发送和接收数据报文的位置会发生变化, 从而产生相对移动距离, 导致动态时延增大. 如此随着转发次数增多, 时钟的误差(主要由传送时间、传播时间和接收时间组成)也逐渐增大, 造成水下传感器无线网络同步精度(节点估算的参考时间与实际参考时间的偏差)逐渐降低. 现存的水下无线传感器网络时钟同步算法, 并没有充分考虑到节点随洋流运动而产生的动态时延, 只是利用时间戳机制求解时钟同步参数, 然后利用传统的线性拟合对同步参数进行求精处理, 如TSHL[7], MM-sync[8]和MU-sync[9]等算法. 对动态时延的精确求解是同步精度的一个关键因素. 利用传统的优化算法(如最小二乘法)对同步参数进行求精, 容易陷入局部最优, 进而使得同步精度不高. 因此现有传统的时钟同步算法研究不能很好地解决由于节点移动性导致的时钟同步精度问题.
因此, 在设计UWSNs时钟同步算法时, 时钟同步参数的精度是水下传感器网络时钟同步算法需要着重考虑的因素, 为了提高时钟同步的参数精度, 需要对同步误差进行补偿.
本文的篇章组织结构如下: 第1节介绍UWSNs时钟同步算法的研究意义及误差补偿的重要性; 第2节详细给出现有时钟同步算法及研究现状; 第3节给出了各种模型的搭建过程; 第4节详细介绍BP神经网络模型时钟同步误差补偿算法; 第5节通过仿真实验证明该误差补偿模型的实用性; 第6节对整篇文章进行分析总结.
针对水下无线传感器网络时延的随机性, 研究者们提出了一系列适用水下传感器网络的时钟同步算法. Eidenbenz等提出了高延迟时钟同步算法TSHL, 该算法首先利用信标节点发送数据报文, 然后待同步节点将收到报文的时间与本地时间组成元组, 再利用线性拟合计算频偏, 最后根据一次双向数据报文求解相偏, 该算法解决了高时延的问题, 但是因为需要多次发送数据报文, 所以存在能耗较高的问题, 同时该算法忽略了水下节点移动的特点, 因此算法的时钟精度不高. 与此同时, 该算法用的是线性拟合求解方法, 其误差较大. Sajjad等[13]在分析时间间隔对时钟同步精度影响的基础上, 增大了TSHL 算法的同步信号的时间间隔, 减少了同步信号的发送次数, 这种改进版的TSHL 算法降低了算法复杂度和能量消耗. 文献[14]针对TSHL算法同步交互信号多, 能量消耗大的不足, 提出了一个Tri-Message 同步算法, 首先改用3次发送-接收交互计算频偏, 然后使用双向交换计算相偏, 这可以降低消息开销并保持一定同步精度, 进一步优化了TSHL算法的性能. 文献[15]提出TSMU算法, 利用卡尔曼滤波对多普勒计算的相对速度求其精度, 再用线性回归和校准来计算时钟同步的频偏和相偏. 文献[16]提出的Hybrid-Sync同步算法, 利用混合时钟交换数据报文的方式计算相偏和频偏, 最后利用计算得到的频偏来进一步校正相偏. 与TSHL算法相比, 降低了算法的通信费用, 但是Hybrid-Sync的计算费用较高且时钟同步精度不高.
上述算法虽然在一定程度上解决了时钟同步问题, 但都没有考虑节点移动性导致时钟同步精度不高的问题.
MM-sync 算法考虑传感器网络移动性对同步参数的影响, 推出时钟同步参数模型, 进而构建出一种适合浅水域的时间同步算法. 文献提出的一个分簇UWSNs时钟同步算法MU-Sync. 该算法先对网络节点进行分簇, 再利用簇首周期性地广播同步信号来进行簇内时钟同步, 利用簇首节点收集到的同步信息进行两次线性拟合估计往返传播时延, 以此来降低误差, 通过多次双向信息交换, 使MU-Sync 算法获得了较好的同步精度. Shi等[17]首次将水下时钟同步问题分为授权、簇内同步和簇间同步三个阶段; 在授权阶段, 所有的节点相互授权, 并确认和删除恶意节点; 在簇内同步阶段, 簇首节点通过发送、接收模式和普通节点进行同步. 该算法为了提高同步精度, 利用CESVM (centered hyperellipsoidal support vector machine based anomaly detection) [18]过滤非正常的接收端到接收端的传播延迟, 同时假设随机传输延迟符合方差为0的高斯分布, 进行时钟同步求精.
