1.School of Chemical Science and Engineering, Shanghai Research Institute for Intelligent Autonomous Systems, Key Laboratory of Advanced Civil Engineering Materials of Ministry of Education, Tongji University, Shanghai 200092, China 2.Shanghai Synchrotron Radiation Facility, Zhangjiang Laboratory, Shanghai Advanced Research Institute, Chinese Academy of Sciences, Shanghai 201800, China 3.School of Chemistry and Chemical Engineering, Shanghai Jiao Tong University, Shanghai 200240, China
Fund Project:Project supported by the National Key R&D Program of China (Grant Nos. 2016YFA0400900, 2016YFA0201200), the National Natural Science Foundation of China (Grant Nos. 21722310, 21834007, 21873071, 91953106), and the Fundamental Research Fund for the Central Universities, China
Received Date:30 August 2020
Accepted Date:03 November 2020
Available Online:03 March 2021
Published Online:20 March 2021
Abstract:The fabrication of precise arrays of atoms is a key challenge at present. As a kind of biomacromolecule with strict base-pairing and programmable self-assembly ability, DNA is an idea material for directing atom positioning on predefined addresses. Here in this work, we propose the construction of iron atom arrays based on DNA origami templates and illustrate the potential applications in cryptography. First, ferrocene molecule is used as the carrier for iron atom since the cyclopentadienyl groups protect iron from being affected by the external environment. To characterize the iron atom arrays, streptavidins are labelled according to the ferrocene-modified DNA strand through biotin-streptavidin interactions. Based on atomic force microscopy scanning, ferrocene-modified single-stranded DNA sequences prove to be successfully immobilized on predefined positions on DNA origami templates with high yield. Importantly, the address information of iron atoms on origami is pre-embedded on the long scaffold, enabling the workload and cost to be lowered dramatically. In addition, the iron atom arrays can be used as the platform for constructing secure Braille-like patterns with encoded information. The origami assembly and pattern characterizations are defined as encryption process and readout process, respectively. The ciphertext can be finally decoded with the secure key. This method enables the theoretical key size of more than 700 bits to be realized. Encryption and decryption of plain text and a Chinese Tang poem prove the versatility and feasibility of this strategy. Keywords:DNA origami/ atom array/ self-assembly/ cryptography
