全文HTML
--> --> -->生物组织可视为由许多散射子构成, 组织微结构的改变会导致散射子分布变化, 从而影响超声回波信号的形状和强度. 基于超声回波信号包络形状特性的统计方法可以用于组织定征, 常用的数学模型包括: 瑞利分布[13,14]、Rician分布[15]、K分布[16]和Nakagami分布[17]等. 但应用此类模型需要先验证超声回波信号的包络特征是否可靠. 此外, 在从超声射频(radio frequency, RF)信号得到回波包络的数字信号处理过程也会导致信息损失.
熵是概率密度的函数, 与分布参数相关, 可以定量描述散射介质的微结构[18,19]. 熵分析无需预先验证信号的分布, 既可使用包络信号, 也可使用原始超声RF信号. 超声原始RF信号由于没有预压缩、平滑、对比度增强等处理, 比传统超声图像包含更多的组织结构信息[20]. 直接使用RF信号可以避免数字解调过程中对参数估计的影响, 并且不依赖于机器的个性化设置. 因此, 基于超声RF信号的熵分析, 在超声组织定征具有重要的应用前景. 另一方面, 超声在生物组织中传播时会产生不可忽略的非线性, 非线性信号可以反映生物组织的动力学信息, 因而可以提供更多的组织结构信息[21,22].
本文基于超声RF信号二次谐波的熵研究乳腺结节的良恶性定征. 采集306例乳腺结节的RF信号(包括良性158例, 恶性148例); 基于滑动窗口技术[20]实现非线性超声的熵成像, 提取包括熵、加权熵等特征参量, 使用支持向量机(support vector machine, SVM)[23-25]进行良恶性分类, 并采用交叉验证法对结果进行验证. 此外, 本文还讨论了滑动窗口大小对非线性超声熵成像效果的影响.
2.1.熵与加权熵
熵是反映信号混乱度的参数[26]. 如果信号所有位置的幅值大小相等, 熵为最小值; 如果信号所有位置的幅值大小均不相等, 且每种大小只出现一次, 熵为最大值.加权熵[27]也同样反映信号的混乱程度, 但计算公式中多了一个幅度加权因子, 可以补偿熵定义中缺失的信号幅度,
2
2.2.数据采集
从2019年4月至2020年1月, 使用彩色超声成像系统(Vinno-70, 苏州飞依诺)对306例患者进行乳腺超声扫查并保存超声原始RF信号. 数据采集采用X6-16L宽带探头(6—18 MHz), 设置在二次谐波模式, 发射频率为5 MHz, 接收频率为10 MHz. 其他参数(机械指数、成像深度、增益等)根据诊断需要设置. RF信号的采样率为50 MHz, 每帧312线, 每个病例采集20帧. 为保证采样数据格式一致, 采集时尽量将乳腺结节置于图像正中, 选取合适探头角度使得结节剖面尽可能大以便于观察.由超声科医师在RF灰度图像上手动选取感兴趣区(region of interest, ROI), 选取外切于乳腺结节的矩形区域, 要求包含结节区域, 且选取尽可能少的正常组织. 图1(a)是超声RF灰度图像和感兴趣区ROI的选取示意图, 图1(b)是某三条RF信号线的波形图, 其中RF2穿过乳腺结节.