文献[19]提出D-sync时钟同步算法, 是基于水下通信产生的多普勒效应, 利用该效应计算节点间的相对速度, 估计传播延迟完成时钟同步. 但由于水声环境影响因素过多, 该算法测量的误差会较大. 因此, NU-sync算法[20]加入了更准确的多普勒测量的方法因素, 通过计算节点的相对速度解决延迟多变的问题, 利用潜水器作为信标节点对节点进行同步, 极大降低了误差.
综上所述, 现今水下无线传感器网络时钟同步算法的研究需要综合考虑节点移动对同步精度的影响, 同时也要避免传统时钟同步算法使用线性拟合思想造成误差较大的问题. 因此, 本文综合考虑节点的移动性、误差补偿等因素构建符合水下网络的BP神经网络时钟同步误差补偿算法, 从而设计出一个精度高、误差小的水下传感器网络时钟同步算法.
3.1.洋流模型
本节首先分析洋流运动对节点运动的影响, 然后根据速度计算公式计算待同步节点的移动速率.由于水下环境复杂多变, 水下物体运动并不是完全无规律的, 而是呈现出半周期的运动特性. 文献[21]中提出一种权威的洋流模型, 本文用此模型对节点的运动进行分析. 模型公式为






 图 1 x方向的速率
图 1 x方向的速率Figure1. The velocity in the x direction.
 图 2 y方向的速率
图 2 y方向的速率Figure2. The velocity in the y direction.
对普通节点来说, 难与浮标节点通信, 但利用自身的相关性, 可以获取移动速度. 假定节点i想要取得自身的速度




2
3.2.时钟同步参数模型
本文传感器节点以线性模型为例, 根据文 献[24]节点的时钟t与标准时间T的关系为本文采用先分簇后对簇群进行时钟同步, 分为浮标节点、簇首节点、普通节点. 簇首节点可以直接获取浮标节点的标准时间, 故只需要考虑簇群的时钟同步. 报文交换过程如图3所示.
 图 3 数据报文交换过程
图 3 数据报文交换过程Figure3. Data message exchange process.
普通节点分别向各个节点发送数据报文进行时间同步, 簇首节点收到后向普通节点发送多个数据分组. 信息交互过程如图3所示. C在















 图 4 数据报文交换过程
图 4 数据报文交换过程Figure4. Data message exchange process

2
3.3.BP神经网络时钟同步误差补偿模型
基于BP神经网络的时钟同步误差补偿模型, 是将根据时钟同步参数模型中的(9)式和(11)式计算得到的m个同步参数估计值作为网络学习样本, 经过大量重复不断地学习, 沿着误差减小的方向, 不断调整各层神经元之间的权值和阈值, 目的是得到一个最佳预测补偿模型.针对3.2节时钟同步参数模型精度不高提出的BP神经网络时钟同步误差补偿模型如图5所示.
 图 5 BP神经网络时钟同步误差补偿结构图
图 5 BP神经网络时钟同步误差补偿结构图Figure5. BP neural network clock synchronization error structure diagram.
3
3.3.1.激活函数的设定
激活函数对本文算法网络尤为重要, 常用的sigmoid和tanx虽然易于实现, 但存在不可避免的缺陷. 基于此本文为避免陷入局部计算以及综合节点移动对水下传感器时钟同步产生的影响, 本文提出

3
3.3.2.代价函数、误差补偿模型和误差方向传播更新过程
1)代价函数本文有m个输入样本










2)时钟同步误差补偿模型
为避免过拟合现象造成的误差无法达到极小值, 参数的更新过程采用随机梯度下降算法. 考虑到水下传感器节点资源有限并结合BP神经网络结构, 构造时钟同步误差补偿模型为:









另外,
2
4.1.模型搭建阶段
如表1所示, 输入层节点个数设置为2, 输出层节点的个数设置为1, 隐藏层的神经元个数使用了经验公式[27]| 算法: 基于BP神经网络模型时钟同步误差补偿算法 |
| 输入: $\begin{array}{l} {{a}} = [{a_1}, {a_2}, {a_3}, \cdots, {a_i}, \cdots, {a_m}], i = 1, 2, \cdots m \\ {{b}} = [{b_1}, {b_2}, {b_3}, \cdots, {b_i}, \cdots, {b_m}], i = 1, 2, \cdots m \\ {{t}} = [{t_1}, {t_2}, {t_3}, \cdots, {t_i}, \cdots, {t_m}], i = 1, 2, \cdots m \end{array} $ |
| 阶段1: BP模型搭建阶段 |
| 01: 算法 |
| 02: 算法阶段一开始 |
| 03: 数据收集 |
| 04: $\begin{array}{l}m\leftarrow \big\{ {{a} }=[{a}_{1}, {a}_{2}, {a}_{3}, \cdots, {a}_{i}, \cdots, {a}_{m}], \;\\{{b} }=[{b}_{1}, {b}_{2}, {b}_{3}, \cdots, {b}_{i}, \cdots, {b}_{m}], \\{{t} }=[{t}_{1}, {t}_{2}, {t}_{3}, \cdots, {t}_{i}, \cdots, {t}_{m}]\big\}\end{array}$ |
| 05: 数据归一化 |
| 06: $\tilde m \leftarrow m$ |
| 07: for $c = {\rm{ 1}}$, $c \leqslant 10, {\rm{c}} + + $ |
| 08: 根据$l \!=\! \sqrt{q \!+\! s} \!+\! c$计算隐藏层的神经元的个数 |
| 09: BP神经网络模型 |
| 10: end for |
| 11: end |
表1模型搭建阶段
Table1.Model construction phase.


