全文HTML
--> --> -->对于网络中节点影响力排序问题, 最简单高效的方法是度中心性[1], 它反映节点的邻居数, 例如微博中拥有粉丝数多的大V用户就具有很高的传播影响力. 后来, Chen等[2]又给出了一个局部中心性指标, 该指标考虑了二阶邻居数, 但这两个指标在反映节点传播影响力时没有考虑传播概率的影响, 也无法充分反映节点的局部拓扑结构. 对于全局性的指标有介数中心性[3]、接近度中心性[4]、K核[5]、特征向量中心性[6]等. 而对于多源影响力极大化(influence maximization)问题, 最初由Domingos和Richardson[7]提出, 后被Kempe等[8]证明该问题是NP-Hard难问题. 一种最简单的选取策略就是选出某指标值最大的若干节点作为传播源, 但这种算法选出的各传播者之间可能会有较大影响力重叠. 因此, Leskovec等[9]采用贪心算法来寻求初始传播集, 但这种算法的复杂度较大不适用于大型网络. Chen等[10]提出两种改进的贪心算法新贪心算法和最大贪心算法, 这两种改进算法均比贪心算法的算法复杂度要低, 但在大型网络中仍具有较高算法复杂度. 后来, 一些特殊的启发式算法被提出, 度折扣算法[11]就是其中一种高效的启发式算法, 它是对探索式算法的一种优化策略的改进, 具有较高的实用价值, 其基本思想为当节点的邻居节点已被选为传播源时, 会对该节点的度指标产生折扣效应, 从而达到了去重叠的目的. 再后来, Kimura等[12]利用分解极大连通子图来寻找最优传播源, 基于此, 又提出了利用最大影响路径的方法[13], 这种方法虽然大大降低了了算法复杂度, 但限制了只能在最短路径上传播. Wang等[14]提出了一种结合动态规划的算法选择最优传播源, 提升了算法效率, Li等[15]考虑积极消极影响力, 提出了一种新的模型, 尽管这些算法效率都很高, 但很容易陷入局部最优的情况, 效果不及贪心算法.
在线社交网络具有规模庞大, 结构复杂的特点, 运用节点的局部信息指标描述节点的传播影响力更具现实意义. 但目前的局部性指标均不能够很好的刻画节点的局部拓扑结构, 因此本文基于独立级联模型, 提出一种描述节点有限步传播范围期望的指标—传播度. 对于网络中的任一节点作为传播源, 我们充分分析信息在局部网络中的传播路径, 设计了一种精确的递推算法计算有限步后传播范围的期望值, 之后通过真实网络数据集仿真验证了该指标与节点传播影响力具有更高一致性. 另一方面, 在考虑多传播源影响力极大化问题时, 选择的各传播源影响力会发生重叠, 因此基于传播度提出了一种启发式算法—传播度折扣算法, 同样通过真实网络数据集仿真验证了该算法相较于经典方法具有更好的效果.
本文的主要贡献在以下几个方面:
1)提出了描述网络节点传播能力的指标—传播度, 用于描述节点在有限步后能够传播到网络节点范围的期望值. 并设计了计算该指标的迭代算法, 可以高效的计算节点的任意阶(步数)的传播度.
2)相较于传统指标, 传播度指标考虑了传播概率对节点传播的影响. 对于小型网络, 可以直接利用该算法计算节点的最终传播期望; 对于大型网络, 可利用低阶传播度刻画节点的传播影响力, 充分利用了节点的局部拓扑结构信息.
3)对于多传播源问题, 基于传播度指标提出了一种传播度折扣的算法, 能有有效地去除不同初始传播源间的影响力重叠, 相较于原有的度折扣算法有更好的选择效果.
2
2.1.辅助算法一
为了更清楚地反映初始传播源的传播情况, 将节点的局部拓扑结构转化成树的形式, 并定义为该传播源的传播树, 该算法称为传播树算法. 根据信息在网络中的传播路线, 传播树是基于特定的单个种子节点的网络的另一种拓扑表示(简单的例子见图1). 图1(b)为图1(a)的传播树, 传播树的生成规则如下: 图 1 一个简单网络例子 (a)网络图; (b)图(a)对应的传播树
图 1 一个简单网络例子 (a)网络图; (b)图(a)对应的传播树Figure1. A simple network example: (a) The network diagram; (b) the corresponding propagation tree of (a).