全文HTML
--> --> --> 1.引 言自20世纪50年代以来, 硅基集成电路技术的进步推动了电子计算机的蓬勃发展. 然而, 随着“自上而下”的光刻等手段不断走向尺寸极限, 电路越来越集成化、电子设备越来越小型化的要求正面临新的巨大挑战, 后摩尔时代的来临已迫在眉睫. 突破原有技术极限, 进行原子尺度的精准构筑, 是当前的重大科学问题, 也是解决下一代信息技术发展的关键. 不同于“自上而下”的光刻、操纵等手段, “自下而上”的自组装是构成生命体系的基本原理, 也充分展示出生命体从原子直到宏观的跨尺度、跨维度的精准度, 更在此基础上使生命体展现出了超乎无机材料的智能性. 受此启发, 从原子尺度进行物质的人工自组装, 通过调控基本构筑单元的物理排布与功能集成, 进而实现器件制造, 是未来的一项前沿发展方向. DNA是一类具有原子级精准度的生物大分子. 基于精确的A-T, G-C碱基配对原理, DNA单链之间可以形成具有碱基序列特异性的双链结构—即著名的DNA双螺旋结构, 此外DNA也能够形成三链[1]、四链[2]等结构. 特定序列的DNA单链可通过人工化学合成获得, 而通过设计并合成DNA序列, 就能够实现可编程性自组装构建人工DNA纳米结构. 这些DNA纳米结构可看作由若干DNA链在空间上进行排布, 进而形成的人工框架结构, 由于框架上的每个碱基位置都是可定位的, 因此也为功能基元在框架上的定点修饰提供了可能[3,4]. DNA框架结构中最为著名的是DNA折纸(DNA origami)结构[5], 组装原理是由约200多条20—60碱基的订书钉链(staple)引导一条7000多碱基的骨架链(scaffold)以类似光栅填充的形式折叠而成, 具有良好的结构稳定性和可编程设计性, 能够设计构建任意二维和三维结构[6]. DNA折纸在结构上可看作一种具有精确寻址功能的模板, 经常被用作有机染料分子[7]、核酸[8]、蛋白质[9-11]、无机纳米颗粒[12-15]、碳纳米管[16,17]等的阵列构建, 在光电器件[18]、生物医药[19-21]、信息处理[7,22,23]等领域取得了一系列重要应用. 本文首次基于DNA折纸结构的精准寻址性, 进行原子阵列的自组装构筑. 由于原子的化学稳定性问题, 实验选取二茂铁分子为研究对象, 通过两个茂基使铁原子处于稳定的化学状态, 再通过化学共价修饰将二茂铁准确定位在DNA折纸的指定位置上, 构成受茂基保护的铁原子阵列图案. 为了展示此材料的应用潜力, 结合前期发展的DNA折纸加密技术(DNA origami cryptography, DOC)[24], 发展了基于原子阵列的加密技术(A-DOC). 通过对DNA序列及自组装过程的编码, 将明文加密成密文隐藏于铁原子阵列中, 并借助单分子成像手段进行密文的读取, 最后使用正确密钥进行解密. 该策略在原子层面上整合了加密术和隐写术, 理论上适用于文本、数字、图片等各类信息的加密, 为信息安全的发展提供了一种具有巨大潜力的生物分子解决方案. 2.“信息预置”思路制备铁原子阵列图案本文提出的铁原子阵列图案构建思路如图1所示, 与通常的DNA折纸组装方法不同, 本文采用了一种具有“信息预置”特点的思路(图1(a)). 首先, 根据最终阵列图案的要求, 将用于固定二茂铁基团的订书钉链先与长骨架链杂交结合. 这个过程等同于将铁原子阵列信息“预置”于骨架链上, 因此, 这些订书钉链被称为“信息链”(M-strand, M链)(补充材料的图S1 (online)). 第二步, 携带信息链的骨架链经过纯化后与一套通用订书钉链集合(universal staples)进行退火, 形成折纸结构, 此时的折纸在预定放置铁原子阵列的位点上具有相同的一段捕获序列. 为了将二茂铁基团在折纸结构上进行固定, 即形成铁原子阵列, 实验中采用了修饰有二茂铁的DNA序列, 通过分子识别与折纸上的捕获序列杂交结合(图1(b)). 在修饰二茂铁的序列另一端修饰了生物素分子(biotin)使铁原子阵列能够以成像的方式被观测到. 这是因为生物素分子能够特异性地与链霉亲和素(streptavidin, SA)结合, 而后者能够被原子力显微镜(atomic force microscope, AFM)清晰成像, 从而可通过观测SA阵列来验证设计的铁原子阵列形状. 因此, 修饰有二茂铁与生物素的序列可被称为“显影链”(N-strand, N链), 而SA就是“显影剂”. M链与骨架链结合部分的长度为40个碱基(补充材料的图S2 (online)), M链延伸端与N链序列互补. 图 1 铁原子阵列的构建 (a), (b) 信息链预置于骨架链上的策略形成DNA折纸并组装铁原子阵列, 通过生物素和链霉亲和素的强结合力将位置显影; (c)—(e) 3个位点单个铁原子图案组装原子力表征图(比例尺: 100 nm) Figure1. Fabrications of iron atoms arrays. (a), (b) The M-strand strategy forms DNA origami and assembles the iron atoms arrays. The position is visualized by the strong binding force of biotin and streptavidin. (c)–(e) The atomic force characterization diagram of the assembly of a single iron atom at three sites (scale bar: 100 nm).
