 ,中国科学院遗传与发育生物学研究所,植物细胞与染色体工程国家重点实验室,基因组编辑中心,北京 100101
,中国科学院遗传与发育生物学研究所,植物细胞与染色体工程国家重点实验室,基因组编辑中心,北京 100101Progress on base editing systems
Yuan Zong, Caixia Gao,State Key Laboratory of Plant Cell and Chromosome Engineering, Center for Genome Editing, Institute of Genetics and Developmental Biology, Chinese Academy of Sciences, Beijing 10010, China通讯作者:
编委: 张博
收稿日期:2019-07-19修回日期:2019-08-7网络出版日期:2019-09-20
| 基金资助: |
Editorial board:
Received:2019-07-19Revised:2019-08-7Online:2019-09-20
| Fund supported: |
作者简介 About authors
宗媛,博士,研究方向:遗传学E-mail:

摘要
关键词:
Abstract
Keywords:
PDF (792KB)元数据多维度评价相关文章导出EndNote|Ris|Bibtex收藏本文
本文引用格式
宗媛, 高彩霞. 碱基编辑系统研究进展[J]. 遗传, 2019, 41(9): 777-800 doi:10.16288/j.yczz.19-205
Yuan Zong, Caixia Gao.
如何精准、高效地对基因组进行修饰是生命科学领域研究的重要目标。近年来,基因组编辑技术尤其是CRISPR/Cas9 (clustered regularly interspaced short palindromic repeats/CRISPR associated 9)介导的基因组编辑系统成为实现该目标的最强工具[1,2,3,4,5,6,7]。CRISPR/Cas9系统是在sgRNA引导下招募Cas9蛋白靶向基因组DNA,从而在靶点处产生DNA双链断裂(double strand break, DSB),诱发细胞内非同源末端连接(non-homologous end joining, NHEJ)和同源重组(homologous recombination, HR)修复途径,进而实现对基因组DNA的定点敲除、替换、插入等精准修饰[8]。其中,NHEJ途径发生频率较高,但通常是一种不精确的修复方式,往往会在靶点处产生少量碱基的插入或缺失(insertions/deletions, Indels),是一种有效地创制基因敲除突变体的途径。HR途径是一种更为精确的修复方式,需要人为提供与基因组DNA具有同源序列的供体DNA,以供体DNA为模板进行重组修复,最终实现精准的基因定点替换或定点插入[8]。
单核苷酸变异会导致约2/3人类疾病的发生[9],也是许多作物重要农艺性状变异的遗传基础[10],因此如何开发一种精准且高效实现碱基替换的技术尤为重要。理论上,HR途径可实现任意碱基之间的改变,但该途径受细胞类型及细胞周期的限制,且如何将供体DNA高效递送到细胞中也是一大难题,这些弊端导致HR在动植物中的发生频率及应用范围均受到了一定的限制[11]。另外,NHEJ途径会与HR途径竞争发生,因此往往会造成靶点处不必要的编辑产物的产生。因此,DSB引发的HR很难实现高效的、稳定的单碱基突变。
2016年,碱基编辑系统(base editing)的开发将CRISPR/Cas系统从切割DNA的“剪刀”变为能改写特定碱基的“修正器”,打开了精准基因组编辑的大门。该系统目前已被广泛地应用于农业、基因治疗、作物育种等各个领域的研究[12,13,14,15,16,17]。2017年,Science杂志将碱基编辑技术评为年度十大科学技术突破之一。
1 碱基编辑系统的概况及特点
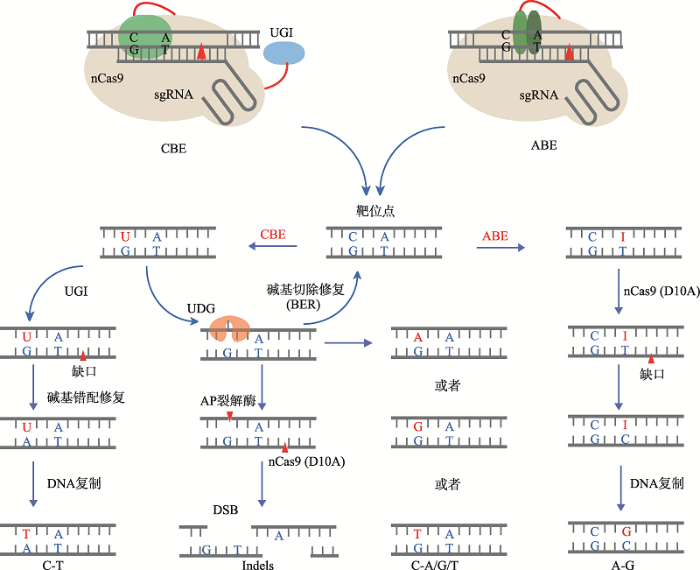
碱基编辑系统将失去催化活性的Cas蛋白(如deactivated Cas,简称dCas)或只有切割一条链活性的Cas蛋白(如nickase Cas,简称nCas)和可作用于单链DNA (single-stranded DNA, ssDNA)的脱氨酶进行融合,从而实现对靶点的碱基替换。目前碱基编辑系统依据融合的不同碱基修饰酶分为胞嘧啶碱基编辑器(cytosine base editors, CBE)和腺嘌呤碱基编辑器(adenine base editors, ABE)[12]。这两种碱基编辑器能在不产生DSB的情况下,分别利用胞嘧啶脱氨酶或经过改造的腺嘌呤脱氨酶对靶位点上一定范围的胞嘧啶(C)或腺嘌呤(A)进行脱氨基反应,最终经DNA修复或复制,实现精准的C-T或A-G的替换 (图1)。该系统与传统的基于HR途径实现点突变的方法相比,主要优势如下(表1):图1
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图1CBE和ABE工作模式图
Fig. 1Mechanisms of CBE and ABE
(1)不依赖DSB的产生。HR途径必须依赖DSB的产生才有可能实现基因定点替换,并且在该过程中会不可避免的激发NHEJ途径产生的非必要Indels产物。有效DSB的发生通常需要科研人员花费较大的精力去找寻并筛选出足够高活性的sgRNA或Cas核酸酶。另一方面,当细胞内产生大量甚至过量的DSB后会对细胞带来较大的毒性,从而会对生物体造成一定的影响。而碱基编辑系统由于利用失去切割活性的或只有一条链切割活性的Cas蛋白来实现靶位点处碱基的定点替换,因此不依赖DSB的产生。尽管有相关报道证明CBE系统会产生一 定的Indels,但效率远远低于其介导的单碱基替换 效率[12]。
(2)无需供体DNA的参与。HR途径必须在提 供外源供体DNA的前提下才能实现碱基的定点替换。供体DNA形式目前主要包括环形双链DNA (double-stranded DNA, dsDNA)、线性dsDNA和单链DNA (single-stranded DNA, ssDNA) 3种形式。而CBE系统在胞嘧啶脱氨酶及UGI的作用下将靶位点处一定活性窗口内的C脱氨变为U,经DNA修复和复制后实现C-T的突变(左);CBE系统经胞嘧啶脱氨酶、UDG、AP裂解酶等作用下会产生非C-T或Indels的突变(中);ABE系统在腺嘌呤脱氨酶的作用下将A脱氨变为I,经DNA修复和复制后实现A-G的突变(右)。
Table 1
表1
表1 CBE、ABE和HR的比较
Table 1
| 比较项目 | CBE | ABE | HR |
|---|---|---|---|
| DNA切割 | SSB | SSB | DSB |
| 编辑结果 | C-T | A-G | 任意 |
| 产物纯度 | > 90% | > 99% | 5%~50% |
| 效率 | 高 | 高 | 低 |
| 供体DNA | 不需要 | 不需要 | 需要 |
| 细胞周期 | 不依赖 | 不依赖 | 依赖 |
| 基因组重排 | 否 | 否 | 是 |
| 全基因组脱靶 | 严重 | 否 | 否 |
| RNA水平脱靶 | 严重 | 严重 | 否 |
新窗口打开|下载CSV
对于选择何种形式的供体DNA以及确定供体DNA形式后又应该设计多少长度的同源序列才能够达到最佳的同源重组效果,这在不同的动物细胞系或不同的植物体中均不相同,目前还没有明确的统一的方法[4]。此外,如何将足量的供体DNA有效地递送到细胞中也是目前的一大难题。碱基编辑系统无需提供供体DNA,有效地避免了上述各种不确定性。该系统借助于胞嘧啶脱氨酶或腺嘌呤脱氨酶的作用,通过sgRNA的引导直接对靶标碱基进行脱氨,从而高效地实现C-T或A-G的突变。
(3)高效性和广适性。HR一般发生在分裂的细胞,并且只能发生在细胞的S期和G2期[11],这使其在动植物中发生的频率较低,尤其在植物中HR的阳性筛选往往需要依赖除草剂抗性基因或靶标基因附近的抗生素基因来富集提高效率,因此大多数报道仅仅局限于对某些特殊的基因如ALS和EPSPS等的研究[4,11],使其很难被广泛地应用。而碱基编辑系统介导的碱基替换在动植物中均表现出高效的优势,且已被广泛地应用于各种动物细胞系、人类胚胎、各种哺乳动物、非哺乳动物、单双子叶植物、细菌、真菌等中[12,13,15,16]。
但是相比HR,碱基编辑系统目前只能实现碱基之间的转换(transition)而不能实现碱基之间的颠换(transversion),并且其在全基因组范围和RNA水平存在较高的脱靶效应(下文将详细介绍)。但从整体来看,碱基编辑系统的开发及不断的优化发展为生命科学领域带来了新的曙光。
2 CBE碱基编辑系统
2.1 CBE系统的开发
CBE一般由胞嘧啶脱氨酶、nCas9或dCas9组成[12,18]。具体工作原理是当CBE融合蛋白在sgRNA的引导下靶向基因组DNA时,胞嘧啶脱氨酶可结合到由Cas9蛋白、sgRNA及基因组DNA形成的R-loop区的ssDNA处,将该ssDNA上一定范围内的胞嘧啶(C)脱氨为尿嘧啶(U),进而通过DNA修复或复制将U转变为胸腺嘧啶(T),最终实现C至T (C-T)或G至A (G-A)的直接替换[18] (图1)。自然界中存在的胞嘧啶脱氨酶大多数作用于RNA,而APOBEC (apolipoprotein B mRNA editing enzyme, catalyticpolypeptide-like)家族是目前报道的少数可作用于单链DNA的胞嘧啶脱氨酶,该类脱氨酶共同特点是都有一个能对碱基C进行脱氨的CDA (cytidine deaminase)保守结构域,通过与CRISPR系统相结合,该类胞嘧啶脱氨酶由传统的“突变器”被开发为新型的“编辑器”[18]。