2
4.2.模型训练阶段
如表2所示, 分别对




| 阶段2: BP网络模型训练阶段 |
| 01: 算法开始 |
| 02: 开始训练网络 |
| 03: 参数初始化 |
| 04: 随机设置$w \in (0, 1), b \in (0, 1),~ \alpha \in (0, 1), $ $ \rlap-{\lambda} \in (0, 1),~ \sigma \in (0, 1)$ |
| 05: r =3000, $\rho $ = 0.001 |
| 06: create $f(x)$, P |
| 07: $\tilde m$ 分成训练集和测试集 |
| 08: start training |
| 09: for all $\left\{ {{t_i}, {a_i}, {b_i}} \right\} \in \tilde m$ do |
| 10: if ($E > \rho $) do |
| 11: $w, b$ 被更新 $w_{ij}^{(l)}, b_i^{(l)}$ according to Eq. (20) and Eq. (21) |
| 12: end if |
| 13: end for |
| 14: 输出J |
| 15: end |
表2模型训练阶段
Table2.Model training stage.
2
4.3.模型预测阶段
如表3所示, 模型预测阶段具体过程如下: 当网络达到迭代终止条件, 即E小于期望误差



| 阶段3: BP网络预测 |
| 01: 开始 |
| 02: 算法预测 |
| 03: 当满足条件时, 执行以下 |
| 04: if ($E < $$\rho $) do |
| 05: 停止训练 |
| 06: 得到J |
| 07: 输入$[{a_{i + 1}}, {b_{i + 1}}]$ to J |
| 08: 输出$[{\tilde a_{i + 1}}, {\tilde b_{i + 1}}]$ |
| 09: end if |
| 10: end |
表3模型预测阶段
Table3.Model prediction stage.
2
5.1.算法时间复杂度分析
时间复杂度是衡量一个算法的度量指标, 本节主要分析基于BP神经网络模型时钟同步误差算法. 本文算法的核心是网络的前向传播和误差反向调整权重和阈值部分. 前向信号传播时间复杂度为


2
5.2.实验设置
本文仿真实验的相关参数如表4所示.| 仿真实验参数 | 符号表示 | 数值 |
| 浮标节点 | N | 2 |
| 节点布置区域/m3 | O | $400 \times 400 \times 400$ |
| 普通传感器节点 | m | 200 |
| 迭代次数 | r | 3000 |
| 正则惩罚因子 | $\rlap-{\lambda}$ | 0.01 |
| 稀疏性惩罚因子 | $\sigma $ | 0.03 |
| 稀疏性因子 | $\tau $ | 0.6 |
| 激活因子 | $\zeta $ | 0.4 |
表4实验参数
Table4.Experimental parameter setting.
3
5.2.1.本文算法和线性拟合作同步时间与标准时间的误差对比分析
为了比较BP神经网络时钟同步误差补偿的效果, 引入利用传统线性拟合对数据报文交换进行误差补偿[28], 同时使用传统线性拟合对m组训练样本进行拟合.由图6可知, 精度在0.001时几乎看不出变化, 因为使用BP神经网络模型的补偿效果几乎与标准时间一致, 为了更好地看出BP补偿效果与传统补偿效果的区别, 将其扩大

 图 6 误差对比分析
图 6 误差对比分析Figure6. Error comparison and analysis.
同时本文使用10个样本对已经训练好的补偿模型和线性拟合作对比预测, 对比它们之间的均方误差.
