HTML
--> --> -->Such synoptic observations about the organization of weather systems have motivated decades-long efforts to separate and operationally utilize the positional (e.g., location of central pressure or track) and amplitude (i.e., value of central pressure, or intensity of maximum winds, Goerss and Sampson, 2004; Goerss, 2007; Kehoe at al., 2007) errors associated with Tropical Cyclones (TC, see, e.g., Colby, 2016). Errors in the central position of TCs can be further decomposed into along and across track errors (Buckingham et al., 2010). More recently, similar statistics have also been evaluated for extratropical cyclones (e.g., Colle and Charles, 2011).
Motivated by the decomposition for TC errors, the past decades saw the emergence of a number of other feature-based approaches. These studies include the object-oriented approach of Ebert and McBride (2000), Nachamkin (2004), and Davis et al. (2006), as well as a study by Wernli et al. (2008) that focuses on small regions around selected features to determine structure, amplitude, and location related error statistics.
Other studies take a more systematic approach to forecast error decomposition. These use field deformation (also referred to as optical flow) to smoothly deform one field to align it with another, e.g. verification field. In its verification applications, field deformation is used to decompose full 2D forecast error fields (as opposed to only errors related to selected features). A study by Hoffman et al. (1995), further discussed in the next section, and the correlation and variational optic-flow-based technique of Keil and Craig (2007) is an example of this type of approach. The field deformation concept was first developed and used for other applications (e.g., data fusion—Mariano, 1990; hurricane relocation—Hoffman et al., 1995; bias correction—Nehrkorn et al., 2003; and data assimilation—Lawson and Hansen, 2005; Ravela et al., 2007; Beechler et al., 2010).
In this study, a new method called Forecast Error Decomposition (FED) is introduced, using the Field Alignment (FA) technique of Ravela (Ravela, 2007; Ravela et al., 2007). FA and its application in FED are introduced in section 2. The experimental data and setup are described in section 3, while FED application results are shown in Section 4. section 5 offers a brief summary and a discussion of the characteristics of the approach.
2
2.1. Field Alignment
As Hoffman et al. (1995) point out, there is no unique way of defining forecast displacement errors. In this study, we test the use of an alternative technique, the FA technique (Ravela et al., 2007) in FED. FA and its variants in the Field Alignment System and Testbed (FAST, Ravela, 2007; Ravela et al., 2007) align two gridded fields (in its FED application, a forecast with its verifying analysis field) by smoothly remapping the coordinate system underlying the state of a variable. For example, for two 2D fields of a state variable (e.g. surface temperature), where one field is the observed or analyzed field (which would be considered as the target state) and the other one is a forecast of that field valid at the same time, the FA method estimates a smooth 2D displacement vector field that aligns the forecast with the analysis field. If the displacement vectors are applied to each grid point of the original forecast field as a translation operation in 2D space, the result is an adjusted forecast field for which the difference in RMSE between this aligned field and the analysis field (i.e., cost function) is minimized. The displacement vector field and the aligned field are derived through a variational minimization of the cost function in FA (Ravela, 2007). The smoothness of the displacement vector field is controlled via a “smoothness wavenumber parameter” (SWP) in the FA truncation algorithm (Ravela, 2012). SWP defines the scales at which alignments of features between two fields are performed. Smaller scale features are moved along with the larger scale features that are aligned, without additional adjustments. SWP is the only free parameter in FA and it is analogous to the choice of truncation in Hoffman et al.’s (1995) approach.Unlike the method proposed by Hoffman et al. (1995), FA does not rely on forecast error covariance information. For additional details on how FA differs from the method of Hoffman et al. (1995), see Ravela et al., 2007; and Ravela, 2014. As for other FA applications, Ravela (Ravela, 2007; Ravela et al., 2007) and Williams (2008) align the first guess forecast field with the latest observations before the application of a standard data assimilation scheme. This pre-processing reduces the remaining, mostly amplitude errors for a further improvement in the fit to the observations. FA has also been used to analyze (with ensemble-based analysis approaches, Ravela et al., 2009; Ravela, 2012, 2014) and represent (e.g., Ravela et al., 2009) coherent structures in other fluid applications. Additionally, FA has been found to be an effective tool for nowcasting (Ravela, 2012, 2014), initialization, verification (Ravela et al., 2007; Ravela, 2014), and various other applications (Yang and Ravela, 2009a,b; Ravela, 2015a, b).