Step 1 确定一个种子节点作为

Step 2 将种子节点的邻居作为种子节点的孩子, 记为

Step 3 对于



Step 4 若



2
2.2.传播度的计算公式及辅助算法二
32.2.1.传播度的计算公式
在2.1节传播树概念的基础上, 先引入几个参量, 用









3
2.2.2.辅助算法二
由2.2.1节的介绍, 关键问题在于如何计算联合概率





















| 辅助算法二 | 联合概率算法 |
| 输入 | 时间t, 节点u以及对于u的序号集W |
| 输出 | 联合概率${{{f}}_{{t}}}\left( {{{{u}}_{{W}}}} \right)$ |
| 1. | if W只含一个元素 then |
| 2. | 找到该节点的双亲节点${{{v}}_{\left( {{i}} \right)}}$ |
| 3. | ${{{f}}_{{t}}}\left( {{{{u}}_{{W}}}} \right) = {{{f}}_{{{t}} - {{1}}}}\left( {{{{v}}_{\left( {{i}} \right)}}} \right) \times {{\beta }} \times \left( {{{1}} - {{{p}}_{{{t}} - {{1}}}}\left( {{u}} \right)} \right)$ |
| 4. | else |
| 5. | 找到传播树种${{{P}}_{{t}}}$代序号集为W的u节点, 记其双亲节点为${{{v}}_{{1}}}, {{{v}}_{{2}}}, \cdots , {{{v}}_{{l}}}$, 出现次数为$ m_1, $$ m_2, \cdots , m_l$, 这些路径对于双亲节点的序号集分别为${{{X}}_{{1}}}, {{{X}}_{{2}}}, \cdots , {{{X}}_{{l}}}$, 对于节点u的序号集分别为${{{Y}}_{{1}}}, {{{Y}}_{{2}}}, \cdots {{{Y}}_{{l}}}$. |
| 6. | for ${{j}} = 0 \to {{l}}$ do |
| 7. | ${{{f}}_{{t}}}\left( {{{{u}}_{{{{Y}}_{{j}}}}}} \right) = {{F}}\left( {{{t}} - {{1}}, {{{v}}_{{j}}}, {{{X}}_{{j}}}} \right) \times {{\beta }}$ |
| 8. | end for |
| 9. | ${{{f}}_{{t}}}\left( {{{{u}}_{{W}}}} \right) = \left[ {{{1}} - \mathop \prod \nolimits_{{{j}} = {{1}}}^{{l}} \left( {{{1}} - {{{f}}_{{t}}}\left( {{{{u}}_{{{{Y}}_{{j}}}}}} \right)} \right)} \right] \times \left( {{{1}} - {{{p}}_{{{t}} - {{1}}}}\left( {{u}} \right)} \right)$ |
| 10. | end if |
| 11. | return ${{{f}}_{{t}}}\left( {{{{u}}_{{W}}}} \right)$ |
表1联合概率算法
Table1.Joint probability algorithm
2
2.3.传播度递推求解
由方程(6)可知, 在计算



| 递推算法 | 求种子节点s阶传播度 |
| 输入 | seed, ${{\beta }}$, s |
| 输出 | ${{{d}}_{{s}}}$ |
| 1. | ${\rm Tree }_{s} = {\rm FTree }(\rm seed)$ %获取节点${{seed}}$的s阶传播树 |
| 2. | 赋初值${ { {p} }_{ {0} } }\left( { { {\rm seed} } } \right) = { { {f} }_{ {0} } }\left( { { {\rm seed} } } \right) = { {1} }$, 其他情况${{{p}}_{{t}}}\left( {{u}} \right) = {{{f}}_{{t}}}\left( {{u}} \right) = {{0}}$ |
| 3. | for ${{t}} = {{1}} \to {{s}}$ do |
| 4. | for ${{{u}}_{{y}}} \in {{{P}}_{{t}}}$ do %遍历传播树中${{{P}}_{{t}}}$代的个体 |
| 5. | 获得${{{u}}_{{y}}}$的双亲节点${{{v}}_{{x}}}$ %表示节点u所在传播树层中第x个u节点 |
| 6. | ${{{f}}_{{t}}}\left( {{{{u}}_{{y}}}} \right) = {{{f}}_{{{t}} - {{1}}}}\left( {{{{v}}_{{x}}}} \right) \times {{\beta }} \times \left( {{{1}} - {{{p}}_{{{t}} - {{1}}}}\left( {{u}} \right)} \right)$ |
| 7. | end for |
| 8. | for ${{u}} \in {{{P}}_{{t}}}$ do |
| 9. | 获得u的序号集W %指${{{P}}_{{t}}}$代节点u出现次序构成的集合 |
| 10. | 计算联合概率${{{f}}_{{t}}}\left( {{u}} \right) = {{F}}\left( {{{t}}, {{u}}, {{W}}} \right)$ |
| 11. | end for |
| 12. | for $u \in {\rm Tree}_{s}$ do |
| 13. | ${{{p}}_{{t}}}\left( {{u}} \right) = {{{p}}_{{{t}} - 1}}\left( {{u}} \right) + {{{f}}_{{t}}}\left( {{u}} \right)$ |
| 14. | end for |
| 15. | end for |
| 16. | ${ { {d} }_{ {s} } }\left( { { \rm{seed} } } \right) = \mathop \sum \nolimits_{ {u} } { { {p} }_{ {s} } }\left( { {u} } \right)$ |
| 17. | return ${{{d}}_{{s}}}$ |
表2种子节点s阶传播度的算法流程伪代码
Table2.Pseudocode of the algorithm flow for s order progpagation of the seed node.