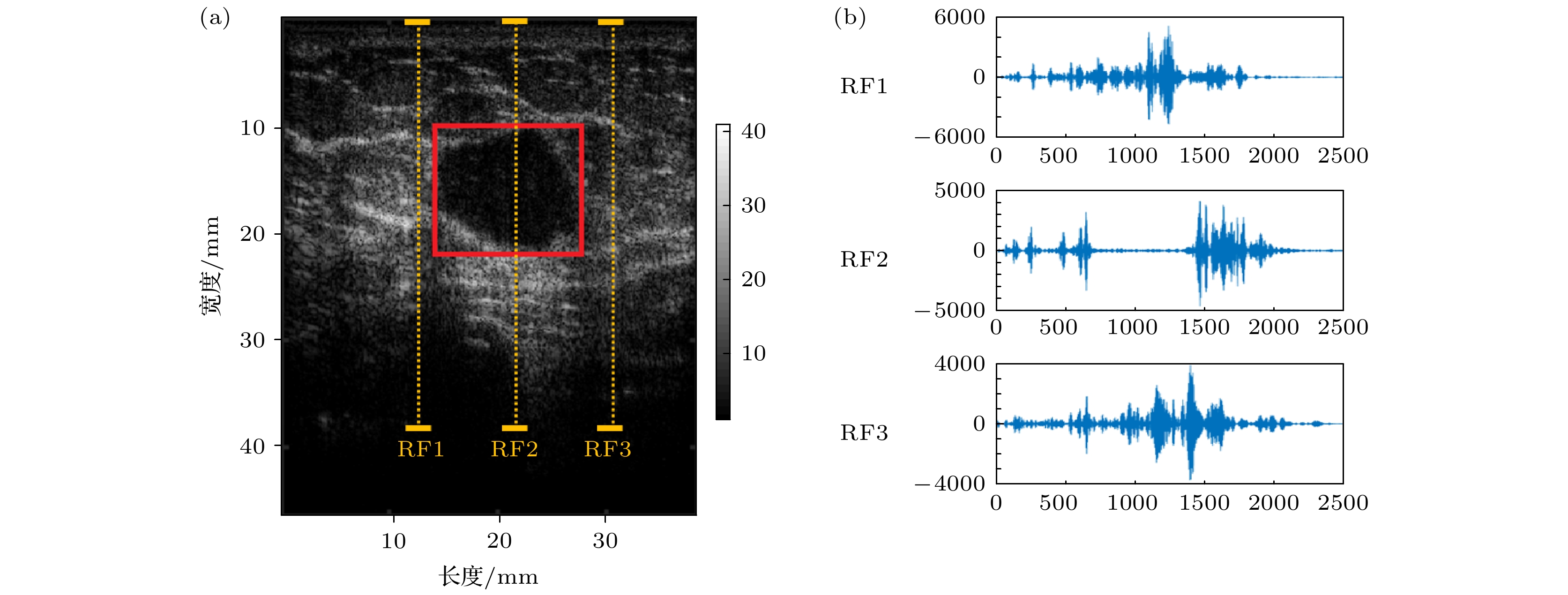 图 1 (a) 超声RF灰度图像和ROI选取示意图; (b) RF信号线的波形图
图 1 (a) 超声RF灰度图像和ROI选取示意图; (b) RF信号线的波形图Figure1. (a) Illustration of ultrasound RF gray imaging and selection of ROI; (b) waveforms of RF signals.
除熵与加权熵之外, 还提取了常用于乳腺结节良恶性诊断的其他图像参数(灰度、结节纵横比、不规则度、深度、大小). 灰度为传统超声图像的局部亮度, 反映超声在局部区域的回波强度大小. 纵横比是结节的纵向长度和横向宽度的比值, 是临床上评判结节良恶性的重要指标. 不规则度是良恶性判别的一项重要指标, 恶性结节由于细胞的分裂更易扩散, 形状更易趋向于不规则. 深度一定程度上影响结节被发现的难度, 更深的结节不易被发现因而更有可能转为恶性, 本文取ROI下边框的纵坐标作为结节的深度. 大小也与结节良恶性相关, 恶性结节由于容易扩散, 其面积会迅速增大, 而良性结节的生长相对缓慢[13]. 本文计算ROI矩形的长度与宽度的乘积, 作为结节的大小.
2
2.3.熵及加权熵成像
图2为熵及加权熵成像过程的示意图. 首先使用滑动窗口遍历整个原始RF信号二次谐波矩阵, 计算局部的概率密度函数, 并利用公式计算局部的熵或加权熵. 再对得到的新矩阵进行线性插值和上色操作, 即可得到样本所对应的熵或加权熵图像.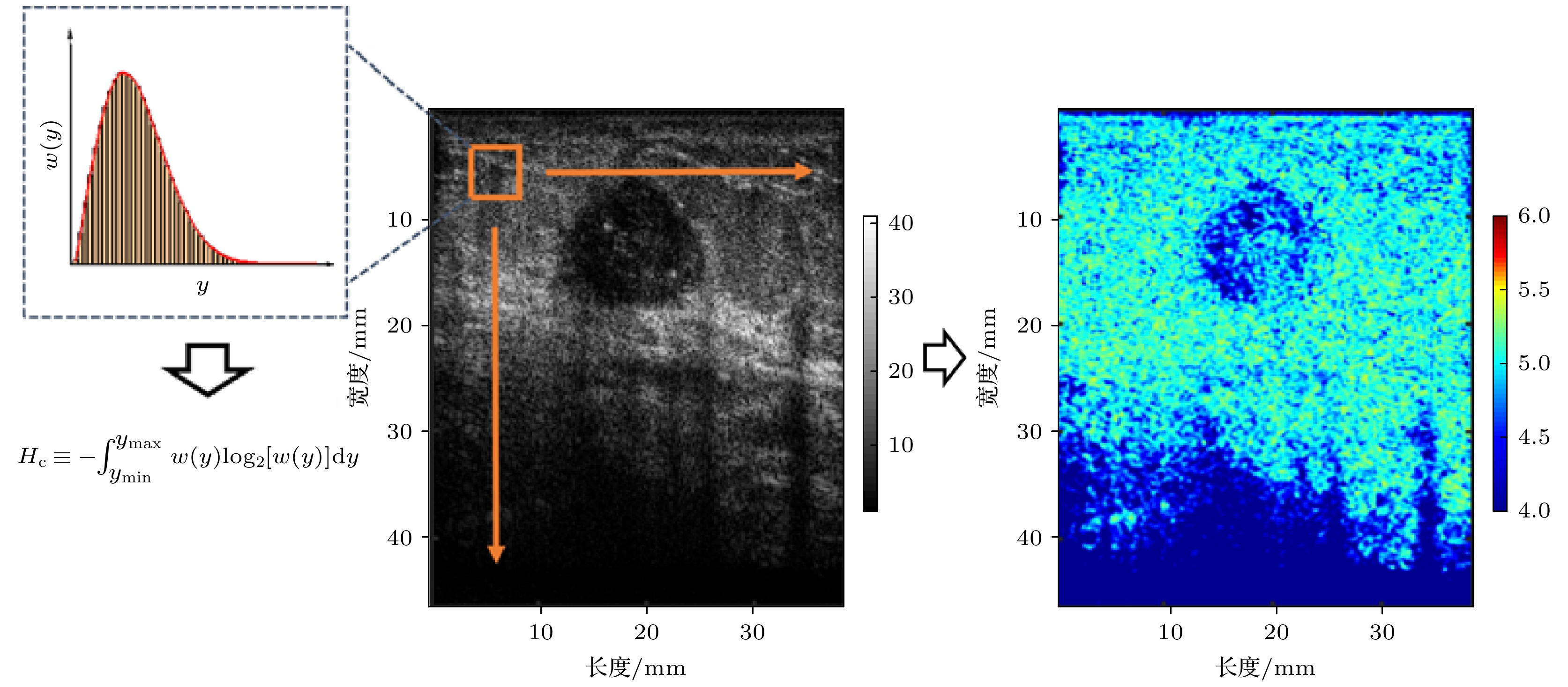 图 2 熵及加权熵成像过程示意图
图 2 熵及加权熵成像过程示意图Figure2. Illustration of entropy and weighted entropy imaging.
2
2.4.组织病理学检查
组织病理学检查作为判断乳腺结节良恶性的金标准. 将所取乳腺包块标本置于浓度10%福尔马林溶液固定, 石蜡包埋, 4 μm层厚. 脱蜡后行苏木精-伊红染色(HE染色), 使用光学显微镜进行形态学观察和图像采集分析. 对于恶性病变者予以免疫组化检测, 观察细胞染色情况.2
2.5.支持向量机分类
支持向量机是一种用于解决二分类问题的机器学习算法, 属于监督学习[31]. 其目标是在样本特征所组成的高维空间中计算出一个超平面, 最大限度地分隔两类样本, 使其到超平面的距离最大化. 在n维空间, 设超平面为

2
2.6.统计学方法