需要指出的是, 本思路的实现基于对DNA杂交反应热力学和动力学过程的严格调控. 在预置有M链的骨架链与通用订书钉链集合共同退火时, M链的长度以及退火温度决定了能否避免未期望的解离以及设计图案的生成. 一方面, M链的长度可以通过模拟计算确定, 需特别注意的是要避免M链在骨架链上形成来回折叠, 以及由于M链的独特设计对于周围其他订书钉链的影响. 结果显示, M链与骨架链杂交长度设计为40碱基时, 与普通订书钉链比较, 在能量上具有较大优势(补充材料的图S3 (online)). 另一方面, 退火温度的选择可以进一步避免预置M链的脱落, 根据模拟结果, 在起始温度设置为57 ℃、M链与骨架链结合长度为40个碱基时, 未配对比例仅为3.5%; 而对于普通订书钉链, 与骨架链的未配对比例, 相比M链高了至少2倍以上. 与通常制备DNA折纸结构的思路不同, 将信息链预置于骨架链上极大降低了实验工作量. 设单个折纸的订书钉链数量是s, 阵列中的铁原子数量是m, 按常规做法需要将m条信息链去替代对应的普通订书钉链, 即需要将m条信息链与s-m条剩余普通订书钉链逐条混合, 然后再和1条骨架链混合, 总计需要s + 1个混链步骤. 需要指出的是, 如果制备另一个不同的铁原子阵列, 前述混合的样品将完全不能使用, 而是再重新经过s + 1个步骤获得新的样品. 以图1所示的十字形折纸为例, 共有201条普通订书钉链, 如果用于制备图1(c)—(e)中的3个不同图案, 需要606个混链步骤. 但是, 使用“信息预置”的方法, 只需混合1个包含201条普通订书钉链的通用库, 然后根据图案的不同单独将信息链与骨架链混合即可, 总计需要207个混链步骤. 如果一次制备的通用订书钉链集合的量非常巨大, 不再考虑构建此集合的步骤, 此方法将进一步节省工作量, 仅需6步就能完成. 为了验证此方法的有效性, 对铁原子在十字形折纸的3个不同位置上的组装效率进行了测试, 如图1(c)—(e)所示, 分别是棱角上、棱中点和折纸面上. 由于二茂铁和生物素是同步修饰在N链两端, AFM下观测到SA的正确组装即说明生物素和二茂铁都固定在正确的位置上. 结果显示, 这3个不同位置的组装效率均在90%以上, 分别为96.3%, 97.3%, 90.3%. 最终图案的高效组装决定于三方面的高效率: 一是M链在骨架链上的高效结合, 二是显影剂N链高效地与M链延伸段杂交, 三是SA与生物素的结合效率. SA与生物素的结合被公认为亲和能力很强, 以上结果验证了本方案在M链和N链的结合上也具有高效率, 因此实现折纸上铁原子阵列构建的有效性. 3.“一锅法”同时制备不同铁原子阵列图案采用“信息预置”的另一个更为重要的优势, 是能够实现以“一锅法”同时批量制备多种不同的阵列图案. 如图2(a)所示, 将携带不同M链的3条DNA骨架链进行混合, 然后与通用订书钉链集合进行退火, 可以在一锅内制备出三种铁原子点阵图案. 其实现原理是, 信息链M从能量上保护了杂交位置的骨架链, 使普通订书钉链难以与骨架链杂交, 即替换下M链; 携带不同M链的骨架链之间同样也不会发生串扰. 从结果看, 该方法成功获得了所设计的三种点阵图案, 且观察到的图案比例分布与各骨架链的比例一致, 这证实了订书钉链对M链与骨架链的结合几乎没有影响. 此外, 也没有观察到两个图案点出现在同一个折纸上的情况发生, 说明没有发生不期望的解离并结合到别的骨架链的情况(图2(b)). 图 2 M链策略“一锅法”制备多种DNA折纸纳米图案 (a) 多种携带不同M链的骨架链混合, 一同退火, 在单个离心管中快速制备多种DNA折纸纳米图案; (b) 原子力表征图及产率统计图(比例尺: 200 nm) Figure2. M-strand strategy to prepare a variety of DNA origami nanopatterns by “one-pot” method: (a) A variety of scaffolds carrying different M-strands are mixed and annealed together to quickly prepare a variety of DNA origami nanopatterns in a single centrifuge tube; (b) AFM diagram and yield statistics (scale bar: 200 nm).
