全文HTML
--> --> -->目前, 光场稠密重建主要包括基于压缩感知[1,2]、视角合成[3-5]和深度学习[6]的稠密重建方案. 基于压缩感知的稀疏光场重建方案, 提供了一种比奈奎斯特采样定理更有效的稀疏信号采集框架[7], 减少了光场采集所需的相机数量, 但是该方案由于编码掩膜对光线的阻碍作用损失了部分光信号的强度信息, 导致重建的图像信噪比较低, 光场质量下降. 基于视角合成的方案包括基于模型的视角合成(mode-based rendering, MBR)和基于图像的视角合成(image-based rendering, IBR)方法. 由于复杂场景建模困难, MBR仅适应于简单场景. 对于IBR, 由于存在平移、遮挡等因素, 使得部分场景信息丢失, 深度图求取不准确, 从而产生“空洞”[8]和裂纹[9,10], 由于无法获取被遮挡目标的颜色信息使得合成图像产生失真. 基于深度学习的稠密重建方法利用光度立体技术进行虚拟视角表面重建取得了很好的效果, 但是需要大规模稠密采样的数据集, 网络泛化能力差, 而且该技术在光场稠密重建中应用困难[6]. 虽然现有方法都能完成光场稠密重建, 但是由于自身算法限制均不能很好地适用实际应用的需求.
鉴于此, 本文从压缩感知的基本原理出发, 分析光场图像数据间的冗余特性[11], 自然场景在本质上存在的稀疏结构特性, 充分利用光场全局与局部的空间-角度约束关系, 提出一种基于过完备字典学习的稀疏光场稠密重建算法. 将本文算法应用到各种场景的稠密重建中, 结果表明算法能够有效地对虚拟视角进行恢复, 提高光场角度分辨率.
2.1.稀疏采样光场的稠密重建原理
根据光场成像的基本原理可知空间场景光场是对目标光辐射的方向、强度和光谱等信息的参数化表示, 反映了光辐射在三维空间中的位置分布与传播方向之间的映射关系, 是三维空间中光线集合的完备表示[12,13]. 特定场景光场信号具有完备性, 在空间和角度上又具有冗余性, 根据压缩感知的基本原理[14], 可以将其投影到一个低维稀疏空间中, 稀疏编码的低维数据能更好地反映原始数据的本质特征. 同一场景目标多视角信息在空间和角度信息的关联性和冗余性, 表现为稀疏表示域中各向量的稀疏性、非零元素位置及其值之间的相互约束关系. 这样, 就可以将图像及其字典学习和稀疏编码过程限制在比待恢复的光场维度低得多的空间中[15], 再通过域间变换的稀疏系数重构就可以合成虚拟视角图像[16].算法流程如图1所示. 由线性相机阵列获取特定场景的稀疏4D光场后, 通过固定窗口逐像素遍历光场图像的方法将其在所有通道上分解为互有重叠的图像碎片, 这些图像碎片按顺序构成初始二维观测值矩阵, 以此训练光场字典并进行稀疏编码. 经光场字典编码的观测值各元素之间具有稀疏性约束关系, 在该约束关系下计算虚拟角度稀疏表示矩阵, 再通过稀疏逆变换就可以构建出虚拟角度图像, 完成光场稠密重建.