2
2.4.仿真验证
综上所述, 对于一个网络, 确定初始种子节点, 先用传播树算法得到相应的传播树, 在利用递推算得到任何时刻任意节点的期望值
 图 2 (a)不同仿真次数下的近似传播期望值和传播度随时间的变化; (b)不同仿真次数的近似传播期望值与传播度的方差变化
图 2 (a)不同仿真次数下的近似传播期望值和传播度随时间的变化; (b)不同仿真次数的近似传播期望值与传播度的方差变化Figure2. (a) Approximate propagation expectation and the degree of propagation over time for different simulation times; (b) variance of the approximate propagation expectation and the degree of propagation of different simulation times.
由图2可知, 模型计算的期望值是精确的. 有了传播度的指标后, 便可以用该指标来反应节点的传播影响力.
对于小型网络, 可以直接计算最高阶的传播度来反应节点的传播影响力, 该方法有两方面优势. 一方面, 在现实中, 出于商业考虑, 可能不会选取明显较优的核心节点, 如图1小型网络中的1号节点, 因此, 进一步比较2, 3号, 甚至5, 6, 7, 8号节点的传播影响力优劣具有重要意义. 另一方面, 网络中节点的传播影响力是与传播概率相关的, 而传播度指标可以很好地将传播概率融入到刻画节点传播影响力中去.
如图1所示, 节点最多传递四步, 因此利用上述方法计算所有节点的四阶传播度来反映节点的传播影响力. 为了比较各节点传播影响力的大小以及验证节点的传播影响力与传播概率相关, 图3给出了不同传播概率下各节点四阶传播度的变化情况.
 图 3 图1中的网络各节点4阶传播度(归一化)随传播概率变化
图 3 图1中的网络各节点4阶传播度(归一化)随传播概率变化Figure3. Changes of the 4th degree of propagation (normali-zed) of network node in Fig. 1 with the propagation pro-bability.
由图3可知, 随着传播概率不断增加, 各节点的传播影响力排序会发生明显变化, 且可以量化比较各节点传播影响力大小. 当传播概率较大时, 可以选择普通的节点作为传播源, 兼顾成本和传播能力两个方面. 后文将主要关注传播度在大型网络中识别高传播影响力传播源的作用展开详细讨论.