如图7和图8所示, 节点一开始是随机抛洒, 故需要将训练好的BP神经网络误差补偿模型和传统线性拟合去逼近节点真实值, 通过比较并计算可得图7的均方误差


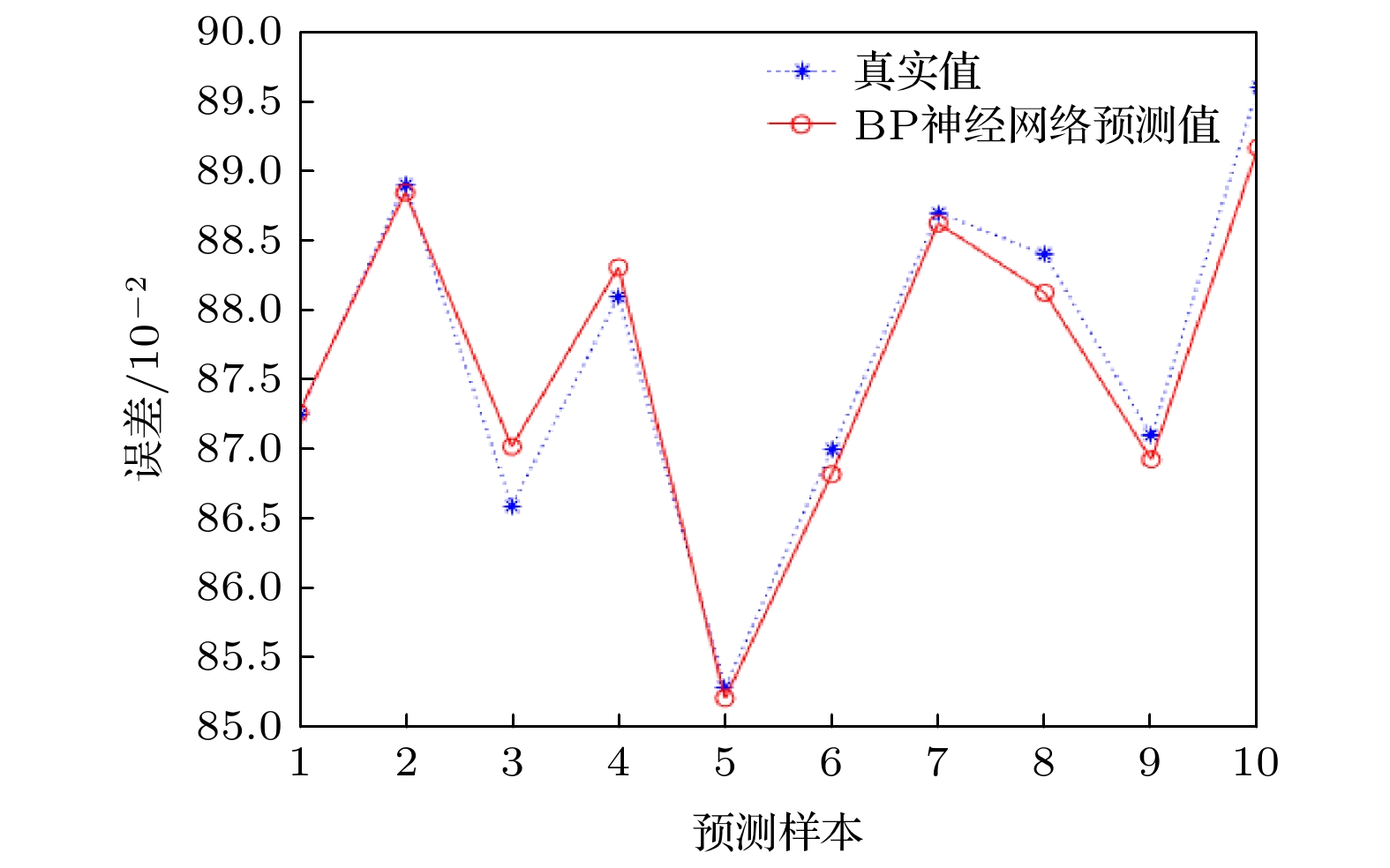 图 7 BP神经网络预测
图 7 BP神经网络预测Figure7. BP neural network prediction.
