0 引言
【研究意义】谷子起源于中国,是传统的优势作物、主食作物和抗旱耐瘠作物[1],距今已有8 700多年的栽培历史[2]。谷子具有抗旱耐瘠、水分利用效率高、适应性广、营养丰富、各种成分平衡、饲草蛋白含量高等突出特点,被认为是应对未来水资源短缺的战略贮备作物,建设可持续农业的生态作物以及人们膳食结构调整、平衡营养的特色作物[3-5]。中国既是栽培谷子的起源地,也是拥有谷子种质资源最多、研究利用最充分的国家。全世界谷子总产中,中国占80%[6],主要种植区分布在北方干旱、半干旱地区。在“全国种植业结构调整规划(2016—2020)”[7]中指出:适当调减“镰刀弯”地区玉米面积,改种耐旱耐瘠薄的薯类、杂粮杂豆,满足市场需求,保护生态环境。可见谷子等耐旱耐贫瘠杂粮类资源越来越受到重视,而掌握谷子资源在空间上的总体质量分布概况,对于有效利用和开发谷子资源、寻找优异谷子种质具有重要意义。【前人研究进展】近年对谷子资源的品质及农艺性状的研究也越来越多。李庆春等[8]从各生态区的角度对于谷子的蛋白含量进行和普查与评价,从统计学的角度分析了各生态区内谷子资源粗蛋白含量的极值、平均值和标准差等;那海智等[9]通过研究谷子粗蛋白、粗脂肪含量与物候期的关系得出,生育期越短,粗蛋白含量越高,反之越低,而生育期对粗脂肪的影响并不显著;王海岗等[10]利用聚类分析、相关分析和主成分分析等方法对谷子核心种质的茎粗、穗重、粒色等15个表型性状进行了分析和综合评价。刘三才等[11]测量和评价了谷子品种资源内微量元素硒和蛋白质的含量;刘敏轩等[12]利用统计分析和相关性分析等方法研究了谷子育成品种维生素E含量分布规律及其与主要农艺性状和类胡萝卜素的相关性分析。以上研究的共同点在于,在研究某一性状的分布特点或地区差异时,均采用数理统计、相关性分析等数学方法得到一个或几个数值,根据数值差异定量的评价该性状,均利用省份或生态区作为分区研究区域差异。【本研究切入点】这种方法虽然能够从定量角度充分说明资源性状的特性,但不能直观的反映出某一性状在地理空间上的分布特性,可视化效果差;并且以行政区划为单元对谷子资源性状的地区差异进行分析打破了原有的自然区划关联。【拟解决的关键问题】本研究从地理空间的角度出发,利用空间插值、空间聚类等方法研究谷子资源的农艺及品质性状的空间分布规律,为解决传统分析方法中可视化差及行政界线的限制等问题提出依据。1 材料与方法
1.1 材料
20世纪50年代以来,中国先后组织了两次全国规模的农作物种质资源调查,在资源调查和信息共享方面取得了重大进展和显著成效,积累了大量的种质资源数据[13-15]。同时,近十年来,中国先后在云南、贵州、西南干旱地区、东部沿海等地区开展了多次种质资源调查工作,丰富了国家农作物种质资源数据库。对于国家农作物种质资源数据库中的谷子资源数据,共整理出27 000余条谷子资源数据记录,这些数据中,初步完成了形态学特征和农艺性状鉴定半数种质进行了抗病虫、抗逆、营养品质的特性鉴定[16]。根据其经纬度属性信息转换为地理空间数据(图1)。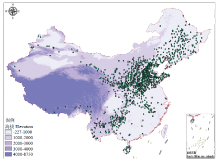 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图1谷子资源分布图
-->Fig. 1The distribution map of foxtail millet germplasm resources
-->
1.2 方法
由于谷子种质资源数据在空间上为点数据,不利于进行空间分析等操作。而针对点数据,在空间上可利用地统计分析方法通过插值得到面上的数据,从而进一步进行空间分析。基于该点考虑,首先对谷子种质资源待分析的属性值进行插值,估测全国各地对应的属性值情况,然后将全国网格化数据与插值数据进行分区统计,将属性值赋给每个网格,并利用赋值的网格数据进行优化热点分析,实现网格的聚类,最后将聚类结果进一步处理,对全国进行分区,找到目标属性对应的高值、随机值和低值区域。1.2.1 农艺及品质性状数据空间插值 地统计分析方法可用于估计尚未进行任何采样的位置的值以及评估这些估计的不确定性。地统计分析方法主要用来研究那些在空间上既有随机性又有结构性的自然现象[17]。由南非矿山工程师KRIGE等[18]在金矿储量估计上提出了该方法的雏形,其应用领域从地质、矿业逐渐拓展到土壤[19]、水资源[20]、农业[21-23]、气象[24]、海洋[25]等领域。地统计中最常用的空间插值方法为克里金插值法,该方法是建立在变异函数理论及结构分析基础之上的,在插值时需要选择一种适宜的半变异函数模型,并且待插值的数据需要服从或近似服从正态分布。所以在选择使用克里金插值方法时,首选需进行数据分布检验,确定该数据是否适合插值,然后利用交叉检验法对插值结果的精度进行评价,从而选择最适宜的半变异函数模型进行插值。