2
2.2. Forecast Error Decomposition
The purpose of this study is to demonstrate the use of the FA technique in FED for the quantification of what is subjectively perceived as major modes of error. In our study, we will use Error Variance (EV, or on some figures, its root, the Root Mean Square error—RMS) as traditional, scalar references measuring the difference between two 2D fields. The total forecast error variance (Et) is defined as a difference between forecast (F) and analysis (A) fields. A displacement operator (D) adjusts the forecast field to a new, aligned state (Fa) for which the difference in RMSE between the forecast field (F) and the analysis (A) is minimized. The displacement operator generates both the displacement vector field and the scalar field of the magnitude of displacement.As pointed out in section 2.1, only large scale features of F are aligned with similar features in A. Correspondingly, positional (Pls) and structural (Sls) errors in F will also be defined for the large scales. To calculate large scale positional and structural errors, we first smooth fields F, Fa, and A with the moving average method, using 5 points as the smoothing parameter. The level of smoothing (over 5 points) was chosen so the lines defined by Fs–






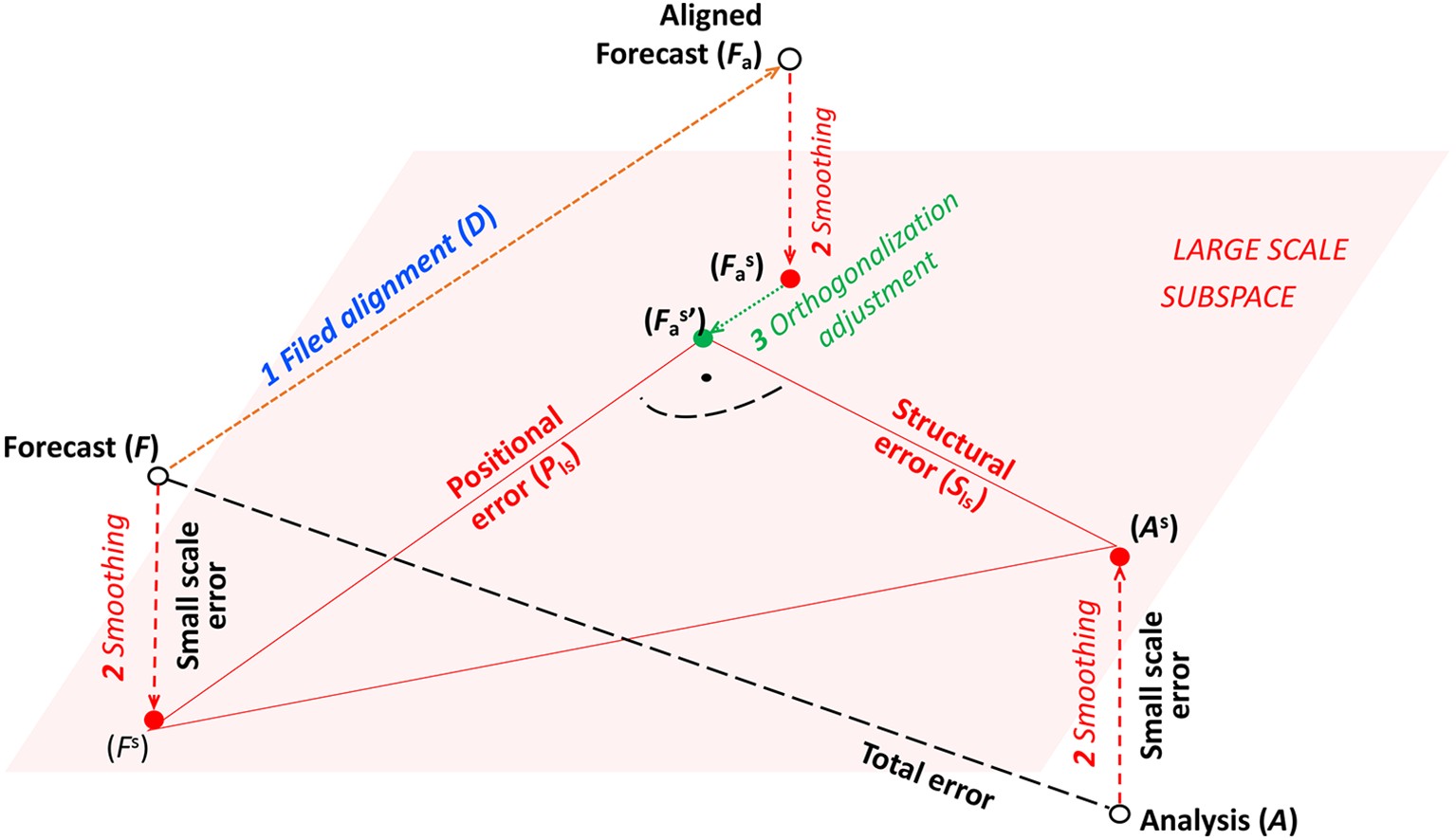 Figure1. Schematic of a forecast, verifying analysis, and aligned forecast (open black circles) situated in the phase space of full atmospheric variability, shown in 3D here. Smoothed versions of these fields (solid red circles) reside in the subspace of large scale atmospheric variability, represented with a plane. The orthogonally adjusted smoothed aligned forecast (green solid circle) is defined as a point on the Forecast – Aligned Forecast line in the large scale subspace closest to the Analysis. Large scale positional, large scale structural, and small scale error variances are defined as the variance distance between Forecast and Aligned Forecast, and Aligned Forecast and Analysis in the large scale subspace, and the sum of the variance distances between the original and smoothed Analyses, and the original and smoothed Forecasts, respectively. For further discussion, see text.
Figure1. Schematic of a forecast, verifying analysis, and aligned forecast (open black circles) situated in the phase space of full atmospheric variability, shown in 3D here. Smoothed versions of these fields (solid red circles) reside in the subspace of large scale atmospheric variability, represented with a plane. The orthogonally adjusted smoothed aligned forecast (green solid circle) is defined as a point on the Forecast – Aligned Forecast line in the large scale subspace closest to the Analysis. Large scale positional, large scale structural, and small scale error variances are defined as the variance distance between Forecast and Aligned Forecast, and Aligned Forecast and Analysis in the large scale subspace, and the sum of the variance distances between the original and smoothed Analyses, and the original and smoothed Forecasts, respectively. For further discussion, see text.Large scale positional and structural errors are then defined as Fs–


In this study, FED has been applied to Mean Sea Level Pressure (MSLP) and 850 hPa temperature forecasts of the unperturbed (or control) member of the GEFS initialized at 0000 UTC during the period 1 to 30 September, 2011. This period was characterized by two tropical storms (Lee and an unnamed storm), two category one hurricanes (Maria and Nate), and two category four hurricanes (Katia and Ophelia) in the Atlantic Basin.