2016年,美国哈佛大学David R. Liu实验室率先建立了3种基于融合来源大鼠胞嘧啶脱氨酶rAPOBEC1的碱基编辑器(base editors, BE)[18]。第一代碱基编辑器BE1 (rAPOBEC1-XTEN-dCas9)由rAPOBEC1和完全失去切割活性的dCas9组成,可在体外实现有效的C-T碱基的编辑(25%~40%),编辑的活性窗口可覆盖sgRNA的第4~8位(PAM计为第21~23位),但该碱基编辑器在哺乳动物细胞内的编辑效率却大大下降(0.8%~7.7%)。这在很大程度上与细胞体内存在的尿嘧啶DNA糖基化酶(uracil DNA glycosylase, UDG)有关,UDG可识别U?G错配,并切割尿嘧啶和脱氧核糖骨架之间的糖苷键,通过细胞内的碱基错配修复途径(base excision repair, BER)逆转由BE1产生的U?G中间产物返回到C?G碱基对(图1)。为了抑制UDG的作用,David R. Liu实验室在BE1基础上融合了来自噬菌体PBS的尿嘧啶DNA糖基化酶抑制剂(uracil DNA glycosylase inhibitor, UGI),开发了第二代碱基编辑器BE2 (rAPOBEC1-XTEN-dCas9-UGI)。UGI能够抑制人类和细菌中的UDG作用,在一定程度上增加C-T的编辑效率,经测试BE2比BE1编辑效率提高了3倍。随后,该实验室结合细胞的内源修复机制开发了第三代碱基编辑器BE3 (rAPOBEC1-XTEN-nCas9-UGI)。BE3将BE2中的dCas9替换为nCas9 (D10A),可特异性的将非编辑链产生一个缺口,进而刺激细胞内碱基错配修复途径(mismatch repair, MMR)以含有C的编辑链作为模板进行修复,从而增加碱基编辑效率。研究结果表明,BE3在人类细胞的6个位点中可实现平均约37%的编辑效率,比BE2提高了2~6倍,其编辑窗口仍为第4~8位,该碱基编辑器也是目前使用较为广泛的CBE版本。
另外,日本神户大学Akihiko Kondo实验室采用上述类似策略将来源于七鳃鳗(Lampetra japonicum)的胞嘧啶脱氨酶PmCDA1用于开发新的碱基编辑器—Targeted-AID[19]。研究人员通过该系统成功在酵母及哺乳动物细胞中实现了C-T的定点替换,效率分别高达80%及10%,编辑窗口为sgRNA的第5~9位,相比BE3的编辑窗口略大。
同年,基于融合人类胞嘧啶脱氨酶hAID的碱基编辑系统也被建立[20,21]。其中,中国科学院上海生命科学研究所健康所常兴实验室开发的TAM系统融合了dCas9及UGI[20];美国斯坦福大学Michael C. Bassik实验室开发的CRISPR-X同样融合了dCas9,不同的是该碱基编辑器未融合UGI并且通过MS2招募hAID脱氨酶[21]。这两种系统在转入多个sgRNA的情况下,可以在哺乳动物细胞中实现较大范围(编辑范围宽达100 nt)以及较多类型的碱基编辑。
另外,美国哈佛大学George M. Church实验室开发了基于融合ZF或TALE特异性识别单元与hAID的碱基编辑系统[22]。相比上述基于融合Cas9变体的碱基编辑系统,这两种碱基编辑器无PAM的需求,但在细菌及人类细胞中的编辑效率明显下降,猜测原因是由于ZF或者TALE识别DNA特定区域后仍以dsDNA形式存在,未能够提供胞嘧啶脱氨酶工作时所需要的ssDNA底物,从而降低了脱氨酶的催化效率。
2.2 CBE系统的限制及优化
2.2.1 编辑产物纯度多项研究表明,经CBE系统编辑后的编辑产物纯度并不高,主要表现在两方面:(1) CBE除将C编辑为T之外,也有一定几率将C编辑为G或A[12]。这是由于UDG可将碱基U切除形成无嘧啶位点(apyrimidinic site, AP),经过跨损伤合成(translesion synthesis, TLS)聚合酶作用及DNA复制等,也有一定的几率将该位置原始碱基C替换为其他碱基(图1);(2)在编辑过程中会产生少量的Indels[12,18],这是由于形成的AP位点会在AP裂解酶或自发断裂下产生一个缺口,进而与nCas9在非编辑链产生的缺口刚好形成一个DSB,经过NHEJ修复途径后会产生非必要的Indels产物(图1)。David R. Liu实验室在BE3的基础上融合了第二个拷贝的UGI,构建了第四代碱基编辑器BE4。测试结果表明,BE4不仅提高了碱基编辑效率,并且非C至T的替换效率相比BE3降低了2.3倍[23]。上海科技大学陈佳实验室采取类似策略,通过优化UGI的表达量,将UGI增至4个拷贝,建立的eBE-S3在哺乳动物细胞中同样提高了编辑产物纯度[24]。因此,通过添加更多拷贝UGI的策略对提高编辑产物纯度具有重要作用。另外,David R. Liu实验室进一步建立的BE4-Gam碱基编辑器可有效降低Indels的发生,这是由于融合的来源于噬菌体Mu的Gam蛋白可结合于DSB的末端防止其降解,进而阻止了NHEJ途径的发生[23]。而基于融合环化的Cas9的4种CP-CBEmax编辑器也可一定程度的降低副编辑产物的发生[25]。
2.2.2 碱基编辑效率
研究发现,细胞内碱基编辑器的表达水平是影响其编辑效率的一个重要因素。David R. Liu实验室通过增加不同个数的核定位信号(nuclear localization signal, NLS)以及使用不同公司优化的密码子序列等方法构建了BE4max和AncBE4max,这两种碱基编辑器可在各种哺乳动物细胞进行高效编辑[26]。Zafra等[27]通过增加NLS个数、改变NLS位置以及将nCas9密码子优化为哺乳动物细胞所偏好的密码子序列,开发的FNLS-BE3的编辑效率相比BE3平均提高了15倍。另外,本实验室开发的基于融合人类APOBEC3A胞嘧啶脱氨酶的A3A-PBE可在植物中实现比BE3平均高约13倍的碱基编辑效率[28]。
2.2.3 碱基编辑范围
上述碱基编辑器均是融合SpCas9,因此只能靶向NGG序列的PAM形式,大大限制了CBE在基因组中的靶向范围。为此,研究人员将SpCas9替换为其他Cas蛋白或相应变体,通过不同Cas蛋白识别不同PAM,进而扩大CBE系统在基因组中的编辑 覆盖度。目前SpCas9的不同变体(VQR、EQR和VRER)、SaCas9和SaCas9的变体SaKKH与胞嘧啶脱氨酶的融合成功将CBE由NGG的PAM拓展为相应的NGA、NGCG、NNGRRT和NNNRRT等多种PAM形式[29,30]。而dCpf1和Sp-macCas9的融合将CBE由识别富含GC序列拓宽至识别富含AT序列的的PAM位点[31,32,33]。值得一提的是,基于融合xCas9及SpCas9-NG变体的两种碱基编辑器的开发使CBE系统可实现直接靶向NG PAM形式的位点[34,35]。
2.2.4 碱基编辑活性窗口
不同类型的CBE的碱基编辑窗口有略微的不同,依据不同的研究目的需要对编辑活性窗口做相应的改变。当被用于精准改变某个特定的碱基C时,过大的脱氨化窗口会导致窗口内非靶标碱基C的编辑,使得CBE系统被用于基因治疗等领域时存在一定风险。David R. Liu实验室通过突变rAPOBEC1胞嘧啶脱氨酶上与DNA作用的关键酶活位点,开发了YE1-BE3、YE2-BE3、EE-BE3和YEE-BE3碱基编辑器,进而可将脱氨窗口由5 nt缩小至1~2 nt,但同时对靶标C的编辑效率有所降低[29]。德国马普分子植物生理所Ralph Bock实验室开发的BE3-PAPAPAP以及通过缩短PmCDA1脱氨酶羧基端序列而建立的一系列nCDA1-BE3版本,能够在保证对靶标C编辑效率依然高效的同时,可有效将编辑的活性窗口缩小到1~2 nt[36]。但如何进一步缩小突变窗口,真正做到只改变单一碱基而不影响旁侧序列,将是碱基编辑系统今后重点攻克的方向。
另外,当CBE系统被用于基因功能筛选、大规模饱和突变、编辑调控元件、引入提前终止密码子或进行可变剪接等时,更大的编辑活性窗口是更为有利的。Jiang等[37]采取SunTag系统策略开发了BE-PLUS系统,从而将BE3的突变窗口由5 nt (4~8)拓宽至13 nt (4~16)。基于融合hA3A胞嘧啶脱氨酶的碱基编辑器在人类细胞及植物中脱氨化的窗口可分别宽达14 nt (2~13)和17 nt (1~17)[28,38]。而CP1020- CBEmax和CP1028-CBEmax的编辑活性窗口可覆盖sgRNA的8~9 nt[25]。Liu等[39]通过改造开发的DBE- A3A和DBE-AIDmono可将突变窗口拓宽为2~17位,并且依赖DBE系统可在体外培养的细胞中实现抗体亲和成熟。
2.2.5 序列背景依赖性
基于融合rAPOBEC1的BE3具有强烈偏好TC序列,而对GC序列基本无编辑活性的特点[18]。而基于融合hAID、PmCDA1和hA3A的碱基编辑系统均可在GC序列背景下有效地编辑[23,28,40],且hA3A- BE3可对高甲基化区域有较强的编辑活性[38]。而美国麻省总医院Keith Joung实验室通过加强碱基编辑效率依赖序列背景的特性,开发了eA3A-BE3,该碱基编辑器在保证其偏好TC序列背景的前提下,对其他序列背景下C的编辑活性大大下降,也进一步降低了对邻近非靶标C的编辑[41]。类似的,基于融合人类hAPOBEC3G的hA3G-BE3只特定的编辑CC序列的第二个C或CCC序列的后两个C[42]。
总之,针对胞嘧啶碱基编辑系统的各种不足之处,科研人员们不断开发和优化出新的碱基编辑器,极大地丰富了碱基编辑工具盒。上述各种碱基编辑器具体构建及编辑特性见表2。
2.3 CBE系统的应用
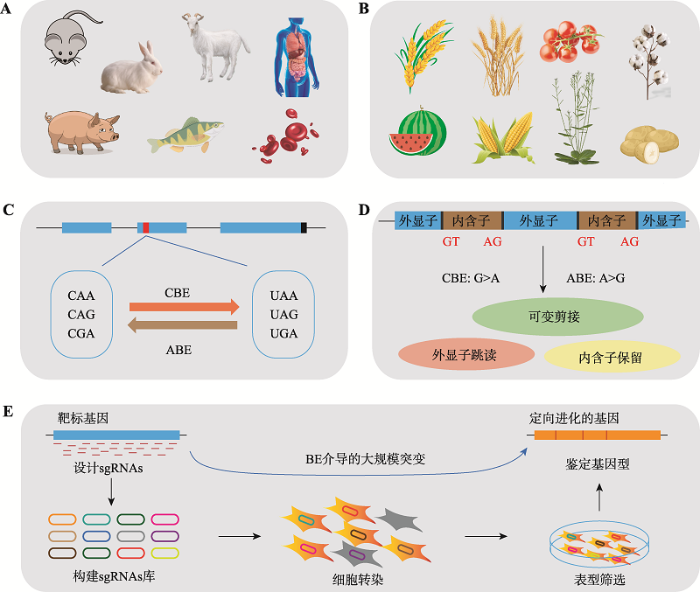