2
3.1.单个节点的影响力排序
由传播度的定义知道, 一阶传播度为d1 =

2
3.2.传播度折扣解决多源影响力极大化问题
关于多源传播影响力极大化问题, 一般采用启发式算法, 然而不同传播源的传播影响力会有较多“重叠”部分, 因此在算法进行的过程中需要采用去重叠过程. 由于定义的传播度是基于概率期望的, 基于这一特性, 去重叠过程是十分简便的, 下面进行理论分析.考虑s阶传播度, 计算出所有节点的s阶传播度, 选择最大的一个节点加入种子节点集R的第一个节点, 其各节点的传播期望为






2
3.3.模型总述
综上所述, 算法的总流程图如图4所示. 从新定义的传播度指标出发, 充分考虑节点所有可能就近的传播路径和传播概率的大小, 分别对单源节点影响力排序问题和多源影响力极大化问题给出了解决方案. 对于小型网络, 我们在2.4节中指出, 可以计算最高阶的传播度从而可以精确的找出最优传播源. 对于大型网络, 将在第4节详细验证该模型的优势.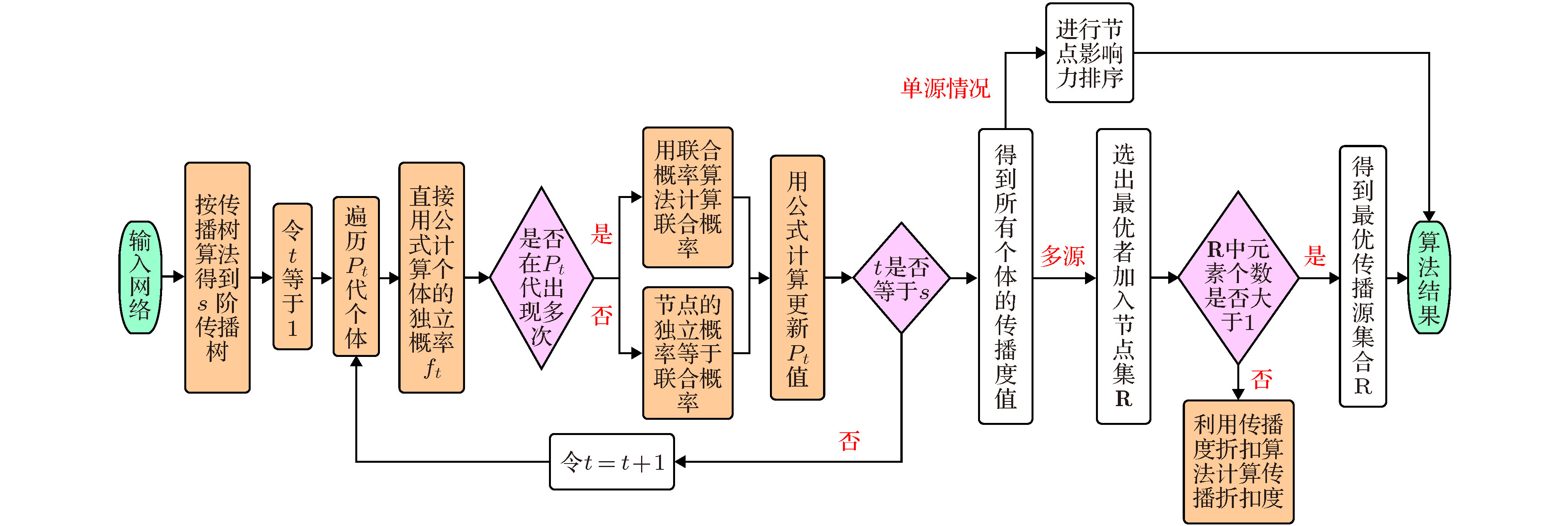 图 4 基于传播度的节点影响力极大化算法流程图
图 4 基于传播度的节点影响力极大化算法流程图Figure4. Flow chart of node influence maximization algorithm based on propagation degree.
2
4.1.数据集
为了评价模型, 采用如下3个不同领域的真实网络数据集(无向)进行仿真实验.1) Deezer[17]: 数据来源于音乐流服务网站Deezer提供的数据, 表示罗马尼亚用户朋友网络. 数据下载于: http://snap.stanford.edu/data/(简称SLNDC), 共有41773个节点, 平均度为6.024.
2 Email-Enron[18]: 数据来源于安然电子邮件网络, 下载于SLNDC, 共有36692个节点, 平均度为10.020.
3) Facebook[17]: 数据来源Facebook朋友网络, 下载于SLNDC, 共有13866个节点, 平均度为12.528.