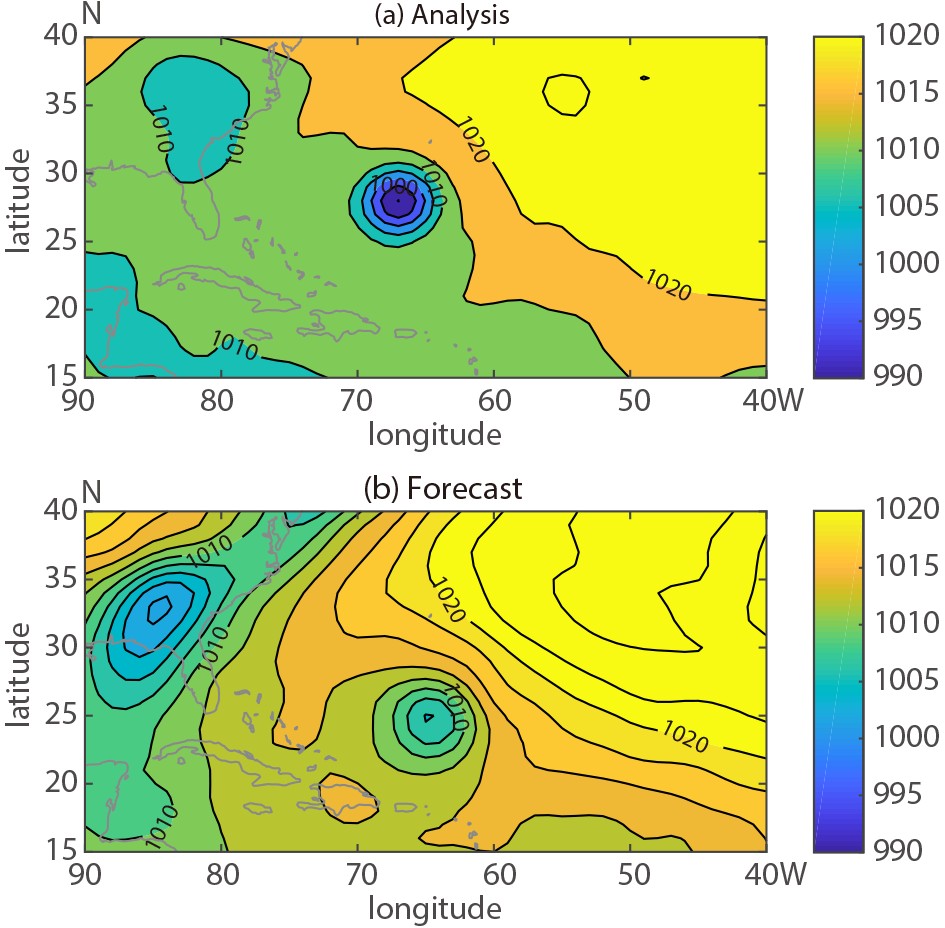 Figure2. GEFS control member 84 h forecast and the GFS analysis valid at 1200 UTC September 6, 2011.
Figure2. GEFS control member 84 h forecast and the GFS analysis valid at 1200 UTC September 6, 2011.The decomposition of the error for the same 84-hour forecast is shown in Fig. 3, with total error as a difference between the original forecast and the verifying analysis field (a), the displacement vector field as defined by the difference in the position of the original and aligned forecast fields (b), the large scale positional error as a difference between the smoothed forecast and the adjusted smoothed aligned forecast fields (c), the large scale amplitude error as a difference between the adjusted smoothed aligned forecast and the smoothed analysis fields (d), and the small scale error as the difference between the total error and total error for large scales. For clarity, the displacement vector field (Fig. 3b) has been scaled and the data have been thinned (represented only at every 2nd grid point). In the tropical Atlantic, the magnitude of the displacement vectors is largest over and around the hurricane itself (Fig. 3b). The structure of the vector field indicates an error related to an along-track delay in the forecast movement of the storm.
