 ,1,2, 陈旭,1,2, 陈婷婷,1,2, 朱军伟1,2, 唐碧霞1,2, 王安可1,2, 董丽莉1,2, 张哲文1,2, 孙艳玲1,2, 俞彩霞1,2, 翟爽1,2, 孙玉彬1,2, 陈焕新1,2, 杜政霖1,2,3, 肖景发1,2,3, 章张1,2,3, 鲍一明1,2,3, 王彦青1,2, 赵文明1,2,3
,1,2, 陈旭,1,2, 陈婷婷,1,2, 朱军伟1,2, 唐碧霞1,2, 王安可1,2, 董丽莉1,2, 张哲文1,2, 孙艳玲1,2, 俞彩霞1,2, 翟爽1,2, 孙玉彬1,2, 陈焕新1,2, 杜政霖1,2,3, 肖景发1,2,3, 章张1,2,3, 鲍一明1,2,3, 王彦青1,2, 赵文明1,2,3GSA-Human: Genome Sequence Archive for Human
Sisi Zhang,1,2, Xu Chen,1,2, Tingting Chen,1,2, Junwei Zhu1,2, Bixia Tang1,2, Anke Wang1,2, Lili Dong1,2, Zhewen Zhang1,2, Yanling Sun1,2, Caixia Yu1,2, Shuang Zhai1,2, Yubin Sun1,2, Huanxin Chen1,2, Zhenglin Du1,2,3, Jingfa Xiao1,2,3, Zhang Zhang1,2,3, Yiming Bao1,2,3, Yanqing Wang1,2, Wenming Zhao1,2,3通讯作者: 张思思,博士,工程师,研究方向:基因组学、生物信息学。E-mail:zhangss@big.ac.cn;陈旭,硕士,工程师,研究方向:生物信息学、计算机科学。E-mail:chenx@big.ac.cn;陈婷婷,硕士,工程师,研究方向:基因组学、生物信息学。E-mail:chentt@big.ac.cn; 张思思、陈旭和陈婷婷并列第一作者。
编委: 朱波峰
收稿日期:2021-07-13修回日期:2021-09-16
| 基金资助: |
Received:2021-07-13Revised:2021-09-16
| Fund supported: |

摘要
GSA-Human是人类遗传资源数据汇交、存储、管理与共享的数据库系统,可提供人类遗传资源数据的上传、下载、浏览、检索等公共服务,并有效支撑了国家重点研发计划科技项目数据的汇交与管理工作。系统具有符合《中华人民共和国人类遗传资源管理条例》数据安全管理策略,提供公开访问和受控访问相结合的数据使用模式。公开访问数据允许用户自由下载与获取;受控访问数据采用申请-审核的模式,即需要通过数据管理委员会(Data Access Committee, DAC)的授权方可获得下载和使用权限。系统自上线以来,截至2021年7月,汇集数据总量已超5.27 PB。
关键词:
Abstract
The Genome Sequence Archive for Human (GSA-Human) is a data repository specialized for human genetic related data derived from biomedical researches, and also supports the data collection and management of National Key Research and Development Projects. GSA-Human has a data security management strategy according to the national regulations of human genetic resources. It provides two different models of data access: Open-access and Controlled-access. Open-access data are universally and freely accessible for global researchers, while Controlled-access ensures that data are accessed only by authorized users with the permission of the Data Access Committee (DAC). Till July 2021, GSA-Human has housed more than 5.27 PB of data from 750 datasets.
Keywords:
PDF (559KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
张思思, 陈旭, 陈婷婷, 朱军伟, 唐碧霞, 王安可, 董丽莉, 张哲文, 孙艳玲, 俞彩霞, 翟爽, 孙玉彬, 陈焕新, 杜政霖, 肖景发, 章张, 鲍一明, 王彦青, 赵文明. GSA-Human:人类遗传资源数据管理的公共系统. 遗传[J], 2021, 43(10): 988-993 doi:10.16288/j.yczz.21-248
Sisi Zhang.