2
4.2.单源影响力排序效果
采用节点的仿真影响力值和传播度值的kendall’s tau系数[19]来反映单源影响力的排序效果. 该指数反映了两个序参量的一致性, 大小介于–1和1之间, 当该系数越大时, 两个序参量越趋于一致. 该算法排序效果见图5和图6.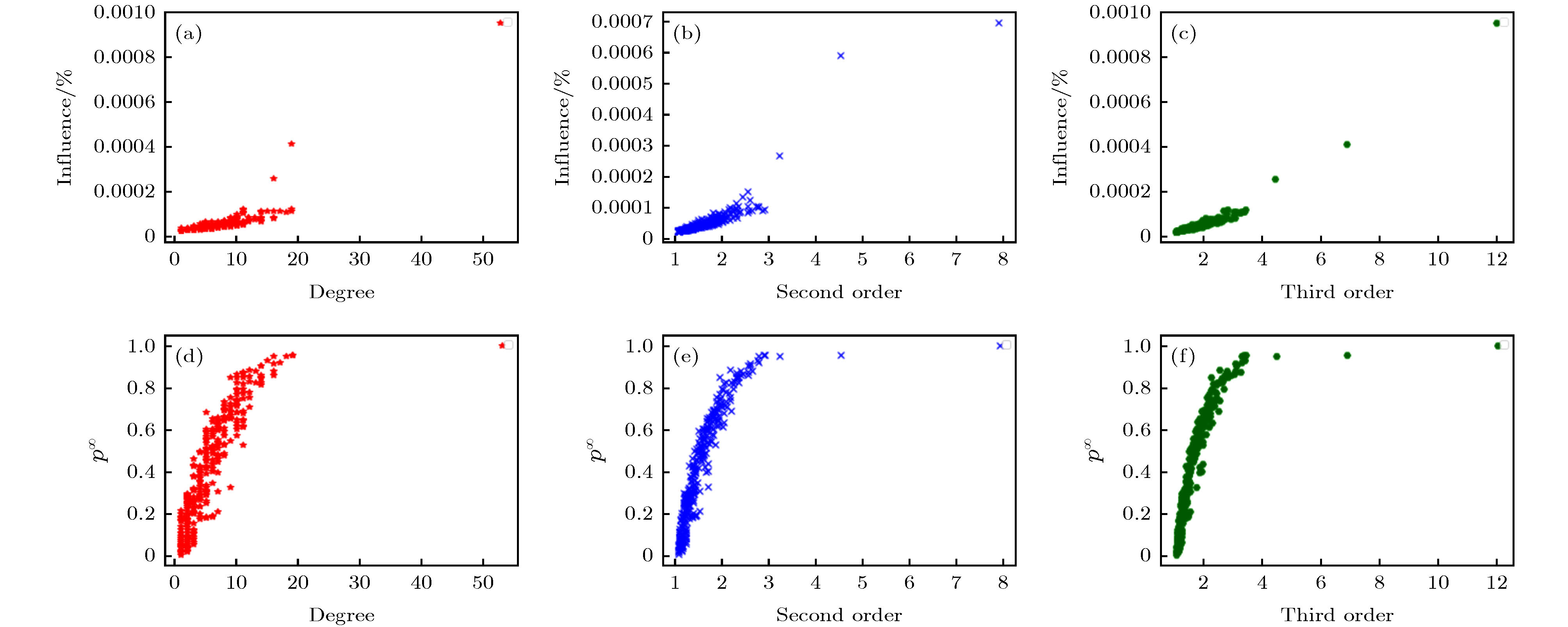 图 5 (a)?(c) 分别反映了Deezer网络随机挑选若干节点的传播能力与度, 二阶传播度, 三阶传播度的关系, 其中β = 0.06; (d)?(f) 分别反映了Deezer网络随机挑选若干节点全局传播概率(参见文献[12])与度, 二阶传播度, 三阶传播度的对应情况, 其中β = 0.12(这里通过仿真实验不难发现该网络的渗流阈值介于0.06和0.12之间)
图 5 (a)?(c) 分别反映了Deezer网络随机挑选若干节点的传播能力与度, 二阶传播度, 三阶传播度的关系, 其中β = 0.06; (d)?(f) 分别反映了Deezer网络随机挑选若干节点全局传播概率(参见文献[12])与度, 二阶传播度, 三阶传播度的对应情况, 其中β = 0.12(这里通过仿真实验不难发现该网络的渗流阈值介于0.06和0.12之间)Figure5. (a)?(c): Respectively reflects the relationship between the propagation capacity and degree, second-order propagation, and third-order propagation of several nodes randomly selected by the Deezer network, where β = 0.06; (d)?