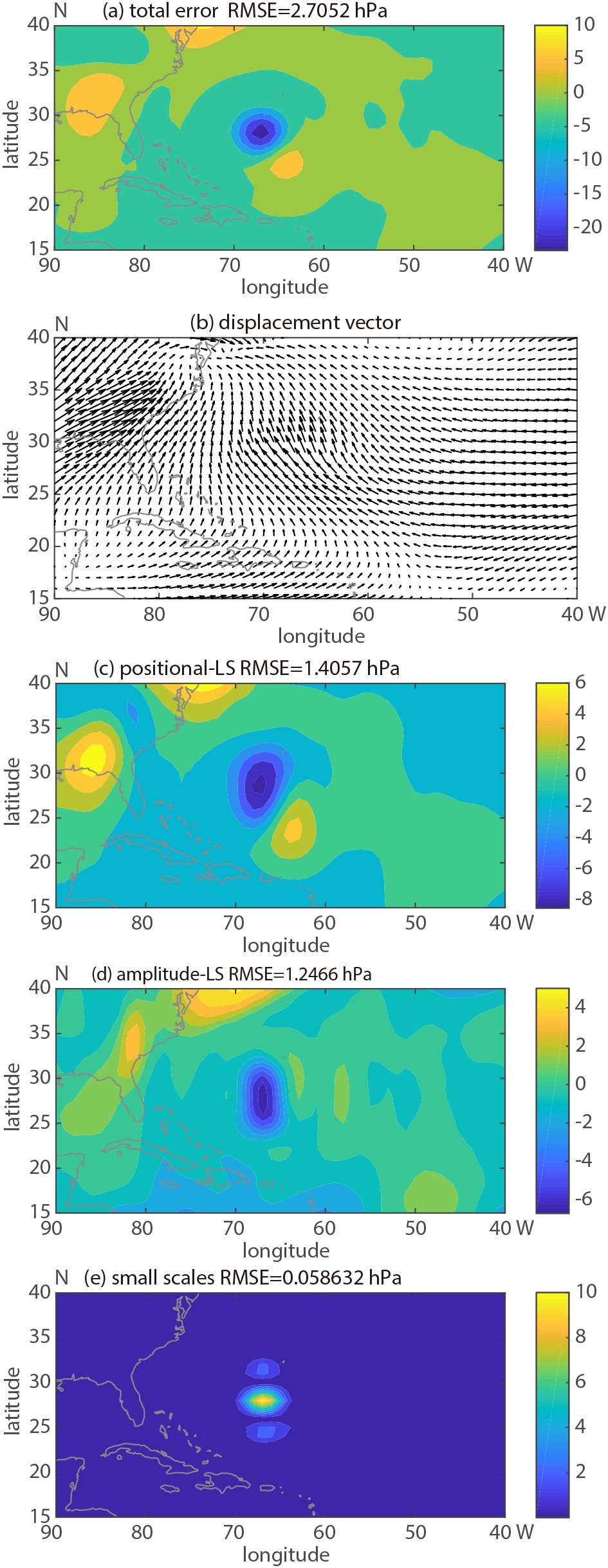 Figure3. Total error (a), displacement vector (b), large scale positional error (c), large scale amplitude error (d) and small scale error for the 84 h lead time GEFS Control member MSLP forecast initialized at 0000 UTC on 3 September 2011. The domain average Root Mean Square Error/Difference (RMSE/RMSD) is included for panels a, c, d and e. Error Variance/difference magnitudes are illustrated with the color bar (hPa).
Figure3. Total error (a), displacement vector (b), large scale positional error (c), large scale amplitude error (d) and small scale error for the 84 h lead time GEFS Control member MSLP forecast initialized at 0000 UTC on 3 September 2011. The domain average Root Mean Square Error/Difference (RMSE/RMSD) is included for panels a, c, d and e. Error Variance/difference magnitudes are illustrated with the color bar (hPa).Focusing on the area of hurricane Katia (2011), the large scale positional error (Fig. 3c) manifests as a dipole pattern, indicating a slower than observed movement of the forecast storm. The large scale structural error (Fig. 3d), on the other hand, has a single minimum, pointing to a forecast storm less intense than observed. While the magnitudes of the large scale positional and structural error are similar, small scale error (Fig. 3e) has a much lower magnitude, except over the hurricane itself (see area average error variance numbers on error panels in Fig 3).
The partitioning of the MSLP forecast error variance components as a function of lead times for the same Katia (2011) forecast also has been examined (Fig. 4). Interestingly, the total error variance initially grows, and then reaches a minimum for 48 h lead time before increasing again. Large scale positional and amplitude components of error follow the same trend as the total error. Importantly, for all lead times large scale positional error variance represents about ~50% of total error while the amplitude (structural) component contributes with only ~15%. The small-scale error variance mainly remains constant with time.
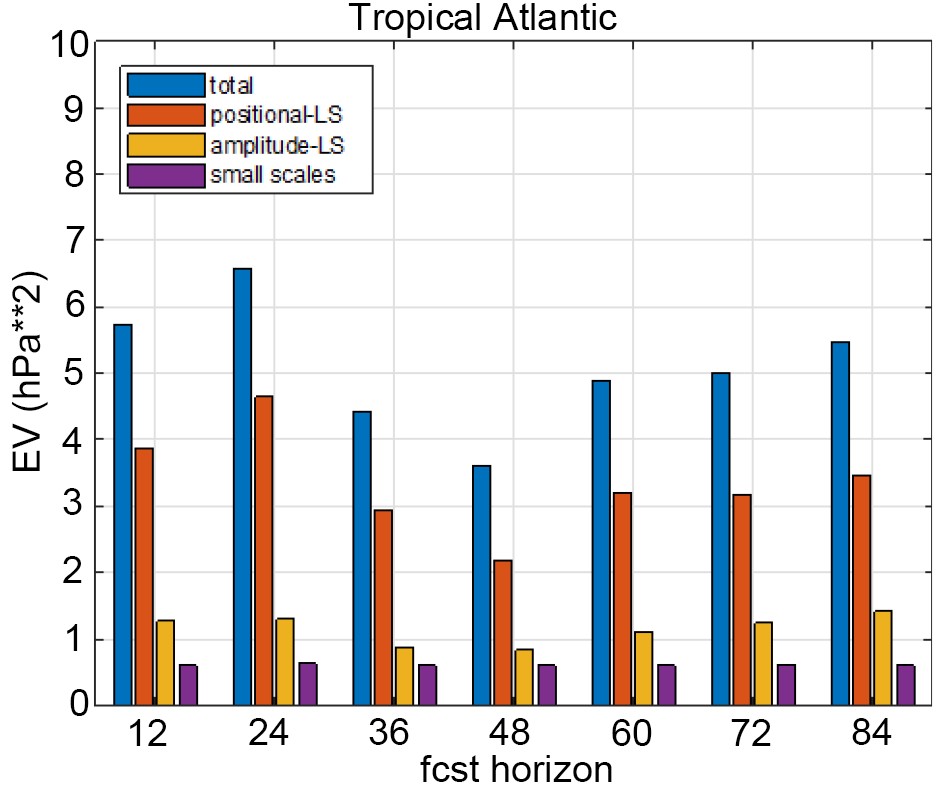 Figure4. The error variance decomposition for MSLP, for different forecast horizons, calculated over the regional domain for a forecast initialized at 0000 UTC 6 September 2011.