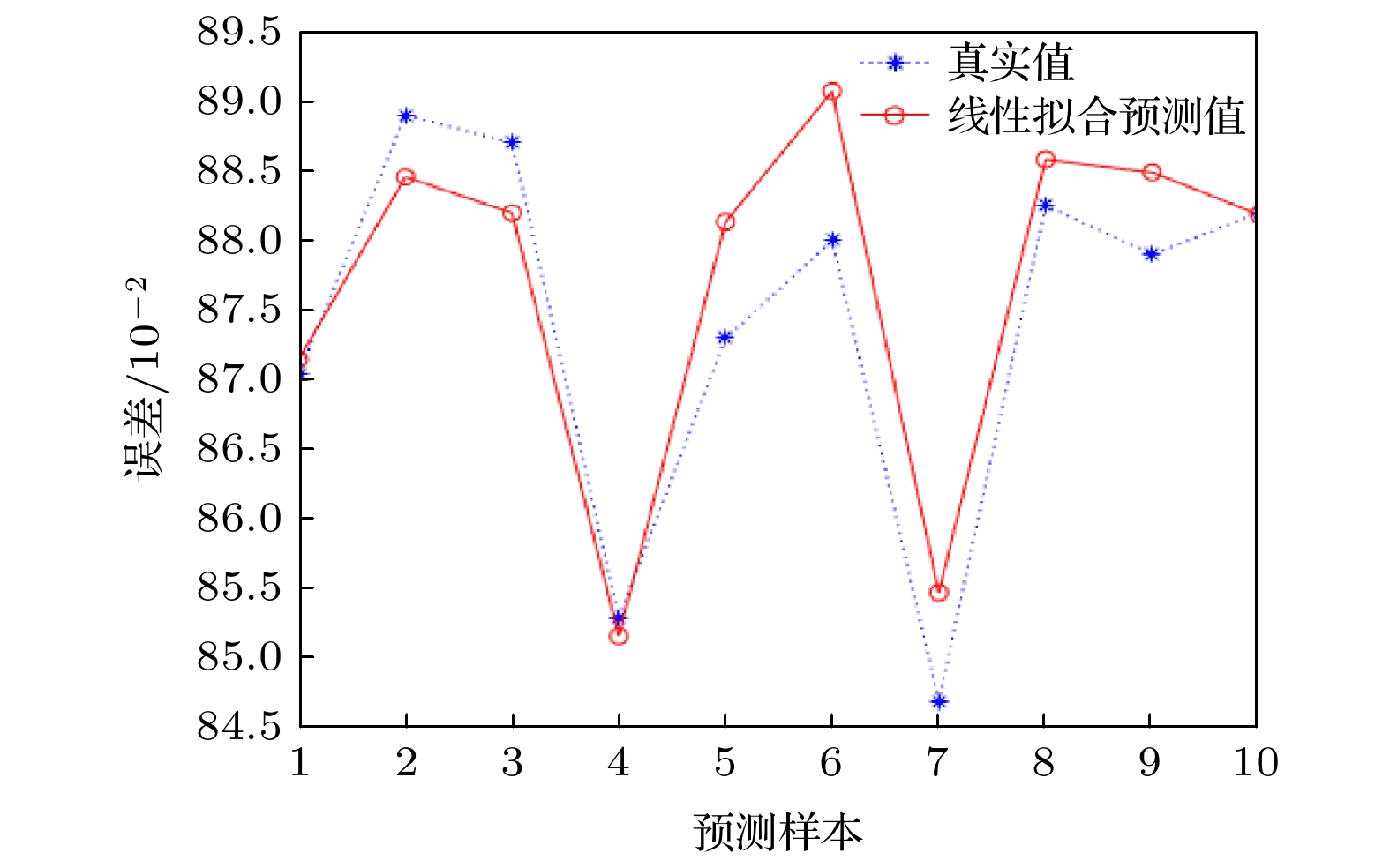 图 8 线性拟合预测
图 8 线性拟合预测Figure8. Linear fitting prediction.
3
5.2.2.本文算法与其他时间同步算法的对比分析
本节针对时钟同步精度和数据报文能耗, 将本文算法与TSHL[7]算法、MU-sync[9]算法、MM-sync[8]算法进行对比实验分析.图9和图10分别表示时钟频偏a计算偏差随节点移动速度的变化情况和时钟漂移b计算偏差随节点移动速度的变化情况.