其中m是单个折纸可用的位点数量, $ {P}_{i}^{m} $是m的i种替换可能. 在本研究中, m取值为12, 这导致密钥大小约为32位. 由于骨架链的折叠强烈依赖于通用订书钉链的序列信息, 所以窃密者需要掌握完整的订书钉链序列信息才能重现折纸折叠形状, 使A-DOC具有了很大的密钥空间. 基于骨架链的序列、长度和折叠的难以预测性, 对骨架链或订书钉链进行蛮力攻击实际上是非常困难的. 假设存在聪明的窃密者(命名为Eve), 他可以以某种方式拦截从Alice传递给Bob的骨架链. 实际上, 在交付过程中用伪造品代替DNA的可能性很小. 另一方面, 若想重现折纸折叠形状和上面的图案信息, Eve需要费力地测序, 之后必须破解DNA折纸中骨架的特定路径和滑动, 任何因素的任何变化将导致图案变化. 通过简化模型预测, 对于7249个核苷酸的M13 mp18链, 密钥大小可能达到702位($K_{{\rm{DOE}}}^M = \left\lfloor { {L}/{{10.5}}} \right\rfloor + {\log _2}L$, L为骨架链长度), 而现有高级加密标准(AES)的密钥大小最大仅为256位. 如果使用更长的骨架链(例如p7560和p8064), 理论密钥大小可进一步提升为732和780位. 在以上工作基础上, 进一步提出了多折纸编码单字符的设计, 对字符串长度和可编码字符容量进行了提升, 并以加密唐诗《登鹳雀楼》为例进行演示(图4). 根据汉字代码标准GB2312的规定, 汉字按94个“区”和94个“位”分区索引, 可以看作一个横竖各有94个格子的正方形棋盘, 每个格子对应一个汉字或者符号. 其中1—9区为符号区, 16—87区为汉字编码区, 其他为用户自定义编码区. 如图4(a)所示, 本文使用两个不同标记的十字折纸, 对于第一个折纸, 12个可识别位点中5个黑色点位代表在字符串中的位置信息, 容量为25; 7个蓝色的位点①—⑦编码汉字的区, 称为区码 (section code), 信息容量可达128位(27), 超过了国标规定94位的需求. 同样另一个折纸以相同的五个黑色点位代表位置信息, 对应第一个折纸, 红色的7个点位①—⑦代表在该区所处的位, 称为位码(postion code). 通过两个折纸位置信息匹配读取信息就可得到汉字信息和这个汉字在文本中所处的位置. 在图4(b)中演示了该编码规则的实例, 对于汉字“流”, 根据区码表得到它的区码为33、位码为87, 代表它在区码表中处于33行87列的位置. 然后将区码和位码分别转换为二进制数据, 区码二进制为“0100001”, 位码二进制为“1011101”, 根据红色和蓝色序号的循序依次写入. 同时根据它在诗中的位置定义了它的位置码为15, 即“01110”. 图 4 将汉字在DNA折纸上的加密方案 (a) 区位码在折纸上的编码原理; (b)汉字“流”的编码演示; (c) 28个汉字唐诗文本AFM实验图(比例尺: 40 nm); (d)唐诗随扫描次数收集完成度和错误率图, 正确收集标记为红色, 单个链霉亲和素图案未收集超过20个的标记为白色 Figure4. Scheme of encoding Chinese characters on DNA origami: (a) Encoding principle of section and position code on origami; (b) demonstration of Chinese encoding Chinese character “流” on DNA origami (scale bar: 100 nm); (c) AFM experimental graph of 28 Chinese characters Tang poetry text (scale bar: 40 nm); (d) collection completion and error rate graphs of Tang poetry with the number of scans completed and error rate graphs. The correct collection is marked as red, and the single streptavidin pattern which is not collected for more than 20 will be marked as white.