1.2.2 农艺及品质性状数据网格化处理 网格是对地理空间的划分[26]。网格化数据不仅能够实现不同尺度、不同类型数据的统一和融合,而且能够打破行政单元约束,提高信息检索与更新效率[27-28]。与栅格数据相比,便于空间统计和分析,选择将插值得到的栅格数据转换成统一大小的网格数据。首先根据全国的范围,选择适宜的网格大小,创建全国范围内的网格数据,并利用空间分析中的分区统计方法,将对应的插值后的农艺或品质性状数据统计到每个网格上,得到带有目标属性值的网格数据。
1.2.3 农艺及品质性状数据空间聚类及区域划分 通过空间聚类,将空间上相邻、数值上相近的网格数据聚集成一类,根据聚类结果进行区域划分。空间聚类的方法很多,热点分析方法就是其中一种,它的特点是能够识别具有统计显著性的高值(热点)和低值(冷点)的空间聚类。利用该方法,不仅能够实现聚类,而且能够根据聚类结果区分出哪些地区对应的值比较高,哪些地区对应的值比较低,比较符合本研究的需求。故在空间聚类方面,选择利用ARCGIS的优化热点分析工具,对网格数据进行高低值聚类。根据聚类结果,将网格数据分为高值、随机值和低值三类,融合空间相邻、类别相同的网格,并进行平滑处理,划分农艺或品质性状的空间分布区域。
具体流程如下:
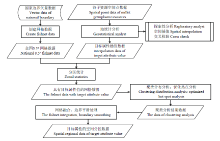 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图2方法流程图
-->Fig. 2The flow chart of the method
-->
2 结果
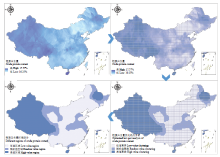
根据谷子种质资源的数据和地统计中的探索性分析,最终选择粗蛋白含量和粗脂肪含量2个品质性状与生育期和单株粒重2个农艺性状为空间分区要素,对以上方法进行实例化分析。在27 000余份资源数据中,分别具有粗脂肪值、粗蛋白值、单株粒重值、生育期值的资源有20 451份、20 477份、25 807份和26 420份,这4项属性数据的缺失较少,并且经过数据分布检验后表明,这4项数据的分布均接近于正态分布(图3),适合利用克里金法进行空间插值。 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图34种目标属性的直方图分布情况
-->Fig. 3The distribution histograms of the four target attributes
-->
对以上4项属性数据进行空间插值,选择球面函数、高斯函数和四球3种半变异函数模型进行插值,利用平均值预测误差、平均标准误差、均方根预测误差、均方根标准化误差进行交叉检验,检验结果如表1所示。在交叉检验中,如果预测误差具有无偏性,平均值预测误差应接近于0;如果正确估计了预测中的变异性,平均标准误差与均方根预测误差应接近,并且均方根标准化误差应接近于1。经过综合分析发现,这4类性状均在利用高斯函数模型时预测效果最优。
Table 1
表1
表1不同变异函数模型的插值误差值对比
Table 1Comparison result of interpolation error values of different variation function models