采用双样本t检验[32]来衡量所提取参数在良性和恶性两类样本之间是否具有显著差异. 使用“受试者工作特征(receiver operating characteristic, ROC) ”曲线和曲线下面积(area under curve, AUC)来评价分类结果[4].以TP (true positive), TN (true negative), FP (false positive), FN (false negative)分别表示被模型预测为正的正样本、被模型预测为负的负样本、被模型预测为正的负样本、被模型预测为负的正样本, 则真阳性率(true positive rate, TPR)、真阴性率(true negative rate, TNR)、假阳性率(false positive rate, FPR)、假阴性率(false negative rate, FNR)、准确率(accuracy)可以由下述公式计算:
本文以FPR为横轴, TPR为纵轴给出ROC曲线, AUC可以衡量分类能力. 当ROC曲线为一条对角线(纯机遇线)时, 代表分类能力为0, 对应的AUC为0.5. ROC曲线离纯机遇线越远, AUC越大, 表明分类能力越强. AUC的取值范围为0.5—1.0, 1.0代表能够完全区分.
3.1.熵及加权熵成像
本文共收集306个病例. 经过病理分析, 其中良性158例, 恶性148例. 图3和图4分别为典型的恶性乳腺癌和良性纤维瘤的病理图、RF灰度图、熵图和加权熵图. 图3(a)为乳腺癌的典型病理图, 病理表现为不规则的异型腺体在纤维间质中浸润性生长; 图4(a)为良性纤维瘤的病理图, 病理表现为增生的纤维围绕在由双层上皮构成的腺体周围. 由于结节的吸声特性, 无论恶性还是良性结节, 在RF灰度图中均呈现低回声. 相比与良性结节, 恶性结节呈现明显的直立生长特征, 纵横比明显大于1, 而良性结节只在某个层面横向延伸, 纵横比往往较小. 熵图和加权熵图上结节的轮廓与RF灰度图基本一致. 但由于良恶性结节间熵和加权熵值的统计学差异(熵约0.2, 加权熵约0.1)相对两者的整体取值范围(熵为4—6, 加权熵为1—3)较小, 单张图像无法通过熵或加权熵直观反映样本的良恶性. 后续将通过病例的定量统计表明熵和加权熵在乳腺结节良恶性区分中的作用. 图 3 某恶性结节表现 (a) 病理; (b) RF灰度图; (c) 熵图; (d) 加权熵图
图 3 某恶性结节表现 (a) 病理; (b) RF灰度图; (c) 熵图; (d) 加权熵图Figure3. Presentations of a typical malignant mass: (a) Micrograph; (b) RF grayscale image; (c) entropy image; (d) weighted entropy image.
