1.School of Management, Shanghai University of International Business and Economics, Shanghai 201620, China 2.College of Mathematics and Science, Shanghai Normal University, Shanghai 200234, China 3.Key Laboratory of Trustworthy Distributed Computing and Service, Beijing University of Posts and Telecommunications, Beijing 100876, China
Fund Project:Project supported by the Major Research Plan of the National Natural Science Foundation of China (Grant No. 91546121) and the Young Scientists Fund of the National Natural Science Foundation of China (Grant No. 71601005).
Received Date:02 November 2018
Accepted Date:17 January 2019
Available Online:23 March 2019
Published Online:05 April 2019
Abstract:In the age of Web 2.0, modeling and predicting the popularity of online information was an important issue in information dissemination. Online social medium greatly affects the way we communicate with each other. However, little is known about what fundamental mechanisms drive the dynamical information flow in online social systems. To address this problem, we develop a theoretical probabilistic model based on branching process to characterize the process in which micro-blog information gains its popularity. Firstly, the data of information popularity and network structure of micro-blog network are analyzed. The statistical results show that the attenuation of information popularity follows a scaling law whose exponent is 1.8, and in-degree and out-degree of micro-blog network each also obey a power law distribution whose exponent is 1.5. The results of power law distribution show that there is a high-degree heterogeneity in a micro-blog system. The proportion of micro-blog information with popularity less than 100 is 95.8%, while the amount of micro-blog information with popularity more than 10, 000 is very small. The number of fans (in-degree) less than 100 accounts for 56.4%, while some users have millions of fans.Secondly, according to the design mechanism of the Weibo system, we assume that each user has two lists, i.e. a "home page list" and a "personal page list". Meanwhile, each user has two states at each moment: generating a new message with probability ${\mu} $ to be sent out; 2) or forwarding the information already on the "personal page list" with probability $ (1-{\mu}) $ . Based on the assumptions, the information popularity model is proposed. Finally, the model is simulated. The simulation results show that the model can reproduce some features of real social network data, and the popularity of information is related to the network structure. By solving the model equation, the results of theoretical prediction are consistent with the simulation analyses and actual data. Keywords:statistical physics/ branching process/ complex network/ information popularity















 图 1 流行度模型示意图
图 1 流行度模型示意图
























































 图 2 微博的流行度分布
图 2 微博的流行度分布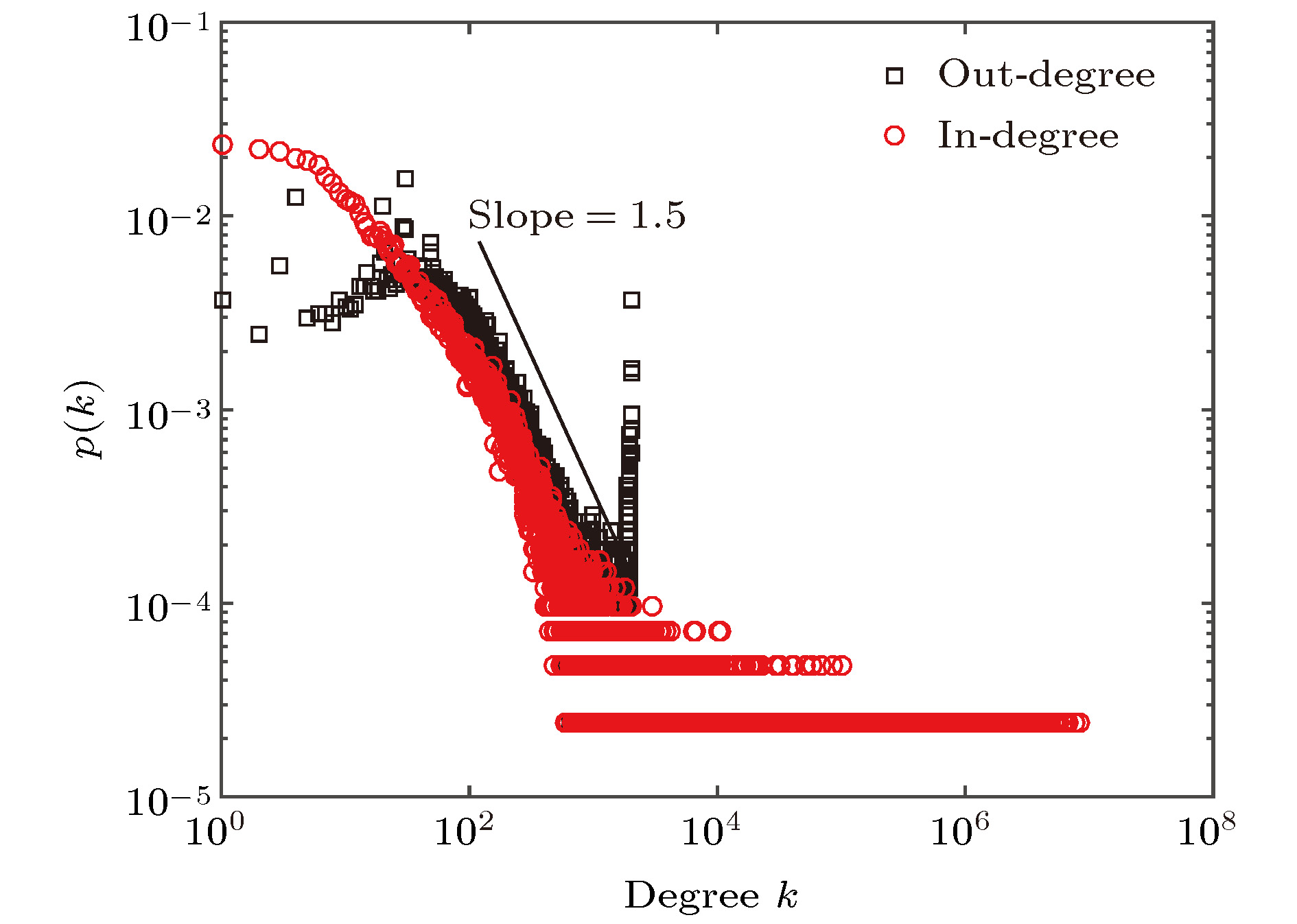 图 3 微博用户度分布
图 3 微博用户度分布