| 4种性状的变异函数模型 The variation function models of four traits | 平均值预测误差 Mean forecast error (MFE) | 平均标准误差 Mean standard error (MSE) | 均方根预测误差 Root mean square forecast error (RMSFE) | 均方根标准化误差 Root mean square standard error (RMSSE) |
|---|---|---|---|---|
| 粗蛋白含量 Crude protein content | ||||
| 球面函数Spherical function | -0.0334 | 1.6018 | 1.5008 | 0.9376 |
| 高斯函数Gaussian function | -0.0317 | 1.5588 | 1.5034 | 0.9652 |
| 四球Four-ball function | -0.0336 | 1.5919 | 1.5001 | 0.9430 |
| 粗脂肪含量Crude fat content | ||||
| 球面函数Spherical function | 0.0253 | 0.7170 | 0.6797 | 0.9471 |
| 高斯函数Gaussian function | 0.0244 | 0.7169 | 0.6810 | 0.9492 |
| 四球Four-ball function | 0.0252 | 0.7174 | 0.6796 | 0.9465 |
| 单株粒重 Kernel weight of single plant | ||||
| 球面函数Spherical function | 0.0607 | 5.2316 | 5.4249 | 1.0362 |
| 高斯函数Gaussian function | 0.0378 | 5.3691 | 5.4644 | 1.0178 |
| 四球Four-ball function | 0.0611 | 5.2132 | 5.4245 | 1.0398 |
| 生育期Growth period | ||||
| 球面函数Spherical function | 0.0167 | 12.1834 | 11.2528 | 0.9254 |
| 高斯函数Gaussian function | 0.0244 | 12.1207 | 11.3770 | 0.9413 |
| 四球Four-ball function | 0.0133 | 12.0128 | 11.2472 | 0.9380 |
新窗口打开
 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图4谷子资源粗蛋白含量的区域划分结果
-->Fig. 4The result of dividing the crude protein content in foxtail millet germplasm resources
-->
对经过插值后的数据进行网格化处理、空间聚类分析、网格融合和平滑处理,最终得到4项要素的空间分区分布图(图3—图6)。
蛋白质含量是谷子营养品质的主要构成成分之一[29-30],在谷子品质育种中应重点提高蛋白质含量[31]。谷子资源粗蛋白含量高的地区主要集中在中国的西部地区和黑龙江省东北部,低值地区主要在中国的中部和东部,在高低值之间存在随机值过度地带,呈现两侧向中间越来越小的分布趋势,不是随意穿插分布的,并且各分区的多边形相对面积较大,不存在零星分布的小多边形,说明中国谷子的粗蛋白含量地域连续性较强(图3)。从均值上看,根据表2数据,粗蛋白含量的全国平均值为(13.98±1.23)%,低值区平均值为(12.80±0.70)%,占41.89%;随机区平均值为(13.98±0.39)%,占18.69%;高值区平均值为(15.24±0.42)%,占全国总面积39.42%。由于高值地区主要分布在西部高原地区,大部分地区不适宜种植,而谷子主要种植区均属于粗蛋白含量低值区,表明中国谷子资源的粗蛋白含量高且聚集分布的区域较小,大部分谷子的粗蛋白含量水平处于低值聚集区的水平上。从变幅上看,全国粗蛋白含量变幅在10.47%—17.33%,低值区、随机值区、高值区的变幅分别在10.47%—14.90%、12.72%—15.30%和13.61%—17.33%,低值区的跨度最大,并且三者的变幅值有重复部分,这是因为空间聚类时不仅需要考虑数值的近似性,还要考虑空间上的相邻性,所以不会严格按照数据标准进行聚类。从聚类效果看,粗蛋白含量的全国变异系数为8.80%,低值区、随机值区和高值区的变异系数分别为5.47%、2.79%和2.76%。变异系数越小,证明聚类的效果最好,经过聚类后的3个分区的变异系数都小于国家级变异系数,高值区聚类效果最佳,低值区聚类效果最弱。