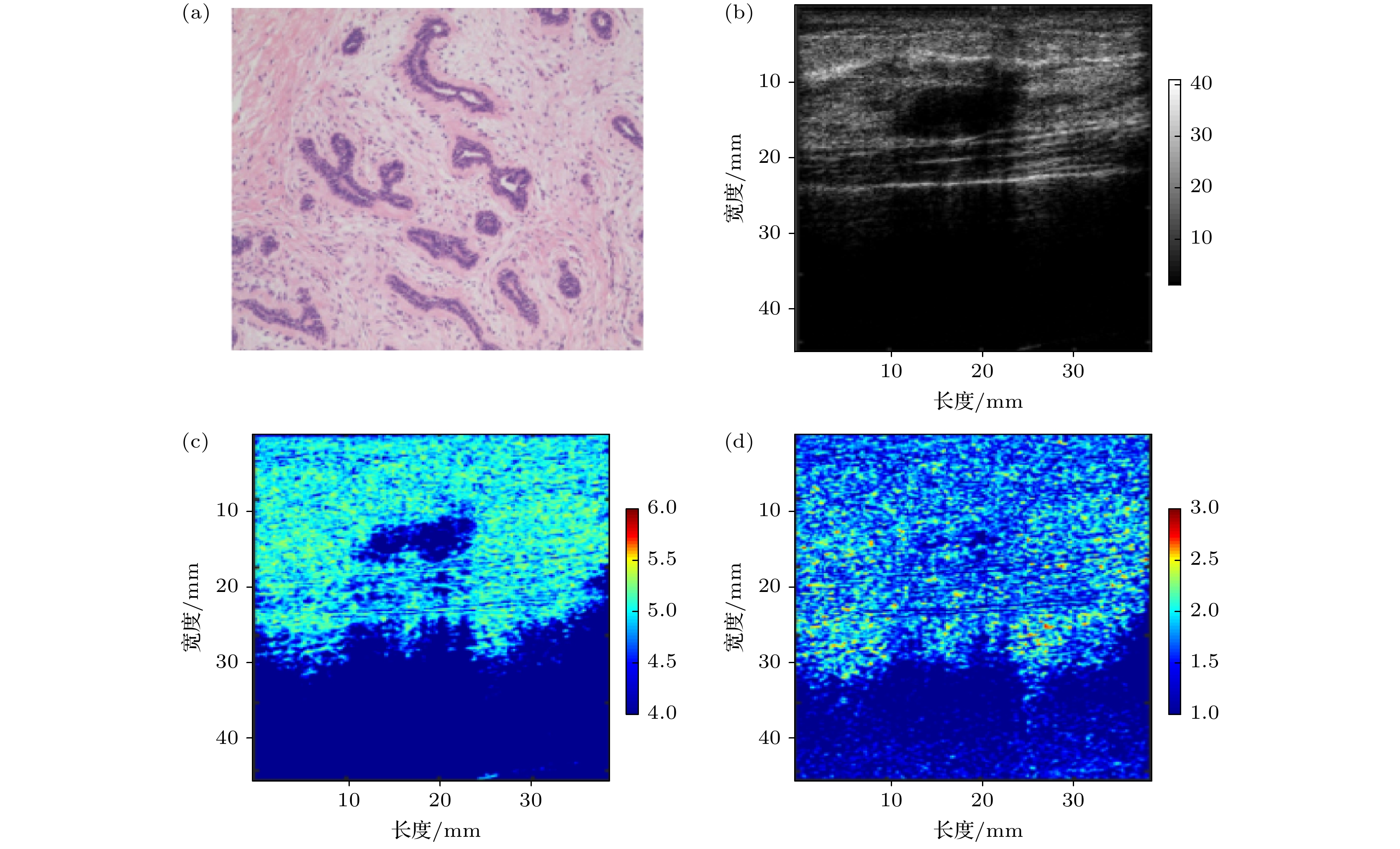 图 4 某良性结节表现 (a) 病理; (b) RF灰度图; (c) 熵图; (d)加权熵图
图 4 某良性结节表现 (a) 病理; (b) RF灰度图; (c) 熵图; (d)加权熵图Figure4. Presentations of a typical benign mass: (a) Micrograph; (b) RF grayscale image; (c) entropy image; (d) weighted entropy image
2
3.2.单参数与良恶性的相关度
使用窗长为0.5倍RF脉冲宽度(横向与纵向空间尺度一致)的矩形窗对所有样本进行熵和加权熵成像. 为了保证滑动窗在实际空间中的形状接近于正方形, 横向窗长由纵向窗长结合探头的阵元宽度(即相邻两个RF序列的间距)换算得到. 两个方向扫描的重叠率均设置为50%(即滑动步长为窗长的一半). 然后根据医生选取的ROI计算样本各项参数. 表1统计了每个参数在所有良性和恶性样本中的平均值和标准差, 并对两类样本作t检验以验证差异性. 进一步利用线性分类器对每个参数根据良恶性分类. 表1列出了各参数经线性分类器(linear-discriminant classifier, LDC)分类的准确率和ROC曲线的AUC. 由表1可见, 所提取的参数(图像灰度、纵横比、不规则度、深度、结节大小、熵、加权熵)中, 除了图像灰度以外, 均与良恶性相关, 表现为双样本t检验下, 良性和恶性的参数值有显著差异. AUC和准确率最高的两个参数是纵横比和熵, 表明这两个参数与乳腺结节良恶性的相关度较高. 纵横比作为重要的临床诊断指标, 当结节属于恶性的时候, 更倾向于直立生长, 因此高度往往会大于宽度, 导致纵横比大于1. 表1中恶性结节的纵横比(约1.06)显著高于良性结节的纵横比(约0.78). 