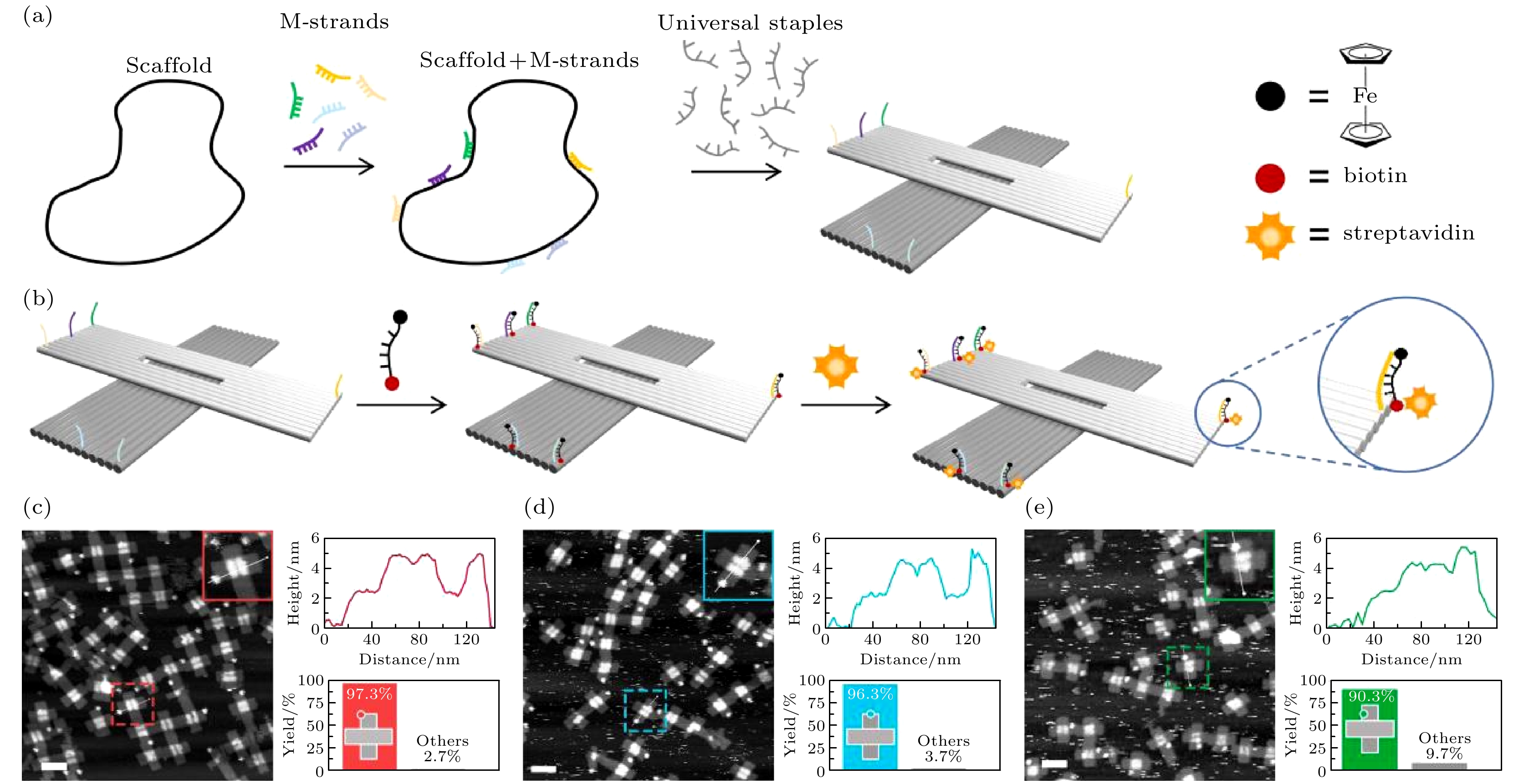 图 1 铁原子阵列的构建 (a), (b) 信息链预置于骨架链上的策略形成DNA折纸并组装铁原子阵列, 通过生物素和链霉亲和素的强结合力将位置显影; (c)—(e) 3个位点单个铁原子图案组装原子力表征图(比例尺: 100 nm)
图 1 铁原子阵列的构建 (a), (b) 信息链预置于骨架链上的策略形成DNA折纸并组装铁原子阵列, 通过生物素和链霉亲和素的强结合力将位置显影; (c)—(e) 3个位点单个铁原子图案组装原子力表征图(比例尺: 100 