谷子资源粗脂肪含量高的地区主要集中在中部地区,低值地区为西部和部分东北地区,与粗蛋白情况相反,呈现中间向两侧越来越小的趋势分布,并且相对于粗蛋白含量的分区结果来说,出现多个面积较小的分区多边形,分区相对不规整(图4)。从均值上看,根据表2数据,粗脂肪含量的全国平均值为(4.01±0.38)%,低值区平均值为(3.69±0.13)%,占44.36%;随机值区平均值为(3.99±0.16)%,占18.67%;高值区平均值为(4.41±0.26)%,占全国总面积36.97%。虽然低值区域占地面积最大,但由于西部地区存在大面积不适宜种植的区域,所以,从整体上来看,中国谷子资源的粗脂肪含量高且呈现聚集的区域面积广阔。从变幅上看,全国谷子资源粗脂肪含量变幅在3.08%—5.47%,低值区、随机值区、高值区的变幅分别在3.11%—4.39%、3.08%—4.48%和3.57%—5.47%,3个区间均有重叠部分,其中,随机值区域跨度最大。从聚类效果看,粗脂肪含量的全国变异系数为9.48%,高于粗蛋白含量的变异系数,说明粗脂肪含量的聚类效果不如粗蛋白含量的显著。低值区、随机值区和高值区的变异系数分别为3.52%、4.01%和5.89%。低值区聚类效果最佳,高值区聚类效果最弱。
 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图5谷子资源粗脂肪含量区域划分结果
-->Fig. 5The result of dividing the crude fat content in foxtail millet germplasm resources
-->
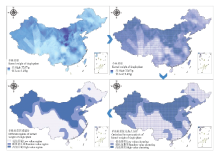 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图6谷子资源单株粒重区域划分结果
-->Fig. 6The result of dividing the kernel weight of single plant in foxtail millet germplasm resources
-->
单株粒重直接影响谷子的产量,当种植密度相同时,单株粒重越大,产量越高。从地理分布上分析(图6),宁夏、山西、陕西,以及甘肃、内蒙、湖北和新疆大部分地区、河北北部和山东中部均属于高值区,而黑龙江、浙江、内蒙北部、安徽南部以及中国的大部分西南地区,均属于单株粒重低值区;其他地区属于高值区与低值区的过度地带的随机值区。从均值(表2)上看,单株粒重的全国平均值为(10.39±4.13)g,低值区平均值为(6.49±1.84)g,占39.45%;随机值区平均值为(10.51±1.49)g,占22.80%;高值区平均值为(14.44±2.88)g,占全国总面积37.75%。正如上文所说,虽然低值区域占地面积大,但由于这些地区不属于谷子的主要种植区,所以,从整体上来看,中国谷子主要集中在单株粒重高的高值区域内。从变幅上看,全国谷子单株粒重变幅在(1.65—29.30)g,低值区、随机值区、高值区的变幅分别在(1.65—13.38)、(5.42—16.54)和(7.63—29.30)g,3个区间均有重叠部分,其中高值区域跨度最大。从聚类效果看,单株粒重的全国变异系数为39.75%,属于这4项性状中变异系数最高的1项,说明单株粒重在这4项性状中聚类效果最弱,全国范围内差异最明显;低值区、随机值区和高值区的变异系数分别为23.73%、14.18%和19.94%。随机值区聚类效果最佳,低值区聚类效果最弱。
Table 2
表2
表24项性状聚类后的相关统计数值表