胞嘧啶碱基编辑系统自开发以来,被迅速的广泛应用于各种动物细胞系、人类胚胎、动物、植物及细菌等基础体系的建立(图2,表3),其中包括酵母(Saccharomyces cerevisiae)、真菌、小鼠(Mus musculus)、斑马鱼(Barchydanio rerio var)、兔子(Oryctolagus cuniculus)、家蚕(Bombyx mori L.)、海胆(Strongylocentrotus purpuratus)、非洲爪蟾(Xenopus laevis)、猪(Sus scrofa domastica L.)、羊(Capra hircus L.)、水稻(Oryza sativa L.)、小麦(Triticum aestivum L.)、玉米(Zea mays L.)、番茄(Lycopersicon esculentum Mill.)、拟南芥(Arabidopsis thaliana)、马铃薯(Solanum tuberosum L.)、西瓜(Citrullus lanatus L.)、棉花(Gossypium hirsutum L.)和细菌等[12,13,15,16,43~50]。除此之外,该系统也被用于基因治疗、动物疾病模型建立、植物重要农艺性状创制等方面[12,13,15] (图2,表3)。2.3.1 基因治疗及动物疾病模型的建立
CBE系统的开发为精准基因治疗提供了强有力的技术手段。通过CBE在各种细胞系水平上修正相应致病位点的研究已经很多,其中包括Komor等[18]利用BE3在小鼠星形胶质细胞中修正了与阿尔兹海默症相关的APOE4基因的突变;Zara等[27]在小鼠肝脏细胞中通过递送密码子优化的FNLS-BE3纠正了与癌症相关的Ctnnb1 S45F突变;Komor等[18]在人类乳腺癌细胞中纠正了p53 Y163C突变;Koblan等[26]在来源于病人的原发性纤维细胞中实现了MPDU1、HBB等位基因的纠正等。而在哺乳动物体内及人类胚胎中实现致病基因的定向修正也有相关报道,如Chadwick等[51]在成年小鼠中通过慢病毒递送BE3,对PCSK9基因进行提前终止突变,可大幅度降低小鼠血浆中PCSK9蛋白表达水平及胆固醇水平;Yang等[52]对组蛋白相关基因进行点突修饰,探索了表观调控在小鼠胚胎发育中的重要性。Zeng等[53]在人类细胞和杂合子胚胎中纠正了马凡综合征致病性FBN1突变;中山大学黄军就实验室在重构的人类胚胎中修复了引起β-地中海贫血病的HBB突变[54];中国科学院上海生命科学研究院神经科学研究所杨辉实验室研究发现在人类胚胎的二细胞期注射BE3比在一细胞期注射时对基因的编辑效率更高,这为研究人类胚胎发育中的基因功能提供了一种强有力的方法[55]。
Table 2
表2
表2 各种碱基编辑器(BE)的特点
Table 2
| BE名称 | 脱氨酶 | Cas蛋白 | PAM 类型 | UGI 个数 | NLS 个数 | 密码子 优化 | 编辑 活性窗口 | 参考 文献 |
|---|---|---|---|---|---|---|---|---|
| BE1 | rAPOBEC1 | dCas9 | NGG | - | 1× | - | 4~8 | [18] |
| BE2 | rAPOBEC1 | dCas9 | NGG | 1× | 1× | - | 4~8 | [18] |
| BE3 | rAPOBEC1 | nCas9 | NGG | 1× | 1× | - | 4~8 | [18] |
| PBE | rAPOBEC1 | nCas9 | NGG | 1× | 3× | + | 3~9 | [82] |
| HF-BE3 | rAPOBEC1 | HF1-nCas9 | NGG | 1× | 1× | - | 4~8 | [123] |
| HF2-BE2 | rAPOBEC1 | HF2-dCas9 | NGG | 1× | 1× | - | 4~8 | [58] |
| BE4 | rAPOBEC1 | nCas9 | NGG | 2× | 1× | - | 4~8 | [23] |
| BE4-Gam | rAPOBEC1 | nCas9 | NGG | 2× | 1× | - | 4~8 | [23] |
| BE4max | rAPOBEC1 | nCas9 | NGG | 2× | 2× | - | 4~8 | [26] |
| AncBE4max | rAPOBEC1 | nCas9 | NGG | 2× | 2× | + | 4~8 | [26] |
| eBE-S3 | rAPOBEC1 | nCas9 | NGG | 4× | 1× | - | 4~8 | [24] |
| FNLS-BE3 | rAPOBEC1 | nCas9 | NGG | 1× | 2× | + | 3~8 | [27] |
| VQR-BE3 | rAPOBEC1 | nVQRCas9 | NGA | 1× | 1× | - | 4~11 | [29] |
| EQR-BE3 | rAPOBEC1 | nEQRCas9 | NGAG | 1× | 1× | - | 4~11 | [29] |
| VRER-BE3 | rAPOBEC1 | nVRERCas9 | NGCG | 1× | 1× | - | 3~10 | [29] |
| SaBE3 | rAPOBEC1 | nSaCas9 | NNGRRT | 1× | 1× | - | 3~12 | [29] |
| SaBE4 | rAPOBEC1 | nSaCas9 | NNGRRT | 2× | 1× | - | 3~12 | [23] |
| SaBE4-Gam | rAPOBEC1 | nSaCas9 | NNGRRT | 2× | 1× | - | 3~12 | [23] |
| SaKKH-BE3 | rAPOBEC1 | nSaKKHCas9 | NNNRRT | 1× | 1× | - | 3~12 | [29] |
| Spy-macnCas9-BE3 | rAPOBEC1 | Spy-nmacCas9 | NAA | 1× | 1× | - | 4~8 | [31] |
| dCpf1-eBE | rAPOBEC1 | dCpf1 | TTTV | 4× | 3× | - | 8~13 | [32] |
| enAsBE1.1-1.4 | rAPOBEC1 | denAsCas12a | TTTV | 1× | 1×-4× | - | -5~25 | [33] |
| xBE3 | rAPOBEC1 | nxCas9 | NG | 1× | 1× | - | 4~8 | [34] |
| BE3-NG | rAPOBEC1 | nSpCas9-NG | NG | 1× | 1× | - | 4~8 | [35] |
| YE1-BE3 | rAPOBEC1-YE1 | nCas9 | NGG | 1× | 1× | - | 4~7 | [29] |
| YE2-BE3 | rAPOBEC1-YE2 | nCas9 | NGG | 1× | 1× | - | 5~6 | [29] |
| EE-BE3 | rAPOBEC1-EE | nCas9 | NGG | 1× | 1× | - | 5~6 | [29] |
| YEE-BE3 | rAPOBEC1-YEE | nCas9 | NGG | 1× | 1× | - | 5~6 | [29] |
| BE3-PAPAPAP | rAPOBEC1 | nCas9 | NGG | 1× | 1× | - | 5~6 | [36] |
| BE3-R33A | rAPOBEC1-R33A | nCas9 | NGG | 1× | 1× | - | 5~7 | [131] |
| BE3-R33A/K34A | rAPOBEC1-R33A/K34A | nCas9 | NGG | 1× | 1× | - | 5~6 | [131] |
| BE-PLUS | rAPOBEC1-scFV | nCas9 | NGG | 1× | 1× | - | 4~16 | [37] |
| CP-CBEmax | rAPOBEC1 | CP-nCas9 | NGG | 2× | 1× | - | 4~11 | [25] |
| eA3A-BE3 | hAPOBEC3A-N57G | nCas9 | NGG | 1× | 1× | - | 4~8 | [41] |
| eA3A-HF1-BE3-2xUGI | hAPOBEC3A-N57G | HF1-nCas9 | NGG | 2× | 1× | - | 4~8 | [41] |
| eA3A-Hypa-BE3-2xUGI | hAPOBEC3A-N57G | nHypaCas9 | NGG | 2× | 1× | - | 4~8 | [41] |
| hA3A-BE3 | hAPOBEC3A | nCas9 | NGG | 1× | 1× | - | 2~13 | [38] |
| hA3A-BE3-Y130F | hAPOBEC3A-Y130F | nCas9 | NGG | 1× | 1× | - | 3~8 | [38] |
| A3A-PBE | hAPOBEC3A | nCas9 | NGG | 1× | 2× | + | 1~17 | [28] |
| DBE-A3A | hAPOBEC3A-MS2 | nCas9 | NGG | 1× | 1× | - | 2~17 | [39] |
| hA3AR128A | hAPOBEC3A-R128A | nCas9 | NGG | 1× | 1× | - | 3~9 | [133] |
| A3G-BE4max | hAPOBEC3G-CTD | nCas9 | NGG | 2× | 1× | - | 4~10 | [42] |
| Target-AID | PmCDA1 | nCas9 | NGG | 1× | 1× | - | 2~8 | [19] |
| Target-AID-NG | PmCDA1 | nCas9 | NG | 1× | 1× | - | 2~8 | [35] |
| nCDA1-BE3 | PmCDA1Δ | nCas9 | NGG | 1× | 1× | - | 3~4 | [36] |
| TAM | hAIDx | dCas9 | NGG | 1× | 1× | - | 4~10 | [20] |
