全文HTML
--> --> -->2009年, Wright等[3]受生物视觉稀疏性启发, 首次提出稀疏表示分类模型(sparse representation based classification, SRC), 并将其成功应用于非约束人脸识别中, 很好地解决了人脸图像中光照、遮挡、噪声等因素的影响. 分析其原因, 关键在于稀疏表示分类中并不需要精确的特征表达, 只需遵循“简约性”原则, 从字典中选择“有限”原子对待测样本进行线性表示, 并期望达到所选“原子”仅与待测样本同类. 由此可见, 构建学习紧致、判别的字典在稀疏表示分类中具有极其重要的作用. Yang等[4]提出Fisher判别字典学习(fisher discrimination dictionary learning, FDDL)方法, 将Fisher判别准则引入结构字典学习中, 使得同类字典原子具有相似性而异类字典原子具有差异性. Vu等[5]在此基础上引入低秩共享字典(low-rank shared dictionary, LRSD)用于表示人脸本质特征, 与表示人脸差异性的类特定字典(class-specific dictionary, CSD)相结合, 进一步提高了字典空间的判别性. 为使学习得到的字典具有更丰富的语义信息, Babaee等[6]摒弃了二值标签信息而采用相对属性信息, 提出相对属性引导字典学习(relative attribute guided dictionary learning, RAGDL)算法. 同时, 文献[7-10]在字典学习方面也进行了深入研究.
分析发现, 字典学习(dictionary learning, DL)方法虽然在构建学习紧致、判别字典空间上取得一定效果, 但仍受2个方面限制: 1)稀疏表示分类[3]要求字典原子的维度远远小于字典原子个数, 从而保证解空间存在最优稀疏解, 然而, 以M×N像素大小的样本图像作为字典原子构建字典空间, 其维度远大于样本个数, 容易导致出现“小样本”问题; 2)字典学习方法通过增加各种约束条件优化字典满足类内紧凑和类间分离, 然而, 由于原始样本图像的高维性、复杂性和冗余性, 使得优化效果大打折扣, 严重抑制了待测样本稀疏表示分类的准确性.
鉴于此, 大量****提出采用降维(dimensionality reduction, DR)方法克服上述不足, 一方面通过降低字典空间维度可以避免“小样本”问题, 减少稀疏编码计算复杂度, 加速搜寻最优解; 另一方面增加投影约束条件, 使高维样本字典在低维子空间更具紧致性、判别性, 稀疏表示更准确, 这已成为稀疏表示分类中必不可少的步骤.
以主成分分析(principle components analysis, PCA)[11]、线性鉴别分析(linear discriminant analysis, LDA)[12]为代表的经典降维方法被首先用于稀疏表示分类模型中[3,4,13], 但受数据全局线性分布条件的限制, 当处理复杂扭曲的非线性分布的真实数据时, 这类方法效果不佳. 鉴于此, 广大****提出采用基于核的方法[7,14-16]和流形学习方法[17-21]进行数据非线性降维. 核方法的本质是利用核函数映射样本到高维空间进行线性划分, 但起关键作用的核函数的选择机制和意义并不明确. 因此, 以等距映射(isometric mapping, ISOMAP)[17]、局部线性嵌入(locally lineare mbedding, LLE)[18]、拉普拉斯特征映射(Laplacian eigenmaps, LE)[19]、平行向量场嵌入(parallel vector field embedding, PFE)[20]、测地线距离学习(geodesic distance function learning, GDL)[21]等为代表的非线性流形学习方法更受青睐. 这类方法符合人眼视觉感知机制, 可以有效挖掘出隐藏在错综复杂的高维数据中的低维流形本质结构. He等[22,23]针对LE和LLE的隐式映射问题进行改进, 在不改变原有目标函数的基础上增加线性约束, 提出具有显式映射函数的局部保持投影(locality preserving projections, LPP)和近邻保持嵌入(neighborhood preserving embedding, NPE)算法, 有效克服了样本外扩展问题(out-of-sample extension problem)[24], 使得流形学习方法在图像、视频、文本等高维、海量、真实数据中的应用成为可能. 随后, 大量改进算法被陆续提出, 例如, 指数判别局部保持投影(exponential discriminant locality preserving projection, EDLPP)[25]、二维判别局部保持投影(two-dimensional discriminant LPP, 2DDLPP)[26]、双向二维近邻保持判别嵌入(bilateral two-dimensional neighborhood preserving discriminant embedding, B2DNPDE)[27]、快速正交局部保持投影(fast and orthogonal LPP, FOLPP)[28]、监督近邻保持嵌入(supervised NPE, SNPE)[29]等.
Yan等[30]对LPP, NPE及改进算法的实现原理进行分析, 将它们归纳到图映射框架(graph embedding framework, GEF)中. 分析发现, GEF的核心思想是通过构建高维样本近邻分布图, 寻找使低维子空间数据仍保持高维样本分布特性的最优投影矩阵. 因此, 在GEF中如何构建一个准确的高维样本近邻分布图是这类方法的关键. 近邻图的构建包含2个关键步骤: 图顶点选择和图边权分配. 传统方法多采用k-nearest[31]或ε-ball[23]方法搜索样本近邻点, 并用热核函数[31]或逆欧式距离[32]计算近邻点之间的权值. 然而, 实际应用中真实数据的分布是未知的、复杂的, 选择合适的近邻点非常困难, 并且样本之间距离测度的可区分性也会随着样本维数的增加而减弱, 这在一定程度上抑制了基于GEF的降维方法的广泛应用.
2010年, Qiao等[33]受信号稀疏表示(sparse representation, SR)[3-5]的启发, 首次将稀疏技术引入图映射框架中, 提出稀疏保持投影(sparsity preserving projections, SPP)算法. 这是一种不以距离测度为区分, 而以保持样本间稀疏重构关系为目标的全新降维方法. 它通过优化求解每一个样本在全局超完备字典下的线性稀疏表示, 自适应得到与该样本近邻的少量重构样本以及样本之间的重构权值, 有效克服了传统图映射方法中预定义近邻图的弊端. 这种以SPP为代表的自适应稀疏图映射(sparse graph embedding, SGE)方法极大提高了真实复杂数据低维投影的准确性, 受到广大****们的高度关注.