Figure4. The error variance decomposition for MSLP, for different forecast horizons, calculated over the regional domain for a forecast initialized at 0000 UTC 6 September 2011.Further inspection of the displacement vector field in Fig. 3b reveals a displacement over the southeastern US even larger than present around hurricane Katia (2011). This particular displacement in the MSLP forecast is associated with the position of frontal zones connecting multiple low pressure centers along the eastern US. To evaluate error partition related to this phenomenon and a different variable, a shorter lead time forecast (24 h) than was available for 850 hPa temperature was evaluated over a domain centered on the Eastern US. Figure 5 shows generally good agreement between the GFS analysis and the GEFS control (unperturbed) member 24 h forecast. More substantial differences between the analysis and GEFS control run appear over the Great Lakes area. The error decomposition is illustrated in Fig. 6. Higher values in large scale amplitude error component are detected over the Great Lake area (Fig. 6d). Similarly, the large-scale positional error component is characterized by similar features in addition to displaying greater amplitudes along the east US coast (Fig. 6c). The domain averaged RMSE values show larger contribution to the total error coming from the positional component (~61%) as compared to the amplitude component (~28%). Small scale error is confined over limited areas in the Great Lake region and along the frontal zone (Fig. 6e).
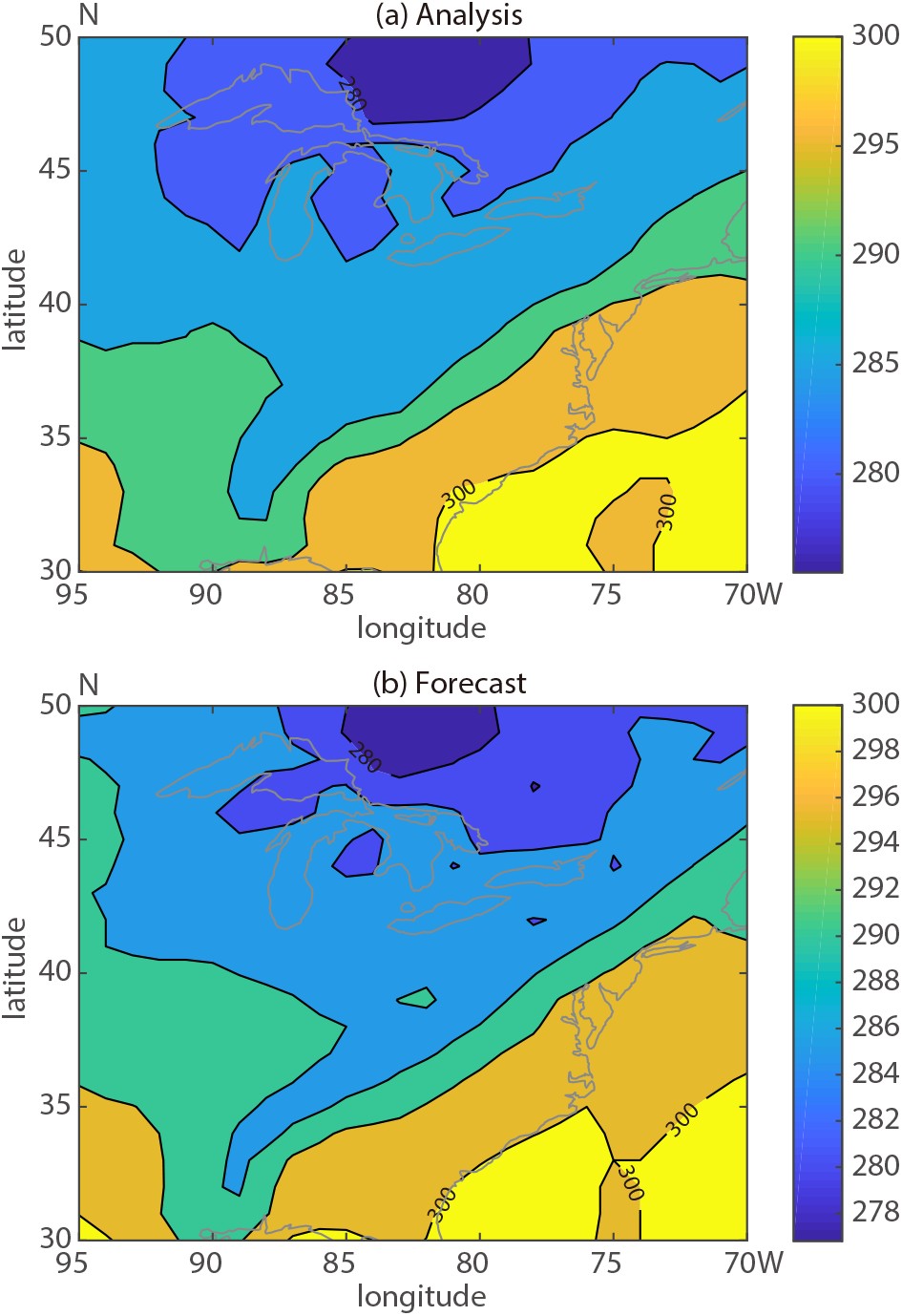 Figure5. GEFS control member 24 h forecast and the GFS analysis valid at 1200 UTC 6 September 2011.