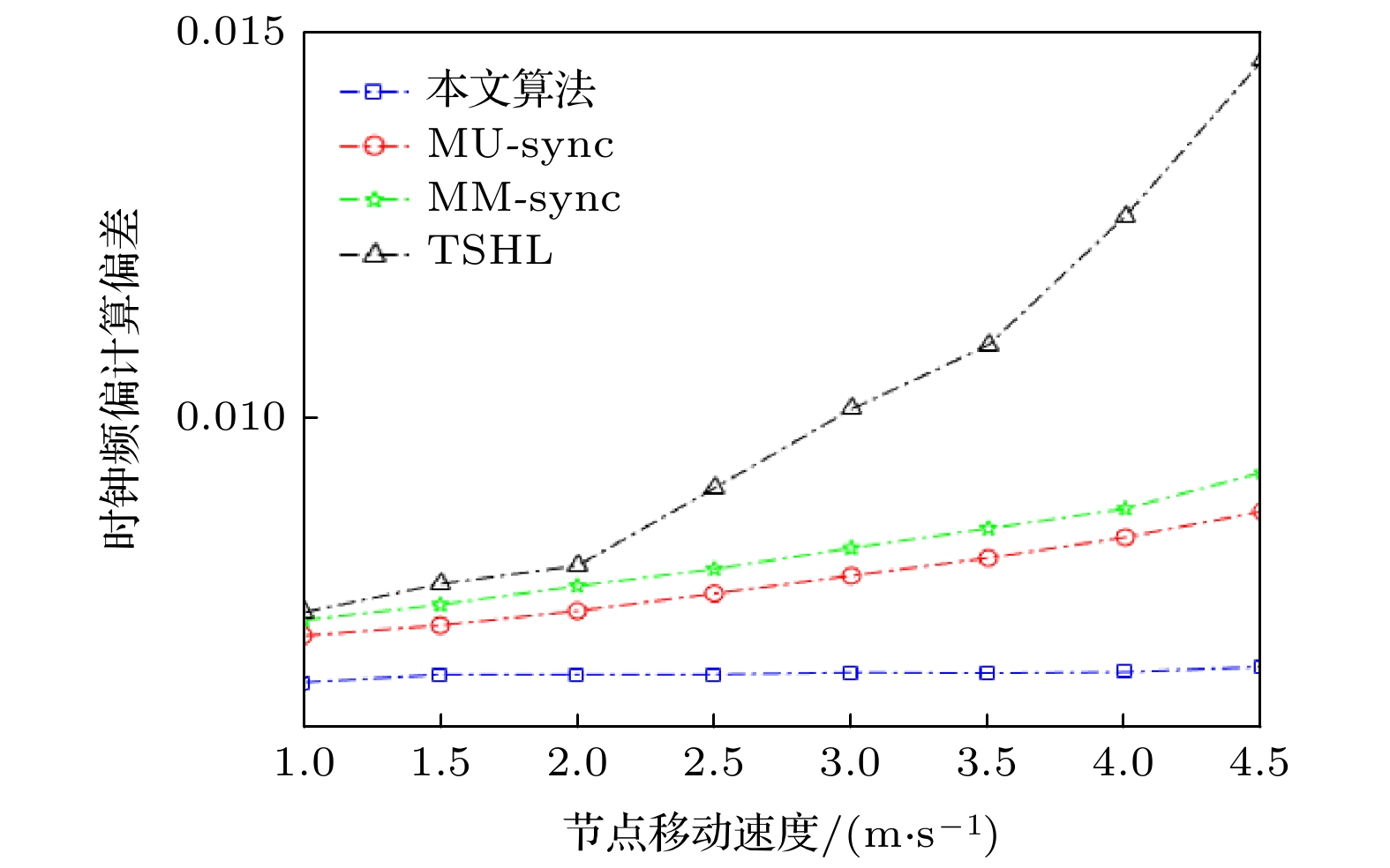 图 9 时钟频偏计算偏差随节点移动的变化
图 9 时钟频偏计算偏差随节点移动的变化Figure9. The variation of clock-frequency offset calculation deviation with node move.
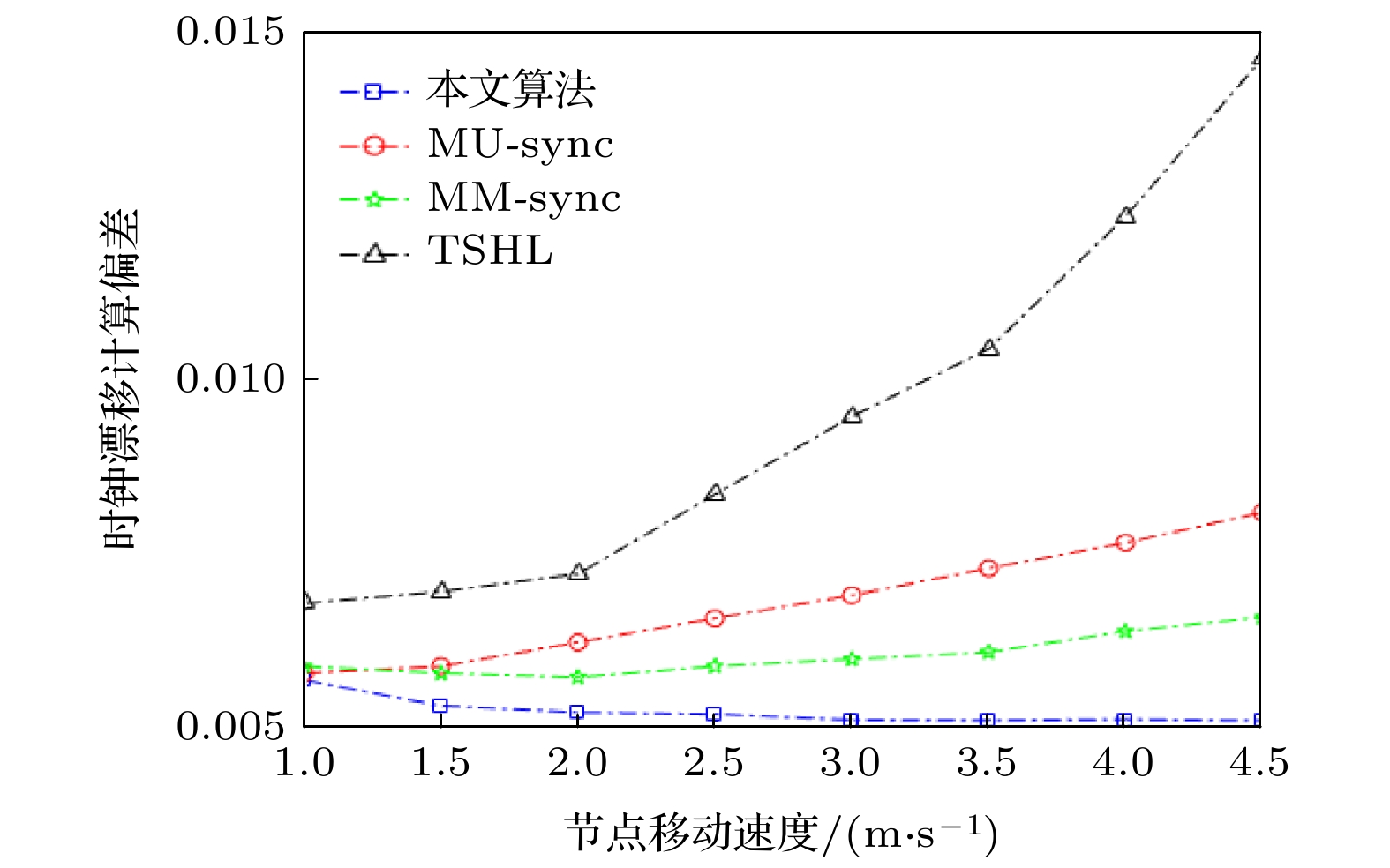 图 10 时钟漂移计算偏差随节点移动变化情况
图 10 时钟漂移计算偏差随节点移动变化情况Figure10. The clock drift calculation deviation changes with the node movement.
由图9可知, 本文算法的误差明显小于其他算法, 分别比TSHL[7]算法、MU-sync[9]算法、MM-sync[8]算法降低37.42%, 17.29%和21.86%. 因为随着节点速度增大, 而TSHL忽视了节点的移动性问题, 在时钟同步期间假定节点位置不变, 即传播过程时延没有发生变化, 导致速度增大时, TSHL的误差会异常明显. MU-sync是针对节点移动性提出的算法, 但忽视了传播时延, 采用不变的值去计算频偏, 再用线性拟合去除相应的传播时延, 从而求得时钟漂移, 当速度明显增大时, 算法表现就会减弱. MM-sync算法在误差补偿中, 假设节点做匀速运动, 当节点速度增大时, 误差补偿效果减弱. 本文算法基于BP神经网络的时钟同步误差补偿模型, 考虑了节点移动性带来的时延问题, 同时通过BP神经网络反复训练得到一个精度较高的误差补偿模型.