Lai等[34]将稀疏表示技术引入LLE框架中, 提出稀疏线性映射(sparse linear embedding, SLE)算法, 并扩展到核空间, 在3个人脸库和2个目标库上验证了其降维有效性, 尤其是在小样本情况下表现更突出. Yin等[35]将稀疏表示与LPP相结合, 提出局部稀疏保持投影(local sparsity preserving projection, LSPP)算法, 并成功应用于生物大数据的降维与识别中. Zhang等[36]结合近邻图和稀疏图优点, 提出稀疏邻域保持投影(sparsity and neighborhood preserving projections, SNPP)算法. 分析发现, 基于全局样本的稀疏关系约束会破坏样本局部结构, 导致样本间的近邻关系描述并不准确. Lu等[37]在SPP基础上引入类别标签, 提出鉴别稀疏邻域保持嵌入(discriminant sparsity neighborhood preserving embedding, DSNPE)算法, 分别考虑待测样本与同类样本的重构关系, 以及异类样本对待测样本的重构影响, 有效提高了待测样本稀疏近邻图的准确性, 相比SPP算法识别性能大大提升. 同样地, Wei等[38]提出加权判别稀疏保持映射(weighted discriminative sparsity preserving embedding, WDSPE)算法, Lou等[39]则将稀疏表示技术引入LPP框架中, 提出正则图稀疏判别分析(graph regularized sparsity discriminant analysis, GRSDA)算法. 鉴于传统方法中多将降维和分类作为2个独立步骤分别建模, 存在降维效果与分类器不匹配的问题, Yang等[40]提出稀疏表示分类引导判别投影(sparse representation classifier steered discriminative projection, SRC-DP)算法, 以同类重构残差最小、异类重构残差最大为目标, 联合优化投影矩阵以及稀疏表示分类系数, 使SRC分类器在投影子空间获得最佳性能. 类似地, Zheng等[41]提出特征加权组稀疏判别投影(feature weighted group sparse classification steered discriminative projection, FWGSDP)算法, 并采用迭代重约束稀疏编码优化方法对该模型进行高效求解. Gao等[42]基于Fisher判别准则引导数据降维和分类. Zhang等[43]将SRC-DP进一步扩展到核空间, 从多个不同角度验证算法有效性. 可见, 由于稀疏表示技术的引入, 以SPP为代表的稀疏图映射方法具有非常好的图自适应性和噪声鲁棒性, 将其与SRC分类器相结合, 用于构建低维、紧致、判别字典可以显著提高分类器的精度和速度, 是近年来值得研究和探索的热点方向之一.
受基于统计局部特征的鲁棒核表示(robust kernel representation with statistical local features, RKR-SLF)[44]以及基于Gabor特征的鲁棒表示分类[45](gabor feature based robust representation and classification, RRC-GF)等算法的启发, 我们发现, 采用LBP, Gabor等鉴别力和鲁棒性较强的局部特征代替传统的冗余数据样本构建特征字典, 可以显著提高稀疏表示分类的准确性. 因此, 本文考虑将局部特征算子与降维方法相结合, 提出一种基于旋转主方向梯度直方图特征的判别稀疏图映射(discriminative sparse graph embedding based on histogram of rotated principal orientation gradients, DSGE-HRPOG)算法, 实现流程如图1所示. 首先, 从特征描述角度设计一种旋转主方向梯度直方图(histogram of rotated principal orientation gradients, HRPOG)特征算子, 相比传统方向梯度直方图(histogram of oriented gradients, HOG)特征算子, 它从多个尺度、多个方向捕捉人脸纹理的梯度变化信息, 可以更准确提取出人脸本质特征, 显著提高了特征字典的鉴别性和鲁棒性. 其次, 从降维角度提出判别稀疏图映射(discriminative sparse graph embedding, DSGE)算法, 在DSNPE算法[37]的基础上, 通过引入类内、类间紧凑度约束, 有效增强了待测样本与同类非近邻样本的重构关系, 并削弱了异类伪近邻样本的重构影响; 同时, 在低维投影阶段又增加了全局约束因子, 利用样本全局分布中隐含的鉴别信息使HRPOG特征字典在低维子空间更判别、更紧致. 最后, 受SRC-DP[40]的启发, 提出一种投影矩阵和稀疏重构关系交替的迭代优化算法, 将维数约简过程伴随在稀疏图构建过程中, 使分类效果更理想. 经实验环境下采集的人脸数据库(AR和Extended Yale B)和真实环境下采集的人脸数据库(LFW和PubFig)验证, DSGE-HRPOG算法可以有效提取这些高度扭曲的人脸数据的低维流形本质结构, 大大增强特征字典的紧致性、判别性和鲁棒性, 使SRC分类性能更突出.
 图 1 本文算法的实现流程
图 1 本文算法的实现流程Figure1. Flow chart of the proposed algorithm.
2.1.方向梯度直方图(histogram of oriented gradients, HOG)
2005年, Dalal和Triggs[46]提出方向梯度直方图(histogram of oriented gradients, HOG)用于行人检测, 其基本原理是统计图像中各个像素点的梯度幅值和梯度方向, 用于表征目标形态、轮廓变化等信息. 相比LBP, Gabor等局部纹理特征算子, HOG算子提取的方向梯度变化信息更符合人眼视觉感知特性, 受光照、旋转、噪声等外界干扰影响更小, 提取目标特征效果更佳、更鲁棒[47,48]. 实现步骤如下:1)将图像