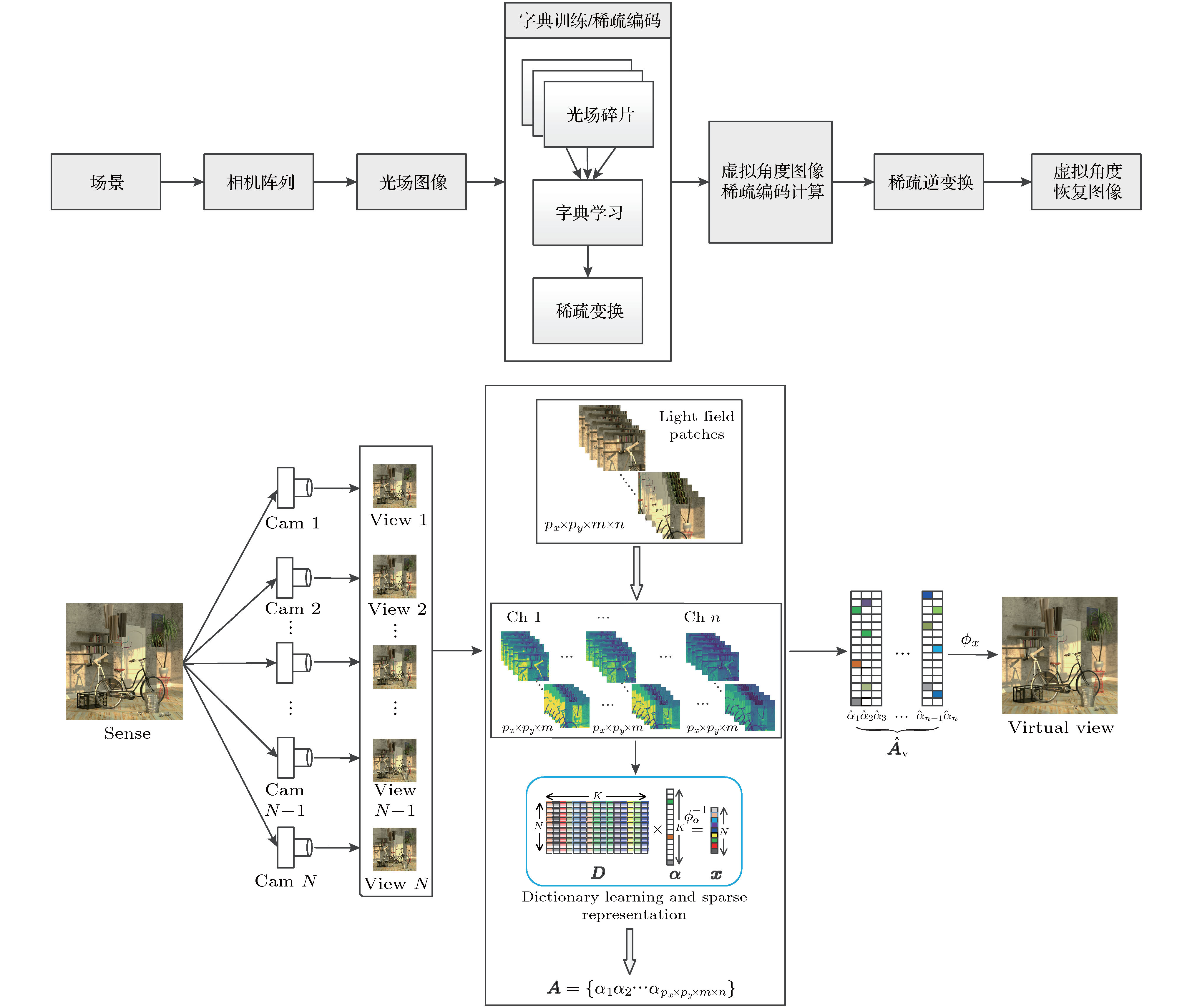 图 1 算法架构图
图 1 算法架构图Figure1. Algorithm workflow.
2
2.2.稠密光场重建算法
假设
光场字典训练与稀疏编码问题是光场图像稀疏逼近的逆问题, 将光场的线性稀疏性约束转化到约束函数中, 则光场的稀疏表示模型可以表示为
不同角度的光场图像之间形成了严格的全局约束, 邻近的互有重叠的光场碎片采样之间形成了强有力的局部约束, 这些空间-角度约束关系都经由过完备字典线性映射到了图像的稀疏表示域. 光场图像碎片化观测值可以表示为




 图 2 光场过完备字典
图 2 光场过完备字典Figure2. Light field overcomplete dictionary.
在低维稀疏变换空间中将高维信号重建问题转换为低维特征向量的表达问题[20], 可以更加简洁、有效地恢复虚拟视角. 假设光场的虚拟角度图像为Iv, 相应的稀疏域中系数矩阵为



假设H为Hilbert空间,




1)实验1 稀疏编码矩阵的稀疏度是一个重要的参数, 决定了在重构图像时对基矩阵中基础结构元素的选择, 直接影响重构图像的质量以及字典训练时间. 字典的冗余度决定了基矩阵的规模, 也就决定了字典中含有的自然场景中基础元素的数量. 图像碎片的尺寸与字典的特征维度直接相关, 而原子的尺寸与字典的冗余度成正比, 能够影响光场的局部一致性, 同时, 重建时间随着探测器分辨率和原子尺寸的增加而线性增加, 最终会影响到重构图像的精细程度. 因此在设计算法时采用稀疏度、冗余度、原子尺寸3个参数来优化设置相关参数.