Table 2The correlation statistical values of the clustering results of the four characters
| 农艺及品质性状 Agronomic and quality traits | 分区 Region | 平均值 Mean±SD | 变幅 Range | 变异系数 CV (%) |
|---|---|---|---|---|
| 粗蛋白含量 Crude protein content (%) | 全国 National Scale | 13.98±1.23 | 10.47—17.33 | 8.80 |
| 低值区 Low Value Region | 12.80±0.70 | 10.47—14.90 | 5.47 | |
| 随机值区 Random Value region | 13.98±0.39 | 12.72—15.30 | 2.79 | |
| 高值区 High Value region | 15.24±0.42 | 13.61—17.33 | 2.76 | |
| 粗脂肪含量 Crude fat content (%) | 全国 National Scale | 4.01±0.38 | 3.08—5.47 | 9.48 |
| 低值区 Low Value Region | 3.69±0.13 | 3.11—4.39 | 3.52 | |
| 随机值区 Random Value Region | 3.99±0.16 | 3.08—4.48 | 4.01 | |
| 高值区 High Value Region | 4.41±0.26 | 3.57—5.47 | 5.89 | |
| 单株粒重 Grain weight per main stem (g) | 全国 National Scale | 10.39±4.13 | 1.65—29.30 | 39.75 |
| 低值区 Low Value Region | 6.49±1.84 | 1.65—13.38 | 23.73 | |
| 随机值区 Random Value Region | 10.51±1.49 | 5.42—16.54 | 14.18 | |
| 高值区 High Value Region | 14.44±2.88 | 7.63—29.30 | 19.94 | |
| 生育期 Growth period (d) | 全国 National Scale | 111.46±10.94 | 79.15—150.43 | 9.81 |
| 低值区 Low Value Region | 99.58±6.64 | 79.15—116.81 | 6.67 | |
| 随机值区 Random Value Region | 111.89±2.99 | 99.53—124.44 | 2.67 | |
| 高值区 High Value Region | 121.17±6.04 | 108.34—150.43 | 4.98 |
新窗口打开
从生育期的地理分布分析来看(图7),东北大部分地区、西北和西南部分地区属于生育期较长的地区,生育期较短区域主要包括了河南、山东、河北等谷子夏播期的地区。从数值上分析(表2),生育期的全国平均值为(111.46±10.94)d,低值区平均值为(99.58±6.64)d,占34.28%;随机值区平均值为(111.89±2.99)d,占24.30%;高值区平均值为(121.17±6.04)d,占全国总面积41.42%。从变幅上看,全国生育期变幅在(79.15—150.43) d,高值区、随机值区、低值区的变幅分别在(108.34—150.43)、(99.53—124.44)、(79.15—116.81) d,3个区间均有重叠部分,其中高值区域跨度最大。从聚类效果看,全国变异系数为9.81%,高值区、随机值区和低值区的变异系数分别为4.98%、2.67%和6.67%。随机值区聚类效果最佳,低值区聚类效果最弱。
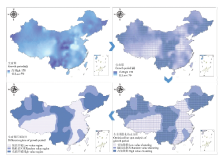 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图7谷子资源生育期区域划分结果