2)将


3)将4个相邻的无重叠的单元格组合成一个块(block), 级联块中单元格的方向梯度直方图构成该块的方向梯度直方图特征;
4)级联所有块的方向梯度直方图, 得到整幅图像的HOG特征.
2
2.2.HRPOG特征算子
分析发现, 在HOG算子实现过程中, 图像











可以看出, 依据(2)式计算图像梯度受2个方面限制: 1)








首先, 将梯度卷积模板



 图 2 3-HRPOG算子的梯度卷积模板示意图 (a)
图 2 3-HRPOG算子的梯度卷积模板示意图 (a) 

Figure2. Gradient convolution masks of 3-HRPOG feature descriptor: (a)







 图 3 3-HRPOG算子的旋转梯度卷积模板
图 3 3-HRPOG算子的旋转梯度卷积模板Figure3. Rotated gradient convolution masks of 3-HRPOG feature descriptor.



 图 4 旋转不变性分析 (a) 原图及HOG和3-HRPOG的梯度矢量值; (b) 旋转
图 4 旋转不变性分析 (a) 原图及HOG和3-HRPOG的梯度矢量值; (b) 旋转
Figure4. Rotation invariance analysis: (a) Original binary image and gradient vectors of HOG and 3-HRPOG; (b) rotated

2
2.3.多尺度旋转主方向梯度直方图(multi-scale histogram of rotated principal orientation gradients, Ms-HRPOG)特征算子
研究表明, 人眼视觉系统具有多尺度分析能力, 通过调节视网膜细胞感受野范围可以提取不同尺度下的目标信息, 从而更加全面准确地“认识”目标[49,50]. 受此启发, 本文在2.2节3×3尺度的3-HRPOG算子基础上(图3), 将卷积模板尺寸扩展为5×5大小, 且卷积权值设置方法不变, 进一步设计出5×5尺度的5-HRPOG算子(图5), 并将2种算子相互结合, 提出一种Ms-HRPOG特征算子, 特征提取流程如图6所示, 其中, 5-HRPOG特征提取步骤与3-HRPOG特征提取一致, 将二者级联得到最终的Ms-HRPOG特征向量. 图 5 5-HRPOG算子的旋转主方向梯度模板
图 5 5-HRPOG算子的旋转主方向梯度模板Figure5. Rotated dominant direction gradient masks of 5-HRPOG feature descriptor.
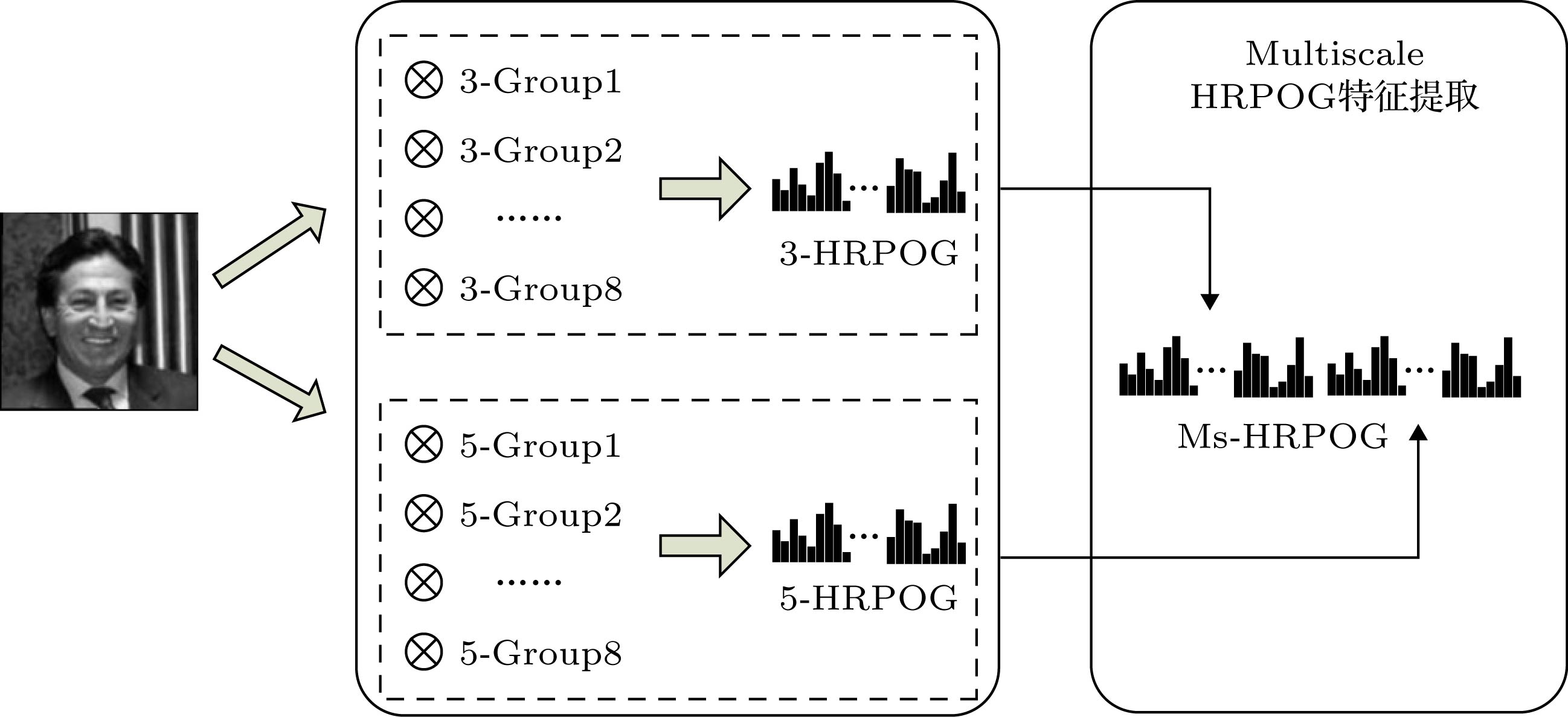 图 6 Ms-HRPOG特征提取示意图
图 6 Ms-HRPOG特征提取示意图Figure6. The sketch of Ms-HRPOG feature descriptor.

















以LFW数据库为例, 图7给出了根据(7)式计算得到的某一样本图像的稀疏重构权值. 图中, 前10个为同类样本的重构权值, 后90个为异类样本的重构权值. 由图7可以看出, 图中仅同类的第4个样本和第8个样本参与了重构(有权值), 而剩余的同类样本均未参与重构(权值为0); 相反, 某些异类样本在重构中具有较大权值, 如第29, 39, 48, 65个样本等. 造成这种结果的原因是, 真实采集的人脸图像复杂多变, 同类样本受光照、遮挡、表情、年龄、姿态等影响, 彼此之间存在差异, 导致部分同类非近邻样本重构权值为0, 而不同类样本间又具有人脸结构相似特征, 造成部分异类伪近邻样本参与重构. 可见, SPP算法在非约束人脸识别中仍有局限性, 不能准确描述样本的近邻重构关系.
 图 7 LFW数据库中某一图像的SPP稀疏重构权值
图 7 LFW数据库中某一图像的SPP稀疏重构权值Figure7. Sparsity reconstruction weights of one sample with SPP algorithm on the LFW database.
2
4.1.类内、类间重构关系矩阵
首先, 分析待测样本与同类样本之间的重构关系. 设训练样本集














依据(10)式分别计算样本子集


















为了便于描述样本集






2
4.2.DSGE低维投影
首先, 为了使低维子空间中同类样本尽可能聚合, 在最小化类内重构误差基础下, 增加全局类内约束条件, 使得低维子空间数据既保留了样本间局部类内稀疏重构关系, 又考虑了同类样本子集的全局紧凑度分布特性. 最小化类内重构散度目标函数如下:



