| CRISPR-X | hAIDΔ-MS2 | dCas9 | NGG | - | 1× | - | -50~50 | [21] |
| eAID-BE4max | hAID | nCas9 | NGG | 2× | 2× | + | 4~8 | [40] |
| DBE-AIDmono | hAID-mono-MS2 | nCas9 | NGG | 1× | 1× | - | 2~17 | [39] |
| ZF-AID | hAID | ZF | - | 1× | 1× | - | - | [22] |
| TALE-AID | hAID | TALE | - | 1× | 1× | - | - | [22] |
| ABE7.9 | TadA-TadA* | nCas9 | NGG | 1× | 1× | - | 4~9 | [107] |
| ABE7.10 | TadA-TadA* | nCas9 | NGG | - | 1× | - | 4~7 | [107] |
| PABE-7 | TadA-TadA* | nCas9 | NGG | - | 1× | + | 4~7 | [108] |
| ABEmax | TadA-TadA* | nCas9 | NGG | - | 2× | + | 4~7 | [26] |
| VQR-ABE | TadA-TadA* | nVQRCas9 | NGA | - | 1× | +/- | 4~8 | [30,114] |
| VQR-ABEmax | TadA-TadA* | nVQRCas9 | NGA | - | 2× | + | 4~8 | [25] |
| VRER-ABE | TadA-TadA* | nVRERCas9 | NGCG | - | 1× | + | 4~8 | [30] |
| VRER-ABEmax | TadA-TadA* | nVRERCas9 | NGCG | - | 2× | + | 4~8 | [25] |
| VRQR-ABEmax | TadA-TadA* | nVRQRCas9 | NGA | - | 2× | + | 4~8 | [25] |
| ABEsa | TadA-TadA* | nSaCas9 | NNGRRT | - | 1× | + | 6~12 | [111] |
| SaABEmax | TadA-TadA* | nSaCas9 | NNGRRT | - | 2× | + | 4~14 | [25] |
| SaKKH-ABE | TadA-TadA* | nSaKKHCas9 | NNNRRT | - | 1× | + | 8~13 | [30,117] |
| SaKKH-ABEmax | TadA-TadA* | nSaKKHCas9 | NNNRRT | - | 2× | + | 4~14 | [25] |
| xABE | TadA-TadA* | nxCas9 | NG | - | 1× | - | 4~7 | [34] |
| xABEmax | TadA-TadA* | nxCas9 | NG | - | 2× | + | 4~8 | [25] |
| ABE-NG | TadA-TadA* | nSpCas9-NG | NG | - | 1× | + | 4~7 | [74] |
| ABE-NG-S | TadA* | nSpCas9-NG | NG | - | 1× | + | 4~7 | [74] |
| NG-ABEmax | TadA-TadA* | nSpCas9-NG | NG | - | 2× | - | 4~8 | [35] |
| CP-ABEmax | TadA-TadA* | CP-nCas9 | NGG | - | 2× | + | 4~12 | [25] |
| ScCas9-ABE(7.10) | TadA-TadA* | nScCas9 | NNGN | - | 1× | - | 4~7 | [109] |
| ABEmaxAW | TadA-E59A-TadA*-V106W | nCas9 | NGG | - | 2× | + | 4~8 | [132] |
| ABEmaxQW | TadA-E59Q-TadA*-V106W | nCas9 | NGG | - | 2× | + | 4~8 | [132] |
| ABE7.10F148A | TadA-F148A-TadA*-F148A | nCas9 | NGG | - | 1× | - | 5 | [133] |
新窗口打开|下载CSV
点突变动物模型的建立可通过HR实现,但该途径效率低且周期长,并不能被广泛的应用。目前通过CBE系统已在多种动物中建立了相应的疾病模型(图2A,表3)。在小鼠中建立的疾病模型类型最多,包括白化病、肌营养不良、肝病和雄性激素不敏感综合征等[56],其中韩国首尔国立大学Jin-Soo Kim实验室通过BE3 mRNA编辑小鼠胚胎基因Tyr和Dmd而建立了相应的小鼠白化病和肌营养不良疾病模型[57];中山大学松阳洲实验室利用HF2-BE2也建立了小鼠白化病模型[58];Sasaguri等[59]利用BE3和Targeted-AID系统在小鼠中引入了与早衰症相关的Psen1基因的突变;Villiger等[60]在成年小鼠中利用AAV慢病毒载体递送分割的BE3系统,修正了Pah突变,治疗了代谢肝病;Li等[61]利用hA3A-BE3- Y130F编辑富含GC的区域,获得了雄性激素不敏感综合征的小鼠。在大型哺乳动物如兔子、猪和羊中也有相关疾病模型的建立。兔子中,利用BE3、BE4-Gam、AID-nCas9和hA3A-eBE-N57G等不同的CBE碱基编辑器建立了白化病、早衰症、双肌臀、X-连锁扩张性心肌病等疾病模型[62,63,64,65]。在猪中,Li等[66]利用BE3在猪胚胎成纤维细胞中编辑Twist2基因和TYR基因,而后通过体细胞核移植的方法建立了无脸巨口综合征和皮肤白化病的疾病模型;而中国科学院广州生物医药与健康研究院赖良学实验室在猪中首次实现了多个基因靶点的同时C-T突变,并建立了相应的疾病模型[67]。在羊中,利用BE3编辑SOC2和FGF5基因,成功获得了体重、尺寸和毛长等生长指标增加的突变体羊[68,69]。除了在哺乳动物中,在非哺乳动物斑马鱼和非洲爪蟾中建立模拟人类疾病的模型也有相关报道,其中Zhang等[70]通过编辑斑马鱼胚胎的Tyr基因建立了模拟人类眼白化病的疾病模型;Tanaka等[71]利用Targeted-AID编辑了斑马鱼基因chd和oep,并观察到了相应突变体表型。在非洲爪蟾中,Park等[72]通过转化BE3的RNP形式建立了白化病疾病模型;Shi等[73]利用BE3建立了模拟人类Holt-Oram综合征和眼皮白化病1A型的疾病模型。上述致病基因的点突动物模型的建立为进一步真正进行临床疾病治疗提供了坚实的基础。
图2
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图2碱基编辑系统的应用
A:基因治疗及动物疾病模型建立;B:植物中的应用;C:提前终止密码子的引入及改变;D:mRNA剪接;E:蛋白定向进化。
Fig. 2The applications of base editing systems
Table 3
表3
表3 碱基编辑系统在动物、植物和细菌中的应用
Table 3
| 物种 | BE名称 | 靶基因 | 参考文献啊 |
|---|---|---|---|
| 小鼠(Mus musculus) | BE3 | Dmd、Tyr、Vista、Cd160、CTNNB1、Hist1H3、Hist2H3、Carm1、Pcsk9、Hpd、Psen1、Hoxd13、Ar、Gfap、Lmna、Mecp2、Tnni3、Abcd1、Atoh1、Otof和Slc26a5 | [48,51,52, 56,57,59] |
| 小鼠(Mus musculus) | SaBE3 | Tyr | [49] |
| 小鼠(Mus musculus) | SaKKH-BE3 | Pah | [60] |
| 小鼠(Mus musculus) | HF2-BE2 | Tyr | [58] |
| 小鼠(Mus musculus) | Target-AID | Psen1 | [59] |
| 小鼠(Mus musculus) | VQR-BE3 | Psen1 | [59] |
| 小鼠(Mus musculus) | hA3A-BE3-Y130F | Tyr、Hoxd13、Ar、Gfap、Dmd、Lmna、Mecp2、Tnni3和Abcd1 | [61] |
| 兔子(Oryctolagus cuniculus) | BE3 | Mstn、Dmd、Tia1、Tyr和Lmna | [62] |
| 兔子(Oryctolagus cuniculus) | BE4-Gam | Dmd和Tia1 | [62] |
| 兔子(Oryctolagus cuniculus) | hA3A-eBE | Tyr | [64] |
| 兔子(Oryctolagus cuniculus) | hA3A-eBE-Y130F | Tyr、Lmna和Mstn | [64] |
| 兔子(Oryctolagus cuniculus) | hA3A-eBE-N57G (eA3A-BE3) | Tyr、Lmna和Mstn | [64] |
| 兔子(Oryctolagus cuniculus) | eAID-BE4max | Tyr | [65] |
| 兔子(Oryctolagus cuniculus) | exBE4 | Tyr | [63] |
| 兔子(Oryctolagus cuniculus) | A3G-BE4max | Dmd和Tyr | [42] |
| 猪(Sus scrofa domastica L.) | BE3 | Twist2、Tyr、TYR、LMNA、RAG1、RAG2、IL2RG和pol | [66,67] |