由图10可以看出, 本文算法明显优于其余三种算法, 当节点速度越大, 误差几乎不在发生变化, 其运动轨迹和移动模型更加符合实际, 并且时钟同步精度也更高, 因而计算偏差越小.
图11给出本文算法、MU-sync[9]算法、MM-sync[8]算法和TSHL[7]算法在完成同步后, 本地时钟增长的误差趋势.
 图 11 时钟同步后本地时钟误差增长趋势变化
图 11 时钟同步后本地时钟误差增长趋势变化Figure11. The increasing trend of local clock error changes after clock synchronization.
由图11可知, 本文算法的误差明显小于其他算法, 分别降低47.12%, 31.37%和12.89%. 其他算法误差较大的主要是原因为: TSHL法假设网络为静态网络, 这势必会导致更大的同步误差; MU-sync使用两次线性回归来估计时钟频偏和相偏, 但该算法假设每一轮消息交换到的传播时延是一致的, 没有考虑往返时间不一致的传播时延, 这会导致更大的同步误差; MM-sync算法虽然考虑节点移动性, 但是在误差估计阶段, 将节点运动状态单一化的归结为匀速运动, 如此随着网络的动态变化, 该算法的性能也随之下降; 这三种算法并没过多考虑节点随洋流运动而产生的动态时延, 导致误差较大. 本文算法通过引入洋流模型估计待同步节点的速率, 提高了动态传播延时的精度, 且使用BP神经网络反复训练, 得到一个误差补偿精度很高的模型.
图12给出本文算法与其余三种算法在同步35次后产生的数据报文数, 以此来分析数据报文能耗的高低.