数据是21世纪的珍贵财产。人类遗传资源数据关系到人口健康和人类社会的可持续发展,是国家重要战略资源。2019年7月1日开始实施的《中华人民共和国人类遗传资源管理条例》(简称“条例”)明确了人类遗传资源范围,即人类遗传资源数据是指利用含有人体基因组、基因等遗传物质的器官、组织、细胞等材料产生的数据。该条例规定了人类遗传资源数据在采集、保藏、利用和对外开放方面的审批事项,为我国人类遗传资源数据的管理提供了指导思想。国家生物信息中心-国家基因组科学数据中心(National Genomics Data Center, China National Center for Bioinformation, CNCB-NGDC)于2015年建立的组学原始数据归档库(Genome Sequence Archive, GSA)(
1 GSA-Human系统建设
1.1 支持数据类型
通常,生命组学数据可分为三级:一级为原始测序数据,大多为通过基因测序仪或相关仪器设备产生的并经过简单整理和质量控制后的数据,这类数据含有最全面的信息;二级为原始测序数据经过一些处理,如序列比对、基因组拼接等操作后所产生的数据;三级为在二级数据的基础上进一步深加工产生的数据,如基因组的变异、基因注释、转录组表达量、表观组调控位点等分析结果数据。GSA-Human主要面向一级测序序列数据,支持当前主流测序平台,如二代测序平台Illumina、BGISEQ等,三代测序平台PacBio SMART、Bionano Genomics、Oxford Nanopore等。针对二、三级数据,CNCB- NGDC已建立了多个数据库系统收录并整合数据,如基因组数据库(Genome Warehouse, GWH)[4], 基因组变异数据库(Genome Variation Map, GVM)[5],基因组表达库(Gene Expression Nebulas, GEN)[6],甲基化数据库(Methylation Bank, MethBank)[7],多元数据归档库(Open Archive for Miscellaneous Data, OMIX)等。各数据库通过项目编号(BioProject accession)进行相互关联,相辅相成,形成了我国人类遗传资源数据安全存储和统一管理的公共平台。1.2 数据组织模式
GSA-Human中的数据包括元数据信息和测序序列数据。元数据信息主要为测序序列数据的描述信息,鉴于人类遗传资源承载的基本对象是人,GSA-Human使用“个体”(individual)来描述研究对象,并组织与此研究对象相关联的信息,主要包括“样本信息”(sample)、“实验信息”(experiment)、“测序反应”(run)信息以及对应的测序序列数据(sequence)。其中,“个体信息”是用于收集取样对象的基本信息,主要收集包括性别、身体形态指标、生活习惯、疾病、治疗情况以及其他属性信息。当取样对象为细胞系时,主要收集原代培养物或细胞系的取样组织、生理性别和种族来源等信息。“样本信息”是主要收集研究涉及的生物样本描述,如样本类型、样本属性等。为更加灵活的实现个体和样本的元数据信息的收集管理,GSA-Human采样用固定词条与自定义属性相结合的方式组织数据,即系统设置个性化的数据描述字段以满足不同的数据管理需求。“实验信息”包括实验目的、文库构建方式、测序类型等信息。“测序反应”信息为测序文件所对应的校验信息,测序文件则为各种测序平台的测序原始数据,主要测序格式包括Fastq、BAM等。GSA-Human系统中,一个或多个个体组成的数据组由“研究信息”(study)数据模型进行统一管理,包括研究类型、数据访问机制、数据备份号与备案号等信息。因此,“研究信息”被定义为GSA-Human中的一个独立数据集(dataset),并以“HRA+6位数字”(如“HRA000001”)编码进行唯一标识。各类数据元素之间采用层级及关联的模式进行组织,从而形成包括“研究(study)-个体(individual)-样本(sample)-实验(experiment)-测序反应(run)-序列数据(sequence)”的“金字塔”式的数据组织与管理模式。1.3 数据质控与审核