nm)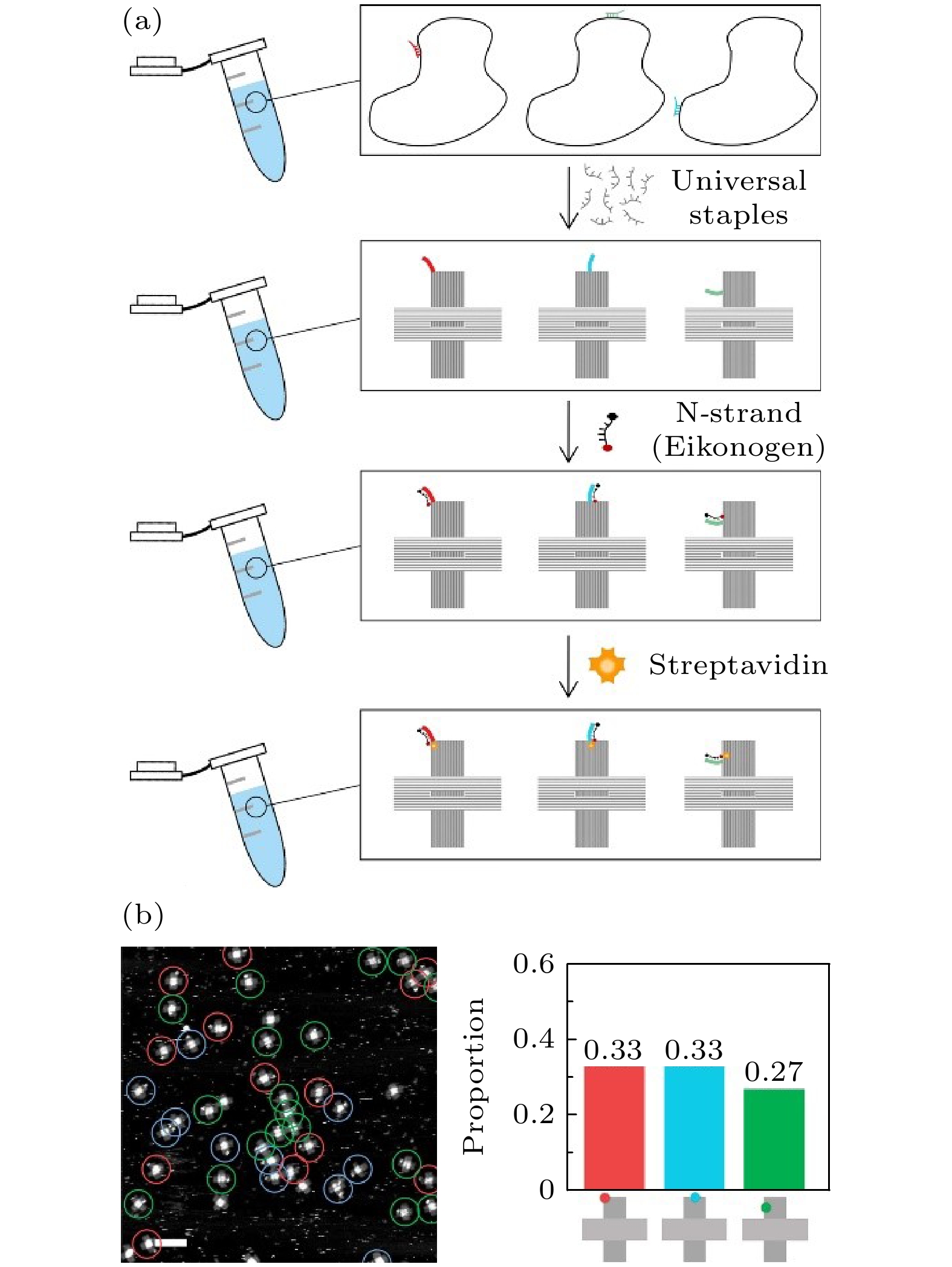 图 2 M链策略“一锅法”制备多种DNA折纸纳米图案 (a) 多种携带不同M链的骨架链混合, 一同退火, 在单个离心管中快速制备多种DNA折纸纳米图案; (b) 原子力表征图及产率统计图(比例尺: 200 nm)
图 2 M链策略“一锅法”制备多种DNA折纸纳米图案 (a) 多种携带不同M链的骨架链混合, 一同退火, 在单个离心管中快速制备多种DNA折纸纳米图案; (b) 原子力表征图及产率统计图(比例尺: 200 nm)