熵表示了图像局部的混乱程度, 与细节上的毛刺、边界的清晰度等因素均有关系. 恶性结节存在边缘毛刺, 边界不清晰等特点, 会导致局部图像的混乱度增大, 因而恶性结节的熵(熵或加权熵)大于良性结节. 由表1可见, 熵的表现优于加权熵, 可能是因为图像灰度(体现RF信号强度)与良恶性无明显关联. 但加权熵依然具有69%的准确率, 可以作为对熵的补充. 此外, 不规则度、深度及大小这些参数也与结节的良恶性相关, 可以作为良恶性分类时的辅助参数.| 参数 | 平均值 ± 标准差 | 双样本t检验(p < 0.05) | 线性分类器(LDC) | |||||
| 良性 | 恶性 | 差异性 | p值 | AUC | 准确率/% | |||
| 图像灰度 | 5.01 ± 0.97 | 4.98 ± 0.93 | 否 | 0.79 | ||||
| 纵横比 | 0.78 ± 0.37 | 1.06 ± 0.36 | 是 | 6.2 × 10–12 | 0.75 | 70.6 | ||
| 不规则度 | 2.82 ± 1.07 | 3.45 ± 1.11 | 是 | 1.4 × 10–7 | 0.64 | 63.7 | ||
| 深度/mm | 16.72 ± 5.29 | 20.91 ± 5.49 | 是 | 4.1 × 10–13 | 0.72 | 66.7 | ||
| 大小/mm2 | 114 ± 142 | 171 ± 172 | 是 | 4.5 × 10–4 | 0.59 | 58.2 | ||
| 熵 | 4.64 ± 0.40 | 4.87 ± 0.15 | 是 | 6.7 × 10–12 | 0.75 | 72.5 | ||
| 加权熵 | 1.69 ± 0.13 | 1.76 ± 0.05 | 是 | 1.7 × 10–11 | 0.74 | 69.0 | ||
表1特征参数的分布
Table1.Distribution of various parameters.