Figure5. GEFS control member 24 h forecast and the GFS analysis valid at 1200 UTC 6 September 2011.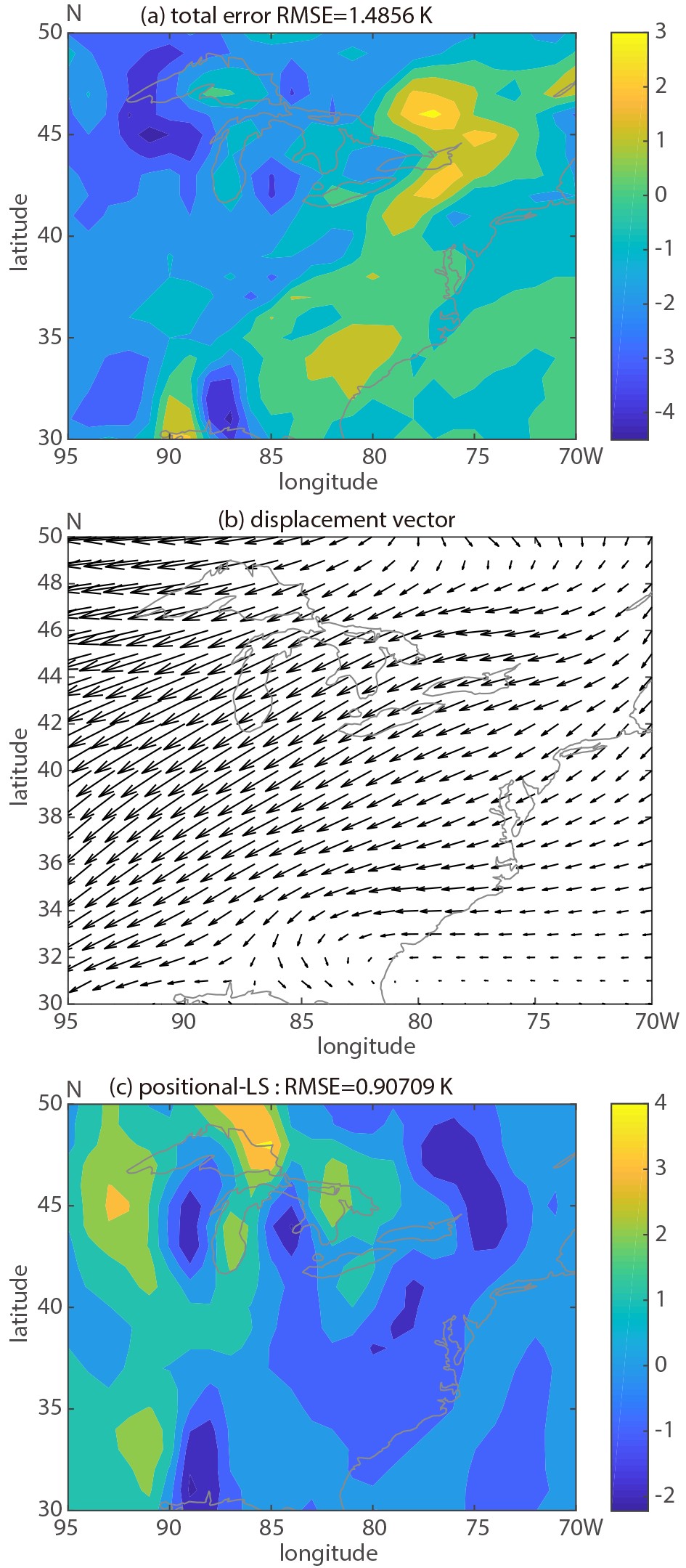 Figure6. As in Fig. 3, except for 850 hPa temperature, 24 h lead time and the domain centered on Eastern US.
Figure6. As in Fig. 3, except for 850 hPa temperature, 24 h lead time and the domain centered on Eastern US.For a statistically more informative evaluation of FED results, Fig. 7 displays the magnitude of the three orthogonal error components over three large non-overlapping regions (tropics, Northern and Southern Hemisphere), averaged over the month of September 2011. First, we note that as expected, the total error (blue bars in Fig. 7) generally exhibits a growing tendency with increasing lead times. In all regions and at all lead times, large scale positional error (red bars) is the largest of the three components. Approximately 50%, 60%, and 75% of the total error variance is associated with the large-scale positional error for features over the Tropics, the Northern and Southern hemispheres, respectively. Large scale positional error in general also displays a growing tendency as a function of lead time, indicative of chaotic error growth.