(f): Respectively reflects the global propagation probability of randomly selected nodes by the Deezer network (see reference[12]) Correspondence with degrees, second-order propagation, and third-order propagation, where β = 0.12 (here, it is not difficult to find through the simulation experiments that the percolation threshold of the network is between 0.06 and 0.12)
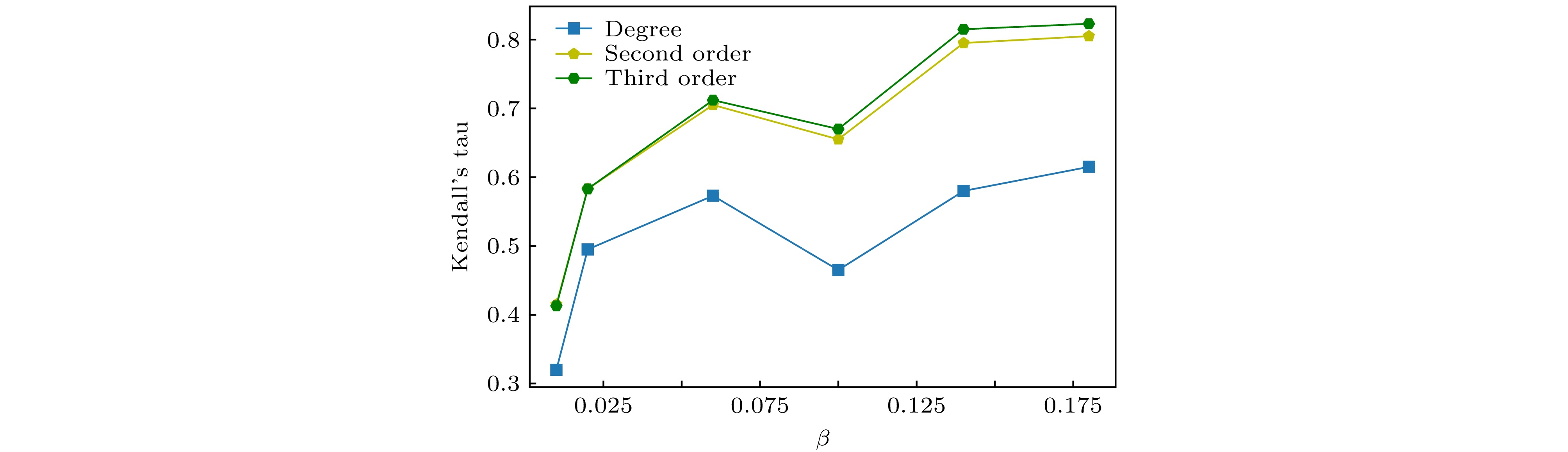 图 6 不同传播概率下度, 二阶、三阶传播度与仿真传播能力的kendall’s tau系数
图 6 不同传播概率下度, 二阶、三阶传播度与仿真传播能力的kendall’s tau系数Figure6. Kendall’s tau coefficient for different propagation probabilities, second-order, third-order propagation and simulation propagation ability.
由图5和图6可知, 传播度相较于度, 高阶传播度相较于低阶传播度与节点的传播能力之间具有更高的一致性, 特别是在传播概率偏大时, 这种效果是明显的, 这种现象同样适用其他的真实网络.
目前最常用的节点重要度排序指标有k核[20](coreness), 特征向量中心性[6](eigenvenctor), 考虑节点最近邻居核次近邻居的多级邻居信息指标[2](local centrality), 而介数中心性和接近度中心性由于其算法复杂度较高, 不适用于大型网络. 不同方法下的比较情况见图7和图8.