2
3.3.基于SVM的良恶性分类
进一步采用不同参数组合作为特征输入, 利用SVM进行良恶性分类. 不同参数组合如下: 输入A为纵横比+不规则度、输入B为纵横比+不规则度+大小+深度、输入C为纵横比+不规则度+熵+加权熵. 图5为使用不同输入参数进行SVM训练时的ROC曲线. 当输入A时, 曲线下面积(AUC)为0.76, 准确率为72.2%. 当输入参数增加大小和深度之后, AUC提升为0.79, 准确率提高至75.5%. 当加入熵(包括熵和加权熵)时, AUC提升至0.87, 准确率提升至81.4%, 相对于输入A和B, AUC和准确率明显增加. 当输入参数为C时, 敏感性为78.4%, 特异性为84.2%.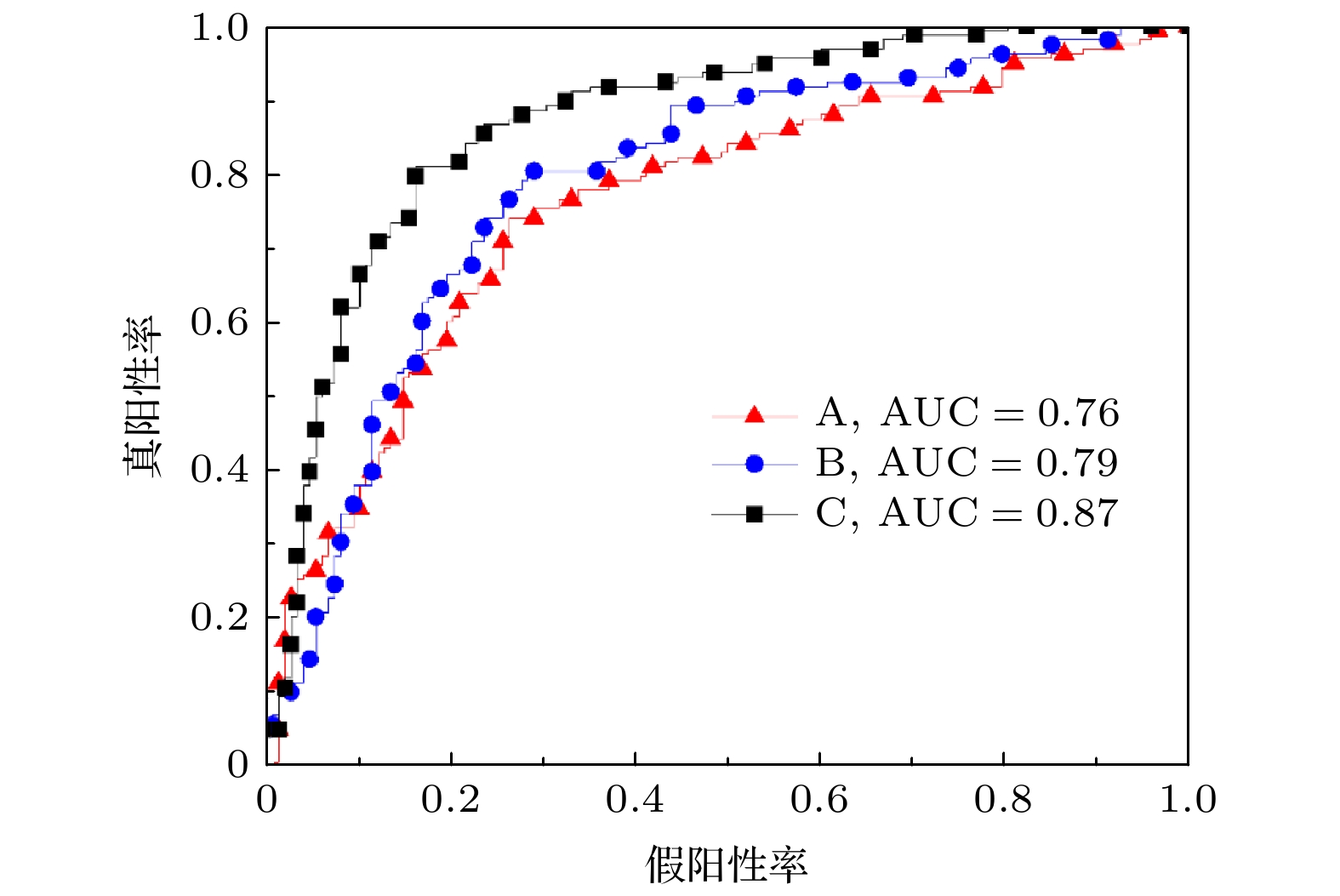 图 5 不同参数组合的ROC曲线
图 5 不同参数组合的ROC曲线Figure5. ROC curves with various input parameter combinations.
图5的结果与表1的结果相比较可以看出, 组合多个参数并使用SVM进行分类的结果要明显优于在LDC下仅使用单个参数的结果. 因为SVM可以寻找参数之间隐含的组合, 使其与良恶性的相关度比单个参数更高. 另一方面, 使用高斯核函数可以将低维输入空间线性不可分的样本, 通过非线性映射算法, 转化为高维空间线性可分的样本, 进而在高维空间建立一个线性超平面来对样本进行分类.