选择数据集中相对简单的场景table作为实验对象进行初始参数选择. 为了有效缩短程序运行时间, 将图像转换为灰度图像后进行实验. 如图3(a)和图3(b)所示, 首先设定字典规模为N = 256, 在不同分辨率的训练集上构建虚拟视角图像. 在稀疏度K = 34时, 均方误差(mean squared error, MSE)都达到极值, 而结构相似度(structural similarity index measure, SSIM)也都达到了相对较大值. 从图3(c)可以看出, 峰值信噪比(peak signal-to-noise ratio, PSNR)在不同分辨率、相同稀疏度的实验中变化趋势差异不明显, 在K = 16时达到极值. 由于稀疏编码是由筛选出的少量的字典原子对原信号进行线性表示, 因此, 本文算法可以在一定的稀疏度范围内快速构建出高质量图像. 固定稀疏度参数K = 34, 再次进行实验, 随着字典冗余度的增加, 构建的图像的质量逐渐提高, 冗余度在N = 896时达到平稳状态. 如图3(d), 当N = 256时, 3个定量评价指标都达到总体指标的70%以上, 综合考虑计算能力及重建时间, 冗余度N = 256为理想的重建参数值. 同时, 实验中发现

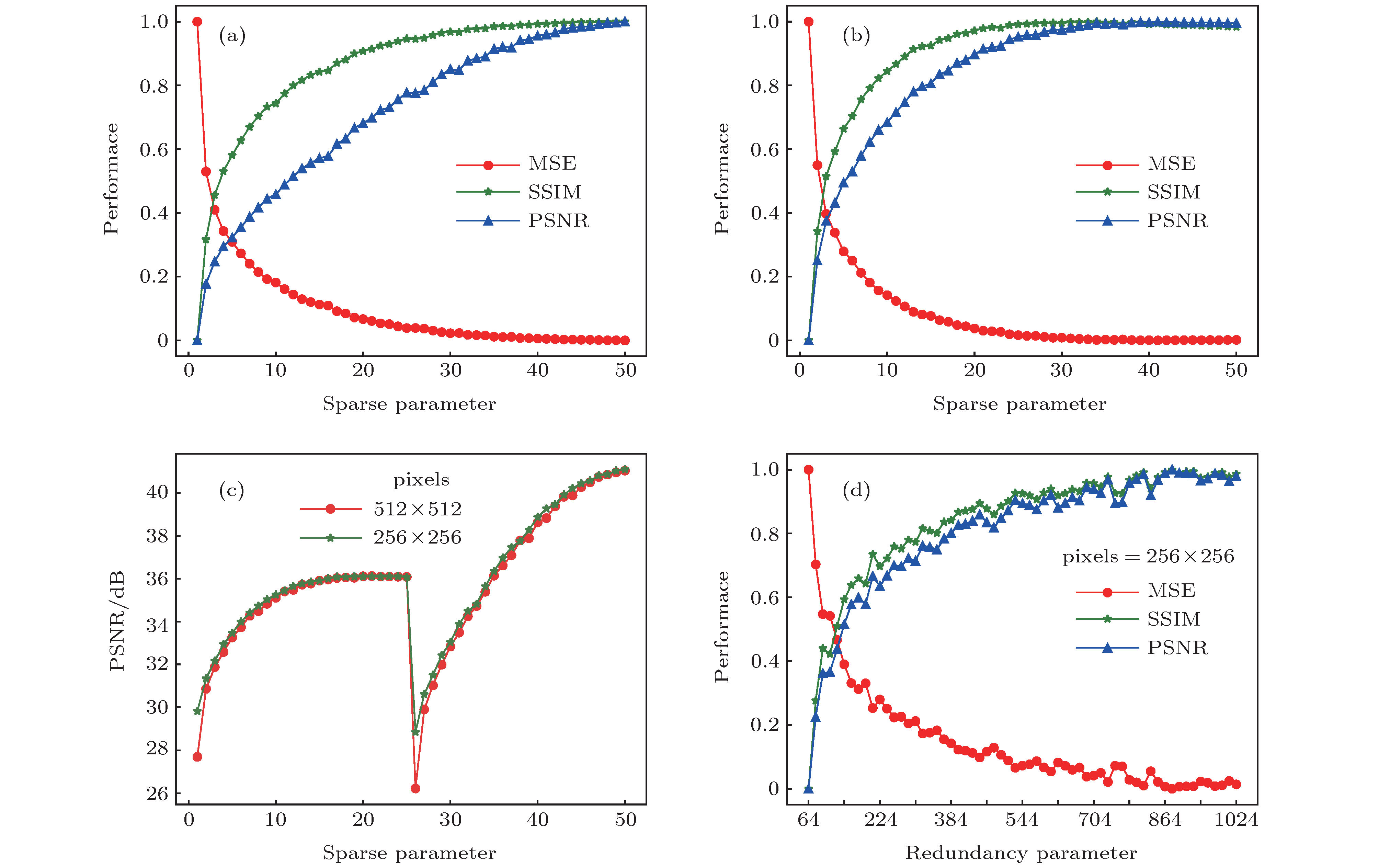 图 3 重建图像质量曲线图 (a) pixels为256 × 256, 不同稀疏度重建性能曲线图; (b) pixels为512 × 512, 不同稀疏度重建性能曲线图; (c) 不同分辨率重建图像的PSNR曲线图; (d) pixels为256 × 256, 不同冗余度重建性能曲线图
图 3 重建图像质量曲线图 (a) pixels为256 × 256, 不同稀疏度重建性能曲线图; (b) pixels为512 × 512, 不同稀疏度重建性能曲线图; (c) 不同分辨率重建图像的PSNR曲线图; (d) pixels为256 × 256, 不同冗余度重建性能曲线图Figure3. Performance of reconstructed image: (a) Performance in sparsity, pixels = 256 × 256; (b) performance in sparsity, pixels = 512 × 512; (c) PSNR in different resolution; (d) performance in redundancy, pixels = 256 × 256.