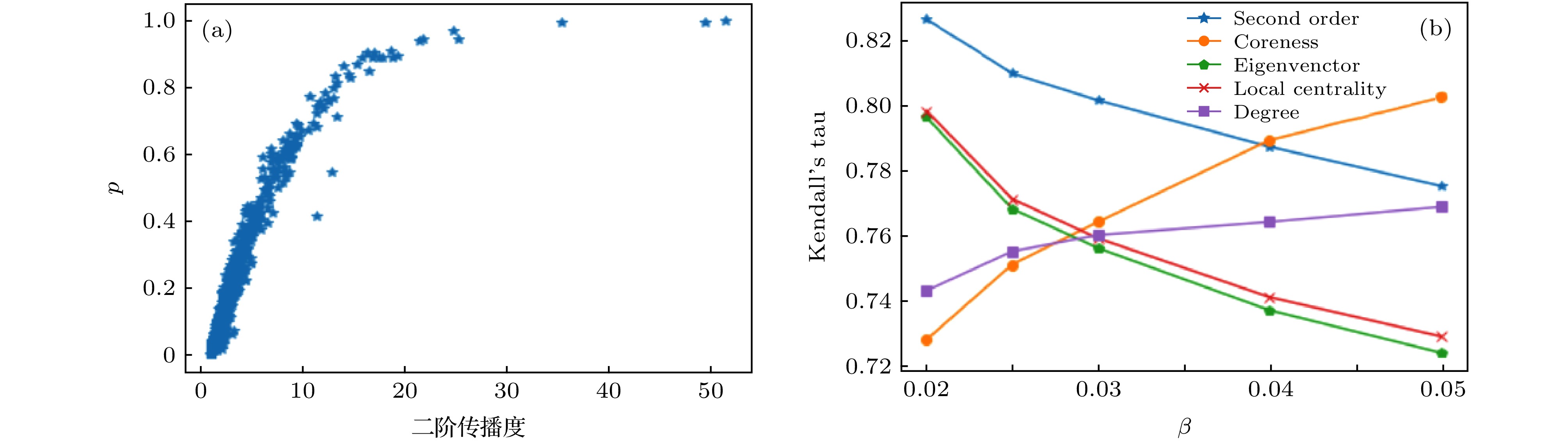 图 7 (a)在Email-Enron网络中, 传播概率为0.02的情况下二阶传播度和全局传播概率p的关系; (b)各指标在不同概率下与传播能力的kendall’s tau系数
图 7 (a)在Email-Enron网络中, 传播概率为0.02的情况下二阶传播度和全局传播概率p的关系; (b)各指标在不同概率下与传播能力的kendall’s tau系数Figure7. (a) The relationship between the second-order propagation degree and the global propagation probability p in the case of the Email-Enron network with a propagation probability of 0.02; (b) the kendall's tau coefficient of each indicator with different propagation rates and propagation capabilities.
 图 8 (a)在Facebook网络中, 传播概率为0.09的情况下二阶传播度和全局传播概率p的关系; (b)各指标在不同概率下与传播能力的kendall’s tau系数
图 8 (a)在Facebook网络中, 传播概率为0.09的情况下二阶传播度和全局传播概率p的关系; (b)各指标在不同概率下与传播能力的kendall’s tau系数Figure8. (a) The relationship between the second-order propagation degree and the global propagation probability p in the case of a Facebook network with a propagation probability of 0.09; (b) the kendall's tau coefficient of each indicator with different propagation rates and propagation capabilities.
由图7和图8可以看出, 对于大型网络, 二阶传播度相较于其他指标在不同的传播概率和网络下具有更好的效果和更高的稳定性. 因此, 我们给出的传播度能更好地利用节点的局部拓扑结构来描述单源影响力排序.
2
4.3.多源影响力极大化效果