2
3.4.滑动窗口大小的优化
为了准确估计图像局部的熵或加权熵, 需要设置合适的滑动窗口大小. 已有研究表明, 过小或过大的窗口均会影响参数的稳定估计, 同时过大的窗口还会导致分辨率的下降[19]. 本文针对乳腺RF信号, 对滑动窗大小进行优化. 图6为同一张超声原始RF信号经过不同大小滑动窗口重构的熵图, 图7是306例乳腺RF信号经过不同大小滑动窗重构之后, 所选取的ROI中的平均熵值. 结果表明, 在滑动窗口大小等于0.5倍RF脉冲长度时, 平均熵取得最大值, 此时的熵图最为清晰明亮.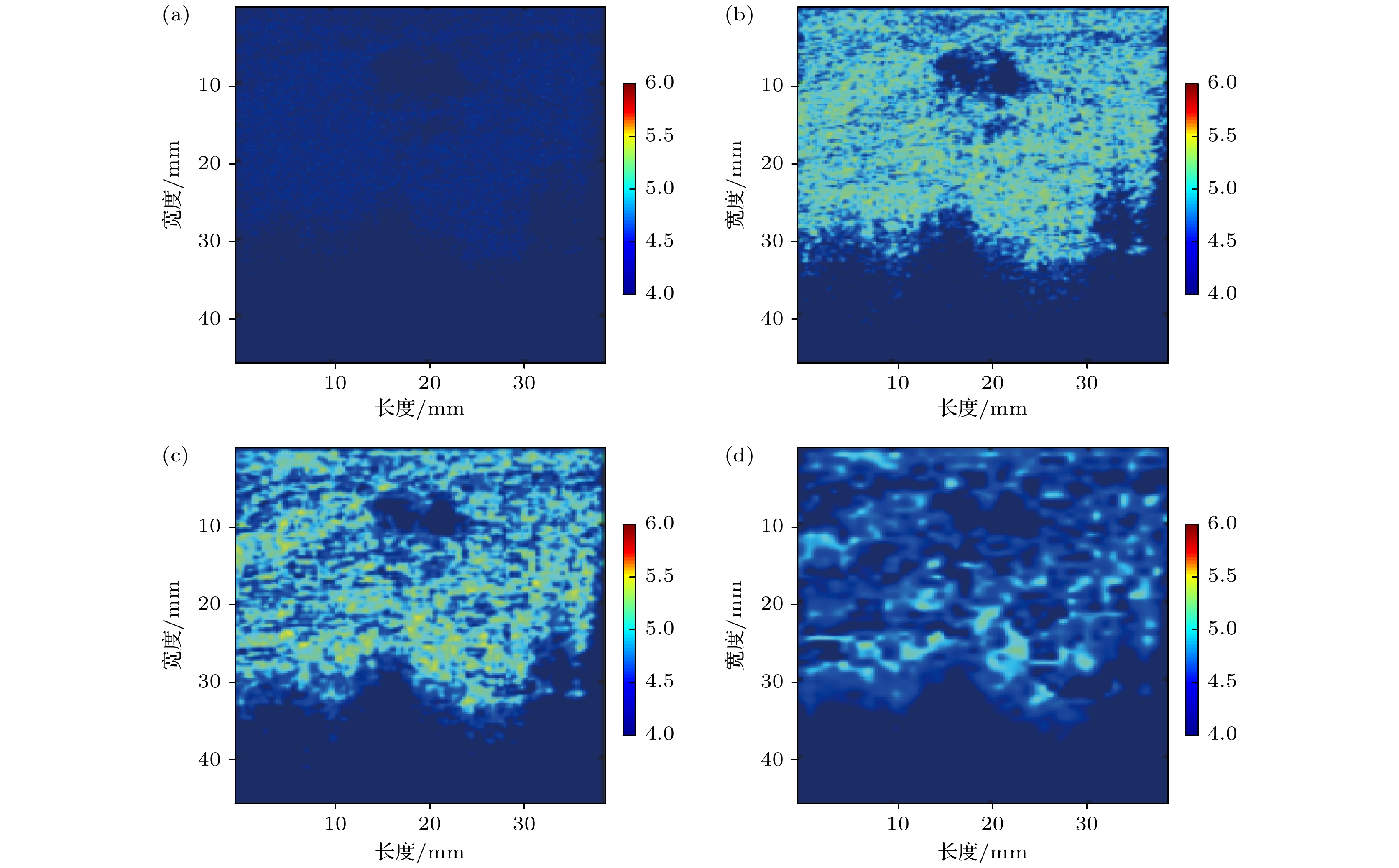 图 6 不同滑动窗口大小重构的熵图 (a) 0.2倍脉冲长度; (b) 0.5倍脉冲长度; (c) 1.0倍脉冲长度; (d) 2.0倍脉冲长度
图 6 不同滑动窗口大小重构的熵图 (a) 0.2倍脉冲长度; (b) 0.5倍脉冲长度; (c) 1.0倍脉冲长度; (d) 2.0倍脉冲长度Figure6. The reconstructed entropy images with various window sizes: (a) 0.2 times pulse length; (b) 0.5 times pulse length; (c) 1.0 pulse length; (d) 2.0 times pulse length.