算法1 DSGE-HRPOG算法
输入: 训练样本






输出: 最佳投影矩阵

步骤1. 采用HRPOG算子(单尺度或多尺度)提取训练样本X的特征, 并采用PCA对HRPOG特征向量进行预处理降维, 构建特征字典

步骤2. 初始化投影矩阵


步骤3. 将特征字典


步骤4. 依据(10-13)式计算变换空间




步骤5. 计算




步骤6. 取


步骤7. 若







2
6.1.AR数据库
AR数据库是在严格控制实验环境条件下采集的具有不同面部表情、照明条件和遮挡(包括太阳镜和围巾)的人脸正视图, 图像尺寸为50×40像素大小. 本文选取120类人(65男55女)在2个阶段拍摄的图像, 其中每人每个阶段包含7张无遮挡图像(包含表情、光照影响)和6张遮挡图像(3张墨镜遮挡, 3张围脖遮挡), 样本如图8所示. HRPOG算子的参数设置为1个cell = 2×2 pixels, 1个block = 2×2 cells, bin = 9. 图 8 AR数据库部分样本图像
图 8 AR数据库部分样本图像Figure8. Samples of one person in the AR database.
3
6.1.1.表情、光照、时间的影响
本实验主要分析表情、光照、时间等非遮挡因素对人脸识别的影响. 取AR数据库中每类人在Session1中7张无遮挡图像作为训练样本, Session2中7张无遮挡图像作为测试样本进行实验仿真(表1). 由表1可以看出, 在本文提出的DSGE-HRPOG算法框架下, 无论采用单尺度特征算子(3-HRPOG和5-HRPOG), 还是多尺度特征算子(Ms-HRPOG)构建特征字典, DSGE-HRPOG的识别率均高于其他算法, 与DSNPE[37], DP-NFL[51]和SRC-DP[40]相比, 识别率最大提升了12.74%, 17.01%和13.61%. 这说明, 本文提出的DSGE-HRPOG算法在降低人脸识别中表情、光照、时间等非遮挡影响时, 具有绝对的优势. 同时, 本实验又基于原始图像构建样本字典, 并采用DSGE算法进行字典降维, 得到DSGE-pixels的识别率为76.79%, 相比SPP[33], DSNPE[37], DP-NFL[51]和SRC-DP[40], 识别率分别提升了8.58%, 0.72%, 4.99%和1.59%. 这也从另一个角度说明, 摒弃特征字典的作用, 本文提出的DSGE算法在去除数据冗余、构建低维判别字典方面也具有一定优势, 但将DSGE与HRPOG特征字典相结合, 识别效果更佳, 如表1中所示, DSGE-HRPOG算法的识别率比DSGE-pixels最大提升了12.02%.| Method | LPP[22] | NPE[23] | SPP[33] | DSNPE[37] | DP-NFL[51] | SRC-DP[40] | DSGE-pixels | DSGE-HRPOG | ||
| 3-HRPOG | 5-HRPOG | Ms-HRPOG | ||||||||
| Recognition Rate/% | 67.14 | 68.69 | 68.21 | 76.07 | 71.8 | 75.2 | 76.79 | 88.45 | 88.21 | 88.81 |
| Dimension | 115 | 311 | 220 | 140 | 63 | 63 | 322 | 777 | 754 | 774 |
表1AR数据库在表情、光照和时间干扰因素下的实验结果
Table1.Experimental results on the AR database with the interference factors of expression, illumination and time.
3
6.1.2.遮挡的影响
本实验主要分析遮挡因素对人脸识别的影响, 包括眼镜遮挡、围巾遮挡以及混合遮挡3个方面. 下面有针对性地设计3个实验, 依次进行实验仿真(表2).| Experiment 1/% | Experiment 2/% | Experiment 3/% | |
| LPP[22] | 71.39 | 68.68 | 69.46 |
| NPE[23] | 72.64 | 71.81 | 71.08 |
| SPP[33] | 75.90 | 72.92 | 74.07 |
| DSNPE[37] | 80.28 | 78.26 | 78.14 |
| SRC-DP[40] | 78.35 | 76.50 | 77.80 |
| SRC-FDC[42] | 80.90 | 79.90 | 80.30 |
| DSGE-pixels | 79.03 | 78.75 | 82.65 |
| DSGE-HRPOG (3-HRPOG) | 88.54 | 89.51 | 90.53 |
| DSGE-HRPOG (5-HRPOG) | 89.31 | 89.58 | 90.98 |