通过实验发现, 分解极大连通子图等方法虽然算法复杂度低, 但由于做了过多近似, 效果不如算法复杂度较高的贪心算法, 因此这些方法不是本文研究的重点, 而是致力于贪心算法的一种改进算法. 为了验证传播度折扣算法的效果, 将该算法与最大度[1] (degree), 核[20] (coreness), 特征向量[6] (eigenvenctor), 介数[3] (betweeness), 折扣度算法[11] (degreediscount)进行仿真比较. 同样, 也分两种情况来比较: 一种取传播概率较小且低于渗流阈值, 另一种取传播概率较大且高于渗流阈值. 算法效果见图9和图10所示.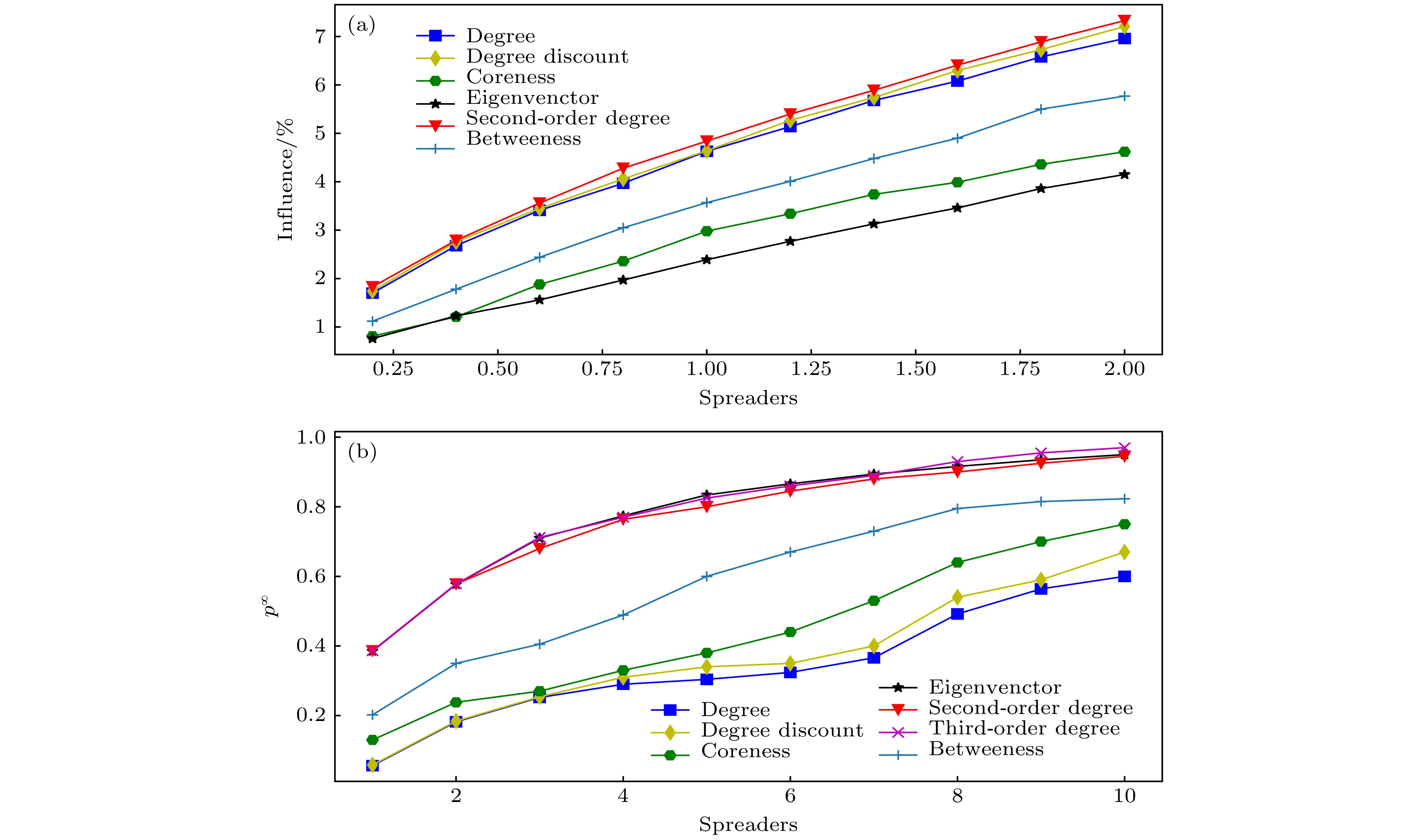 图 9 在Deezer网络中(a)不同算法下传播范围随所选种子节点数量的变化和(b)不同算法下全局传播概率随种子节点数量的变化, 其中候选节点为度为6, 7, 8的9792个节点
图 9 在Deezer网络中(a)不同算法下传播范围随所选种子节点数量的变化和(b)不同算法下全局传播概率随种子节点数量的变化, 其中候选节点为度为6, 7, 8的9792个节点Figure9. In the Deezer network, (a) the variation of the propagation range with the number of selected seed nodes under different algorithms; (b) the variation of the global propagation probability with the number of seed nodes under different algorithms. The candidate nodes are 9792 nodes with a degree of 6, 7 and 8.
 图 10 (a), (b)和(c), (d)分别比较了Email-Enron, Facebook网络在不同算法下所选种子节点的传播性能
图 10 (a), (b)和(c), (d)分别比较了Email-Enron, Facebook网络在不同算法下所选种子节点的传播性能Figure10. (a), (b), and (c), (d), respectively, compare the propagation performance of Email-Enron, the selected seed node of the Facebook network under different algorithms.
由图9和图10可以看出, 传播度折扣算法能够较好的解决多源影响力极大化问题, 因此在利用局部信息去除影响力重叠时, 传播度折扣算法具有不错的效果.
给出了一种精确计算有限步传播范围期望的递推算法, 事实上, 当传播到达一定步数后, 即当传播步数较大时, 节点被传播的概率往往很小, 因此, 如何设置局部的递推终止条件, 引入较小的误差, 可以进一步优化算法, 计算更高阶的传播度, 这一问题有待进一步研究.