 图 4 微博信息平均流行度
图 4 微博信息平均流行度





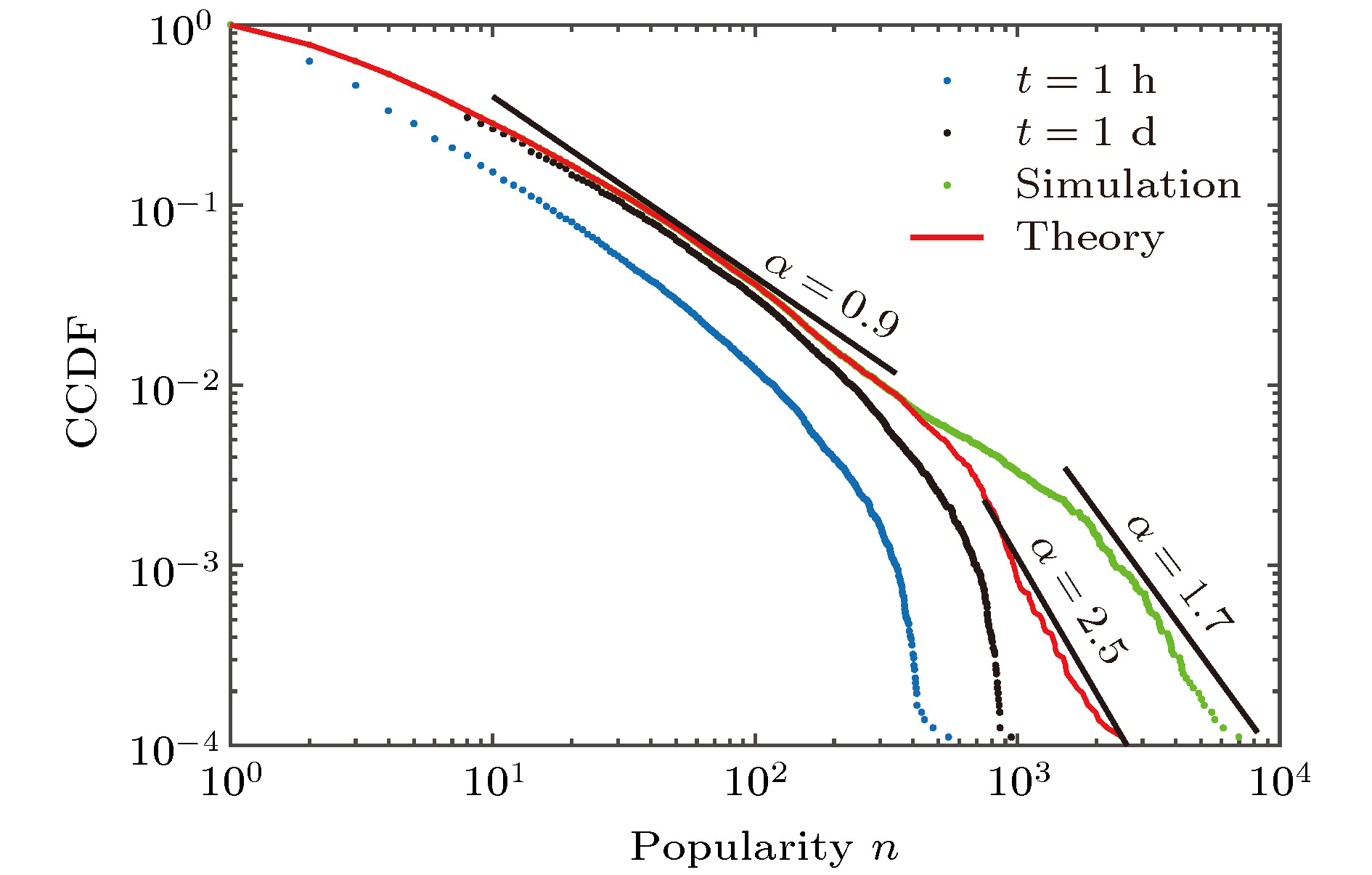 图 5 微博信息流行度的互补累积概率分布(CCDF)
图 5 微博信息流行度的互补累积概率分布(CCDF)