| 羊(Capra hircus L.) | BE3 | SOC2 | [68,69] |
| 斑马鱼(Barchydanio rerio var) | BE3 | Twist2、Gdf6、Ntl和Tyr | [70] |
| 斑马鱼(Barchydanio rerio var) | VQR-BE3 | Twist2、Tial1和Urod | [70] |
| 斑马鱼(Barchydanio rerio var) | Targeted-AID | chd和oep | [71] |
| 非洲爪蟾(Xenopus laevis) | BE3 | Tyr、tp53、tbx5、Apc、cyp1b1、tbx22、kcnj、hhex、sftpb和ptf1a/p48 | [72,73] |
| 家蚕(Bombyx mori L.) | BE3 | BmGAPDH和BmV-ATPase B | [43] |
| 海胆(Strongylocentrotus purpuratus) | CRISPR/Cas9-DA (Targeted-AID) | SpAlx1、SpDsh和SpPKS | [45] |
| 水稻(Oryza.sativa L.) | BE3 (PBE/CBE-P1) | OsCDC48、OsNRT1.1B、OsSPL14、OsSLR1、OsPDS、OsSBEIIb和OsSNB | [75~77,82] |
| 水稻(Oryza sativa L.) | Targeted-AID | OsALS、OsWaxy和OsFTIP1e | [87~89] |
| 水稻(Oryza sativa L.) | BE3-ΔUGI | OsNRT1.1B和OsSLR1 | [76] |
| 水稻(Oryza sativa L.) | CBE-P3 (VQR-BE3) | PMS3 | [30] |
| 水稻(Oryza sativa L.) | A3A-PBE | OsAAT、OsCDC48、OsDEP1、OsNRT1.1B、OsOD、OsEV和OsHPPD | [28] |
| 水稻(Oryza sativa L.) | rBE9 (hAID*Δ-XTEN-Cas9n-NLS) | OsAOS1、OsJAR1、OsJAR2和OsCOI2 | [40] |
| 水稻(Oryza sativa L.) | xBE3/xCas9(D10A)-PmCDA1 | OsGS3、OsDEP1、LF、IAA13、SPL7、SPL4和MADS57 | [74,78] |
| 水稻(Oryza sativa L.) | CBE-NG/rBE22/nSpCas9-NGv1-AID/Cas9-NG(D10A)-PmCDA1-UGI | OsDEP1、OsEPSPS、OsPDS、OsCERK1、GSK4、ETR2、MPK11、MPK7、MPK10、MPK8、SERK1、SERK2、RLCK185、BZR1、Os03g020040、LF、IAA13、SPL7、SNB和PMS3 | [74,77, 78,92] |
| 小麦(Triticum aestivum L.) | PBE | TaLOX2 | [82] |
| 小麦(Triticum aestivum L.) | A3A-PBE | TaALS、TaMTL、TaLOX2、TaDEP1、TaHPPD、TaVRN1-A1和TaACC | [28] |
| 玉米(Zea mays L.) | PBE | ZmCENH3 | [82] |
| 马铃薯(Solanum tuberosum L.) | A3A-PBE | StALS和StGBSS | [28] |
| 马铃薯(Solanum tuberosum L.) | BE3 | GBSS | [82] |
| 马铃薯(Solanum tuberosum L.) | Target-AID | StALS | [90] |
| 番茄(Lycopersicon esculentum Mill.) | Target-AID | DELLA、ETR1和SlALS | [87,90] |
| 拟南芥(Arabidopsis thaliana) | BE3 | AtALS、AtHAB1、AtT30G6.16、AtRS31A和AtAct2 | [84,104] |
| 西瓜(Citrullus lanatus L.) | BE3 | ALS | [85] |
| 棉花(Gossypium hirsutum L.) | BE3 | GhCLA和GhPEBP | [86] |
| 细菌(大肠杆菌, Escherichia coli ) | Target-AID | GalK、rpoB、xylB、manA、pta、adhE和tpiA | [93] |
| 细菌(大肠杆菌, Escherichia coli) | BE3 | tetA和rppH | [94] |
| 细菌(羊布鲁式杆菌, Brucella melitensis) | BE3 | virB10 | [94] |
| 细菌(金黄色葡萄球菌, Staphylococcus aureus) | BEC (BE3-ΔUGI) | agrA、cntA和esaD | [95] |
| 细菌(假单胞杆菌, Pseudomonas aeruginosa) | BEC (BE3-ΔUGI) | rhlR、rhlB、cadR、ompR、per、aspC、gacA和hrpL | [96] |
| 细菌(肺炎杆菌, Klebsiella pneumoniae) | BE3 | fosA、bhaK和bla | [97] |
| 真菌(黑曲霉丝状真菌, Aspergillus niger) | BEC (BE3) | pyrG、fwnA和prtT | [47] |
| 小鼠(Mus musculus) | ABE7.10 | Tyr、Dmd、AR、Hoxd13、Hbb-bs和Fah | [49,111,113] |
| 小鼠(Mus musculus) | VQR-ABE | Hbb-bs | [114] |
| 小鼠(Mus musculus) | SaKKH-ABE | Otc | [114] |
| 大鼠(Pattus norveqicus) | ABE7.10 | Gaa、Hemgn和Ndst4 | [114, 115] |
| 兔子(Oryctolagus cuniculus) | ABE7.10 | Dmd、Otc和Sod1 | [62] |
| 兔子(Oryctolagus cuniculus) | exABE | Tyr、Dmd和APP | [63] |
| 斑马鱼(Barchydanio rerio var) | zABE7.10 | ddx17-g1、musk、rps14、atp5b和wu:fc01d11 | [116] |
| 斑马鱼(Barchydanio rerio var) | zABE7.10max | Musk、rps14、atp5b和wu:fc01d11 | [116] |
| 斑马鱼(Barchydanio rerio var) | zABE7.10-GE | Musk、rps14、atp5b和wu:fc01d11 | [116] |
| 水稻(Oryza sativa L.) | ABE7.10 | OsSPL14、SLR1、OsSPL16、OsSPL18、LOC_Os02g24720、OsMPK6、OsMPK13、OsSERK2和OsWRKY45 | [117,118] |
| 水稻(Oryza sativa L.) | PABE-7 | OsACC、OsALS、OsCDC48、OsAAT、OsEV、OsOD、OsDEP1和OsNRT1.1B | [108] |
| 水稻(Oryza sativa L.) | ABE-P2 (ABEsa) | OsSPL14和OsSPL17 | [117] |
| 水稻(Oryza sativa L.) | ABE-P3 (VQR-ABE) | OsSPL14、OsSPL16、OsSPL17和OsSPL18 | [30] |
| 水稻(Oryza sativa L.) | ABE-P4 (VRER-ABE) | OsTOE1和OsIDS1 | [30] |
| 水稻(Oryza sativa L.) | ABE-P5 (SaKKH-ABE) | SNB | [30] |
| 水稻(Oryza sativa L.) | ABE-NG | OsSPL14、LF1、OsIAA13和OsSPL7 | [74] |
| 水稻(Oryza sativa L.) | ABE-NG-S | OsSPL14、LF1、OsIAA13和OsSPL7 | [74] |
| 小麦(Triticum aestivum L.) | PABE-7 | TaDEP1、TaEPSPS和TaGW2 | [108] |
| 拟南芥(Arabidopsis thaliana) | ABE7.10 | AtALS、AtPDS、AtFT和AtLFY | [119] |
| 油菜(Brassica campestris L.) | ABE7.10 | BnALS和BnPDS | [119] |
新窗口打开|下载CSV
2.3.2 在植物中的应用
植物中许多重要农艺性状是由单个或少数几个碱基突变引起,基于传统化学诱变的TILLING (targeting induced local lesions in genomes)可获得植物中的点突,但该方法耗时、耗力、随机性强、突变效率低,而CBE系统的开发为在植物中快速、高效且精准的创制突变体提供了有力的工具(图2B,表3)。其中,基于融合rAPOBEC1的BE3系统在植物中的应用最多。自2016年以来,来自国内外的多个研究团队利用BE3及基于融合SpCas9-VQR、SaKKH、SpCas9-NG和xCas9变体的BE3碱基编辑器在水稻中创制了多个基因的突变体[30,74~81]。本实验室利用基于融合rAPOBEC1的PBE系统在水稻、小麦和玉米原生质体中实现了多个基因的编辑,并获得了突变效率高达45.8%的相应突变体植株[82];并利用PBE系统编辑小麦TaALS和TaACCase基因,创制了一系列抗除草剂小麦新种质,为麦田杂草防控提供了育种新材料及技术路径[83]。另外,基于此本实验室还在小麦中建立了无外源选择标记、直接筛选碱基编辑事件的方法[83]。Chen等[84]通过对ALS基因的碱基替换,创制了抗除草剂拟南芥材料。Tian等[85]利用BE3获得了世界首例碱基编辑抗除草剂西瓜。另外,BE3介导的碱基编辑也已成功用于四倍体棉花基因组中[86]。