GSA-Human系统建立了元数据实时审核、人工审编和数据文件审编三个层次的数据质控与审核功能。元数据实时审核发生在数据录入过程中,审核内容包括数据合规性、一致性、控制词汇、专有术语和数据结构等。人工校验发生在数据录入之后,由GSA-Human的系统审编员执行,人工校验可以防止一些内容不当或垃圾信息进入系统并被公布,从而确保元数据信息的准确性,并使得系统中的数据干净整洁。数据文件审编由后台监控程序自动检测并触发运行,该过程主要检查用户递交序列数据的完整性和可靠性,防止数据文件在处理、压缩、拷贝、传输和存档过程中出现异常,自动化程序审核过程和内容包括:(1)文件压缩的正确性;(2)文件格式的合规性,目前主要的文件格式包括Fastq和Bam格式;(3)序列信息的统计,包括reads数量、碱基数量、reads长度、碱基数量分布和reads长度分布等。针对用户递交的数据集,只有当元数据和序列数据均通过审核,GSA-Human才为该数据集分配正式的访问序列号(accession number)。1.4 数据管理委员会
GSA-Human设置数据管理委员会(Data Access Committee, DAC)对数据的访问权限进行管理和控制。DAC由数据递交者提供并在递交数据时创建,每一个需要受控管理的数据集均需设置DAC,DAC中可包含一个或多个成员,一般由资深专家组成,且需要设定一名DAC联系人(DAC contact)。DAC是GSA-Human中审批数据使用请求的最终决策方,DAC成员负责审核用户请求,DAC联系人负责接收数据申请、组织DAC成员对数据申请进行审核、处理相关的决策决议。GSA-Human为每个DAC分配一个编号,并实现与其管理数据的关联与访问。1.5 数据安全保障措施
为保证人类遗传资源数据的存储安全,GSA- Human从系统架构整体设计了多重安全防护措施。在用户身份认证方面,采取双重认证方式,用户既需要通过CNCB-NGDC的单点登录系统(single sign- on, SSO)的密码认证,还需要在数据提交和申请下载的人工审核阶段,进行项目负责人身份信息核实,以确保数据的可溯源性。针对数据上传服务,GSA- Human为每个用户提供独立的数据存储空间,有效避免不同用户之间相互干扰,降低信息泄露的可能性,充分确保数据的安全性和私密性。在数据存储方面,采用磁盘和磁带库相结合的数据备份方式,防止因意外事故造成数据丢失。在用户下载数据方面,实现了用户身份认证和数据访问目录权限控制的系统开发,并通过数据文件软连接(soft link)、授权账户关联以及自动权限控制的模式实现数据的受控共享,既保证了数据的安全性,也保障了多用户同时访问同一数据时的效率。2 人类遗传资源数据汇交与共享
2.1 数据汇交原则与方法
为了有效管理和保护我国人类遗传资源数据,促进数据有序共享与合理利用,GSA-Human建立了人类遗传资源数据汇交的基本规范,核心内容包括:(1)数据递交者身份认证,只允许以课题研究组长的身份进行数据提交,从而确保数据的可溯源性;(2)伦理合规性,即数据递交者应已经从数据集对应的研究对象处获得知情同意书,并符合伦理原则,通过相应的伦理审查;(3)隐私保护性,数据递交者提供的信息必须对其研究对象的个人信息进行脱敏处理;(4)政策合法性,数据递交者在对外发布其数据集前,遵循科技部人类遗传资源信息备案流程获得数据集备份号及备案号;(5)遵守科研诚信与道德,数据递交者对其提交的数据质量负责。按照数据的组织模式,GSA-Human的数据递交包含两部分内容:元数据递交和序列文件递交。元数据递交主要为在线递交(
2.2 数据共享模式