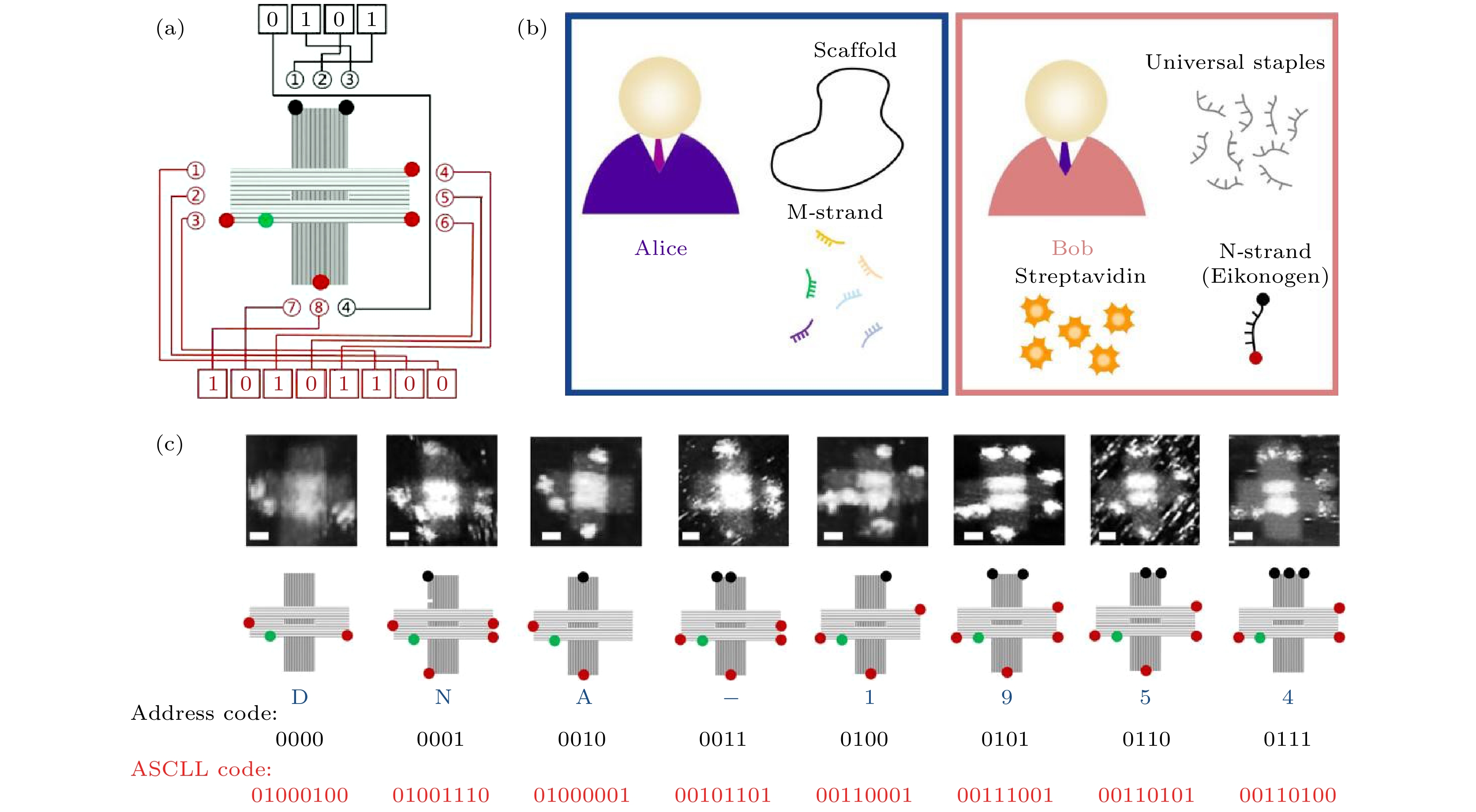 图 3 DNA折纸加密及编码原理示意图 (a) DNA折纸斑点编码原理; (b) 发送者(Alice)和接收者(Bob)通信流程; (c) 文本“DNA-1954”的编码演示(比例尺: 25 nm)
图 3 DNA折纸加密及编码原理示意图 (a) DNA折纸斑点编码原理; (b) 发送者(Alice)和接收者(Bob)通信流程; (c) 文本“DNA-1954”的编码演示(比例尺: 25 nm)

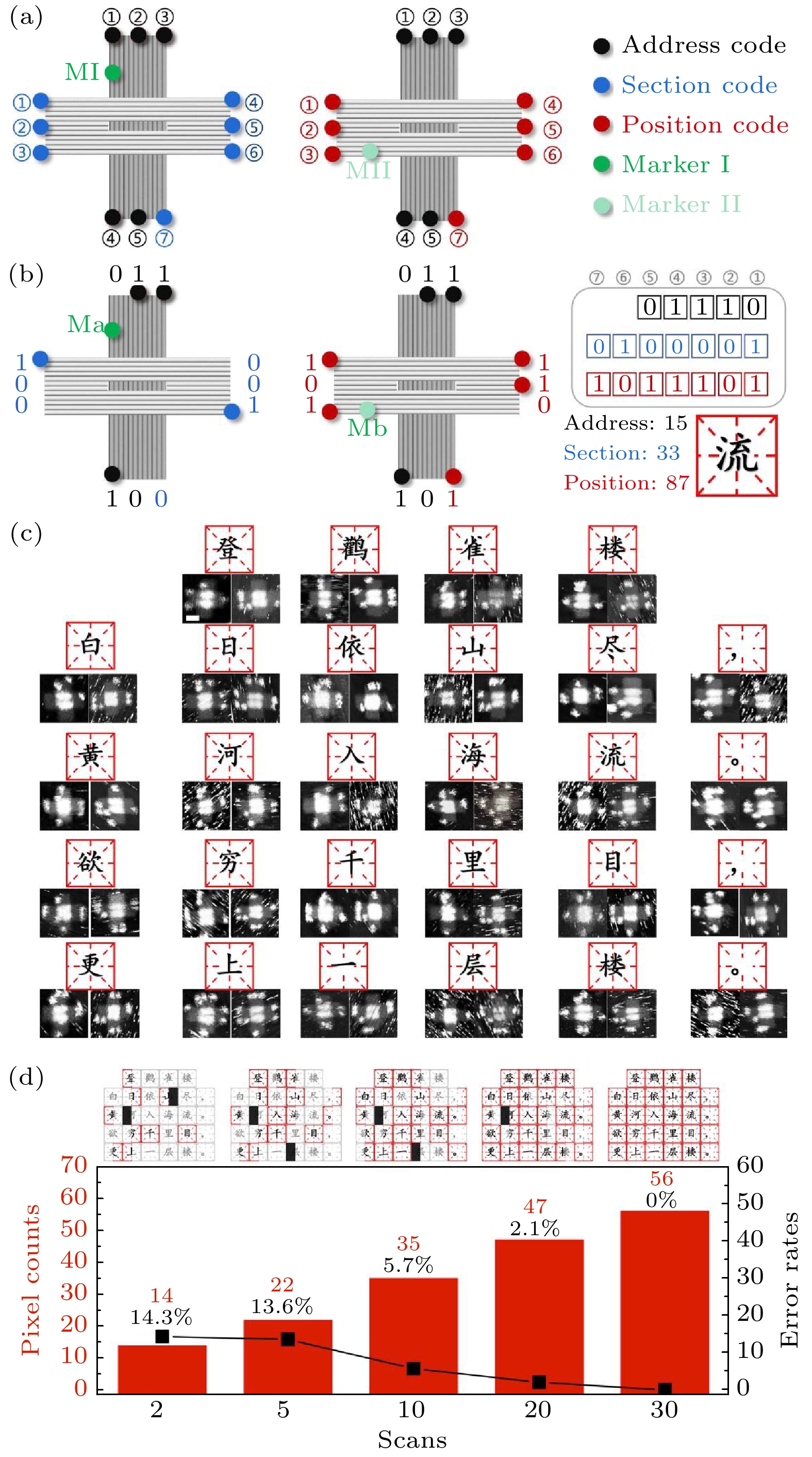 图 4 将汉字在DNA折纸上的加密方案 (a) 区位码在折纸上的编码原理; (b)汉字“流”的编码演示; (c) 28个汉字唐诗文本AFM实验图(比例尺: 40 nm); (d)唐诗随扫描次数收集完成度和错误率图, 正确收集标记为红色, 单个链霉亲和素图案未收集超过20个的标记为白色
图 4 将汉字在DNA折纸上的加密方案 (a) 区位码在折纸上的编码原理; (b)汉字“流”的编码演示; (c) 28个汉字唐诗文本AFM实验图(比例尺: 40 nm); (d)唐诗随扫描次数收集完成度和错误率图, 正确收集标记为红色, 单个链霉亲和素图案未收集超过20个的标记为白色