基于融合其他类型胞嘧啶脱氨酶的CBE系统在植物中的应用也有相关报道。基于融合PmCDA1脱氨酶的Target-AID系统已成功用于水稻、番茄和马铃薯相关基因的编辑,并创制了抗咪唑类除草剂水稻材料[87,88,89,90]。并且,该系统后续被用于建立植物抵御RNA病毒的免疫系统[91]。另外,SpCas9-NGv1与PmCDA1的融合进一步拓宽了胞嘧啶碱基编辑系统在水稻基因组中的靶向范围[78,92]。而本实验室利用基于融合人类APOBEC3A的A3A-PBE系统在水稻、小麦和马铃薯原生质体实现了非常高效的碱基编辑并且创制了抗除草剂小麦材料[28]。基于融合hAID的碱基编辑系统在水稻中表现出能高效编辑GC序列背景的特点[40]。
2.3.3 在细菌中的应用
CRISPR/Cas系统来源于原核生物的免疫系统,可被用于细菌的编辑,同样BE系统已被测试也可用于细菌的碱基编辑(表3)。Banno等[93]利用Targeted- AID编辑了大肠杆菌(Escherichia coli)等多个基因,更重要的是该系统在只转入4个sgRNA的情况下可在多拷贝的转座子元件中诱导41个突变的发生。Zheng等[94]利用BE3对大肠杆菌rppH基因引入了提前终止密码子。除在大肠杆菌中,科研人员利用BE3或者BE3-ΔUGI在羊布鲁式杆菌(Brucella melitensis)、金黄色葡萄球菌(Staphylococcus aureus)、假单胞杆菌(Pseudomonas aeruginosa)和肺炎球菌(Klebsiella pneumoniae)等中也成功实现了相关基因的碱基编辑[94,95,96,97],这表明碱基编辑系统可被广泛的应用于多种原核生物的编辑。
2.3.4 引入提前终止密码子
CBE系统通过C-T或G-A突变可以将非编码链的CAA、CAG、CGA以及编码链的TGG共4种密码子中的任意一种突变为终止密码子,从而在不产生DNA双链断裂的情况下达到敲除基因的效果(图2C)。Jin-Soo Kim实验室率先利用BE3在Dmd基因中引入提前终止密码子,建立了肌营养不良的小鼠疾病模型[57]。随后报道的CRISPR-Stop和iSTOP方法利用同样的思路建立了大规模BE3介导的基因失活体系。其中,CRISPR-Stop相关研究发现,通过BE3产生的基因失活效率与Cas9介导的敲除效率相当,并且BE3对细胞的死亡损伤明显降低[98]。Billon等[99]建立的iSTOP可覆盖人类基因组读码框的98.6%以上,并且该实验室提供了可免费设计人类、小鼠和拟南芥等8个物种iSTOP sgRNA的在线数据库。而当同时使用多个sgRNA时,可显著增加BE3介导的iSTOP效率[100]。
2.3.5 调控内源mRNA的可变剪接
mRNA可变剪接是转录后基因调控的重要过程,典型真核内含子连接有5?-GT(供体序列)和AG-3? (受体序列),它们在剪接中起着重要作用[101],而碱基编辑系统的出现对特定mRNA剪接过程的功能研究提供了重要的技术工具(图2D)。Gapinske等[102]率先利用BE3介导的CRISPR-SKIP剪接体系,对小鼠和人类不同细胞系的mRNA的可变剪接位点进行了编辑,导致外显子跳读。常兴实验室利用TAM系统在人类细胞中实现了目前存在的4种mRNA剪接形式的改变(外显子跳读、改变可变剪接位点的选择、调节互斥外显子的选择和诱导小的内含子的包含),并且通过编辑Dmd基因的剪接位点,实现了目标外显子的完全跳读,在所有表达TAM的细胞中修复了心肌细胞的缺陷[103]。植物中,本实验室利用BE3在拟南芥中对位于内含子5'端的剪接保守位点“GU”以及AtAct2基因5' UTR区的内含子剪接位点处进行突变,结果发现利用该方法可高效的删除或改变mRNA特定剪接形式或组成型剪接形式[104]。中山大学李剑峰实验室同样利用BE3在拟南芥和水稻中建立了有效的mRNA可变剪接体系[105]。
2.3.6 蛋白定向进化
碱基编辑系统除可以进行单个氨基酸位点的基因编辑以外,理论上还可以通过氨基酸位点的遗传筛选进行蛋白结构和功能的研究(图2E)。常兴实验室利用TAM系统在慢性粒细胞白血病细胞中靶标
BCR-ABL基因,有效鉴定了赋予细胞伊马替尼抗性的已知突变和新突变,这表明CBE系统可以在单碱基水平上筛选功能获得性变异[20]。Michael C. Bassiks实验室利用基于MS2招募hAID脱氨酶的CRISPR-X系统在哺乳动物细胞中突变了癌症治疗药物万珂(bortezomib)的靶标基因PSMB5,从中找到了引发bortezomib耐药性的已知和全新的突变[21]。中国科学院上海生命科学研究院生物化学与细胞生物学研究所李劲松实验室利用优化的BE3向小鼠“人造精子”中导入了一个靶向Dnd1基因的一个sgRNA慢病毒文库(含77个sgRNA),通过两轮的遗传筛选,他们发现并验证DND1蛋白的E59K、V60M、P76L和G82R对PGCs的发育具有重要作用[106]。该项研究是首次利用碱基编辑技术实现了个体水平蛋白质关键氨基酸功能位点的遗传筛选,理论上可同样筛选人类疾病相关基因的功能位点。目前,在植物中碱基编辑系统用于基因大规模突变并没有相关报道,分析原因主要有3个方面:(1)由于组织培养产生的大量再生植物没有快速且高效的阳性筛选体系,为鉴定突变体带来了很大的困扰;(2)缺乏高效的植物原生质体再生方法,限制了突变类型的饱和度;(3)将碱基编辑系统与多个sgRNA同时递送到植物细胞中是目前植物遗传转化的一大困难。因此,在植物中利用碱基编辑系统实现蛋白功能定向进化是目前重要研究方向之一。
3 ABE碱基编辑系统
3.1 ABE系统的开发
2017年,David R. Liu实验室开创性地开发了腺嘌呤碱基编辑系统(ABE),该系统由人工定向进化的腺嘌呤脱氨酶及nCas9组成,可实现A至G (A-G)或T至C (T-C)的替换[107]。其作用原理与CBE系统类似,即腺嘌呤脱氨酶可将靶位点处一定范围的腺嘌呤(A)脱氨变为肌苷(I),肌苷在DNA水平会被当作鸟嘌呤(G)进行读码与复制,最终实现A-G的改变。ABE的开发打破了之前碱基编辑系统仅能编辑C或G的限制,为碱基之间的相互转变提供了更多的可能性(图1)。由于目前已知的腺嘌呤脱氨酶不能以DNA为底物对碱基A进行脱氨,这导致ABE系统的开发比CBE系统更具有挑战性。David R. Liu实验室最初也尝试将来自大肠杆菌TadA、大鼠ADA、人类ADAR2和人类ADAT2 4种腺嘌呤脱氨酶分别直接与nCas9融合,但均没有编辑活性,这表明必须将现有腺嘌呤脱氨酶进行定向改造,才有可能实现对碱基A的编辑[107]。对此,该实验室选取大肠杆菌TadA为改造对象,将随机突变的TadA序列融合dCas9构建成随机突变文库,通过ABE恢复氯霉素、卡那霉素、壮观霉素等抗性基因的功能,结合易错PCR、DNA重排等定向进化策略,进行相应的抗生素筛选, 先后经过7轮进化与改造后,成功筛选到了能直 接作用于ssDNA的ABE系统。在人类细胞中建立了目前效率最高且应用最广的ABE版本ABE7.10 (ecTadA-ecTadA*-nCas9)。ABE7.10将nCas9与野生型腺嘌呤脱氨酶ecTadA和经过定向进化的腺嘌呤脱氨酶ecTadA* (与野生型相比引入了W23R、 H36L、P48A、R51L、L84F、A106V、D108N、H123Y、S146C、D147Y、R152P、E155V、I156F和K157N共14个位点的突变)二聚体相融合,在人类细胞中编辑效率约为50%,编辑活性窗口可覆盖sgRNA的第4~9位[107]。相比CBE,ABE不需要抑制烷基腺嘌呤DNA糖基化酶(alkyl adenine DNA glycosylase, AAG)的活性,这暗示着肌苷的损伤修复机制可能与AAG无关。
3.2 ABE系统的优化
研究发现ABE无论在哺乳动物还是在植物等中的编辑,相比CBE系统可保证高精确度的碱基替换和较低的Indels发生,因此科研人员对ABE系统的优化主要表现在对碱基编辑效率的提高、扩大编辑活性窗口和碱基编辑范围方面[12,13,15]。对于碱基编辑效率的提高,本实验室率先通过优化密码子、调整腺嘌呤脱氨酶二聚体的位置和NLS的位置、增加NLS个数以及使用3种不同sgRNA形式等手段优化的PABE-7碱基编辑器相比原始的ABE7.10的编辑效率在小麦和水稻中提高了1.1倍[108]。David R. Liu实验室通过不同公司优化的密码子序列和增加NLS的个数而建立的ABEmax也提高了对碱基A的替换效率[26]。另外,CP1012- ABEmax、CP1028-ABEmax、CP1041-ABEmax和CP1249-ABEmax碱基编辑器在保证效率与ABEmax相当的情况下,可在一定程度上将4~8位的碱基编辑窗口拓展为4~12位[25]。在扩大PAM选择范围方面,VQR-SpCas9 (PAM: NGA)、VRER-SpCas9 (PAM: NGCG)、VRQR-SpCas9 (PAM: NGA)、SaCas9 (PAM: NNGRRT)、SaKKH (PAM: NNNRRT)、ScCas9 (PAM:NNGN)、xCas9 (PAM:NG)和SpCas9-NG (PAM: NG)的融合扩大了ABE在动植物基因组可编辑位点的范围[25,30,74,109]。
3.3 ABE系统的应用