| DSGE-HRPOG (Ms-HRPOG) | 89.31 | 90.00 | 91.06 |
表2AR数据库在遮挡干扰因素下的实验结果
Table2.Experimental results of AR database with the occlusion interference.
实验1: 取AR数据库中每类人在Session1中7张无遮挡图像和任意1张眼镜遮挡图像作为训练样本, 而Session2中7张无遮挡图像和3张眼镜遮挡图像, 以及Session1中剩余的2眼镜遮挡图像作为测试样本.
实验2: 取AR数据库中每类人在Session1中7张无遮挡图像和任意1张围巾遮挡图像作为训练样本, 而Session2中7张无遮挡图像和3张围巾遮挡图像, 以及Session1中剩余的2围巾遮挡图像作为测试样本.
实验3: 取AR数据库中每类人在Session1中7张无遮挡图像和任意1张眼镜遮挡图像以及任意1张围巾遮挡图像作为训练样本, 而Session2中7张无遮挡图像、3张眼镜遮挡图像、3张围巾遮挡, 以及Session1中剩余的眼镜和围巾遮挡图像作为测试样本.
分析表2中3个实验结果, 可以看出, 本文提出的DSGE-HRPOG算法在眼镜遮挡、围巾遮挡以及混合遮挡3种真实遮挡情况下, 均具有最佳识别效果, 其中, 基于Ms-HRPOG特征字典的识别率最高, 分别为89.31%, 90.00%和91.06%, 比次优算法SRC-FDC[42, 52]高8.41%, 10.1%和10.76%. 这说明, DSGE-HRPOG算法通过结合HRPOG特征字典以及DSGE低维投影的优势, 可以有效消除人脸识别中各种遮挡因素的影响, 具有较强的遮挡鲁棒性. 同时, 从表2中也可以看出, 基于多尺度特征字典(Ms-HRPOG)的DSGE-HRPOG的识别率均高于基于单尺度特征字典(3-HRPOG和5-HRPOG)的情况, 这也说明, 采用多尺度特征融合策略有助于进一步提升特征字典的鉴别能力, 增强系统的稳定性.
3
6.1.3.混合影响
前2个实验分别分析了遮挡因素以及非遮挡因素对人脸识别的影响, 本实验将遮挡因素和非遮挡因素综合考虑, 分析混合因素(遮挡、表情、光照、时间)对人脸识别的影响. 随机取每类人26张(2个Session)图像中的13张图像作为训练样本, 剩余图像作为测试样本进行实验仿真, 交叉验证10次(表3). 分析发现, 当样本中随机包含各种不同干扰因素时, 本文提出的DSGE-HRPOG算法在消除人脸识别中遮挡、表情、光照、时间等混合影响时, 仍具有一定优势. 相比文献[53]和[54]中提出的2个先进算法, 基于Ms-HRPOG特征字典的DSGE-HRPOG算法的平均识别率提升最多, 分别提升了0.96%和1.7%. 同时, 文献[53]和[54]算法的标准差分别为0.53和0.93, 而DSGE-HRPOG的标准差最大为0.17, 远远小于文献值, 这也进一步说明了本文提出的DSGE-HRPOG算法不受样本选择和干扰因素变化的影响, 具有分类稳定性.| Mean/% | Std/% | Dimension | |
| LPP[22] | 95.90 | 0.38 | 141 |
| NPE[23] | 95.87 | 0.55 | 311 |
| SPP[33] | 90.39 | 0.90 | 151 |
| DSNPE[37] | 98.02 | 0.33 | 200 |
| Wang[54] | 97.85 | 0.93 | — |
| Gao[53] | 98.59 | 0.53 | — |
| DSGE-pixels | 98.45 | 0.27 | 202 |
| DSGE-HRPOG (3-HRPOG) | 99.45 | 0.17 | 1350 |
| DSGE-HRPOG (5-HRPOG) | 99.37 | 0.12 | 1297 |
| DSGE-HRPOG (Ms-HRPOG) | 99.55 | 0.13 | 1385 |
表3AR数据库在混合干扰因素下的实验结果
Table3.Experimental results on the AR database with the mix interference factors.
2
6.2.Extended Yale B数据库
Extended Yale B数据库包含38类人在不同光照条件下拍摄的人脸正视图, 每类人约64张图像, 共2414张, 图像尺寸为32×32像素大小, 部分样本图像如图9所示. 这里, HRPOG算子的参数设置与AR数据库一致. 图 9 Extended Yale B数据库部分样本图像
图 9 Extended Yale B数据库部分样本图像Figure9. Samples of one person in the Extended Yale B database