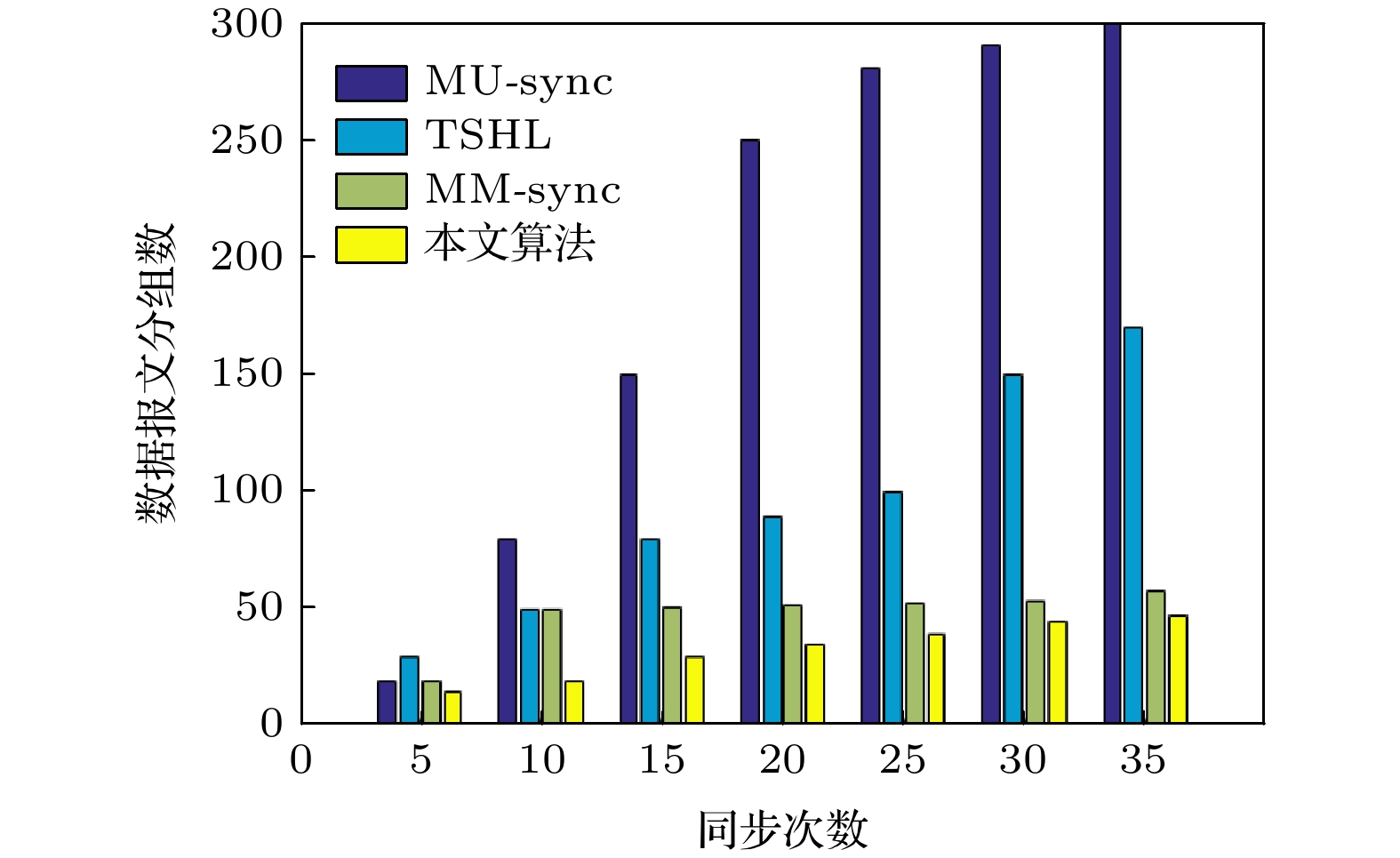 图 12 同步次数与数据报文的变化
图 12 同步次数与数据报文的变化Figure12. Changes in synchronization times and datagram.
由图12可知, 本文算法在能耗方面少于其他三种算法[7-9]. 分别比其余三种算法降低了37.46%, 61.26%和18.75%. 本文算法只需要BP神经网络反复训练即可, 与其余三种算法的原理不同, 需要的数据报文较少. 随着同步次数的增加, TSHL算法在同步过程的第二阶段需要参考节点和普通节点进行一次双向数据报文交换, 用来计算时钟漂移. MU-sync算法为追求更高的精度, 通过增加了双向数据报文的交换次数, 导致当同步次数增加时, 数据报文量快速增加. MM-sync需要提高线性拟合的次数来提高精度, 导致数据报文的消耗大.