ABE系统的开发为创制更多的动植物突变体、治疗更多的点突引起的疾病以及创制优异的农作物性状等提供了更加全面有力的工具(表3)。在动物中,目前ABE系统已成功用于各种动物细胞系、人类胚胎、小鼠、大鼠、兔子和斑马鱼等中[12,13,15,110]。ABE可修改提前终止密码子突变,当靶向非编码链时可将编码链的TGG修改为CAA、CAG和CGA (图2C)。Jin-Soo Kim实验室率先利用ABE7.10对小鼠Tyr基因引入了错义突变,并将ABE7.10包裹到双反式剪接的AAV病毒系统中,对Dmd基因进行了无义突变,建立了杜氏肌营养不良的小鼠疾病模型[111]。上海科技大学黄行许实验室通过编辑AR和Hoxd13基因,建立了ABE介导的相关小鼠疾病模型,同时该研究使用不同的Cas9同源蛋白实现了ABE和CBE的同时编辑[49]。另外,该实验室利用ABEmax-NG在动物细胞内实现了精准的mRNA剪接位点的编辑[112]。Liang等[113]在小鼠中编辑了Tyr基因和Dmd基因的可变剪接位点,并在含有Dmd突变的小鼠中观察到了相应的杜氏肌营养不良的表型。Yang等[114]利用ABE7.10建立了由Fah突变引起的Ⅰ型酪氨酸血症小鼠模型,并且该研究也证实SaKKH-ABE和VQR-ABE两种编辑器同样可在小鼠中产生有效的A-G的突变。在大鼠中,Yang等[114]和Ma等[115]实现了大鼠基因的编辑,并且Yang等[114]在被ABE7.10编辑的Gaa D645G/ I646V F1后代的大鼠多个组织中发现了充满糖原的大溶酶体异常积累,建立了庞贝氏症大鼠疾病模型。在兔子中,Liu等[62]利用ABE7.10高效地编辑了兔子中的Dmd、Otc和Sod1基因,并且Dmd T279A突变体表现出与人类家族性X-连锁扩张型心肌病相似的典型临床症状。除了哺乳动物,Qin等[116]利用斑马鱼密码子优化的zABE7.10成功在斑马鱼musk、rps14、atp5b和wu:fc01d11中引入了突变,并且rps14突变体有着相应的表型,该实验室进一步将zABE7.10max成功用于斑马鱼基因的编辑。
在植物中,ABE系统已成功被用于水稻、小麦、拟南芥和油菜(Brassica campestris L.)等相关基因突变提的创制及相应性状的创制(表3)。中国科学院上海植物逆境生物学研究中心朱健康实验室利用ABE-P1 (ABE7.10)和ABE-P2 (ABEsa)编辑了水稻的6个基因,并在后续研究中实现了ABE-P3 (VQR-ABE)、ABE-P4 (VRER-ABE)和ABE-P5 (SaKKH-ABE)、ABE-NG和ABE-NG-S (只融合人工进化的TadA变体TadA*)的进一步拓展,且在水稻中可同时实现C-T和A-G的同时编辑[30,74,117]。Yan等[118]同样证明ABE在水稻中可高效工作。而本实验室利用经过多种元件优化后的PABE-7版本编辑了水稻和小麦的多个基因,并且获得了相应的小麦突变体和抗除草剂的水稻ACC基因突变材料[108]。Jin-Soo Kim实验室利用RPS5A启动子驱动ABE,在双子叶拟南芥和油菜中实现了高效的编辑,并创制了拟南芥早花的ft突变体材料以及实现了油菜PDS基因mRNA的可变剪接[119]。
4 碱基编辑系统的脱靶效应及改善策略
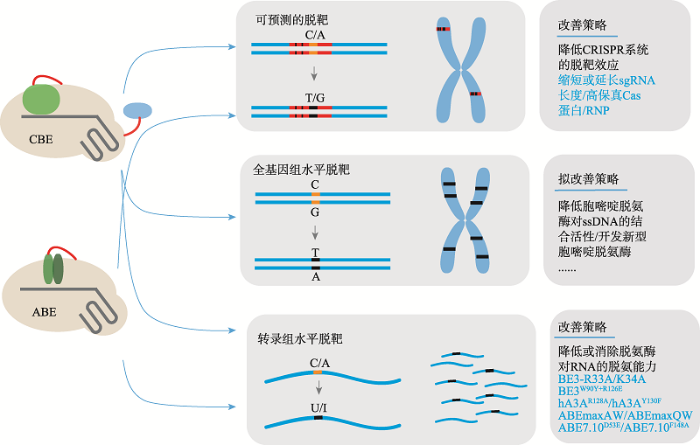
碱基编辑系统最重要的用途在于实现基因的碱基替换,从而达到治疗疾病及作物改良的目的。因此,其编辑的特异性备受关注,也尤为重要。碱基编辑系统的脱靶分为3个方面(图3):图3
 新窗口打开|下载原图ZIP|生成PPT
新窗口打开|下载原图ZIP|生成PPT图3碱基编辑系统的脱靶效应及改善策略
碱基编辑系统的脱靶效应分3个层次:传统的可预测的脱靶、全基因组水平的脱靶及转录组水平的脱靶。目前针对可预测的脱靶及转录组水平的脱靶已有较好的改善策略,而对于CBE系统在全基因组范围的脱靶只有初步的猜想。
Fig. 3The off-target effects and improvement strategies of base editing systems
第一、传统的可预测的脱靶。该类脱靶是指碱基编辑系统除了编辑靶位点以外,还可以编辑与靶位点相似性很高的其他位点,而这些位点往往与靶位点只有几个碱基的错配。这类的脱靶位点一般可用目前的软件预测(如Cas-OFFinder、E-CRISP和CRISPR-P等),后续结合分子生物学手段来判断是否存在脱靶效应。导致该类脱靶发生的原因主要有两方面:一是sgRNA序列的容错性,脱靶效应的高低与sgRNA和靶标DNA之间错配碱基的数目有关[120,121];二是Cas9核酸酶自身的非特异性、脱氨酶与Cas9融合蛋白的高浓度及长时间持续表达都容易造成对非靶标位点的编辑。目前降低此类脱靶效应的策略主要有以下几种[122]:(1) sgRNA的修饰。利用缩短的sgRNA (gX18或gX17)或延长的sgRNA (gX20或ggX20)均可在保持BE3或ABE系统效率的前提下降低它们的脱靶效应[120,121];(2)使用高保真的Cas9核酸酶。利用工程化的Cas9变体可降低碱基编辑的脱靶情况。David R. Liu实验室通过将HF1-Cas9与BE3融合,建立的HF-BE3可明显降低原始BE3对非靶标位点的编辑[123]。Jin-Soo Kim实验室通过将Sniper Cas9与ABE融合建立的Sniper ABE7.10对ABE系统的脱靶效应有明显的改善[120];(3)缩短脱氨酶与Cas9核酸酶融合蛋白在细胞中的作用时间。利用碱基编辑器与sgRNA形成的核糖核蛋白复合体(ribonucleoprotein, RNP)取代其DNA表达形式直接转化细胞,可以使碱基编辑器在细胞内快速降解,从而降低脱靶效应。研究表明,递送BE3 RNP和ABE RNP均可提高相应碱基编辑系统的特异性[120,123]。
第二、全基因组范围内不可预测的脱靶。该类脱靶位点往往随机或有一定规律的分布在全基因组水平上,但通过目前的软件无法预测。体外优化的Digenome-seq、EndoⅧ或Endo V-seq的脱靶评估手段并不能真实有效的反应体内环境下碱基编辑系统的特异性[120,121,124]。由于脱氨酶需要结合在ssDNA处发挥作用,因此细胞内自身存在的ssDNA、转录区域、复制区域等成为了碱基编辑系统在全基因组水平的潜在脱靶对象。Lee等[125]发现在小鼠胚胎中BE3在sgRNA前后200个碱基处的脱靶效应高于ABE系统。而在小鼠中,杨辉实验室利用建立的GOTI技术结合全基因组测序分析,发现BE3在小鼠体内能够引发比自发突变高20倍的C-T的单核苷酸变异(single nucleotide variations, SNVs)[126];同一时间,本实验室在植物中发现了类似的现象,即BE3和HF1-BE3能够引起水稻全基因组水平的C-T SNVs的增加[127],且这两项研究均表明这些C-T SNVs在染色体间均匀分布,但呈现出在转录活跃区富集的趋势[126,127]。而对于融合其他类型胞嘧啶脱氨酶的CBE系统是否也存在该现象还需要进一步的评估。更早的研究发现,过表达不同胞嘧啶脱氨酶或UGI在酵母、大肠杆菌及人类细胞系中会导致基因组内C-T SNVs的增加[128,129,130]。这些问题的发现一方面暗示着现阶段将碱基编辑系统于疾病治疗等精准改造方面有一定的风险,另一方面促使科研人员更深层次的探索究竟是胞嘧啶脱氨酶、UGI还是两个组分共同作用的结果造成了全基因组水平的脱靶,从而改进开发出更加精准安全的CBE系统。而相比之下,ABE系统在全基因水平具有很高的特异性[126,127],这可能与ABE系统融合的腺嘌呤脱氨酶是经过人工定向进化以及ABE系统中并没有UGI组分有关。
第三、转录组水平的脱靶。无论是胞嘧啶脱氨酶还是腺嘌呤脱氨酶在之前的研究报道中都是能够作用于RNA或自身完全作用于RNA的脱氨酶,因此这就有可能导致碱基编辑系统在RNA水平产生脱靶。2019年,Keith Joung实验室通过转录组测序,率先证明了BE3和ABE系统在人类细胞系转录组水平存在严重的脱靶效应[131]。其中,BE3可在38%~58%的表达基因中以0.07%~100%的频率诱导成千上万的C-U的编辑;而ABEmax在RNA水平对碱基A的脱靶编辑也可高达100%[131]。随后,David R. Liu实验室也证明ABE在哺乳动物细胞系中存在很低但能够检测到的RNA脱靶[132]。杨辉实验室定量评价了CBEs和ABEs诱导的RNA单核苷酸变异,结果发现胞嘧啶碱基编辑器BE3和腺嘌呤碱基编辑器ABE7.10都能产生成千上万的非靶向RNA SNVs[133]。对于碱基编辑系统在RNA水平的严重脱靶现象,目前主要的解决方案是利用工程化的脱氨酶变体,即一般通过改造脱氨酶与RNA的活性结合位点从而来降低对RNA的编辑效率。依据此思路,Keith Joung实验室开发的BE3-R33A和BE3-R33A/K34A的变体可将BE3对RNA的编辑分别降低390倍和3800倍。杨辉实验室开发的BE3W90Y+R126E、hA3AR128A和hA3AY130F可直接将BE脱靶降低到本底水平[133]。对于ABE系统的改造,David R. Liu实验室开发的ABEmaxAW (TadA E59A, TadA* V106W)和ABEmaxQW (TadA E59Q, TadA* V106W)可在保证一定DNA水平的编辑效率的同时,降低其在RNA水平的编辑效率[132]。而杨辉实验室也开发了两种ABE变体,ABE7.10D53E和ABE7.10F148A,其中ABE7.10F148A可直接消除ABE系统在转录组水平的脱靶效应[133]。
总之, ABE系统因其在DNA水平具有较高的特异性,而在RNA水平的脱靶也有了很好的解决方案,因此就目前研究结果来看ABE系统具有较高的安全性。而CBE系统在DNA水平的脱靶效应需要进一步的改善,开发出更安全的CBE工具。
5 碱基编辑系统的发展前景