在Extended Yale B数据库上, 首先分析不同强度光照对人脸识别的影响. 随机选取每类人的10张图像作为训练样本, 剩余图像作为测试样本进行实验仿真(表4). 由表4可以看出, 在多尺度特征字典情况下(Ms-HRPOG), DSGE-HRPOG算法可以达到92.48%的识别率, 相比近年来提出的先进算法GRSDA[39]和RCDA[52], 分别提升了9.78%和0.48%, 识别效果最佳. 而在单尺度特征字典(3-HRPOG和5-HRPOG)情况下, DSGE-HRPOG的识别率分别为91.35%和89.77%, 略低于RCDA[52]. 可见, 在少量训练样本条件下, 多尺度特征更有助于消除人脸识别中不同强度的光照影响.
| Method | LPP[22] | NPE[23] | SPP[33] | DSNPE[37] | GRSDA[39] | RCDA[52] | DSGE-pixels | DSGE-HRPOG | ||
| 3-HRPOG | 5-HRPOG | Ms-HRPOG | ||||||||
| Recognition Rate/% | 87.86 | 89.31 | 85.79 | 85.74 | 82.7 | 92 | 86.03 | 91.35 | 89.77 | 92.48 |
| Dimension | 65 | 160 | 95 | 85 | 266 | — | 83 | 355 | 345 | 351 |
表4Extended Yale B数据库在光照干扰因素下的实验结果
Table4.Experimental results of Extended Yale B database with the illumination interference.
其次, 进一步验证DSGE-HRPOG算法在Extended Yale B数据库上的遮挡鲁棒性. 本文又随机选取每类人14张图像, 在上面分别添加大小随机、位置随机的黑白点噪声块, 得到部分遮挡样本图像(图10). 这里, 噪声块大小与图像大小比例在0.05—0.15任意取值.
 图 10 Extended Yale B数据库部分遮挡样本图像
图 10 Extended Yale B数据库部分遮挡样本图像Figure10. Occlusion samples of one person in the Extended Yale B database.
下面设计2个实验, 用以讨论遮挡样本数量不同时, DSGE-HRPOG算法的性能. 实验1: 随机选取每类人32张图像作为训练样本, 其中包含14张遮挡图像, 剩余图像作为测试样本, 交叉验证10次; 实验2: 随机选取每类人32张图像作为训练样本, 其中包含7张遮挡图像, 剩余图像作为测试样本, 交叉验证10次, 实验仿真结果如表5所示. 从表5中可看出, 在光照和遮挡混合干扰情况下, DSGE-HRPOG算法仍具有最佳性能. 当遮挡样本数为7张时, 基于Ms-HRPOG特征字典的平均识别率为98.10%, 当遮挡样本数增大到14张时, 识别率仍有97.98%, 二者仅相差0.12%. 同样地, 基于3-HRPOG和5-HRPOG特征字典的平均识别率也高于其他算法, 并且在不同遮挡样本数量条件下, 实验结果仅相差0.43%和0.08%, 而其余算法则有近1%左右的差值. 这充分说明, 无论是基于单尺度特征字典还是多尺度特征字典, DSGE-HRPOG算法不受遮挡样本数量和质量的影响, 系统性能稳定.
| Experiment 1/% | Experiment 2/% | |
| LPP[22] | 95.51 ± 0.40 | 96.78 ± 0.72 |
| NPE[23] | 96.43 ± 0.23 | 97.85 ± 0.31 |
| SPP[33] | 92.57 ± 0.84 | 93.05 ± 0.77 |
| DSNPE[37] | 94.18 ± 0.48 | 95.29 ± 0.54 |
| Gao[53] | 86.91 ± 1.07 | 88.23 ± 0.91 |
| DSGE-pixels | 95.83 ± 0.66 | 96.21 ± 0.21 |
| DSGE-HRPOG(3-HRPOG) | 97.30 ± 0.20 | 97.73 ± 0.35 |
| DSGE-HRPOG (5-HRPOG) | 96.85 ± 0.38 | 96.93 ± 0.60 |
| DSGE-HRPOG G(Ms-HRPOG) | 97.98 ± 0.50 | 98.10 ± 0.31 |
表5Extended Yale B数据库在遮挡干扰因素下的实验结果
Table5.Experimental results of Extended Yale B database with the occlusion interference.
2
6.3.LFW和PubFig数据库