GSA-Human提供公开访问和受控访问两种共享访问模式。公开访问即已经发布的数据可被任何人浏览和下载,用户对数据的使用无须向数据递交者申请;受控访问即对数据使用在一定限制下进行,用户在下载数据之前需要先获得该数据的使用授权。共享模式的选择由数据递交者自行设定,但需要遵守相关的规则:尚未获得人类遗传资源数据备案编号的数据集(商用细胞系和古人类数据除外,依照相关规定此两类数据无须备案备份)不能设置为公开访问,已获得备案编号的数据集,可以设置为公开访问或受控访问。GSA-Human支持的受控访问被称为“申请-审核制”(图1),即用户检索到所需数据集后(图1
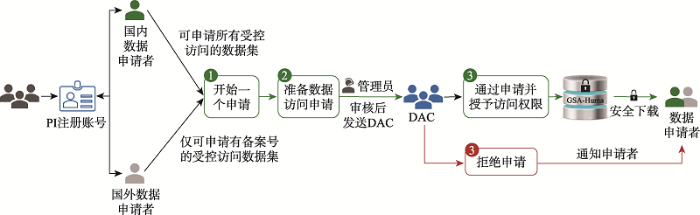 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1受控访问数据集申请下载流程
Fig. 1The Data Access Request wizard
3 GSA-Human运行状况
GSA-Human自正式上线运行以来,已接收了来自全球用户递交的人类遗传数据集750个,已发布数据集395个,其中受控访问数据集313个,公开访问数据集82个,而受控访问数据集中已获得备案备份号的仅43个);共合计收录个体数(individual) 71,283个,生物学样本数(sample)159,747个,实验数(experiment) 180,231个,测序反应数(run)216,546个,总数据量超过5.27 PB,数据日增量统计如图2所示。GSA-Human已接收来自550个用户的数据下载申请共808份,总数据下载量超过300 TB。GSA-Human已支撑数据递交用户在Cell、Science、Nature、Cancer Cell、Nature Immunology等66种国内外期刊发表论文117篇。此外,GSA-Human承担国家重点研发计划与人类遗传资源相关的多组学数据汇聚与统一管理工作,截至2021年7月,已接收来自国家重点研发计划项目的原始测序下机数据共计1.57 PB。图2
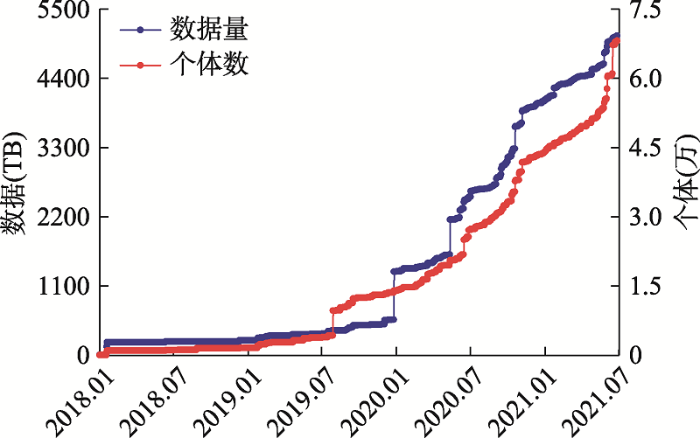 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2GSA-Human数据增长情况统计图
Fig. 2Statistics of data submissions of GSA-Human
4 结语与展望
GSA-Human作为人类遗传资源组学数据汇交、存储和受控访问管理系统,接受来自全球的科研工作者的数据提交和共享请求,为人类遗传资源数据共享与利用提供了良好的平台。同时,GSA-Human系统承担国家科技项目数据汇聚与管理任务,有力支撑了我国重大科研任务的科学数据管理。GSA-Human推行数据“申请-审核”制共享模式,采用数据管理委员会审批数据使用权限的机制,提升数据递交者对数据管理的自主权,在充分保障数据权益的同时激发了数据汇交的积极性,促进了我国人类遗传资源数据的共享与再利用。但随之而来的问题是大量的数据汇交与存储GSA-Human需求,这对当前系统的性能和数据存储能力,尤其是数据长期保存能力提出严峻的考验。因此,未来,GSA-Human将从软件和硬件两方面出发,加强自身能力的建设。针对软件系统层次,在数据汇交和共享方面,将进一步优化数据提交、审核和申请流程,以及管理和共享机制;在数据信息检索方面,完善检索机制,逐步实现数据特性化检索;在数据自动化处理方面,不断完善流程和算法,实现智能化数据处理。此外,在遵守国内外法律法规和道德规范的前提下,实现更加安全、快捷、高效的人类遗传资源数据管理和共享。在硬件系统层次,将加强计算机存储系统和网络带宽资源的建设,优化硬件设施以提升大数据传输与存储效率,同时,借鉴区块链、云计算、流计算等数据安全管理的特性和理念,建立人类遗传资源数据共享和使用的新模式。
(责任编委: 朱波峰)
参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}