碱基编辑技术的开发为定向修正碱基突变和创制基因组中的关键核苷酸变异提供了重要工具,展现了其在遗传疾病治疗与动植物新品种培育等方面的重大应用价值。然而碱基编辑系统仍然存在一些不足之处。最为明显的是,CBE及ABE系统只能实现嘧啶对嘧啶、嘌呤对嘌呤的改变,即C-T、T-C、G-A和A-G的改变,而不能实现碱基之间的颠换,如C-G、C-A、A-T和A-C的转变。虽然目前有研究报道CBE系统可产生C至G或A的突变,但其发生有很大的随机性并且效率很低。另外,碱基编辑系统相比HR在全基因组及RNA水平的脱靶效应更高,安全性更低。受自身的编辑活性窗口及PAM的限制,使碱基编辑系统在实际应用中并不能对所有的靶点都能有效编辑。因此,碱基编辑系统在技术及应用层面等仍具有更深层次的开发潜力,如新型碱基编辑系统的开发、全基因组水平的特异性的提高、碱基编辑材料递送形式的优化等。(1)开发新型碱基编辑系统。主要表现在碱基之间可进行颠换的碱基编辑系统的挖掘。以C变G为例,目前已有关于其设计思路及相关专利的报道[134]。当C被胞嘧啶脱氨酶脱氨之后会在UDG的作用下形成AP位点,进而招募TLS聚合酶如Rev1等结合在此处进行修复,该酶会在AP位点的对侧链偏向性的插入碱基C,留下一个可连接的缺口,最终在DNA连接酶及DNA修复过程中实现C-G的改变。David R. Liu实验室公开相关专利,采用上述思路先后尝试了多种构建策略:rAPOBEC1-d/nCas9-UDG、rAPOBEC1-d/nCas9-UDG变体(UdgX、UdgX*和UdgX_On等)以及rAPOBEC1-d/nCas9-UDG/(UDG变体)+TLS聚合酶(Rev1、Kappa、Lota和Eta)等,经测试后发现只有胞嘧啶脱氨酶同时融合UDG (或UDG变体)和TLS聚合酶时编辑效果最佳,但编辑效率并不理想。可能原因在于UDG只有在细胞处于S期才会将U切除形成AP位点,并且TLS聚合酶必须在ssDNA缺口处才能复制。美国宾夕法尼亚大学科学家Kiran S. Gajula针对此问题提出了可能的改善策略,即一方面可人工定向进化Rev1,理想的Rev1应具有5?至3?外切酶的活性,同时具有自主打开缺口并牢牢结合在AP位点处的功能,这样可大大增加其接触ssDNA的几率;另一方面可融合EvolvR系统中的enCas9变体,从而有可能提高C-G的效率[134]。因而,对于C-G及其他碱基之间相互转变的新型单碱基技术体系的开发需要不断的探索及优化。此外,如何简单高效的实现C-T及A-G的同时编辑也值得探索。虽然目前在动植物中已有相关报道,但均是采用直接融合不同Cas9变体的策略,通过不同Cas9识别不同PAM的特点而实现。但该方案使用的表达载体过大,编辑效率低且能靶向的位点局限性大。因此可尝试使用不同的适配体如MS2、PP7和boxB等招募不同的脱氨酶等方法,快速而高效的实现不同碱基的同时突变。
(2)提高碱基编辑系统的特异性。主要表现为需要开发在全基因组范围具有更高特异性和更高安全性的CBE系统。具体的解决方案可尝试YEE-BE3等其他新近开发的CBE碱基编辑器,由于YEE-BE3与DNA的结合活性较弱,对降低全基因组水平的脱靶效应也许会有一定的帮助[29];或者可人工进化脱氨酶找寻新的变体,在保证其正常编辑效率的同时能从本质上解决CBE在全基因组范围的脱靶。另外,可尝试优化胞嘧啶脱氨酶或UGI组分,如Keith Joung实验室在相关国际专利提出初步设想,即将胞嘧啶脱氨酶分割到两个载体中表达,一部分与ZF或TALE效应因子融合,另一部分与nCas9融合,只有当两部分同时靶向靶位点时,才能通过内含肽二聚化形成具有活性的胞嘧啶脱氨酶,从而有可能降低其在全基因组水平的脱靶风险。除了可改进脱氨酶组分之外,也可将nCas9组分替换为在全基因组水平更加特异的其他Cas蛋白,如dSaCas9或者dCas12a。另外,RNP相比DNA在细胞内更容易快速降,因此猜测使用CBE RNP形式对降低CBE在全基因组脱靶会有一定的改善效果。
(3)碱基编辑材料的形式及递送方式方面。如何将碱基编辑材料有效且安全的递送到细胞内是目前碱基编辑系统需要继续改进及发展的重要方面。目前,碱基编辑系统介导的编辑材料包括质粒(DNA)、体外转录物(in vitro transcripts, IVTs)以及RNP 3种形式发挥作用。目前在动物相关研究中,这3种形式的碱基编辑均已成功报道,主要通过注射、电转、腺相关病毒(AAV)及阳离子脂质体介导的转化方法实现,其中以mRNA的形式居多[12]。但如何缩小BE载体大小使其更容易装载入腺病毒载体、甚至开发出用于基因治疗的新型递送系统及可直接进行组织特异性的递送仍需进一步的探索。相比在哺乳动物细胞中的研究,碱基编辑材料的递送在植物中发展相对缓慢。对于质粒DNA介导的碱基编辑是目前最常用的形式,在植物中可通过基因枪轰击、农杆菌浸染及PEG介导的转化方法实现。但是当DNA整合到基因组中会带来因碱基编辑DNA元件持续表达导致的潜在脱靶效应的增加,且编辑的产品会引起公众的担忧。尽管本研究组采用瞬时表达碱基编辑系统的DNA方式可在一定程度上降低外源DNA的整合[28,82,108],但不是根本的解决办法。以碱基编辑IVTs或RNP的形式作为基因组编辑材料可以更加有效避免外源DNA整合事件的发生,整个过程中不涉及任何外源DNA,因而更有助于避免转基因的监管。本实验室率先利用BE3 mRNA形式在小麦中实现了TaALS基因的编辑[83]。对于RNPs形式的编辑,同样是本实验室初步报道了PEG介导的转化方法在小麦原生质体中初步实现了A3A-PBE-ΔUGI RNP的编辑[28],而对于RNP在植物个体中的碱基编辑并没有成功案例。因此,在植物中如何高效且安全地将碱基编辑RNP形式递送到植物细胞中从而获得DNA-free的突变植株,成为目前植物碱基编辑系统亟待解决的技术瓶颈。由于在植物遗传转化过程中对RNP递送数量及质量均有损失,因此需要摸索RNP各种遗传转化条件,如测试不同的纳米金颗粒包被RNP等。另外,可尝试一些新型基因组编辑材料递送方式,如磁纳米颗粒转化法、碳纳米管转化法、病毒载体转化法等。
总之,碱基编辑技术在人类疾病研究、动植物科学基础研究和育种等方面应用前景广阔,该技术的进一步优化及改造将推动农业生产,生物医药及生命科学等领域的快速发展。
致谢
感谢本实验室王延鹏青年研究员在图片制作和文章写作方面给予的帮助,感谢李超和靳帅博士研究生在文章写作方面给予的建议。参考文献 原文顺序
文献年度倒序
文中引用次数倒序
被引期刊影响因子
Magsci [本文引用: 1]

CRISPR/Cas系统广泛存在于细菌及古生菌中, 是机体长期进化形成的RNA指导的降解入侵病毒或噬菌体DNA的适应性免疫系统。对Ⅱ型CRISPR/Cas系统的改造使其成为继锌指核酸酶(ZFNs)和TALE核酸酶(TALENs)以来的另一种对基因组进行高效定点修饰的新技术, 与ZFNs和TALENs相比, CRISPR/Cas系统更简单, 并且更容易操作。文章重点介绍了Ⅱ型CRISPR/Cas系统的基本结构、作用原理及这一技术在基因组定点修饰中的应用, 剖析了该技术可能存在的问题, 展望了CRISPR/Cas系统的应用前景, 为开展这一领域的研究工作提供参考。
Magsci [本文引用: 1]
CRISPR/Cas系统广泛存在于细菌及古生菌中, 是机体长期进化形成的RNA指导的降解入侵病毒或噬菌体DNA的适应性免疫系统。对Ⅱ型CRISPR/Cas系统的改造使其成为继锌指核酸酶(ZFNs)和TALE核酸酶(TALENs)以来的另一种对基因组进行高效定点修饰的新技术, 与ZFNs和TALENs相比, CRISPR/Cas系统更简单, 并且更容易操作。文章重点介绍了Ⅱ型CRISPR/Cas系统的基本结构、作用原理及这一技术在基因组定点修饰中的应用, 剖析了该技术可能存在的问题, 展望了CRISPR/Cas系统的应用前景, 为开展这一领域的研究工作提供参考。
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 3]
e6,
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
[本文引用: 1]
[本文引用: 1]
[本文引用: 3]
[本文引用: 12]
[本文引用: 6]
[本文引用: 1]
[本文引用: 1]
[本文引用: 6]
[本文引用: 3]
[本文引用: 1]
[本文引用: 1]
[本文引用: 8]
[本文引用: 1]
[本文引用: 3]
[本文引用: 3]
[本文引用: 1]
[本文引用: 3]
[本文引用: 1]
[本文引用: 4]
[本文引用: 3]
[本文引用: 2]
[本文引用: 6]
[本文引用: 3]
[本文引用: 4]
URL [本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
[本文引用: 1]
[本文引用: 2]
[本文引用: 1]
URL [本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 3]
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
[本文引用: 3]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 3]
[本文引用: 3]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 3]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 5]
[本文引用: 3]
[本文引用: 1]
[本文引用: 2]
[本文引用: 1]
[本文引用: 1]
[本文引用: 3]
[本文引用: 3]
[本文引用: 1]
[本文引用: 1]
[本文引用: 1]
[本文引用: 2]
[本文引用: 2]
[本文引用: 3]
[本文引用: 2]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}