前面讨论是基于实验环境下采集的人脸数据库(AR和Extended Yale B)进行实验仿真和分析的, 实验结果具有一定的局限性, 本节将进一步对真实环境中采集的LFW和PubFig数据库上进行实验仿真, 使实验结果更具有说服力.LFW(labeled faces in the Wild database)数据库[55-57]是从Internet上采集的真实人脸数据库, 共有13233张5749类人脸图像, 包含了光照、表情、姿态、遮挡、年龄、种族等多种混合干扰, 对于人脸识别来说非常具有挑战性. 部分样本如图11(a)所示, 图像尺寸为128×128 pixels. 本文从中选取包含10张以上图像的人进行辨识, 得到158类人, 共4324张图像, 随机选取每类人的5张图像作为训练样本, 5张图像作为测试样本进行实验(表6). HRPOG特征算子的参数设置为一个cell = 4×4 pixels, 一个block = 2×2 cells, bin = 9.
 图 11 部分样本图像 (a) LFW数据库部分样本; (b) PubFig数据库部分样本
图 11 部分样本图像 (a) LFW数据库部分样本; (b) PubFig数据库部分样本Figure11. Samples of one person: (a) LFW database; (b) PubFig database.
| LFW/% | PubFig/% | |
| LPP[22] | 35.32 | 24.00 |
| NPE[23] | 35.19 | 25.00 |
| SPP[33] | 31.52 | 29.00 |
| DSNPE[37] | 44.05 | 30.90 |
| WGSC[58] | 47.60 | 37.50 |
| RSRC[3] | 42.80 | 47.00 |
| RRC[57] | 53.20 | 42.20 |
| IRGSC[41] | 56.30 | 48.50 |
| DSGE-pixels | 51.52 | 38.60 |
| DSGE-HOG | 69.62 | 49.00 |
| DSGE-HRPOG(3-HRPOG) | 76.71 | 54.20 |
| DSGE-HRPOG (5-HRPOG) | 76.58 | 53.30 |
| DSGE-HRPOG (Ms-HRPOG) | 73.80 | 53.70 |
表6LFW和PubFig数据库的实验结果
Table6.Experimental results on the LFW database and PubFig database.
PubFig(public figures face database)数据库[56]与LFW数据库类似, 包括从互联网上采集到的200类知名人物的58797张图像. 数据库中的人脸都是真实环境下拍摄的, 包含部分遮挡(眼镜、帽子等饰物)、极端光照、较大的姿势变换(> 45°)、不同种族、年龄等干扰因素. 部分样本如图11(b)所示, 图像尺寸为100×100 pixels. 本文从PubFig数据库中随机选取100类人, 每类人20张图像进行实验仿真, 其中每类人的10张图像作为训练样本, 剩余图像作为测试样本(表6). HRPOG特征算子的参数设置为一个cell = 10×10 pixels, 一个block = 2×2 cells, bin = 9.
从表6中可以看出, DSGE-HRPOG算法在LFW和PubFig这2个数据库上的识别率均高于其他算法, 其中, 基于3-HRPOG特征字典的识别率最高, 达到76.71%和54.20%, 比文献[41]提出的IRGSC算法提升了20.41%和5.7%, 比文献[57]提出的RRC算法提升了23.51%和12%, 比其他算法则提升更多. 然而, 表中DSGE-pixels的识别效果并不理想, 在LFW数据库上识别率仅为51.52%, 低于IRGSC[41]和RRC[57], 在PubFig数据库上识别率为38.6%, 低于IRGSC[41], RRC[57]和RSRC[3]. 可见, 在LFW和PubFig这2个具有挑战性的非约束人脸数据库上, DSGE算法容易受样本影响, 近邻图构建不准确, 而DSGE-HRPOG算法通过结合HRPOG特征字典以及DSGE低维投影两方面的优势, 能够更准确挖掘出嵌入在真实复杂数据中的低维流形本质结构, 显著提高了系统的判别能力.
值得注意的是, 本文也采用传统HOG特征算子构建特征字典, 再与DSGE算法相结合, 得到DSGE-HOG的识别率为69.62%和49.00%, 分类效果仅次于DSGE-HRPOG算法, 并优于其他非特征字典算法. 这进一步说明了, 在稀疏表示分类中, 首先采用特征算子提取图像特征用以构建特征字典, 对准确区分受不同因素干扰的真实环境采集的非约束人脸图像十分有效. 同时, 这也从另一角度验证了, 相比传统HOG特征算子, 本文提出的HRPOG特征算子从多个尺度、多个方向捕捉人脸纹理的梯度变化信息, 可以更准确提取出人脸本质特征, 从而显著提高特征字典的鉴别性和鲁棒性.
2
6.4.参数性能分析
本节主要讨论DSGE-HRPOG算法中最优参数选择, 包括初始投影矩阵