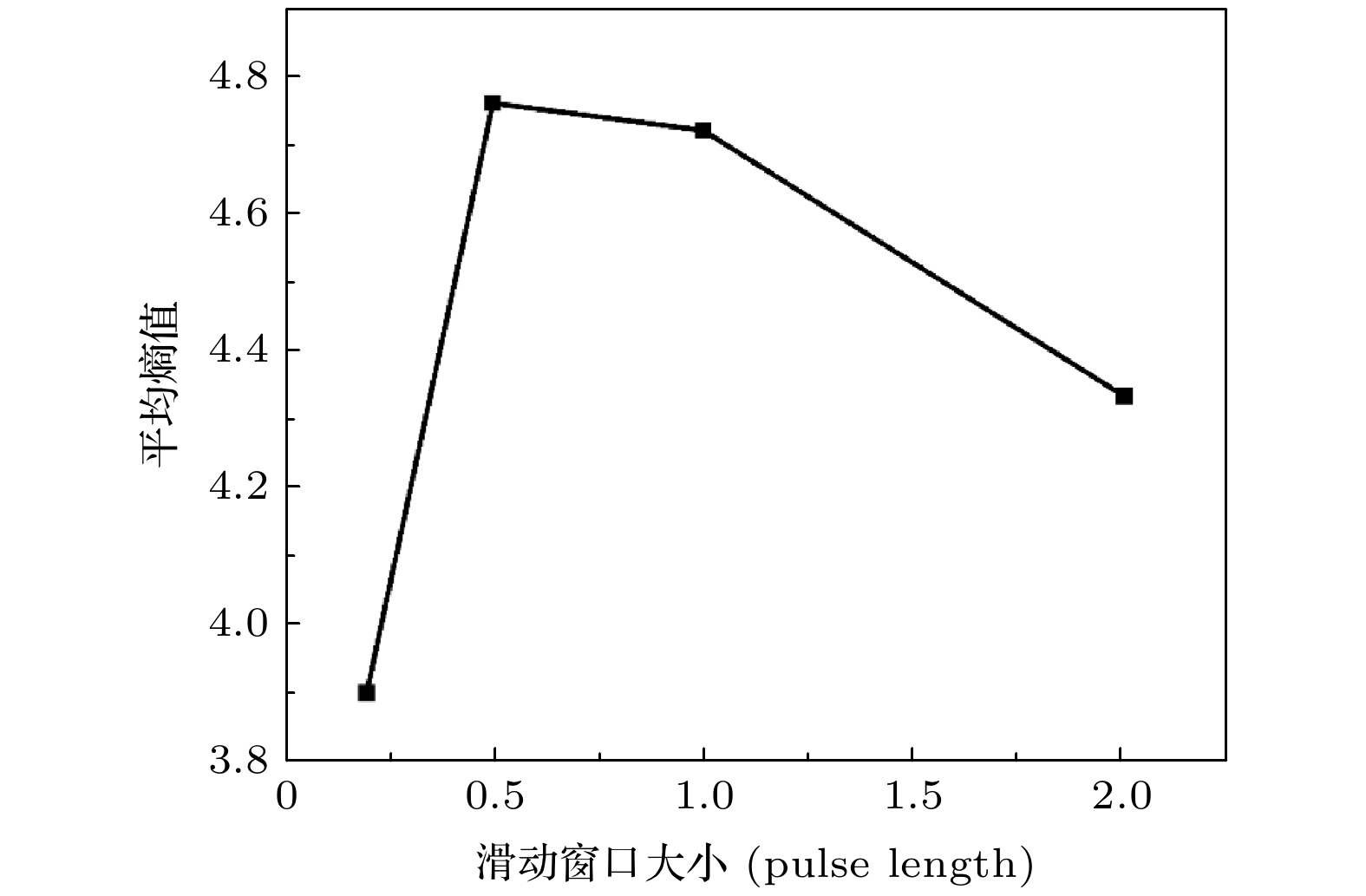 图 7 306例乳腺RF信号的平均熵值随窗口大小的变化
图 7 306例乳腺RF信号的平均熵值随窗口大小的变化Figure7. Dependence of averaged entropy on window size for 306 samples.
本文提出的乳腺结节良恶性分类方法具有较好的普适性, 适用于大多数图像清晰, 能够人工划分出ROI的乳腺结节, 对结节大小没有特殊的筛选需要. 所提取的特征既包括大小、纵横比等整体形态参数, 也包括通过滑动窗口技术提取的反映细节的熵与加权熵. 但该方法仍有一定的局限性, 主要体现在: 1) ROI选取及不规则度的评分由人工给出, 仍然具有一定的主观性; 2) 研究病例数稍显不足, 还需进一步增加样本量以对其适用性进行检验; 3)采用传统SVM进行分类, 有待结合大样本数据进行深度学习网络分类.