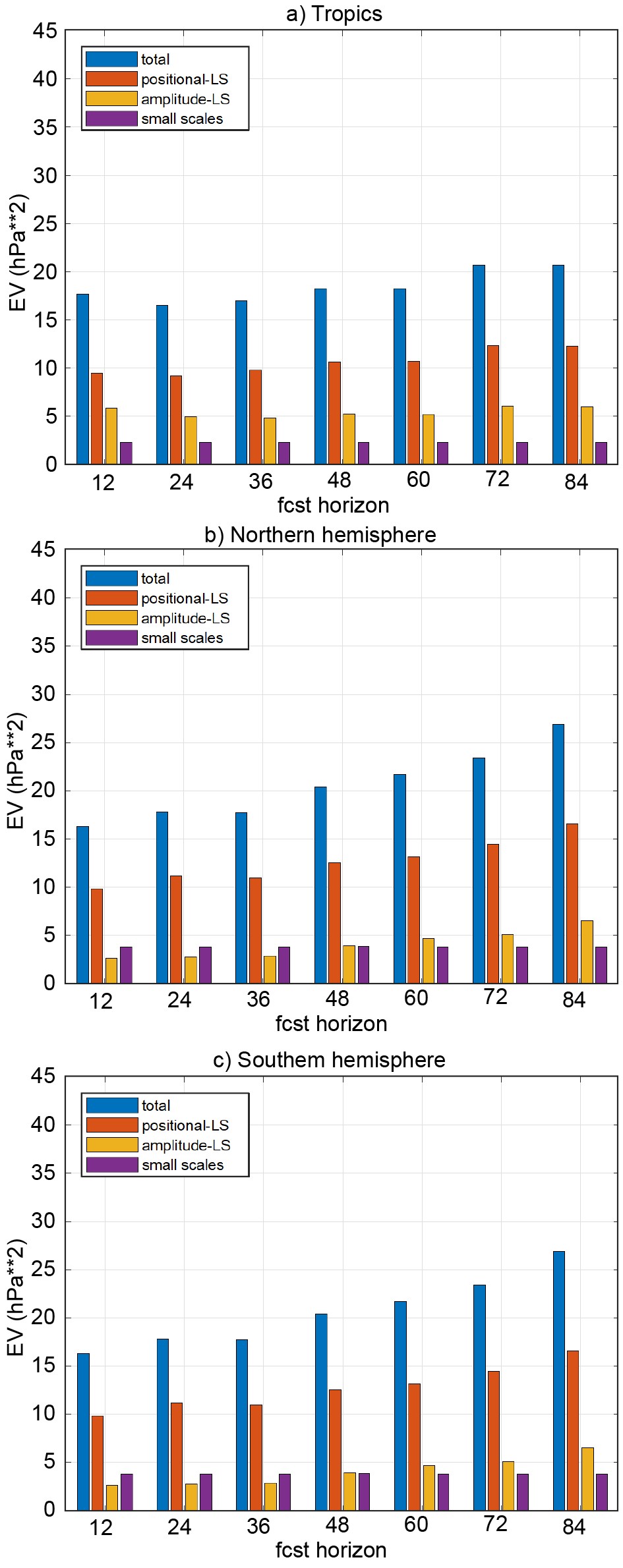 Figure7. As in Figure 4, except for various regions of the globe (tropics—30°S?30°N, Northern—30°?90°N, and Southern hemispheres—30°?90°S) and for the entire month of September 2011.
Figure7. As in Figure 4, except for various regions of the globe (tropics—30°S?30°N, Northern—30°?90°N, and Southern hemispheres—30°?90°S) and for the entire month of September 2011.Over the different lead times and domains, large scale structural and small scale error variance is ~20%?30% and ~10%?15% percent of the total error variance, respectively. In contrast to the large scale positional error, these error components do not always exhibit a growing tendency with increasing lead time. For example, large scale structural / small scale errors do not have a clear growing tendency over the Tropics / Tropics and NH, respectively. The lack of error growth in these regions may be indicative of model error in representing natural phenomena in these regions.
The main focus of this study was to demonstrate the use of the FA technique in FED for quantifying major modes of forecast error. The use of FED was illustrated through a case study [Hurricane Katia (2011)] where the approach was applied to two different variables, MSLP and 850 hPa temperature (Figs. 3 and 6), and through MSLP error statistics calculated over a month-long period (Sep. 2011, Fig. 7). Both approaches showed consistent results. A significant portion of forecast error variance (~50%?70%, depending on geographical region and lead time) is associated with large-scale displacement of forecast features. Notably smaller portions of the total error variance are related to large-scale structural and small-scale error variance. The generality of these results will need to be assessed over extended datasets.
In certain applications, feature-based error decomposition techniques have been used extensively. Errors in TC forecasts, for example, have been described in terms of position and intensity errors. Such applications (a) require the identification of certain features (e.g., the center of a TC), and (b) limit the forecast evaluation to the pre-selected feature. In contrast, with its more general approach, FED offers more detailed, gridded information pertaining not only to pre-selected features but to their environment as well. In case of TC forecasts, for example, the quality of the forecasts can be described by displacement vector and structural error fields, instead of just the error in the position and intensity of the central (or another selected) point of the storm (cf. Fig 3).