为了验证所选参数对于不同的复杂场景的适应性, 选择数据集中bicycle场景进一步进行实验, 该场景在不同的深度上表现出复杂的光照阴影变化信息. 图4(a)和4(b)分别为选取不同稀疏度、冗余度参数时, 虚拟视角图像的重建结果. 如表1所列, 稀疏度与冗余度的提高会极大地增加计算时间, 对硬件设备的计算能力要求也较高, 因此我们最终实验时选择稀疏度为K = 16, 冗余度为N = 256.
| Sparse parameter (K), Redundancy parameter (N) | MSE | PSNR/dB | SSIM | Time/s |
| K = 16, N = 256 | 54.4215 | 30.7731 | 0.8860 | 1266.08 |
| K = 34, N = 1024 | 49.0044 | 31.2285 | 0.8865 | 14306.55 |
表1不同稀疏度、冗余度重建图像质量指标
Table1.Performance of image reconstruction in different sparsity and redundancy
 图 4 不同稀疏度、冗余度参数重建图像 (a) K = 16, N = 256; (b) K = 34, N = 1024
图 4 不同稀疏度、冗余度参数重建图像 (a) K = 16, N = 256; (b) K = 34, N = 1024Figure4. Image reconstruction in different sparsity and redundancy: (a) K = 16, N = 256; (b) K = 34, N = 1024
2)实验2 为了验证算法对遮挡、视差信息恢复的有效性, 选取数据集中包含明显遮挡区域的场景table进行重建.
图5(a)给出了包含两个恢复的虚拟视角图像的1 × 9光场, 光场的空间和角度连续性得以保持. 图5(b)和图5(e)分别为光场的最左、最右侧视角的图像, 作为参考视图. 场景中台灯灯罩为前景目标, 其对后景抽屉上的空洞处造成了明显遮挡, 图5(c)和图5(d)为恢复的两个虚拟视角图像. 从图中的红色方框区域放大图可以清晰地看到算法精确地恢复了场景中局部被遮挡目标的信息, 有效地保持了图像局部颜色一致性. 恢复图像与参考图像之间, 恢复的两个角度图像之间视差明显, 算法有效地恢复了场景光场图像的视差信息. 图5(g)和图5(h)为目标图像, 图5(f)和图5(i)为残差图, 两个虚拟视角的残差总体水平都较低, 可见重建虚拟视角图像在不同深度上对目标的恢复质量较高.