-->Fig. 7The result of dividing the growth period in foxtail millet germplasm resources
-->
3 讨论
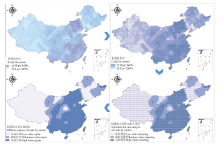
本方法主要根据插值后的结果进行聚类分区,尚未考虑其他因素对谷子种植的影响,所以未区分哪些地区是谷子的适宜和非适宜种植区,而因为海拔、气候等原因,使得一些地区无法进行农作物的种植。根据图1谷子资源样点的分布,绝大部分分布在海拔3 000 m以下的地区,若将海拔3 000 m以上的区域作为谷子不适宜种植区域并进行扣除,各性状的高低值区域比例则会发生较大的变动,如图8所示。粗蛋白含量被扣除的主要是高值区域,其余3个性状被扣除的主要是低值区域。所以,在考虑海拔限制的前提下,粗蛋白含量的高值区主要集中在新疆和黑龙江省东北部,低值区主要在中部和东部;粗脂肪含量的高值区主要集中在中部地区,低值地区为新疆和东北的部分地区;单株粒重的高值区主要集中在宁夏、山西、陕西,以及甘肃、内蒙、湖北和新疆大部分地区、河北北部和山东中部等谷子主要种植区,低值区主要集中在东北和西南地区;生育期的高值区为东北大部分地区、西北和西南部分地区,低值区为东南沿海地区。再加入其它限制因素时,可进一步缩小资源的分布区域,进一步细化资源各性状的高低值分区布局。对于每项性状的聚类,其高低值类型区的划分是
一个相对概念,与聚类时对应的空间尺度关系密切,在另外一个尺度下,如生态类型区尺度下再进行聚类,会出现不同的聚类结果,所以本研究的聚类仅针对国家尺度上的分析。另外,克里金插值是一种光滑的内插方法,在数据点多时,其内插的结果可信度较高,而数据点少的地区其插值结果的偏差则会较大。中国西部和东南部地区的样点数量较少,并且存在大面积地区无样点的情况,这些地区的插值结果的可信度会明显低于中部和东北地区(图1)。
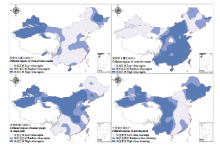 显示原图|下载原图ZIP|生成PPT
显示原图|下载原图ZIP|生成PPT图8海拔限制下的四性状空间分布
-->Fig. 8Spatial distribution of four characters under altitude restriction
-->
4 结论
4.1 谷子资源的粗蛋白含量、粗脂肪含量、单株粒重、生育期4种性状数据的分布均接近于正态分布,适合利用克里金法进行空间插值;对比球面函数、高斯函数和四球3种半变异函数模型插值效果,这4种性状数据均选择高斯函数模型时预测效果最优。4.2 谷子资源粗蛋白含量的高值区、随机值区和低值区的变异系数分别为2.76%、2.79%和5.47%,高值区聚类效果最佳(类内相似性最大,下同),低值区聚类效果最弱(类内相似性最小,下同)。粗脂肪含量的高值区、随机值区和低值区的变异系数分别为3.52%、4.01%和5.89%,低值区聚类效果最佳,高值区聚类效果最弱。单株粒重的高值区、随机值区和低值区的变异系数分别为23.73%、14.18%和19.94%,随机值区聚类效果最佳,低值区聚类效果最弱。生育期的高值区、随机值区和低值区的变异系数分别为6.67%、2.67%和4.98%,随机值区聚类效果最佳,低值区聚类效果最弱。
4.3 谷子资源粗蛋白含量的高值区集中在新疆和黑龙江省东北部,低值区主要在中部和东部,呈现两侧向中间越来越小的分布趋势,地域连续性较强;粗脂肪含量的高值区主要集中在中部地区,低值地区为新疆和东北的部分地区,呈现中间向两侧越来越小的趋势分布,并且相对于粗蛋白含量的分区结果来说,出现多个面积较小的分区多边形,分区相对不规整;单株粒重的高值区主要集中在宁夏、山西、陕西,以及甘肃、内蒙、湖北和新疆大部分地区、河北北部和山东中部,低值区主要集中在东北和西南地区;生育期的高值区为东北大部分地区、西北和西南部分地区,低值区主要集中在河南、山东、河北等谷子夏播期的地区。
The authors have declared that no competing interests exist.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}