Though FA has so far been demonstrated only on 2D fields, its extension to 3D is feasible. Even in its current form, the spatially distributed approach of FED naturally lends itself for use in more thorough diagnostic studies. Potential applications include the assessment of systematic errors in terms of positional and amplitude components. Detailed analyses of various experiments can provide useful feedback to model and data assimilation technique developers by suggesting areas that may be dominated more by positional or structural errors, associated more either with initial value (e.g., amplifying) or model related (e.g., systematic structural) uncertainties, respectively.
Forecasters have long expressed an interest in separately assessing uncertainty in the phase (i.e., position) and amplitude of forecast features (see, e.g., NCEP, 2004). Given the encouraging experiments reported here, we advocate for the more widespread use of gridded error decomposition tools such as that tested in the current paper.
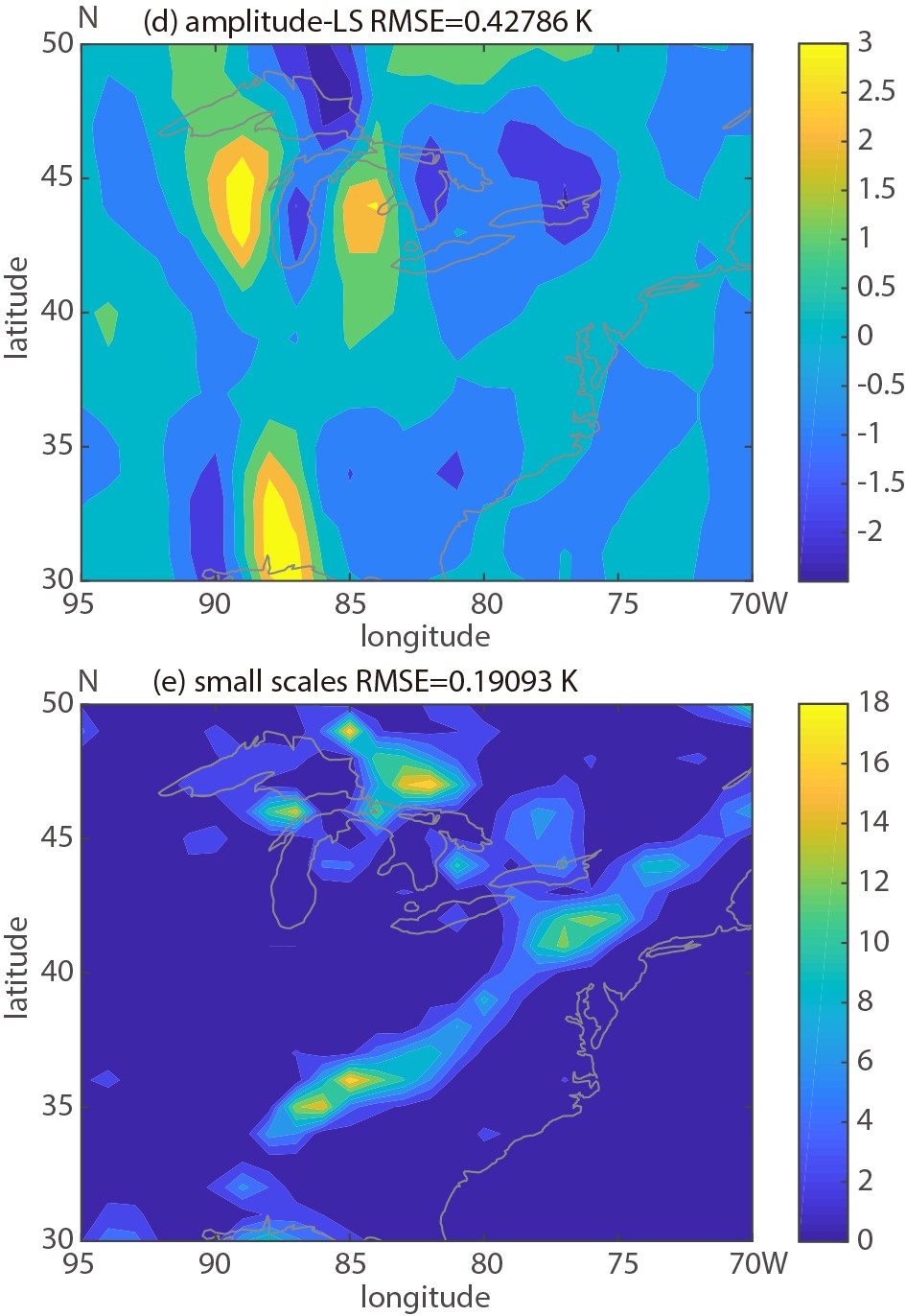 Figure6. (Continued)
Figure6. (Continued)Acknowledgements. The authors would like to thank Tim MARCHOK of GFDL for helpful discussions, Dr. Michael BRENNAN of NHC for providing along and across track error statistics for Hurricane Katia (2011), and Drs. Jie FENG, Lidia TRAILOVIC, Edward TOLLERUD (all formerly affiliated with GSL), and two anonymous reviewers for their comments on an earlier version of this manuscript.