 图 5 包含遮挡目标的稠密光场恢复 (a) 稠密光场; (b), (e) 参考图像; (c), (d) 恢复的view 2, view 5虚拟角度图像; (g), (h)目标图像; (f), (i) 残差图
图 5 包含遮挡目标的稠密光场恢复 (a) 稠密光场; (b), (e) 参考图像; (c), (d) 恢复的view 2, view 5虚拟角度图像; (g), (h)目标图像; (f), (i) 残差图Figure5. Dense reconstruction of light field with occluded targets: (a) Dense light field; (b), (e) reference images; (c), (d) reconstructed virtual images of view 2 and view 5; (g), (h) target images; (f), (i) residual images.
3)实验3 选取数据集中包含自遮挡目标、高低频信息丰富的场景rosemary进行实验, 并与基于深度的图像绘制算法(depth image based rendering, DIBR)重建结果进行对比. 如图6(a)所示为本文算法恢复的虚拟角度图像, 树叶的自遮挡区域中恢复的边缘信息较为明显, 低频信息较为一致, 算法能够对特征相似、深度不同的目标进行高质量重建, 并能对场景中的光照阴影进行恢复, 残差也处于较低水平. 图6(b)为DIBR算法恢复的图像, 图中可以看到存在明显的裂纹, 放大区域可以观察到明显的空洞, 零值像素为无效像素, 恢复图像的局部颜色一致性较差, 所示的定量评价指标为去除恢复图像右侧无效像素后计算所得, 由于空洞和裂缝的存在, 重建图像的峰值信噪比较低.
 图 6 稠密光场恢复 (a) 本文算法恢复图像; (b) DIBR算法恢复图像; (c) 目标图像; (d) 残差图; (e)稠密光场
图 6 稠密光场恢复 (a) 本文算法恢复图像; (b) DIBR算法恢复图像; (c) 目标图像; (d) 残差图; (e)稠密光场Figure6. Dense reconstruction of light field: (a) Reconstructed image for proposed algorithm; (b) reconstructed image for DIBR; (c) target image; (d) residual image; (e) dense light field.
将本文算法应用于多种不同场景进行重建实验, 选择稀疏度K = 16, 冗余度N = 256, 重建结果如表2所列, 结果表明本文提出的方法对不同场景的适应性较好, 能够对稀疏光场进行高质量的稠密重建.
| Sense | Table | Bicycle | town | Boardgames | rosemary | Vinyl | bicycle* |
| MSE | 21.2124 | 54.4215 | 25.8005 | 53.9244 | 18.8950 | 22.4756 | 49.0044 |
| PSNR/dB | 34.8649 | 30.7731 | 34.0145 | 30.8129 | 35.3673 | 34.6137 | 31.2285 |
| SSIM | 0.9323 | 0.8860 | 0.9474 | 0.9341 | 0.9699 | 0.9421 | 0.8865 |
| * 稀疏度K = 34, 冗余度N = 1024. | |||||||
表2不同场景光场稠密重建结果
Table2.Dense reconstruction of light field in different scenes.
实验结果表明DIBR重建方法有一定的局限性, 由于遮挡、平移等因素的存在, 在深度图的求取过程中, 被遮挡目标的深度信息无法获取, 使得视角合成过程中会产生“空洞”; 又由于像素渗透, 在边缘处往往会产生裂缝, 使合成图像质量大幅下降. 而基于深度学习的方法中, 自遮挡目标由于遮挡物与被遮挡物特征相似度极高, 使得算法无法对目标进行有效区分从而导致局部重建失败[24].
本文方法应用于稠密光场重建取得了较好的结果. 重建的虚拟角度光场图像中的纹理信息清晰, 表明有限的四维光场数据也存在较高的冗余性, 可以在一定场景范围内构建近似完备的光场数据集, 通过训练得到的小规模全局光场字典包含了该场景中几乎全部的特征, 稀疏编码仅通过几个训练得到光场原子的线性组合就能够恢复光场中的复杂结构信息, 这正是利用了自然场景光场在结构上存在稀疏性, 在特征上存在冗余性; 重建图像中的遮挡、视差以及复杂的光照阴影变化信息的恢复, 说明四维光场的空间-角度约束关系得到保持, 碎片化降维构建光场训练集的方法对于特征选择和变换域数据间相关性保持是有利的.
本文方法目前仅适应于对线性相机阵列获取的光场进行稠密重建, 而实际应用中相机阵列的排布方式是多样的, 这就使得变换域编码构建模型的构建变得困难. 后续研究将围绕非线性相机阵列光场稠密重建展开.