 图 12 不同初始投影矩阵
图 12 不同初始投影矩阵
Figure12. Recognition rates based on different initial matrix

图13为迭代次数与目标函数差值的曲线图, 从图13中可以看出, 随着迭代次数





 图 13 目标函数收敛曲线
图 13 目标函数收敛曲线Figure13. Convergence curve of the objective function.
最后, 表7给出有联合优化和无联合优化条件下, DSGE-HRPOG算法在PubFig数据库上的识别结果及对应最佳投影维度. 这里取初始投影矩阵


| DSGE-HRPOG | |||
| 3-HRPOG | 5-HRPOG | Ms-HRPOG | |
| with joint optimization | 54.20 (630) | 53.30 (473) | 53.70 (514) |
| without joint optimization | 53.50 (514) | 50.90 (423) | 53.20 (514) |
表7PubFig数据库上有联合优化和无联合优化的实验结果
Table7.Experimental results with joint optimization and without joint optimization on the PubFig database.
近年来, 有许多****[59,60]将图像、视频等数据组织为张量形式进行稀疏图映射降维, 避免了将多维数据强制表示为向量形式而引发的一系列问题. 下一步, 我们将研究基于张量特征字典的稀疏重构技巧及优化算法, 对流形学习与字典学习进行改进和推广, 力争进一步提高非约束人脸识别准确率.
